Blog
Designing High-Availability Clusters That Fail Safely
High availability becomes concrete once downtime gets priced. An ITIC survey found that more than 90% of mid-size and large organizations now lose over $300,000 per hour of downtime, while 41% put the hit at $1 million to more than $5 million. Uptime Institute data reinforces the point: more than half of respondents said their most recent serious outage cost over $100,000, and one in five said it exceeded $1 million.
That is why availability targets are architecture constraints, not branding. Google’s SRE availability table turns the choice into a hard downtime budget, and each extra 9 narrows the room for slow failovers, sloppy maintenance, or optimistic recovery assumptions.
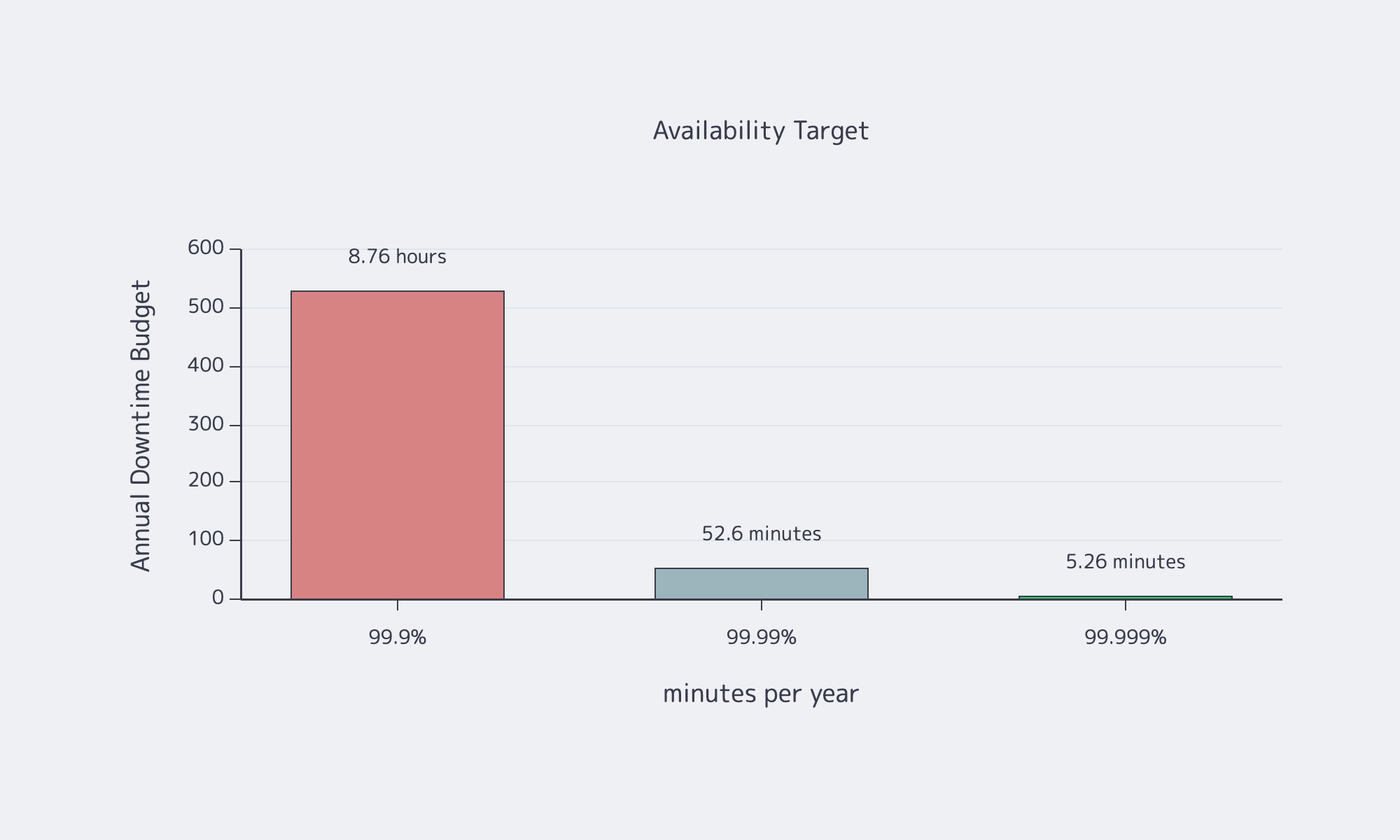
Source: Google SRE availability table.
How Server Clustering Works on Dedicated Hardware for High Availability
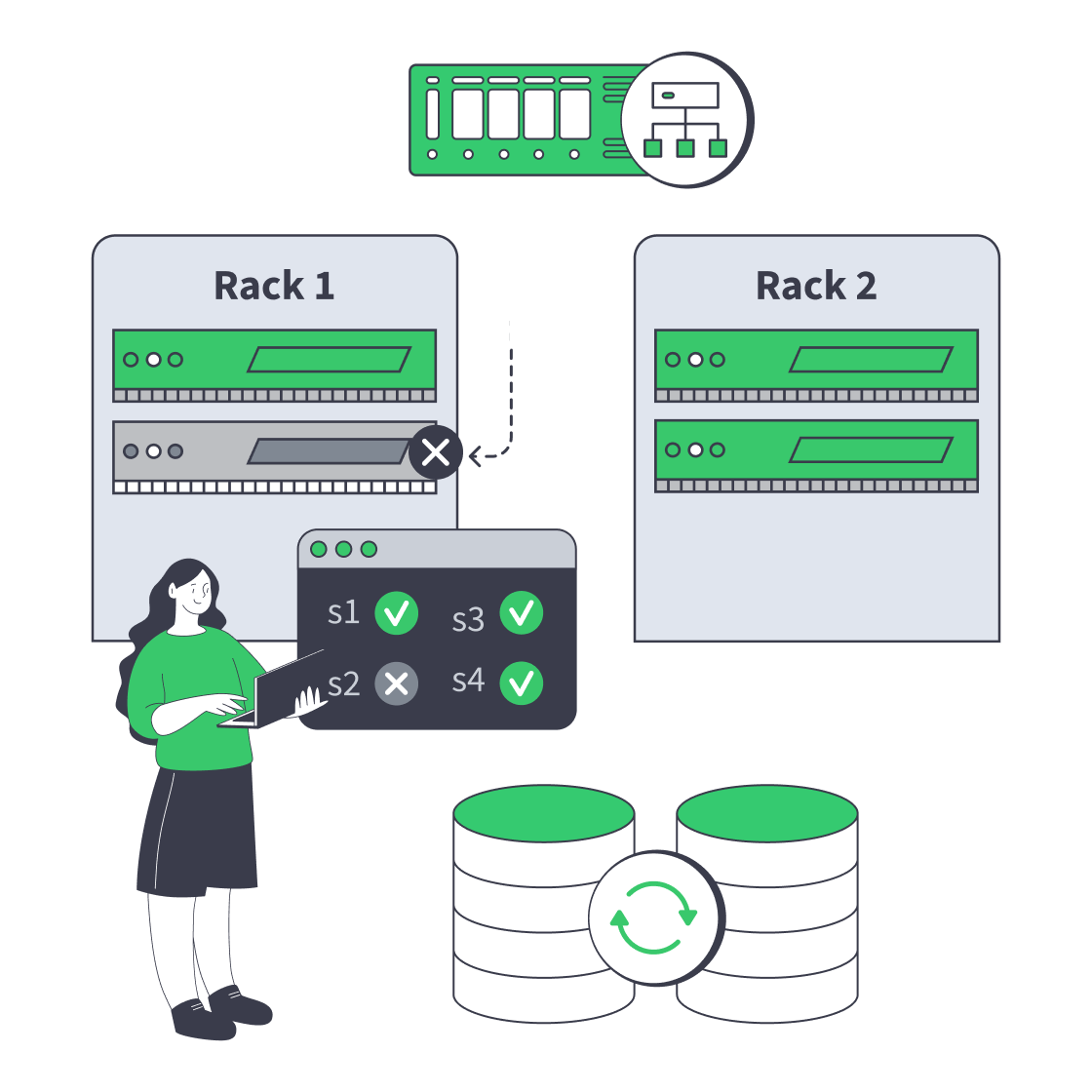
Server clustering on dedicated hardware means multiple servers behave like one service, with explicit rules for failover, traffic flow, and data ownership. The aim is predictable behavior when a node, switch, rack, or site fails—without turning every fault into a manual rescue or a risky improvisation.
On dedicated hardware, you choose the failure domains and define how the application, data, and network layers react. The application layer decides whether work is stateless or stateful, the data layer decides whether failover is fast or safe or a trade between the two, and the network layer decides whether users can actually reach the healthy side. N+1 headroom, patching, and hardware rotation belong in the design.
The Web Almanac reports that 97.3% of mobile homepages are served over HTTPS, and more than 98.8% of mobile requests already use HTTPS. That pushes more HA responsibility into the load-balancing tier: TLS termination, certificate rotation, session handling, and app-aware health checks are now part of the failure path, not edge details.
How to Design Active-Active and Active-Passive Clusters Without Split-Brain Risk

Active-passive and active-active answer the same question in different ways: who may serve traffic and write state when the system is stressed? The safe pattern is the same in both: quorum grants authority, fencing removes ambiguity, and any node that cannot prove ownership must stop taking writes.
Active-passive is simpler, but only if false failover is prevented. A split-brain event happens when a standby promotes itself during a partition while the original primary is still alive. Active-active uses capacity better, but it also raises the cost of bad coordination. The practical rule is simple: never allow writes on a node that cannot prove it still has quorum. Raft formalizes majority-based progress, MongoDB operationalizes that with majority write concern and warnings around weak arbiter layouts, and Red Hat’s guidance is blunt that any node that might still touch shared data must be fenced first.
Load Balancing and Failover Patterns for Server Clusters
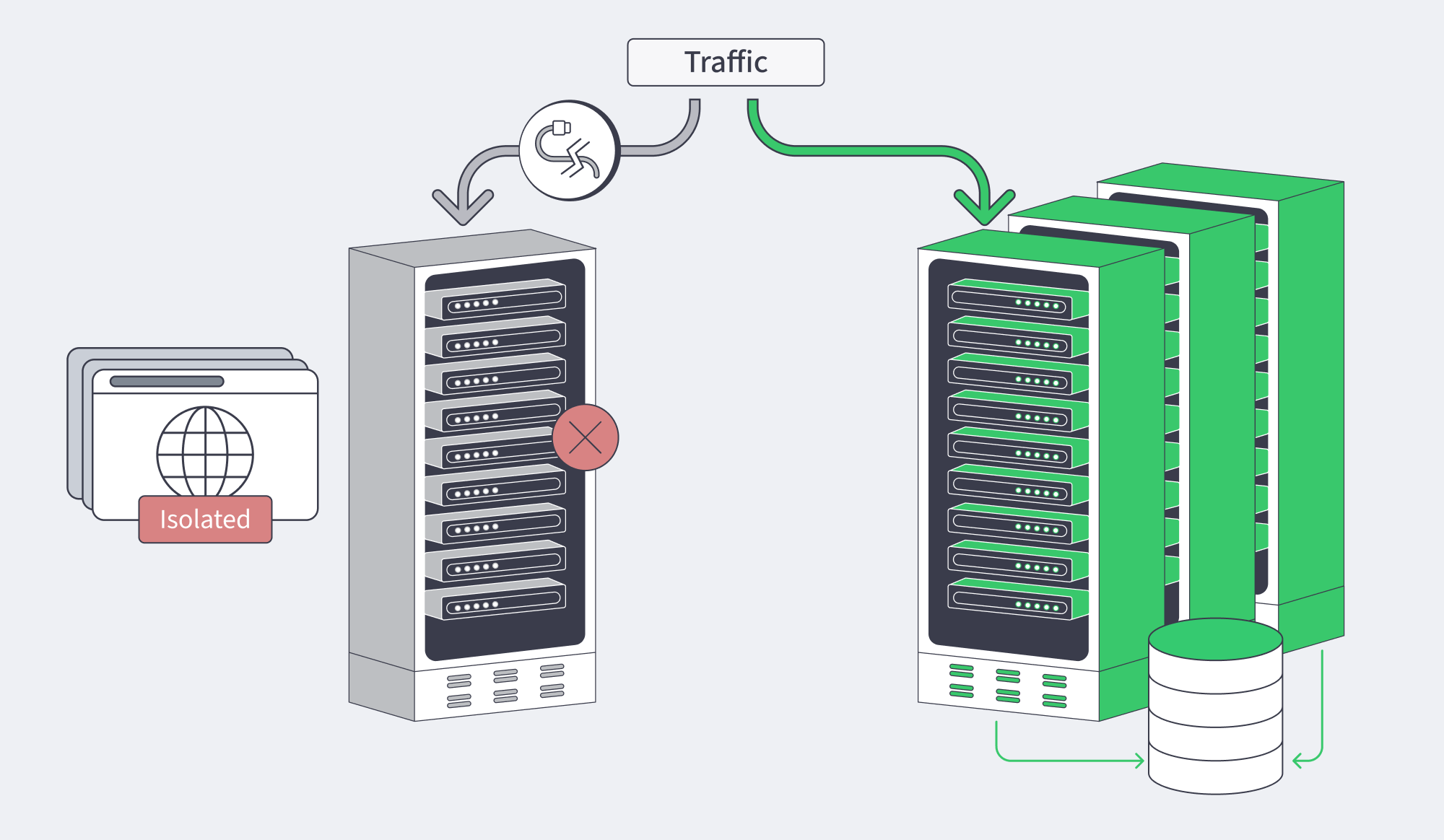
Load balancing is where users feel the cluster. It decides whether healthy capacity is reachable, not just whether it exists.
L4 balancing fits services where any healthy node can answer any request. L7 matters when correctness depends on cookies, headers, affinity, canaries, or TLS-aware routing. The bigger mistake is shallow health checking. A socket that accepts connections is not the same thing as a node that can safely serve traffic, which is why modern HA designs need shallow process checks, deep dependency checks, and role-aware checks that confirm whether a node may accept reads or writes in its current state.
For active-passive services, a virtual IP via VRRP is still a clean pattern because clients keep one address while leadership moves underneath. For larger failover, DNS can steer broadly, edge layers can select the best entry point, and BGP can move reachability itself. That is why the network matters as much as the nodes: Melbicom’s network enables redundant switching with VRRP-protected L3 connectivity, Melbicom’s CDN supports geographic request routing and origin pooling, and our BGP Sessions support BYOIP plus full, default, or partial routes across all locations—useful building blocks when failover has to survive both server faults and path changes.
Replicated Storage and State Consistency in Server Clusters

Compute is easy to duplicate. State is where HA becomes discipline.
The core trade-off is still RTO versus RPO. The MySQL Reference Architectures for High Availability frame HA and DR as service-level design choices, not as a single “best” topology. Distance adds physics to the argument. As an ITU reference notes, signals in optical fiber move at roughly 200,000 km per second, or about 5 milliseconds per 1,000 kilometers; a 6,000-kilometer path costs roughly 30 milliseconds one way. Synchronous cross-site replication can protect data, but latency still sends the invoice.
Keep voting members odd in number, keep replicas provisioned consistently, and do not hide all copies behind the same dependency. A SAN, storage shelf, or network choke point can quietly turn “replication” back into a single point of failure. If the design includes shared-write storage, split brain is existential, not cosmetic.
Operating Server Clusters: Health Checks, Maintenance, and Incident Workflows
Most HA failures are not dramatic hardware crashes. They are lagging replicas, certificate expiry, partial dependency failure, mis-sequenced maintenance, and configuration drift.
The healthier operating pattern is drain, replace, verify, rejoin. Observability also has to catch brownouts, not just outages, which is why Google’s SRE guidance and MongoDB’s production guidance both push teams toward indicators such as replication lag, stale reads, queue growth, and capacity pressure instead of relying on binary “up/down” checks.
The useful chaos-engineering questions are still the obvious ones:
- Will health checks detect the right failure fast enough?
- Will failover pick the right winner based on quorum, fencing, and data freshness?
- Can the system return to a stable state without a split-brain hangover?
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
 |
When Server Clustering Is the Right Answer Instead of Kubernetes or Vertical Scaling
Server clustering is the right answer when a small number of critical services need explicit failover, bounded blast radius, and clear leadership rules. Kubernetes fits broader platform standardization across many services. Vertical scaling fits workloads that mostly need more headroom on one box, not more distributed machinery.
Kubernetes is mainstream; the CNCF reports that 82% of container users now run it in production. But popularity is not a design argument. Stateful reliability still depends on quorum, storage, routing, and failure handling whether the workload runs inside a cluster manager or not.
| Decision Trigger | Prefer This Approach | Why It Fits |
|---|---|---|
| Predictable failover for a small number of critical services | Server clusters | You can define leadership, quorum, storage behavior, and routing rules explicitly, with a smaller operational surface area. |
| Many services, frequent deploys, standardized scheduling | Kubernetes | A common control plane improves fleet operations, but stateful availability still depends on the same storage and quorum fundamentals. |
| CPU or RAM limits on one system, with restart tolerance | Vertical scaling | It is the simplest model, but it keeps single-node failure in play, so some failover plan is still required. |
Design Checklist for Server Clusters
- Design for the failure domains you can actually isolate: node, rack, path, storage tier, or full site.
- Elect leadership with quorum or a witness; heartbeat loss alone is not enough to justify promotion.
- Fence before you fail over any service that can still touch shared-write state.
- Size active-active for degraded mode, not for sunny-day utilization.
- Make health checks role-aware and dependency-aware, especially for write paths.
- Prefer maintenance playbooks that drain, verify, and rejoin instead of “patch in place and hope.”
- Track replication lag, queue depth, route convergence, and recovery time as first-class reliability signals.
- Rehearse partitions and operator mistakes before production rehearses them for you.
Conclusion: Design for Failure You Can Name
The strongest HA clusters are not the ones with the most layers. They are the ones that make failure behavior obvious. If leadership is explicit, writes are gated by quorum, fencing removes doubt, and health checks understand role as well as liveness, failover becomes a property of the design instead of a hopeful script.
That is why the clusters-versus-Kubernetes-versus-vertical-scaling decision matters. Pick the model that matches the workload, then design the failure path with as much care as the happy path.
Dedicated Servers for HA Clusters
Explore dedicated servers in 21 Tier III and IV data centers with high-capacity ports, BGP sessions with route control, CDN support, and fast deployment for high-availability clusters.