Month: May 2026
Blog
Server Dedicated USA: Provider Comparison Checklist
In the US dedicated-infrastructure market, the real differentiator is no longer the processor line on a product page. It is whether a provider can move from quote to production quickly, keep bandwidth and IP behavior predictable under pressure, and reduce the manual work your team inherits after the order is placed. Recent data-center market research says 64% of North American capacity under construction now sits outside traditional mature markets, while operators report rising costs and tighter power constraints. In that environment, “available now,” “automatable now,” and “stable endpoint now” matter more than another raw-hardware headline.
Melbicom gives that decision a practical shape through its Atlanta and Los Angeles locations. The current US ready-configuration list includes dozens of servers in Atlanta and 50+ in Los Angeles. At network level, Melbicom operates 21 data-center locations globally, works with 20+ transit providers and 25+ IXPs, and runs 55+ CDN PoPs across 39 countries.
USA Servers Ready— Atlanta and LA inventory — Guaranteed bandwidth — Crypto-friendly billing |
 |
Why a Server Dedicated USA Shortlist Is Now an Operations Decision
A modern USA dedicated server shortlist should start with route behavior, deployment workflow, and trust boundaries before CPU bins. The useful question is not “Which server is fastest on paper?” It is “Which US location and provider keep latency stable, endpoints consistent, and recovery scriptable when traffic, maintenance, or incidents arrive?”
That shift changes procurement. City names are not enough; teams should test from the geographies that feed the workload. We at Melbicom publish test hosts and downloadable files for both Atlanta and Los Angeles, which lets buyers run packet-loss, path, and throughput checks before committing. The second screen is deployability: stock status, activation time, API access, and a clear support boundary are leading indicators of whether production will run by workflow or ticket queue.
How to Evaluate USA Dedicated Server Offers for Bandwidth, API, and Support

A strong USA dedicated server offer should make five things explicit: bandwidth terms, DDoS posture, IP policy, automation surface, and support scope. API-first survey data says 82% of organizations now use at least some API-first practice, with a quarter fully API-first, so manual-only provisioning is now incident risk.
What a Dedicated Server in USA Should Prove Before You Sign
Bandwidth is where “high bandwidth” often becomes slippery. Separate port speed from guaranteed throughput, oversubscription language, metered versus unmetered terms, and the treatment of attack traffic. For instance, Melbicom offers guaranteed bandwidth and flat monthly pricing tied to hardware and chosen port speed.
| Area | Provider Proof to Request | Deployment Implication |
|---|---|---|
| Bandwidth model | Port speed; guaranteed throughput; metering; attack-traffic billing | Confirms the real sustained channel |
| DDoS posture | Scrubbing mode; telemetry visibility; handoff process; billing impact | Shows behavior under hostile traffic |
| IP policy | IPv4/IPv6; BYOIP; BGP; RPKI/ROA process | Protects endpoints and allowlists |
| Automation and support | Provisioning API; rebuilds; auth model; KVM/IPMI; 24/7 scope | Keeps failover replayable |
| Crypto procurement | Settlement asset; invoice currency; confirmations; renewals; credits/refunds | Prevents renewal friction |
Support needs the same scrutiny. “24/7 support” can mean anything from remote hands to useful help during OS installs, rebuilds, and maintenance windows. DDoS posture belongs in the same pass. Threat telemetry recorded more than 8 million DDoS attacks in a six-month period, and the operational question is not whether a badge says “protected.” It is where scrubbing happens, what telemetry remains visible, and whether attack traffic can distort billing or capacity planning.
Managed vs. Unmanaged US Dedicated Servers for Nodes and Apps
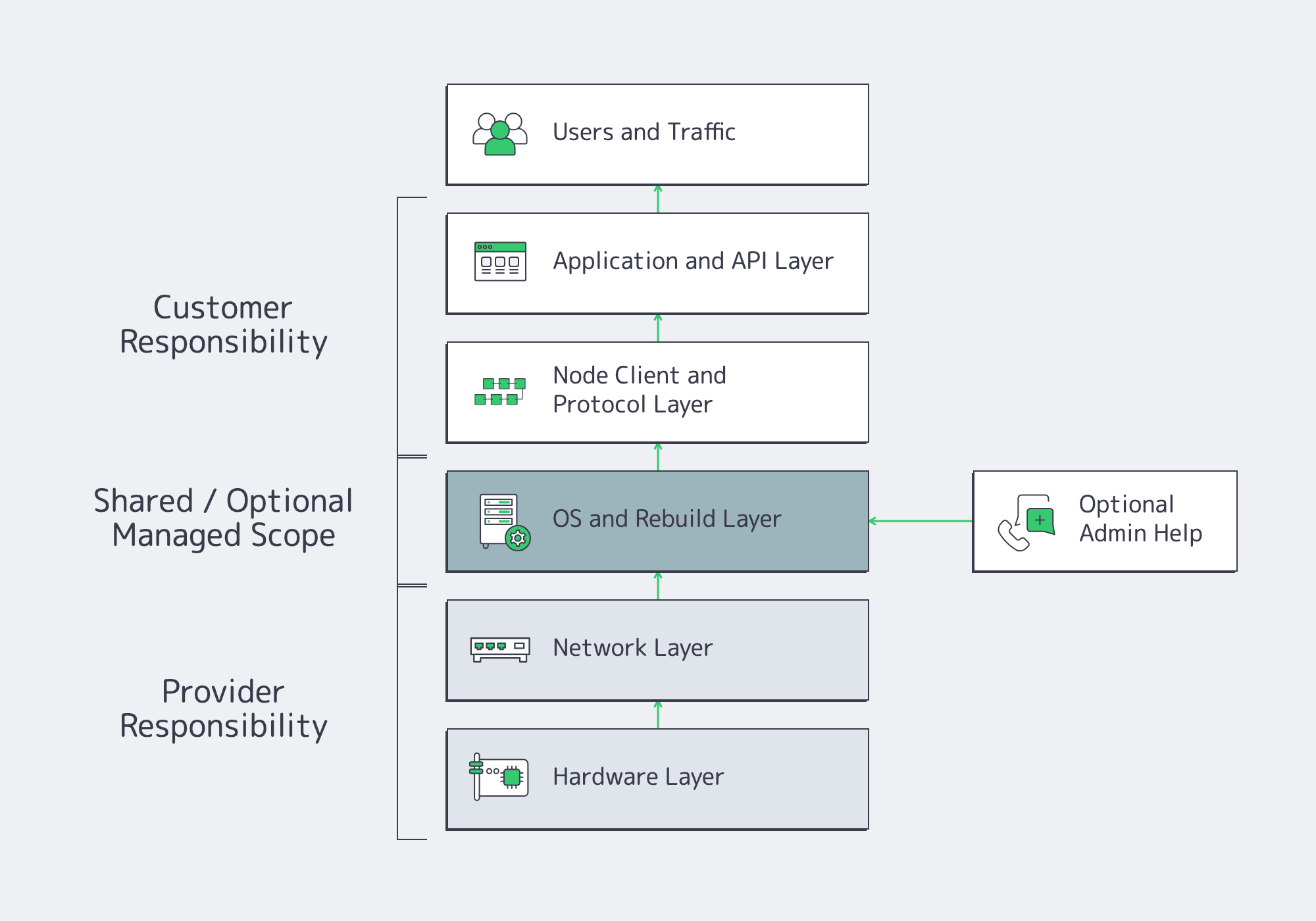
For node workloads and production apps, managed versus unmanaged is too blunt. The practical question is which layers the provider operates and which layers your team retains. The common target is provider-operated hardware and network, customer-controlled protocol and application logic, plus optional administration help for OS work, rebuilds, and patch windows.
For instance, in Web3, that split matters in node and RPC deployment hardening. A resilient layout separates authoritative node paths from public RPC fan-out, keeps replication on private paths, and uses BGP or BYOIP when endpoint continuity matters during maintenance or regional failover. Melbicom offers BGP/BYOIP and private inter-data-center links, horizontally scaled multi-region RPC patterns, and migration paths designed to avoid endpoint changes.
The same logic applies to exchange backends and wallet-adjacent systems. Customer-facing APIs, payment orchestration, and customer-data stores should not share a trust zone with signing systems or withdrawal controls. Blockchain-crime analysis put stolen funds at $2.2 billion and found private-key compromises accounted for 43.8% of losses. The practical takeaway is basic but unforgiving: keep public ingress away from key material, limit systems that can touch signing flows, and use hardware-backed cryptographic controls when asset value justifies them.
BTC Billing, IP Policy, and Security for Dedicated Server Deployment
BTC billing, IP policy, and security baselines should be decided before a dedicated server is deployed, because all three shape production risk. Billing affects renewal continuity, IP policy affects endpoint stability, and management security affects the blast radius of routine operations. Treat them as architecture inputs, not back-office cleanup.
When a USA Dedicated Server with BTC Is Really a Treasury Workflow Decision
A USA dedicated server with BTC should be framed as procurement flexibility, not a compliance shortcut or branding gimmick. The point is whether the payment rail fits how operations and treasury already move. Melbicom’s FAQ says crypto payments are available and can be enabled for new orders or renewals through an account manager, while US pages advertise monthly billing. Before the first invoice, clarify settlement asset, invoice currency, pricing source, quote-lock period, confirmation threshold, renewal workflow, and refund or credit-note path.
For teams that already hold digital assets, crypto billing can remove conversion steps and reduce weekend, cross-border, or card-approval friction. The privacy-friendly version is boring in the best way: clean invoices, clear ownership records, limited exposure of payment credentials, and fewer manual handoffs between treasury and infrastructure.
Dedicated Server USA IP Policy Requirements
IP policy is now architecture. Public registry guidance says the ARIN IPv4 free pool is depleted, new networks should request IPv6, and organizations seeking IPv4 should expect transfer workflows or pre-approval. Public IPv6 measurement puts global adoption around 46.5%, with US capability near 60%, so dual-stack is no longer a side quest. A dedicated server in USA should be evaluated for IPv6 readiness, BYOIP BGP sessions, route objects, RPKI, ROAs, route-origin validation, and prefix filtering. NIST routing guidance points in the same direction: stable endpoints require verifiable routing practice, not just address space.
Security baselines should be written before the server goes live. Management paths should stay off the public internet, VPN access should use MFA and narrow feature exposure, and cryptographic workflows should favor controlled key handling over convenience. For exchanges, wallets, and node operators, the minimum baseline is segmented ingress, hardened management, separate signing surfaces, auditable privileged access, and rebuild automation that can reproduce a known-good state.
Straight to Deployment with a Dedicated Server in USA
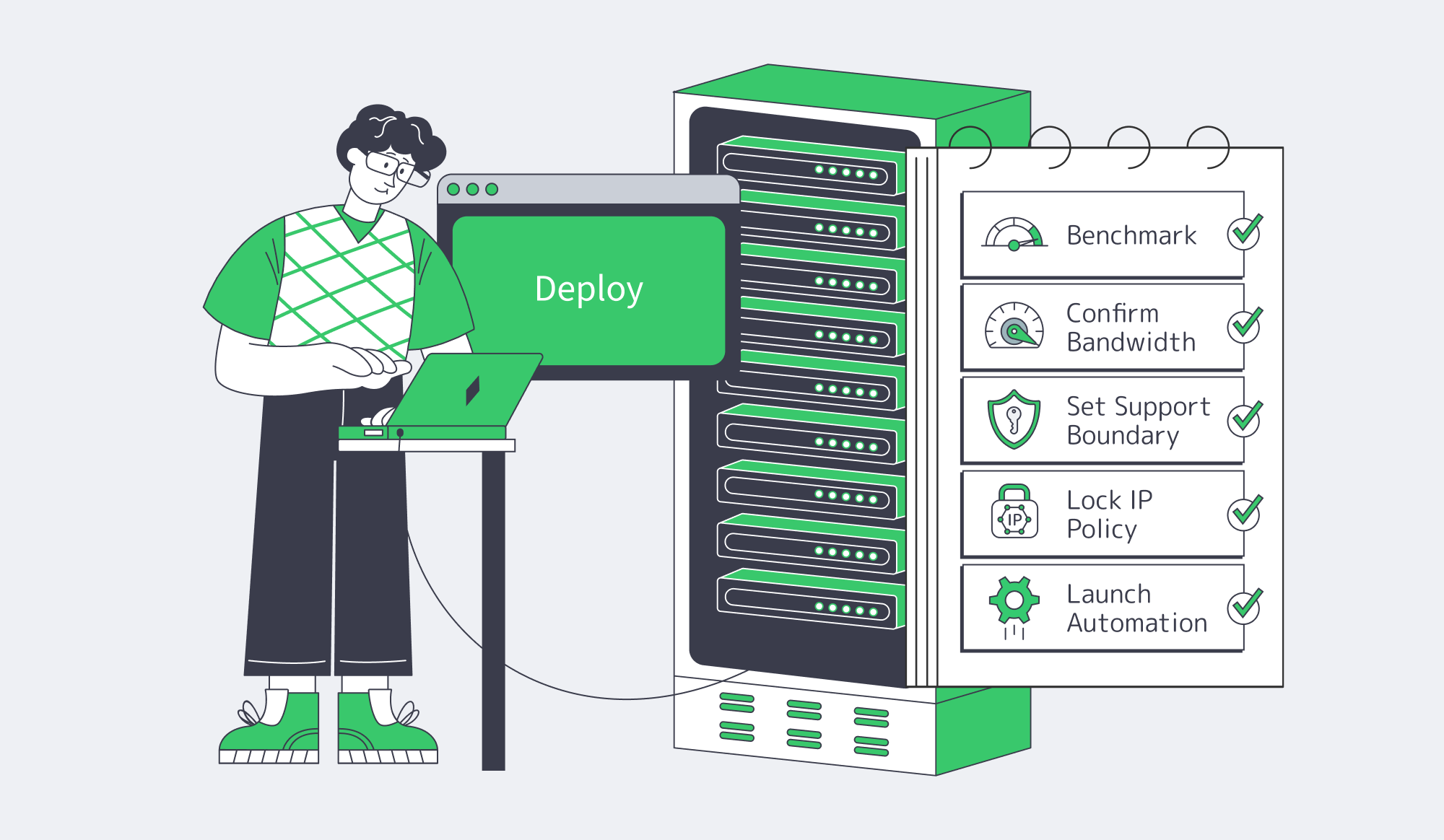
The fastest way to buy well is to turn the shortlist into an execution plan. A dedicated server in USA should be benchmarked from real traffic origins, matched to documented bandwidth and IP terms, deployed through repeatable automation, secured before exposure, and procured through a billing rail that will not interrupt renewals.
- Benchmark both US locations from real traffic origins; use published test files and path tests rather than a city name alone.
- Put bandwidth into writing: port speed, guaranteed throughput, oversubscription language, metered or unmetered terms, and attack-traffic treatment.
- Decide the ownership boundary: let the provider operate hardware and network reliability, while your team controls protocol, client, and release logic.
- Treat IP policy as architecture: require dual-stack readiness, decide whether BGP/BYOIP matters, and ask how routing-security controls are handled.
- Keep management off the public internet and require VPN plus MFA for KVM, IPMI, VPN, and privileged accounts.
- Separate public APIs from signing, payments, and customer-data systems; use hardware-backed cryptographic handling where key risk is material.
- Confirm crypto procurement before the first invoice: settlement asset, invoice currency, pricing source, confirmation threshold, renewal workflow, and credits or refunds.
- Use API hooks or infrastructure-as-code for provisioning, rebuilds, and failover; if deployment cannot be replayed automatically, it is not production-ready.
That is the practical meaning of a modern server dedicated USA purchase. It is not a hunt for the lowest monthly number or the loudest bandwidth claim. It is a search for infrastructure that is deployable, automatable, supportable, and compatible with the way security and finance already work.
Deploy in the USA
Compare US locations, bandwidth, APIs, routing, stock, and BTC billing.
Get expert support with your services
Blog
Dedicated Server United States: East vs. West, SLAs, and Cost Control
Buying a dedicated server in the United States is no longer a coastal shortcut. The old rule – East for Europe, West for Asia, one region for savings – breaks once dynamic APIs, replication traffic, media control planes, and recovery events carry real cost. Microsoft’s Azure latency tables put scale on the problem: representative median RTTs are about 73 ms from East US to West US, 79 ms from East US to UK South, 107 ms from West US to Japan East, and 147 ms from West US to UK South.
Melbicom makes the decision concrete: Atlanta and Los Angeles, both are Tier III facilities, with 1-200 Gbps per server, control panel, API, KVM, IPMI, and bandwidth and data-transfer filters. The framework is simple: place latency-sensitive work first, decide whether the second coast is for performance or disaster recovery, then optimize the bill.
Choose a U.S. Coast— Atlanta or Los Angeles — 1-200 Gbps per server — Ready or custom builds |
|
How to Choose East vs. West for a Dedicated Server in the United States
Choose east or west by locating the traffic that cannot hide behind a cache: writes, authentication, API calls, operator actions, and hard dependencies. East usually fits Europe-adjacent and Eastern/Central U.S. demand; West fits Pacific and Asia-facing paths. When both matter, assign each coast a role instead of chasing a single compromise metro.
The table uses Microsoft medians, not Melbicom measurements, as a proxy for the routing penalty distance still imposes.
| Representative Pair From Published Tables | Median RTT | Buying Implication |
|---|---|---|
| East US to West US | 73 ms | Coast-to-coast synchronous write paths will feel it immediately. |
| East US to UK South | 79 ms | An eastern U.S. location keeps Europe-linked traffic materially closer. |
| West US to Japan East | 107 ms | A western U.S. location is the better Pacific-facing launch point. |
| West US to UK South | 147 ms | Serving Europe from the West adds a substantial trans-U.S. penalty first. |
For a dedicated server in the United States, east vs. west is shorthand for the long-haul penalty on every uncached request. Single-region placement should remove the most expensive user-visible path. Once both paths matter, split roles across coasts instead of forcing one metro to impersonate the country.
Mapping Latency and Service-Level Targets to a Dedicated Server in the United States
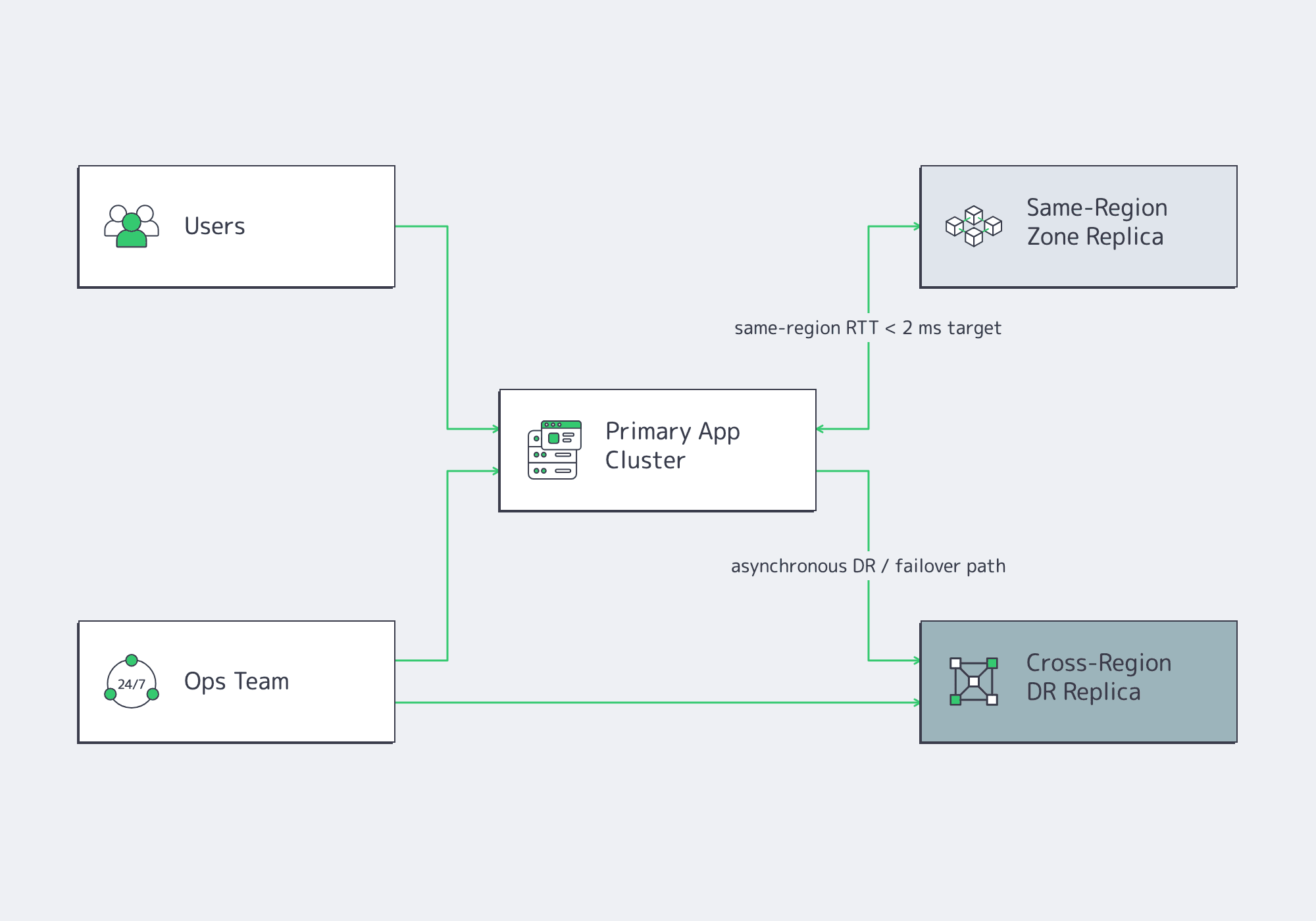
Map the server plan to internal service targets: p95 latency, recovery time, and acceptable data loss. Keep synchronous replicas and quorum-heavy services near each other, where regional latency can stay low. Use coast-to-coast links for disaster recovery, read locality, stateless absorption, and staged failover, not default chatty writes.
Microsoft says availability zones target inter-zone round-trip latency below roughly 2 ms, recommends multiple availability zones for production workloads, and points mission-critical workloads toward multi-zone plus multi-region architecture. That is the line: same-region zones can protect tightly coupled systems; coast-to-coast replication is a different operating mode.
The economic case is just as sharp. Uptime Institute reports that 54% of respondents said their most recent significant outage cost more than $100,000, while one in five put the figure above $1 million. At that price point, a second region stops looking like decorative redundancy and starts looking like usable insurance.
When Multi-Region Replication Is Worth It for SaaS, Media, and API Backends
Multi-region replication is worth it when it reduces real user latency, contains outage cost, or lets a national platform absorb uneven demand without sending every transaction across the continent. SaaS decisions hinge on write authority, media decisions on origin pressure, and API decisions on dynamic ingress and state boundaries.
SaaS
For SaaS, the decisive variable is where the write path lives. If users, support teams, and core transactions lean eastward, keep primary writes there and use the opposite coast for asynchronous disaster recovery, read locality, search copies, object replication, and fast failover capacity. Cross-region replication becomes wasteful when it turns a transactional database into active/active behavior before the application can resolve conflicts.
Media
For media, the old one-origin-plus-CDN pattern is weaker than it looks because manifests, entitlement checks, live spikes, and packaging pipelines do not cache away cleanly. AppLogic Networks says video remains the largest application category by volume, users download an average 5.6 GB per day, and live-streamed sports can spike traffic 3-4x above normal usage. Place origins and control planes near the heaviest egress region, keep the opposite coast warm, and use CDN plus object storage so origins carry less.
API Backends
For API backends, a second coast becomes useful early because traffic is dynamic and often impossible to hide behind cache. Postman’s API report says 82% of organizations use some level of API-first development, 65% generate revenue from APIs, 46% plan to increase API investment, and 93% still struggle with collaboration. A practical east-to-west split is active/active stateless ingress, local queues and caches, and one deliberate source of truth for mutable state unless the platform can reconcile active/active writes.
US Dedicated Hosting Checklist: Carriers, Bandwidth Caps, and Remote Console
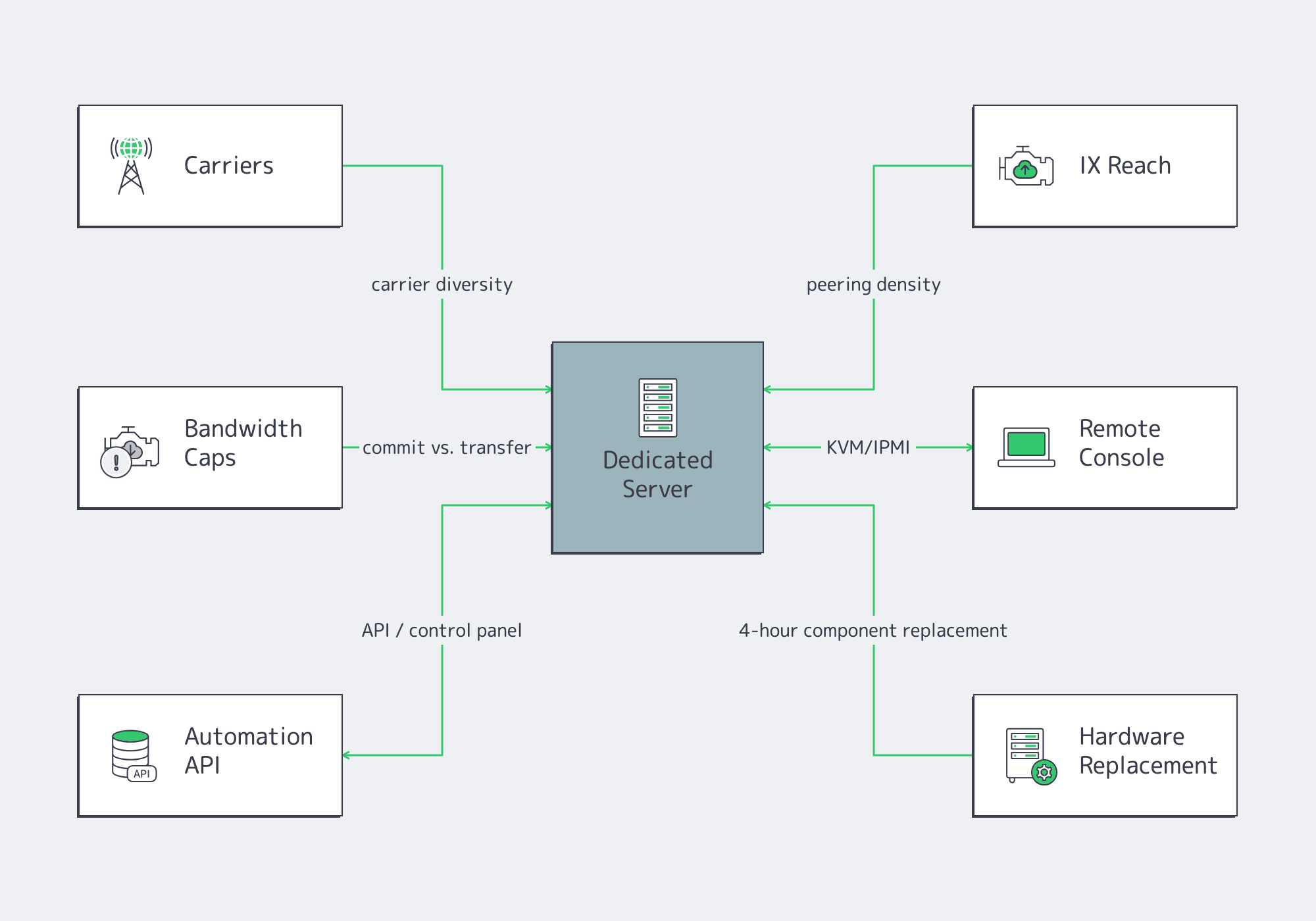
Do not buy a U.S. dedicated server by port speed alone. Route quality comes from carrier diversity, peering density, transfer model, and operational tooling. Verify network reach, translate bandwidth into monthly volume, confirm remote console and automation access, and know the hardware-replacement path before the incident starts.
The Internet Society explains why peering and IX participation matter: they shorten routes, reduce latency, and lower cost. PeeringDB shows a dense exchange presence in Los Angeles, including Any2West with 266 peers and BBIX US-West with 82 peers; Atlanta also has exchange options, including CIX-ATL and Equinix Atlanta. The right question is which metro matches your upstreams, eyeball networks, partners, and CDN paths.
Bandwidth caps are where cost control becomes math. One gigabit per second sustained for 30 days is about 324 TB; 10 Gbps is about 3.24 PB; 40 Gbps is about 12.96 PB. Port speed, commit, bundled transfer, and metered traffic are different decisions. Operational readiness is just as concrete: remote console plus automation is how teams recover from a bad kernel, bootloader, or network change without waiting in a ticket queue. Melbicom’s U.S. pages advertise control panel, API, KVM, IPMI access, and replacement of failed server components within four hours.
| U.S. Location | Melbicom’s Current Ready-to-Go Range | Planning Signal |
|---|---|---|
| Atlanta | Dozens of configurations; Intel Xeon E5 v4 and Scalable G1-class CPUs; 32-256 GB RAM; 1-40 Gbps bandwidth with 50 TB or unmetered plans; public location network options up to 1-200 Gbps per server. | East/Southeast anchor for primary writes, Europe-adjacent traffic, analytics, and DR counterpart to Los Angeles. |
| Los Angeles | 50+ configurations; Intel Xeon E5 v4 and Scalable G1-class CPUs; 128-256 GB RAM; 1-40 Gbps bandwidth with 50 TB or unmetered plans; public location network options up to 1-200 Gbps per server. | West/Pacific anchor for media origins, API ingress, APAC-facing routes, and DR counterpart to Atlanta. |
Custom server configurations can be deployed in 3-5 business days when the ready-to-go list does not match the workload. Where BGP matters, evaluate support for announcing your IP networks and route-change operations; routing features should complement, not replace, a tested disaster-recovery runbook.
Cost Control for a Dedicated Server in the United States
Cost control is topology discipline, not a hardware shopping exercise. The efficient U.S. design often starts with one authoritative region, then adds a narrow second region for stateless ingress, caches, replicated assets, and recovery capacity. That captures latency and resilience gains without paying a permanent active/active tax.
For media, move cacheable bytes to CDN before buying more origin port speed. For SaaS, split transactional writes from analytics, exports, search indexing, and file distribution before mirroring the whole stack. For APIs, split ingress east/west before splitting every database east/west. These choices keep the bill rational while improving user experience.
Use this sequence before committing spend:
- Put the primary write path on the coast where interactive users, operator actions, and latency-sensitive dependencies already live.
- Keep synchronous replication inside one region; treat coast-to-coast links as disaster recovery, read locality, or stateless traffic distribution unless active conflict handling is already built.
- Add the second coast when outage cost, national user spread, or Pacific- versus Europe-facing traffic patterns justify it.
- Price network capacity by monthly transfer volume and event peak shape, not by the port label.
- Validate carrier and IXP quality with tests from each metro, because peering depth turns advertised capacity into usable performance.
- Require remote console and automation from day one; API plus KVM/IPMI is resilience, not an upsell.
- Replicate only the layers that buy latency or recovery: cacheable media to CDN, assets to object storage, stateless ingress to both coasts, and stateful tiers only as far as service targets require.
Applying the Framework to Melbicom’s USA Dedicated Server Options
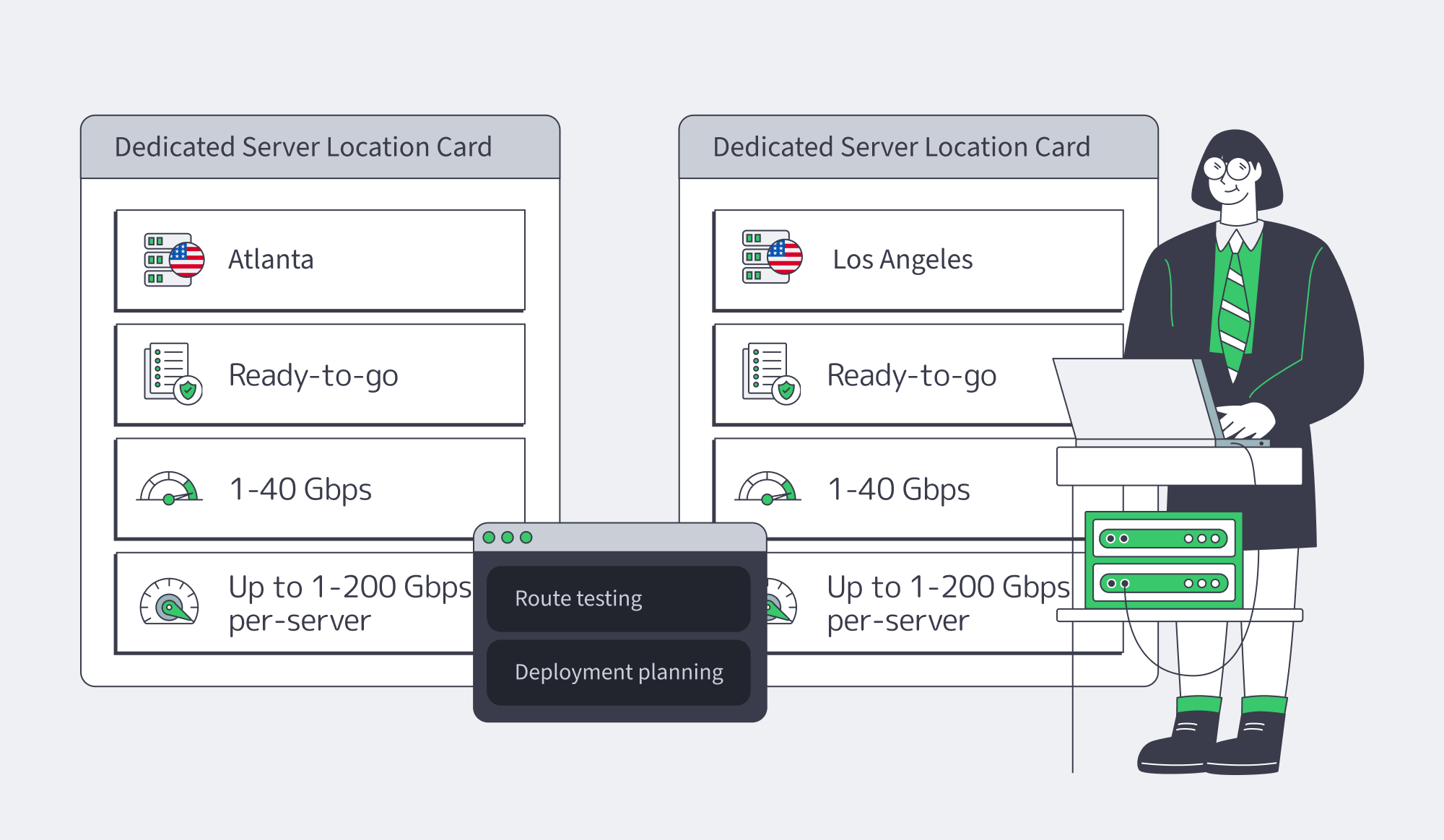
Melbicom makes the framework practical by giving U.S. buyers two real placement choices: Atlanta and Los Angeles. Use those metros to test routes, model transfer economics, decide whether disaster recovery needs a second coast, and validate operational readiness before the architecture hardens.
At Melbicom, we pair those U.S. metros with 19 other global data centers, 1,400+ ready-to-go configurations, 20+ transit providers, 25+ IXPs, 14+ Tbps of network capacity, and a CDN footprint in 55+ PoPs across 39 countries. Start with the coast that protects user latency, then add the opposite coast when recovery design or traffic mix proves the need.
Compare USA Servers
Compare Atlanta and Los Angeles options for routes, bandwidth, and recovery.