Author: Melbicom
Blog
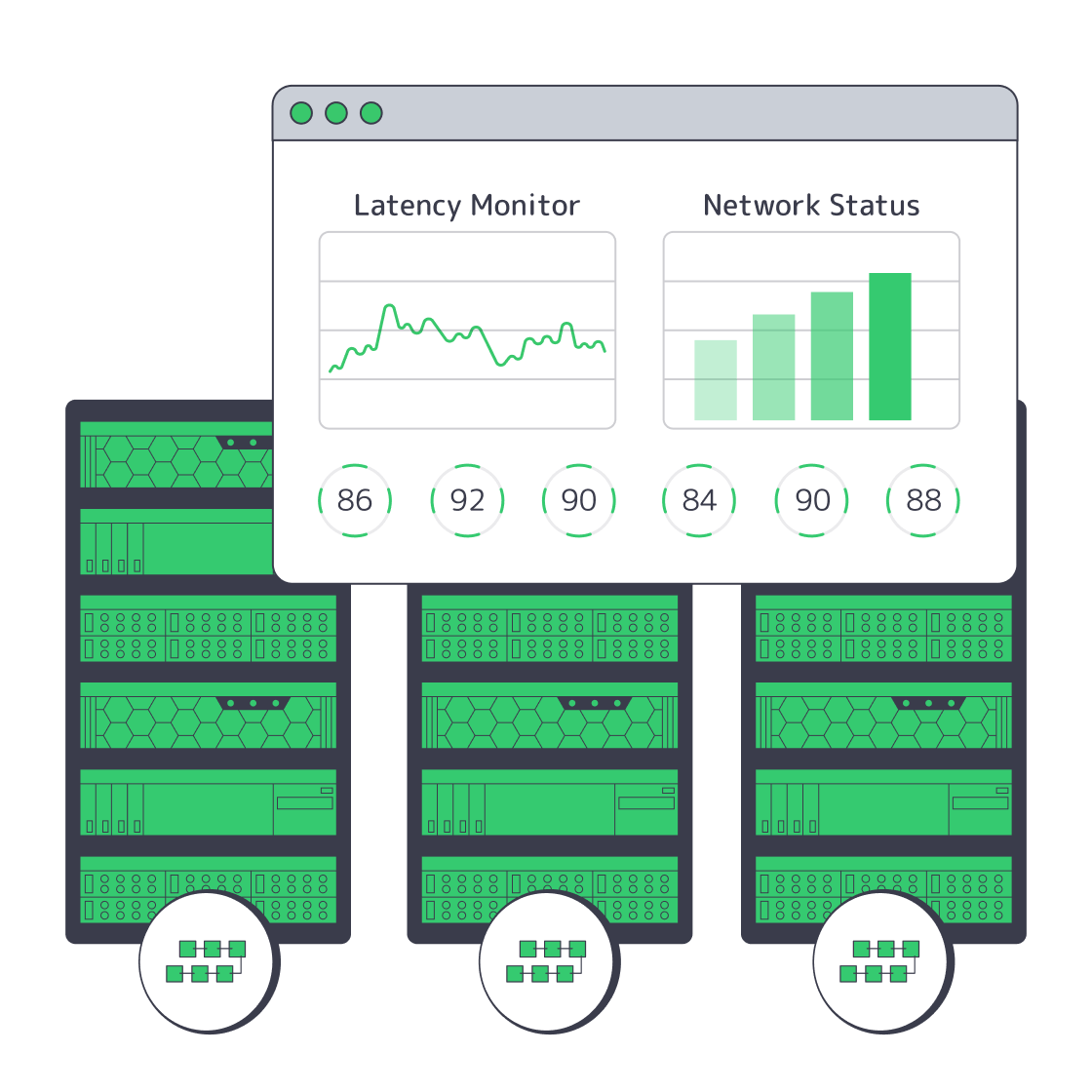
Dedicated Servers for dApp Backends and Off-Chain APIs
In Q2 2025, the dApp ecosystem averaged 24.3M daily active wallets, up 247% versus early 2024, according to industry tracking. That’s huge load growth for infrastructure that was never designed to serve interactive user traffic in the way a web or mobile app does.
User expectations, however, are still Web2-fast: Google’s research shows 53% of mobile visitors abandon a site if it takes longer than three seconds to load. If your dApp’s UI is waiting on an overloaded RPC endpoint, a slow indexer, or a congested on-chain call, users don’t care that “the blockchain is busy” – they just leave.
Base-layer constraints make this worse. Ethereum mainnet still processes only around 15 transactions per second, while traditional payment networks comfortably execute thousands of TPS. When popular early dApps like CryptoKitties pushed all logic and metadata on-chain in 2017, they famously congested Ethereum and slowed down unrelated applications. That experiment proved a point: the chain is a consensus engine and settlement layer, not a general-purpose application runtime.
Even “off-chain” isn’t automatically safe. In October 2025, a multi-hour outage in a major US cloud region froze thousands of apps – including Web3 platforms – because too much critical infrastructure depended on a single provider and region. And in November 2020, an outage at a leading Ethereum infrastructure provider rippled through wallets and dApps that had standardized on a single RPC backend.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
We at Melbicom see – modern dApps that feel “instant” to users are almost always hybrid systems: minimal on-chain logic, plus powerful dedicated servers for backends, databases, APIs, indexing, storage, and observability. In this article, we unpack what that hybrid stack looks like in practice and why dedicated servers are such a strong fit for dApp backends.
Decentralization Meets Reality: Why dApps Need Off-Chain Backends
Blockchains are fantastic append-only ledgers; they are terrible primary data stores for interactive applications. Research on blockchain indexing is blunt: chains are optimized for integrity and consensus, not querying – most ledgers store data sequentially, which makes complex queries slow and expensive without specialized indexers.
Protocols like The Graph emerged specifically because directly querying chain state from UIs does not scale. The Graph’s own docs describe it as a decentralized indexing protocol that turns raw blockchain data into subgraphs – structured, queryable APIs dApps can hit using GraphQL instead of scanning blocks themselves. Those subgraphs are not magic; they run on servers, with CPUs, memory, and storage under someone’s ops budget.
The same is true for RPC nodes. They are essentially specialized servers exposing a JSON-RPC surface between your application and the chain. Studies on Web3 infrastructure point out that every interaction – checking a balance, submitting a swap, fetching an NFT list – ultimately travels through RPC nodes that must stay online, current, and low-latency. When those fail, on-chain contracts keep existing, but your app becomes unusable.
Monitoring all this isn’t trivial either. Web3 observability guides highlight that teams must track both classic infrastructure metrics (CPU, RAM, disk IO, p95 latency) and blockchain-specific signals (block times, gas usage, reorgs, mempool depth). Those metrics live in logs, traces, and time-series databases – again, off-chain systems running on servers.
Many protocols now formalize “off-chain agents” as part of their architecture. The Ergo ecosystem, for example, relies on watchers and bots that continuously scan blocks, update databases, and trigger on-chain actions when conditions are met. Bridges, oracle networks, and cross-chain messaging systems follow similar patterns: long‑running services process events in real time and only occasionally commit back to the chain.
- On-chain is slow, expensive, secure, and authoritative.
- Off-chain is fast, flexible, observable, and where most UX and business logic live.
The question is not whether you need an off-chain backend – you already do. The question is what that backend runs on and whether it is architected for the scale and reliability Web3 usage now demands.
Best Backend Services for dApp Management
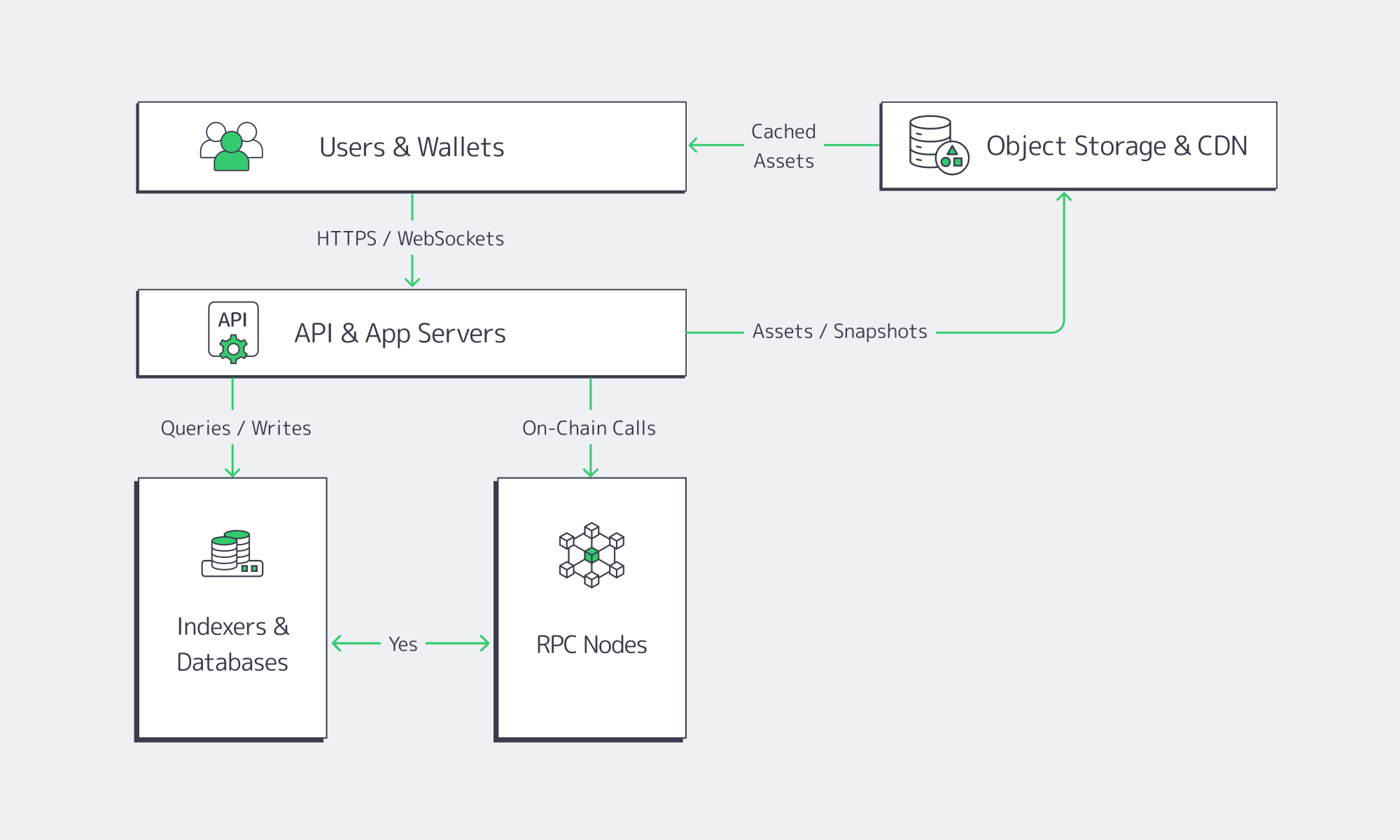
In practice, the best backend services for dApp management share three traits:
- They are close to the chain (low-latency RPC and indexers).
- They are close to the users (global delivery, caching, and storage).
- They run on infrastructure you can understand, observe, and control.
For most teams, that means building dApp backends on high‑performance dedicated servers and layering in specialized services – RPC providers, decentralized storage networks, DePIN, and so on – rather than replacing dedicated infrastructure with them.
What Runs Off-Chain in a Modern dApp Backend
A realistic dApp backend typically includes:
- RPC gateways and full / archival nodes serving JSON-RPC and websockets.
- Indexers and subgraphs that transform blockchain events into queryable views.
- Business-logic APIs (authentication, rate limits, portfolio views, risk rules).
- Job schedulers and bots publishing transactions, refreshing oracle feeds, or monitoring bridge events.
- Databases and caches for user profiles, sessions, non-critical metadata, and analytics.
- Observability stacks (logs, metrics, traces) correlating RPC performance, chain conditions, and app-level incidents.
All of that is “just software,” but it’s software with very particular needs: predictable IOPS and latency, high memory ceilings, fast recovery after a crash or resync, and a lot of network throughput.
Blockchain Infrastructure for Next-Gen dApps
Infrastructure for next‑gen dApps increasingly looks like a hybrid between Web3 protocols and Web2‑style distributed systems:
- Indexing layers – Teams often run their own indexers alongside or instead of public networks like The Graph, using the same ideas: consume chain data once, store it in a fast DB, expose a clean API. Even decentralized indexing still requires CLI tools, build pipelines, and servers to host the indexers themselves.
- Decentralized storage – IPFS, Arweave, and Filecoin store content-addressed blobs across distributed networks. But Web3 storage guides are explicit: you still need gateways, pinning services, and caching layers to make this usable in real-time applications. Typically, that means pairing decentralized storage with S3-compatible object storage and a CDN for hot assets – all hosted on robust server infrastructure.
- RPC and node fleets – setting up blockchain nodes requires certain hardware requirements: multi-core CPUs, large RAM, SSD or NVMe storage, and high-speed 1–10+ Gbps networking, especially for full or archival nodes. Those profiles line up extremely well with dedicated servers that we deliver at Melbicom.
dApp infrastructure maintenance is the ongoing work of keeping this stack patched, upgraded, observant, and ready for protocol changes. That work is drastically easier when the underlying platform is predictable single-tenant hardware instead of opaque shared virtual machines.
Comparing Dedicated Server Options Suitable for Scalable dApp Infrastructure
For most production dApps, the most scalable option is single-tenant dedicated servers with SSD or NVMe storage, high-bandwidth ports, and direct networking features such as BGP and private links. Virtual machines and serverless still help at the edges, but latency‑sensitive RPC, indexers, and APIs tend to belong on dedicated hardware.
As dApps mature, the architecture conversation usually isn’t “on-chain vs off-chain”; it’s “how much do we run on dedicated servers, and how do we combine them with managed services and decentralized networks?” The table below sketches typical patterns:
| Use Case | Pure On-Chain Approach | Hybrid With Dedicated Servers (Recommended) |
|---|---|---|
| Simple DeFi farm / staking UI | Contracts hold state; front-end reads directly via shared RPC. | Contracts stay minimal; API and indexer on dedicated servers handle positions, rewards history, and analytics. |
| NFT marketplace | All metadata on-chain; client queries chain directly. | Contracts store identifiers; metadata, search, and recommendations live in DBs and indexers on dedicated servers, fronted by CDN. |
| Cross-chain bridge or oracle | On-chain light clients only. | Off-chain watchers, relayers, and risk engines run on dedicated servers across regions, with occasional on-chain commitments. |
Dedicated infrastructure also plays a key role in DePIN and decentralized compute. Emerging reports show decentralized physical infrastructure networks can significantly undercut hyperscale cloud pricing – in some cases by up to 85% – and are projected by the World Economic Forum to reach trillions in value by 2028. But these networks still depend on physical servers; they are another layer in the stack, not a replacement for operating your own backbone for mission-critical workloads.
The pragmatic pattern we see: teams run core dApp backends, RPC, and indexers on dedicated servers, then selectively integrate decentralized compute or storage where it aligns with their risk and cost models.
Who Provides Reliable Servers for Running dApp Backends?

Melbicom focuses on dedicated infrastructure for Web3: single-tenant servers in 21 Tier III/IV data centers, a global backbone above 14 Tbps, and a CDN with 55+ PoPs across 36 countries. Combined with S3-compatible storage and 24/7 support, this gives dApp teams a predictable, latency-optimized platform for backends.
We designed our platform specifically around the workloads described above:
- Global footprint, local latency – Web3-ready configurations are available across 21 data centers in Europe, the Americas, Asia, Middle East, and Africa.
- Network tuned for blockchain – A backbone with more than 14 Tbps of capacity, over 20 transit providers, and 25+ internet exchanges is engineered to keep block propagation, gossip, and RPC traffic stable.
- Capacity when you need it – Web3 teams can choose from more than 1,300 ready-to-go server configurations, with custom builds delivered in 3–5 business days. This mix lets you spin up testnets quickly and then migrate to bespoke GPU, high-memory, or high‑storage configurations as projects grow.
- Integrated delivery and storage – An enterprise CDN with 55+ PoPs and unlimited requests, plus S3-compatible object storage in a Tier IV Amsterdam data center, makes it straightforward to ship dApp frontends, snapshots, proofs, and NFT assets close to users while keeping authoritative copies on resilient storage.
In practice, teams often run dApp backends on our servers, while also integrating multiple third-party RPC providers for redundancy. Unmetered, guaranteed bandwidth and stable IPs make it feasible to keep self‑hosted RPC, indexers, and subgraphs in the loop without unpredictable egress bills or IP changes.
Because Melbicom focuses on the infrastructure layer – servers, networking, CDN, S3 storage, and BGP – your team keeps full control over node clients, smart contracts, and app code. That aligns well with the operational reality many Web3 teams want: sovereign control over critical infrastructure, without having to also build data centers and global networks from scratch.
Conclusion: Hybrid Infrastructure Is How dApps Reach Scale

The last few years have been a stress test for Web3 infrastructure. Congested chains, RPC outages, and centralized cloud incidents all exposed the same weakness: if your “decentralized” application depends on a single region, a single provider, or a single endpoint, users will discover that weakness at the worst possible time.
At the same time, the core blockchain model is not going away. On-chain consensus is still the best tool we have for global, tamper-resistant state. The way forward is not to push everything into smart contracts, but to treat the chain as the final source of truth and surround it with robust, observable, regionally distributed off‑chain infrastructure.
Dedicated servers, global networks, CDNs, and S3-compatible storage are the pieces that let you build that hybrid model with the determinism and performance users expect.
Practical Takeaways for dApp Backends
- Design around end-to-end latency, not just gas. Map the full request path – UI → API → cache → indexer → RPC – and place latency-sensitive components (RPC, indexers, APIs) in the same region and on similarly performant dedicated servers.
- Run your own critical infrastructure, even if you use managed services. Use multiple RPC providers plus self‑hosted nodes, and design failover so no single provider can take your dApp offline.
- Invest early in observability. Capture metrics for block times, gas costs, RPC error rates, node sync lag, and p95/p99 API latency. Correlate them so you can distinguish chain-level issues from infrastructure or code regressions.
- Treat indexing and storage as first-class concerns. Whether you use decentralized indexing protocols or roll your own, budget dedicated servers and S3/object storage for subgraphs, search indexes, and historical analytics – and front them with a CDN for user-facing workloads.
- Adopt decentralized compute and storage incrementally. DePIN and decentralized storage networks can meaningfully cut costs and reduce centralization, but they still sit atop physical servers. Start by offloading appropriate workloads (e.g., archives, non-critical compute) while keeping core dApp backends on infrastructure you can control.
Taken together, these practices get you close to the original Web3 vision – applications that remain usable and trustworthy even when individual components fail – without sacrificing the performance and observability today’s users demand.
Scale Your dApp Backend on Dedicated Servers
Build low‑latency RPC, indexers, and APIs on single‑tenant hardware with global bandwidth and S3 storage. Explore configurations or request a custom build for your Web3 stack.
Get expert support with your services
Blog

Make IP Space Portable With BYOIP, BGP And RPKI
The global border gateway protocol routing table now carries roughly 950,000–1,000,000 IPv4 prefixes, adding more than 50,000 new entries in 2024 alone.
In parallel, over half of all routes are now covered by RPKI Route Origin Authorisations (ROAs), and an estimated 74% of traffic flows toward prefixes protected by RPKI.
That scale and shift toward cryptographic validation are changing how serious operators think about address space. Public cloud egress still commonly costs $0.08–$0.12 per GB; a multi‑region database that replicates just 100 GB/day between three regions can burn through about $30,000 per year in transfer fees alone. Moving workloads between providers or regions without changing IPs—and without breaking reputation or access controls—starts to look less like a luxury and more like risk management.
Industry guidance on IP transit and addressing is clear: provider‑independent (PI) space + an autonomous system number (ASN) gives you portability and the ability to multi‑home; provider‑assigned space ties you directly to an ISP’s routing and commercial terms.
In this article, we combine those industry trends with what we at Melbicom see (running BGP sessions and dedicated servers across 21 Tier III/IV data centers, backed by 20+ transit providers, 25+ IXPs, and a CDN with 55+ PoPs. You’ll get a practical blueprint for:
- The prerequisites and workflow for BYOIP using border gateway protocol BGP
- How BYOIP compares to renting provider IPs
- The security controls that matter now that RPKI and IRR filtering are mainstream
- A concrete border gateway protocol configuration example you can adapt
Choose Melbicom— BGP sessions with BYOIP — 1,300+ ready-to-go servers — 21 global Tier IV & III data centers |
 |
What Is the Main Purpose of BGP in Computer Networks?
The border gateway protocol (BGP) is the Internet’s inter‑domain routing protocol. Its main purpose is to let autonomous systems exchange reachability information and select paths based on policy, not just distance. That’s what enables multi‑homing, traffic engineering across transit providers, and global reachability for your own IP space.
Under the hood, BGP is a policy engine. Each autonomous system (AS) advertises IP prefixes it can reach, attaching attributes like AS_PATH, local preference, and MED. These attributes let operators express business and technical policies—prefer cheaper transit, avoid certain countries, keep local traffic on local links vs. just “shortest path wins.”
In practical terms, border gateway routing protocol sessions between your ASN and your upstreams are how you turn address space into a globally reachable, multi‑homed asset. For BYOIP, that’s exactly the mechanism you use to make your own prefixes visible at scale.
BYOIP Prerequisites and Workflow: From Allocations to Global Reach
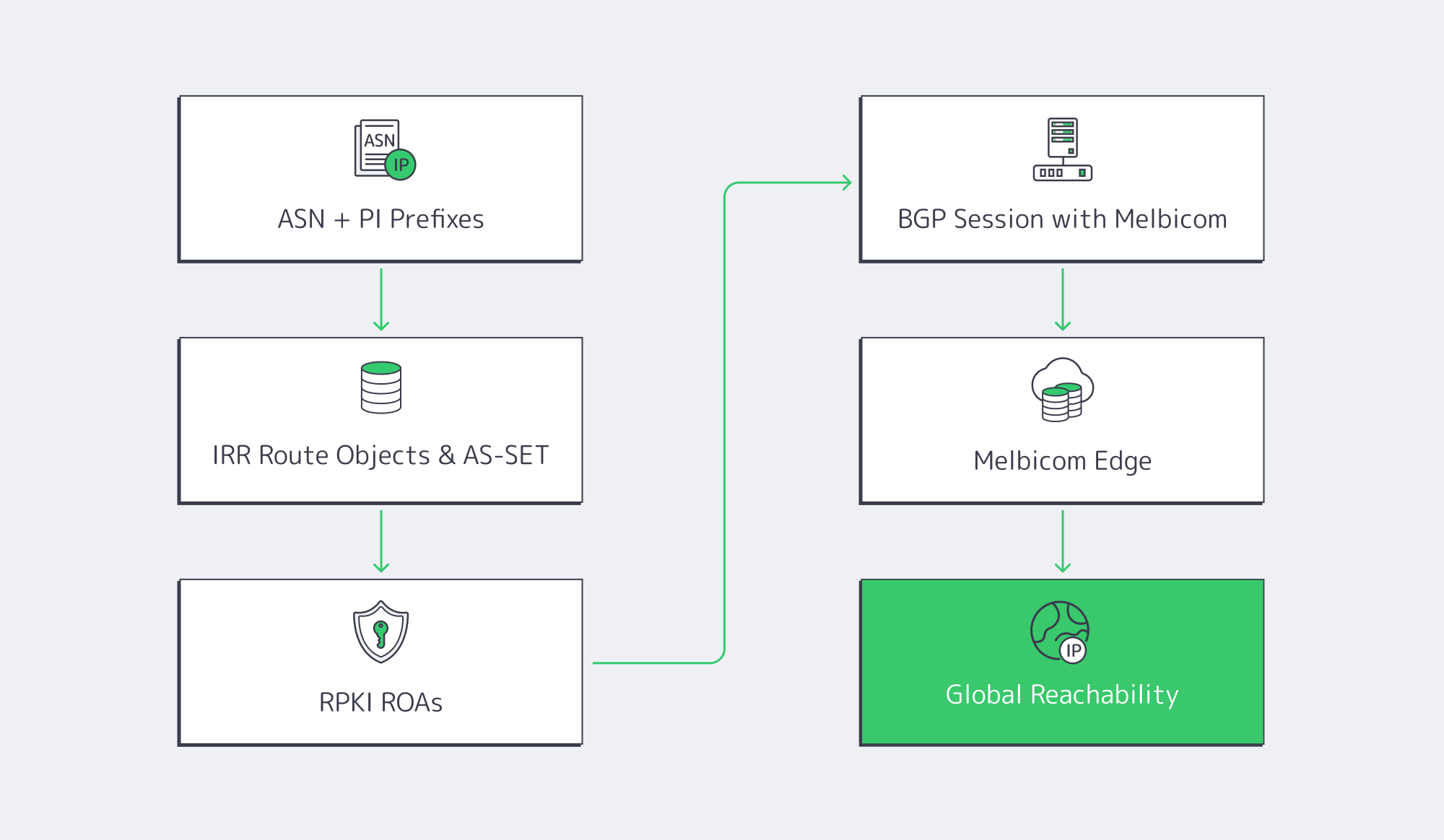
At a high level, BYOIP means: you own the addresses, you originate them from your ASN, and your infrastructure provider re‑announces them through its edge. Getting there is a four‑part workflow.
1. Own an ASN and Provider‑Independent Prefixes
You need:
- A public ASN from your regional internet registry
- Provider‑independent (PI) IP blocks, typically at least a /24 in IPv4 and /48 in IPv6
PI space is assigned directly to your organization by an RIR and is portable across providers; PA space is allocated by an ISP, is typically aggregated within their larger block, and can’t follow you when you change providers.
That portability is the foundation of BYOIP: the same prefixes can be originated from different data centers, different providers, or both. It does, however, commit you to running BGP border gateway protocol sessions somewhere in your stack—on your own routers, on dedicated servers, or both.
2. Publish IRR Route Objects and AS‑SETs
Internet Routing Registries (IRRs) are DBs that describe which AS is authorized to announce which prefixes (ROUTE/ROUTE6 objects), and which ASNs belong to a given organization (AS‑SETs). They’re still widely used by transit providers for prefix‑list and filter generation.
For BYOIP with Melbicom, the operational baseline is:
- Each prefix has a correct, current ROUTE/ROUTE6 object referencing your ASN
- You maintain an AS‑SET that lists your customer or internal ASNs
- IRR data is present in major DBs like RIPE, ARIN, APNIC, AFRINIC, LACNIC, RADB, or IDNIC
Melbicom validates customer prefixes against these IRRs and only accepts announcements that match published objects. It’s a straightforward step that dramatically reduces accidental route leaks and spoofed announcements.
3. Secure Routes with RPKI
IRRs are useful, but they’re essentially signed with a password. RPKI adds cryptographic proof that the holder of a prefix has authorized a specific ASN to originate it.
Using your resource certificate from the RIR, you create ROAs (Route Origin Authorisations) that state:
- Prefix (and maximum prefix length)
- Authorized origin ASN
When other networks perform BGP Origin Validation, each route targeting your prefix is classified as: VALID, INVALID, or UNKNOWN, depending on how it lines up with your ROAs.
RIPE and MANRS both now treat RPKI deployment as table‑stakes routing hygiene, and more than half of global IPv4 and IPv6 routes are RPKI‑covered. LACNIC’s guidance is clear: prefix holders—not transit providers—are responsible for creating ROAs, and multi‑homed prefixes can authorize multiple origin ASNs if needed.
Two practical rules for your RPKI setup:
- Keep max‑length fields tight (e.g., /24 on a /24) to avoid unintentionally blessing over‑specific hijacks
- Treat ROA management as part of change control whenever you add regions/providers
Melbicom enforces RPKI origin validation and rejects announcements with INVALID status, so ROAs are not optional in a BYOIP workflow.
4. Establish a BGP Session with Melbicom
With IRR and RPKI in place, the next step is to bring up one or more BGP sessions between your router and Melbicom’s edge.
Operationally, that means:
- You run a BGP daemon (BIRD or FRRouting are common choices) on a dedicated server or edge appliance
- We at Melbicom provision a BGP peering in the requested data center(s) for your ASN
- You export only your authorized prefixes; we import them after IRR and RPKI checks and propagate them to transit and peering neighbors
Melbicom offers free BGP sessions on dedicated servers, with IPv4 and IPv6 support and up to 16 prefixes per session by default. We also support full, default‑only, or partial route feeds, and BGP communities you can use to influence how we advertise your routes upstream, including which transit providers receive them and how they are prioritized.
5. Announce via Melbicom’s Global Edge
Once your prefixes are accepted, we re‑announces them from a globally distributed edge:
- 21 Tier III/IV data centers across the Americas, Europe, Asia, and Africa
- Per‑server bandwidth options up to 200 Gbps, depending on location
- A backbone with 20+ transit providers and 25+ IXPs, tuned for short, stable paths
- A CDN with 55+ PoPs in 35+ countries to keep content close to users
From your perspective, this means your PI space keeps its reputation and access lists while your workloads move between Melbicom locations or grow into multi‑region architectures. Combine that with BGP communities for provider and region preference (a pattern widely used in operator backbones), and you can dial in how traffic enters your network at a fairly granular level—without ever surrendering ownership of the addresses.
BYOIP vs. Provider‑Assigned IPs
From a distance, both BYOIP and renting IPs end in the same place: packets flow. But the economic and operational profiles are almost opposites. Guidance on PI vs. PA space from operator‑focused sources all lands on the same trade‑off: PA is simpler and cheaper; PI plus border gateway protocol buys you control and portability.
Here is a condensed comparison for planning purposes:
| Decision Factor | Provider‑Assigned IPs (PA) | Bring Your Own IPs (PI + BGP) |
|---|---|---|
| Ownership & Lock‑In | Addresses belong to provider; renumbering required when you leave. | Addresses belong to you; portable across providers and regions. |
| Migration & Multi‑Cloud | DNS changes, TTL tuning, and gradual cutovers every time you move. | Same prefixes follow workloads; DNS changes become optional or minimal. |
| Security & Reputation | Reputation tied to provider’s overall hygiene and other tenants. | You control RPKI, IRR, and abuse handling for long‑lived, “clean” ranges. |
| Operational Overhead | No BGP required; provider handles routing. | Requires BGP expertise and ongoing border gateway protocol configuration hygiene. |
| Best Fit | Single‑provider, regional, or cost‑sensitive deployments. | Multi‑cloud, multi‑region, or compliance‑sensitive systems with long planning horizons. |
If you already operate an ASN and PI space, the marginal cost of BYOIP over Melbicom’s edge is almost entirely operational—getting the routing right once and keeping it clean.
What Are the Main Security Considerations for BGP?

BGP was designed for a smaller, more trusting Internet. The main security issues are route hijacks, route leaks, and plain misconfiguration that causes traffic to be mis‑routed or black‑holed. Modern best practice combines IRR filtering, RPKI origin validation, prefix‑limit controls, and careful policy design to mitigate these risks.
Even with RPKI adoption crossing the 50% mark, real‑world incidents show how fragile global routing can be. Datasets built from BGP‑monitoring tools record thousands of anomalies—many accidental, some malicious—impacting major technology firms and even government networks.
For BYOIP deployments, a secure posture typically includes:
- RPKI and IRR at the same time. IRR data is still widely used to build prefix filters; RPKI adds cryptographic checks and standardized VALID/INVALID/UNKNOWN states.
- Tight export policies. Your routers should only ever announce your PI prefixes and, where relevant, any customer prefixes you’ve explicitly agreed to originate.
- Inbound route filtering and max‑prefixes. Protect your own infrastructure from a misbehaving upstream and from accidental full‑table floods. Operator BCPs emphasize that the main scalability pressure on BGP is the growth of the routing table and churn from updates; enforcing sensible limits is table stakes.
- Conservative use of BGP communities. Communities are powerful for traffic engineering and provider selection; widespread measurement shows that most global prefixes now carry at least one community tag. Melbicom supports both our own and pass‑through communities but does not offer BGP blackhole services, keeping policies focused on routing rather than DDoS signaling.
For our part, Melbicom runs RPKI‑validated routing, strict IRR filtering across all major registries, and controlled acceptance of more‑specific routes (only /24s that are individually registered), which significantly reduces the risk of hijacks propagating through our edge.
BGP Configuration Example
At a high level, a BYOIP border gateway protocol configuration does three things: establishes a session with your provider, originates your prefixes, and applies import/export filters. The example below uses BIRD, which is what many Melbicom customers run on dedicated servers. It assumes you already have your PI prefix on eth0.
| # /etc/bird/bird.conf (IPv4) router id X.X.X.X; # Your server’s IPv4 protocol static static_byoip { route YOUR.PREFIX.IP/MASK via “eth0”; } protocol bgp melbicom_ipv4 { local as YOUR_ASN; neighbor X.X.X.X as MELBICOM_ASN; # Provided by Melbicom import all; # Or add filters here export where net ~ [ YOUR.PREFIX.IP/MASK ]; next hop self; } |
| # /etc/bird/bird6.conf (IPv6) router id X.X.X.X; # Still an IPv4 address protocol static static_byoip_v6 { route YOUR:V6::/MASK via “eth0”; } protocol bgp melbicom_ipv6 { local as YOUR_ASN; neighbor XXXX:XXXX::1 as MELBICOM_ASN; import all; export where net ~ [ YOUR:V6::/MASK ]; next hop self; } |
From there, you can extend the configuration with BGP communities for traffic engineering—tagging routes to prefer certain upstreams, limit propagation, or steer traffic via specific regions, mirroring the patterns documented in operator training materials.
Key Takeaways: Why BYOIP with BGP Is Worth the Effort
If you already hold PI space and an ASN, treating those addresses as a strategic asset rather than just plumbing changes how you build infrastructure. Based on industry data and what we see in production environments, a few practical recommendations emerge:
- Align IP strategy with multi‑region reality. Latency‑sensitive and regulated workloads increasingly span regions, and even small amounts of cross‑region traffic can become a major line item at public‑cloud egress prices. BYOIP over BGP lets you move or duplicate workloads without repeatedly paying in downtime and address churn.
- Make RPKI and IRR first‑class citizens. With more than half of global routes now RPKI‑covered, failing to publish ROAs and maintain IRR objects is no longer a harmless omission—it’s a security and reachability risk. Build ROA and IRR updates into your normal deployment and change‑management processes.
- Invest once in routing expertise, reap benefits for years. Standing up robust border gateway protocol routing—with filters, communities, prefix‑limits, and monitoring—takes time, but the payoff is cumulative: every future migration, new region, or new provider is easier because your IP space is already portable.
- Choose providers that amplify, not dilute, your control. BYOIP only delivers if upstreams respect RPKI and IRR, give you useful BGP community hooks, and operate a well‑peered, low‑latency edge. Look for clear documentation of filtering policies, RPKI support, and route‑control options—not just raw bandwidth numbers.
Turn Routing into a Strategic Capability
The combination of PI address space, an ASN, and a well‑designed border gateway routing protocol deployment turns IP addressing from a sunk cost into a strategic lever. Instead of re‑numbering every time you change providers, you re‑pin BGP sessions. Instead of accepting whatever path your upstream picks, you use communities and policy to shape how traffic enters and leaves your network.
As routing tables grow and RPKI deployment crosses critical thresholds, the gap between “best effort” and “engineered” Internet connectivity is widening. Operators who treat BGP as a first‑class system—complete with security controls, telemetry, and clear ownership—will be able to adopt new regions, hardware generations, and commercial models without renegotiating their identity on the network. BYOIP is the natural endpoint of that mindset.
Deploy BYOIP on Melbicom’s Global Edge
Announce your own prefixes over free BGP sessions on dedicated servers worldwide. Keep reputation, reduce migrations, and steer traffic with communities.
Get expert support with your services
Blog
Dedicated Servers: Slashing iGaming Hosting Costs
iGaming platforms run hot, late, and global, so the infrastructure choices you make are directly correlated with gross margin. The question is simple: where does the iGaming dedicated server model beat utility cloud on total cost of ownership without compromising performance and efficiency?
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
How Does Dedicated Server Hosting Lowers TCO for iGaming?
Usage-based cloud pricing scales every minute of uptime for the compute-heavy service (game logic, ledgers, trading/odds engines, compliance integrations), providing always-on services. You pay for instance hours, storage I/O, inter‑AZ and regional traffic, and—most agonizingly—egress. By comparison, a dedicated server contract charges a flat monthly OpEx for CPU, RAM, disks, and port capacity—your bill does not increase when sessions peak or streams run long.
The economics become more compelling as scale increases. Global online gambling revenue is already in the tens of billions, and with a double‑digit CAGR, steady backend utilization is the norm rather than the exception. Within that kind of environment, flat rate infrastructure is expected to win on TCO due to the marginal cost of an extra player minute being near zero until the point of capacity is reached. Current market estimates put online gambling revenue at approximately $78.7 billion, with sports betting as the largest sub‑segment—useful context for setting traffic and infrastructure requirements.
The second half of the equation is predictability. IDC indicates that almost half of cloud buyers spent more than planned in the previous year, and 59% expected to overspend again, noting that forecasting in pay‑per‑use environments is difficult even for mature teams; dedicated contracts avoid that forecasting problem.
A simple, illustrative iGaming server comparison for steady load
| 3 year host comparison Dedicated server Cloud instance | Dedicated server | Cloud instance |
|---|---|---|
| Monthly infrastructure charge | $250 (flat) | $400 (usage‑based) |
| Total cost – 1 year | $3,000 | $4,800 |
| Total cost – 3 years | $9,000 | $14,400 |
| Billing predictability | High (fixed) | Low (variable) |
Numbers are illustrative only; actual rates vary. The idea is to demonstrate the effect of a flat rate compounding to lower TCO in the case of continuous utilization.
Predictable Costs vs. Surprise Bills: How Flat‑Rate Pricing Restores Budget Control
Storage/egress and cross‑region bandwidth are typically associated with bill shock. Recent survey results show that 95 percent of organizations have been hit by unexpected cloud storage charges (egress, retrieval, API operations), underscoring how non‑compute line items can quietly sink budgets. And even as some of the providers have softened their egress at the point of leaving their platform on a permanent basis, multicloud or CDN egress costs are day to day.
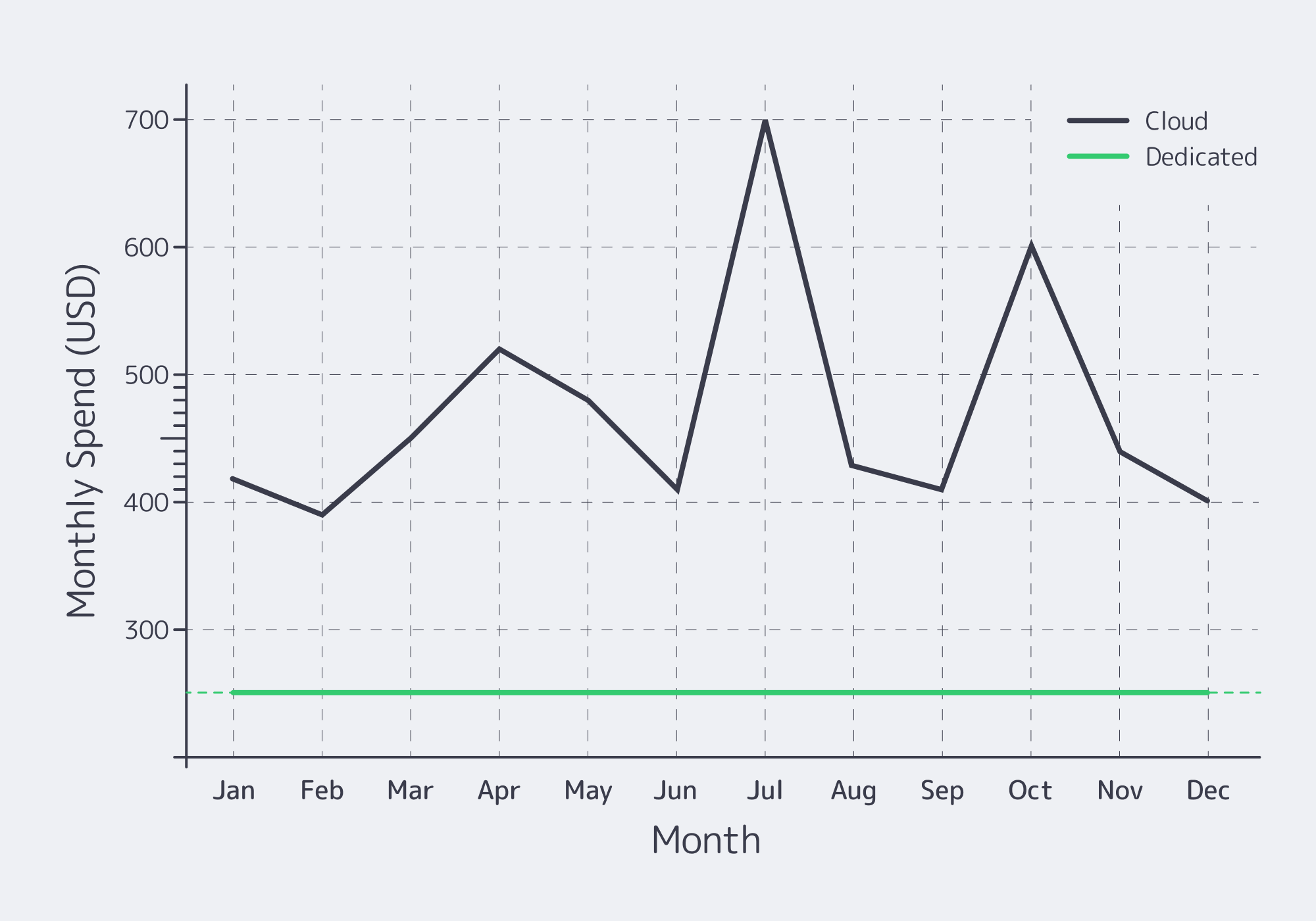
These dynamics make cloud bills far more volatile from month to month than the monthly rental price of dedicated server hosting.
The impacts at the CIO level are not mythical: cloud overruns, project postponements, and forced reprioritizations have become the norm, according to industry reports. Dedicated hosting avoids that volatility; with a flat rate, you pay once for the capacity and can drive it to the limit. To offload traffic, install a CDN before your origins such that most of the bytes do not reach your server ports. CDN of Melbicom operates in 55+ PoPs in 36 countries and thus not only origin load is minimized but also allows bandwidth expenditure to remain linear on the core.
Headroom bandwidth is also important: Melbicom’s network provides per‑server ports of up to 200 Gbps at select sites, which are invaluable for live‑dealer video, jackpots with mass fan‑outs, and logs/telemetry replication, again on a predictable monthly payment rather than per‑GB surprises.
Maximizing Cost Efficiency without Compromising Performance
Hybrid scaling for peak events (baseline on dedicated, burst tactically)
The working solution is frequently that of both: implement the stable base load on dedicated machines and scale stateless front ends or microservices to the cloud on peak events. In that manner, you do not pay cloud premiums 24/7 and have elastic headroom in case of the Champions League final or to the Super Bowl. Industry analysis reveals that repatriation is not an all‑or‑nothing movement; in most cases, organizations end up with hybrid estates, with some workloads on dedicated servers and others on public cloud.
Executing this approach means placing origins in a few well‑peered metros for low‑latency paths to critical markets, fronting them with a global CDN, and exposing only the presentation tier to the internet. Melbicom has 21 Tier III/IV data centers and 1,000+ ready‑to‑go server configurations with 2-hour activation, so you can size the base just in time while still responding swiftly to forecast changes.
Automation reduces management overhead (without cloud mark‑ups)
Dedicated was once the word that meant manual. Not anymore. Using API driven provisioning, configuration management and IaC, you can treat physical servers just like any other pool:
- Provision via API into CI/CD flows, then join nodes to clusters automatically.
- Autoscale in coarse steps (add/remove physical nodes by policy) instead of fine‑grained VM steps—which is often simpler and cheaper in practice.
- Have observability SLOs (CPU saturation, tail latency, queue depth) to resource scheduling when on predictable cadences (weekly vs seasonal sports on live cadences), intra day vs predictable promos (live dealer promos).
Increasingly, FinOps programs are placing more focus on automation so that they can do more optimization with less human intervention- a practice that is easily ported to dedicated estates since the APIs and pipelines do not vary. Melbicom also has 24/7 technical assistance and managed support where you require hands-on assistance so your DevOps department does not turn into a hardware support desk.
Capacity planning: enough headroom, not waste
iGaming Capacity Planning should be fact based:
- Right‑size by region: peak concurrency follows time zones, so allocate capacity accordingly to avoid over‑building a single mega‑cluster and place cores close to major IXPs to minimize path variance; Melbicom’s presence in global metros keeps compute near players and payment rails.
- Incremental scale‑out: add mid‑sized servers as DAU grows over time rather than buying one piece of big iron, and use month‑to‑month dedicated contracts to flex seasonally without long commitments.
- Move bulk bytes to the CDN such that origin capacity is purchased on low-latency interactions and not on bulk delivery.
Performance isn’t a luxury; it’s the ROI multiplier
Single‑tenant servers eliminate noisy‑neighbor effects and hypervisor overhead. Practically, that provides smaller latency distributions, which is directly proportional to bet completion + session length.
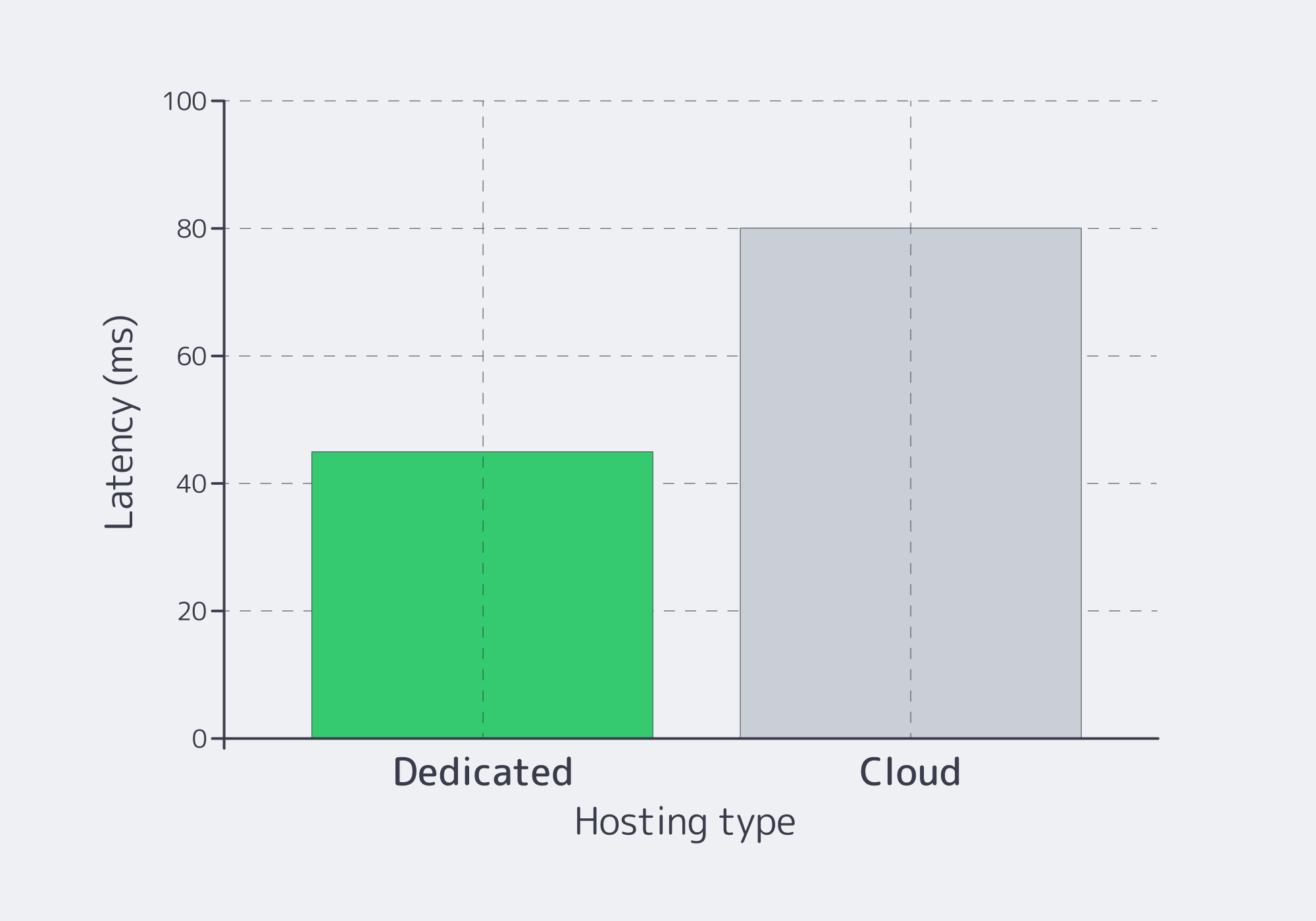
So that, with fewer tail spikes, there is less abandoned carts, and fewer hedged bets because of jitter-value that you can put back to revenue.
Why is Cloud Repatriation Back on the Roadmap?
Modern repatriation is surgical: organizations pull back specific workloads from the cloud when unit economics no longer make sense (high, constant utilization, strict data‑residency requirements) and keep the rest where elasticity is valuable. Numerous studies converge on the same pattern: only about 8–9 percent of companies even consider full repatriation, yet a much larger share expects some movement to improve cost and latency control, often resulting in hybrid architectures. The headline driver is cost.
The economics can be seen in the wild: 37signals publicly projected $7 million in five‑year savings—without increasing the operations team—by moving a steady‑load SaaS off the public cloud to owned and dedicated capacity. It is not iGaming, but the trend (stable workload base → standardized prices base → reduced TCO-base) is similar.
iGaming Hosting Solutions Checklist
- Lock in a predictable base. Fixed price dedicated nodes with fixed size (60-75 percent peak) put durable workloads (accounts, RNG/odds, payments) on them.
- Burst only the edge. Use cloud autoscaling for API and presentation tiers during major events, then spin them down afterward.
- Engineer out egress. Serve as much traffic as possible from the CDN to minimize cross‑region chatter, and track and cap egress in SLOs.
- Automate capacity turns. Add/ remove dedicated nodes using IaC on schedules based on sports seasons and promotions.
- Buy bandwidth once. Prefer providers that have large per server ports to ensure replication and video do not come across per GB surprises.
- Measure ROI in user terms. Tie infrastructure changes to bet latency, session length, and hold rate; don’t optimize for instance count—optimize for margin.
- Keep options open. Hybrid is no trade-off but an allocation plan, which adheres to workload economics.
Where Does Melbicom Fit When You Make “Dedicated Server vs Cloud” Trade‑offs?
The iGaming dedicated server placement cannot be overlooked when your model requires flat rate predictability as well as performance. Melbicom operates Tier III/IV data centers in 21 locations with 1,300+ ready‑to‑go server configurations that can be online in less than 2 hours and offers bandwidth of up to 200 Gbps per server to accommodate unusual peaks. Install a CDN in 55+ PoPs to move heavy resources off the origin and retain origin capacity on low latency routes. The outcome: a floor that you can count on, and a worldwide competitive advantage that ensures gameplay and live streaming is responsive.
What’s the bottom line?

When your platform is continuously running and you want low variance in latency and cost, a flat‑rate dedicated model is usually the superior financial default. The cloud remains invaluable—particularly for experimentation and short bursts—but in practice egress, cross‑region traffic, and per‑unit compute pricing are pure pay‑as‑you‑go, which tends to over‑index on volatility. The case of TCO gets stronger with the increase in utilization and with the dependency of global delivery on smart CDN offload rather than the over provisioned origin fleets.
A forward‑looking plan doesn’t pick a single winner; it allocates workloads—dedicated for the stable spine, cloud for elasticity, CDN for bytes, and S3‑compatible object storage for media, logs, and backups, ideally with clear pricing and data residency. This combination maximizes ROI while keeping budget risk low, and you should evaluate providers on time‑to‑deploy, per‑server bandwidth, PoP coverage, and support depth rather than just GHz or core counts.
Build predictable iGaming infrastructure
Deploy dedicated servers with global CDN and 24/7 support to cut bill shock and keep latency low across peak events.
Get expert support with your services
Blog

Lightning-Fast iGaming: Dedicated Hosting for Low-Latency Performance
In live sportsbooks and interactive casino tables, the systems that update odds, deal cards, or close spins first determine who wins the session—and who earns repeat business. Any failure to refresh odds or process live bets promptly can undermine user confidence and expose operators to financial risk. Consistency across regions is just as critical: bettors in Frankfurt and Los Angeles must see the same game state at the same time.
Why Low Latency Is Non‑Negotiable in the iGaming Space
The latency is the time period taken by the packet between the server and the client and vice versa. The first offender is distance: a request of length of (say) 100 miles could take up to (say) 5-10ms; a request sent across (say) 2200 miles would take up to (say) 40-50ms, until you start handshakes, TLS, rendering, or application code. The architectural suggestion to iGaming is not to philosophize, and it’s to bring the computer near the players and eradicate jitter elsewhere.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
The iGaming hosting offered by Melbicom is based on single tenant dedicated servers that are located in 21 Tier III/IV locations supplemented by a 50+ PoP CDN, 1,300+ ready to spin server setups and per server 200Gbps uplinks. This footprint allows us to maintain a short, deterministic critical path and push heavy content to the edge.
How Does iGaming Hosting on Dedicated Servers Cut Latency?
Single‑tenant dedicated servers eliminate both resource contention and hypervisor overhead, whereas virtual machines add both. With no noisy neighbors, there are no surprises from stolen CPU cycles, shared NIC interrupts, or jitter caused by an overselling host. This is why operators keep key paths—odds engines, RNG, wallet, settlement—on core servers, while bursty or experimental web front ends are pushed to the cloud.
Hardware matters:
- NVMe over PCIe provides deep queue parallelism and end‑to‑end latency under roughly 10 microseconds (including the software stack). Recalculation of odds, writing in a wallet and updating the session state are completed before an eye of a human being could make a blink.
- High‑clock Xeon and EPYC SKUs keep single‑threaded bet placement snappy while parallelizing event ingestion, pricing, and streaming workloads.
- Keep hot odds, session state, and leaderboards off disk, reserving HDDs only for cold reads and cold data modifications.
- We scale NICs to 10/40/100/200 Gbps based on concurrency and streaming requirements and keep network paths short through local peering.
iGaming Infrastructure: Dedicated Servers vs. Cloud vs. VPS

The concise one: dedicated servers are selected as far as the critical path is concerned. In the case of elasticity on the edges (marketing landers, stateless APIs), the cloud comes in handy. VPS inherits the same problem of the noisy neighbors as the public cloud and tends to overcapacity the I/O and throughput more violently.
| Significant factor | Cloud hosting (virtualized) | Dedicated Computing (single‑tenant) |
|---|---|---|
| Latency & jitter | Poor and steady, tail can spike up in times of load due to hypervisor overhead and noisy neighbors. | Deterministic: There are no hypervisors or neighbors; they are ideal when it comes to placing bets and streaming. |
| Throughput under load | Frequently capped; egress fees promote off platform delivery. | High sustained throughput of up to 200 Gbps per server for price feeds, streams, and settlement. |
| Control & locality | Hardware non-transparent; placement may vary across areas. | Complete control (root/IPMI), fine positioning of performance and compliance. |
Table. Dedicated servers vs cloud for latency-constrained iGaming workloads.
Where Do the Big Milliseconds Go—and How Do You Remove Them?
Distance: deploy at the edge & route by proximity
Every handshake is compounded by distance. The solution lies in regional hubs (e.g., EU, US, APAC) with global load balancing or anycast so that a bet out of Frankfurt would land in Europe and one out of Atlanta would land in North America- then make data resident to make audits simpler. The 21 locations and 55+ CDN PoPs that Melbicom offers build proximity into the design and allow most interactions to complete well below the threshold where users perceive delay.
Bandwidth & queuing: remove choke points
Saturated 110Gbps connections buffer packets and distend tail delays. Saturated 1–10 Gbps links queue packets and magnify tail latencies, so headroom on interfaces is essential. Our recommendation is a headroom to NICs (enlarge where needed to 40/100/200 Gbps) as well as peering to reduce hop count. To maintain your game-related origin, offload the delivery of large media or updates using the CDN of Melbicom.
Storage stalls: keep hot paths in memory and NVMe
Cache session state and odds in RAM, then write behind to NVMe; NVMe’s microsecond‑class latency makes on‑commit durability realistic without stalling user paths.
Application tail latencies: isolate and decouple
For live analytics, personalization, or fraud models, decouple compute from the betting path: write the transaction and immediately acknowledge it on the core service, then mirror events to separate analytics clusters (GPU‑enabled if needed). If you integrate blockchain components (wallets or provably‑fair attestations), buffer transactions behind queues so on‑chain latency never blocks gameplay.
Optimizations That Move the Needle Today

Set realistic latency targets for each region. Traffic within a region should feel instantaneous to players; globally, keep interactions below the threshold where delay is perceptible. A practical north star is sub‑100 ms end‑to‑end latency for the vast majority of interactive actions, with P95/P99 budgets enforced per region.
Harmonize with determinism and not averages. Track and budget tail latencies explicitly, focusing on the worst‑case response times for bets, odds updates, table actions, and withdrawals. When P95 latency drifts out of bounds, scale horizontally or add capacity before users feel the impact. We recommend keeping core clusters at roughly 60–70% CPU and memory utilization during peak windows and using thresholds to trigger automatic provisioning of additional nodes.
Exploit the edge for everything that isn’t transactional. Offload everything non‑transactional to the edge by serving static assets through Melbicom’s CDN and storing media in S3‑compatible object storage (NVMe‑accelerated, up to 500 TB). Let the CDN fetch those objects instead of your game servers so the critical path stays lean and avoids extra origin round trips.
Design for failover and proximity. Launch in your two most important regions first, then expand, keeping warm standbys where needed so traffic can be drained and rerouted cleanly when a region is under pressure or being tested.
iGaming Hosting Solutions vs. Unpredictable Cloud Spikes
The demand of sports calendar and promotions is step functions. You don’t need infinite servers; what you need is predictable activation and automation. Melbicom has 1,300+ pre‑built configs, 2‑hour activation, and API‑driven provisioning so operators can pre‑stage capacity in the right location and scale based on telemetry (queue depth, P95 latency, cache hit rate). Combine with container orchestration and images optimized to warm up quickly in order to maintain tail latencies at a constant as traffic doubles in minutes.
In the case of interactive add ons such as real time chat, watch betting social, micro competition the latency budgets should be kept to a minimum despite the addition of features. Industry experience shows that any delay in realtime features hurts engagement and trust, so design these services as independent, horizontally scalable microservices whose load never interferes with bet placement.
Key Recommendations for Low‑Latency iGaming Hosting
- Distribution: Geographic distribution: stand up clusters in several regions, steer users by latency, and keep regulated data local by default.
- Single‑tenant core placement: run odds, RNG, payments, and stateful databases on dedicated single‑tenant servers.
- Ultra fast hardware stack: NVMe SSDs (micro seconds class), new multi core CPU, large RAM, concurrency-sized NICs.
- High‑bandwidth networks & CDN offload: avoid queueing by giving links headroom, reducing hops, and serving assets as close to users as possible.
- Scale under contention: automation using tail aware SLOs: Scale on P95/P99; pre stage capacity: fixtures and promotions.
Conclusion: Build for Speed You Can Prove

Low latency in iGaming is not a trick; it is a system property built from proximity, single‑tenancy, fast storage, and generously provisioned network capacity. The hardest platforms store the processing of bets and state on dedicated hardware, move all that is not vital to the edge and expand regionally. The result is measurable: fewer high‑percentile outliers during peak periods, fewer suspended markets, and more settled bets per minute, all contributing to a smoother user experience.
This foundation becomes more valuable as new interaction models—live micro‑markets, watch‑bet chat, AR tables—continue to raise expectations. Global proximity and consistent single‑tenant performance let you keep adding features without introducing additional latency. When money is measured in milliseconds, the right hosting posture becomes a competitive advantage.
Launch low‑latency iGaming hosting
Provision dedicated iGaming servers in 21 global regions with 200 Gbps uplinks and 55+ CDN PoPs for fast activation, keeping gameplay responsive and consistent worldwide.
Get expert support with your services
Blog
Guide to Deploying a Bare Metal in Brazil for AI/ML Workloads
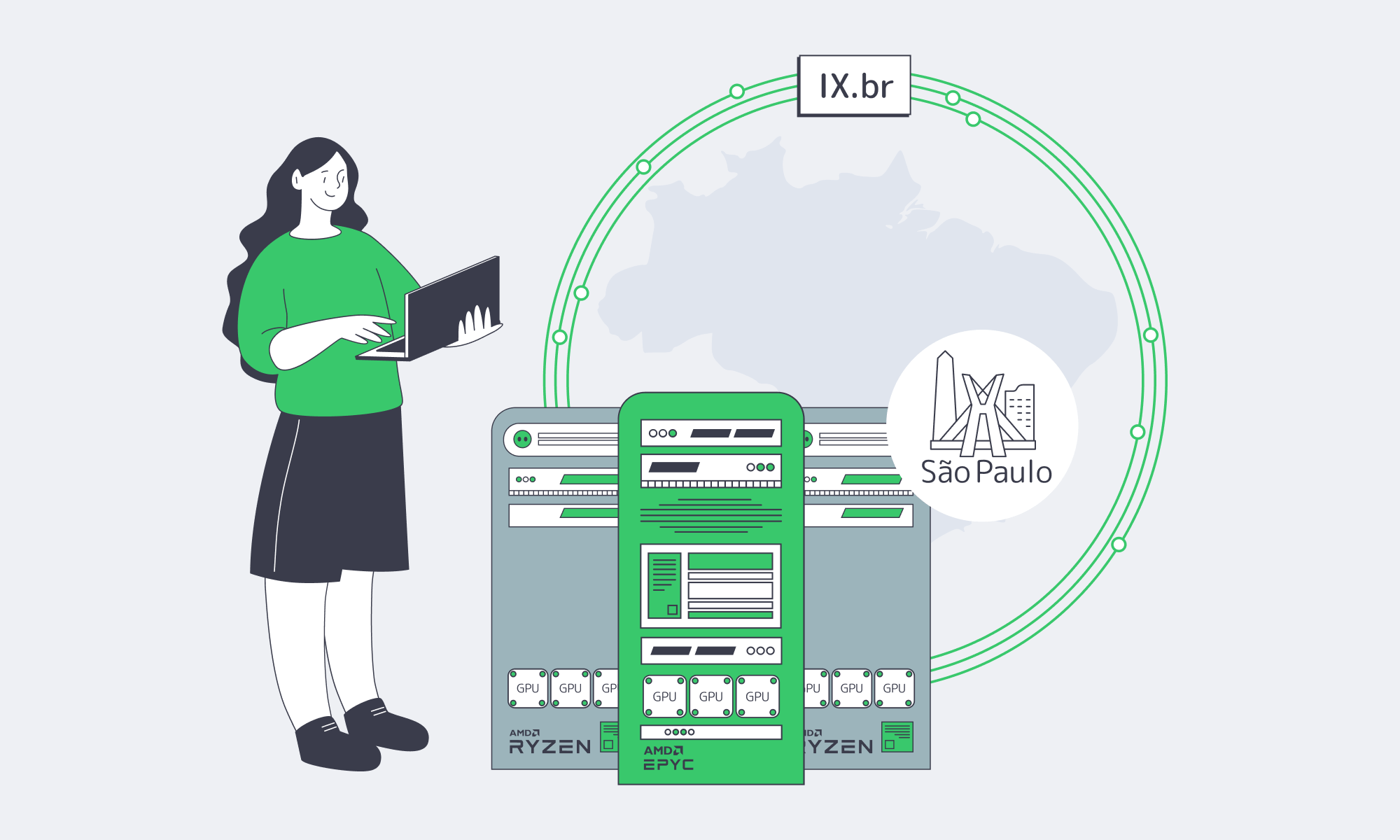
The IX.br exchange in São Paulo has become one of the world’s densest hubs with record traffic peaks, and the demand for interconnectivity in the area is only growing. The dense networks and fiber concentrated in the area provide an advantage if AI/ML teams are in the position to deploy modern bare metal in Brazil. With an origin in proximity to such a hive of interconnectivity, you gain lower latency and more deterministic throughput, and regional compliance and privacy obligations become far easier to prove.
Host in LATAM— Reserve servers in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
Why Deploy AI/ML on São Paulo Bare Metal?
The data center market in Brazil is seeing rapid expansion; it is currently valued at US$3.4 billion and projected to reach US$5.96 billion within the next few years, according to investment research.AI‑heavy workloads are driving the need to compute closer to Brazil’s network core.
Surveys show that this will only snowball as most organizations in Brazil plan to increase AI investment, with AI/Generative projects predicted to cross BRL 13 billion, and it goes without saying that these AI systems will benefit from local, high‑performance infra.
The advantages of placing AI on bare metal in Brazil:
- Full hardware performance for AI math: Bare metal means no hypervisor overhead and sole access to CPU cores, RAM, and attached GPUs, which is better for training runs and high‑QPS inference.
- Proximity to IX.br São Paulo: Round-trip times are significantly reduced by having direct paths to Brazilian eyeball networks, and streams see much lower jitter, which is also a benefit for fraud scoring and interactive AI features.
- Provable data residency: If data is kept within Brazil, then LGPD compliance and audits are far simpler, reducing the risk of fines that can reach 2% of Brazilian revenue with a BRL 50 million cap per infraction.
- Predictability and customization: With full control over OS, drivers such as CUDA/ROCm, frameworks, and network layout, you can tune for specific model stacks and data pipelines without costs getting out of control.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
Which CPUs/GPUs to Choose for “AI‑Ready” São Paulo Server
For a dedicated server in Brazil, AMD EPYC and AMD Ryzen are the workhorses you need; EPYC boasts high core counts, large caches, and robust memory bandwidth, making data preprocessing, vector search, and distributed training coordination a doddle, while Ryzen’s high clock speeds boost latency‑sensitive logic and are ideal for smaller inference models. Each can be paired with optional GPUs to support deep learning.
AI integrations and operations in general are only expected to grow, and as they do so, the technology will push capacity requirements further, raising the bar. We have seen training compute for notable models doubling nearly every 6 months, a macro trend that reinforces the need to design nodes with plenty of headroom and the ability to scale horizontally.
How Local Interconnection Slashes Latency for AI Workloads

Serving from afar via long-distance pathways to Brazil adds latency and lengthens round-trip times. AI services are demanding and need shorter, more predictable paths for user requests and real‑time data feeds. By deploying in São Paulo and leveraging the direct links through the IX.br exchange, you move inference closer to last‑mile ISPs and major content networks. The hub has reported peaks surpassing 31–40 Tb/s; São Paulo regularly exceeds 22 Tb/s, making it a global leader in terms of both volume and participation.
Edge‑adjacent assets such as front‑end bundles, embeddings, and video tiles can be cached and delivered through Melbicom’s CDN in 55+ PoPs, which include South America, allowing core inference to run smoothly in São Paulo. Working in this hybrid manner reduces latency without relocation.
Where a Brazilian dedicated server trumps
Hosting in Brazil reduces cross-border hops, which is especially beneficial if your pipeline ingests Brazilian transaction, clickstream, or sensor data and helps maintain stable bandwidth during peaks. A local origin has a notable effect on user perception in terms of responsiveness, especially when it comes to recommendation engines, fintech risk scoring, live‑ops analytics, and speech systems.
The Privacy and Sovereignty Benefits of Bare Metal in Brazil
When workloads are privacy‑sensitive, compliance can be more complex, but keeping your processing and storage in the country and under your direct control is the perfect built-in solution. With local bare metal deployment, you isolate your data regionally, and as your models are on dedicated hardware, you have sole tenancy with transparent visibility into where copies reside. You avoid the challenges of cross-border transfer, making LGPD requirements for deletion and audits far less complicated while reducing the risk of LGPD fines that can cost up to 2% of Brazilian revenue, capped at BRL 50 million per violation, as well as non‑monetary sanctions like processing suspensions.
Monitoring and Capacity Planning for Instrumentation and Scaling

Design aside, you also need to be able to ensure a performant node is healthy and right‑sized. That means doing the following:
- Instrumenting from day one: High‑frequency metrics for CPU, GPU, memory, NVMe I/O, and NICs should be collected, and you need to ingest application traces and logs into a searchable store. That way, you can identify GPU throttling, data‑loader stalls, and queue build‑ups before they hit SLOs.
- Applying AIOps: Employ anomaly detection on latency, throughput, GPU memory, and temperature to surface subtle degradations such as drift‑driven latency creep or a slow memory leak.
- Forecasting capacity on leading indicators: Monitor and track sustained GPU utilization, p95/p99 latency, request queue depths, and feature‑store I/O. When critical resources consistently hold above roughly 70–80% during peaks, you should plan scale‑up or scale‑out with a design for modular growth that can cope with AI’s accelerating compute appetite, which seems to double every 6 months. This means adding GPUs to a chassis or adding nodes behind a model router.
- Operational discipline: Kernel/driver updates should be scheduled, SMART/NVMe health should be monitored, and replacements should be pre‑staged when error rates tick up.
Sizing for Training, Inference, and Pipelines
- Training nodes advice: Favor EPYC with abundant RAM and NVMe scratch; attach GPUs sized to the model (VRAM ≥ parameter+activation footprint). Use 25–100 Gbps to speed checkpoint sync and multi‑node all‑reduce.
- Latency‑critical inference: Ryzen or EPYC with strong single‑thread perf and ample L3 cache is ideal. If your model is particularly large, then you can cut tail latencies with a single or dual GPU. RTT can also be minimized by keeping all critical services near the IX.br fabric in São Paulo.
- Data pipelines in Real-time: Handle Kafka/Fluentd ingestion with NVMe + >10 Gbps NICs and co‑locate feature stores with inference when the data is sensitive or high‑velocity.
- Hybrid edge caching operation: The model execution should be kept on the São Paulo node while static assets and pre/post‑processing artifacts are pushed to the edge with a CDN such as Melbicom’s that offers PoPs in South America.
Future‑Proof Deployment with Melbicom’s Global Footprint
A locally based AI platform will eventually branch out globally, so why not prime ahead of time for ease when you are ready to do so? Melbicom has 21 global Tier III/IV DCs and a CDN that encompasses 55+ PoPs to enable symmetric patterns abroad, allowing you to replicate a trained model to Europe/Asia while simultaneously retaining Brazil‑resident training data. We can provide up to 200 Gbps per server, ideal for multi‑region checkpointing and dataset syncs. We have large in‑stock server pools and offer 24/7 support.
How Bare Metal in Brazil Addresses AI Workload Challenges
| AI/ML challenge | How São Paulo’s bare metal helps |
|---|---|
| High compute demand, such as deep nets and large optimizers | EPYC/Ryzen with optional GPUs deliver exclusive, non‑shared compute tailored to training and high‑QPS inference. |
| Massive I/O, for example, streaming features, and checkpoints | Local NVMe + high‑bandwidth NICs (with options up to 200 Gbps in selected sites) keep pipelines flowing without cross‑border backhaul. |
| Low latency/user proximity | Direct peering at IX.br São Paulo shortens paths to Brazilian ISPs/content networks; deterministic RTT results in better UX. |
| Data privacy/LGPD | Processing/storage on dedicated hardware kept in-country helps simplify compliance and reduces the risk of LGPD fines. |
| Rapid demand growth | Planning your capacity against compute trends (~6‑month doubling) plus modular scale‑up/out prevents bottlenecks. |
Deploying Bare Metal in Brazil: Next Steps
Melbicom is gearing up São Paulo data center presence and can support your launch in the near future while delivering advantages that generic providers often don’t: we operate our own network end‑to‑end; we deliver high‑bandwidth options globally; we build custom hardware configurations; and we run as an international remote company designed for speed and flexibility. The result is infrastructure freedom across four dimensions: deployment (place anything, anywhere, at any scale), configuration (customize hardware and network to your stack), operational (no vendor lock‑in or shared tenancy), and experience (simple onboarding with transparent control). Share your traffic volumes, latency SLOs, data‑residency needs, GPU/CPU requirements, and peering preferences; we’ll convert them into a precise, reservation‑backed deployment plan for São Paulo.
Be the first to host in Brazil on special terms
We at Melbicom will help you deploy, customize, and scale infrastructure freely—from AMD EPYC/Ryzen bare metal with optional GPUs to high‑capacity network interfaces and 50+ CDN PoPs you can use immediately. Tell us your volumes, targets, and exact specs so we can shape a tailored early offer and reserve capacity for your launch.
Get expert support with your services
Blog

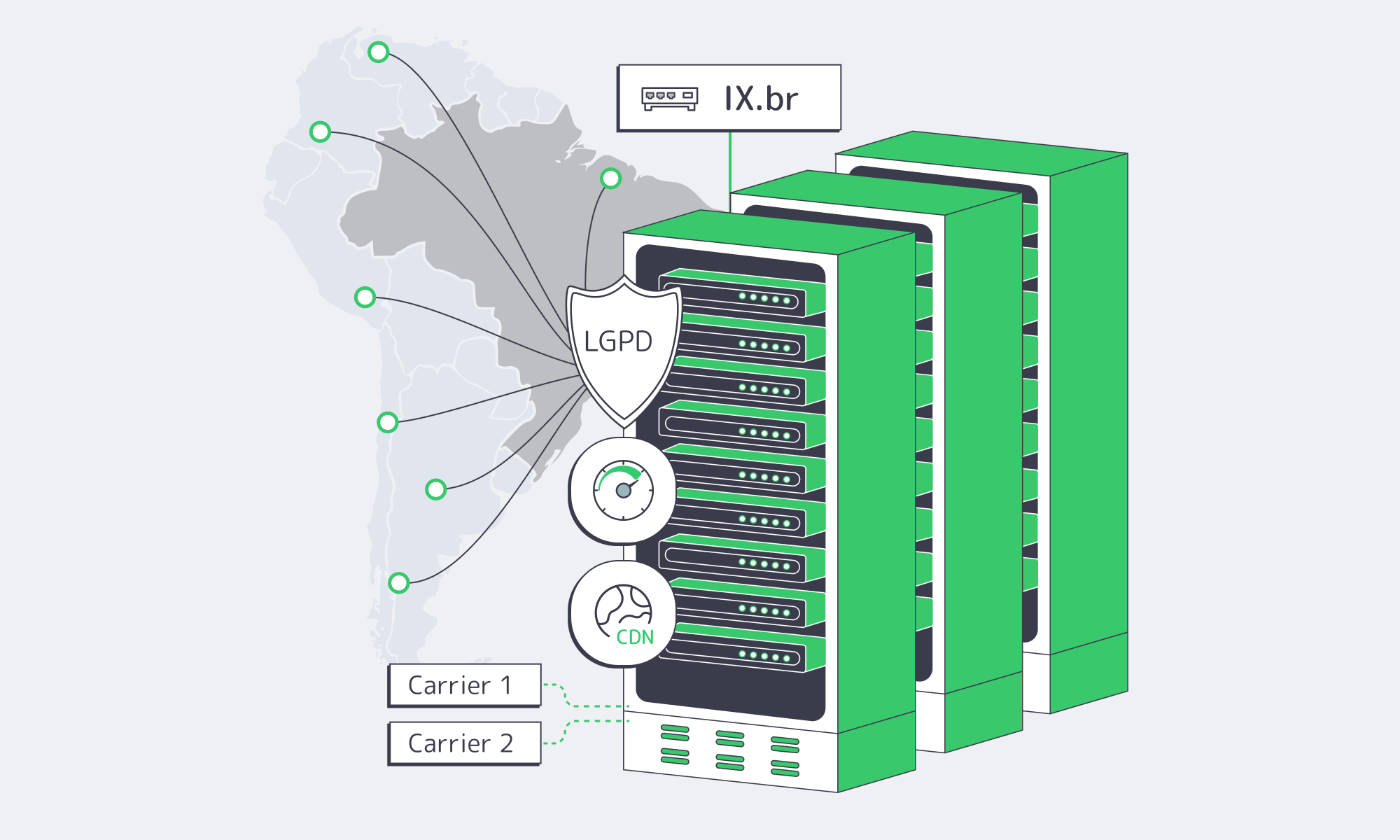
Faster Apps & Easier LGPD Compliance with Dedicated Servers in Brazil
Why Rent Dedicated Servers in Brazil Instead of Serving from Abroad?
The distance penalty is real. Each transoceanic hop adds tens to hundreds of milliseconds to every API call, UI render, fraud check, or video segment fetch. Brazil has roughly ~183 million internet users and internet penetration around ~86%, so even small latency deltas compound into large revenue and engagement impacts at national scale. Hosting application origins on a Brazil dedicated server keeps packets on-net and close to users.
Representative RTTs relevant to Brazil hosting placement

Local vs. cross-Atlantic and to the U.S. East. Local round trips typically stay in the tens of ms.; EllaLink enables fast EU paths; São Paulo↔Miami checks routinely sit ~100 ms.
Two structural factors tip the scales further toward local compute:
- Brazil’s internet exchanges are world‑class. IX.br aggregates dozens of IXPs nationwide, peaking >31 Tbps; São Paulo alone exceeds 22 Tbps and connects >2,400 ASNs, so peering locally shortens paths to the last mile.
- Modern subsea routes reduce overseas detours. The EllaLink system provides a direct EU–BR corridor with <60 ms RTT between Brazil and Portugal—useful for cross-regional services and BCP, but still slower than in‑country origins for Brazilian end users.
Host in LATAM— Reserve servers in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
How Do São Paulo Proximity, IX.br Peering, and Multi‑Homed Transit Cut Latency?
Put your origin where Brazil’s networks meet. In São Paulo, you can peer at IX.br with thousands of ISPs and content networks, keeping traffic local and avoiding trombone routes through distant transit hubs. Multi‑homed upstreams add deterministic performance: one carrier may minimize northbound paths to North America while another optimizes West‑East flows across Brazil; BGP can prefer the best‑performing, lowest‑loss path and fail over instantly on faults. This combination—São Paulo adjacency + IX.br peering + multi‑homed transit—is why a Brazil dedicated server routinely delivers single‑ to low‑double‑digit millisecond experiences nationwide while maintaining resilience against congestion and fiber cuts.
Which Regulatory “Rules of the Road” Are Easier to Meet with In‑Country Hosting?

Brazil’s LGPD and recent ANPD resolutions set clearer guardrails for cross‑border transfers of personal data, including standard contractual clauses (SCCs) and related compliance mechanics. Keeping regulated data in‑country—on a Brazil‑based dedicated server—reduces reliance on SCCs and lowers the risk and overhead of cross‑border flows. In addition, incident rules impose tight notification timelines to the ANPD and data subjects (three business days in certain steps), making local control and observability of your stack a pragmatic choice.
What Does the Market Signal Say About Repatriating Steady Workloads?
As cloud adoption has matured, a record share of CIOs report plans to repatriate some public‑cloud workloads back to private/dedicated infrastructure—driven by cost, performance, and compliance. Recent Barclays data pegs repatriation intent in the low‑80s percent range—the highest on record—with storage and databases among the most‑moved workloads. In parallel, spending expectations on public cloud remain high, underscoring a pragmatic hybrid reality rather than a single‑stack dogma.
How Does TCO Look When You Shift Origin Compute to a Dedicated Server in Brazil?

Three cost levers dominate: always‑on compute, egress, and control overhead. Dedicated hosts exchange variable instance pricing for fixed monthly economics and large, predictable bandwidth allocations—attractive when origin traffic and job queues run 24/7. You also reclaim hardware‑level tuning (I/O, NUMA, storage layout) and no noisy‑neighbor penalties, which stabilizes tail latency without over‑provisioning. For global platforms with Brazilian user concentrations, the combination of lower RTTs (fewer retries, faster TLS/HTTP waterfalls) and fixed‑rate bandwidth can materially reduce both SLO breaches and monthly infra volatility.
Local vs. remote origin for Brazil (at a glance)
| Hosting Location | Typical Latency for Brazilian Users | Data Sovereignty & Compliance |
|---|---|---|
| Remote Cloud (US/EU) | ~100 ms+ RTT (e.g., São Paulo↔Miami ≈106 ms) | Cross‑border transfers require SCCs and added LGPD controls |
| Local Dedicated Server (BR) | Tens of ms within Brazil | Data stays in BR; fewer cross‑border obligations |
Sources for representative values: WonderNetwork pings and ANPD/Trade.gov summaries.
The Pragmatic Migration Path from Hyperscale Cloud to Dedicated Servers
You don’t need a “big bang.” Migrate with deliberate, low‑risk steps that preserve uptime and auditability:
- Stand up a parallel origin in São Paulo. Choose a dedicated server in Brazil sized for your peak request/second and storage IOPS profiles. Establish site‑to‑site VPN or private interconnect to your cloud VPC to sync data and logs.
- Replicate state methodically. Bulk‑load historic datasets over high‑bandwidth links (or offline media if needed); then switch to near‑real‑time streaming for deltas. Multi‑homed transit and IX.br peering will keep sync jitter low.
- Cut over with your CDN. If you already run CDN edges in Brazil, point them to the new São Paulo origin and ramp traffic with weighted DNS or header‑based routing. Cache‑hit traffic moves first; dynamic traffic follows after SLO burn‑in.
- Retain a thin cloud footprint. Keep object storage, backups, or DR replicas in the cloud while production origin sits on a Brazil based dedicated server. This avoids lock‑in while giving you regional autonomy.
The Operating Model: MSAs, Remote Management, and a 24/7 NOC

MSAs. With dedicated hosting in Brazil, you contract directly for the outcomes that matter—data location, support scope, hardware replacement windows, access controls, log retention, and peering policy. A well‑drafted MSA clarifies who can access what (and from where) and how incidents are handled under LGPD.
Remote management. Dedicated servers in Brazil shouldn’t mean hands‑on‑keyboards in a cage. Expect IPMI/KVM for full out‑of‑band control so your SREs can reimage kernels, manage firmware, or capture consoles without a truck roll.
24/7 NOC. Network‑aware ops is non‑negotiable for low‑latency applications. Look for round‑the‑clock support with hardware replacement SLAs measured in hours and engineers who understand BGP, peering, and routing health—because a fast origin is only as reliable as the path to it.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
Latency and Compliance in Brazil: the Bottom Line
Placing origins on a dedicated server in Brazil—ideally in São Paulo with IX.br peering and multi‑homed transit—delivers the fastest user experience your stack can realistically achieve in the country. Traffic takes direct, local paths to last‑mile ISPs; dynamic requests no longer backhaul across oceans; and packet loss variability drops with fewer long‑haul segments. For regulated workloads, keeping personal data within Brazil simplifies LGPD posture and avoids much of the SCC overhead that accompanies cross‑border data transfer. The commercial signals point the same way: many technology leaders are re‑balancing steady workloads toward dedicated or private infrastructure to regain cost control and performance predictability.
Enabling Fast, Compliant Dedicated Server Launches in Brazil
Melbicom is preparing data center presence in São Paulo and is collecting early‑access demand for dedicated servers. Until go‑live, we can stage your Brazil launch using the same architecture we’ll deliver at turn‑up: IX.br peering plans, multi‑homed transit, and in‑country data handling aligned to LGPD—fronted today by Melbicom CDN nodes across South America. At cutover, we shift the origin to São Paulo via a controlled migration. Unlike others, Melbicom operates its own global network, offers high‑bandwidth options (up to 200 Gbps per server, where supported) and custom hardware almost anywhere, and runs a 24/7 NOC with IPMI/KVM and BGP/BYOIP readiness. Share your traffic volumes, compliance needs, and hardware/network specs now; we’ll reserve capacity and return a Brazil‑ready design.
Dedicated Hosting in Brazil, Made Flexible
- Deploy fast: We’re collecting detailed requirements now (traffic profiles, IX.br peering needs, carrier preferences, rack‑level constraints) to pre‑stage capacity and shorten activation windows at launch. Our 24/7 NOC and remote‑hands workflows are already in place to support first installs and early production.
- Customize freely: Specify CPU/RAM/NVMe/GPU mixes, NICs, and storage layouts; request BGP/BYOIP and routing policy; define private L2/L3 overlays. Melbicom’s global baseline includes per‑server bandwidth up to 200 Gbps (location‑dependent); we’ll bring the same performance mindset to São Paulo at go‑live.
- Operate globally: Keep a consistent operating model across Melbicom’s 21 Tier III/IV DC footprint and a CDN in 55+ locations. Build once (automation, monitoring, IaC), then roll out in Brazil without re‑tooling. Our own network means predictable routing and the ability to engineer paths—not just rent them.
- Control TCO: Fixed‑price dedicated servers with generous bandwidth allocations reduces egress shock and keeps costs legible for steady workloads. Use CDN edges in LATAM today to cut cross‑border traffic; shift the origin to São Paulo at launch to minimize long‑haul dependencies.
- Engineer for resilience: Pre‑plan IX.br peering, map multi‑homed transit (at least two upstreams), define failure domains, and codify playbooks with the 24/7 NOC. Remote management (IPMI/KVM) and hardware replacement procedures are standard, so operational recovery doesn’t hinge on local hands.
- Experience freedom: Simple onboarding, clear MSAs, transparent control surfaces, and access to network engineers—not ticket ping‑pong. We’re structured for no vendor lock‑in and no shared tenancy on your compute.
Be the first to host in Brazil on special terms
Share your traffic and hardware needs to reserve São Paulo capacity. We’ll follow up with launch timelines and options for peering, transit, and compliance.
Get expert support with your services
Blog
BGP Multi-Homing: Reliability, Control, and Speed
Industry benchmarks still cite average losses near $5,600 per minute—a 2014 Gartner figure that remains a touchstone for risk planning. A single ISP outage can take entire application stacks dark, as seen during the August 30, 2020 CenturyLink/Level(3) incident that knocked out ~3.5% of global Internet traffic for several hours. Multi‑homing with BGP is the antidote: connect to multiple ISPs, let the border gateway protocol decide the best path, and fail over automatically when a path breaks.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — BGP sessions with BYOIP |
|
What is BGP Multi‑Homing and Why Does It Matter for Reliability?
BGP multi‑homing means advertising your IP space to two or more upstream ISPs and receiving routes from each. When a provider fails, BGP withdraws the bad path and traffic shifts to the surviving ISP—no manual changes, no DNS TTLs to wait out. In steady state, you can use both links actively for load sharing, favor destinations by cost or latency, and shape inbound paths with policy (local‑pref, MED, AS‑path prepends, and communities). The result is resilience + control that single‑homed links simply don’t provide.
A core advantage over “backup‑only” designs: multi‑homed BGP isn’t idle capacity. With the border gateway routing protocol, you can keep links hot—for example, prefer ISP‑A to western Europe while favoring ISP‑B to East Asia, or send bulk backups over the cheaper link while keeping real‑time flows on the lower‑jitter path. Policy lives on the router, not in ticket queues.
How Does Border Gateway Protocol Routing Make Multi‑Homing Work in Practice?
At the edge, you run eBGP to each provider, announce your public prefixes, and ingest either full tables or defaults (depending on router scale). For outbound control, you set local preference to favor one ISP or split by destination. For inbound control, you influence the outside world’s choice of path using AS‑path prepending, selective advertisement of more‑specifics (where registries and filters allow), and BGP communities that request provider‑side action (e.g., de‑prefer with certain carriers). This is why multi‑homing with the BGP is as much policy engineering as plumbing.
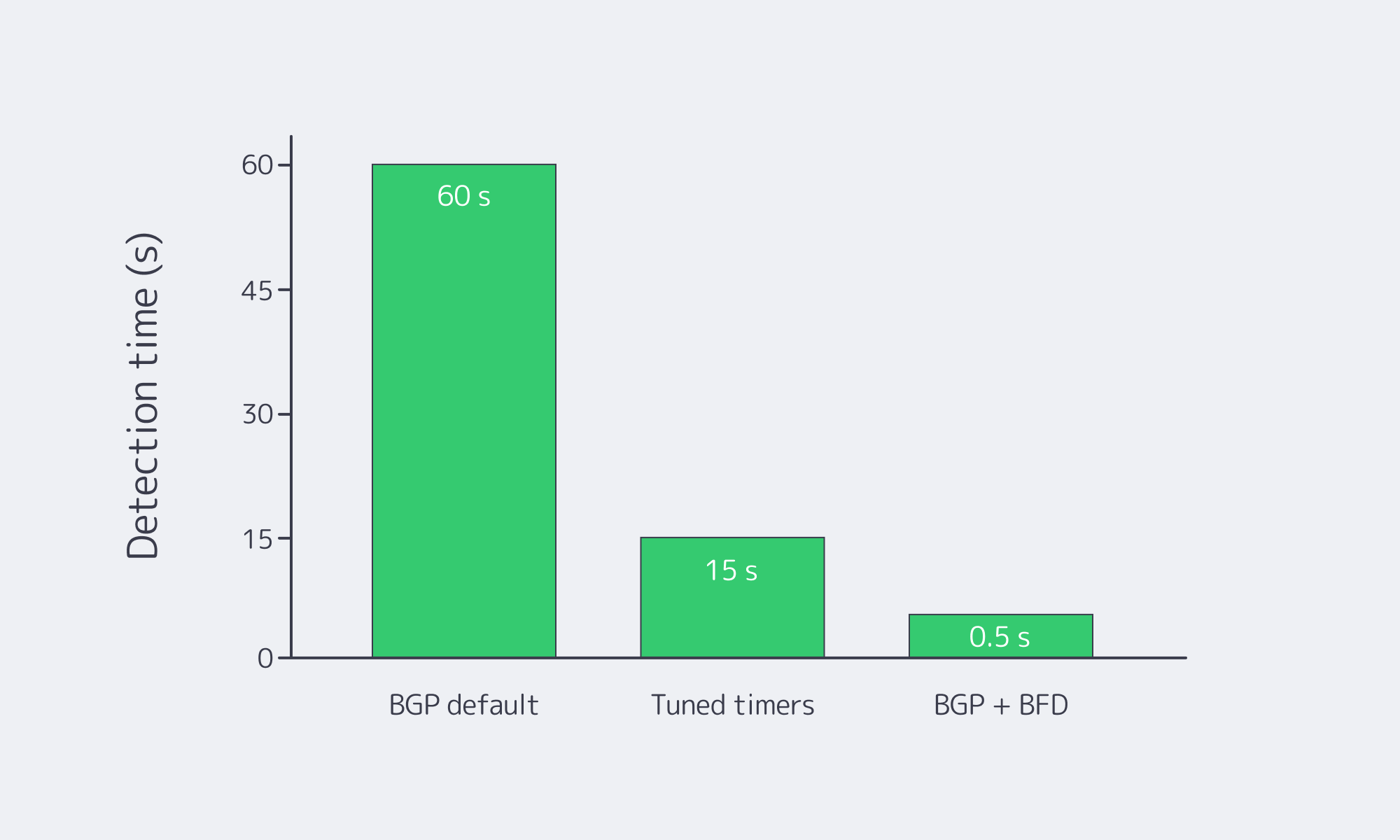
Can BFD make failover essentially instant?
By default, BGP prioritizes stability, so neighbor‑down detection can be slow with conservative timers. Pairing BGP with Bidirectional Forwarding Detection (BFD) changes that. BFD runs millisecond‑level heartbeats at the forwarding plane and signals BGP to tear down sessions immediately upon failure, yielding sub‑second reconvergence in well‑tuned networks—documented directly in border gateway protocol Cisco references (“the main benefit of implementing BFD for BGP is a significantly faster reconvergence time”).
In practice, most teams combine modestly aggressive BGP hold timers with BFD for the truly fast link‑or‑node‑dead cases.
Which Uptime Gains Can You Expect from a Dual‑Provider Design?
If each ISP averages ~99.9% availability, the chance of both failing at once—assuming diverse paths and providers—is very small. Real‑world deployments regularly reach 99.99%+ effective uptime with two independent links. The table illustrates expectations:
| Network Setup | Typical Uptime (Annual) | Approx. Downtime/Year |
|---|---|---|
| Single ISP (business‑grade) | ~99.9% | ~8.8 hours |
| Dual ISP BGP multi‑homing (independent providers) | 99.99% or higher | < 1 hour (often just minutes) |
Two caveats keep those numbers honest:
- Independence matters. Avoid shared last‑mile ducts, common meet‑me rooms, or the same carrier resold by two brands.
- Failover speed matters. BFD‑assisted convergence turns hard outages into a blip rather than a multi‑minute event.
What Do You Actually Need to Deploy?
A minimal, production‑ready border gateway protocol configuration for multi‑homing has just a few prerequisites:
- Resources: Your ASN and a routable prefix (e.g., IPv4 /24, IPv6 /48).
- Edge device: A router that can run eBGP (hardware or a hardened VM running BIRD/FRR) sized to the route load you’ll ingest.
- Two (or more) carriers: Contracts and cross‑connects to diverse ISPs, plus IRR/RPKI hygiene so they’ll accept and propagate your prefixes.
- Policy & safety rails: Local‑pref for outbound, a simple inbound plan (prepending/communities), strict prefix‑limits and filters, and (ideally) BFD on the peering links.
Where Melbicom’s Multi‑Carrier Network Adds Practical Value
Melbicom operates a multi‑homed backbone with transit from many Tier‑1/Tier‑2 carriers and broad IXP reach across the US and EU. That upstream diversity—paired with capacity measured in double‑digit terabits per second—lets traffic take clean paths and shift quickly if a carrier stumbles. Melbicom’s catalog includes 14+ Tbps backbone capacity, 20+ transit providers, and 25+ IXPs, plus 55+ CDN locations to cache static assets closer to users.
From a deployment standpoint, we at Melbicom make BGP multi‑homing straightforward:
- BGP sessions anywhere: Free BGP on dedicated servers and available for a nominal add‑on on VPS, with BYOIP, IPv4/IPv6, and full/default/partial route options.
- Inbound control that scales: BGP communities (including passthrough to upstreams) for de‑preferencing, selective advertisement, and region‑tailored announcements—without bespoke tickets.
- Route integrity by default: RPKI‑validated routing and strict IRR filtering to reject invalids and keep the table clean.
- Capacity when you need it: Per‑server ports up to 200 Gbps in select sites—useful when a failover concentrates traffic on the surviving path; recent location pages confirm 1–200 Gbps options).
- Faster time to value: With 1,300+ dedicated servers in stock and 24×7 support, Melbicom’s team can raise your session, validate IRR/RPKI entries, and help with policy tuning so BGP does what you intend—before you hit production.
If you prefer starting smaller, VPS with BGP delivers the same peering semantics—use a virtual router (BIRD/FRR), ingest defaults or partial routes, and announce your prefixes via a paid VPS BGP session, upgrade to dedicated later as traffic grows.
How Does This Compare to Single‑Homed Connectivity?
Single‑homed Internet links are both simpler and brittle: one circuit, one provider, one control plane. Mean‑time‑to‑repair is outside your control, and even “five‑nines” promises don’t help if a control‑plane blunder propagates bad routes or a fiber cut isolates your facility far from your data center.
By contrast, multi‑homed border gateway protocol routing gives you two levers:
- Availability: If ISP‑A breaks, instant failover to ISP‑B keeps flows alive (especially with BFD‑assisted convergence).
- Performance economics: Prefer lower‑latency or lower‑cost paths by policy; shape inbound traffic using communities and prepends instead of asking the world to change for you.
Quick Answers to Common Questions
- Is BGP difficult? The concepts are simple; the risk is in sloppy filtering. That’s why RPKI + IRR and strict prefix‑limits matter.
- Do I need full tables? Not necessarily. Many edge routers run default‑only or partial routes from each ISP and achieve excellent results with far lower memory/CPU.
- Will I need vendor‑specific wizardry? No. While syntax differs, border gateway protocol configuration principles are consistent across stacks.
- What about brownouts (congestion/packet loss) rather than hard failures? BGP reacts to reachability. You can layer telemetry‑driven policies (or scheduled community changes) to steer around soft faults.
Key Takeaways Before You Architect
- Multi‑homing eliminates single points of failure. With two truly independent ISPs, you move from ~99.9% toward 99.99%+ effective availability.
- BFD makes a failover feel “instant.” Sub‑second detection + BGP withdrawals turn hard outages into a blip; use moderate BGP timers plus BFD.
- Use policy, not hope, to shape flows. Local‑pref for outbound, communities/prepends for inbound; keep it simple and measurable.
- Design for diversity. Separate carriers, paths, and POPs. The 2020 incident shows why relying on a single upstream is risky.
- Leverage providers that “speak BGP.” Melbicom offers free BGP on dedicated servers + BYOIP, RPKI/IRR, and communities passthrough—accelerating adoption without overbuilding.
Elevate Uptime and Control with BGP Multi‑Homing

The Internet is resilient in aggregate but fragile in parts. A fiber cut or routing misconfiguration far from your data center can still remove your sole path to users. BGP multi‑homing replaces hope with engineering: multiple providers, policy‑driven border gateway protocol routing, and BFD‑assisted convergence that turns failures into non‑events. The economics pencil out quickly; preventing a single hours‑long outage can pay for a second ISP many times over.
If you’re modernizing connectivity for globally distributed apps in the US and EU, start with architecture, not vendors: diverse carriers, simple policies, tight filters, and the shortest possible failure‑detection loop. Then choose a platform that makes those choices easy to implement—and easy to run at scale.
Run BGP multi‑homing with Melbicom
Get carrier‑grade reliability with multi‑homing. Free BGP on dedicated servers, BYOIP support, RPKI/IRR filtering, and communities passthrough. Our team helps you configure sessions and tune policies fast.
Get expert support with your services
Blog
Brazil Unmetered-Port Servers and CDN for Boosting Conversions
The online economy in Brazil has seen a substantial surge in the last few years, which will only continue with revenue projections for retail e-commerce of around US$36.3B and a widely addressable market of approximately 94M online shoppers. The high-traffic stores and video platforms are bandwidth‑heavy and subject to spikes, especially in the cases of flash‑sale checkouts and live premiere streams. When your site traffic multiplies in minutes, the infrastructure needs to be able to cope. An infrastructural blueprint to facilitate the demands would be the following: unmetered ports on dedicated servers at local Brazilian origins that can be autoscaled by simply adding additional nodes and edge cache via a CDN with PoPs in South America. If well executed, even volatility can still spell revenue; you have faster checkouts and higher stream start rates, which equate to fewer abandons.
Host in LATAM— Reserve servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
Low Latency Dedicated Server Hosting in Brazil for Better Conversion Rates
Physical infrastructure distance adds delay. Typical trans‑oceanic round‑trip times can exceed 100 ms because physics (speed of light in fiber ≈ 200,000 km/s, ~4.9 µs/km) sets a hard baseline and real networks add additional overhead. By hosting your origins within Brazil, you can shave hundreds of milliseconds from user paths compared with serving São Paulo from North America or Europe. Google has reported that bounce probability rises by 32% as page load time increases from 1s to 3s, and video studies show that viewer abandonment rises by about 5.8% per additional second when startup is delayed beyond 2s. Fortunately, these revenue leaks can be closed by addressing the infrastructural locality.
How Much Unmetered Bandwidth Do 1/10/100+ Gbps Ports Deliver?
By opting for an unmetered port, you aren’t limited by a monthly GB quota, which means no egress overages from any spikes from a sudden viral promotion or premiere. The port is the limit, and the scale is easily quantifiable:
| Port speed (unmetered) | Max transfer/month* | Approx. concurrent 1080p streams |
|---|---|---|
| 1 Gbps | ~324 TB | ~200 |
| 10 Gbps | ~3.24 PB | ~2,000 |
| 100 Gbps | ~32.4 PB | ~20,000 |
| 200 Gbps | ~64.8 PB | ~40,000 |
The above table is calculated on the assumption of a 30‑day month, 24×7 full utilization, ~5 Mbps per 1080p stream.
With the headroom offered by an unmetered port, e‑commerce stores won’t suffer from uplink saturation during peak checkouts, and tens of thousands of HD streams per node group can stream without the network being throttled. You also have the bonus of a predictable flat‑rate price for your bandwidth, and rest assured that a successful launch won’t incur the egress seen with per‑GB cloud operation.
Revenue‑Focused Planning for Dedicated Hosting in Brazil
When sifting through cheap dedicated server Brazil offers, you should look beyond the price alone and consider the total cost of performance:
- Place origins in‑region to minimize round‑trips for dynamic calls (cart, auth, APIs) and initial stream manifests.
- Provision unmetered ports sized to peak—start with 10 Gbps, and if your daily peaks hit multi‑Gbps scale to 40/100/200 Gbps with your audience.
- Offload everything cacheable to a local CDN to free up the origin to focus on compute and cache misses.
- Autoscale horizontally with a design that allows you to bring additional nodes online rapidly as traffic climbs.
Which workload economics and use cases justify 100–200 Gbps per server?
Video makes up an estimated 82% of global consumer traffic; with that in mind, pragmatic planning is a requirement, not an extravagance:
- For OTT premieres and live events: Thousands to tens of thousands of concurrent FHD/UHD sessions per port tier with AV1/HEVC playback for better efficiency.
- High‑SKU storefronts with rich media: Having a 10–40 Gbps pipe helps for product detail pages with multiple images and video during campaigns.
- Moving large data: 40/100 Gbps links reduce times for nightly replication, object store rebalancing, and preload jobs completion, which reduces maintenance windows.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
Proving Revenue Impact
Financially speaking, two performance levers carry boardroom weight:
- Millisecond conversion: Speed moves revenue as observed by Amazon, which found that every +100 ms of latency costs ~1% of sales.
- A slow start loses the viewer: Studies show a rise in abandonment when the startup exceeds 2s, with 5.8% per additional second.
Shave RTTs, cut startups, lift conversions, and engagement by tying the above performance levers to local‑origin plans.
Autoscaling without Cloud Lock‑In

Autoscaling on dedicated servers is easy, provided the architecture is correct:
- To scale horizontally: App tiers should be kept stateless behind a load balancer to scale out with additional nodes, either reserved, on‑hand, or provisioned from inventory. They can then be added to the pool in moments through containerization and automation.
- For traffic distribution: Steer traffic to the least-loaded or nearest node via anycast/geo‑DNS.
- Scaling stateful layers: Leverage read replicas, partitioning, or distributed SQL for databases and segment writes where necessary.
- Automation & SLO‑based triggers: Monitor CPU, RPS, p95 latency, port utilization, and let telemetry trigger scripted capacity addition for known peaks such as drops, sales, or hot title premieres.
CDN in Brazil: Why Edge Caches Matter
While a local origin speeds processes to compress user-perceived distance, edge caching plays a crucial role. Melbicom has an extensive CDN that spans 50+ PoPs in 36 countries with South American edges in São Paulo, Buenos Aires, Santiago, Bogotá, Lima, among others. That allows you to serve up cacheable assets such as product images, JS/CSS, thumbnails, HLS/DASH segments from the nearest PoP, letting your origin deal with dynamic and cache misses, resulting in faster first paint and startup, higher cache‑hit ratios, and lower origin egress/CPU—especially during flash crowds.
Moving playlists and segments to the CDN helps with video workloads, and setting strong cache‑control and using Brotli/HTTP‑2/TLS 1.3 at the edge helps with heavy lifting on the web. All of which works to keep your origin focused on transactional logic.
Rollout Checklist for Dedicated Server Hosting in Brazil

- Baseline measurement: Record current RTT from Brazilian metros to your existing origins and compute peak Mbps/Gbps needs for checkout and playback using 1080p ~5 Mbps / 4K ~15 Mbps as a sizing guide for streaming peaks.
- Choose a Brazilian data‑center footprint: Prioritize proximity to São Paulo and make sure upgrade paths from 1/10 Gbps to 100/200 Gbps per server.
- Deploy origins and harden: Tune stacks for latency. Secure transport and enable observability.
- Wire up CDN PoPs in Brazil and across South America: Cache your static assets, thumbnails, and HLS/DASH segments. Confirm cache‑hit ratios before launching.
- Engineer to autoscale: Keep stateless app tiers behind load balancers and use a scripted add‑node flow based on telemetry to bring additional servers online at peak.
- Optimize: Compress, minify, lazy‑load, and use adaptive bitrate ladders.
- Load‑test: Validate NIC utilization, CPU headroom, and CDN offload with Brazil‑sourced traffic at peak and pre‑approve upgrades to 10/40/100 Gbps if tests approach saturation.
- Instrument business KPIs: keep track of LCP/TTFB/startup time vs. conversion/engagement in Brazil and publish weekly infra‑to‑revenue dashboards.
Conclusion: Building for Locality, Bandwidth, and Freedom
Brazil is best served by a plan that marries locality (origins in‑country), capacity (unmetered 1/10/200 Gbps ports sized to peak), and distribution (Brazil‑centric CDN caches) with pragmatic autoscaling via additional nodes. That combination reduces round‑trips, prevents uplink saturation during surges, and converts traffic spikes into revenue—faster checkouts, quicker video starts, steadier retention. While we finalize local dedicated‑server capacity, we at Melbicom can support your launch in the near term: stage the architecture on our existing global 21-DC footprint, front it with our South American CDN PoPs, and pre‑provision hardware/network profiles so your move to in‑country origins is a switch‑flip, not a rebuild.
Unlike typical providers, Melbicom is built around Infrastructure Freedom. In practice, that means deployment freedom (run anything, anywhere, at any scale), configuration freedom (tune hardware and network to your spec), operational freedom (own the stack end‑to‑end), and experience freedom (straightforward onboarding and clear controls). Share your targets; we’ll shape a build that matches them exactly and transitions cleanly to local Brazil capacity as it comes online H1 2025.
Be the first to host in Brazil on special terms
Tell us your peak traffic volumes, target port speeds, bitrate, cache rules, regions, and exact hardware/network specs—and we’ll return a tailored rollout plan with early‑placement options and South America CDN acceleration from day one.
Get expert support with your services
Blog

Hybrid Wins: Cost, Control, Performance In Atlanta
The cloud is easy to start with, but costs can rise quickly and performance can fluctuate. The modern question isn’t “cloud or not,” but “what runs best where.” Dedicated server hosting in high‑connectivity hubs such as Atlanta has evolved into a predictable, high‑performance alternative to multi‑tenant cloud.
Below, we focus on cost, control, and performance—and show why a hybrid strategy anchored in Atlanta dedicated server hosting often proves highly effective.
Choose Melbicom— 50+ ready-to-go servers in Atlanta — Tier III-certified ATL data center — 55+ PoP CDN across 6 continents |
|
Why Are Teams Re‑Evaluating All‑Cloud Strategies?
Current planning is dominated by two realities: spend uncertainty and performance variability. Across enterprises, cloud spend governance remains the top challenge, and multi‑cloud complexity has become the norm. Independent surveys indicate organizations self‑estimate roughly 30–32% of cloud spend as waste—idle or abandoned capacity, over‑provisioned instances, forgotten services, and egress surprises.
Simultaneously, hard figures have made a hole in the myth that clouds are always less expensive. Free surveys indicate that organizations are self-estimating cost on their cloud wastages at about three times their cloud costs abandoned capacity trees, over provisioned instances, forgotten services and egress surprises. And there are top-notch examples of firms reclaiming spending through the transfer of steady workloads off public clouds. Dropbox reported nearly $75 million in infrastructure savings over two years after repatriating substantial storage from the public cloud. 37signals projects about $10 million in savings over five years (~$1–2 million per year) from moving remaining workloads off the public cloud.
The next phase of architecture movement is practical: hybrid. Organizations embrace a right fit model – have elastic or experimental scales in the cloud, but fix steady, bandwidth intense, or provide very low latency loads to dedicated servers. Polls indicate that hybrid/ multi cloud is the new reality: 88% of those who purchase clouds are or run hybrid clouds.
What Makes Atlanta a Strategic Hub for Dedicated Infrastructure?
Density and reach. Atlanta hosts 140+ data centers, with key interconnection at 56 Marietta Street (Digital Realty ATL13), the Southeast’s largest carrier hotel with hundreds of networks. The mesh provides low‑tens‑of‑milliseconds paths to the East Coast, Midwest, and Latin America, with abundant options for private and public peering.
Economics. Georgia’s commercial electricity rates are in the low‑teens cents per kWh, a structural advantage that translates into competitive server pricing. The region is growing rapidly: hyperscalers are expanding, and AWS has announced at least $11 B of new DCs in Georgia to meet cloud and AI demand. That development is the foundation of extended network and supply chain robustness that could be tapped by committed clients.
Melbicom in Atlanta. Melbicom operates a Tier III Atlanta facility with 1–200 Gbps per‑server connectivity and a 14+ Tbps global backbone. Provisioning is fast—ready‑to‑go servers can be online within hours—and component replacement is completed within 4 hours, with free 24/7 technical support. Additional options include BGP sessions and private networks for advanced routing.
Costs Compared in Practice
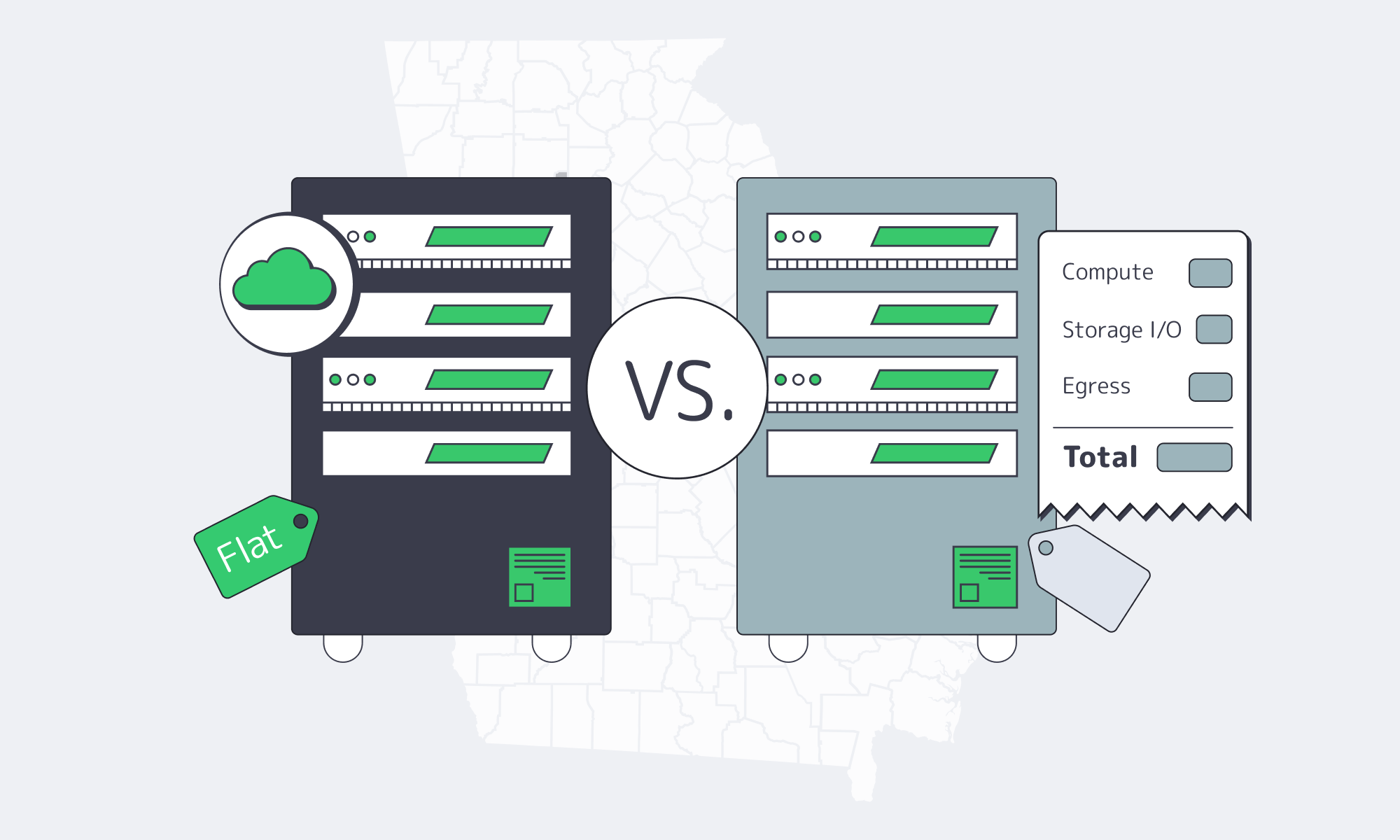
A spiky workload suits the cloud, whereas steady 24/7 loads are penalized as CPU, storage, and especially egress rack up line items. Because dedicated resources are reserved, dedicated servers flip the equation: pricing is predictable, and generous or unmetered transfer often neutralizes egress shocks. The outcome is proper budgeting and a reduction of what just happened scenarios where traffic goes crazy.
The macro picture matches what finance sees on invoices: cost management is the top cloud challenge, and roughly one‑third of spend is waste without disciplined FinOps, whereas dedicated servers enable deliberate capacity planning—you right‑size, run hot as needed, and aren’t charged extra when more users show up.
Case evidence: Dropbox saved $75M and 37signals wrote a series titled ‘We Left the Cloud’ is an illustration of the consistent workloads which is advantageous to owning or renting dedicated capacity. To most teams, an Atlanta dedicated server is the cost anchor: 24/7 throughput is flat and cloud means automatically the elasticity is a pay-off.
Cost model at a glance
| Cost factor | Public cloud (on‑demand) | Dedicated server (Atlanta) |
|---|---|---|
| Pricing model | Per hour compute, storage I/O, egress. Bills vary with consumption. | Highly desired CPU/RAM/Storage, flat monthly; immensely high transfer |
| Scalability vs. cost | Elastic but scale linearly with peak demand; bill spikes potential. | Fixed capacity at a fixed monthly price; no per‑use bill spikes within your port limits. |
| Bandwidth charges | Egress is usually $/GB; high transfers prevail. | No per‑GB charges within plan; often unmetered or high‑quota transfer included. |
| Long‑term TCO | Economical in short lived or infrequent activities; expensive in 24/7 base load | Lower TCO when the workload remains constant; easier monthly budget planning. |
Dedicated Servers: Consistent Performance
On cloud instances, you share the physical host with other tenants, which can introduce variability. This phenomenon is extensively studied in literature and in trade knowledge bases and still presents a source of variation even with mitigation done by the providers.
With a dedicated server, there is no other tenant—100% of the CPU, RAM, disk, and NIC capacity are yours, eliminating hypervisor‑level contention and burst‑credit throttling. In high throughput pipelines, training jobs, high throughput pipelines or large streamers, that consistency can have a better value than the theoretical burst of a cloud VM. In Atlanta specifically, Melbicom offers 1–200 Gbps per‑server ports, providing far higher line‑rate headroom than typical VM tiers.
Dedicated Servers: Greater Control and Customization
The advantage of clouds is abstraction, and the disadvantage is a lack of control over the underlying stack. You can’t tune firmware settings, choose specific RAID topologies, or attach hardware outside a cloud provider’s catalog. With dedicated servers, you are in control of the environment, the OS, kernel parameters, storage layout and network stack. Need BGP to announce your own prefixes or private L2 between nodes? Melbicom assists with those scenarios while handling the heavy lifting (remote hands, component swaps, facility operations).
Specificity matters: a Tier III facility in Atlanta, GA with defined access policies and physical security controls is easier to attest than an abstracted cloud region. Regulated data or deterministic forensics to regulated data or deterministic forensics, it is often the case that this specific machine in this specific building becomes the short route to green light.
Hybrid Deployments: Combining Cloud and Atlanta Dedicated Servers?

The sensible middle ground Hybrid, stack your elastic, event driven bits in cloud; Pin steady baseload -databases, origin servers, batch engines -on Atlanta dedicated servers, flat cost and predictable performance. It has become a thing: the use of multi clouds is almost universal and hybrid implementations are indicated by the vast majority of buyers.
Atlanta plays both a technical and geographic role: interconnection at 56 Marietta enables cross‑connects to carriers, CDNs, and cloud on‑ramps, and the metro’s fiber mesh reaches the Southeast and East Coast in low‑tens‑of‑milliseconds. The global CDN (55+ PoPs) of Melbicom allows pinning an Atlanta dedicated server as the origin and pushes the content closer to users all over the world.
Which Should You Choose: Dedicated Servers or Cloud?
Architecture to workload reality: Use this checklist to balance architecture to workload:
- Workload profile & predictability. 24/7 continual demand → support Atlanta dedicated server hosting due to cost/TCO, sudden/short-term → cloud.
- Budget control. Require flat and predictable OPEX and no egress surprises? Dedicated fits. Cloud demands aggressive FinOps lest it run out of control; the most reported issue is spend control.
- Performance sensitivity. Throughput‑bound or latency‑critical systems (real‑time analytics, trading, MMO backends, media origin) prioritize single‑tenant consistency over multi‑tenant burst. Risk of noisy neighbor effects tilts toward dedicated.
- Geography. Atlanta dedicated server placement offers advantages to users in the southeast of the U.S.; the 56 Marietta backbone has more variety to further path selection to the larger ISPs.
- Control & compliance. Seeking firmware level tuning, custom network or more restrictive data residency? Dedicated. Melbicom facilitates BGP, private network and full control of an OS in a tier III Atlanta location.
- Long‑term economics. In the case of baseloads, the example given by Dropbox and 37signals indicate sustained savings in making the transition off of on demand cloud to owned/rented capacity.
Balancing Cloud Elasticity with Atlanta’s Dedicated Server Predictability

The pay as you go concept of the cloud is indispensable- test it, short lived loads, and especially, global managed services. There is no change in the economics or physics of compute, though: stable, bandwidth intensive, and latency sensitive systems are cheaper and more stable when running on the hardware alone. That’s why the strongest architectures today are hybrid, with Atlanta dedicated servers anchoring baseload capacity and the public cloud providing on‑demand elasticity. The outcome would be budget predictability, head room of performance, and control over operations- without compromising agility that the teams would require.
Atlanta adds to those profits. The intensive connection network, competitive power economy, rich carrier options, and extensive support ecosystem has meant that you will be able to locate compute in any place it will be of the most benefit to your users. And Melbicom completes the puzzle with the missing components—Tier III facility standards, fast provisioning, and a backbone built for high throughput—so you aren’t trading convenience for control.
Deploy Atlanta Dedicated Servers
Order high‑bandwidth dedicated servers in Atlanta with fast setup, 24/7 support, and BGP options for predictable cost and consistent performance.
Get expert support with your services
Blog
Why UAE Hosting Delivers Speed, Compliance, and Scale
Enterprises serving customers across the Gulf now face a simple infrastructure question with complicated consequences: where should the origin servers live? For years, many hosted in Europe or North America and absorbed the cost of distance—triple‑digit‑millisecond round trips and cross‑border data exposure. Between London and Dubai alone, typical latency hovers around ~130 ms. Today, a dedicated server in the UAE places compute inside the region’s network core, aligning with data‑residency rules and delivering ultra‑low latency for fintech, e‑commerce, AI inference, streaming, and collaborative apps. This is no incremental tweak; it’s the difference between “fast enough” and instant—and between “legally acceptable” and locally compliant.
Choose Melbicom— Dozens of ready-to-go servers — Tier III-certified DC in Fujairah — 55+ PoP CDN across 6 continents |
|
Why Are Digital Demands in the Middle East Surging?
Two secular shifts define the region’s new reality. First, digital consumption and online commerce are exploding; Deloitte estimates Middle East e‑commerce will reach roughly US$50 billion in the near term, propelled by mobile adoption and pro‑digital policy. Second, data center capacity is ramping hard: PwC projects regional capacity to triple—from ~1 GW to ~3.3 GW—over five years, driven by cloud, AI, and sovereign data strategies. In other words, the demand side (users, transactions, streams) and the supply side (local compute, power, and interconnects) are meeting in the UAE and its neighbors, making a regional hosting footprint both practical and advantageous.
What Do Strict Data‑Residency Laws Mean for Your Hosting Strategy?
Compliance has moved infrastructure decisions from “best practice” to “must have.” In the UAE, sector rules make the stakes explicit:
- Payments: The Central Bank’s Retail Payment Services and Card Schemes Regulation requires payment service providers to store and maintain personal and payment data within the UAE, with secure backups retained locally.
- Healthcare: The Health Data Law (Federal Law No. 2 of 2019) limits the transfer or processing of UAE health data outside the country except under defined exceptions.
- IoT: The national IoT regulatory policy requires Secret/Sensitive/Confidential data—especially for government or critical infrastructure—to remain in the UAE.
Leading firms summarize the risk plainly: non‑compliance may trigger fines, service suspensions, or even criminal penalties—and cross‑border transfers face stricter scrutiny.
Creating Measurable Advantage via Ultra‑Low Latency

Latency is not an abstraction; users feel it. Human‑factors research shows three crucial thresholds: ~0.1 s feels instantaneous, ~1 s remains flow‑friendly, and >10 s breaks focus—guardrails that translate directly to web and app UX. For revenue‑producing funnels, the numbers are unforgiving: a 100‑ms delay can cut conversions by up to 7%, and 53% of mobile visitors abandon pages exceeding three seconds.
The geography of your origin matters more than any front‑end micro‑optimization. Hosting in Europe or the U.S. keeps round‑trips in the triple‑digit milliseconds for Gulf users (e.g., London–Dubai ~133 ms), whereas a UAE origin collapses that to tens of milliseconds. The regional UAE‑IX exchange (operated by DE‑CIX) keeps traffic local and has demonstrated latency reductions of up to 80% for gaming and interactive content—precisely the workloads most sensitive to jitter and lag.
For industries where milliseconds decide outcomes, the bar is even higher. As DataBank’s Gregory Ryman notes, “Whereas milliseconds were once acceptable, microsecond responses are now required” for trading, payments, and real‑time analytics. AI inference pipelines and personalization engines show similar sensitivity; moving model scoring closer to users reduces tail latency and bandwidth costs, enabling richer on‑page experiences without the penalty of long‑haul calls.
Local UAE Server vs. Overseas Hosting: What changes in practice?
| Factor | UAE Dedicated Server | Overseas Hosting (EU/US) |
|---|---|---|
| Data compliance | Meets UAE localization (payments, health, IoT), keeping sensitive records on UAE soil. | Cross‑border exposure; additional legal burden for transfers and higher penalty risk if localization applies. |
| Latency to Gulf users | Tens of milliseconds via in‑country peering and regional IXs (UAE‑IX). Up to 80% lower vs. out‑of‑region. | 100–200+ ms transcontinental RTT common; sluggish UX under load. |
| User experience | Faster pages and APIs → higher conversions and engagement. | Slower flows → bounce and cart abandonment. |
| Network resilience | Local exchanges + diverse subsea routes keep Gulf traffic in‑region. | Long‑haul dependency raises risk from cable events and congestion. |
| Operational control | Local time‑zone support and auditability under UAE standards. | Remote operations across time zones and jurisdictions. |
What Makes UAE Data Centers Genuinely World‑Class?
Three ingredients: tiered facilities, dense interconnects, and subsea diversity.
- Tiered reliability at scale. The UAE hosts multiple Tier III+ sites, including in Fujairah and Dubai, designed for concurrent maintainability and enterprise uptime.
- A heavyweight Internet core. UAE‑IX (DE‑CIX) now connects 110+ networks and pushes terabit‑scale peaks, keeping content, cloud, and eyeballs local—explicitly to reduce latency and improve experience.
- A cable‑landing powerhouse. Fujairah is the Middle East’s largest subsea landing hub, with systems like AAE‑1, EIG, GBI, SEA‑ME‑WE variants, and the 2Africa mega‑cable adding more diversity via the UAE’s east coast (Kalba). This translates to east‑west path optionality and fast failover when one route degrades.
On top of the physical network, capacity headroom is real. We at Melbicom operate dedicated servers in Fujairah with 1–40 Gbps dedicated port options locally, and per‑server bandwidth up to 200 Gbps in select global locations, with a CDN spanning 55+ PoPs to accelerate static/video workloads outside the Gulf. Free 24/7 support remains standard for dedicated servers.
Why Choose a UAE Dedicated Server Strategy Over “Host Elsewhere and Hope”?

Because distance and jurisdiction now impose hard costs. The UAE offers a rare combination—lawful locality, tens‑of‑milliseconds proximity, and carrier‑dense interconnects—that few offshore options can match for Gulf user bases. The result is not just faster pages; it’s fewer abandoned checkouts, snappier banking flows, and smoother AI‑assisted experiences.
When is dedicated server hosting in UAE non‑negotiable:
- You process regulated data (payments, health, government/IoT), or must prove records stay in‑country.
- You sell or trade in real time (fintech, marketplaces, gaming) where milliseconds—or microseconds—matter.
- Your conversion engine depends on speed (retail, subscriptions, ads), and you can’t afford 100‑ms tax from offshore origins.
- You need scale and resilience with in‑region peering and subsea path diversity—not single‑continent bets.
Where Does the UAE Stand vs. Saudi Arabia and Qatar?
All three markets are modernizing fast and tightening oversight of personal data. Saudi Arabia’s PDPL and sector frameworks (e.g., SAMA) restrict cross‑border transfers and increasingly enforce localization—making in‑KSA hosting advisable for Saudi‑resident datasets. Qatar’s PDPPL also limits transfers and prescribes fines.
What makes the UAE uniquely useful is its function as the GCC interconnect fabric—home to UAE‑IX and Fujairah’s cable landings—so UAE servers serve the wider region with lower latency, even as organizations stand up country‑specific clusters where laws require. Many enterprises therefore adopt hybrid regional topologies: a UAE origin for GCC‑wide proximity and shared workloads, plus in‑country nodes where sectoral laws demand.
Local Infrastructure Has Become Table Stakes
Data sovereignty and user experience are now board‑level issues in the Gulf. The shortest, safest path to both is to run your origin in the UAE—within the jurisdiction that governs your customers and close enough to render the network invisible. With e‑commerce growth, AI‑heavy applications, and payments modernization all accelerating, the performance and compliance dividend from UAE hosting compounds year over year.
The strategic calculus is simple: if your revenue, risk, or reputation depends on speed and lawful processing in the GCC, a UAE dedicated server is no longer optional. It’s the foundation for the services your users already expect.
Deploy a UAE dedicated server
Place your workloads in Fujairah for low latency, local compliance, and carrier‑dense connectivity. Choose from ready configurations and 1–40 Gbps ports, backed by 24/7 support.