Month: March 2026
Blog

Validate 10Gbps Dedicated Server Line-Rate Performance
A “10Gbps” port is not a guarantee. It is a systems claim that has to survive CPU scheduling, PCIe topology, kernel queues, storage I/O, and transit design. That matters because traffic keeps climbing: the ITU recently estimated roughly 6 zettabytes of annual fixed-broadband traffic and 1.3 zettabytes of mobile-broadband traffic, and Sandvine’s latest application data shows how heavily usage now skews toward bandwidth-intensive delivery (source).
Annual Broadband Traffic by Access Type:

Why a 10Gbps Unmetered Dedicated Server Is a System Design Problem
A 10Gbps unmetered dedicated server only performs as advertised when every stage of the path can sustain that rate. “Unmetered” usually removes per-terabyte billing, not contention, shaping, or design limits, so the real metric is repeatable throughput with acceptable jitter, loss, and latency under load.
That is why line rate can collapse in practice. “Unmetered” hosting usually means a port and a policy model, not infinite headroom (example).
What Hardware Bottlenecks Limit Sustained 10Gbps Throughput on Dedicated Servers

Sustained 10Gbps throughput is limited by four usual suspects: PCIe bandwidth to the NIC, single-thread CPU headroom on hot flows, kernel queue and offload behavior, and the storage path feeding or absorbing data. If any one of those falls behind, the “10Gbps” label becomes a best-case moment instead of an operating baseline.
NIC + PCIe Topology for a 10Gbps Dedicated Server
A capable NIC on a weak PCIe path is the fastest route to disappointment. PCIe 3.0’s bandwidth jump over PCIe 2.0 matters because slot generation and width can be the reason a 10GbE interface stalls below line rate. NIC manuals are explicit about slot requirements (example), and platforms such as AMD EPYC emphasize high lane counts for the same reason.
CPU Single-Thread Ceilings and Per-Flow Reality
Many teams over-index on total core count. The catch is that a single TCP flow, encryption path, or userspace process can still pin one core first. That is why single-stream tests often underfill 10Gbps while multi-stream tests look healthier, a pattern practitioners regularly report when troubleshooting 10GbE upgrades (discussion). Test both: one tells you what a real session can do, the other tells you what the platform can do.
Kernel Queues, Offloads, and the Packet Plumbing
At 10Gbps, the OS path matters. Check these first:
- Are receive or transmit queues dropping packets?
- Are interrupts collapsing onto one busy core?
- Are offloads and ring sizes sensible for the workload?
Tools like ethtool exist for this layer, and vendor documentation explains why checksum offload, TSO/GSO, interrupt moderation, and ring sizing reduce per-packet CPU cost. Linux buffer ceilings are not the same as defaults.
NVMe Read/Write Paths: The Hidden Limiter in Network Problems
A lot of “network” failures are storage failures in disguise. At 10Gbps, large-object delivery can require roughly 1+ GB/s of sustained storage throughput once overhead is included, and concurrent writes from logs or cache churn can introduce jitter if they share the same NVMe path. That is one reason to keep archive behavior off the hot path; Melbicom’s S3-compatible object storage is useful when you need to separate storage roles instead of forcing one delivery node to do everything.
Choose Melbicom— Unmetered bandwidth plans — 1,300+ ready-to-go servers — 21 DC & 55+ CDN PoPs |
 |
How to Verify Line-Rate Performance on a 10Gbps Unmetered Dedicated Server
To verify line-rate performance on a 10Gbps unmetered dedicated server, prove three things in sequence: the host can hit line rate in controlled conditions, it can hold that rate long enough to expose drift, and it can repeat the result across real network paths. That is the mindset behind RFC 6349: throughput testing is a method, not a screenshot.
A practical plan starts with three questions:
- Can the server and NIC hit line rate in controlled conditions?
- Can the system sustain TPT long enough to expose thermal, IRQ, or buffering issues?
- Does performance still hold outside the provider’s immediate neighborhood?
Start With a Clean, Controlled Baseline
Begin locally or within the same metro. If the box cannot move bits there, WAN testing only adds ambiguity. ESnet’s iPerf guidance uses the same pattern: parallel streams, longer runs, interval output, and reverse testing.
| # On receiveriperf3 -s# On sender: multi-stream, longer run, 1s intervaliperf3 -c <server_ip> -P 8 -t 120 -i 1 # Reverse directioniperf3 -c <server_ip> -P 8 -t 120 -i 1 -R |
Use Linux endpoints when possible; Microsoft has warned that iPerf3 on Windows can be misleading in some cases. Do not stop at a burst.
Test UDP Separately When Jitter Matters
TCP can hide timing problems behind retransmits and backoff. If delay variation matters, test UDP explicitly. RFC 3393 and RFC 5481 are useful references because they treat jitter as a measurable delay-variation problem, not a hand-wavy complaint.
| # Start lower, then step upiperf3 -c <server_ip> -u -b 2G -t 60 -i 1iperf3 -c <server_ip> -u -b 8G -t 60 -i 1 |
Confirm TCP Windowing and Buffer Headroom on Wide Paths
Fast long-distance TCP is gated by bandwidth-delay product. If buffers are too small, the server underfills the pipe even when the hardware is fine. Linux’s tcp(7) and RFC 7323 are the right references: window scaling and autotuning only work when the system has enough headroom to use them.
How to Test Oversubscription, Jitter, and Real-World TPT Before Choosing a Provider
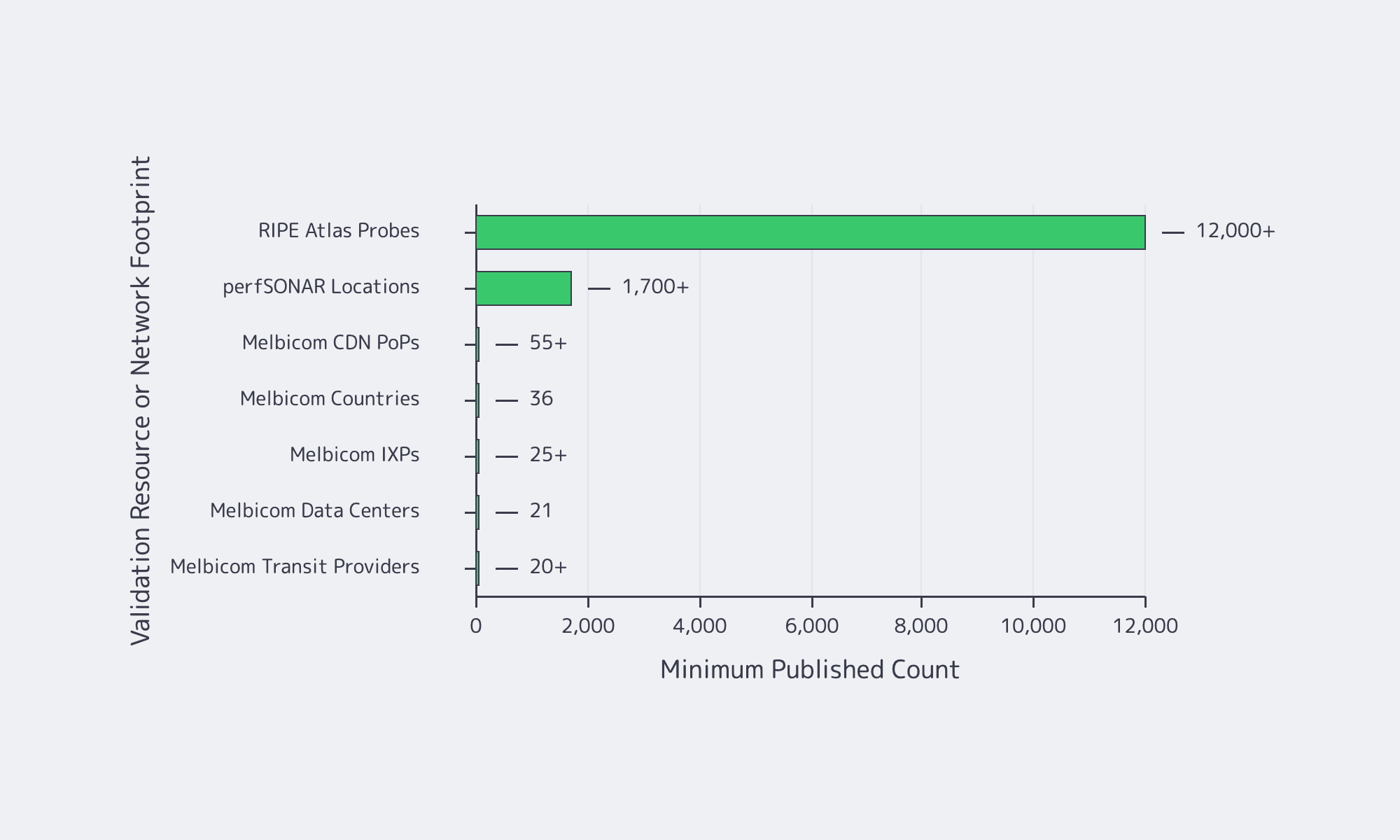
The tests that expose oversubscription and weak transit are the ones a provider cannot easily stage-manage: multi-region runs, multiple source networks, long-enough durations, and measurements taken during busy hours. The goal is not a flattering peak number. It is repeatable performance when the path is congested, asymmetric, or both.
Throughput Tests That Are Hard to Game
For realism, test across different geographies, different networks, and different times of day. Add infrastructure the provider does not control. RIPE Atlas offers more than 12,000 probes for path and latency checks. For multi-domain throughput troubleshooting, perfSONAR’s training material describes deployments in 1,700+ locations, and pScheduler shows how those tests are orchestrated (reference).
Jitter and Queueing: Proving Stability, Not Just Bandwidth
At high utilization, latency is often the first thing to break. That shows up in operator discussions on Hacker News and in newer IETF work. RFC 9341 describes alternate marking for measuring live loss, delay, and jitter, while RFC 9330 sets out the L4S architecture for lower queueing latency at high TPT. Hitting 10Gbps is not enough if the tail turns ugly.
Provider Questions That Reveal Oversubscription and Weak Transit
Ask whether the service is sold as guaranteed bandwidth without ratios. Ask how much transit and peering diversity exists. Ask whether external test files and test IPs are published. Ask whether BGP sessions are available if routing control matters. Melbicom makes that diligence easier because Melbicom publishes bandwidth tiers and test files, and BGP session capabilities, so you can validate the path rather than trust a sales claim.
Reference Server Builds for Predictable 10Gbps Egress
A reference build shows which components cannot be underspecified when 10Gbps is the baseline. Treat these as validation-oriented shapes, then map them to current inventory and location-specific bandwidth before ordering.
| Workload Pattern | Reference Build Focus | What to Validate Before Scaling |
|---|---|---|
| High-throughput streaming origin or large-file delivery | High-clock CPU, clean PCIe layout, NVMe for hot content, correct NUMA affinity | Sustained multi-stream TCP, single-stream ceiling, UDP jitter under load, disk read stability during concurrent writes |
| CDN cache or software distribution mirror | NVMe capacity and endurance, strong read plus concurrent-write behavior, enough RAM for page cache | Throughput during cache fill and eviction, queue drops, peering diversity, multiple external source networks |
| Real-time APIs and RPC endpoints with heavy egress | Stable CPU scheduling, low-jitter path, tuned queues, balanced interrupts, buffer headroom | Tail latency under load, route asymmetry, peak-hour behavior, TCP window scaling on longer RTT clients |
10Gbps Unmetered Dedicated Server: Verification Checklist
Reliable 10Gbps buying discipline looks like this:
- Buy the test plan before the port: define duration, regions, stream counts, and acceptable jitter ahead of time.
- Separate host proof from network proof: first prove the box can move data locally, then prove the provider can move it across real paths.
- Treat jitter as a first-class failure mode: a link that peaks at 10Gbps but blows out tail latency is still the wrong answer for real-time delivery.
- Ask location-specific questions: per-server bandwidth, transit mix, public test files, and BGP policy should vary by site, and you should know how.
Conclusion

A 10Gbps unmetered dedicated server is not validated by a product page. It is validated when the server holds line rate in controlled tests, repeats the result across real paths, and stays stable when storage, CPU, and kernel behavior are under pressure.
That is why provider due diligence matters as much as hardware choice. Buyers should demand transparent network details, test points, clear answers on contention, and operational data to build a repeatable test plan before moving production traffic.
Deploy 10Gbps Unmetered Servers
Validate sustained 10Gbps line rate with tested builds, real-path checks, and location-specific bandwidth. Launch faster on Melbicom with predictable egress and transparent network details.
Get expert support with your services
Blog

Dedicated Server Bandwidth: Plan Ports, Not Bills, For Viral Demand
Traffic does not rise smoothly anymore; it spikes. A live event, a product launch, a software update, or a sudden API surge can turn outbound throughput into a bottleneck in minutes. Sandvine’s Global Internet Phenomena Report estimates total internet traffic at roughly 33 exabytes per day across fixed and mobile networks, while Ericsson says mobile networks alone now carry 200 exabytes per month, with video still dominant.
A dedicated server with unmetered bandwidth has become a control surface for high-traffic systems: single-tenant hardware, a known port speed, and a fixed monthly cost instead of a bill that inflates every time demand does.
Choose Melbicom— Unmetered bandwidth plans — 1,300+ ready-to-go servers — 21 DC & 55+ CDN PoPs |
|
Dedicated Server Unmetered Bandwidth and What “Unlimited” Actually Buys You
A dedicated server with unmetered bandwidth does not mean infinite throughput. It usually means you are no longer billed per GB transferred; instead, you buy a defined port speed and can use that capacity continuously without per-GB overage surprises. In practice, that turns traffic growth from a billing problem into a capacity-planning problem.
In hosting, “bandwidth” mixes two different ideas: port speed, which is instantaneous throughput, and data transfer, which is monthly volume. The unmetered part changes the economics. You stop paying for every TB and start engineering around a known ceiling.
Unmetered Dedicated Server vs. Metered Transfer
An unmetered dedicated server makes sense when traffic is bursty, event-driven, or difficult to forecast. A metered model may expose a large port, but every surge also becomes a financial event. For modern delivery stacks, that can turn success into overhead.
A brief historical note: the old problem was hard bandwidth caps and punitive overages. The modern problem is whether the port, backbone, and routing path can sustain demand without throttling, congestion, or billing shock.
Cost Certainty and Budget Control When Traffic Spikes
The real value of unmetered bandwidth is not “cheap data.” It is cost certainty during the exact moments when your system is already under operational stress. A fixed monthly bill removes one variable from launch planning, premiere planning, and incident response, so traffic spikes stay an engineering problem instead of becoming a finance problem too.
This matters most for workloads that push heavy outbound traffic: adaptive video segments, software binaries, online gaming patches, recordings, exports, large SaaS payloads, or user-generated assets. Peaks are no longer unusual. AppLogic’s summary of the Global Internet Phenomena report describes live events as traffic “earthquakes” that can hit several times normal usage.
The user-facing penalty for underprovisioning is clear. In a Carnegie Mellon quality-of-experience study, buffering ratio had the strongest negative effect on engagement; for live content, even small increases in buffering reduced viewing time.
Unthrottled Performance during Viral Events Hinges on Ports, Routing, and Caching
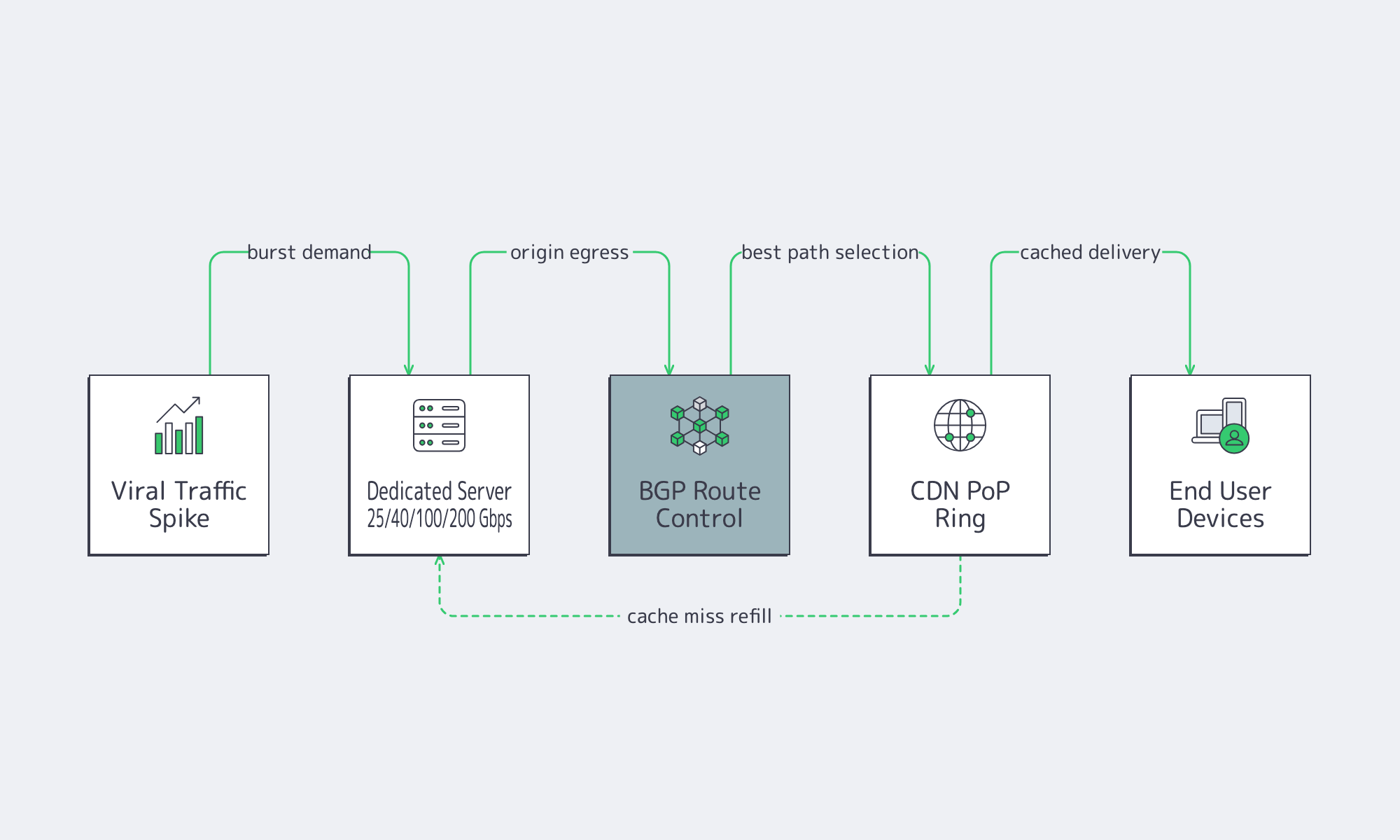
“Unthrottled” is not a marketing switch. It is the outcome of having enough port capacity, a network that can deliver that capacity under load, and a delivery architecture that keeps your origin from becoming the bottleneck. During viral events, all three matter at once.
The choke points are server egress, upstream path quality, and origin load. Even with caching in front, origins still get hit during cache-miss storms and release waves. Ethernet Alliance’s summary of IEEE 802.3bs shows how 200 GbE and 400 GbE became standardized Ethernet classes; by 2026, providers such as Melbicom can credibly expose dedicated ports in 25, 40, 100, and 200 Gbps classes for heavy workloads, depending on location.
Dedicated Server Hosting Unmetered and the Network Checklist
If you are evaluating dedicated server hosting unmetered, the right question is not “Is it unlimited?” The right question is whether the provider can keep delivery stable when concurrency jumps, cache efficiency drops, or a single event turns your quiet origin into the hottest endpoint in the stack.
The checklist is practical: port tiers that map to real concurrency, route control when you need stable ingress and egress, and a CDN footprint that reduces long-haul hops and origin load. RFC 4271 still matters because BGP policy keeps reachability predictable across regions. Melbicom’s CDN spans 55+ PoPs across 36 countries to keep repeated content closer to users.
Affordable Unmetered Dedicated Servers
For high-traffic projects, “affordable” does not mean the lowest sticker price. It means buying bandwidth in a way that prevents both overage shocks and quality collapse. The cheapest plan on paper is often the expensive one in practice if it breaks the first time demand spikes.
The traffic mix makes that obvious. Sandvine shows video as the largest downstream category across regions, roughly in the low-40s to high-40s percent range, while file delivery remains a major traffic class in several markets. Those are exactly the patterns that punish per-TB billing during releases, updates, and live events.
Unmetered still does not change physics. Port speed is the real control knob.
| Port Speed (Gbps) | Theoretical Max per Day (TB) | Theoretical Max per 30 Days (PB) |
|---|---|---|
| 1 | 10.8 | 0.32 |
| 10 | 108 | 3.24 |
| 40 | 432 | 12.96 |
| 100 | 1,080 | 32.4 |
| 200 | 2,160 | 64.8 |
At 40 Gbps and above, metered transfer stops looking like a small variable and starts looking like a structural risk. Gartner projects data-center systems spending will exceed $650 billion in 2026.
Melbicom’s affordability angle is capacity you can actually plan around: more than 1,300 ready-to-go server options in stock, custom builds in 3–5 business days, unmetered options with guaranteed throughput, and a network footprint described in current commercial-page language as a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs. Layered with 55+ CDN PoPs in 36 countries and BGP sessions with BYOIP, that is the difference between “we got popular” and “we need to explain the bill.”
How to Size Unmetered Servers without Guesswork
The fastest way to misbuy bandwidth is to size around averages. High-traffic systems fail at the peak, not in the monthly mean. A better approach starts with peak concurrency, converts that into required egress, and adds enough headroom to preserve quality when the burst arrives.
For adaptive delivery, the math is simple: concurrency multiplied by average delivered bitrate gives you the egress target. That is why larger port tiers exist. If your event model says 60 Gbps sustained, a 10 Gbps port is not a growth path; it is the bottleneck you are about to hit.
A Throughput Sketch for Peak Events
Below is a simple back-of-the-envelope model for event sizing:

What to Do with That Sizing Result
Once you have a peak target, the next steps are operational:
- Choose a port tier with explicit headroom. If your model lands near 35 Gbps, a 40 Gbps port may work; if it lands near 70 Gbps, 100 Gbps is the safer class; for especially bursty delivery, 200 Gbps becomes relevant.
- Put unmetered bandwidth where bursts are hardest to smooth: origin delivery during premieres, large file distribution, and cache-miss-heavy launch windows.
- Offload repeated assets aggressively. A CDN lowers origin egress, trims long-haul latency, and buys you stability during the first wave of demand.
- Keep endpoints stable when compute moves. Melbicom’s BGP sessions and BYOIP support matter here because route control is a tool for migrations and multi-region designs.
Key Takeaways
- Model bandwidth from peak concurrency and delivered bitrate, not from monthly averages.
- Buy headroom at the port layer; the cost of unused capacity is usually lower than the cost of degraded quality at peak.
- Put unmetered bandwidth on origin, release, and export tiers where bursts are hardest to predict and hardest to cache away.
- Treat CDN offload and BGP-based route control as part of the same design problem as server bandwidth.
- Recheck the economics once sustained egress reaches double-digit Gbps; that is usually where fixed monthly pricing starts to beat transfer-based surprises.
Why Dedicated Server Unmetered Bandwidth Is Now a Strategic Buy

For modern high-traffic systems, unmetered dedicated infrastructure solves two problems at once: it caps financial uncertainty and raises the performance ceiling when demand turns nonlinear. You are not buying “unlimited internet.” You are buying a monthly cost you can model, a port you can design around, and a delivery path that does not flinch when a launch or viral event lands.
That is why this category keeps moving upmarket. When providers can pair single-tenant hardware with global caching, route control, and dedicated ports up to 200 Gbps, unmetered bandwidth stops being a checkbox and becomes an architectural choice for services that cannot afford buffering, throttling, or billing surprises.
Scale bandwidth with fixed monthly pricing
Get single-tenant servers with unmetered ports up to 200 Gbps, global CDN offload, and BGP sessions with BYOIP. Build around predictable performance and costs for launches and viral events.