Author: Melbicom
Blog
Cheap Unlimited-Bandwidth Dedicated Servers: Avoid Hidden Costs
Infrastructure teams running streaming, gaming, AdTech, or analytics workloads know bandwidth—not CPU—is often the real bill driver. Against that backdrop, offers for a cheap dedicated server with unlimited bandwidth are everywhere. The promise is simple: a flat monthly fee, “unlimited” traffic, and instant savings over metered cloud egress. The reality is often less pretty: fair‑use throttling once you actually saturate the port, surprise “abusive usage” emails, or renewal hikes that quietly erase any early discount.
At the same time, the cost of high‑capacity connectivity has collapsed. TeleGeography’s 2025 IP transit data shows that in the most competitive markets, the lowest 100 GigE transit offers sit at about $0.05 per Mbps per month, with 100 GigE port prices falling roughly 12% annually from 2022 to 2025. On the transport side, weighted median 100 Gbps wavelength prices across key routes have dropped 11% per year over the last three years. Those economics are exactly what make genuinely unmetered dedicated servers viable—if the provider actually passes the savings through instead of hiding limits in the fine print.
In other words: the market now supports truly TCO‑optimized unlimited plans, but there are still plenty of traps. The rest of this piece is about telling those apart.
Choose Melbicom— Unmetered bandwidth plans — 1,300+ ready-to-go servers — 21 DC & 55+ CDN PoPs |
 |
What Makes an Unlimited-Bandwidth Dedicated Server Truly TCO-Optimized
A truly TCO‑optimized dedicated server with unlimited bandwidth keeps lifetime cost predictable: “unmetered” with no fair‑use throttling, guaranteed port capacity rather than shared ratios, clear renewal pricing, and enough backbone, peering, and support that you can run hot 24/7 without surprise bills or performance degradation.
- Start with the word “unlimited.” Many offers advertise it but tuck the real terms into a fair‑use policy: you can use as much as you like until the provider decides it’s too much. That usually means throttling or forced plan changes when you actually drive the link near line rate. A cost‑optimized plan instead spells out port speed—1, 10, 40, or even 200 Gbps—and lets you use that capacity continuously. At Melbicom we design our unlimited bandwidth dedicated server plans around that principle: if you pay for a 10 Gbps port, you can run 10 Gbps without being treated as an outlier.
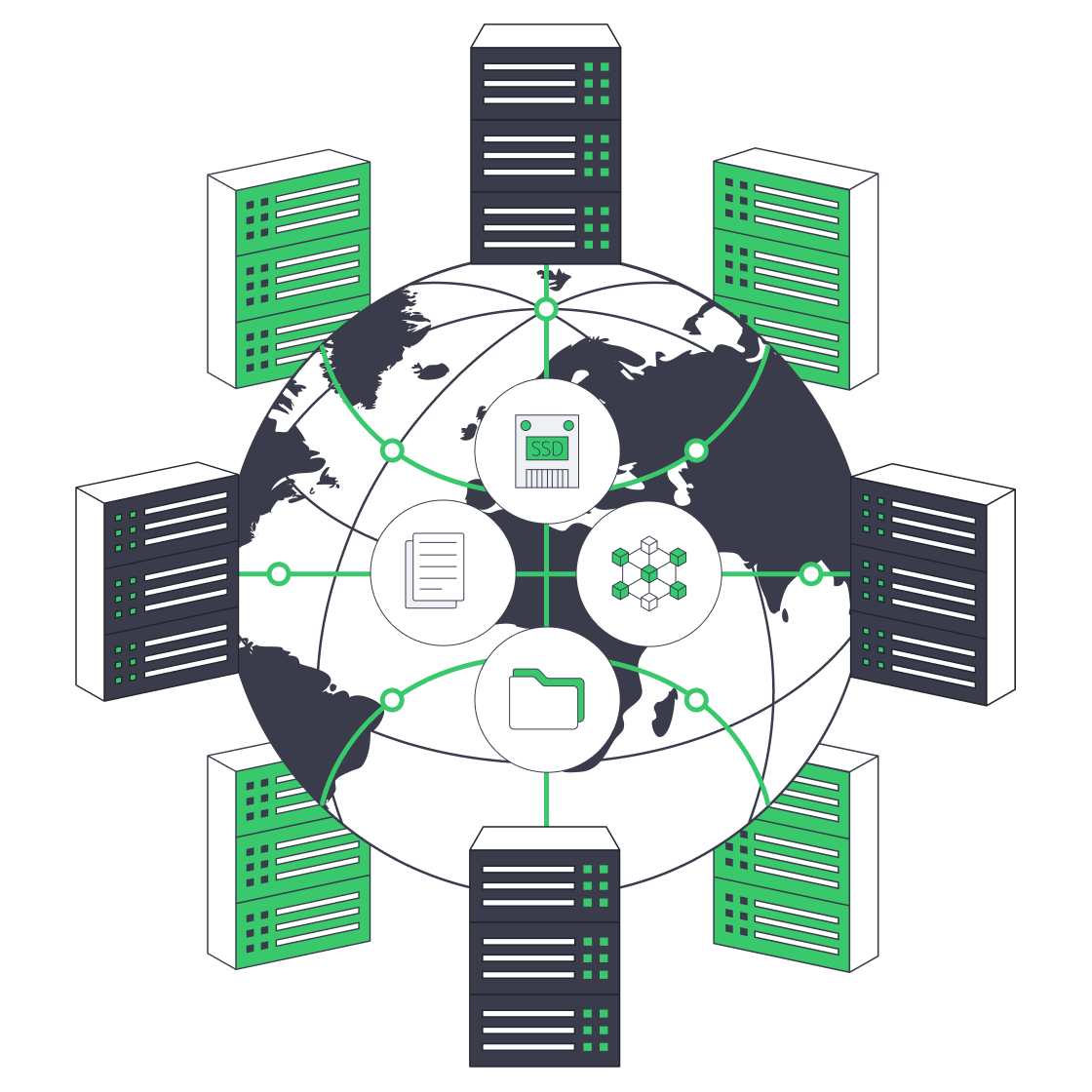
- The second filter is whether the network can support that promise. Melbicom operates a global backbone with 14+ Tbps of capacity, connected to 20+ transit providers and 25+ internet exchange points (IXPs), plus 55+ CDN PoPs that push content closer to users. Ports scale from 1 Gbps up to 200 Gbps per server, so “unlimited” has real headroom rather than marketing‑only numbers.
- Finally, TCO isn’t just bandwidth. Hardware quality, provisioning agility, and support translate directly into operational cost. Melbicom runs 21 global Tier IV & Tier III data centers so you can deploy close to users without redesigning your stack each time. All of that sits behind a flat monthly price per server, with free 24/7 support, so you’re not quietly paying in engineering hours for every incident or hardware tweak.
Which Unlimited Bandwidth Plans Avoid Hidden Renewal Hikes

Unlimited bandwidth plans that genuinely avoid renewal hikes are almost boring: a single, clearly documented monthly price; no “introductory” or “promo” qualifiers; no vague fair‑use clauses; and no essential features split into billable add‑ons after month twelve.
The classic “too good to be true” pattern is a rock‑bottom first‑term price that quietly doubles at renewal. That’s tolerable on a small SaaS plan; it’s disastrous when the asset is a high‑traffic dedicated server with terabytes of data gravity. You migrate workloads, tune performance, maybe colocate other services near it—and then the second‑year invoice jumps 2–3× because the initial rate was promotional. The same trick often shows up as add‑on metering: “unlimited” on paper, but with specific traffic types, locations, or features billed separately.
The way to spot this is to read pricing tables and terms as if you were finance. If the offer page shows only a discounted introductory rate and is silent on renewals, assume the hike exists. If “unlimited” appears alongside mention of 95th‑percentile billing, burst caps, or loosely defined fair‑use policies, the risk is high that your total cost of ownership will drift up as soon as you actually use the bandwidth you’re paying for.
By contrast, a TCO‑oriented unlimited plan aims for rate stability. At Melbicom we price dedicated servers on a flat monthly basis: you pick hardware and port speed, we provide the capacity, and the price tag on our dedicated server page is what you build into your model. If you need more bandwidth, you upgrade the port or add servers—rather than discovering a multiplier in the fine print. The absence of teaser pricing matters because it prevents the infra you depended on at 1× scale from becoming untenable at 10× scale.
How Do Flat-Rate Plans Simplify Bandwidth Budgeting
Flat‑rate unmetered plans simplify bandwidth budgeting by turning a volatile, usage‑driven cost into a fixed monthly line item. Instead of watching per‑GB meters or 95th‑percentile graphs, you decide what a given server and port are worth and know your bill won’t spike every time traffic does.
Usage‑based egress pricing is the opposite. Consider a typical major cloud provider. Public documentation for Amazon EC2, for example, starts data transfer out at $0.09 per GB for the first 10 TB per month, then drops to $0.085 per GB for the next 40 TB and $0.07 per GB for the next 100 TB. Those numbers sound small until you multiply them by real‑world traffic:
| Monthly Data Transfer | Estimated Cloud Egress Cost* | Flat-Rate Server Cost |
|---|---|---|
| 10 TB | ≈ $900 (usage-based) | $500 (fixed) |
| 50 TB | ≈ $4,400 | $500 (fixed) |
| 100 TB | ≈ $7,800 | $500 (fixed) |
*Illustrative calculation based on EC2 data transfer out pricing tiers across the first 150 TB/month. Actual charges vary by region and service.
At small scales, usage‑based billing is manageable. As soon as you cross into tens of terabytes per month, bandwidth becomes your primary cost risk. Analysis from practitioners and vendors alike repeatedly flags data transfer as one of the most common sources of unexpected overruns on cloud bills. That’s before you add AI inference traffic, larger media assets, or new regions.
Flat‑rate unlimited servers invert that risk profile. Instead of bandwidth being a variable cost that explodes with success, it becomes a predictable input: you choose an unlimited bandwidth server with, for example, a 10 Gbps port at a known monthly rate, then treat bandwidth as fixed when you model margins and runway. If you need more capacity, you add nodes or step up port speeds, but individual traffic spikes don’t translate into four‑ or five‑figure surprises. Pair that with a globally distributed CDN—and you can keep content close to users while keeping origin bandwidth and cost curves stable.
From a planning perspective, that means fewer worst‑case scenarios in your spreadsheets and more confidence in long‑term commitments. Bandwidth becomes the boring part of your infrastructure P&L—which is exactly what most CFOs and CTOs want.
From Chasing a Cheap Unlimited Bandwidth Plan to Choosing a TCO-Optimized One

The current market makes it easy to chase the absolute lowest sticker price on anything labeled “unlimited.” The problem is that infrastructure rarely stays at its day‑one footprint. If your workloads grow as intended, 10× traffic is a matter of when, not if—and contracts that looked cheap at small scale can quietly accumulate risk.
What you want instead is a TCO‑optimized unlimited bandwidth strategy: understand how much bandwidth your workloads will consume, pick flat‑rate plans that genuinely let you use the ports you’re paying for, and ensure the underlying network and support model can keep up without hidden surcharges. Unlimited bandwidth dedicated servers that meet those requirements let you absorb new features, bitrates, codecs, and even extra regions without having to renegotiate your relationship with finance every quarter.
When you zoom out from individual offers, a few practical recommendations emerge:
- Treat “unlimited” as a technical claim, not a slogan. Ask explicitly what happens if you run the port hot 24/7. If the answer involves undefined “fair use,” thresholds, or 95th‑percentile clauses, assume there are financial or performance cliffs.
- Model renewals/edge cases before you sign. TCO‑optimized plans make renewal pricing explicit and avoid jumps after an introductory term. Include high‑traffic months, peak events, and feature launches in your cost scenarios—not just your current baseline.
- Move bandwidth from variable to fixed where it makes sense. For workloads pushing tens of terabytes per month, flat‑rate unmetered plans plus CDN offload are often cheaper and vastly more predictable than per‑GB egress, even if the per‑server sticker price looks higher at first glance.
- Favor providers that invest in backbone capacity and peering. Multi‑terabit backbones, 20+ TP, and broad IXP reach reduce both performance risk and the chance that your “unlimited” plan is really just oversold capacity with contention during peaks.
In practice, you’ll mix models—some usage‑based services where traffic is low or bursty, some flat‑rate unmetered infrastructure where throughput dominates. The key is that you choose where to take risk, instead of letting unclear fair‑use rules decide for you.
Choose flat-rate unlimited bandwidth servers
Predictable pricing and performance without fair-use throttling. Deploy in 21+ global locations with ports up to 200 Gbps and 24/7 support. Pick hardware and port speed, and keep bandwidth a fixed monthly cost.
Get expert support with your services
Blog

Compliance Playbook For Italian Dedicated Servers
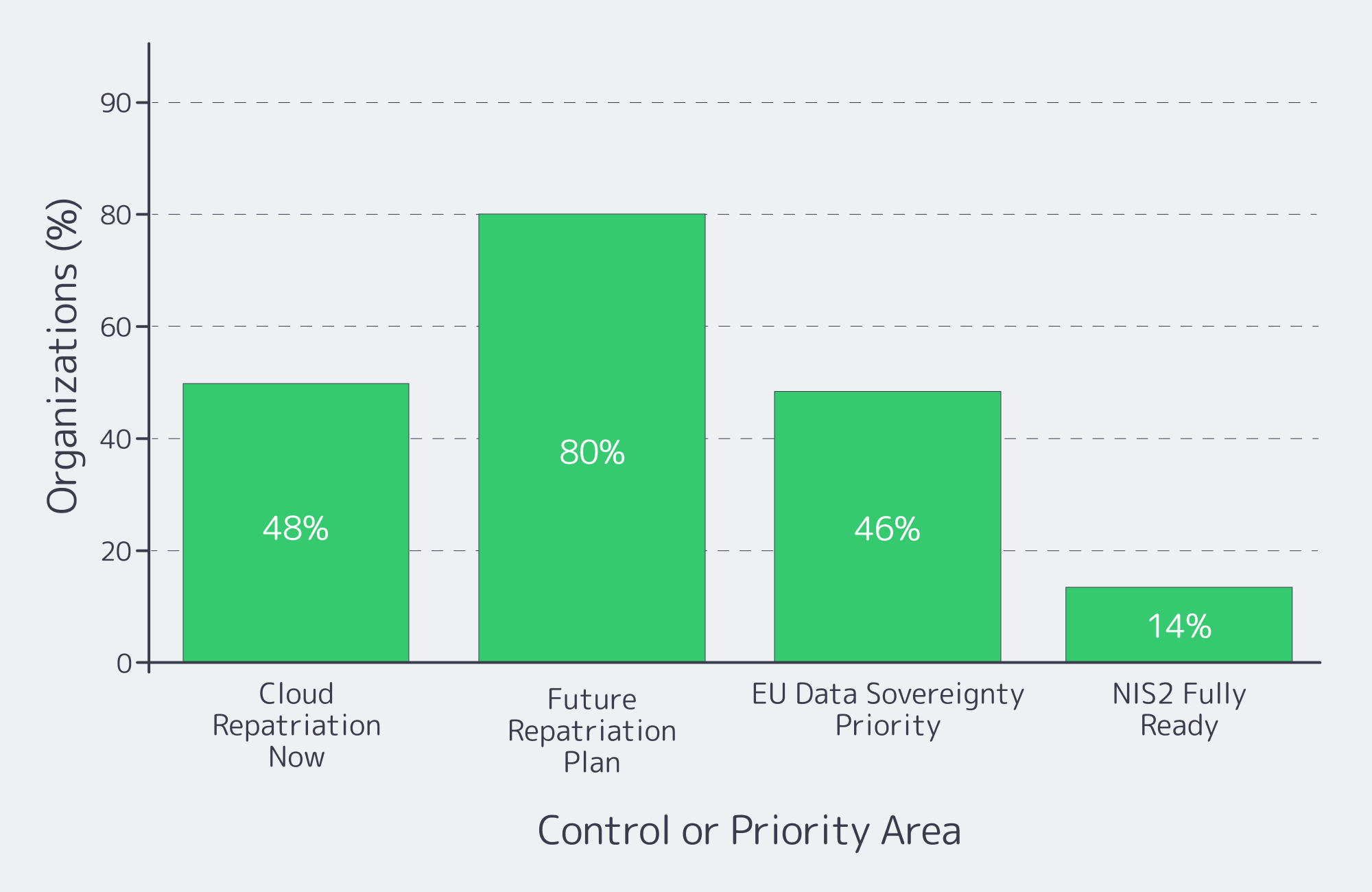
European regulation has quietly killed “move fast and break things” for infrastructure teams. GDPR set the baseline for data protection; NIS2 and DORA now turn cyber‑risk and resilience into board‑level issues. Recent research shows that over 48% of companies are considering or actively moving workloads from public clouds back on‑premises or to private clouds, and around 80% expect to repatriate some workloads within the next two years, largely due to cost and sovereignty pressures.
At the same time, 46% of European security leaders now rate EU data sovereignty as their single most important buying criterion, ahead of cost. For regulated services, that translates into a blunt infrastructure mandate: keep critical data on infrastructure where you can prove where it lives, who can access it, and which controls wrap around it.
Italy is a strong candidate for that anchor point. Palermo sits on top of multiple Mediterranean cable landing stations, and Melbicom’s Tier III data center there connects directly into those systems. That location can shave 15–35 ms of latency to North Africa and the Middle East and improve overall route quality by 50–80% for those regions. For EU‑facing workloads, hosting on a dedicated server in Italy combines clear EU jurisdiction with low‑latency connectivity into European backbones.
Choose Melbicom— Tier III-certified Palermo DC — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
|
This article offers a practical compliance playbook for running regulated workloads on a dedicated server in Italy deployment – how to map data flows, what GDPR artifacts to demand, which controls line up with NIS2 and DORA, and how to stay audit‑ready instead of scrambling when someone says, “We have an assessment next month.”
What GDPR Artifacts to Request from Italian Dedicated Server Hosting Providers
For Italian hosting, you want GDPR paperwork that proves where data lives, who touches it, and how it’s protected. In practice, that means a DPA with teeth, full sub‑processor and location transparency, mapped data flows, security certifications or audits, and clear incident‑handling clauses you can point to in an assessment.
The non‑negotiables:
- Data Processing Agreement (DPA). Your DPA with a hosting provider should clearly scope which services are in play, what security measures apply, how data‑subject rights are supported, and how audits or inspections can be performed.
- Sub‑processor and location transparency. Demand a current list of sub‑processors with their roles and countries.
- Data‑flow and data‑category mapping. Before migrating, map which components on the server handle personal data, which handle telemetry or logs, and which external services receive copies (backups, monitoring, email gateways). That map becomes your single reference when customers or regulators ask, “Exactly where does this field go?”
- Security certifications and audits. Independent audits are now standard proof that “appropriate technical and organisational measures” exist.
- Incident handling and cooperation clauses. Your DPA and main contract should commit the provider to prompt incident notification and meaningful cooperation (log access, forensic details, timelines) so you can meet GDPR’s breach‑reporting deadlines and NIS2/DORA thresholds without conflict.
With this pack in place, you can show regulators and enterprise customers that server hosting in Italia isn’t just a rack in Palermo – it’s a controlled processing environment with clear legal responsibilities and traceable data flows.
Which Security Controls Meet NIS2 and DORA Requirements
NIS2 and DORA effectively codify what used to be optional security hygiene. On a dedicated server in Italy, regulators expect encrypted data, strong identity and access control, rich logging and monitoring, disciplined patching, and tested incident‑response – plus contracts that make your provider an accountable part of that control system.
Encryption, Access, & IAM for Server Hosting Italia
Encrypt data at rest and in transit by default: full‑disk or volume encryption for storage, TLS for services, and VPN or private links for management and inter‑DC traffic. NIS2 guidance calls for “state of the art” cryptography and documented key‑management, including rotation and logging. Combine that with strong identity: SSH keys or certificates for server logins, MFA on Melbicom’s control panel and IP‑KVM, and role‑based access control so only those who truly need it can touch production.
Logging, Monitoring, & Vulnerability Management
NIS2 and DORA both assume that you can detect, investigate, and reconstruct incidents. Centralize system, application, database, and network logs from your Italian server into a SIEM or log pipeline, define retention windows, and monitor for anomalies. Only 14% of organizations say they’re fully NIS2‑ready, according to IDC research sponsored by Microsoft – most are still filling gaps in monitoring and response. A disciplined patch and vulnerability‑management process – defined patch windows, regular updates, and documented remediation timelines for critical CVEs – is one of the fastest ways to close that readiness gap.
Incident Response and Resilience on Your Server Italia Stack
NIS2 and DORA introduce strict timelines and expectations for incident reporting, alongside resilience requirements. Essential entities under NIS2 face fines of up to €10 million or 2% of worldwide annual turnover, whichever is higher, if they fall short on key security obligations. To keep your Italian server environment on the right side of that line, you need a written incident‑response plan, mapped roles between your team and Melbicom, and a tested disaster‑recovery design: encrypted backups (for example, to Melbicom’s EU‑based S3 object storage in Amsterdam), restore drills, and, where needed, second‑site capacity in another EU DC.
How GDPR, NIS2, and DORA Line Up for Hosting
| Framework | Primary Focus | Hosting‑Relevant Must‑Haves |
|---|---|---|
| GDPR | Personal‑data protection and privacy | DPA with your Italian provider; transparent data flows and sub‑processors; appropriate security (encryption, access control); breach detection and 72‑hour reporting processes. |
| NIS2 | Cybersecurity for essential/important entities | “State of the art” controls: encryption, MFA, logging/monitoring, vulnerability management, documented risk management, and fast incident reporting backed by clear governance. |
| DORA | Digital operational resilience for finance | ICT‑risk framework, segregated and tested backups, documented RTO/RPO, rigorous incident handling and reporting, and strong third‑party oversight for infrastructure providers. |
How to Ensure Audit Readiness for Italian Dedicated Hosting
Audit readiness for Italian hosting means treating your environment as an evidence machine, not just a stack of servers. You need up‑to‑date documentation, log trails you can reconstruct incidents from, clear ownership with your provider, and a lightweight review cadence that keeps controls aligned with GDPR, NIS2, and DORA expectations.
Start with an evidence repository. Collect the DPA, main contract, network diagrams, data‑flow maps, and risk assessments that describe your Italian environment. Add vulnerability‑scan reports, backup/restore test logs, penetration‑test summaries, and configs proving MFA, encryption, and hardening. When an audit lands, you’re curating from a library, not hunting through inboxes.
Then audit from the outside‑in. Periodically run an internal checklist against GDPR, NIS2, and DORA requirements: Can you show where personal data sits on your dedicated server Italy deployment? Produce a sub‑processor list? Prove that backups are tested? The point isn’t to build a bureaucracy – it’s to ensure that if a bank client, regulator, or board asks, you have concrete answers backed by evidence.
Finally, stay ahead of regulatory drift. GDPR enforcement has already produced roughly €5.88 billion in cumulative fines as of early 2025, and regulators are widening their target list beyond “big tech.” NIS2 and DORA are only increasing the stakes. Build a lightweight governance loop: periodic reviews of guidance from EU and Italian authorities, internal gap analyses, and scheduled updates to your controls and documentation. When rules shift, you adjust the Italian environment deliberately instead of reacting under audit pressure.
Turning a Dedicated Server in Italy Into a Compliance Advantage

Put all of this together and a dedicated server in Italy stops being “just hosting” and becomes part of your governance architecture. You concentrate your regulated workloads in a single‑tenant, clearly located environment under EU law; you can prove where every packet lives, who has access, and which controls wrap around it.
Key Takeaways for Hosting in Italy
- Anchor sensitive workloads in a single‑tenant Italian environment. Keep personal‑data‑heavy systems on a dedicated server Italy deployment so you can explain data residency and access in one slide – and avoid cross‑border transfer issues unless they’re explicitly required and documented.
- Treat security controls as regulatory requirements, not best‑effort. Map encryption, MFA, logging, vulnerability management, backups, and incident response directly to GDPR, NIS2, and DORA articles. Make sure each control has an owner, a test schedule, and an associated piece of evidence.
- Build audit readiness into day‑to‑day operations. Maintain an evidence repository, standardize log retention, and schedule periodic “mini‑audits” so there are no surprises when an external assessor or major customer wants proof that your Italian hosting stack is under control.
Get compliant hosting in Italy
Deploy dedicated servers in Palermo with EU data residency, NIS2-ready controls, encrypted backups, and 24/7 support. Choose a configuration that fits your workloads and compliance goals.
Get expert support with your services
Blog
Italy Dedicated Servers: A Due Diligence Playbook
Italy is no longer a “secondary” EU hosting decision. Market researchers estimate the country’s data‑center market at about $5.73B and project it to reach $7.54B in the near term, with forecasts climbing to $13.49B by the end of the decade.
If you’re here to rent a dedicated server in Italy, treat this guide like a production dependency: translate workload into CPU/RAM/NVMe and bandwidth tiers, pick a city that hits latency targets, and validate the boring‑but‑fatal details—routing, out‑of‑band access, remote hands, provisioning, and exit clauses. This is the checklist you can reuse.
Choose Melbicom— Tier III-certified Palermo DC — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
|
Italy: Rent a Dedicated Server by Sizing the Workload First
Sizing isn’t about buying “big.” It’s about making performance predictable under ugly realities: cache misses, replication spikes, batch jobs colliding with user traffic, and the day your database vacuum decides it’s the main character.
- Profile (peak QPS, background jobs, read/write mix, hot‑set size).
- Translate into CPU/RAM/NVMe and a baseline bandwidth tier.
- Add headroom you can justify (incident mode + growth).
- Decide scaling path (vertical now, horizontal later—or vice versa).
Dedicated server Italy CPU: map concurrency to cores and clocks
For latency‑sensitive services, clock speed and sustained all‑core behavior often matter more than “how many cores can we afford.” Ask for the exact CPU model and generation, then sanity‑check it against your p95 CPU time per request and expected concurrency. If the provider can’t name the SKU, you can’t reproduce performance later.
RAM: budget for churn, not average
Memory pressure is an incident generator. Size for the worst five minutes: GC churn, cache turnover, and page cache behavior during heavy reads. Confirm ECC RAM and ask how upgrades are handled (in‑place vs reprovision). For data stores, treat RAM as a performance tier (indexes + hot sets), not a cost center.
Storage: NVMe as the default, not the upsell
NVMe isn’t just “faster disk.” It’s a different latency profile. NVM Express’ analysis notes that PCIe 4.0 x4 NVMe can be over 10× faster than SATA 3.0 at the interface level, and cites lab results showing ~5.45× more read bandwidth and ~5.88× more random‑read IOPS for data‑center NVMe versus enterprise SATA. If storage touches your request path, NVMe is how you buy predictability.
Bandwidth: tier it like a resource, not a line item
Define two requirements: steady‑state commit (normal egress, replication) and burst (backfills, re‑shards, release windows). Also decide if you need metered transfer or an unmetered port. The “right” tier is the one that doesn’t punish growth—or turn incident response into a cost spike.
Which Italian Data Centers Meet Low-Latency EU Requirements
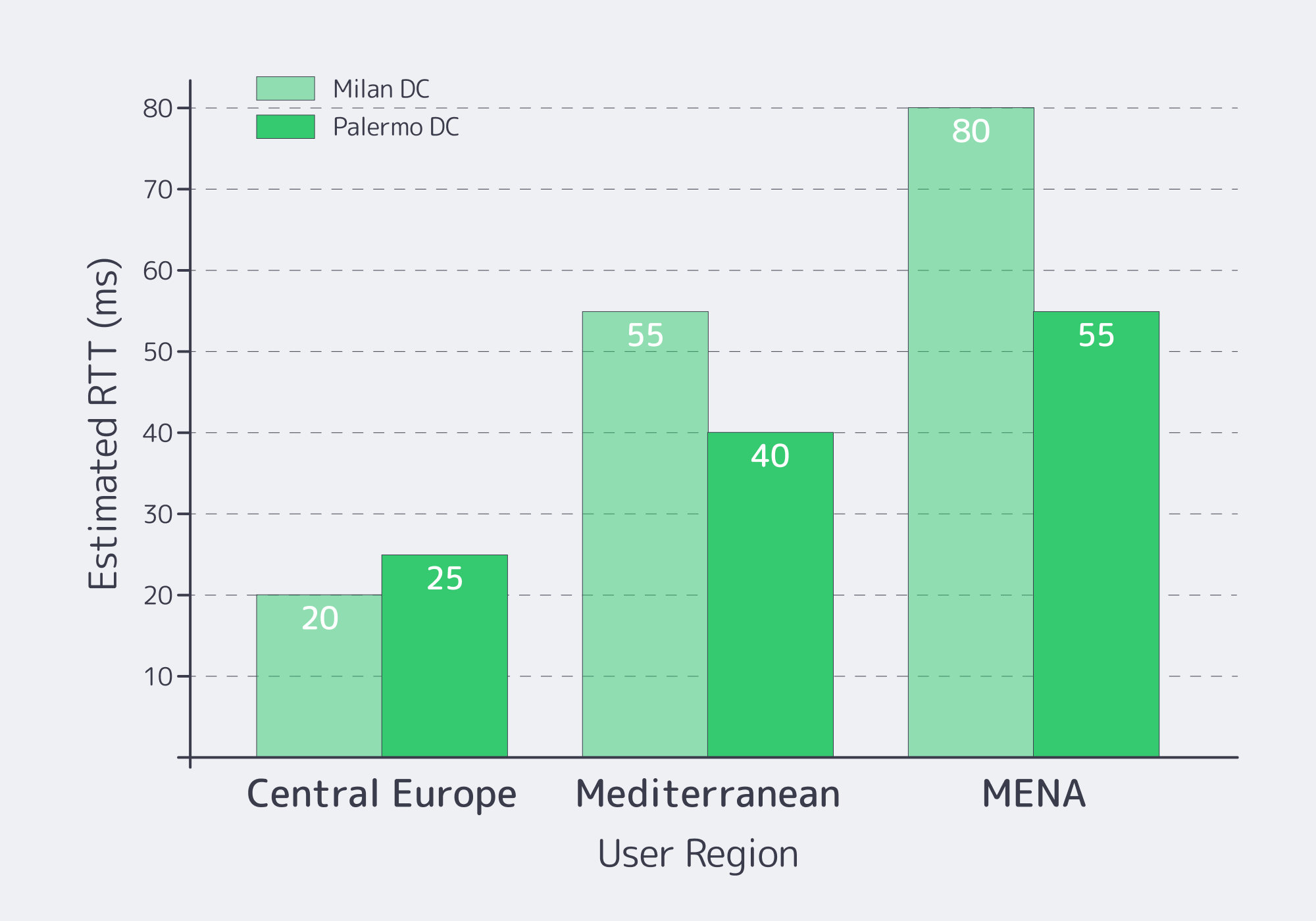
Italy meets low‑latency EU requirements when you choose the city for your user geography and upstream routes—not because “Italy is central.” Milan is typically best for Central/Northern Europe paths; Southern Italy can be better for Mediterranean and MENA adjacency. Validate with real RTT and loss measurements from your top regions, then pick what hits your p95 SLOs.
Start with targets, then back into geography. A public ping dataset shows Milan ↔ Frankfurt round‑trip latency around ~10.3 ms under typical conditions. That’s why Milan is the default “close to everything” choice for many EU workloads.
But “Italy” is not just Milan.
Palermo as a latency and routing lever
Melbicom’s Italy location is Palermo, a Tier III facility with 1–40 Gbps per server options. The Palermo site is much closer to Mediterranean cable landings and can save 15–35 ms of latency and deliver a 50%–80% overall quality improvement for traffic tied to Africa, the Mediterranean, and the Middle East.
Due‑diligence move: don’t accept “quality” as a vibe. Run multi‑probe RTT + packet‑loss checks from the networks you care about.
What to Validate in Italian Hosting MSAs
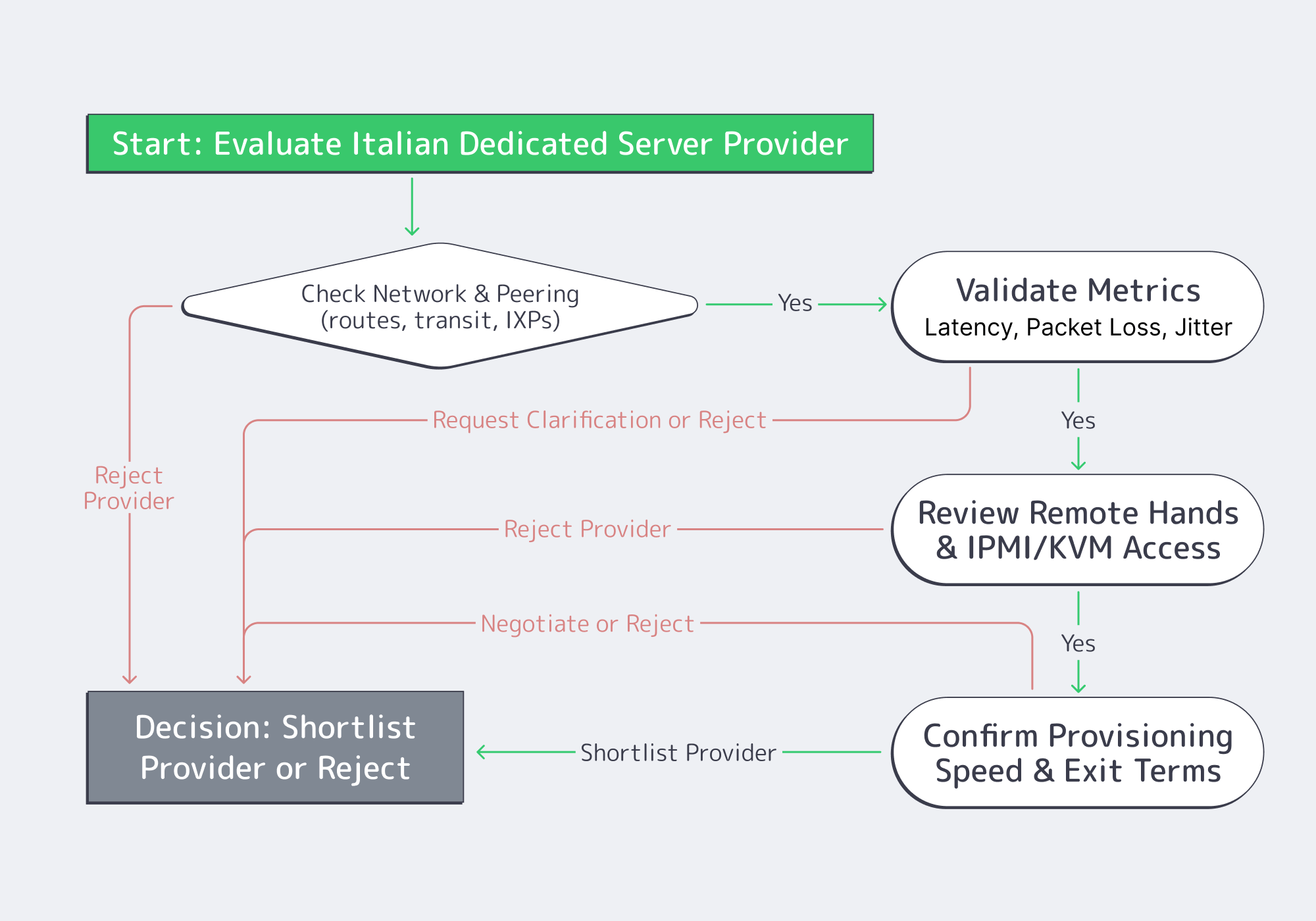
Treat the SLA (or MSA + service terms) like part of your architecture: it defines how performance is measured, how fast issues are handled, and what “support” actually includes. Validate peering quality, packet‑loss targets and measurement windows, remote‑hands scope, IPMI/KVM access, provisioning timelines, and exit/migration clauses. Anything ambiguous becomes a problem during an outage.
Here’s the due‑diligence checklist that actually changes outcomes.
- Peering and routing evidence. Ask for traceroutes to your top destinations (or a looking‑glass), and verify paths stay sane during peak hours. “Many peers” is not a guarantee; consistent paths are.
- Packet‑loss targets + measurement method. A common backbone benchmark is ≤0.1% average monthly packet loss—but only if the agreement defines where and how it’s measured. Lock down scope (inside provider backbone vs public internet), sampling, and how you can reproduce the metric.
- Remote hands scope. Define what’s included (reboots, reseats, KVM hookup) vs billable (disk swaps, rack work), plus response times and escalation. This is how you turn “we’ll help” into an operational control.
- IPMI/KVM access (out‑of‑band recovery). Out‑of‑band access is your last line of defense when the OS is dead or the network is misconfigured. Validate isolation, credential rotation, and auditability.
- Provisioning lead time (stock vs custom). Put timelines in writing and separate “stocked config activation” from “custom build delivery.” When you need capacity under pressure, hand‑wavy provisioning is not a plan.
- Exit and migration clauses. Confirm notice periods, data wipe proof, and IP handling. If IP identity matters, routing options can make migrations cleaner; Melbicom supports BYOIP and BGP sessions on dedicated servers.
How to Build a Server Scoring Matrix
A scoring matrix turns subjective impressions into a repeatable decision. Weight the criteria that map to production risk, score each provider only with evidence, and force trade‑offs into the open. Include workload fit, measured latency, network quality, operational access (IPMI/KVM, remote hands), provisioning, and exit terms.
Weighted Score = Σ (weight_i × score_i) / Σ weight_i # score_i is 1–5, backed by a test result or a contract clause |
| Category | Weight (%) | What “5/5” looks like |
|---|---|---|
| Workload fit (CPU/RAM/NVMe) | 25 | Exact CPU SKU, ECC RAM, NVMe options; clear upgrade path |
| Latency to users/partners | 20 | Measured RTT meets p95 SLO from target regions |
| Network & peering quality | 20 | Clean traceroutes; defined loss target + measurement method |
| Operations (IPMI/KVM + support) | 20 | OOB access works; remote‑hands scope + escalation is explicit |
| Provisioning + exit terms | 15 | Timelines in writing; migration window; IP portability options |
To score honestly: run the same tests from the same probes, mark unknowns as unknowns, and penalize ambiguity in service terms. Evidence beats vibes.
Frequently Asked Questions (Ops Edition)
Is “Italy” automatically the lowest‑latency EU option? No. Latency is route‑dependent. Italy can be excellent for specific corridors, but you need measurements from your user regions and partner networks.
What’s the minimum due diligence before signing? A test IP for RTT/loss, exact hardware SKUs, written provisioning commitments, remote‑hands scope, and an exit clause you can execute without downtime gambling.
Do I need a CDN if I rent a dedicated server in Italy? If you serve global users or heavy static content, a CDN is how you stabilize TTFB and reduce origin egress. Melbicom delivers CDN capacity through 55+ PoPs in 36 countries.
What’s the safest way to migrate in? Parallel run: replicate continuously, cut over in stages, and keep rollback. If stable IP identity matters, consider BYOIP via BGP sessions.
Key Takeaways for Renting a Dedicated Server in Italy
- Size from workload behavior: CPU/RAM/NVMe and bandwidth tiers should map to measurements, not guesses.
- Pick Italian locations by latency targets and real routes—then verify with RTT and packet‑loss tests.
- Treat peering quality and out‑of‑band access as production requirements.
- Put remote hands, provisioning, and escalation rules in writing.
- Build an exit plan: migration windows and IP strategy are operational safety nets.
Conclusion: a Dedicated Server Is an Architecture Decision
An Italy dedicated server is only “fast” if the whole stack is predictable: hardware that matches the workload, geography that matches users, routing that stays sane, and service terms that make recovery and exit possible. Do the diligence once—profile, measure, and score—and procurement becomes repeatable instead of emotional.
Deploy in Palermo today
Stocked servers activate within 2 hours; custom builds ship in 3–5 days. Compare Palermo vs Milan for your latency targets and run real tests before ordering.
Get expert support with your services
Blog
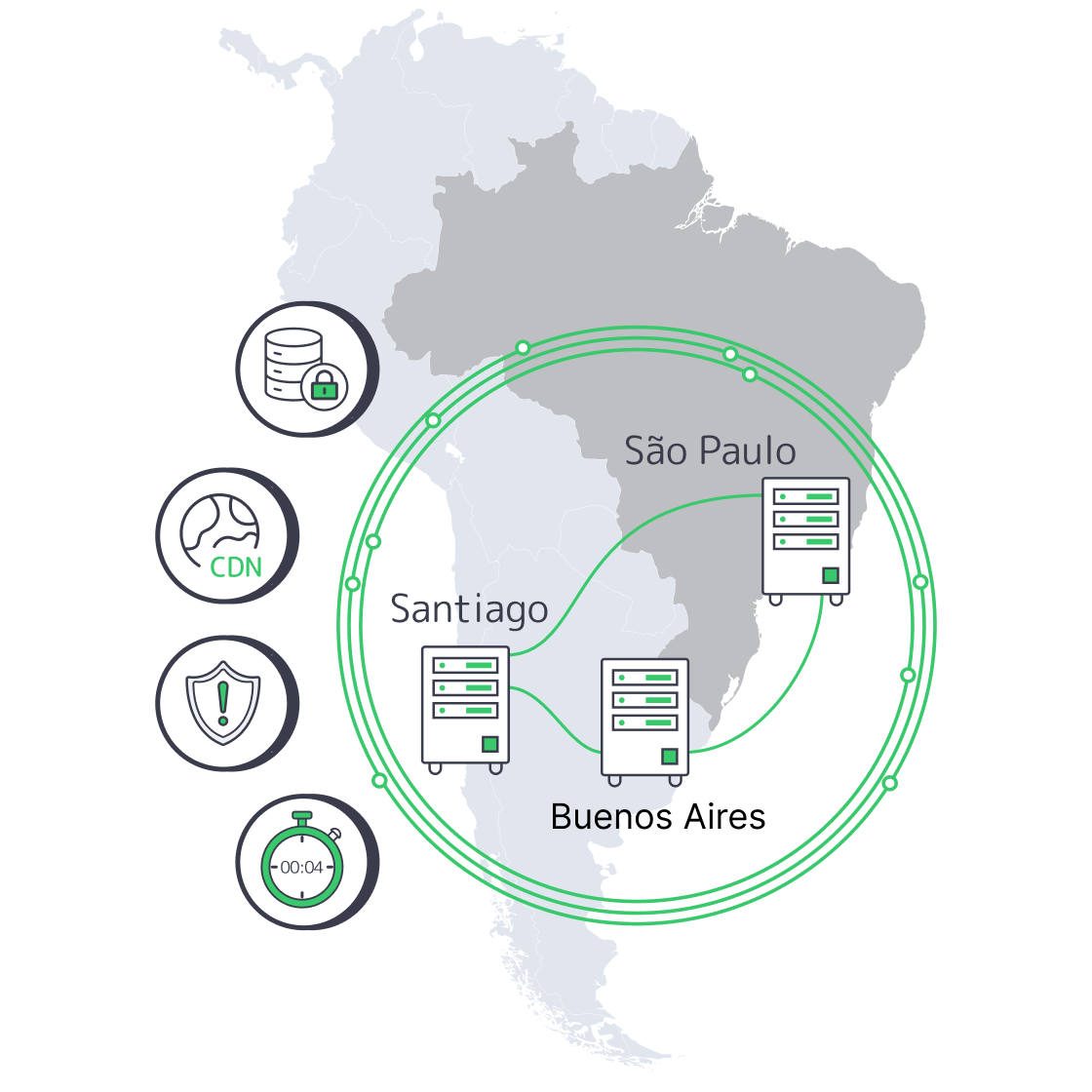
Active/Active Across São Paulo, Santiago, Buenos Aires
South America forces availability engineering to get honest—fast. When your workload is regulated (payments), adversarial (crypto), or real-time (iGaming cores), you don’t get to treat a region as “just another edge.” You have to prove uptime under partial failure: broken fiber segments, bad upstream routes, and the kind of cascading latency spikes that turn “highly available” into “highly unpredictable.”
This playbook shows how to run active/active clusters across São Paulo, Santiago, and Buenos Aires using dedicated hosting patterns that survive real incidents: transaction-safe replication, health-based traffic steering, and a CDN that can absorb volatility without masking it.
Choose Melbicom— Reserve dedicated servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
South America Dedicated Server Requirements for “No-Excuses” Uptime
If you’re shopping for a South America dedicated server setup for 24/7 apps, don’t start with hardware checklists. Start with failure math:
- Every region is a set of metro failure domains. São Paulo, Santiago, and Buenos Aires are not just points on a map; they’re independent blast radii.
- Your data layer decides your uptime story. If the ledger can’t fail over safely, your active/active front end is theater.
- Routing must be health-based and reversible. Steer based on measured health (app + data), not on geography.
Diagram. The Three-Site Active/Active Shape
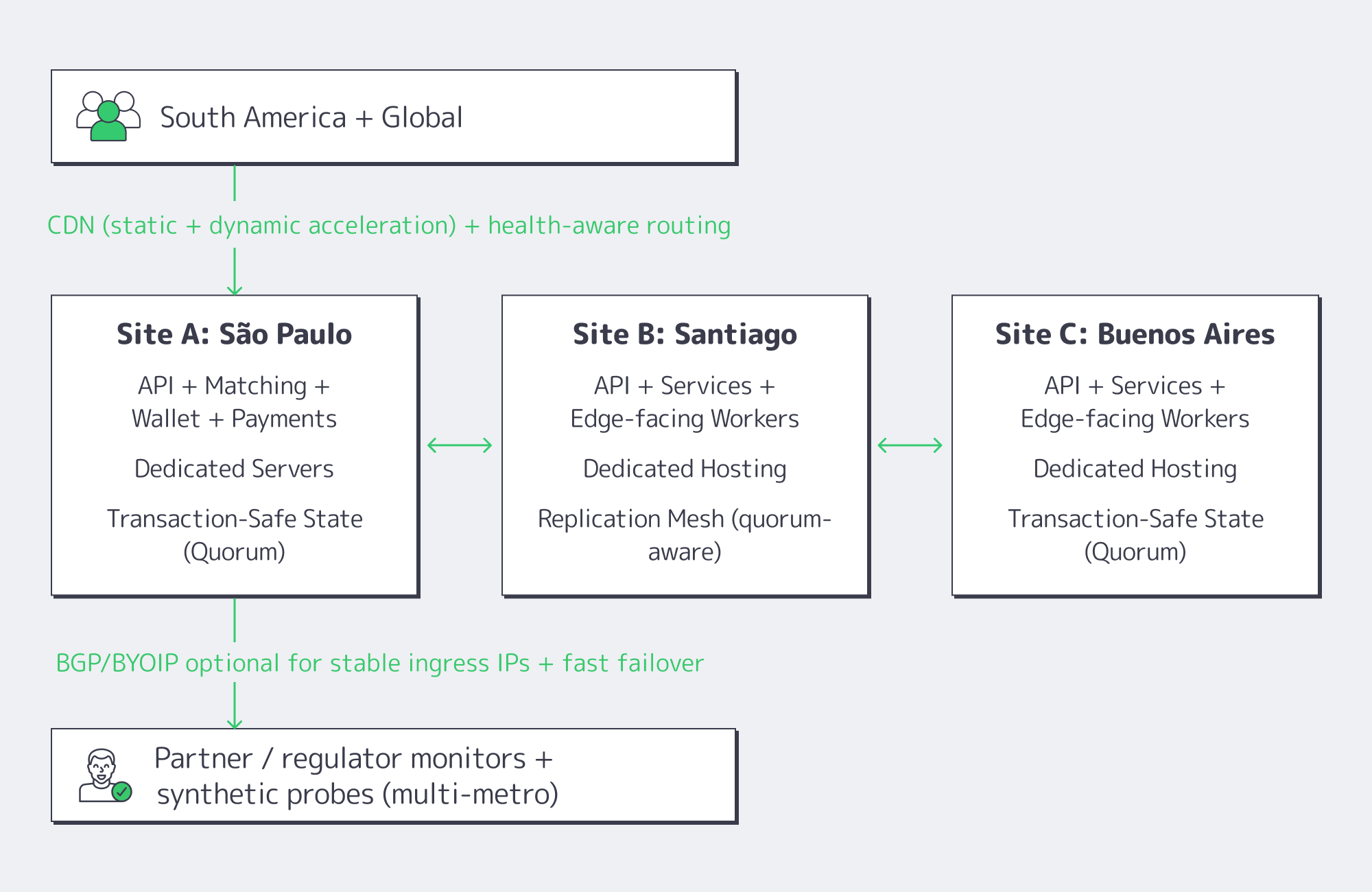
Melbicom supports the primitives you need for this design—BGP sessions (including BYOIP), private networking/inter-DC links, and S3-compatible object storage for snapshots/rollback artifacts—so your HA plan isn’t glued together from one-off scripts.
What Active/Active Dedicated Hosting Architecture Keeps 24/7 Apps Online Across South America?
Active/active that actually works in South America is a three-site design: each metro runs full production services, while a transaction-safe data core enforces correctness across sites. Put São Paulo on dedicated servers as the throughput anchor, use Santiago and Buenos Aires as equal peers, and front everything with health-based routing plus CDN shielding so failures degrade locally—not region-wide.
Dedicated Hosting in South America: The Stack That Holds Under Stress
For crypto exchanges, Web3 wallets, payment gateways, and iGaming cores, break the platform into three layers:
- Edge layer (CDN): static assets, API caching where safe, WAF rules if you use them, and the ability to steer around failures quickly.
- Stateless service layer: auth, pricing, game logic, matchmaking, session services—everything horizontally scalable.
- State layer: balances, orders, settlements, wallet state, player economy—anything that can’t be “eventually fixed” after an incident.
Melbicom’s CDN is explicitly built for multi-origin routing and automatic failover, delivered through 55+ PoPs in 36 countries (including Brazil, Argentina, Chile, Peru, and Columbia), which matters because the edge is where you buy time during a regional brownout (latency spikes, packet loss, upstream route churn).
São Paulo as the Regional Anchor (And Why It’s Not Optional)
São Paulo is where South America’s “always-on” backends usually converge because it’s the region’s interconnection gravity well: from there, you can reach IX.br’s 2,400+ networks, and latency can drop dramatically once you stop tromboning traffic via other continents.
Which Replication Strategy Between São Paulo, Santiago, and Buenos Aires Can Meet Strict RPO/RTO Targets?
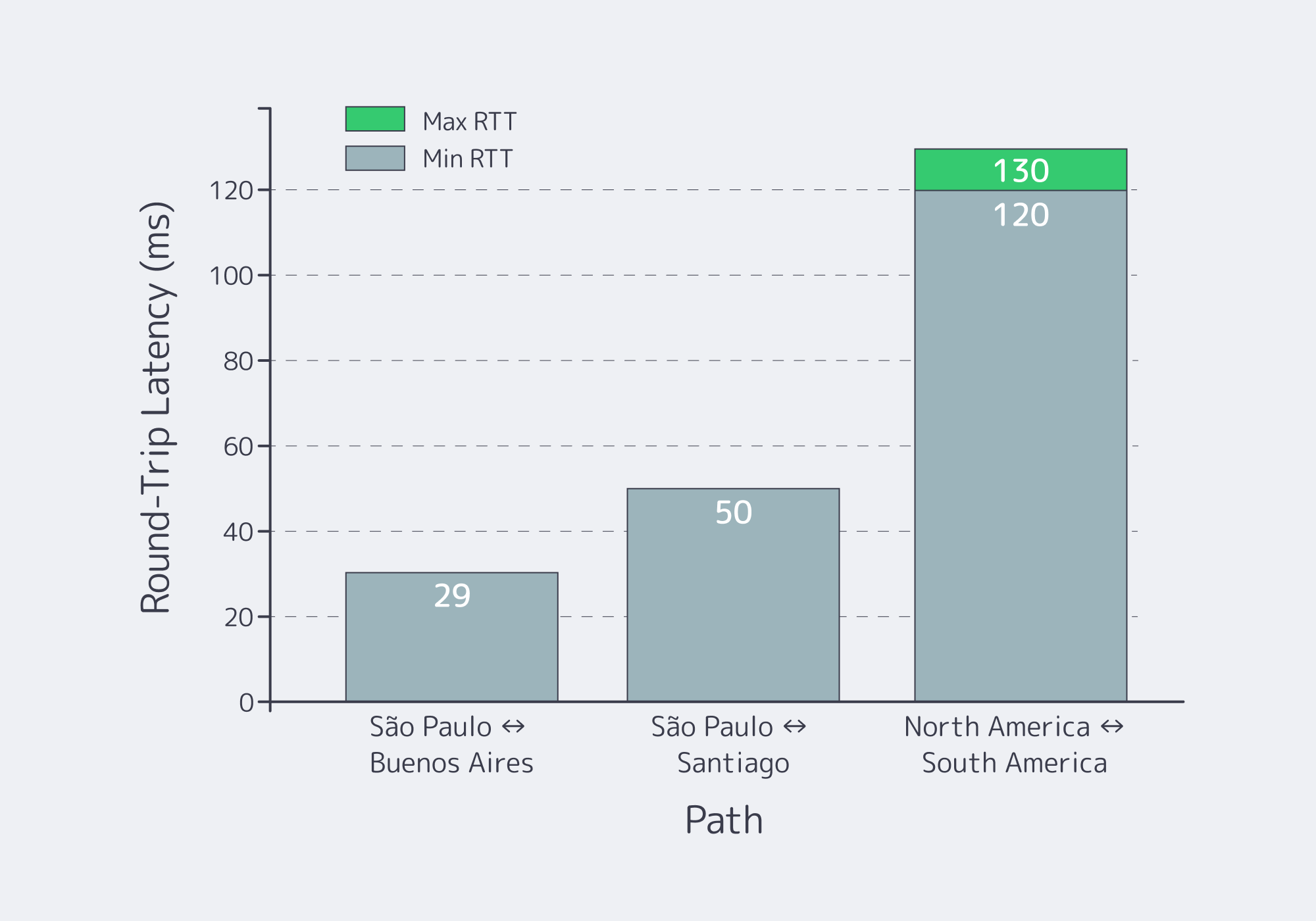
The replication strategy that hits strict targets is quorum-based, transaction-safe replication for the critical ledger, paired with asynchronous replication for everything else. Use synchronous commits only where “no lost transaction” is a hard requirement; otherwise replicate asynchronously with monitored lag. This yields near-zero RPO for the ledger and minute-scale RTO with automated promotion.
The Practical Replication Split: “Ledger vs. Everything Else”
A workable pattern in regulated systems:
- Tier 0 (Ledger / balances / settlement): quorum-based replication (Raft/Paxos-style consensus or another transaction-safe system) across three metros.
- Tier 1 (Orders, sessions, gameplay state): async replication + idempotency + replay.
- Tier 2 (analytics, logs, non-critical caches): async batch replication or rebuild.
Table: Replication Choices and Realistic RPO/RTO Outcomes
| Replication Mode (Three-Site) | Realistic RPO | Realistic RTO |
|---|---|---|
| Quorum-based, synchronous commit for ledger | 0 for committed txns | ~30–180s (automated failover + routing convergence) |
| Async replication with monitored lag (services + read models) | seconds (bounded by lag alarms) | ~1–5 min (promote + warm caches) |
| Snapshot/backup-driven recovery (last resort) | minutes to hours | hours (restore + rehydrate + verify) |
These are engineering targets, not marketing numbers. You only get the top row if you keep the quorum small (3 sites), keep the critical dataset scoped (ledger-only), and make routing conditional on data health—not just HTTP health.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
Which Traffic Routing and CDN Pattern Across South America Maximizes Uptime for Regulated Workloads?
Use a two-tier routing design: CDN first (multi-origin + health checks) for everything cacheable and latency-sensitive, and BGP/BYOIP-based stable ingress for APIs that must keep fixed endpoints. Route only to sites that are healthy at both the app layer and the data layer; otherwise you’ll fail “correctly” but still break users.
Health-Based Routing That Isn’t Geo-DNS
Skip old geo-DNS tricks. Use:
Real health signals (not just “port open”):
- API p95 latency
- dependency health (DB quorum status, replication lag thresholds)
- queue depth / saturation
A routing controller that can make the call:
- CDN origin selection for web + assets
- L7 load balancer decisions for APIs
- BGP failover/anycast when fixed IPs are required
Melbicom’s BGP service is designed for this category of control—BGP at every data center, with routing policy support and IRR integration—so you can keep endpoints stable while still failing over quickly.
The CDN Pattern: Shield + Multi-Origin + Fast Purge
For regulated workloads, CDN is not “just static assets.” It’s a resilience layer:
- Origin pooling: keep three origins hot (SP/SCL/BUE) and route to the best healthy one.
- Shielding: reduce cross-border chatter by collapsing cache misses to a regional shield (often São Paulo), then distribute.
- Fast purge + versioned assets: when you push a critical client fix (wallet UI, payment flow), purge globally without waiting on TTL drift.
Melbicom’s CDN delivers instant cache purge across PoPs and supports multi-origin routing patterns explicitly.
Code example: a concrete “Only Route If Data Is Safe” gate
Below is a simple pattern, not a vendor-specific magic trick: the router only sends traffic to a site if (1) the API is healthy and (2) the site reports “ledger quorum OK” or “replication lag < threshold.”
| | routing_policy:sites:sao_paulo:http_health: https://sp.example.com/healthzdata_health: https://sp.example.com/ledger-quorumsantiago:http_health: https://scl.example.com/healthzdata_health: https://scl.example.com/ledger-quorumbuenos_aires:http_health: https://bue.example.com/healthzdata_health: https://bue.example.com/ledger-quorumdecision:- if: “data_health != OK”action: “drain_site” # do NOT route writes here- if: “http_health != OK”action: “remove_from_pool”- else:action: “weighted_route” # bias nearest healthy site | |
This is how you avoid the most common active/active failure mode: routing users to a site that’s “up” but not safe.
FAQ
Does active/active mean “no downtime ever”?
No. It means you can survive site failure without a full outage. You still need maintenance windows, rollback plans, and a strict definition of “correctness” under partial failure.
Can we hit zero RPO and sub-minute RTO at the same time?
For the ledger: often yes, if you scope the synchronous/quorum system to the critical dataset and keep automated routing tied to data health. For all state: usually no, because latency becomes the outage.
Where does object storage fit?
Use S3-compatible object storage for snapshots, rollback artifacts, and forensic retention. It’s not your hot-path database; it’s your “recover and prove” layer.
Closing the Loop: Proving Uptime, Not Promising It

The South America active/active story that passes scrutiny is simple: three metros, a ledger that replicates safely, and routing that refuses to lie. If São Paulo is degraded, Santiago and Buenos Aires should keep serving—but only when the data layer says it’s safe. If the data layer isn’t safe, you fail closed, preserve correctness, and recover fast.
Before going live, document the failure model you’re willing to survive (loss of one metro, loss of one interconnect path, partial packet loss), then build the telemetry and routing gates to enforce it. That’s what regulators, partners, and enterprise customers ultimately care about: not the diagram, but the evidence trail.
- Treat the ledger as a separate system with its own RPO/RTO targets; don’t let it inherit the “stateless scaling” assumptions of the API tier.
- Gate routing on data health, not just HTTP health (quorum status, replication lag, write availability).
- Keep a playbook for draining a site (read-only mode, write redirection, cache shielding) that can be executed automatically and verified externally.
- Use CDN as a resilience amplifier (multi-origin + shielding + purge discipline), not as a UX-only tool.
- Store rollback artifacts and snapshots where they can be audited and restored—then test restores as a scheduled production exercise.
Plan your São Paulo active/active rollout
Talk to our engineers about BGP/BYOIP, CDN, and S3-backed rollback so your South America active/active design is measurable, testable, and resilient.
Get expert support with your services
Blog

From São Paulo to a Five‑City Production Mesh
For businesses that already work in Europe or North America, South America is no longer an optional region. Latin America’s cloud infrastructure market is expected to grow at 21.7% CAGR from 2024 to 2031, reaching about USD 131 billion by 2031, with Brazil alone over USD 12.9 billion in 2024.
Mobile gaming is on a similar trajectory: South America’s mobile gaming market is about USD 3.23 billion in 2025 and forecast to reach USD 5.21 billion by 2030. iGaming and Web3 traffic are following the same arc, with SOFTSWISS reporting portfolio and jackpot programs that boost player turnover by up to 50% in the region.
At the same time, Brazil’s IX.br system has become a gravity center for the entire continent. Aggregated traffic across IX.br exchanges has exceeded 31 Tbit/s, with São Paulo alone crossing 22 Tbit/s and connecting more than 2,400 ASNs. If you care about deposits, bets, or on-chain events clearing in real time, your South America story starts in São Paulo.
Choose Melbicom— Reserve dedicated servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
This article lays out a practical expansion path: starting with a single dedicated server in São Paulo, then layering CDN South America coverage and additional cities—Buenos Aires, Santiago, Bogotá, Lima—while balancing dedicated hosting in South America against caching, routing, and data‑residency constraints.
Why São Paulo Should Be Your First South American Dedicated Server Location
IX.br São Paulo is the region’s switchboard: top‑three IXP globally by traffic, with local paths between São Paulo and Rio typically in the low‑single‑digit millisecond range when you sit inside the ecosystem. That makes a dedicated server in South America, located in São Paulo, the logical first origin for anything latency‑sensitive.
We at Melbicom are building Brazil as a full‑fledged hub: São Paulo capacity is anchored in a robust data center, with integration into IX.br for dense local peering. From there, your flows can either stay entirely within Brazil or exit toward Atlanta (US‑Southeast) and Madrid on tuned, Tier 1‑backed paths via our 20+ transit providers and 25+ IXPs worldwide.
Once you have that first node, the question shifts from “Should we be in Brazil?” to a more detailed series of questions: Where do we rely on CDN? How do we keep data compliant and routes sane as we expand beyond São Paulo?
Which Cities Need Dedicated Server vs CDN?
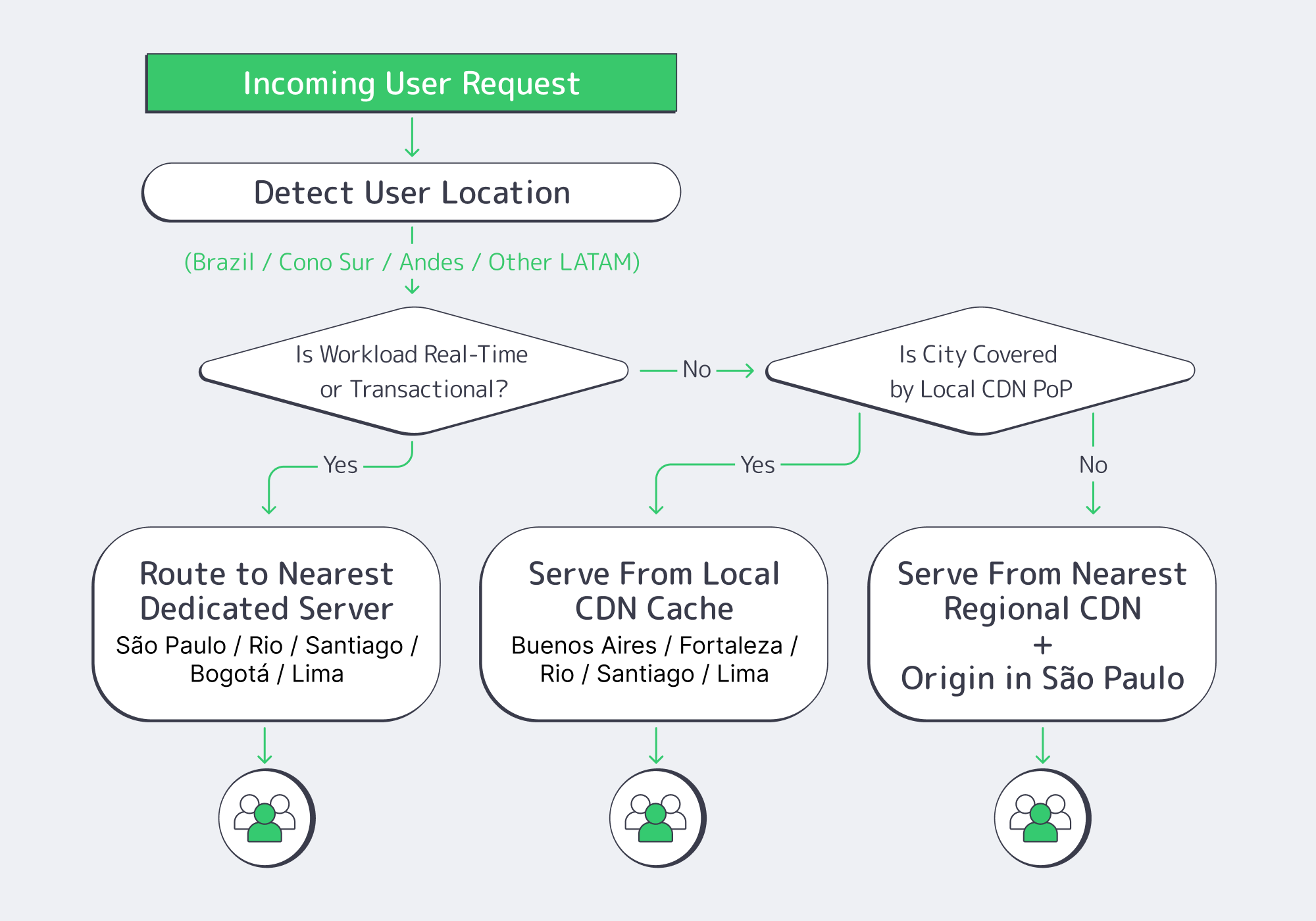 Use São Paulo for dedicated servers that handle stateful, money‑moving, or real‑time gameplay, and lean on CDN in Buenos Aires, Santiago, Bogotá, and Lima for static and semi‑static content. As volumes grow, graduate CDN‑only cities into mixed models by watching latency, rebuffering, and conversion curves.
Use São Paulo for dedicated servers that handle stateful, money‑moving, or real‑time gameplay, and lean on CDN in Buenos Aires, Santiago, Bogotá, and Lima for static and semi‑static content. As volumes grow, graduate CDN‑only cities into mixed models by watching latency, rebuffering, and conversion curves.
The practical rule: dedicated hosting South America is for write‑heavy, high‑value flows that cannot tolerate extra round trips (bets, on‑chain events, stateful matchmaking, KYC flows). CDN South America is for media, assets, and any API call that tolerates a tiny bit of cache staleness or regional aggregation.
Today Melbicom’s CDN runs PoPs in Buenos Aires, Bogotá, Santiago, and Lima, among others, giving you a regional mesh even before you deploy new origin nodes.
A common pattern looks like this:
- Dedicated servers in São Paulo handle core transactional workloads for Brazil and, initially, much of the continent.
- CDN PoPs in Buenos Aires, Santiago, Bogotá, Lima terminate static and semi‑static traffic locally: game assets, static API responses, images, on‑chain state snapshots.
The outcome: Brazil‑origin traffic stays inside Brazil; Southern Cone traffic uses Santiago/Buenos Aires edges that shield the origin; Andean flows get localized reads while writes traverse optimized paths to São Paulo or your upstream hubs in Atlanta and Madrid.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
Which South American Location to Choose After São Paulo?
After a single São Paulo origin, typical sequencing is Baires for Southeast, Santiago for Cono Sur, then Bogotá and Lima for Andean mobile usage. Each step should follow measured demand and regulatory checks, not a single launch date, so you avoid stranded capacity or surprise compliance gaps.
A practical South America dedicated server build‑out usually goes through five stages:
| Stage | Trigger Signal (Business / Ops) | Recommended Move (Dedicated vs CDN) |
|---|---|---|
| 1 – São Paulo MVP | Brazil is ≥15–20% of revenue; high complaint rate about Brazil latency. | Deploy 1–2 dedicated servers in São Paulo as the regional origin; use CDN for rest of LATAM. |
| 2 – Cono Sur Expansion | Material user base in Chile/Argentina; streaming or live‑ops uptake. | Deepen CDN use in Santiago/Buenos Aires; keep origin in São Paulo unless origin RTT visibly hurts conversion or retention. |
| 3 – Andean Focus | Colombia/Peru traffic growing faster than Brazil; mobile‑only cohorts dominate. | Use Lima and Bogotá PoPs heavily; plan dedicated servers in at least one Andean capital when active user concurrency and regulatory needs converge. |
| 4 – Five‑City Mesh | Region behaves like 3–5 distinct markets; local compliance pressures increase. | Run dedicated servers in Brazil plus at least one origin per sub‑region, with CDN layering everywhere. |
This staged approach mirrors the broader cloud infrastructure story: Latin America’s cloud infrastructure market already exceeds USD 30 billion and is growing at 21.7% CAGR, but investments are far from evenly distributed. You buy time and optionality, not just capacity.
Early on, CDN buy you coverage and cost-effective offload. As TCP handshakes and stateful latency start to drag KPIs—bet confirmation lag, in-app purchase completion, or Web3 transaction finality—you promote a city from “edge-only” to “edge + dedicated origin.”
Local Data Residency, LGPD, and Cross‑Border Patterns

Infrastructure decisions in South America are now inseparable from data‑residency questions. Brazil’s LGPD has been in force since 2020; recent regulations (ANPD Resolution 19/2024) clarify cross‑border transfers via standard contractual clauses and adequacy‑style mechanisms, rather than imposing blanket data localization.
For many platforms, that translates into a simple playbook:
- Keep primary Brazilian PII in Brazil. Store customer profiles, KYC data, and transactional logs on dedicated servers in São Paulo, potentially with encrypted replicas in another jurisdiction.
- Move telemetry and aggregates freely. Anonymized analytics and gameplay metrics can safely live in Atlanta or Madrid, provided your legal basis and contracts are aligned.
- Treat other LATAM countries as “regulated but pragmatic.” Argentina and Mexico, for example, emphasize purpose limitation and cross‑border safeguards rather than hard localization rules; regulators still expect you to know where your primary stores sit and how you handle international transfers.
Routing ties this together. Without tuning, flows from Chile or Peru to Brazil can hairpin via the United States. With BGP sessions on your dedicated servers (free on Melbicom’s dedicated platform), you can:
- Prefer routes that keep Brazilian data inside Brazil when possible.
- Use regional peers so Santiago/Baires traffic reaches São Paulo directly, not via Miami.
- Steer non‑sensitive analytics toward Atlanta or Madrid where your global data lakes live.
The goal is to make South America dedicated hosting feel local to users and regulators while still benefiting from global hubs.
Who Can Design a Brazil‑First Mesh?
You want a provider that combines both dedicated hosting and CDN coverage in South America, and BGP expertise, plus the ability to ship custom servers in days, not months. Melbicom fits that profile, aligning São Paulo capacity, CDN PoPs, and procurement planning with your release roadmap.
Melbicom operates 21 Tier III/IV data centers worldwide and a CDN with 55+ PoPs across 36 countries, including South American locations such as Baires, Bogotá, Santiago, or Lima. That combo lets us treat origin + edge as one fabric rather than two disconnected systems.
Custom server configurations are typically delivered in 3–5 business days (including Ryzen/Xeon/EPYC CPUs, DDR4/DDR5 RAM, NVMe storage, with optional GPU) and free BGP sessions on dedicated servers give your network team full routing control.
Because Melbicom runs both the CDN and the dedicated hosting stack, cache misses stay on‑net: a Lima or Santiago PoP pulling from a São Paulo origin uses regional paths, not surprise trans‑oceanic backhaul. That simplifies latency tuning and cost control for Web3, iGaming, and mobile gaming workloads.
Key Steps to Expanding in South America (without the Big Bang)
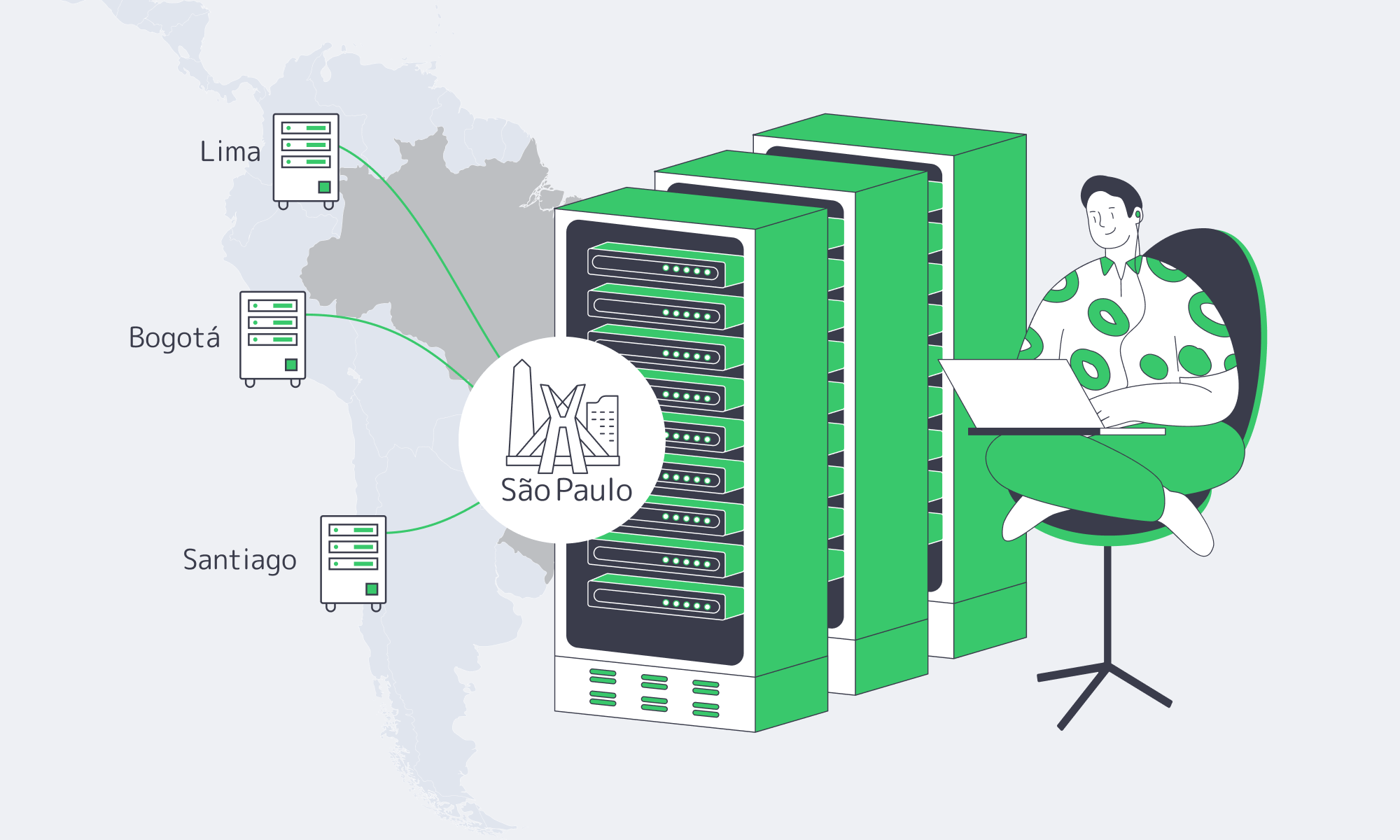
Rather than lighting up five cities at once, treat South America as a rolling program with explicit decision gates. In practice, a low‑risk plan for dedicated hosting in South America and regional caching looks like this:
- Start with a single, well‑provisioned São Paulo origin. Give yourself headroom on CPU, NVMe, and bandwidth so you are not rebuilding hardware during your initial Brazil launch window.
- Lean hard on the existing CDN mesh. Use PoPs in Buenos Aires, Bogotá, Santiago, and Lima as your first line of defense for assets and semi‑static APIs. Watch hit ratios, TTFB, and rebuffering before ordering new servers.
- Promote cities based on lived metrics. When a metro’s concurrency, transaction value, or regulatory exposure crosses your internal threshold, move it from CDN‑only to a combination of CDN plus dedicated origin.
- Tie procurement to milestones, not dates. Map hardware orders to growth signals (DAU, GGR, or TVL bands) and regulatory inflection points, so you avoid shipping racks into cities that never quite materialize in your revenue mix.
- Make BGP and data‑residency part of the design, not a retrofit. Decide early which flows must remain in‑country, which can land in Atlanta or Madrid, and how you prefer routes between Brazil and its neighbors.
These are infrastructure decisions, but they are really business risk decisions: you are trading capital outlay, regulatory exposure, and performance headroom against each other at every step.
Planning Your South America Dedicated Server Mesh
By the time you reach a five‑city mesh—São Paulo, Baires, Santiago, Bogotá, Lima—your region behaves more like a mini‑continent than a single “LatAm” market. Users expect local responsiveness; regulators expect clarity on where data lives; and finance expects that your capacity curve tracks revenue, not hope.
A good South America dedicated server strategy keeps three constraints in balance:
- Latency: Keep real‑time traffic on origins as close as possible to users, with São Paulo as the anchor and regional hubs for Cono Sur and the Andes.
- Compliance: Align data stores and cross‑border routes with LGPD and local rules; don’t let operational convenience accidentally dictate your residency story.
- Capital discipline: Use CDN and BGP tuning to delay expensive moves, but not so long that latency and uptime begin to erode user trust and lifetime value.
Done well, your footprint evolves from a single Brazilian node into a resilient mesh where São Paulo, Buenos Aires, Santiago, Bogotá, and Lima each play defined roles, some as heavy origins, some as cache-first edge cities, all connected via predictable routes to the USA and Europe where your main customer base is located.
Plan your Brazil‑first server rollout
Get a tailored plan for São Paulo origins, CDN coverage, and BGP routing across South America. Our team maps latency, compliance, and capacity milestones to a phased buildout.
Get expert support with your services
Blog
Dedicated Servers for Decentralized Storage Networks
Decentralized storage stopped being a curiosity the moment it started behaving like infrastructure: predictable throughput, measurable durability, and node operators that treat hardware as a balance sheet, not a weekend project. That shift tracks the market. Global Market Insights estimates the decentralized storage market at $622.9M in 2024, growing to $4.5B by 2034 (22.4% CAGR).
The catch is that decentralization doesn’t delete physics. It redistributes it. If you want to run production-grade nodes—whether you’re sealing data for a decentralized storage network or serving content over IPFS—your success is gated by disk topology, memory headroom, and the kind of bandwidth that stays boring under load.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Decentralized Storage Nodes: Where the Real Bottlenecks Live
You can spin up a lightweight node on a spare machine, and for demos that’s fine. But professional decentralized storage providers are solving a different problem: ingesting and proving large datasets continuously without missing deadlines, dropping retrievals, or collapsing under “noisy neighbor” contention.
The scale is already real. The Filecoin Foundation notes that since mainnet launch in 2020,the network has grown to nearly 3,000 storage providers collectively storing about 1.5 exbibytes of data. That’s 1.5 billion gigabytes distributed across thousands of independent nodes—far beyond hobby hardware.
That scale pushes operators toward dedicated servers because the constraints are brutally specific: capacity must be dense and serviceable (drive swaps, predictable failure domains); I/O must be tiered (HDDs for bulk, SSD/NVMe for the hot path); memory must absorb caches and proof workloads without thrashing; and bandwidth must stay consistent when retrieval and gateway traffic spike.
In other words: decentralized cloud storage isn’t “cheap storage from random disks.” It’s a storage appliance—distributed.
Decentralized Blockchain Data Storage

Decentralized blockchain data storage merges a storage layer with cryptographic verification and economic incentives. Instead of trusting a single provider’s dashboard, clients rely on protocol-enforced proofs that data is stored and retrievable over time. Smart contracts or on-chain deals govern payments and penalties, turning “who stored what, when” into a verifiable ledger rather than a marketing claim.
This is where centralized vs decentralized storage stops being ideological and becomes operational. Centralized systems centralize trust; decentralized storage networks distribute trust and enforce it with math. The price is heavier, more continuous work on the underlying hardware: generating proofs, moving data, and surviving audits.
Explaining How Decentralized Cloud Storage Works With Blockchain Technology
Decentralized cloud storage uses a blockchain (or similar consensus layer) to coordinate contracts and incentives among independent storage nodes. Clients make storage deals, nodes periodically prove they still hold the data, and protocol rules handle payments and penalties. The chain anchors “who stored what, when” and automates enforcement—without a single trusted storage vendor.
Under the hood, production nodes behave like compact data centers. You’re not just “hosting files”; you’re running data pipelines: ingest payloads, encode or seal them, generate and submit proofs on schedule, and handle retrieval or gateway traffic. The blockchain is the coordination plane and the arbiter; the hardware has to keep up.
Deployment Is Getting Faster—and More OPEX‑Friendly
The industry trend is clear: shorten the time between “we want to join the network” and “we’re producing verified capacity.” In one Filecoin ecosystem example, partners offering predefined storage‑provider hardware and hosted infrastructure cut time‑to‑market from 6–12 months to 6–8 weeks, turning what used to be a full data‑center build into a matter of weeks. That shift reframes growth: you expand incrementally, treat infrastructure as OPEX, and avoid the “buy everything upfront and hope utilization catches up” trap.
A high‑performance dedicated server model fits that pattern. Instead of buying racks, switches, and PDUs, you rent single‑tenant machines in existing facilities, pay monthly, and scale out node fleets as protocol economics justify it.
| Factor | Build (CAPEX) | Rent (OPEX) |
|---|---|---|
| Upfront Cost | Large hardware purchase | Monthly or term spend |
| Deployment Time | Procurement + staging | Faster provisioning |
| Hardware Refresh | You fund and execute upgrades | Provider manages lifecycle |
| Scaling | Stepwise, slower | Add nodes as needed |
| Maintenance | Your ops burden | Shared support and replacement model |
| Best Fit | Stable, long‑run fleets | Fast expansion or protocol pilots |
Decentralized Content Identification and IPFS Storage

IPFS flips the addressing model: you don’t ask for “the file at a location”; you ask for “the file with this identity.” In IPFS terms, that identity is a content identifier (CID)—a label derived from the content itself, not where it lives. CIDs are based on cryptographic hashes, so they verify integrity and don’t leak storage location. This is content addressing: if the content changes, the CID changes.
In practical terms, decentralized file storage performance often comes down to where and how you run your IPFS nodes and gateways. Popular content may be cached widely, but someone still has to pin it, serve it to gateways, and move blocks across the network. If those “someones” are running on underpowered hardware with weak connectivity, you’ll see it immediately as slow loads and timeouts.
Bringing IPFS into production usually involves:
- Pinning content on dedicated nodes so it doesn’t disappear when caches evict it.
- Running IPFS gateways that translate CID requests into HTTP responses.
- Using S3 storage and CDNs in front of IPFS to smooth out latency + absorb read bursts.
That’s exactly where dedicated servers shine: you can treat IPFS nodes as persistent origin servers with high‑bandwidth ports, local NVMe caches, and large HDD pools—then rely on a CDN to fan out global distribution.
Hardware Demands in Practice: Build a Node Like a Storage Appliance
The winning architecture is boring in the best way: isolate hot I/O from cold capacity, avoid resource contention, and over‑provision the parts that cause cascading failures.
Decentralized Storage Capacity Is a Disk Design Problem First
Bulk capacity still wants HDDs, but decentralized storage nodes are not just “a pile of disks.” Filecoin’s infrastructure docs talk explicitly about separating sealing and storage roles, and treating bandwidth and deal ingestion as first‑class design variables. The pattern is roughly:
- Fast NVMe for sealing, indices, and hot data.
- Dense HDD arrays for sealed sectors and archival payloads.
- A topology that lets you replace failed drives without jeopardizing proof windows.
Memory Is the Shock Absorber for Proof Workloads and Metadata
Proof systems and high-throughput storage stacks punish tight memory budgets. In Filecoin’s reference architectures, the Lotus miner role is specified at 256 GB RAM, and PoSt worker roles are specified at 128 GB RAM—a blunt signal that “it boots” and “it proves on time” are different targets.
Bandwidth Isn’t Optional in a Decentralized Storage Network
Retrieval, gateway traffic, replication, and client onboarding all convert to sustained egress. Filecoin’s reference architectures explicitly call out bandwidth planning tied to deal sizes, because bandwidth is part of whether data stays usable once it’s stored.
A snapshot of what “serious” looks like: the Filecoin Foundation profile of a data center describes a European storage-provider facility near Amsterdam contributing 175PiB of capacity to the network, connected via dark fiber links into Amsterdam, and serving 25 storage clients. That is pro-grade infrastructure being used to power decentralized storage.
Melbicom runs into this reality daily: the customers who succeed in production are the ones who provision for sustained operations, not peak benchmarks. Melbicom’s Web3 hosting focus is built around that exact profile—disk-heavy builds, real memory headroom, and high-bandwidth connectivity tuned for decentralized storage nodes.
Web3 Storage Scales on the Same Basis as Every Other Storage System

Decentralized storage networks are converging on mainstream expectations: consistent retrieval, verifiable durability, and economics that can compete with traditional cloud storage—without collapsing into centralized control. The way you get there is not mysterious: tiered disks, sufficient memory, and bandwidth that can carry both ingest and retrieval without surprises.
Dedicated servers are the pragmatic bridge between decentralized ideals and decentralized cloud storage as a product. They turn node operation into engineering: measurable and scalable. Whether you are running Filecoin storage providers, IPFS gateways, or other decentralized storage network roles, the playbook looks like any serious storage system—just deployed across many independent operators instead of a single cloud.
Practical Infrastructure Recommendations for Decentralized Storage
- Treat nodes as appliances, not pets. Standardize a small number of server “shapes” (e.g., sealing, storage, gateway) so you can scale and replace them predictably.
- Tier storage aggressively. Put proofs, indices, and hot data on NVMe; push sealed or archival sectors to large HDD pools. Avoid mixing hot and cold I/O on the same disks.
- Over‑provision memory for proofs. Aim for RAM budgets that comfortably cover proof processes, OS, observability, and caching—especially on sealing and proving nodes.
- Size bandwidth to your worst‑case retrieval. Design for sustained egress and replication under peaks; use 10+ Gbps ports where retrieval/gateway traffic is critical.
- Plan for regional and provider diversity. Distribute nodes across multiple DCs and regions when economics justify it, to reduce latency and mitigate regional failures.
Deploy Dedicated Nodes for Web3 Storage
Run decentralized storage on single-tenant servers with high bandwidth, NVMe, and dense HDDs. Deploy Filecoin and IPFS nodes fast with top-tier data centers and unmetered ports.
Get expert support with your services
Blog

GPU-Optimized Servers for ZK Proofs & Web3 Research
Zero-knowledge proofs (ZKPs) have moved from “clever crypto demo” to production infrastructure: ZK-rollups, privacy-preserving DeFi, ZK-based identity, and data-availability schemes all rely on generating proofs at scale. That’s a specific hardware problem: parallel compute, huge memory bandwidth, and a predictable environment.
Recent work on GPU-accelerated ZKP libraries shows proof generation speed-ups ranging from roughly 1.2× to over 8× (124%–713% faster) versus CPU-only runs for practical circuits. GPU-centric studies find that well-tuned GPU implementations can drive up to ~200× latency reductions in core proving kernels compared to CPU baselines. And production deployments of CUDA-based ZK libraries report roughly 4× overall speed-ups for real-world Circom proof generation.
Those gains only turn into real-world value when the GPUs sit inside dedicated, well-balanced servers: high-core-count CPUs to orchestrate the pipeline, ample RAM to keep massive cryptographic objects in memory, NVMe storage for chain data and proving keys, and strong networking to move proofs and state quickly.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
This is where Melbicom’s GPU-powered dedicated servers come in. We at Melbicom run single-tenant machines in 21 Tier III+ data centers across Europe, the Americas, Asia, and Africa. For ZK proofs, that combination of GPU density, memory, and predictable network paths is what turns “interesting benchmarks” into production-ready proving infrastructure.
What GPU Configuration Optimizes Zero-Knowledge Proof Performance
The optimal GPU setup for zero-knowledge proof generation combines massive parallelism, high memory bandwidth, and large VRAM capacity. For zk proofs, that means modern NVIDIA GPUs (24–80 GB) in dedicated servers, paired with fast host memory and I/O so the GPU can continuously process MSMs, FFT/NTT steps, and proving keys without stalling.
Most of the heavy lifting in ZK proofs comes from multi-scalar multiplication (MSM) and Number-Theoretic Transform (NTT) kernels. Studies of modern SNARK/STARK stacks show these two primitives can account for >90% of prover runtime, which is why GPU implementations dominate end-to-end performance.
A good GPU layout for ZK proofs focuses on:
- Core count and integer throughput. For large circuits, you want tens of thousands of CUDA cores working in parallel. An RTX 4090, for example, exposes 16,384 CUDA cores and pushes up to 1,008 GB/s of GDDR6X bandwidth.
- VRAM capacity. Real-world ZK benchmarks show curves and circuits that can consume 20–27 GB of VRAM during proof generation. That immediately rules out older 6–8 GB cards for bigger circuits or recursive proofs; 24 GB is a practical minimum, and 48–80 GB becomes essential for very large proving keys or deep recursion.
- Memory bandwidth. Data-center GPUs like NVIDIA A100 80 GB ship with HBM2e and deliver on the order of 2 TB/s memory bandwidth, making them ideal for MSM/NTT-heavy workloads that are fundamentally bandwidth bound.
Topology matters as well. ZK stacks today are usually optimized for one GPU per proof, not multi-GPU sharding of a single circuit. That means:
- One GPU per box works well for single, heavy proofs (zkEVM traces, recursive rollups).
- Multiple GPUs per server are ideal when you want to run many independent proofs concurrently – batched rollup proofs, per-wallet proofs, or proof markets.
We at Melbicom see most advanced teams standardizing on 1–2 high-end GPUs per server, then scaling out horizontally across many dedicated machines instead of fighting the complexity of multi-GPU kernels before the prover stack is ready.
Which Server Specifications Support Large-Scale ZK Computations
A ZK prover node is effectively a specialized HPC box: it streams huge matrices and vectors through heavy algebra kernels under strict latency or throughput requirements. To keep the GPUs saturated, the server around them needs balanced, predictable, stable performance.
The ideal ZK-focused server is built around three pillars: high-core-count CPUs, large RAM pools, and fast storage/networking. The goal is simple: never let the GPU wait on the CPU, memory, or disk—especially when proving windows or test campaigns are time-bound.
ZK Prover Server Baseline
Here’s a concise baseline for ZK proof and ZK-proof blockchain workloads:
| Component | Role in ZK / Blockchain Workloads | Recommended Specs for Heavy ZK Proofs |
|---|---|---|
| GPU | Runs MSM/NTT and other parallel cryptographic kernels; holds proving keys & witnesses | Latest-gen NVIDIA GPU with 24–80 GB VRAM and high bandwidth (e.g., RTX 4090 / A‑class), 1–2+ GPUs per server depending on parallelism needs |
| CPU | Orchestrates proving pipeline, node logic, preprocessing, I/O | Modern 32–64‑core AMD EPYC / Intel Xeon, strong single-thread performance, large cache |
| RAM | Stores constraint systems, witnesses, proving keys, node data | 128 GB+ DDR4/DDR5, with 256 GB recommended for large circuits or multiple concurrent provers |
| Storage | Holds chain data, proving keys, artifacts, logs | NVMe SSDs for high IOPS and low latency; multi‑TB if you keep full history or large datasets |
| Network | Syncs blockchain state, exchanges proofs, connects distributed components | Dedicated 10–200 Gbps port, unmetered where possible, with low-latency routing and BGP options |
CPU and RAM: Feeding the GPU
Even with aggressive GPU offload, the CPU still:
- Builds witnesses and constraint systems
- Schedules batches and manages queues
- Runs node clients, indexers, or research frameworks
- Handles serialization, networking, and orchestration
A low-core CPU turns into a bottleneck as soon as you run multiple concurrent provers or combine node operation with research workloads. Moving to 32–64 cores allows CPU-heavy stages to overlap with GPU kernels and keeps accelerators busy instead of stalled.
RAM is the other hard constraint. Proving keys, witnesses, and intermediate vectors for complex circuits can easily consume tens of gigabytes per pipeline. Once the OS starts swapping, your effective speed-up vanishes. That’s why ZK-focused machines should treat 128 GB as the floor and 256 GB as a comfortable baseline for intensive zk proofs and ZK-proof blockchain experiments.
We at Melbicom provision GPU servers with ample RAM headroom and current-generation EPYC/Xeon CPUs so research teams can keep entire circuits, proving keys, and node datasets resident in memory while running multiple provers side by side.
Storage and Networking: Moving Proofs and State
For ZK-heavy Web3 stacks, disk and network throughput are first-class design parameters:
- Storage: NVMe SSDs cut latency for accessing chain state, large proving keys, and data-availability blobs. This matters when you repeatedly regenerate proofs, replay chain segments, or run ZK proofs crypto experiments across big datasets.
- Networking: Proof artifacts (especially STARKs) can be tens of megabytes. Rollup sequencers, DA layers, and validators all stream data continuously. Without sufficient bandwidth, proof publication and state sync become the new bottleneck.
Melbicom runs its servers on a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs, exposing unmetered, guaranteed bandwidth on ports up to 200 Gbps per server. Because these are single-tenant bare-metal servers in Tier III/IV facilities, Melbicom’s environment avoids hypervisor noise and noisy neighbors. That determinism is particularly important when you’re trying to reproduce ZKP research results or hit on-chain proving SLAs reliably.
How to Select GPUs for Blockchain Research Workloads
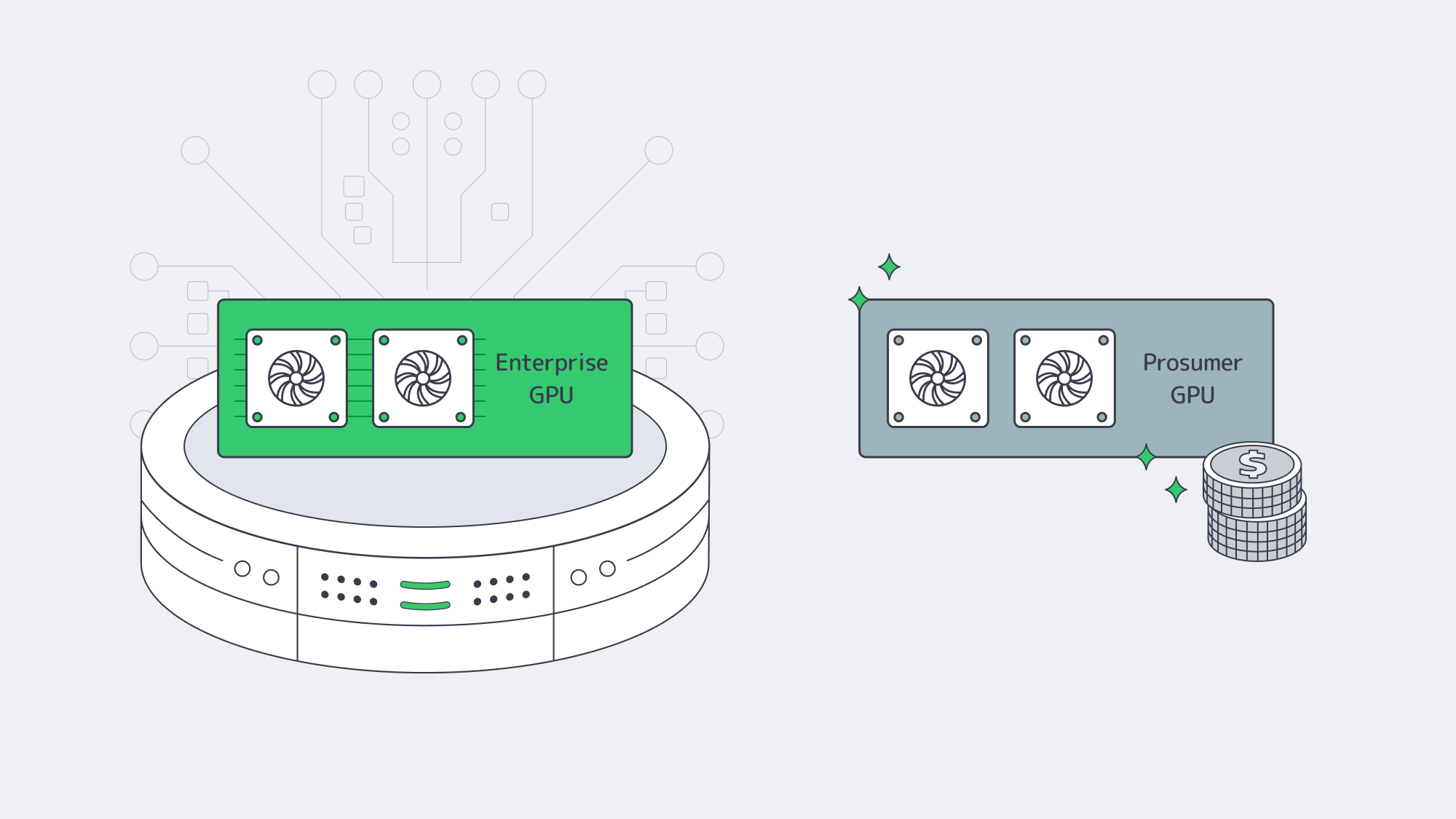
The right GPU for blockchain and ZK research balances compute density, memory capacity, and total cost of ownership. For many ZK workloads, modern NVIDIA GPUs with 24–80 GB VRAM strike the best trade-off, with enterprise GPUs favored for the highest-capacity proofs and prosumer GPUs used where cost efficiency and flexibility matter more than capacity.
In broad strokes:
- For very large circuits, deep recursion, or rollup-scale proofs in production, A‑class data‑center GPUs (such as A100 80 GB) are ideal. They combine 80 GB of high-bandwidth memory and >2 TB/s bandwidth, making them suitable for massive proving keys and wide NTTs.
- For lab clusters and mid-scale prover fleets where proofs fit in ~24 GB, RTX 4090-class GPUs are compelling. A single 4090 offers 24 GB of GDDR6X with ~1,008 GB/s bandwidth and 16,384 CUDA cores, providing excellent throughput at a far lower unit cost than data-center cards.
Economically, this often leads to a two-tier model:
- Development and research fleets built on 24 GB GPUs (e.g., for protocol experiments, circuit iteration, or testnets).
- Production prover clusters that add A‑class GPUs where circuits or recursion depth demand larger memory footprints or higher concurrency.
GPU-accelerated libraries like ICICLE, which underpin production provers, have already shown multi‑× speed-ups at the application level: one case study reports 8–10× speed-up for MSM, 3–5× for NTT, and about 4× overall speed improvement in Circom proof generation after integrating ICICLE. That kind of uplift is what makes it practical to move more proving work off-chain or into recursive layers.
Parallelism strategy also shapes the hardware plan. Because most proving systems today are optimized for one GPU per proof, it’s usually easier to:
- Run multiple independent proofs per server (one per GPU), or
- Scale out across many GPU servers, rather than complex multi-GPU sharding inside a single proof.
We at Melbicom keep dozens of GPU-powered server configurations ready to go—ranging from single‑GPU boxes to multi‑GPU workhorses—and can assemble custom CPU/GPU/RAM/storage combinations in 3–5 business days for more specialized ZK and blockchain research workloads.
Key Infrastructure Takeaways for ZK Proofs
For teams designing serious ZK-proof and ZK proof blockchain infrastructure, a few practical takeaways consistently show up in the field:
- Standardize GPUs as the default proving backend. MSM and NTT dominate proving time and map naturally to thousands of GPU threads; recent work shows GPU-accelerated ZKPs reaching up to ~200× speed-ups over CPU baselines on core kernels.
- Over-provision RAM relative to your largest circuits. Assume per-pipeline working sets in the tens of gigabytes; plan for 128 GB minimum and 256 GB+ on nodes running concurrent provers, to avoid swapping + subtle failures in long-running proof workloads.
- Design networking as part of the proving system. High-throughput links (10–200 Gbps) with good peering are essential when proofs, blobs, and chain state move between sequencers, DA layers, and storage. Melbicom’s 14+ Tbps backbone with strong peering and BGP support is built to keep those paths short and predictable.
- Prefer dedicated, globally distributed infrastructure. Single-tenant GPU servers in Tier III+ sites give deterministic performance and stronger isolation than shared cloud. Combining those with a well distributed CDN lets you pin ZK frontends, proof downloads, and snapshots close to users while keeping origin traffic on-net.
These aren’t abstract “nice-to-haves” – they’re the baseline for hitting proving windows, reproducing research results, and operating complex ZK systems under production load.
Building ZK-Proof Infrastructure on Dedicated GPU Servers
Zero-knowledge proofs may be “just math,” but turning that math into scalable Web3 infrastructure is an engineering exercise in compute, memory, and networking. Dedicated GPU servers are the practical way to get there: they expose raw accelerator performance, enough RAM to keep large cryptographic structures in memory, and the predictable network capacity required to move data and proofs on time.
AsZK systems evolve—ZK-rollups moving more logic off L1, ZK VMs becoming more sophisticated, and more protocols adopting ZK techniques for privacy and scalability—the hardware bar will only rise. Teams that treat GPU-optimized servers as first-class infra today will be better positioned to run fast provers, adapt to new proving systems, and maintain a tight feedback loop between research and production deployments.
Deploy GPU ZK Servers Today
Spin up dedicated GPU servers in 21 Tier III+ locations with unmetered 10–200 Gbps ports. Fast activation for in‑stock hardware and custom builds in 3–5 days to power your ZK proving and blockchain research.
Get expert support with your services
Blog

Dedicated Multi-Region Infrastructure for Oracles and Bridges
Oracle and bridge services live in the gap between deterministic chains and nondeterministic reality: data sources change, networks jitter, servers reboot, and packets occasionally disappear. Yet users and contracts still expect “now,” not “eventually.” In practice, the infrastructure is part of the security model—because when attestations arrive late or inconsistent, trust erodes fast.
Modern oracle and bridge operators already know the hard part isn’t computing the answer; it’s delivering the same answer, everywhere, on time—across multiple chains, regions, and failure modes—without leaking keys or accepting silent data-feed drift.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
The Infra Problem: Trust Dies in the Jitter
Latency for oracle updates and cross-chain messaging isn’t one number. It’s a stack: ingest → normalize → sign/attest → broadcast → observe finality. Each stage has its own tail latency—and tails are where “near-100% uptime” quietly turns into a reliability incident.
The stakes are not theoretical. Infrastructure that enables millions of dollars in transaction value is less about marketing scale and more about operational expectation: once you’re a dependency, your failure modes become other people’s risk. And cross-chain is no longer a niche edge case. Today’s best practices obsess over operational hardening and key custody.
The takeaway: your latency budget and your failure budget are entangled. If you want fast, consistent delivery, you architect for the tail—not the median.
What Dedicated Infrastructure Minimizes Oracle and Bridge Latency

Dedicated infrastructure minimizes oracle and bridge latency by removing noisy-neighbor contention and by keeping hot-path services (ingest, signing, relays, and chain-facing RPC) on single-tenant machines with predictable CPU and I/O. The best setups treat latency like a budget: pin workloads per region, minimize cross-region hops, and keep failover paths warm—not theoretical.
The Practical Latency Budget: Where “Sub-Second” Gets Spent
- Inbound feed variability: API response jitter, rate limits, TLS handshake churn.
- Disk and queue pressure: state persistence, retry queues, log compaction.
- Cross-region coordination: quorum collection, threshold signing, finality watchers.
- RPC variability: shared endpoints, congestion, request throttling.
Dedicated servers help because you can shape the platform: reserve headroom, keep state on local NVMe, and isolate signing and quorum traffic from everything else.
Web3 Server Hosting That Treats the Network as a First-Class Component
If you’re running web3 applications that depend on real-time updates, your web3 infrastructure is not just compute—it’s routing discipline. This is where multi-region dedicated servers plus predictable networking matter.
Melbicom provides the building blocks that map to oracle/bridge needs: 21 Tier IV/III data centers, a 14+ Tbps backbone, and 20+ transit providers plus 25+ IXPs to reduce propagation delays and jitter between regions.
Example: a Concrete Multi-Region Topology
| Layer | Region Examples | What Matters Most |
|---|---|---|
| Ingest + Normalize | Amsterdam, Frankfurt | Keep collectors close to data sources; buffer aggressively; avoid shared queues. |
| Sign/Attest Quorum | Singapore, Los Angeles | Isolate signing; prefer deterministic I/O; keep quorum traffic on private paths. |
| Broadcast + Observe Finality | Tokyo, Stockholm | Fast chain-facing egress; stable RPC; region-local watchers for tail control. |
Locations above reflect some of Melbicom’s data centers and are shown as examples; pick regions that match the chains and venues you’re servicing.
Which Multi-Region Server Setup Ensures Near-100% Uptime
A near-100% uptime setup uses at least two independent regions with active-active service, plus a third region as a cold or warm backstop for disaster recovery. Critical services—signing, relays, and finality observation—should fail over automatically with stable endpoints, while state replication is continuous and tested. Uptime isn’t a promise; it’s engineered behavior.
Active-Active Isn’t Optional for Oracles and Bridges
The “single region + hot standby” model fails a basic reality check: even brief regional network events can create mismatched observations. For oracle operators, that shows up as delayed updates. For bridges, it shows up as relay lag and message backlog.
The modern pattern is:
- Active-active ingest and observation
- Regional quorum for signatures (threshold or multisig)
- Deterministic failover for client endpoints
The point isn’t only uptime. It’s keeping behavior stable under stress: same inputs, same outputs, same latency envelope.
Stable Endpoints: BGP Sessions, BYOIP, and Controlled Failover
If clients, contracts, or counterparties pin to endpoints, IP churn is operational debt. The clean way out is bringing your own IP space and controlling routing.
Melbicom supports BGP sessions (including BYOIP) so operators can keep endpoints stable while engineering regional preference and failover through routing changes rather than “change the URL and pray.”
What most CTOs care about is not that “BGP exists,” but routing safety and hygiene. This is where Melbicom delivers: RPKI validation and strict IRR filtering for customer routes—important guardrails when uptime is tied to the integrity of your route announcements.
State Replica That Doesn’t Become a Latency Tax
Replication is where good architectures die: either you replicate too slowly and failover loses state, or you replicate too eagerly and build a constant cross-region latency bill into every request.
A pragmatic pattern is asynchronous replication with fast catch-up and explicit RPO/RTO targets. That can be as simple as structured logs + object snapshots, or as involved as streaming replication—what matters is predictability and observability.
# Example: lightweight feed-state replication (operator-owned logic) # Goal: ship signed artifacts + last-seen checkpoints, not your entire database. rsync -az --delete /var/lib/oracle/checkpoints/ replica:/var/lib/oracle/checkpoints/ rsync -az --delete /var/lib/oracle/signed-artifacts/ replica:/var/lib/oracle/signed-artifacts/ |
When bandwidth is the constraint, location matters. Melbicom offers per-server port speeds up to 200 Gbps in most locations, which lets operators place replication-heavy tiers where the network headroom actually exists.
What Secure Hardware Protects Bridge Keys and Data Feeds
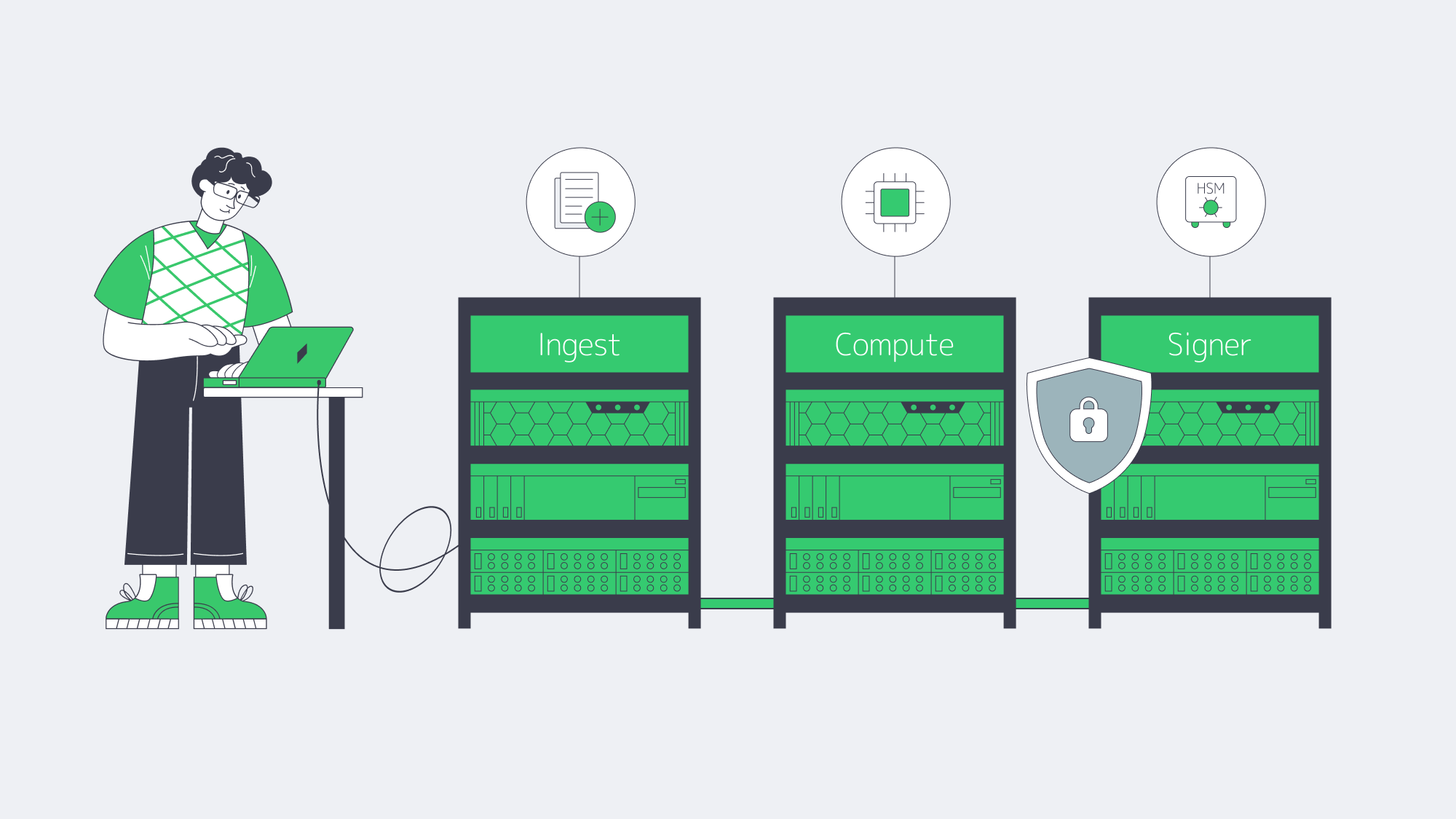
Secure hardware protects bridge keys and data feeds by isolating signing and sensitive processing onto single-tenant machines with locked-down access paths, hardware-backed key custody (such as HSM-backed operations), and strict separation between ingest, compute, and signing roles. The goal is blast-radius control: a compromised service shouldn’t expose keys or rewrite feeds.
Separate the Roles: Ingest ≠ Compute ≠ Sign
Most real incidents start with a “small” compromise: a collector host, a CI runner, a debug port. If ingest and signing share the same blast radius, you don’t have a key-management strategy—you have a hope-based security model.
Best practice is boring and effective:
- Ingest nodes can be replaced quickly; they should not hold signing material.
- Normalization nodes should have restricted egress and strict provenance controls.
- Signing nodes should be isolated, minimal, and auditable.
Dedicated servers make this separation more enforceable because you’re not sharing kernel neighbors or relying on a provider’s abstraction layer for isolation.
Hardware-Backed Key Custody Without Slowing the Hot Path
For bridges and high-stakes oracles, hardware-backed key operations reduce the chance that a software compromise becomes a key compromise. The operational trick is designing it so the signer remains fast and predictable: isolate it, keep it warm, and avoid forcing every request through cross-region round-trips.
Melbicom gives you in-region control and root-level access in Tier III+ DCs, along with stable networking: private links and BGP sessions that help keep the signaling path deterministic.
Data Feed Integrity: “Correct” Must Be Verifiable, Not Just Fast
- Multiple sources with explicit quorum logic
- Signed artifacts with traceable provenance
- Replay protection and deterministic ordering
- Continuous validation (detect drift, missing updates, and timestamp anomalies)
This is the difference between “a fast feed” and “a feed you can defend.”
FAQ
How do I know whether latency is a compute problem or a network problem?
Instrument the hot path end-to-end and split metrics by stage (ingest, normalize, sign, broadcast, finality). If p95 spikes correlate with cross-region hops or RPC response variability, it’s networking and topology—not CPU.
Is multi-region always worth the complexity?
For oracle and bridge operators, yes—because your failure modes are externalized. The complexity is the price of keeping outputs consistent under partial failures.
What’s the minimum multi-region footprint that still behaves well?
Two active regions + one backstop. Anything less turns “failover” into downtime plus cold-start latency.
Where does a CDN fit in this stack
Not for signing or quorum, but for distributing non-sensitive artifacts: dashboards, proofs, snapshots, static content, and client-side assets that should load fast globally. Melbicom’s CDN footprint spans 55+ PoPs across 36 countries.
Bridge Oracle Crypto: Key Takeaways for Low-Latency Trust
- Design for the tail, not the mean. Your p95/p99 latency is what users experience during congestion, RPC turbulence, and partial outages—so measure per stage and budget headroom intentionally.
- Run active-active where correctness matters. Two regions observing and relaying independently reduces “regional truth” drift and prevents one site’s network event from becoming system-wide lag.
- Keep endpoints stable through routing, not DNS scramble. Treat BGP-controlled failover as an operational primitive so clients don’t need reconfiguration during incidents.
- Isolate signing like it’s production finance—because it is. Separate ingest/compute/sign roles and assume any internet-facing node can be compromised.
- Practice failover as a routine operation. Define RPO/RTO, test replay scenarios, and rehearse key procedures so the first “real” failover isn’t also your first experiment.
Trust Is Built at the Speed of Your Infrastructure
Oracles and bridges don’t just use infrastructure—they are infrastructure. When latency spikes, updates arrive late. When uptime wobbles, counterparties lose confidence. And when keys or feeds aren’t protected by design, operational mistakes become systemic risk.
The durable pattern is consistent: dedicated servers for predictable performance, multi-region layouts that keep the hot path close to where it must execute, and hardened signing and data-feed boundaries that keep trust intact even when everything around gets noisy.
Deploy multi-region dedicated servers
Design for the tail with dedicated servers, stable BGP endpoints, and warm failover across regions. Keep keys isolated and updates consistent—without unpredictable jitter.
Get expert support with your services
Blog

Scaling Blockchain Analytics & Indexing with Dedicated NVMe-Powered Servers
Blockchain analytics has hit a true big‑data scale. A pruned Ethereum full node now holds 1.4 TB of data, up more than 22% year‑over‑year, based on Etherscan metrics tracked by YCharts. Archive‑style Ethereum nodes can require over 21 TB of disk, and Solana’s ledger has already exceeded 150 TB of history. Ethereum alone processes roughly 1.5–1.6 million transactions per day, more than 23% higher than a year ago.
On the demand side, the crypto compliance and blockchain analytics market is projected to grow from $4.4 billion in 2025 to nearly $14 billion by 2030 (25.85% CAGR). Put together, that’s more chains, more activity, and far heavier datasets landing on your infrastructure every month.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Keeping up with that reality requires high‑performance dedicated servers: multi‑core CPUs, large RAM pools, fast NVMe SSDs, and serious bandwidth in predictable, single‑tenant environments. Melbicom builds specifically for this profile with single‑tenant servers across 21 Tier IV/III data centers, a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs, and 55+ CDN PoPs in 36 countries that push data closer to users.
Blockchain and Analytics
A blockchain is an append‑only log of everything that has ever happened: transfers, swaps, liquidations, governance votes, NFT mints. Blockchain analytics is about turning that log into structured data that powers dashboards, risk models, and compliance workflows.
Most serious stacks follow an ETL pattern:
- Extract blocks, transactions, logs, and state diffs from nodes across many chains.
- Transform them into normalized tables (addresses, token transfers, positions, fees).
- Load them into OLAP engines, column stores, or time‑series databases for aggregations.
Academic work on blockchain data analytics repeatedly highlights scalability, data accessibility, and accuracy once datasets reach multi‑terabyte size. Add multi‑chain and multi‑year history, and you’re firmly in big‑data territory.
In practice, modern platforms resemble web‑scale analytics systems: parallel ETL workers feeding NVMe‑backed warehouses, with query engines distributing scans across many cores. The bottleneck stops being “can we parse this?” and becomes “can our infrastructure ingest and query on‑chain data fast enough?”
What Server Specs Maximize Blockchain Indexing Throughput
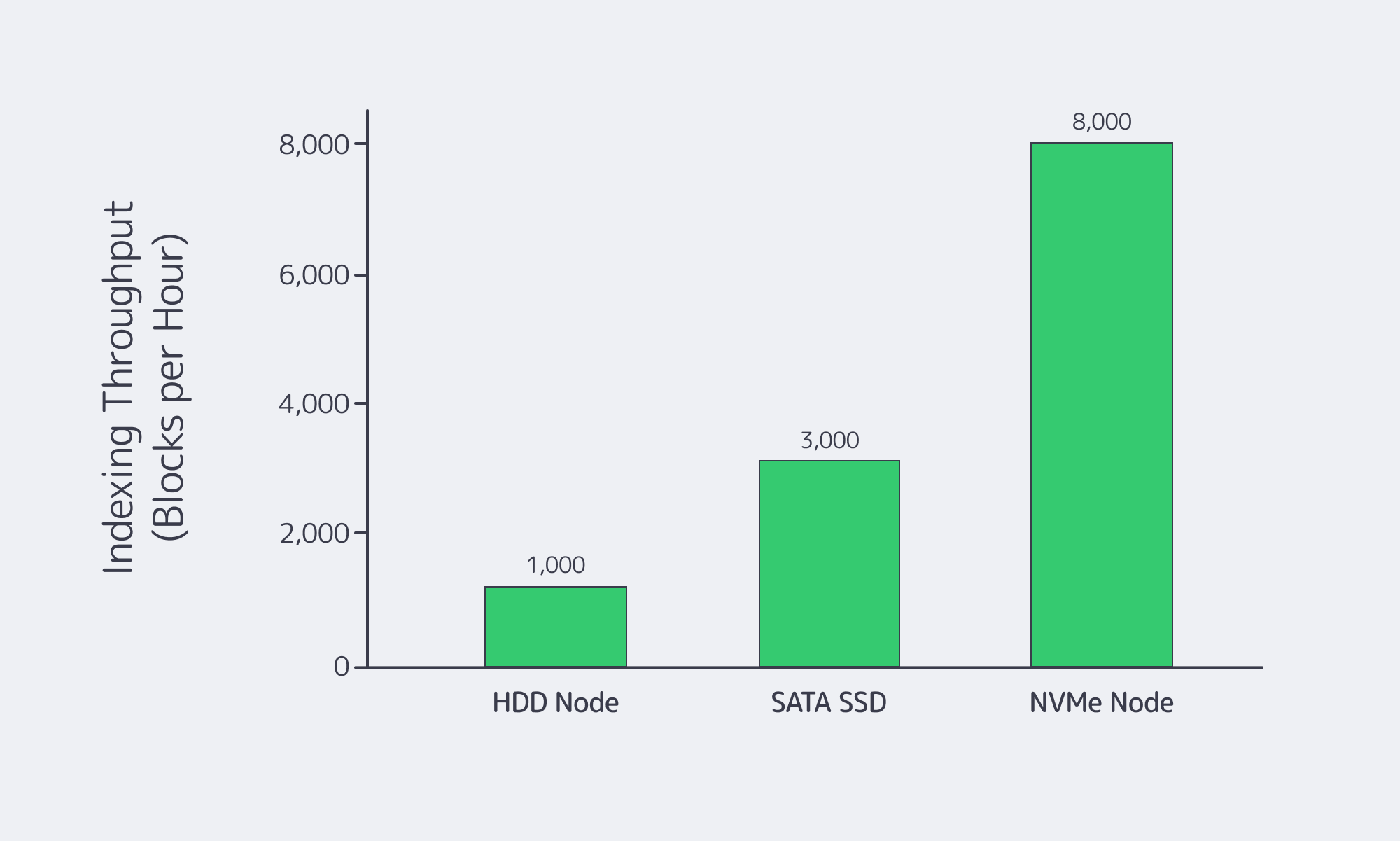
You want high‑core, high‑clock CPUs paired with generous RAM, NVMe SSDs, and high‑bandwidth networking on dedicated servers. That combination lets you parallelize indexing and ETL, keep hot state in memory, and avoid disk or network bottlenecks as chains, users, and queries scale.
CPU and Parallelism
Indexers parallelize naturally: one process per chain, per contract family, or per ETL stage. A 32‑ or 64‑core CPU lets you run many workers concurrently, while single‑thread speed still matters for replaying blocks and verifying signatures.
For Ethereum‑style workloads, the sweet spot is having many strong cores. We at Melbicom lean on the latest‑generation AMD EPYC options in Web3‑optimized builds so multiple nodes and ETL workers can share a host without sacrificing per‑thread performance.
Memory and Caching
Memory is the first line of defense against slow storage. Node clients and indexers cache as much state as RAM allows so they don’t hit disk on every lookup. Operator guides explicitly warn not to “skimp” on memory because extra RAM directly reduces disk I/O.
For multi‑chain analytics, 64–128 GB is a practical baseline, while high‑throughput chains such as Solana often push validators and RPC nodes toward 256 GB+ configurations. That headroom benefits both nodes and analytics engines by keeping large joins in memory instead of thrashing NVMe.
Storage, Network, and Why NVMe Is Non‑Negotiable
Storage and network are where indexing pipelines either fly or stall. Full and archival nodes on major chains now routinely sit in the multi‑terabyte range. That load makes storage throughput and network latency first‑class constraints.
Fast NVMe SSDs are effectively mandatory. Node‑operator guides recommend NVMe over SATA SSDs and warn that network‑attached storage introduces latency that is “highly detrimental” during sustained writes. On the network side, guidance for high‑throughput validators and RPC nodes calls for 10 Gbps or better connectivity and low‑latency routing.
Melbicom’s backbone is designed around those requirements: more than 14 Tbps of capacity, 20+ transit providers, 25+ IXPs, and per‑server ports up to 200 Gbps in most DC locations. That combination keeps nodes in sync with chain heads and absorbs traffic spikes from analytics APIs.
Dedicated, Single‑Tenant Environments
Dedicated servers remove noisy‑neighbor effects and hypervisor overhead that can skew latency and throughput. For long‑running node and ETL processes, that predictability is crucial: when you profile a bottleneck, you know it comes from your schema or code, not someone else’s workload.
Melbicom’s Web3‑ready configurations are single‑tenant by default and spread across 21 Tier IV/III locations in Europe, the Americas, Asia, the Middle East, and Africa, so teams can place heavy analytics nodes close to users and liquidity.
Table 1. Server Components That Actually Move the Needle
| Component | Role in Pipeline | Why High‑End Specs Matter |
|---|---|---|
| CPU (Cores & GHz) | Runs node clients, parsers, ETL workers | More cores and faster threads cut block processing time. |
| RAM | Caches state and query working sets | Large memory reduces disk hits during indexing and queries. |
| NVMe SSD | Stores chain DBs and analytics datasets | High IOPS keeps multi‑TB syncs and scans responsive. |
| Network Uplink | Moves blocks in and query results out | 10–200 Gbps links prevent sync lag and API timeouts. |
| Single‑Tenant Dedicated Hardware | Provides isolated, predictable resources | Dedicated servers avoid noisy neighbors and virtualization drag. |
Which NVMe Configuration Speeds On-Chain Analytics Queries
You want fast, local, enterprise‑grade NVMe—often more than one drive—and a layout that separates hot analytics reads from heavy write paths. Avoid cheap, DRAM‑less or QLC models, and keep network storage out of the critical query path whenever possible if you care about latency, stability, and query speed.
Multiple NVMe Drives for Parallel I/O
Analytics workloads are highly parallel: workers scan different partitions while nodes append new blocks and ETL jobs compact or re‑index tables. Spreading that activity across multiple NVMe drives—via separate volumes or RAID0—lets the kernel and controllers service more I/O queues in parallel.
A practical layout:
- NVMe 0: chain databases (Ethereum, L2s, Solana, etc.)
- NVMe 1: analytics warehouse (columnar or time‑series DB)
- NVMe 2: ETL scratch space and logs
This separation prevents a heavy analytical query from starving the node’s state updates.
Enterprise NVMe Over Consumer Shortcuts
Under indexing loads, you’re writing and rewriting terabytes. Consumer QLC drives often fall off a cliff under sustained writes or hit endurance limits early. Node‑hardware guides recommend fast NVMe and warn that cheaper flash “suffers significant performance degradation during sustained writes,” with network storage adding harmful latency on top.
Enterprise-grade TLC NVMe SSDs with DRAM caches and high TBW ratings are a safer baseline. They help keep IOPS high even while you backfill years of history and serve live queries at the same time.
Local NVMe Plus Object Storage for Cold Data
Not every byte needs NVMe forever. Historical partitions older than a certain horizon may see limited traffic outside audits and backtesting.
A pragmatic design is:
- Keep the active window (recent blocks and hot tables) on local NVMe.
- Offload older partitions and periodic snapshots to S3‑compatible object storage.
Melbicom’s S3‑compatible object storage runs in a Tier IV certified Amsterdam data center, uses NVMe‑accelerated storage, and offers plans from 1 TB to 500 TB with free ingress. That keeps the hot analytics tier lean and fast while still retaining full history for compliance and long‑horizon research.
DeFi Llama and Blockchain Analytics
DeFi Llama shows what scaled blockchain and analytics looks like in production. The platform tracks DeFi metrics across hundreds of chains and thousands of projects and pools, which is only possible because indexing is continuously happening underneath every chart, table, and leaderboard users see.
Much of that work flows through The Graph. Many protocols expose subgraphs; DeFi Llama queries those instead of raw nodes. The Graph’s network has processed more than one trillion queries and supports thousands of active subgraphs across DeFi, NFTs, DAOs, gaming, and analytics.
Behind the scenes sit full and archival nodes, indexers that parse events into structured stores, and query engines that fan out across cores and NVMe to answer user requests. Any team aiming to provide similar multi‑chain views has to assume that per‑chain data volumes, query concurrency, and historical lookback windows will keep climbing—and size infrastructure accordingly.
Scaling Blockchain Analytics With High-Performance Servers

On‑chain data volumes are not slowing down. New L1s, L2s, and app‑chains add their own multi‑terabyte histories, while existing networks keep compounding. The only sustainable way to keep ETL jobs and queries in step with reality is to run them on high‑performance dedicated servers rather than undersized, oversubscribed instances.
Multi‑core CPUs let you parallelize ingestion and transformation. Large RAM footprints keep hot state and query working sets in memory. NVMe SSDs keep multi‑terabyte syncs and scans practical. High‑bandwidth, well‑peered networks prevent your nodes from falling behind chain heads or rate‑limiting analytics traffic.
For teams designing or scaling analytics pipelines, a few principles stand out:
- Design for multi‑chain growth. Plan for dozens of chains and terabytes of new data per year from day one.
- Make NVMe mandatory. Use multiple NVMe drives and clear hot/cold storage tiers; don’t rely on network storage for hot paths.
- Treat bandwidth as a product feature. 10 Gbps+ uplinks and clean peering reduce sync times and API latency under load.
- Choose predictable, single‑tenant servers. Deterministic performance simplifies capacity planning, SLOs, and debugging.
Scale blockchain analytics with Melbicom
Deploy high‑core CPUs, NVMe storage, and 10–200 Gbps networking across 21+ data centers. Get predictable, single‑tenant performance for nodes, ETL, and OLAP.
Get expert support with your services
Blog

Blueprint: Brazil Hub, Regional PoPs, Smarter Routing
South America is no longer a “far edge.” Mobile internet users in Latin America almost doubled from about 230 million to nearly 400 million between 2014 and the mid-2020s. Most of the platforms looking at the region already run their main origins in Europe or the U.S. — and now need a CDN footprint in South America that doesn’t collapse under cross-continent latency.
For those teams, the strategy hinges on three levers: PoP placement across South America, inter‑country routing around a Brazilian hub, and origin consolidation with Europe/US as global cores and Brazil as the regional shield. The rest is plumbing.
South America CDN— Reserve origin nodes in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
Which South American PoP Layout Best Reduces Cross-Continent Latency?
A South America CDN layout should treat São Paulo as the regional hub for traffic coming from existing origins in Europe or the US (let’s use Madrid or Atlanta as examples), then fan out to edge PoPs in cities like Lima, Bogotá, Baires, and Santiago. The objective is simple: keep users in-region while long-haul flows ride the cleanest cables into Brazil.
IX.br’s trajectory explains the role of Brazil. In April 2025, the national IXP fabric hit 40 Tbps peak traffic, with IX.br São Paulo alone exceeding 25 Tbps. That makes SP the natural gravity well for an edge node: place a strong PoP where most of the packets converge.
Modern CDN planning for South America also has to factor in undersea routes. EllaLink’s direct connection between Brazil and Portugal delivers a latency reduction of up to 50% between Latin America and Europe, with RTT under 60 ms between Portugal and Brazil. That turns Brazil into both a regional hub and a clean bridgehead for Madrid‑hosted origins.
For a pan‑regional CDN rollout in South America, a pragmatic pattern looks like this:
- Anchor PoP in São Paulo – which can act as a consolidated regional shield pulling from Madrid or Atlanta origins and feeding the rest of the continent.
- Regional PoPs in Lima, Bogotá, Buenos Aires, and Santiago – existing Melbicom PoPs in these metros shorten last‑mile paths and reduce dependence on long‑haul routes for users outside Brazil.
- Optionally, cable‑adjacent PoPs near landing points (for example on the Brazilian coast) when your cross‑continent flows are especially latency‑sensitive.
The result: users almost always land on a local or near‑local PoP, and the PoPs maintain short, predictable paths into São Paulo and then out to origins in Madrid or Atlanta.
How Should Traffic Be Routed Between Countries Around Brazilian Origin Hubs?
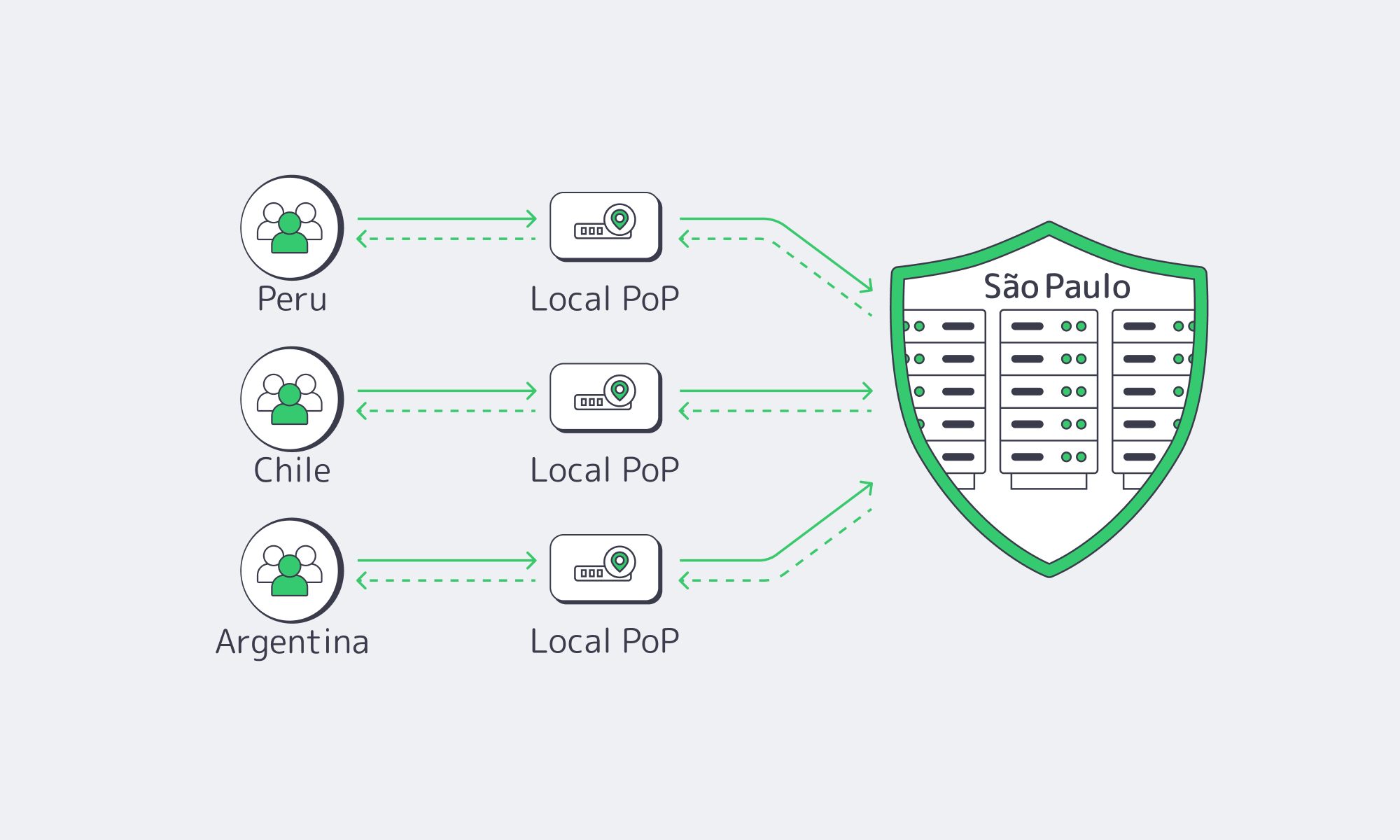
Inter‑country routing should keep packets on South American roads as long as possible. Users attach to the nearest anycast PoP; cache misses travel over regional links to a Brazilian shield in São Paulo, which in turn pulls from European or American origins. BGP policies prevent surprise trombones through distant transit hubs.
The failure mode you want to avoid is classic: a user in Argentina hits content hosted in Spain or the U.S. via a convoluted path that bounces through Miami or random Tier‑2s, turning every click into a 150 ms round‑trip. Properly run, a CDN service in South America does the opposite:
- Anycast on the edge so users in Chile, Peru, or Colombia hit the nearest regional PoP, not North America.
- Brazil as a regional origin hub from the CDN’s perspective: PoPs in Lima, Bogotá, Buenos Aires, and Santiago fetch from a consolidated shield in São Paulo, which in turn talks to Madrid and Atlanta origin clusters over optimized long‑haul.
- Local and regional peering across Latin American IXPs to keep inter‑PoP and PoP‑to‑Brazil traffic inside the continent wherever possible.
This is where routing control matters. A capable CDN provider for South America should expose enough knobs—BGP policies, local‑pref, MEDs—to bias traffic toward regional peers and away from noisy or congested upstreams. Melbicom’s BGP Session service provides free BGP sessions on dedicated servers, IPv4/IPv6, BYOIP, and support for full, default, or partial routes, available in every data center. That’s what allows you to pull Madrid/Atlanta origins into your own routing policy instead of letting transit pick arbitrary paths.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
Resilience rides on multi‑origin thinking. Practically, that means:
- Maintaining at least two independent origin clusters (for example, Madrid + Atlanta) behind the South American shield.
- Using CDN origin pooling and health checks so PoPs fail over cleanly if one of the origin clusters has trouble.
- Defining BGP failover policies that favor alternative regional paths before crossing ocean borders unnecessarily.
From a South American user’s perspective, the priority is consistent, low‑variance RTT—whether the byte actually came from a cache in Santiago or an origin in Madrid via São Paulo is just an implementation detail.
Which KPIs and Traffic Forecasts Should Drive a South America CDN Strategy?

The KPIs that actually move the needle in South America are latency, cache hit ratio, throughput headroom, and availability, all tied to realistic cross‑continent traffic forecasts. Design for video‑heavy, mobile‑first demand, then add capacity and PoPs based on measured TTFB, cache offload, and how quickly long‑haul links saturate.
Latency. Inside Brazil, a realistic target is <50 ms RTT, and <100 ms across major LatAm metros when traffic stays on regional routes and hits a local PoP. With direct systems like EllaLink, Europe–Brazil RTT drops below 60 ms and latency improves by up to 50% versus indirect North American paths.
Cache and origin offload. For a modern CDN in South America, a 90–98% cache hit ratio is achievable on well‑tuned workloads; anything lower usually means TTLs, hierarchy, or routing need work. The practical metric: what % of bytes bound for South American users are served from regional PoPs versus being dragged from Madrid or Atlanta on every miss?
Capacity and per‑server bandwidth. That scale needs serious ports. In Madrid, Melbicom’s dedicated servers come with 1–40 Gbps of bandwidth per unit and more than 100 ready-to-go configurations. Our Atlanta facility supports 1–200 Gbps per server with dozens of stock builds, ideal as a U.S. Southeast origin anchor. Overall, Melbicom offers dedicated servers in 21 Tier III/IV data centers and CDN PoPs in 55+ locations.
Availability and control. Finally, measure per‑PoP uptime, time‑to‑reroute during incidents, and how much routing control you actually have. BGP sessions with BYOIP in every data center let you keep consistent addresses and steer around degraded carriers without touching application code.
Key Metrics and Considerations for a South America CDN Strategy
| Metric/Factor | Target / Example | Strategic Impact |
| Latency (RTT/TTFB) | <50 ms within Brazil; <100 ms across LatAm | Direct regional paths and links like EllaLink cut cross‑continent delay by up to 50% and keep interactive apps usable. |
| Cache Hit Ratio | 90–98%+ | High hit ratios minimize Madrid/Atlanta origin load and long‑haul traffic; bad ratios surface immediately in origin bandwidth graphs. |
| Peak Throughput | At least 2× current peak as headroom | Protects UX during launches and events, especially for video‑heavy workloads; requires 10–100+ Gbps‑class ports at origin and key PoPs. |
| Traffic Mix & Growth | Video ~84% of traffic; IP traffic 18.8 EB/month by 2022 | Justifies deep caching and big pipes—Latin America is already video‑dominant and still growing fast. |
| Availability & Control | 99.9%+ regional availability; BGP + BYOIP everywhere | Lets you treat a CDN provider for South America as programmable network fabric rather than a black box, keeping flows regional and routes predictable. |
Key Design Takeaways for a Pan-Regional CDN South America Footprint
Once you map both infrastructure and demand, a few design patterns show up again and again for CDN South America deployments.
- Localize Aggressively and Peer in-RegionGet traffic onto South American IXPs as early as possible. Peer at IX.br and national exchanges so South America CDN flows don’t hairpin through Miami or random Tier‑2s. The payoff is often 100+ ms shaved off round‑trip times for cross‑border traffic.
- Use Brazil as the Regional Hub, Not the Only OriginKeep PoPs like Madrid and Atlanta as your global origin anchors while treating São Paulo as a regional shield for South America. The São Paulo PoP handles fan-in from long-haul and then fan-out to Lima, Bogotá, Buenos Aires, and Santiago, giving users “local” performance without forcing a full origin migration on day one.
- Design Inter-Country Routing DeliberatelyModel flows between neighbors, not just “user to origin.” Your routing policy should prioritize intra‑LatAm paths, use BGP communities to avoid bad upstreams, and keep return paths symmetric for latency‑sensitive apps.
- Size for Video and Peaks, Not AveragesLatin America’s IP traffic and video share are both on steep, long‑term ramps. Plan capacity around the worst case—launch days, finals, flash sales—backed by ports in the 10–200 Gbps range at origin and PoPs, rather than hoping averages will save you.
- Let KPIs Drive ExpansionTrack TTFB per country, cache hit ratio per PoP, and link utilization into Brazil. Add PoPs, or shift more workloads to forthcoming São Paulo dedicated capacity, when you see those metrics drift, not when users start complaining.
Operationalizing a South America CDN Strategy: Brazil Hub + PoPs
Putting this into practice usually follows a three‑step arc:
- Phase 1 – Core DeploymentStand up your primary origin cluster on dedicated servers in São Paulo, front it with an origin‑shielded CDN configuration, and establish BGP sessions plus BYOIP so routing is under your control. Start with a small ring of South America CDN PoPs that match your initial go‑to‑market countries.
- Phase 2 – Measurement and Policy TuningInstrument p95 latency, hit ratio, and per‑country concurrency. Tighten BGP policies where hairpinning still appears. Adjust cache TTLs and prefetching around traffic patterns (e.g., match‑day surges, trading windows, prime‑time streams).
- Phase 3 – Expansion and HardeningAs traffic grows, add PoPs and capacity in high‑growth markets, introduce secondary origins only where the risk profile justifies it, and harden multi‑origin failover. The result is a fabric that feels local across the continent but behaves like a single, coherent platform.
At that point, the distinction between “Brazil” and “the rest of South America” largely disappears from the user’s perspective — they just experience fast, consistent responses.
How Melbicom Helps You Deploy and Scale in South America
We at Melbicom built our platform for exactly this playbook: global origins plus a programmable edge.

Melbicom operates single-tenant dedicated servers in 21 Tier III/IV data centers spanning Europe, the Americas, Asia, and Africa, backed by a 14+ Tbps backbone, 20+ transit providers, and 25+ IXPs. We keep 1,300+ ready-to-go configurations in stock and deliver custom servers in 3–5 business days, offering per-server ports from 1 up to 200 Gbps depending on location. On top of that, Melbicom’s CDN spans 55+ PoPs in 36 countries, including São Paulo, Lima, Bogotá, Buenos Aires, and Santiago.
If you’re planning or refining your CDN service in South America and want to combine European/African/American origins with a South American edge that you actually control, contact us. We’ll help you translate traffic forecasts and KPI targets into concrete server reservations in existing data center locations and pre-reserved São Paulo capacity, wired directly into our regional CDN PoPs and global backbone.
Deploy Your South America CDN
Build a regional edge in Brazil with origins in Europe or the U.S. Our team can map PoPs, BGP policy, and capacity to your traffic targets across LatAm.