Month: August 2025
Blog

Future-Proof iGaming with Global Dedicated Server Clusters
iGaming has seen a steep growth curve that is only predicted to continue, with the market’s global value projected to surpass $126 billion within the next few years.
However, despite the demands, scaling has a few caveats. The usage patterns are tricky to calculate with huge spikes in traffic that far exceed daily baselines during major events to contend with, as well as the near-zero tolerance that gamers have for delays. Mere millisecond shifts in latency dramatically affect user behavior, meaning that scalability relies less on procurement factors and more on architectural design.
To keep scalability future-proof, you need a forward-looking roadmap. Today, we will discuss what that actually looks like. To meet the needs of iGaming, with infrastructure on dedicated servers, the emphasis has to be on horizontal clustering and low latency. The server capacity needs to be adequately planned and managed, with automation in place to cater for emerging and chaotic workloads intelligently. So let’s take a look at a scalable blueprint with modular resilience for AI, real-time analytics, and blockchain that works smoothly and efficiently under realistic workloads.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Horizontal Clustering: The Bedrock of Scalable Dedicated Servers for iGaming
Scaling vertically requires ever-larger machines; realistically, it means finite headroom for most. The overprovisioning is often wasteful and creates single points of failure within the infrastructure that lead to longer maintenance windows and result in more downtime. By adding servers in parallel with horizontal clustering, you have a better alternative that intelligently balances traffic without wasting provisions, and failure is treated as a routine event rather than a deadly threat.
Horizontal clustering also allows you to separate concerns into independently scalable pools. For iGaming operations, the separation blueprint of tiers would be the following:
- For Web/API and game servers: Nodes remain as stateless as possible and are routed with L4/L7 load balancers. Game rooms and tables are partitioned through consistent hashing, and game nodes are added to the pool when a tournament starts. This prevents tuning and pushing a single box past its breaking point.
- For the data: Heavy reads are dealt with by blending read replicas, and writes are handled via clustering or sharding. The transaction integrity is protected by distributed SQL or sharded RDBMS patterns, and bet placement, settlement, and odds queries are easily handled regardless of the volume.
- Maintaining a low-latency state and messaging: In-memory caches and message queues help decouple spikes from the database’s critical path.
Operating in clusters boosts throughput and availability because health checks and load balancers can drain a single server should a failure be encountered, while the rest continue working. This means safer rollouts, as new builds can be hosted on a subset of nodes with blue-green deployment or canary setups. With a model that adds nodes to increase headroom, your capacity grows in alignment with growing demand, and there is no need for any redesigning, regardless of whether you need to scale from five thousand to fifty thousand concurrent users at a moment’s notice.
This blueprint is easy to start; Melbicom’s dedicated servers align cleanly. We have more than 1,300 ready-to-go configurations capable of providing up to 200 Gbps per-server bandwidth, which enables you to obtain the right-sizing for the above outlined tiers, as well as have the headroom on hand to expand clusters as and when concurrency climbs.
Lowering Latency and Aligning with Regulatory Requirements
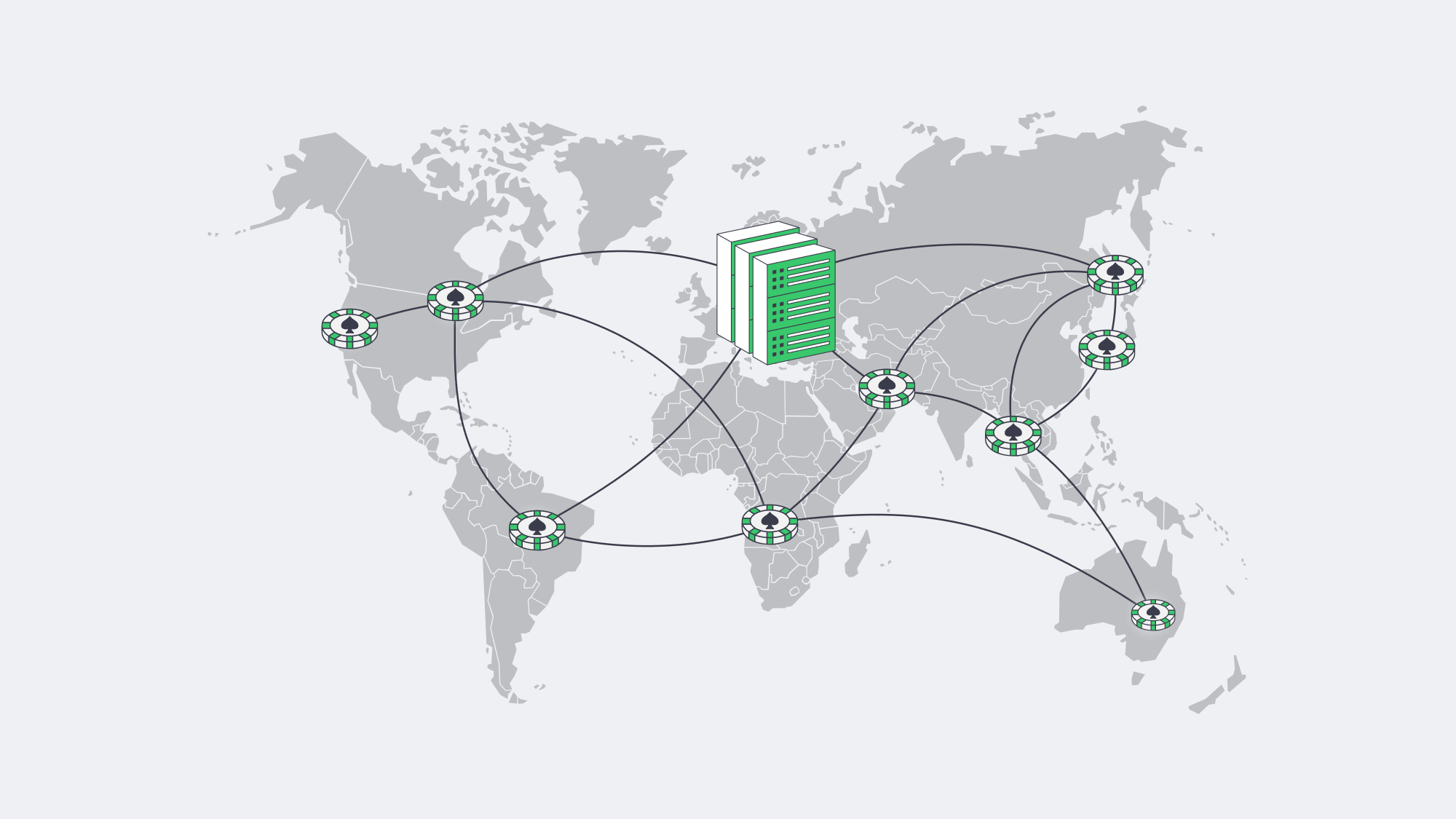
We often think of scaling in terms of “how much,” but “where” is just as important, especially in iGaming, with latency being a key concern. Physical distance equals delay; the longer the distance between a player and your servers, the more latency erodes conversion and churn. Gameplay and in-play betting should be instantaneous for all users, even if those at the table are located as far apart as Madrid, LA, and Singapore at the same time. To provide that globally, multi-regional deployment is vital to your infrastructure.
Design with regional hubs as your focus: Place your active clusters in key geographical regions (e.g., EU, US, APAC). DNS-based global load balancing or anycast can help ensure that a bet placed in Frankfurt resolves to Europe by default, whilst an Atlanta-based one lands in North America. Keep the data local to make compliance easier. Use active-active operation where possible to keep failover seamless and capacity steady.
Free the core cluster via CDN offload: Reduce origin loads and roundtrips by pushing static assets, media, and selected API responses to the edge. The Melbicom CDN spans over 55 locations, ensuring that assets and streams terminate within proximity of the user, freeing up the core cluster and enabling the focus to be on latency-sensitive interactions.
Physical foundational considerations: High-capacity, well-peered networks in fault-tolerant facilities are needed to keep user experiences consistently sub-100 ms. Melbicom operates with a geo-redundant design with data centers in 21 global locations that ensure rapid transactions and recovery. Our data centers have redundant power and diverse network paths, preventing regional incidents from causing any prolonged downtime.
The big payoff of operating with regional hubs is that regional traffic peaks locally; spillover is caught by neighbors; for example, surges from the Champions League are handled by European clusters, the Americas absorb spikes caused by the NFL, while APAC handles weekend traffic.
Handling Surges Seamlessly with Automation and Server Capacity Planning
The iGaming market moves rapidly, and the supply and demand for server capacity are unpredictable, making it tough to keep up with through manual scaling. To keep ahead, automation and server capacity planning are vital; if not, you run the risk of last-minute scrambles that spoil UX.
Infrastructure as Code (IaC). You can smoothly expand clusters in planned windows to cover predictable surges with a ready-to-deploy inventory by provisioning and reimaging servers using code (Terraform/Ansible). At the same time, standardized images across nodes prevent configuration drift.
Elastic orchestration. Although physical servers don’t “pop” instantly, near-instant service-level elasticity can be achieved on dedicated hardware, comparable to cloud operation, by packaging services into containers, scheduling with a cluster manager, and autoscaling horizontal pods on CPU/memory/queue depth.
Autoscale through blending predictive and reactive triggers:
- Schedule calendar-based rollouts, derbies, tourneys, and promotional campaigns.
- Set reactive triggers such as thresholds on error budgets, P95 latency, specific queue lengths, or cache hit rates.
- Avoid idle waste by automating graceful cooldowns when surges recede.
Close the loop with health checks and continuous load testing to analyze previous peak behavior. This ensures that traffic is drained away from unhealthy instances and restart through automation, and that pipelines roll forward and back automatically.
Through this method, you remain cost-aware at baseline, ruthless with headroom, and far more efficient than manually possible.
Build to Fail Safely with Modular, Resilient Architecture as a Backbone

As well as the hardware considerations, you have software architecture to think about if you truly want your scalability to remain future-proof. The benefits of a modular system as a backbone are: localized failure, rapid feature integration, and the ability to scale components independently.
Microservices and event-driven flows: Break down the individual platform services such as identity, wallet, risk, odds, settlement, game sessions, chat, bonus, and analytics. Use APIs and streams for communication. Publish event-driven actions such as “bet placed,” “odds updated,” or “game finished” to a durable bus; adding a fraud model or a loyalty engine is a plug-in, not a rewrite.
Isolation and fallbacks: Ensure that each microservice is isolated so as not to cause collapse should a failure arise, and have a fallback in place for each. Some examples would be: If chat features start to slow, degrade them, but allow bets to proceed. If personalization times out, revert to default settings. Putting these patterns in place for resilience helps counter timeouts, reducing degradation from cascading partial outages.
Redundancy should be throughout: Use primary/replica or clustered databases with automatic failover to make sure that no single data node, cache, or gateway is a lynchpin. Keep multiple instances of all stateless services and run hot spares for critical paths. Site-level incidents can be handled via active-active regions where possible, and if not, at the very least, hot standbys.
Harden your architecture design through regular testing: Run chaos drills in staging and practice region evacuation and database failover. That way, you can make sure that load balancers stay true to health checks and get your rollback paths as predictable as possible.
Working this way protects revenue, preventing outages during the Super Bowl, and accelerates delivery, giving your teams the confidence to deploy changes.
AI, Real-Time Analytics, and Blockchain Readiness
As you scale and integrate other features, the emerging workloads can cause upheaval. The best practice is to architect ahead of yourself a system that is ready for anything.
For AI and real-time analytics operations that rely on streaming events and compute-intensive pipelines such as recommendation engines, risk models, anomaly detection, and dynamic odds, the transactional paths need to be kept as clean as possible (write bet → ack). The events can then be mirrored to analytics clusters and engineered. Through model scoring, you can work out where to add a GPU dedicated server to bolster and accelerate alongside adjacent data streams. By treating analytics stacks as separate but first-class tenants, they can be scaled independently without starving bet paths, which also allows for experimentation, because models can be rolled forward without risking core stability.
You should track P95 latency for real-time operational analytics, such as a dashboard for bet placement, queue times for settlement, cache hit ratios, and regional error budgets, to make sure automation responds rapidly to line breaks or traffic shifts.
Crypto wallets and provably fair gaming, which rely on Blockchain , can write very slowly or be transiently unavailable. The solution is to have their gateways isolated behind queues to prevent stalling when awaiting confirmations. Integrate modularly to keep the core platform running smoothly regardless of any external network hiccups. Remember that fast NVMe stateful nodes require high-bandwidth links to sync heavy chains and state snapshots. At Melbicom, we offer uplinks with up to 200 Gbps per server.
Modularity also helps cover new interaction patterns. VR/AR tables, large-scale PvP pools, and social gameplay can all cause unpredictable surges. To cope, you need architecture that lets you place specialty services in regional hubs and add edge offload via CDN. WebSocket, HTTP/2, and other protocols should be tuned for connection at scale.
This architecture is more pragmatic in terms of costing, with a disciplined baseline (e.g., 60–70% utilization) and planned surge capacity, you evade overbuild and panic-buy cycles, just use the right-sized node types per tier and don’t use GPUs where CPUs suffice.
Further tips: to ensure rightsizing and detect anomalies early, you can leverage unified tracing, analyzing metrics, and logs across tiers. Tie SLOs such as bet latency and odds freshness to automated actions and keep personal and wagering data in-region by default. That way, you replicate summaries rather than raw PII across borders, satisfying auditors.
Growth Pattern Reference
You can use the following summary as a reference for your iGaming architecture blueprint:
- Operate horizontally from the get-go by deploying multiple web/API and game nodes with load balancers to help keep nodes as stateless as possible.
- Introduce caches and queues and utilize clustered databases with read replicas to help decouple the data path.
- Launch globally early by placing small but real clusters in your two most important regions, route by proximity through global load balancing, and keep the user data local to simplify compliance.
- Build IaC, golden images, and orchestrate your deployments with automation to scale. Predict known events and employ reactive triggers to allow for any unexpected surges.
- Ensure each tier has redundancy, test failovers, and add graceful degradation paths to protect against failure.
- Keep bet paths clean by supporting the core with analytics and AI to stream events and score models out-of-band, returning only the necessary signals.
- Observe to iterate, trim any waste, move bottlenecks, and use the data to inform the next scale-up.
Be sure to choose facilities and networks that won’t result in any bottlenecks. Melbicom’s dedicated servers are housed in Tier IV & III sites across 21 global locations. The infrastructure is engineered for redundancy, and each server provides connectivity up to 200 Gbps, meaning sudden spikes won’t saturate the network.
Building with Sustained Global Performance as a Focus

If you want to ensure that your iGaming scaling capabilities are future-proof in iGaming, then you need a disciplined architecture that is built to work in parallel and focused on proximity and automation. You can give your capacity more elasticity and resilience through horizontal clustering, which, paired with automation and server capacity planning, helps you cope with the chaotic traffic expectations. Global deployment ensures low latency and fairness, helping to satisfy regulators, and failure containment is easier to deal with thanks to the modular nature of the blueprint. These architectural design choices work hand in hand to ensure your scaling is steady and smooth rather than episodic and make engineering for iGaming predictable despite the challenges that event days and release cycles can otherwise cause.
The result is a platform that is architecturally strong and resilient as opposed to simply bigger, which means surges are easily absorbed, features launch faster, and the future integration of AI, analytics, and blockchain won’t cause any disruptions. Reaping the rewards of this architectural blueprint requires dedicated servers in global locations that are clustered, observable, and automated from the bootloader up to provide the perfect iGaming infrastructure.
Launch Your iGaming Servers Today
Choose from 1,300+ high-bandwidth dedicated servers across 21 global data centers and scale your platform without limits.
Get expert support with your services
Blog
Boosting Affiliate Conversions with High-Performance Dedicated Servers
Affiliate campaigns are hyper-sensitive to latency. The pages that can be opened within two seconds and those that take three seconds or more may represent the profit and loss difference. Google reports show that the probability of bounce increases by 32% as load time moves from 1s to 3s, and more than 50 percent of mobile visitors leave a page in case of a delay of more than 3 seconds. BigCommerce sums it up simply: a one-second delay has been shown to result in a 7% loss in conversions. Affiliates working on a per-click basis, of course, will translate those percentages into margin.
Modern infrastructure bridges that gap. The fastest deployments are those which combine NVMe storage, multi-core CPUs with high amounts of RAM, and optimized high-throughput networks so that time to first byte is short and page rendering is never interrupted, even in the event of a campaign spike. This is also where performance-tuned dedicated servers pay off, because they can deliver long-term throughput and consistent latency under actual load, not just in lab tests.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
How Dedicated Servers Help Affiliate Marketing to Convert More Clicks
The 2025–26-class hardware and networks do not offer incremental improvements; they are architectural. NVMe on PCIe 4/5 takes the I/O bottlenecks that once made dynamic pages “feel” slow away. NVMe drives will routinely achieve multi-GB/s sequential reads and writes (5,000 MB/s and higher in typical settings), whereas SATA remains capped at 600 MB/s—a limit that is easily saturated under concurrent requests. On the CPU front, dozens of physical cores and high-speed DDR4/DDR5 RAM enable servers to render templates, execute tracking/attribution logic and serve API requests in parallel without spiking tail latency. On the network, the bandwidth-intensive sites are based on high-capacity, dedicated 1–200 Gbps ports, intelligent peering, and global distribution mechanisms that ensure tight p95/p99 response times even when audiences are far-flung across regions.
In the browser: The HTML renders more quickly, the render-blocking assets come sooner, and an overworked origin does not block the main thread. Users are exposed to content earlier, engage earlier, and leave less often, which is the exact direction toward increased conversion rates. This cumulative effect is enormous: BBC reported that every extra second of load time costs them another 10 percent of users—an object lesson on how small mistakes end up building to significant losses.

NVMe dedicated servers for low latency
The advantage of NVMe is not that it offers high headline throughput, it is that it can provide low latency, high queue depth I/O that can keep dynamic sites responsive when under concurrency.
Consider an affiliate landing page that accesses a geo database, and then retrieves creative variants along with recording a click-ID, all before the content is painted above-the-fold. NVMe reduces the wait times of the reads and writes to microseconds, as opposed to milliseconds, across the request pipeline. The end result is a reduced TTFB, a reduced LCP, and a greater likelihood that the user sees and responds to the CTA.
CPA network dedicated hosting
There is a different but related issue facing networks and platforms: high rates of redirects, attribution and postbacks are required 24/7.
A delay in the tracking hop frustrates the user even before they can see the merchant page. Dedicated servers with high numbers of cores and memory can absorb bursty redirect traffic and high-capacity NICs ensure that traffic does not queue on the wire. Keeping tracking latency minimal preserves conversion probability across all offers and geos; it also preserves trust in reported numbers, which is critical when affiliates bid hourly.
Minimize the time it takes to load an affiliate landing page (infrastructure first)
Front-end minification is useful but infrastructure can frequently be the quickest win in affiliate land.
- Move origins closer to demand and cache as much as you can at the edge. A world-wide CDN reduces distances and round-trips; static content is served by edge nodes leaving origin CPU to concentrate on dynamic tasks.
- Right-size compute at the peaks, not averages. Ample headroom avoids CPU-bound stalls that slow down p95 latency in the times that matter the most (e.g., email drop, social virality).
- Employ new routing and protocols. Consolidated connections (HTTP/2/3), intelligent peering, and anycast DNS eliminate much handshaking overhead and path variability, which is often a silent cause of mystery seconds.
A quick comparison
| Lever | Modern capability (examples) | Conversion-side effect |
|---|---|---|
| Storage | NVMe on PCIe 4/5 exceeds 5,000 MB/s; SATA is limited to ~600 MB/s | Lower TTFB and faster DB-backed renders improve completion of key funnel steps. |
| Compute | 24–64+ cores with fast DDR4/DDR5 and generous caches | Handles concurrency during spikes; stable time-to-interactive. |
| Network & Edge | Dedicated 10–200 Gbps ports, global CDN with 55+ nodes | Shorter paths and higher throughput reduce bounce and keep users on page. |
Scaling Strategies for Peak Campaigns (without Slowing Down)
Outstanding campaigns produce their own form of DDoS traffic. The playbook scales without compromising the latency per request.
Vertical headroom + horizontal scale. Start with servers with a margin (CPU, RAM, and NIC bandwidth) so your initial server configuration will not be slow at 5x baseline. Then add two replicas behind a load balancer to handle the next order of magnitude. With dedicated hardware, the environment is predictable—no noisy neighbors, consistent NUMA layout, and high port speeds.
Fast capacity activation. The historical objection to dedicated servers — slow provisioning — is no longer valid. For example, Melbicom pre-stages 1,300+ ready dedicated server configurations and typically brings servers online in about two hours, so additional capacity is in place when it’s needed during scheduled bursts or surprise viral moments.
Keep packets flowing. Spikes will tend to cause the bottleneck to be the NIC rather than the disk. Melbicom offers data center services with bandwidth up to 200 Gbps per server — useful when low-risk, high-throughput delivery is important to scheduled launches.
Push static to the edge. At Melbicom we couple origin servers with our own CDN across 55+ points of presence. Campaign materials (images, CSS, JS, video clips) sit on the edge, with the origin being concentrated primarily on dynamic processing such as personalization and tracking. This maintains your p95 and p99 times consistent as the number of concurrent sessions increase.
Global placement. Latency increases with distance; about 10 ms of round-trip time is added to each ~1,000 km. Melbicom has 21 international locations, so you can anchor origins close to traffic you are actually purchasing, and replicate into secondary regions as campaigns scale.
Operational preparedness. The soft side is also important: when you need to scale due to the results of load tests, the response time of the support team will determine how fast you will be able to do it. Melbicom offers 24/7 technical support at no charge to teams and our control panel allows teams to modify capacity with ease.
Why a Good Enough Shared Hosting Environment is not Good Enough
Shared machines and undersized VMs used to be the first point of call, but are doomed to fail at scale due to resource contention and unpredictable latency. A neighboring tenant backing up or a burst of noisy processes can add hundreds of milliseconds of unpredictability to your requests — just when you launch a high-spend campaign. Modern dedicated environments remove that variability by providing you with the entire CPU, memory channels, disk bus, and NIC — there is no contention or surprise. What a decade of affiliate traffic has taught us is this: when you need the conversions, you pay the price for infrastructure that is only ‘good enough’.
Affiliates Implementation Checklist

- Extend stateful workloads to NVMe-based dedicated origins. Prioritize renderers, session stores and databases.
- Place origin servers close to users and front all static content with a CDN.
- Plan on headroom (CPU, RAM, bandwidth) so your p95 does not drift during peak.
- Perform a load test preflight and maintain an expansion path (pre-approved configs, DNS/balancer rules, warm replicas). Melbicom’s 1,300+ ready configs and 2-hour activation make this a realistic standard practice.
- Metrics that count: TTFB, LCP and conversion rate by geo/ISP. Correlate latency to abandonment and adjust capacity based on it.
Milliseconds to Money: the Server Infrastructure Benefit

Conversion arithmetic is merciless. Every second of delay eats a part of sales; every millisecond of saved time provides a padding to ROI. The most powerful lever available to an affiliate is the performance envelope of its origin — how fast it can accept connections, read off storage, render dynamic content, and push bytes over the wire at peak. NVMe storage eliminates I/O stalls; high-performance CPUs and RAM can absorb concurrency without the latency whiplash; high-speed, global access ports eliminate costly, round-trip delays. That combination can convert paid clicks into engaged sessions and engaged sessions into revenue even when there is a surge in traffic. It is straightforward, the data speaks: the fewer seconds, the fewer bounces, the more conversions.
Deploy High-Performance Servers
Choose from over 1,300 ready-to-deploy dedicated server configurations and launch in as little as two hours.
Get expert support with your services
Blog

Dedicated Servers for Bulletproof iGaming Security
Online gambling has grown into a nearly $100 billion market with sustained double-digit growth. The upside is undeniable; so are the risks. About 70% of gaming and online betting companies report security incidents, and the industry absorbs more than one-third of all DDoS attacks worldwide, with attack volumes rising roughly 37% year over year. The stakes aren’t just technical: the average breach now costs about $4.9 million, and up to 75% of players may never return after a security incident while more than half lose confidence in the platform. In this environment, compliance is inseparable from security, and both are inseparable from infrastructure choices. This guide explains how dedicated hosting anchors modern iGaming compliance and security—focusing on data sovereignty, robust controls (encryption, DDoS resilience, MFA), and audit-ready operations—while addressing emerging threats and evolving rules without dwelling on legacy practices.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Why iGaming compliance dedicated hosting is different
- Data localization and sovereignty. Player and wagering data often must remain in-country. Dedicated servers make it straightforward to “pin” workloads to a specific jurisdiction—critical when a license binds compute and storage to local soil.
- Secure facilities and hardware. Regulators want assurances that “any server used in the gaming process is housed securely,” with strong physical controls. Facility standards matter: Tier IV and Tier III data centers signal fault tolerance and layered security aligned to audit checklists.
- Audit trails and accountability. Every financial transaction, gameplay event, change, and access attempt must be logged and retained. Auditors increasingly expect quick retrieval, forensic fidelity, and clear chains of custody.
- Availability and integrity. Uptime and data integrity are compliance issues. Tier IV’s 99.995% target—less than 30 minutes of annual downtime—illustrates the operational bar regulators and players implicitly expect.
- Privacy and data protection. iGaming platforms sit at the intersection of gambling rules and general data protection laws. Encryption, access control, and least-privilege practices are baseline, not “nice to have.”
How Dedicated Servers Meet iGaming Compliance at the Infrastructure Layer

Dedicated hosting is single-tenant by design: one operator, one physical machine. That isolation, plus full control over the OS and network stack, maps cleanly to compliance.
Data sovereignty you can prove. Operators select exact data centers for each workload—essential for satisfying in-country hosting mandates. Melbicom’s footprint (21 global locations) lets teams place systems where licenses require, confining regulated data at the jurisdictional edge. When latency to players also matters, coupling compute with CDN brings content closer without moving regulated data out of bounds.
Auditability down to the serial number. Single-tenancy simplifies audits. You can provide hardware identifiers, rack placement, and access logs, and you can show who touched what, when. Disk-level evidence is far easier to produce when no other tenants share the device. On multi-tenant platforms, regulators often balk at black-box layers; on dedicated servers, you can open the box—figuratively and, when required, literally.
Control that fits the rulebook. Some jurisdictions require certified RNGs, specific crypto modules, or validated OS/database versions. Dedicated servers let engineering teams harden kernels, pin versions, and schedule patch windows around peak betting periods—without waiting for an abstracted cloud to expose the right knobs. That control extends to configuration baselines aligned to internal policy and external rules, and to evidence generation for audits.
Facility standards that check boxes. Ensuring dedicated servers are hosted within modern Tier IV or III data centers aligns infrastructure resilience with regulator expectations on integrity and availability.
Capacity without co-tenancy risk. iGaming traffic is spiky by nature—major events can multiply load in minutes. With up to 200 Gbps per-server bandwidth, Melbicom’s network helps absorb legitimate surges while giving room for upstream DDoS mitigation to work. The crucial point for compliance: performance during peaks protects fair-play guarantees and reduces operational incidents that can trigger reporting duties.
For teams that must defend design choices to both executives and auditors, this is the elevator pitch: dedicated servers make where data lives, who can access it, and how it’s safeguarded demonstrably clear.
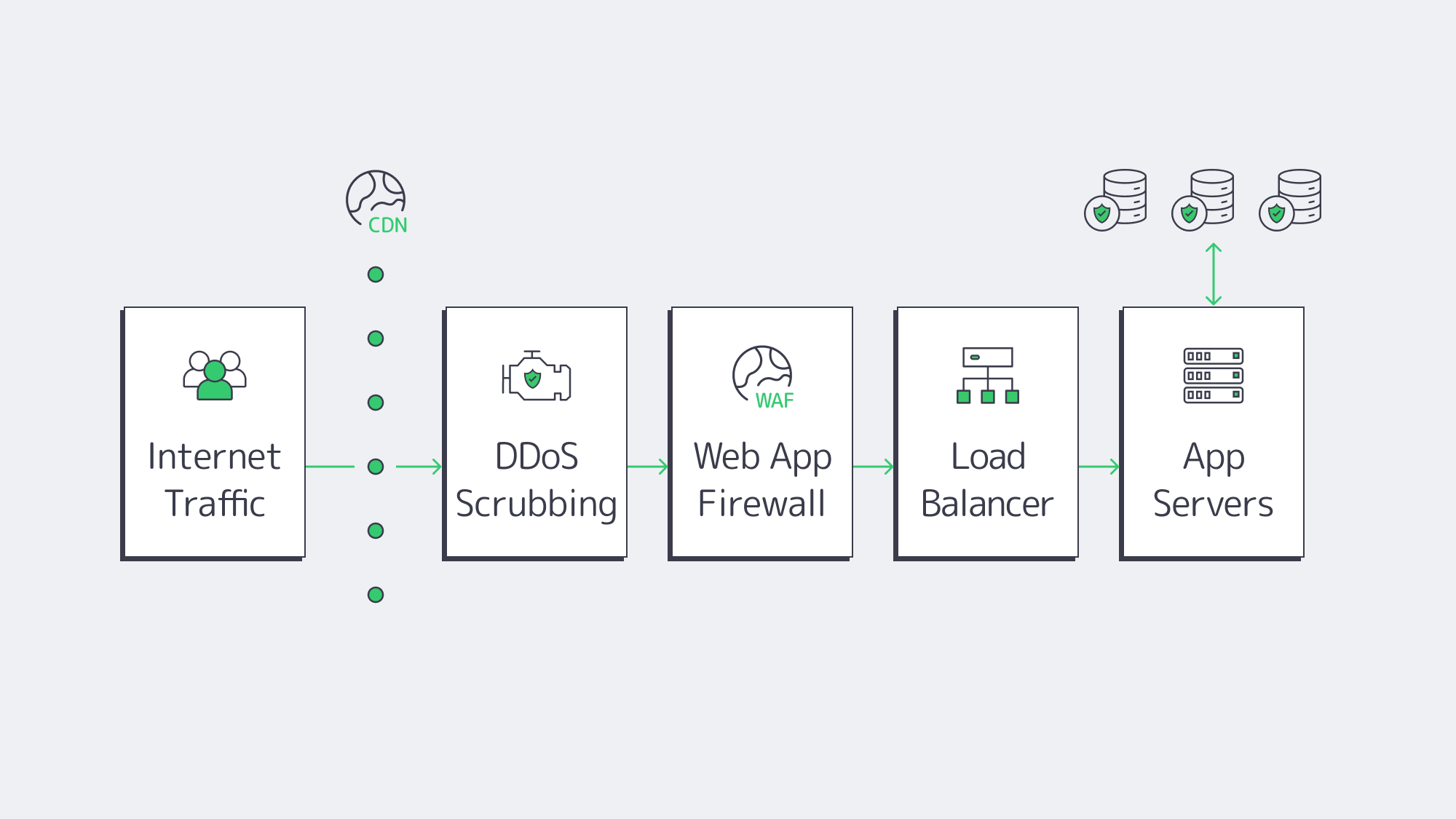
Dedicated Server Security: Encryption, DDoS Resilience, MFA, and Continuous Monitoring

Build a minimal-trust path: edge → WAF → app tier → transaction services → databases, each on distinct servers or server groups. Enforce mutual TLS between tiers, bind secrets to hardware, and log every hop with integrity checks.
Encryption at rest and in transit. Full-disk encryption protects logs and databases if media are removed; app-level encryption protects the most sensitive tables. Keys should live in HSMs or secure modules under operator control. On the wire, TLS 1.3 with modern ciphers is the baseline. Some teams are already planning for post-quantum crypto in high-value paths. Dedicated servers let you choose libraries and rotate keys on your cadence.
DDoS resilience and network controls. Because gaming absorbs a disproportionate share of global DDoS, network design must assume sustained volumetric attacks and low-and-slow Layer-7 campaigns. Dedicated servers integrate with upstream scrubbing, anycast routing, and rate-limiting at the edge; coupling with a global CDN soaks static load at distance while keeping regulated data anchored. The objective is compliance-grade availability: stay up, stay fair, and log precisely what happened.
Access control with MFA everywhere. Least-privilege access, hardware-backed admin credentials, and per-service identities shrink the blast radius. MFA blocks 99.9% of common account-takeover attempts; on dedicated servers you can enforce MFA for SSH/RDP, PAM, and back-office apps, tie privileges to change windows, and record every privileged session.
Continuous monitoring as a control, not an afterthought. SIEM pipelines pull logs from OS, runtime, database, and network layers; detections blend rules with ML to distinguish finals-night surges from credential-stuffing. Continuous vulnerability scanning and configuration compliance checks replace slow, point-in-time reviews. When something drifts—a weak cipher sneaks back in, a port opens unexpectedly—the system alerts and, where policy allows, auto-remediates. Paired with disciplined patch ops, this not only reduces risk but also yields audit-ready artifacts: evidence of controls working, in real time.
Fraud and game-integrity analytics at the host. Because you control the box, kernel-level agents can watch for tampering, RNG anomalies, or bot signatures without violating provider terms. That protects fairness—a compliance outcome—and delivers the telemetry auditors expect when they ask, “How do you know the game is uncompromised?”
Emerging Threats and Evolving Rules: Modern Answers

The threat model is changing fast. Attackers now combine AI-enhanced social engineering (e.g., deepfake voice phish), double-extortion ransomware, and API abuse aimed at payments and game providers. They probe for software supply-chain weaknesses and attempt to manipulate outdated game logic. Meanwhile, regulators add jurisdictions and tighten expectations on reporting, retention, and transparency. The cost of getting it wrong—fines, lawsuits, license jeopardy—keeps rising.
Modern countermeasures fit naturally on dedicated infrastructure:
Zero Trust and segmentation by default. “Never trust, always verify” between services. Place player databases, transaction processors, and game engines on separate server groups; require identity-aware proxies and mutual authentication for every call. If one tier is compromised, it can’t pivot. Dedicated hosting makes these guarantees concrete because topology is fixed and inspectable.
Compliance as code. Express the rulebook—approved ciphers, closed ports, password and key policies, file integrity monitoring, retention windows—as machine-readable baselines. Agents verify and enforce continuously, not quarterly. Drift becomes a ticket or an automated fix. During audits, you hand over change histories and control effectiveness reports rather than screenshots.
Automated audit support and regulator visibility. On dedicated servers, evidence collection is programmable: access logs, change manifests, performance and availability metrics, and signed configuration snapshots can be generated on demand. Where a regulator requires near-real-time supervision, expose a tightly scoped read-only feed without handing over operational control.
Operational agility to keep pace with rules. When a market introduces new data handling or reporting requirements, dedicated environments let teams implement them immediately—no waiting for a multi-tenant platform to expose features. That agility is behind a broader shift: a large majority of enterprises plan to repatriate some workloads from public cloud to regain control and predictability. In iGaming, control translates directly into faster market entry and cleaner audits.
Architecture Patterns That Satisfy Auditors (and Scale Under Load)
- Regional clusters for sovereignty. For each licensed market, deploy a jurisdiction-bound cluster: app/API, transaction services, and databases on dedicated servers inside the required borders. Keep PII and bet records local; replicate only what’s lawfully allowed, ideally in encrypted, minimized form.
- Global delivery without data sprawl. Use a CDN to cache static content worldwide and terminate traffic close to players, while keeping stateful workloads in the regulated region. This balances latency with sovereignty.
- Defense in depth with measurable controls. WAF and rate-limits at the edge; mutual TLS internally; FDE + HSM-bound keys at rest; SIEM-driven monitoring; and automated compliance checks as part of CI/CD and runtime. Every control produces evidence.
- Capacity engineered for spikes. Size for “finals night,” not Tuesday morning. Melbicom’s per-server bandwidth headroom supports burst handling while upstream mitigation scrubs attack traffic. Overprovisioned, isolated tiers prevent a noisy app from starving the transaction path.
Conclusion: Compliance and Security as a Single Engineering Problem

iGaming platforms don’t get to choose between speed, compliance, and safety—they must deliver all three. Dedicated hosting makes that tractable. By fixing data sovereignty at the infrastructure level, isolating critical services, and enforcing encryption, DDoS resilience, MFA, and continuous monitoring, teams reduce both the probability and the blast radius of failure. Just as important, single-tenant transparency makes audits faster and cleaner: where data lives, who accessed it, and what changed are questions the environment can answer with evidence.
Melbicom’s role in this picture is pragmatic. 1,300+ ready-to-go server configurations placed in the right data centers satisfy localization; Tier IV & Tier III data centers aligns with resilience goals; up to 200 Gbps per-server bandwidth and a 55+ location CDN support both peak traffic and robust edge defenses; and global reach enables jurisdiction-by-jurisdiction deployments. The result is an infrastructure posture that lets engineering prioritize fairness, availability, and trust—while compliance teams get the auditability they need.
Launch Your Dedicated Server
Deploy gaming-ready dedicated servers in your required jurisdiction today. Choose from 1,300+ configurations with Tier III & IV facilities, instant setup, and up to 200 Gbps bandwidth.
Get expert support with your services
Blog

Evaluating Mobile App Hosting Server Costs: Budget for Growth
Mobile apps have gone from side projects to top-10 downloads overnight on the news cycle. The cost of infrastructure typically increases when adoption rises. A structured cost-projection model enables the founder to manage the growth rather than be a bill chaser. The discussion below outlines the four forces that drive the hosting bill, compares the three prevailing backend architectures currently available, and explains how FinOps practice and more advanced sustainability metrics turn raw infrastructure into competitive advantage.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
How Much Does a Mobile App Hosting Server Cost and What Drives It?
| Driver | Why It Matters | Typical Cost Trigger |
|---|---|---|
| User concurrency | Determines CPU, memory, DB connections | Instance count, cluster size |
| Media weight | Images & video dominate traffic mix | Bandwidth and storage fees |
| Push traffic | Notifications create bursty loads | Elastic instances, queue capacity |
| Regional latency | Global users expect low RTT | Extra PoPs, data-sync overhead |
User concurrency
Your baseline fleet is determined by the peak concurrent sessions, not the monthly active users. Each node has a limit on the amount of requests-per-second; when that is exceeded, a different server (or VM) is brought online. Repatriating a database-intensive load, 37signals saved nearly 2 million dollars a year (Data Centre Dynamics), proving once again how fixed capacity flattens unit cost when concurrency goes above a few tens of thousands.
Media weight
Video has captured the majority of mobile data, accounting for approximately 73% of all downstream traffic (Economy Insights). At cloud-list rates at $0.08–$0.12 per GB egress, 50 TB/month streaming translates to a $4-5k line item. Dedicated servers may have unmetered ports; combining them with a CDN that offloads 70–90% of repeat hits can protect origin bandwidth at virtually no cost.

Mobile Data Traffic by Content Type (2024)
Push traffic
The average number of push notifications that smartphones get daily is 46 (MobiLoud). A single fan-out of one million devices can increase backend load 10x within a minute. Cloud auto-scaling increases resiliency against downtime but is billed per second at the peak capacity. Hardware does not suffer surprise invoices, but either requires headroom provisioning or throttling queues.
Regional latency
Rule of thumb: each 100 km of fiber will add ~1 ms round-trip. Users defect at RTTs over 100 ms—Amazon notoriously pegged that at a 1 % loss in revenue (GigaSpaces). Satisfying the threshold implies laying compute close to audiences, or putting a CDN in front. Melbicom delivers 21 global data center locations, including Tier IV in Amsterdam, and a 55+ PoP CDN, without the need to stitch together a patchwork of vendors.
Sample Cost Projection: 10 K vs 1 M MAUs
| Monthly Users | Hosting Model | Baseline Servers | Peak Cloud Nodes | Monthly Cost* |
|---|---|---|---|---|
| 10 K | Pure cloud | — | 8 | ≈ $2.9 k |
| 10 K | 1 dedicated + cloud burst | 1 | 2 | ≈ $2.0 k |
| 1 M | Pure cloud | — | 120 | ≈ $124 k |
| 1 M | 14 dedicated + CDN + burst | 14 | 20 | ≈ $66 k |
Assumptions: 150 requests per user / day; 500 MB media/user / month; 40 % CDN hit ratio; cloud egress $0.09/GB; dedicated bandwidth unmetered. Committed pricing: 1 mid-range server at $1.4 k/mo; 14 premium 32-core/200 Gbps servers at $4 k/mo each. Pure-cloud totals include managed DB, storage I/O, and monitoring charges.
Two lessons stand out
- Unit economics curve early. In this model, cloud is already more expensive than a single dedicated server at 10 k MAUs, and the difference widens rapidly beyond roughly 25 k MAUs.
- Media-intensive budgets are dominated by bandwidth. Offloading 40 percent of traffic to a CDN and pushing the rest through high-throughput dedicated ports can reduce total spend by approximately half when traffic gets heavy.
Choosing Among Today’s Hosting Options
Dedicated servers
Physical machines on a monthly basis are best in cases where workloads are consistent.
- Cost efficiency at scale. No premium per virtualization; the price per core decreases with the utilization.
- Consistent performance. The single tenancy prevents the noise of neighbors. Up to 200 Gbps ports on the Melbicom Amsterdam fabric easily accommodate ultra-HD video.
- Predictable budgeting. A single invoice; no surprise scale-outs
Trade-offs: Capacity can expand in step function increments and requires some amount of lead time (Melbicom maintains 1,300+ configs in inventory). OSs continue to be patched by Ops teams and clustering is managed.
Autoscaling cloud fleets
The most popular launch pad remains the public cloud.
- Instant elasticity. Instances are ready in minutes, removed when idle; ideal to deal with viral spikes or A/B tests.
- Managed ecosystem. Databases, queues, observability through API.
- Granular billing. Pay by the second—until traffic slows down.
Drawbacks: 27 % of cloud spend is wasted and 82 % of tech leaders now cite cost control as their top cloud pain (Flexera). Once a baseline is reached, dedicated hardware becomes less costly; a FinOps discipline is required.
Edge CDNs
Edge networks work around latency and reduce egress bills.
- Asset offload. Static media delivered close to users at low dollars per TB.
- Edge compute. Light scripts can run inside 50 ms on personalization or auth.
- Global reach, minimal footprint. Being able to have only one origin plus CDN can be cheaper on a per-user basis than multi-region backends.
Restrictions: stateful services still use central data stores and per-request metering can be painful as every API call moves outwards.
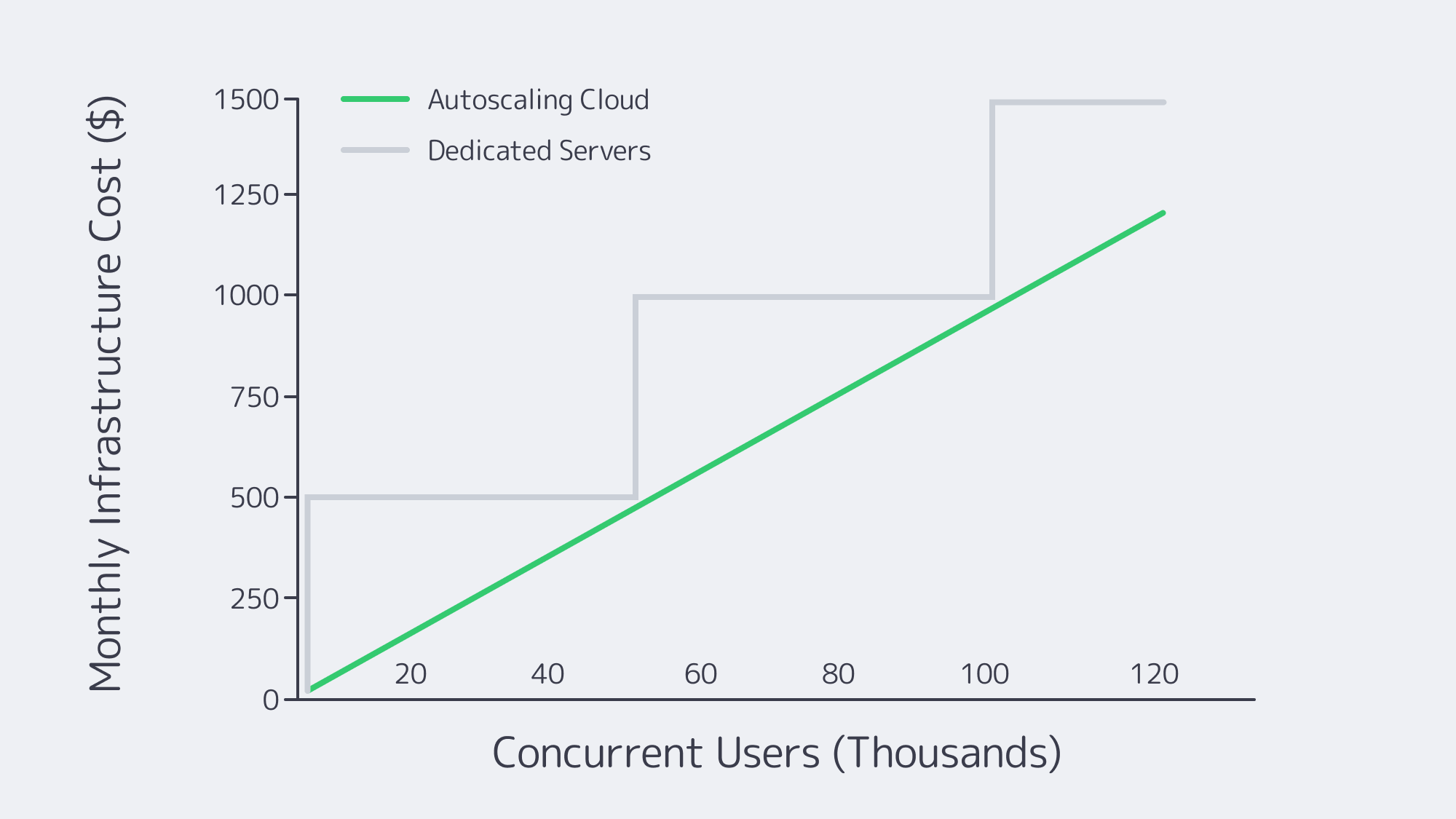
Cloud costs rise in lock-step with traffic; dedicated hosting spend climbs only when another server is added. Apps with high baselines hit break-even quickly.
Hybrid playbook in practice
The majority of roll-outs begin all-cloud. At ~50 k DAU, the bill triggers a migration: the primary database and transcoder migrate to two dedicated boxes in the Melbicom’s Amsterdam facility. Elastic cloud front-ends continue to scale. A CDN layer serves/caches ~80 % of origin hits. Latency goes down, costs remain stable, growth persists- the prototypical hybrid pivot that every scale-focused founder should plan.
FinOps and Sustainability: Cost Governance for the Decade
FinOps considers infrastructure as inventory: monitor it, manage it, relate it to revenue.
- Cost visibility. Tag resources, surface spend by feature.
- Continuous rightsizing. Turn off idle VMs, scale back oversized DBs, migrate consistent load to dedicated lower cost hardware.
- Smart commitments. Maintain a mix of reserved cloud, spot VMs and dedicated leases to achieve the best combination of flexibility and discounts.
- Automated schedules. Dev/test clusters that sleep during the night save 20-30 % of monthly charges.
On average, about 27% of cloud spend is wasted, and 59% of organizations now have dedicated FinOps teams. (Flexera).
The new multiplier is sustainability. The overall PUE worldwide is 1.56, but the new generation halls operate at 1.15. Equinix has reached 96 % renewable energy last year (Equinix); Melbicom has Stockholm and Amsterdam facilities that operate on heavily hydro- and wind-powered grids, which makes the energy both greener and price-stable. Compression of idle cycles, region selection, and aggressive use of caching reduces carbon and cost, now reported together as two KPIs.
From cost center to competitive edge
The FinOps dashboards that demonstrate the cost per push or carbon per signup, along with the latency charts, contribute to better code. Optimizing a single hot query can cut database spend by double-digit percentages; multiplied across microservices, those savings can fund entire feature sprints.
Regulatory pressure is increasing as well. In Europe, public tenders increasingly include annual CO₂ quantities per workload. We direct Nordic customers to our Stockholm data center, where emissions are less than 20 g CO₂e/kWh — about a tenth of the EU average. Cost and carbon optimization as one, and infrastructure becomes a sales opportunity as opposed to a compliance burden.
How to Future-Proof Your Mobile App Backend with a Hosting Server

The three attributes, cost, performance, and sustainability, are no longer in conflict. Plan your concurrency, media, push, and latency plots; forecast when cloud premiums sink their teeth; pre-provision bandwidth where video reigns; and deploy edge caches where RTT is critical. Hybrid architectures—dedicated servers in the steady core, cloud bursts at the peaks, CDN points at the edges—provide applications with the runway to go viral without head-spinning invoices, provided FinOps keeps the spotlight on unit economics.
Spin Up A Dedicated Server Today
Deploy premium hardware with 200 Gbps ports and global CDN support in hours and slash hosting costs.
Get expert support with your services
Blog

Dynamic BGP: Faster, Safer Networks for Growth
Organizations are spreading workloads across both public clouds and edge equipment and an extended array of data-center locations. In this world, the routing model in place today will decide whether the network tomorrow will be a business engine or a business decelerator. Static routing is still depicted on a variety of diagrams because it is visually clean: an engineer manually enters a next-hop address, commits the change, and the route is installed and takes effect immediately. But when there is an addition of a new subnet, signing of a new carrier contract or there is an outage, it necessitates another manual edit. According to Uptime Institute, about 80 percent of network failures are caused by human error, and Ponemon Institute research (as summarized by Atlassian) estimates average downtime costs near $9,000 per minute. Both of these figures are magnified by manual static routing, which increases risk and cost by inviting errors and delaying recovery.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — BGP sessions with BYOIP |
|
That fragility is replaced with automation—specifically, dynamic routing with the Border Gateway Protocol (BGP). Routers advertise what they can reach, learn what other routers can reach, and converge on the best policy-compliant path. A failure of a link causes the advertisement to disappear and traffic is redirected within seconds. When a new site appears, its prefixes are distributed and nobody needs to open tens of SSH sessions. The same protocol that distributes and exchanges more than one million publicly routed IPv4 prefixes among thousands of autonomous systems across the Internet can just as readily underpin a private fabric, delivering automated path discovery, policy control, and resilience. The next sections compare static routing’s manual overhead with BGP’s intelligence, quantify the resulting savings, and show how we at Melbicom make dynamic routing straightforward.
How Basic Static Routing Falls Short in Advanced Networks
Static routes refer to statements that are coded manually and can never change unless a human being changes them (e.g., “send 10.12.0.0/16 to 192.0.2.1”). Such a simplicity is good on a floor of access switches that does not evolve that much. It becomes a maintenance marathon across a mesh of fifteen branch offices spanning two clouds and several partners:
- Manual blast radius. It may take tens of routers to be touched to add a single data-center VLAN. Each modification introduces the potential of a typo, a missed hop or an ACL error, silent black holes that take hours to troubleshoot.
- No automatic failover. Losing a primary WAN circuit causes traffic to keep flowing in that dead end until the operator reprograms the path, minutes that penalize SLA values and user satisfaction.
- Zero policy intelligence. Static routing has no mechanism to favor lower cost carriers at peak, or pin voice traffic to links with low jitter, or direct European users to a PoP in the EU. Any adjustment needs another human input.
How the Border Gateway Routing Protocol Automatically Controls Resilience
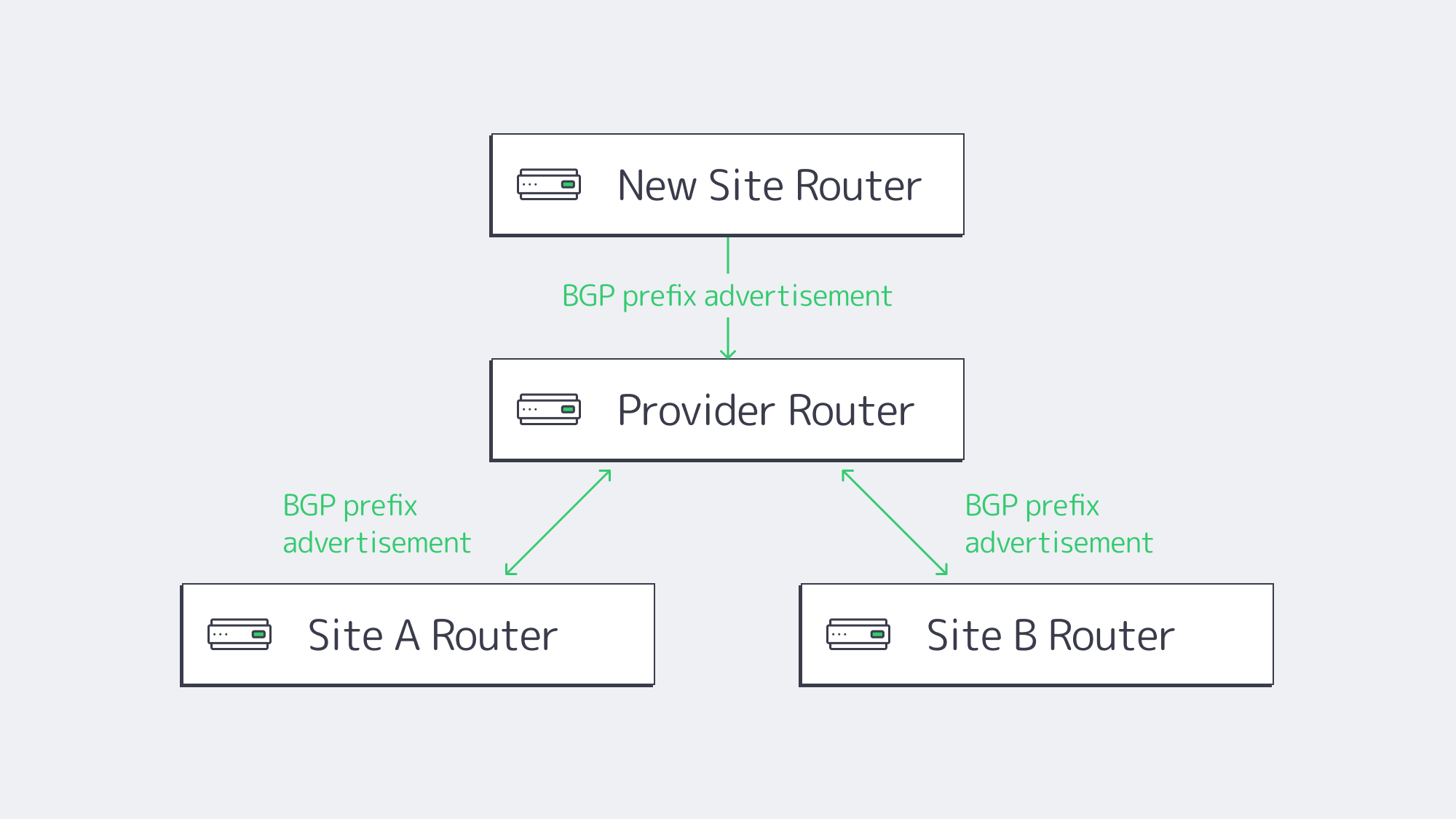
The border gateway routing protocol assumes networks change and dynamically adapts by propagating updates and selecting new best paths. BGP speakers exchange reachability information and tag their route announcements with policy attributes. There are three pillars as to why BGP scales where static breaks:
- Automated path discovery. As soon as a new prefix is announced, all the participating routers know about it, neither any spreadsheet scavenger hunt nor any midnight console session. Withdrawals propagate at the same pace, so failover typically completes before users notice.
- Policy control. Local preference, MED, and communities are attributes that allow architects to incorporate business intent, cap traffic on premium circuits, favor low-latency fiber, and guide partner flows through inspection stacks. These policies persist and continue to steer traffic even as the underlying physical paths change.
- Internet-scale resilience. Currently, BGP is already advertising more than one million prefixes in thousands of autonomous systems. When used with Bidirectional Forwarding Detection, pairing BGP means that sub-second failover is commonplace.
- Observability. Session telemetry exposes flaps, path changes, and upstream anomalies which would otherwise be obscured by static IP route lines, and would allow reactive firefights to become proactive analytics.
Latency and Cost Advantages in Modern Multi-Datacenter Architectures
The advantages of BGP are increased by multi-datacenter topologies. Imagine hubs in Los Angeles, Amsterdam and Singapore:
- Anycast service IPs. Each site is advertising the same /24. Global routing delivers users to the nearest instance, reducing round-trip time by 30–40 ms for European visitors without any DNS changes. If the Amsterdam site goes offline, its BGP route advertisement is withdrawn and traffic automatically shifts to Los Angeles or Singapore.
- Active-active bandwidth. Each site with two ISPs now does not mean primary/backup waste. Local-pref steers bulk traffic to lower-cost carriers while reserving high-SLA links for latency-sensitive flows, increasing utilization and reducing billing spikes.
- Link-specific tuning. Loss and jitter monitoring route-optimization engines can inject more specific prefixes to shift only the affected flows, leaving all contracted gigabits productive and without 95th-percentile burst charges.
Quick TCO Calculator: Static vs BGP
| Cost Component | Static Routing (Annual) | BGP Dynamic Routing (Annual) |
|---|---|---|
| Engineer labor for route changes | 50 changes × 1 h × $110 = $5 500 | 50 reviews × 0.1 h × $110 = $550 |
| Downtime from slow failover | 2 incidents × 20 min × $9 000 = $360 000 | 2 incidents × 1 min × $9 000 = $18 000 |
| Training & ASN fees | $0 | $4 000 |
| Five-year projection | >$1.8 M | < $120 k |
How to adapt: Enter your own number of incidents, outage minutes and labor rates. The majority of the organizations pay back the BGP setup costs in the first avoided outage.
Implementation Notes
Implementation of the border gateway protocol routing is not as difficult as it may sound:
- Start at the edge. Connect your primary data centers to upstream providers, and leave the LAN on OSPF or keep the LAN static. There is a low risk, and the rewards are quick.
- Set guardrails. Import- and export-filters guard against route leakage or full-Internet tables swamping the gear. Prefix-limits and max-AS-path filters are cheap insurance.
- Automate verification. Unexpected ads, flapping neighbors, or policy violations can be identified almost in real time by streaming telemetry, route-monitors, and what-if tools.
Security fits in as well. Contemporary implementations couple BGP with RPKI origin validation, BGP-LS feeds, and micro-segmentation in ways that ensure advertisements are valid, and lateral movement is limited, and dynamic routing is more intelligent and safer than its predecessor.
Melbicom Makes BGP a Checkbox
We at Melbicom take away the final obstacles. Dedicated and cloud servers may support BGP sessions with default, full or mixed route views. Our BGP session supports up to 16 prefixes—ideal for anycast footprints or multi-homed edge nodes. Pricing starts at 5 euros a month with a one-time setup fee—a negligible figure alongside the six-figure savings above. Sessions run over our 21-site backbone, which includes a Tier IV site in Amsterdam and several Tier III sites in Europe, North America, Africa, and Asia, offering up to 200 Gbps per-server connectivity. Since each PoP is connected to our 55+ location CDN, new prefixes are announced to edge caches within minutes reducing first-byte times and introducing regional redundancy. Our engineers are available 24×7 and fluent in BGP; we can advise prefix planning, policy tuning, and RPKI roll-outs when required.
Dynamic Routing as a Strategic Advantage

Static routing was the right solution to some obsolete problems; now it compounds them. Each manual entry is a cost and a liability and the list expands with every new site, circuit, and micro-service. The border gateway protocol BGP is the replacement of that brittle spreadsheet with a living, policy-driven map that heals itself, cuts latency, and enforces real-time cost control. The performance increases in multi-datacenter designs are quantifiable; double-digit performance improvements, six-figure in outage avoidance, and infrastructure that scales by policy and not by late night toil.
Dynamic routing is not a luxury feature to leaders who are planning the next expansion; rather, it is the operating system of the network. The sooner your routers speak BGP, the faster your business will move at cloud speed.
Order Your BGP Session Now
Enable automatic resilience and traffic engineering with a fully managed BGP session from Melbicom—live within minutes on our global backbone.
Get expert support with your services
Blog

Fortress-Like Security for Affiliate Networks on Dedicated Servers
Affiliate marketing’s growth has drawn a parallel boom in cyber risk. The signals are clear: nearly 40% of affiliate traffic is now fraudulent, a drain on budgets and an assault on attribution accuracy. At the same time, large-scale DDoS attacks have spiked 358% year over year, routinely taking down tracking, landing pages, and API endpoints when they’re needed most. The result is revenue leakage at multiple layers—acquisition, conversion, and payout—unless the infrastructure is designed to resist modern attack patterns end-to-end.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
The Attack Surface: From Fraudulent Traffic to Record DDoS Volumes
Bots and hostile automation now masquerade convincingly as human visitors, poisoning traffic quality, inflating conversions, and triggering phantom payouts. That “almost two-fifths” fraud share isn’t a rounding error; it’s the difference between profitable media buying and unprofitable campaigns that look healthy in reporting but don’t cash-flow in reality. Adversaries also target the high-value niches—adult, crypto, iGaming—where even short outages can derail revenue. On the availability side, volumetric DDoS assaults now arrive at a pace that once qualified as rare “black swan” events, with attack counts in a single quarter rivaling an entire preceding year. Affiliates that rely on instant redirects, postbacks, and real-time decisioning are uniquely exposed: if any link in the chain stalls, conversions evaporate, partners lose trust, and reputation suffers.
Historically, networks fretted over lower-grade nuisances—basic click fraud, crude scraper bots, trivial script injections. Those haven’t vanished, but they’re no longer the main story. The center of gravity has shifted to industrialized fraud operations and high-throughput denial attacks, demanding infrastructure, not just point tools, as the primary defense.
High-Performance Dedicated Servers for Affiliate Marketing: The Security Fortress
Dedicated servers provide the security posture affiliates increasingly need: isolation, transparency, and control. Single-tenant hardware means a smaller, well-defined attack surface and the freedom to set aggressive policies without worrying about noisy neighbors or cross-tenant risk. More importantly, the dedicated model lets you compose defenses in layers—network, transport, application, and data—so that no single tactic (or single failure) topples the stack.
DDoS mitigation that keeps the revenue growth
At fortress scale, protection must start upstream—before malicious floods hit your web stack. Network-level scrubbing, rate-limiting, and anomaly detection absorb volumetric surges so legitimate click-throughs, logins, and tracking calls continue to flow. In practice, that means: clean ingress pipes, consistent latency, and far fewer “brownout” conversions during hostile peaks. Attack frequency is up 358%, so always-on mitigation is now table stakes rather than an optional add-on.
For placement strategy, geographic distribution matters. Deploying nodes in multiple facilities creates air-gaps between failure domains and gives you more vantage points to shift traffic when a region is targeted. Melbicom operates 21 global data centers featuring Tier IV and Tier III halls—and per-server capacity up to 200 Gbps—enabling high-bandwidth configurations that resist and reroute hostile traffic without sacrificing user experience.
WAF and bot controls: Gatekeeping the app layer
A modern Web Application Firewall (and associated bot management) filters the subtler threats—credential stuffing against login portals, injection attempts on tracking or admin APIs, and fake sign-ups that skew CPA economics. On dedicated servers you can tune rulesets for your actual traffic patterns (e.g., known publisher IP ranges or geo allowlists), deploy deception endpoints, and enforce stricter policies without collateral damage to other tenants—because there aren’t any.
Encryption and key security: Seal the inner core
Strong TLS at the edge and encryption at rest across click logs, conversion tables, and payment records cut off a whole class of regulatory and breach risk. Dedicated environments simplify key management—HSMs, TPM-backed stores, and tight OS-level hardening—so that even if someone touches the storage, they don’t touch the data.
Multi-server redundancy: No single point of failure
Affiliate workflows are chains: source click → redirect → landing page → conversion → postback → payout. Redundancy ensures a break in one link doesn’t snap the chain. Active-active clusters and multi-region failover keep redirectors and tracking online when you’re under duress or during maintenance windows. When combined with a CDN footprint of 50+ nodes across 36 countries, static assets and cached pages stay close to users while origin traffic stays controlled and predictable.
Performance as Protection: Speed That Preserves Conversions
Security hardening must not slow the business. Properly built, fast dedicated hosting for CPA networks delivers the opposite: security and speed. Capacity at the NIC, kernel tuning for high-concurrency HTTP, and modern TLS offload keep latency low while defenses stay engaged. The payoff is tangible: fewer rage-quits on mobile, healthier quality scores, and steadier EPC when campaigns surge.
Reduce affiliate landing-page load times
Reducing time-to-first-byte and keeping render paths lean is itself a fraud- and DDoS-resilience tactic: the less time each session spends in the funnel, the less exposure to synthetic traffic stalls and cascade failures. Caching at the CDN edge plus small, fast origins minimizes origin load under attack and keeps human users moving.
NVMe dedicated servers for conversion-rate optimisation
For heavy read/write workloads—offer catalogs, stats dashboards, event streams—NVMe storage on dedicated servers cuts I/O wait to a sliver, ensuring tracking writes and analytics reads don’t contend. That throughput headroom preserves consistency under peak loads, which is when campaigns make or lose their ROI.
Emerging Defenses: AI-Driven Detection and Adaptive Controls
Static rules alone can’t keep pace with shifting bot behavior and novel L7 attacks. Affiliates are layering AI-driven threat detection on top of the fortress: models that learn publisher baselines, session dynamics, and conversion semantics, then flag or throttle anomalies in real time. Examples include: collapsing traffic from low-reputation ASNs, quarantining bursts of “too-perfect” user agents, or pausing payouts on statistically impossible conversion paths pending review. Pair that with Zero Trust inside the private network—mutual TLS for services, short-lived tokens, device posture checks for operator consoles—and lateral movement becomes much harder even if a credential leaks.
Critically, AI-assisted controls should be integrated with automated incident response: trigger a geo-shift to a clean region, rotate keys, or ratchet WAF strictness for an affected route—without waiting for a human. On dedicated servers you control the knobs, so playbooks can touch kernel parameters, BGP policies, or CDN rules instantly. The result is a system that learns and adapts as adversaries evolve.
Quick Reference: Threats to Controls
| Threat (typical symptoms) | Revenue risk | Fortress control (dedicated-friendly) |
|---|---|---|
| Volumetric DDoS (timeouts, 5xx spikes) | Lost clicks/conversions; chargebacks | Upstream scrubbing, per-region traffic steering, high-bandwidth uplinks, multi-region origins. |
| Bot fraud (fake clicks/sign-ups) | Wasted budget; polluted attribution | WAF + bot management tuned to traffic patterns; behavioral scoring; allowlists for partners. |
| Credential abuse / panel takeover | Offer hijacks; payout fraud | MFA, device binding, strict rate limits, Zero Trust service mesh; encrypted secrets storage. |
| Origin saturation (flash crowds + attack) | Slow pages; SEO penalties; EPC drop | CDN with 50+ nodes, edge caching; NVMe origins; autoscaling playbooks and request shedding. |
Where Melbicom Fits: The Infrastructure You Control, The Outcomes You Can Trust

The strategic lesson is straightforward: security and performance must be architected—not bolted on. Dedicated servers give you the isolation to run strict policies, the capacity to absorb hostile spikes, and the control to automate incident response. Deployed across multiple regions, with a WAF in front and encryption in depth, your network becomes hard to disrupt and easy to scale. That’s how you protect revenue even as adversaries escalate.
Melbicom aligns to that blueprint. Melbicom operates 21 data centers worldwide, including Tier IV and Tier III facilities, with per-server bandwidth options up to 200 Gbps for traffic-heavy platforms. A CDN with 55+ points of presence reduces global latency, and 24/7 support helps teams act quickly when conditions change. These are the ingredients to build the fortress once—and keep it modern as threats evolve.
Order Your Dedicated Server
Secure your affiliate infrastructure with high-performance dedicated servers from Melbicom.
Get expert support with your services
Blog

Reduce Latency With Melbicom’s Multi-Region Servers
According to the statistics, affiliate marketing is now a $17-billion industry growing annually by roughly 10%. The early audience growth was concentrated in areas with traditional data hubs, but expansion has since shifted further afield — into regions such as the Indian subcontinent and West Africa, where West Africa alone represents a potential base of over 200 million users. However, those new clicks arrive with a tough technical ceiling for performance marketers because the distance induces latency. Pages loading in Lagos or Mumbai can take up to four seconds, in contrast to 800 milliseconds for Frankfurt-based visitors. Four seconds might not sound like much, but it can cause up to 40% of users to abandon the page entirely, and when every redirect and pixel fire counts, mere milliseconds can cost revenue. The link has been quantified as “+100 ms = –1 % sales” by Amazon engineers, as reported by GigaSpaces.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Adding extra CPU is no longer the strategic solution; instead, you have to focus on combating the distance and moving “closer to the click.” At Melbicom, we close that gap by procuring dedicated servers distributed across continents, serving as origins, anchored by a 55-plus-PoP CDN to enable affiliate networks to deliver global sub-second user experiences, be it from Los Angeles to Singapore or from Warsaw to Nigeria.
How Do Global Dedicated Server Locations Reduce Latency for Affiliate Platforms?
Latency boils down to physics and routing. Light in fiber travels at a maximum of ~66 µs per 10 km, and that baseline is typically doubled or even tripled by circuitous paths. An AFRINIC study in 2023 reported >150 ms in-country RTTs across much of West Africa, with some pegging in at 350 ms. Microsoft’s public telemetry reports ≈220 ms latency between South India and the core regions of the U.S.. Affiliate funneling adds to those round-trip operations from tracker to geo-router before the landing page, which is what takes the total wait time beyond the three-second mark.
Table 1 – The true price of distance
| Hosting setup | Round-trip time (RTT) to Lagos visitor | Expected conversion delta* |
| Single EU server (Frankfurt) | 180–220 ms | –15 % to –25 % |
| Lagos local server (Melbicom LOS1) | 25–40 ms | Baseline |
*Calculated from the Amazon + Akamai data that shows each 100 ms delay trims between 1%–7% of conversions.
Revenue can be recouped with a conservative 150 ms shave. When it comes to performance marketing, that marginal difference could be what separates the profitable from the break-even campaigns when scaling paid ads.
Latency Headwinds Seen in Modern Emerging Markets Globally
- Subscriber surges over weak paths: Over 160 million new broadband users emerged in Sub-Saharan Africa between 2019-2022, according to the World Bank, but the majority (75 %) of intra-African traffic operates through European networks, which is why RTTs are so high.
- Mobile user impatience: Nigeria alone has around 163 million internet users, many of whom connect primarily via mobile devices, according to Trade.gov. Mobile users are often more impatient, meaning every millisecond counts.
- Rich payloads. The heavy JavaScript bundles demanded by popularly accessed services such as Crypto dashboards, iGaming lobbies, video segments, and adult HD streams choke narrowband links.
Why Single-Server Hosting No Longer Competes
Once upon a time, a lone data center based somewhere like London or Virginia was “global enough,” but with modern expansion, it is a liability. The long routes are detrimental to SEO, there is often higher waste in terms of ad spending, and a single server means a single point of failure. An additional CPU at that same site improves nothing for distant visitors. Affiliates that neglect to geo-split their origins in today’s market are essentially risking conversion leaks.
Cross-Border Data-Center Network Architecture for Affiliate Campaigns
Melbicom offers an ideal architecture operating with 21 Tier III/IV sites across North America, Europe, Asia, and most importantly, Africa. We have 1,000+ configurations ready to go, each offering 1-200 Gbps of per-server bandwidth, supported by a global network with 14 Tbps aggregate capacity, and they can be racked in under two hours.
- West Africa, Lagos: The first-byte latency reported for Nigeria’s 200 million-plus market and neighboring regions is slashed by having a direct local presence.
- South Asia, Mumbai: Domestic users see latency reduced to under 50 ms locally, while international paths such as the U.S.–India loop avoid the 220 ms delays by routing through regional IXPs.
- Mediterranean transit, Palermo: The quality scores for North-African and Middle-Eastern routes improve by up to 80%, thanks to Palermo’s cable-landing position that trims latency by 15–35 ms.
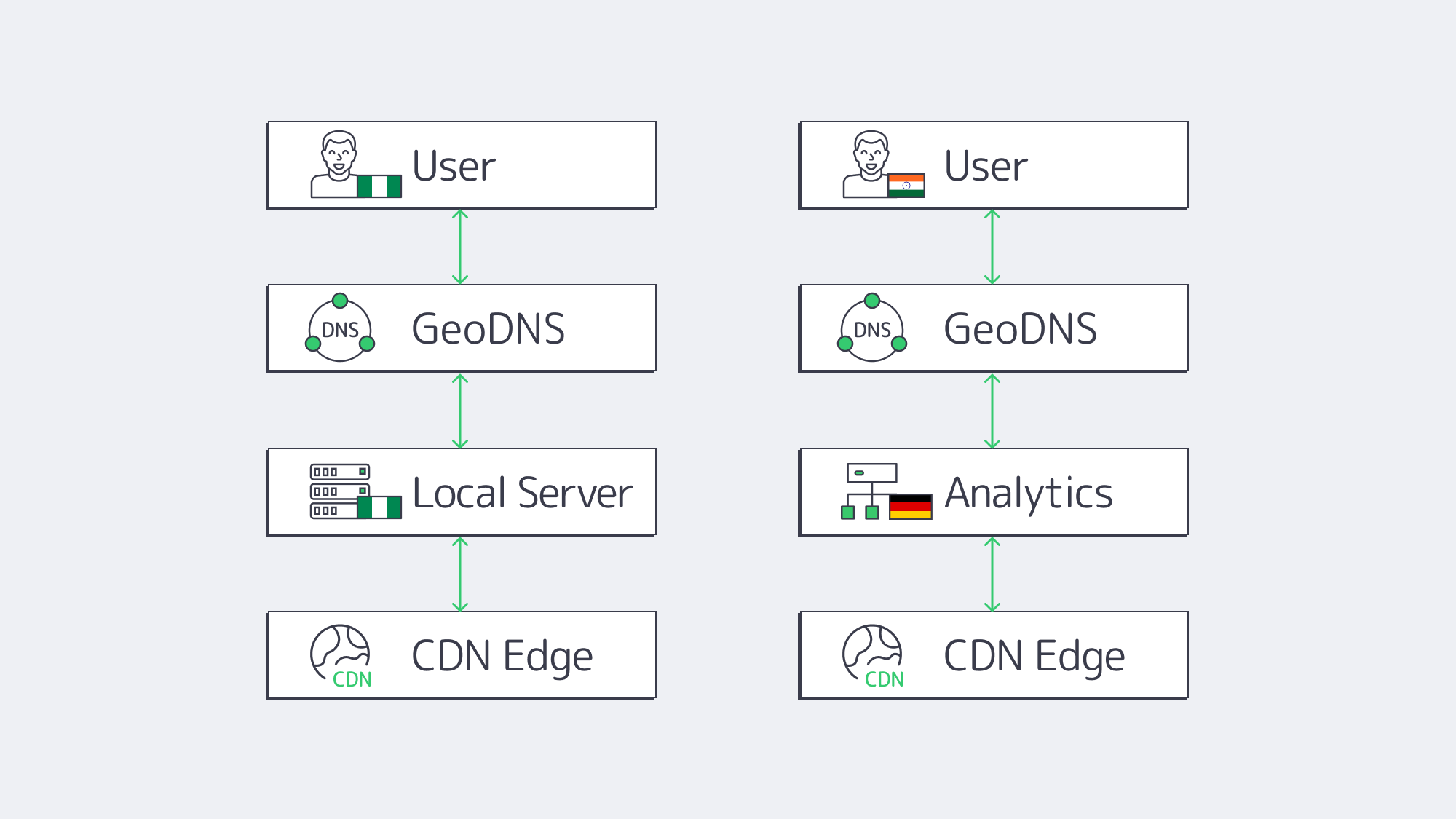
At Melbicom, we can stitch these locations into a multi-region dedicated-server mesh for affiliate marketers using GeoDNS or anycast records to help steer traffic to the nearest live node. The real-time metrics in our portal help flag regional spikes, making it easier to scale horizontally when needed, without unexpected markups or hardware sharing like with cloud setups.
Low-Latency Affiliate Hosting in the US, Europe, and Beyond
Traditionally, hosting in Ashburn for the U.S. and Amsterdam for Europe was the general consensus, which, granted, covers core revenue, but there is a need to adapt since growth has headed south and east. If you don’t want distance-induced latency affecting users of game studios, crypto exchanges, live play table-stakes, or order-book sprites further afield, then the Atlanta (ATL2), Palermo, and Lagos networks are needed to help keep North-Atlantic RTTs under 40 ms and West-African and Gulf RTTs under 50 ms.
The Benefits of Multi-Region Dedicated Servers for Performance Marketers
Each Melbicom’s location uses the same control panel and API, so we can spin up test servers quickly in any region. We also provide free 24/7 support, enabling campaign architects to do the following:
- Split funnels, keeping heavy personalization or analytics in a single hub by running tracking and click-redirects on light, regional CPU nodes.
- Isolate spikes locally, meaning spikes and overloads such as a weekend iGaming tourney in one region won’t affect another.
- Store data within its respective borders, e.g., EU user data inside EU racks, North American data in Los Angeles, without rewriting app logic.
How Do CDNs and Multi-Region Dedicated Origins Work Together?
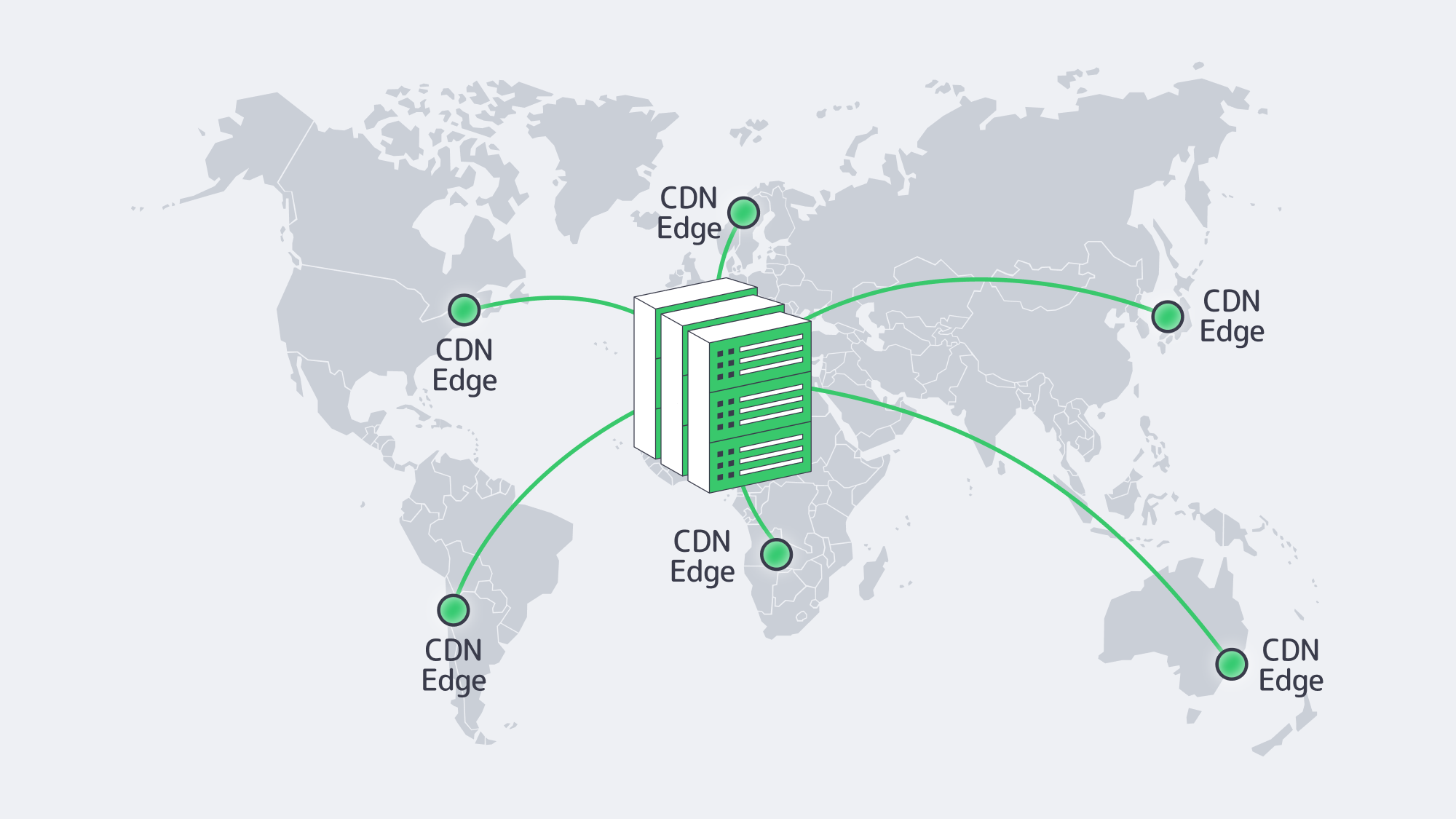
A CDN accelerates cacheable assets at the edge, but minimizing latency for dynamic requests requires distributed origins placed close to users. Melbicom’s 55-plus PoP CDN spans 36 countries in six continents, serving static assets over HTTP/2 and TLS 1.3, and supports Brotli compression out of the box. Perfect for running 4K preview clips. The edge caching offloads terabytes from the origin and delivers segments from city-local PoPs, shaving anywhere between 30-80 % of total page weight latency.
Cache-miss traffic never leaves our backbone because the CDN is co-located with many Melbicom data centers, as well as extending and complementing Melbicom PoPs. This means there are no CDN backhaul surprises due to data unexpectedly transiting an expensive submarine hop. With Melbicom, a Lagos PoP pulling from a Lagos origin stays on a sub-5-ms path, keeping traffic on-net and avoiding transoceanic backhaul.
The origin and CDN act as a single fabric rather than two separate billing lines, which means less engineering, rapid first render, and lower paid-traffic costs.
Outrunning the Click with Dedicated Servers

Global affiliate marketing was once gated by creative factors and compliance mandates, but today it is being gated by physics. Regardless of where the next 100 million users come online from, they will expect instant experiences, which means the single-server blueprint has had its heyday. If you don’t want to watch conversions drain away with every extra round trip, then you need to look to infrastructure that helps accelerate growth, not throttle it. The Melbicom roadmap houses servers and edges ever closer to emerging audiences, providing infrastructure that does just that.
Get low-latency hosting today
Deploy a performance-tuned dedicated server in any of Melbicom’s 21 global data centers and reach your audience in milliseconds.
Get expert support with your services
Blog

Dedicated Server Storage Options: HDD vs. SSD vs. NVMe—Speed, Cost & Fit
Storage speed, scale, and cost are the lifeblood of modern infrastructure. When you’re tuning an AI training cluster, pushing multi-gigabit video streams, or safeguarding years of company records, the decision to use hard disk drives (HDDs), SATA solid-state drives (SSDs), or NVMe SSDs will determine both the user experience and the bottom-line economics. In this concise reference, we compare the three media in terms of latency, IOPS, reliability, power consumption, and cost-per-terabyte and align them against the workloads that take the most dedicated-server space.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
How Did Dedicated Server Storage Evolve from HDD to NVMe?
Data centers were dominated by spinning disks until recent post-2018 declines in price enabled flash at scale. SATA SSDs removed all the mechanical delays and reduced the average access time to microseconds, compared to milliseconds. NVMe, which links flash directly to the PCIe bus, eliminates the final SATA bottlenecks with 64,000 parallel queues and throughput into multi-gigabytes per second. The issue is no longer to select one winner but to combine media intelligently.
How Do HDD, SSD, and NVMe Compare on Latency, IOPS, and Throughput?
| Storage Type | Typical Random-Read Latency | 4 KB Random IOPS | Max Sequential Throughput |
|---|---|---|---|
| HDD (7 200 RPM) | 4–6 ms | 170–440 | ≈ 150 MB/s (up to 260-275 MB/s peak on outer tracks) |
| SATA SSD (6 Gbps) | 0.1 ms | 90 000–100 000 | ≈ 550 MB/s |
| NVMe SSD (PCIe 4.0) | 0.02–0.08 ms | 750 000–1 500 000 | 7 000 MB/s |
Latency
The seek and spin delay of a hard drive is roughly two orders of magnitude slower than flash. In high-touch apps, e.g. transactional databases, virtual-machine hosts, API backends, that latency surfaces millions of times per second becomes the bottleneck on perceived performance to the user.
IOPS
A few hundred random operations per second is the maximum sustained by an HDD, and is attained by a single busy table scan. SATA SSDs are lapping 90 k IOPS, PCIe 4.0 NVMe drives surpass 750 k and premium models approach or exceed 1 M IOPS. With the workloads that generate thousands of simultaneous I/O threads, NVMe is the only interface that maintains shallow queue depths and high CPU utilization.
Throughput
Bandwidth is most important to sequential tasks such as backup jobs, video streaming, model checkpointing. A 1 TB set of data can be transferred by one NVMe SSD at 7 GB/s in less than three minutes, whereas it takes almost two hours to do the same with an HDD. The difference is further increased on PCIe 5.0 where early enterprise drives exceed 14 GB/s.
Which Storage Is Most Reliable—and How Do DWPD Ratings Matter?
Both HDDs and enterprise SSDs claim a mean-time-between-failures in the millions of hours, but the modes of failure are different:
- HDDs have mechanical wear, vibration sensitivity, and head crashes. They frequently have SMART warnings before failure, and occasionally, failed platters may be imaged by a recovery lab.
- SSDs do not have any moving parts and experience slightly lower annualized failure rates, but flash cells cannot withstand an infinite number of program/erase operations. Enterprise models are rated in wear in the form of drive-writes-per-day (DWPD); light-write TLC units can be rated up to 0.3 DWPD over 5 years, and heavy-write SKUs can provide 1-3 DWPD. They rarely bounce back in case they fail.
Practical takeaway: mirror or RAID whichever you trust with data you can never get back, over-provision SSD space on write-heavy work, keep drive bays cool to extend their life.
How Do HDD, SSD, and NVMe Compare on Energy Use and Cost per TB?
An enterprise HDD consumes ~5 W at idle, while a SATA SSD typically consumes ~1–2 W at idle (around 2 W for 128 GB models and ~4 W for 480 GB models). With the sustained load, however, a high-end NVMe drive can draw 10 W or more as it transfers data tens of times faster. Consider the metric of work-done-per-watt instead: NVMe delivers far higher IOPS-per-joule, while large HDDs remain superior in capacity-per-watt. A recent test of a vendor disk revealed that it wrote data with approximately 60 percent less energy per terabyte compared to a 30 TB SSD deployed to perform the same archival workload (Windows Central).
Cost says almost the same. Near 20 TB disks have now been dropping to about 0.017 / GB, and enterprise NVMe is still at ≈ $0.11–$0.13 / GB (typical) and consumer SATA SSDs at around 0.045 / GB. At scale the delta increases: to fill a petabyte it will take ~50 helium HDDs or 125 NVMe drives. Electricity, rack space and cooling reduce the difference a little; media cost remains the largest contributor of total cost of ownership in bulk storage.
Matching Media to Workloads
AI / Machine Learning / HPC
GPUs are waiting microseconds for arriving tensor data, but every millisecond of idle costs dollars. NVMe microsecond latency and 7 Gbps reads ensure that pipelines are full. Training volumes too big to fit pure flash may train subsets on NVMe and leave the long-tail on HDD or in object storage. PCIe 4.0 is now sufficient; PCIe 5.0 doubles the headroom for next-gen models that have a wider data footprint.
Media Streaming & CDN Origins
Streaming video is to a great extent sequential. Some HDDs in RAID have sufficient bandwidth to support 4K streams when file requests are mostly sequential. Then there is the issue of concurrency — hundreds of viewers accessing various files simultaneously causes random seeks. A hybrid origin spreads out the performance and SSD caching in front of HDD capacity balances the performance and keeps the cost down. Use high-bandwidth NICs with paired disks; Melbicom regularly configures 10, 40, or 200 Gbps uplinks so that the storage never saturates the link.
Transactional Databases & Enterprise Apps
Each commit makes an entry in the log; each access of the index is a random access. In this, transactions per second are put in check by the 5ms latency of HDDs. SATA SSD is a starting point, and NVMe delivers tens of thousands of TPS with predictable sub-millisecond response. For write intensities greater than 1 DWPD, use high-endurance SKUs. Most operators replicate two NVMe drives to be durable and not to lose performance.
Archives, Backups, and Cold Data
Cold data is quantified in dollars instead of microseconds. Helium-filled, multi-terabyte HDDs are impressive, with decade-level storage available at pennies per gigabyte. Sequential backup windows fit disk strengths like a glove and restore time is more often than not a scheduled event. For off-site copies, supplement on-premise disks with tape or S3-compatible object storage. Melbicom SFTP and S3 services deliver economical durability without compromising SMB-friendly interfaces.
NVMe-over-Fabric and PCIe 5.0

NVMe-over-Fabric: The NVMe low-latency protocol is extended over Ethernet or InfiniBand by NVMe-over-Fabric, collapsing the divide between direct-attached and networked storage. Latency overheads are in the tens of microseconds—insignificant in most apps—making it feasible to pool flash at rack scale. The technology is now within the scope of mid-sized stacks with the early deployments already booting servers off remote NVMe volumes and converged 25-100 GbE switches in the market.
PCIe 5.0: PCIe 5.0 doubles the bandwidth per lane of Gen4. Peak performance of debut drives is 14 GB/s reads and ~3 M IOPS, a level that would have matched small all-flash arrays only a couple of years ago.
How to Build a Tiered Dedicated Server Storage Stack
All-flash or all-disk is seldom the smartest storage architecture. Use NVMe on ultra-hot datasets, SATA SSD on mixed workloads and high-capacity HDD on cheap depth. This three-tier system maintains responsiveness to critical applications, feeds GPUs, and maintains budgets. From a practical point of view:
- NVMe pools sized to support maximum random I/O loads — AI staging, OLTP logs, and latency-sensitive VMs.
- Pin SSD caches to HDD source when hot and cold media libraries or analytics data exist.
- Store immutable archives on helium HDDs or off-server object buckets.
- Validate dedicated servers have modern PCIe lanes and at least 10 Gbps networking so storage isn’t gridlocked.
We at Melbicom regularly design these hybrids that allow customers to combine over 1,300 prebuilt server configurations at 21 Tier III-plus data centers and scale port speeds up to 200 Gbps per server.
Conclusion

The decision of storage for a dedicated server is, after all, an exercise in aligning performance thresholds with business goals. NVMe is latency and IOPS pushing, with SATA SSD being a compromise between speed and cost, and HDDs retaining their position as the affordable capacity option. With this knowledge of each medium’s behavior at various workloads, including streaming, transactions, and archival, you can design a tiered stack that meets today’s needs and scales to the NVMe-over-Fabric world of tomorrow.
Configure Your Dedicated Server
Choose from 1,300+ prebuilt configs, add NVMe or HDD, and scale bandwidth to 200 Gbps.
Get expert support with your services
Blog

Cheapest Dedicated Server Hosting in India: Risks of Going Low-End
If your budget is restrictive or you are on a brand-new founding adventure, then the promises of the cheapest dedicated server hosting in India are more than appealing. The rapid expansion of India’s data-centers has resulted in the country’s IT load tripling between 2019 and 2024 , and along with the industry’s boom, have come the irresistible rock-bottom prices advertised by countless providers. However, these reel-you-in headline prices are rarely what they seem. What lies beneath the shiny offer is often a compromise rather than a promise. The networks are typically oversubscribed, and the MSAs are little more than boilerplate on closer inspection. When you consider the support gaps, the total cost of ownership (TCO) rises considerably. However, value-oriented providers, like Melbicom, hosting within India can offer low-cost dedicated servers without sacrifice, but it is important to be able to know what is myth and what is reality, so let’s take a look.
Choose Melbicom— Dozens of ready-to-go servers — Tier III-certified DC in Mumbai — 55+ PoP CDN across 6 continents |
|
Initial Appeal Wears Thin
Many hosts boast the “best dedicated server hosting in India,” and some of these cut-rate subscription plans will cost you less per month than a streaming service. This is often used to lure in startups, but servers are not commodities, and you get what you pay for, which, unfortunately, just might be dated CPUs, mismatched memory, or throttled bandwidth. All of which spell performance and reliability issues as soon as any real growth kicks in.
What Lurks Behind the Bargain
Outdated Hardware Slashes Performance Per Euro
Cheaper providers frequently harvest processors from retired hyperscale fleets, meaning you could be relying on hardware that is five- to seven years behind. The “16 cores” listed in the specs can be misleading, given the difference in single-thread speed between a 2012 Xeon E5 and a 2018 Core i9, the latter of which is twice as fast. These older setups are usually lacking modern cache and PCIe lanes, which risks noisy-neighbor I/O resulting in longer workloads, higher memory use, and forced premature scaling. A current generation CPU might cost around 10–15 % more initially, but given that you can double your throughput, it quickly compensates for the monthly savings promised by a bargain deal.
The “Unlimited” Bandwidth Tactic
While the port may well be genuine, the uplink capabilities are another selling point that is oversold. The promise of unlimited bandwidth doesn’t mean much when dozens of tenants are competing for transit at peak hours. Another favorite is the 1 Gbps burst pitch, which again is trivial if you are fighting for a few gigabits of transit. Peak-hour throughput can plunge by as much as 70 %, and for anyone operating in real-time, that simply won’t suffice. At Melbicom, we have dedicated links of up to 40 Gbps per server, which we deliver via carrier-neutral rings based locally in our Tier III facility in Mumbai, ensuring your traffic never has to compete.
Bare-Bones MSAs and Uptime Risk
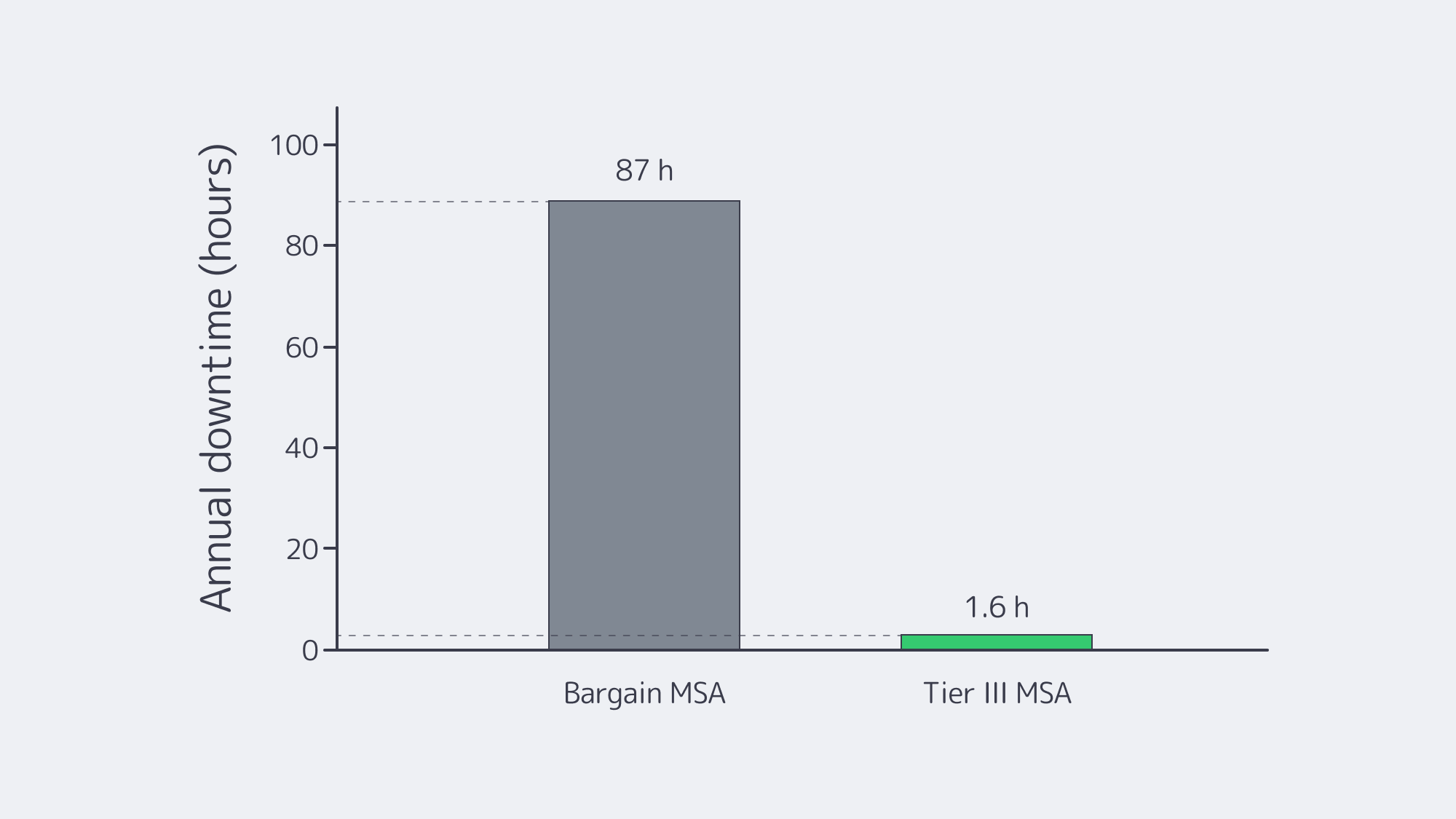
The MSAs of low-end hosts rarely exceed a page and promise nothing more than “best-effort” network availability, amounting to about 99 % uptime—in other words, 87 hours of downtime annually. In contrast, Tier III engineering builds have a target of less than or equal to 1.6 hours. When every hour offline affects the conversions and churn metrics of a subscription-based business, the uptime risk is a big factor. The median outage for mid-size SaaS is about 9,000 dollars per minute , and by that calculation, the savings gained by leveraging the cheapest plans are wiped out in just two incidents.
The Bottom Line: You can protect your revenue in the long run with a stronger MSA with redundant power backing it, cooling in place, and multi-homed fiber, all of which trump the low price tags advertised.
Limited Support Means Inevitable Labor Costs
Support is another area that is often lacking with a bargain host; most of the time, support hours are restricted, or subject to email queues, and some even sell it as an add-on, meaning unexpected costs should a kernel panic strike at an unsociable hour. You also lose valuable development time when you’re left to flounder as your own data-center technician, a cost that is rarely factored into the spreadsheets.
With Melbicom, you get 24/7 engineer access and rapid hardware swap included in your price as standard, so you can focus on shipping product, instead of remote-hands tickets.
What “Cheap” Really Costs: A Side‑by‑Side TCO View
| Factor | Ultra-Cheap Server | Quality Dedicated Server |
|---|---|---|
| Hardware age | 5–7 yrs old; refurbished | Latest-gen enterprise silicon |
| Guaranteed bandwidth | Shared uplink; variable | Dedicated 1–40 Gbps |
| Annual downtime ceiling | 99 % in MSA ≈ 87 h | Tier III design ≈ 1.6 h |
| Support model | Email queue or paid | 24/7 live engineers |
| Likely hidden cost | Scaling early, outage losses, DIY troubleshooting | Predictable opex, faster scale-up |
With a long-term overview that factors in traffic growth, incident response, and early hardware refresh, a bargain server winds up costing between 25 and 40 % more than a mid-tier server over a three-year period.
Summarizing the Myths Versus the Reality
- All “16-core” servers perform equally: Modern 8-core often outperforms legacy 16-core, so the generation is vital.
- Unlimited bandwidth means smooth, reliable networks: Throughput is often throttled at peak hours when it is needed most, as networks are often oversubscribed.
- 99 % uptime is sufficient: 99% equates to 87 hours offline, lowering brand trust and destroying ARR.
- Support is an optional extra: Nothing burns dev hours quite like troubleshooting in the dark. Rapid 24/7 help is priceless.
Melbicom’s Role

- Dozens of Mumbai-based ready-to-go configurations with NVMe, single and dual XEON CPUs, and 20 additional global locations for edge use cases.
- Up to 40 Gbps of dedicated bandwidth delivered via carrier-neutral IXs.
- English-speaking support is provided around the clock, included in the MSA, with a swift hardware swap when necessary.
- 55-plus-POP CDN access for static acceleration without extra egress fees.
By choosing Melbicom, founders can secure a single-vendor relationship with round-the-clock support that ensures predictable performance and global scale, regardless of India traffic spikes, without the noise, challenges, and hidden fees of multi-provider complexity.
Cutting Corners: A Ropey Strategy
User experience is crucial for startups hoping to build brand recognition and trust. If your pages lag, or your users experience intermittent outages, then growth becomes less likely. The modern world is fast-paced, and customers are used to instantly responsive content, especially Americans and Europeans. So while it can be tempting to cut corners as a founder with a low budget, you need to weigh up whether that dollar “saved” outweighs the economic risks of missed conversion opportunities, churn, and engineering distraction.
Ultimately, the calculus flips when you examine the TCO and consider the value rather than the sticker price: a well-built server that comes in at €230 / $260 monthly will outperform and outlast a €80 / $90 bargain offer that requires double-purchased capacity, racks up downtime penalties, and hogs administrators’ attention.
Conclusion: Looking Beyond Headline Stickers in Search of Sustainable Value

The promises of ultra-low pricing grab attention, but the savings unravel under scrutiny. Realistic workload demands, growth traffic, and downtime have to be factored in. Modern hardware, noiseless network guarantees, MSAs with contractual uptime, and around-the-clock expertise bring value to the table that these bargain basement deals can’t meet. If you are ambitious about founding and scaling with lower funds, then securing a partner with modern gear, dedicated bandwidth, tight MSA terms, and live human support for an accessible price is the answer.
Launch Your Mumbai Dedicated Server
Secure enterprise-grade hardware, up to 40 Gbps bandwidth, and 24/7 live support—all at a predictable monthly price.
Get expert support with your services
Blog

Why Germany Became Europe’s Always-On Data Hub
One reason Germany has become the nerve center of European infrastructure is that each of its hosting layers, legal, electrical, environmental, and network, is designed to meet the needs of risk-averse organizations that cannot afford downtime or data privacy errors. GDPR-hardened compliance, 99.98 % availability, and aggressive green-power regulation mean Germany dedicated server hosting can provide the control and continuity multinational businesses demand.
We explore the three pillars that make Germany the most logical destination to deploy mission-critical workloads below, and we lean on a short retrospective of the early 2000s colocation boom to help with the context before zooming in on the unparalleled carrier-hotel ecosystem in Frankfurt.
Choose Melbicom— 240+ ready-to-go server configs — Tier III-certified DC in Frankfurt — 55+ PoP CDN across 6 continents |
|
GDPR-Hardened Compliance Meets 99.98 % Service Availability
Data hosted within Germany is, by definition, subject to the highly protective privacy framework of the country and the broader EU, generally under the General Data Protection Regulation. Since the servers are located on German territory, personal data remains under the jurisdiction of European law, removing the need for complicated cross-border transfer mechanisms, and the companies are no longer exposed to surveillance capabilities of foreign governments. Independent hosting reviews observe that “the majority of providers in Germany adhere to strict GDPR regulations and are clear on data processing,” so audits and breach notification programs are much easier to manage. (HostAdvice)
Operational resilience would hardly matter without legal strength. Luckily, German facilities are constructed to Tier III or higher standards with redundant power and cooling, and carrier paths designed to achieve 99.98 % or higher uptime. The reliability ethos can be traced to the early 2000s colocation boom in the country, when Frankfurt first became the default interconnection point in Europe, and has only grown more serious as workloads have shifted from Web 1.0 to real-time analytics and video. It is now possible to have hardware maintenance done routinely when it is convenient and with no interruption to service, and the legendary stability of the national grid provides an additional buffer against brownouts for data centers.
Melbicom reinforces these guarantees by operating its Frankfurt site on a concurrent-maintainable design, backing servers with dual power feeds, N+1 generators, and hot-standby cooling.
Outcome: Enterprises are able to make commitments to their own demanding availability objectives, without overlaying costly secondary infrastructure.
How Do Germany’s Energy-Efficiency Rules Lower OpEx for Dedicated Servers?
Compliance and uptime don’t pay the electric bill. Germany, however, has the technical rigor coupled with industry-leading sustainability economics that lead to long-term cost savings. A 2024 industry outlook found that 88 % of the power used by German colocation facilities was renewable, and 69 % of operators had secured long-duration power-purchase agreements (PPAs) to hedge pricing and carbon risk.
Even more pressure and opportunity are added by policy. The new Energy Efficiency Act requires that any data center from 2026 onward has a power-usage effectiveness (PUE) of 1.2; existing facilities will have to reach 1.3 by 2030. (Dentons) That requirement practically compels operators to use direct-to-chip liquid loops, modular cooling, and waste-heat reuse. The capital cost is recovered in a short amount of time. Reducing PUE from 1.6 to 1.2 can cut energy overhead by approximately 25 percent, amounting to millions of euros over a typical server refresh cycle.
We at Melbicom have taken up these incentives. Lower electricity consumption per rack lets us price Germany dedicated server plans with up to 200 Gbps ports competitively without reducing margin, an advantage that ultimately benefits customers’ OpEx.
How Do Frankfurt’s DE-CIX & IXPs Improve Latency and Redundancy?
GDPR is the legal moat and Frankfurt is the performance engine of Germany. The city is also home to DE-CIX Frankfurt, which broke its own record by driving 18.11 Tbps of peak traffic at the end of last year. (DE-CIX) Over 1,000 local, regional, and global networks peer there, so any tenant can access Tier 1 transit, hyperscale clouds, SaaS platforms, and eyeball ISPs instantly. (DE-CIX) In latency-sensitive services, trading platforms, multiplayer gaming, and collaborative design, deployment of a Germany dedicated server in Frankfurt can reduce latency by tens of milliseconds over trans-Atlantic links.
To best explain why planning for redundancy in Germany begins in Frankfurt, it is worth examining the present and future power pipeline across the largest hubs in Europe:
| Hub | Operational Capacity (MW) | Under Construction (MW) | Planned Expansion (MW) |
|---|---|---|---|
| London | 993 | 508 | 251 |
| Frankfurt | 745 | 542 | 383 |
| Amsterdam | 506 | 205 | 53 |
| Paris | 416 | 173 | 148 |
Sources: JLL German Data-Center Market report; German Data Center Association outlook. (JLL, germandatacenters.com)
Such figures explain why carrier hotels in Frankfurt along Kleyerstrasse are the hottest interconnection property on the continent. But capacity is not the complete redundancy picture. Germany also has a dense ring of regional Internet-exchange points (IXPs): Berlin (BCIX), Munich (DE-CIX Munich), Hamburg, Nuremberg, and the Ruhr, all of which offer sub-2 ms paths back to Frankfurt and which collectively provide a fail-open route in the event of primary metro link failure. BCIX has linked providers in the capital since 2002, underscoring how deeply distributed peering is embedded in the national infrastructure. (bcix.de)
To an enterprise architect, this topology opens simple active-active architectures: a main rack in Frankfurt, a warm-standby server in Berlin or Munich, GSLB to direct traffic, and dark-fiber or MPLS connections between them. That architecture fits perfectly with the backbone of Melbicom, which spans 21 global POPs and 55-plus CDN edge locations. We provide up to 200 Gbps per server and connect to DE-CIX and downstream IXPs, enabling customers to use native German peering with seamless failover to alternate paths.
What Future Trends Will Shape Dedicated Server Hosting in Germany?

The German dedicated server hosting strategic rationale will only grow, as the EU data-residency checks grow stricter and the AI applications need more power-intensive environments. The 500-plus MW of under-construction capacity in Frankfurt will provide more space to stack high-density racks, and energy law deadlines will drive additional jumps in cooling efficiency. The fact that Germany sits at the nexus of North-South and East-West fiber paths ensures that any future 400 GbE, holographic, or immersive reality application will have sufficient bandwidth and sub-10 ms latency to the major population centers in Europe.
When a firm considers where to run its next compliance-sensitive workload, the calculus is becoming quite simple: sovereignty, uptime, and OpEx all come together in Germany, especially when a hosting provider can combine all these variables into a single, contract-level service.
Why Germany Is a Smart Choice for Dedicated Server Hosting

Germany has a trifecta that is hard to find: GDPR-level data control, four-nines reliability, and cost-effectiveness with regulations that increase over time. DE-CIX Frankfurt—the world’s largest internet exchange by peak traffic—anchors a nationwide mesh of regional IXPs, making redundancy planning nearly plug-and-play. The heritage of the early colocation boom lives on in the design philosophies that consider downtime a taboo, as well as new sustainability requirements that make the hardware you install today affordable and socially acceptable in the future.
Deploy Dedicated Servers in Germany
Choose from 200+ ready servers with up to 200 Gbps ports, Tier III uptime, and instant setup in Frankfurt.