Blog
Buy Amsterdam for Bandwidth and Control
Amsterdam is no longer a “pick a central city and you’re done” decision. The modern trap is subtler: you can buy a strong dedicated server and still ship a slow product because the network path is wrong, the port is “unmetered” only on paper, the abuse workflow is a surprise, or the remote console is available but unsafe to rely on when an incident lands.
This guide is built around a simpler reality: for latency-sensitive platforms, bandwidth is now a product feature because it is tied to peering, backhaul capacity, route control, and how fast your team can regain control when something breaks. The goal is to make Amsterdam measurable before you migrate, not merely attractive on a spec sheet.
Choose Melbicom— 400+ ready-to-go servers configs — Tier IV & III DCs in Amsterdam — 55+ PoP CDN across 6 continents |
 |
Dedicated Server Amsterdam: Why the Network Has Become the Product
Amsterdam’s edge is network gravity, not central geography. AMS-IX says its Amsterdam platform handled 35.66 exabytes of traffic in the most recent full year, reached 69.57 Tb/s of active port capacity, and logged a 65% annual increase in 400G ports. EXA Infrastructure also launched a 1,200 km route and the first new North Sea subsea cable in 25 years. Those are not vanity metrics; they show why exchange density and path diversity now matter as much as rack space.
Capacity pressure is the other half of the story. CBRE expects Europe’s vacancy rate to close at 9% amid strong demand and a “lack of available power,” which is exactly why fast provisioning matters. In Amsterdam, Melbicom’s dedicated server footprint spans Tier III and Tier IV data centers in Amsterdam, and both facilities enable up to 200 Gbps per server. This is not a chassis decision first; it is a network-position decision.
How to Choose a Dedicated Server in Amsterdam for EU Low-Latency Traffic
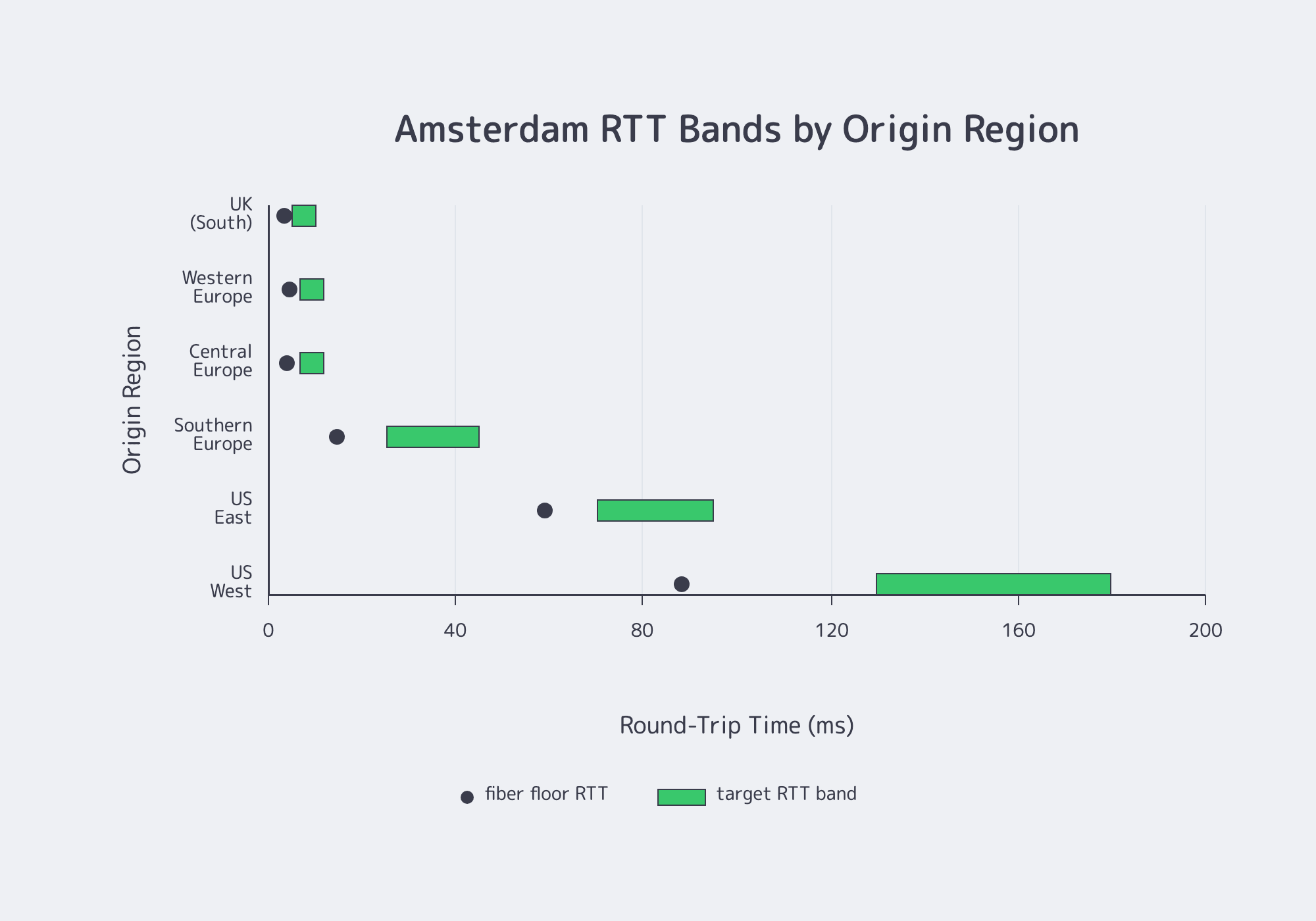
Start with latency mapping, not hardware browsing. For a dedicated server in Amsterdam, the first pass is whether EU, UK, and transatlantic routes stay inside your target RTT bands under real ISP conditions. If paths miss the band, extra cache or compute rarely fixes the user experience.
A useful model separates physics from routing. Physics gives you the floor: a quick rule of thumb for single-mode fiber is roughly 4.9 microseconds per kilometer. Routing determines the lived experience: RIPE Labs notes that “close” according to BGP and geographically close are not always the same thing.
Use the table below as a planning model. The floor RTT uses the fiber rule of thumb; the goal band adds routing overhead, peering variation, and congestion margin. Melbicom publishes an Amsterdam test endpoint and download payload so you can validate the model before migration.
Latency Mapping for a Dedicated Server in Amsterdam
| Origin Region | Distance / Floor RTT | Goal RTT Band | If You’re Above the Band |
|---|---|---|---|
| Western Europe | 450 km / 4.4 ms | 7–12 ms | Test multiple ISPs and avoidable hops |
| Central Europe | 400 km / 3.9 ms | 7–12 ms | Verify reverse-path consistency |
| Southern Europe | 1,500 km / 14.7 ms | 25–45 ms | Watch congested interconnects |
| US East | 6,000 km / 58.8 ms | 70–95 ms | Validate transatlantic diversity |
| US West | 9,000 km / 88.2 ms | 130–180 ms | Prioritize route stability |
The point is simple: Amsterdam is an excellent EU hub, but US performance still depends on path quality, not map distance alone.
A practical decision playbook:
- Define at least two acceptance bands: EU core and transatlantic.
- Test from multiple networks inside each band, not just one office ISP.
- Treat traceroute as diagnostic, not truth; RIPE Labs notes that traceroute shows the forward path while RTT reflects both forward and reverse paths, which can differ.
- If results drift, ask for levers you can actually control, such as BGP policy or a different transit mix.
True Unmetered vs. Capped Ports in Amsterdam Dedicated Server Offers
“Unmetered” matters only if the port stays clean under sustained, parallel load. Ignore headline burst numbers and verify multi-stream throughput, loss, retransmits, and any time-based shaping during real traffic windows. An Amsterdam dedicated server should clear those checks before you move a production origin or API tier.
What matters in practice is port speed, sustained throughput, and policy reality. That matters more now because AMS-IX traffic keeps rising and 400G ports are scaling fast, while Melbicom’s Amsterdam PoP offers high-bandwidth server options with guaranteed bandwidth, without ratios. For a buyer, this matters more than a burst number on a banner.
How to Validate “True Unmetered” on an Amsterdam Dedicated Server
Treat unmetered as a claim to verify. The three failure modes worth catching early are a single-flow ceiling, multi-flow collapse, and time-based shaping after several mins of load.
A pragmatic acceptance test:
- Run ping and MTR baselines for at least 30 minutes.
- Use 8–32 parallel streams, not one optimistic transfer.
- Repeat during local peak windows.
- Hold throughput long enough to reveal shaping, usually 10–20 minutes.
- Track retransmits and packet loss, not just headline Mbps.
- Save the result as your known-good baseline.
A streaming-origin relocation works best when bandwidth verification is treated like release engineering: run the bake, verify that sustained multi-stream load stays flat, then roll traffic in stages. That is how “unmetered” stops being marketing language and becomes operationally believable.
Which Amsterdam Dedicated Server Checks Matter before Migration & Incident Response
Before migration, focus on the checks that still matter at 2 a.m.: remote console recovery, DDoS and abuse workflow, IPv4/IPv6 readiness, and route control. Those are the controls that turn fast provisioning into a safe server deployment instead of a risky cutover.
Remote Management on a Dedicated Server
Remote management is the difference between fixing a bootloader issue in minutes, recovering from a firewall mistake without losing the host, and diagnosing a kernel panic from a real console instead of partial telemetry.
Melbicom’s servers have a dedicated IP-KVM port connected to an isolated management network, with customer access via VPN. That matches NSA guidance that management interfaces should never be directly exposed to the Internet and helps explain why exposed BMC/IPMI surfaces remain a bad idea: NIST still documents high-impact cases such as “cipher zero” authentication bypasses. Looking forward, Redfish-style REST-based out-of-band automation is increasingly the cleaner control plane, even when classic IPMI/KVM remains the break-glass tool.
DDoS and Abuse-Policy Fit Is an Ops Requirement
This is not about selling DDoS features. It is about workflow: what happens to your traffic, your ports, and your support path when pressure starts.
The Netherlands is still a strong jurisdiction for internet operations: Freedom House describes internet freedom there as robust, while the OECD’s Netherlands notice-and-take-down document outlines a structured, intermediary-oriented process for handling alleged unlawful content, with compliance framed as voluntary but procedural. On the DDoS side, NBIP’s NaWas has operated since 2014 and says it provides automatic 24/7 mitigation for connected participants. The takeaway is not “buy a badge”; it is “choose an operating model you can execute quickly.”
What to check before you migrate:
- What triggers suspension versus a remediation request?
- Who can answer an abuse or attack escalation around the clock?
- Are logs, timestamps, and ownership already wired into your playbook?
IPv4/IPv6 Strategy and BGP Control
Addressing is now part of the bandwidth decision. RIPE NCC says its remaining IPv4 pool was exhausted in 2019, while APNIC reports the global average IPv6 capability at around 40%, with adoption still uneven by region. The practical answer is straightforward: treat dual-stack as default, preserve IPv4 where compatibility still matters, and make sure observability and security tooling are IPv6-aware.
Routing control is the next lever. Melbicom’s BGP session service lists BYOIP, IPv4 and IPv6 support, BGP communities, and full, default, or partial routing, and it states that BGP sessions are free on dedicated servers. For a latency-sensitive SaaS cutover, the clean pattern is provision Amsterdam, baseline latency and throughput, then shift traffic in stages while keeping rollback ability. Teams that can announce or re-announce prefixes avoid brittle DNS-only moves and keep endpoint control during change windows.
Fast Deployment Checklist and Acceptance Test Plan

Amsterdam is a location with abundant inventory. Melbicom’s Amsterdam facility provides over 500 ready-to-go server configurations, offering up to 200 Gbps per server. Available stock is prompted for 2-hour activation, and custom configs are deployed within 5 days.
A fast deployment is only “fast” if it includes verification.
Deployment checklist:
- Confirm facility, port size, and redundancy plan.
- Pre-map latency from EU, UK, and US vantage points.
- Decide your minimum IPv4 need and enable IPv6 from day one.
- Define unmetered proof: parallel streams, sustained duration, peak-hour reruns.
- Lock remote-console access behind VPN and document break-glass use.
- Pre-wire abuse handling, ownership, and logging.
- Plan BGP before migration day if route control matters.
Acceptance test plan:
- Validate remote console access while everything is healthy.
- Run 30-minute latency baselines and capture jitter.
- Test single-stream and multi-stream throughput.
- Repeat throughput tests at peak hours.
- Use the Amsterdam test payload as a sanity check.
- Verify IPv6 end to end.
- If using BGP, test propagation and rollback.
Key Takeaways for a Bandwidth-First Amsterdam Buy
- Approve Amsterdam only after three RTT bands are baselined: EU core, UK, and transatlantic.
- Treat unmetered as unproven until sustained multi-stream testing says otherwise.
- Keep remote console on an isolated management path with VPN-only access, and rehearse it before change windows.
- Plan dual-stack early; IPv4 scarcity is structural, not temporary.
- Predefine DDoS and abuse workflow before launch, because policy surprises cost more than latency misses.
- Buy Amsterdam for controllability: path quality, port integrity, and fast recovery must clear the bar together.
Buy the Network Position, Not Just the Dedicated Server

The Amsterdam decision is no longer a hardware beauty contest. It is a routing and ops decision: can the network hold your RTT budget, does the port behave honestly under sustained load, and can you regain console access the moment a change goes wrong?
That is why the best Amsterdam deployments look boring on launch day. Paths were mapped, unmetered was tested, dual-stack was planned, DDoS and abuse workflow was documented, and rollback access was already rehearsed. Do that work up front, and Amsterdam becomes a controllable hub instead of a latency gamble.
Deploy in Amsterdam
Explore Amsterdam dedicated servers with high-bandwidth options, fast activation, and network controls designed for low-latency deployments.