Month: July 2025
Blog
Integrating Windows Dedicated Servers Into Your Hybrid Fabrics
Hybrid IT is not an experiment anymore. The 2024 State of the Cloud report by Flexera revealed that 72 percent of enterprises have a hybrid combination of both public and private clouds, and 87 percent of enterprises have multiple clouds.[1] However, a significant portion of line-of-business data remains on-premises, and the integration gaps manifest themselves in Microsoft-centric stacks, where Active Directory, .NET applications, and Windows file services are expected to function seamlessly. The quickest way to fill in those gaps is with a dedicated Windows server that will act as an extension of your on-premises and cloud infrastructure.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
This guide outlines the process of selecting and configuring such a server. We compare Windows Server 2019 and 2022 for different workloads, map key integration features (Secured-core, AD join, Azure Arc, containers), outline licensing traps, and flag infrastructure attributes such as 200 Gbps uplinks that help keep latency out of the headlines. A brief shout-out to the past: Windows Server 2008, 2012, and 2016 introduced PowerShell and simple virtualization, but they lack modern hybrid tooling and are no longer in mainstream support, so we only mention them in the context of legacy.
Why Edition Choice Still Matters
| Decision Point | Server 2019 | Server 2022 |
|---|---|---|
| Support horizon | Extended support ends Jan 9 2029 | Extended support ends Oct 14 2031 |
| Built-in hybrid | Manual Arc agent; basic Azure File Sync | One-click Azure Arc onboarding, SMB over QUIC (Datacenter: Azure Edition option) |
| Security baseline | Defender, TLS 1.2 default | Secured-core: TPM 2.0, UEFI Secure Boot, VBS + HVCI, TLS 1.3 default |
| Containers | Windows Containers; host must join domain for gMSA | Smaller images, HostProcess pods, gMSA without host domain join |
| Networking | Good TCP; limited UDP offload | UDP Segmentation Offload, UDP RSC, SMB encryption with no RDMA penalty—crucial for real-time traffic |
| Ideal fit | Steady legacy workloads, branch DCs, light virtualization | High-density VM hosts, Kubernetes nodes, compliance-sensitive apps |
Takeaway: When the server is expected to last beyond three years, or would require hardened firmware defenses, or must be migrated out of Azure, 2022 is the practical default. 2019 can still be used in fixed-function applications that cannot yet be recertified.
Which Windows Server Features Make Hybrid Integration Frictionless?
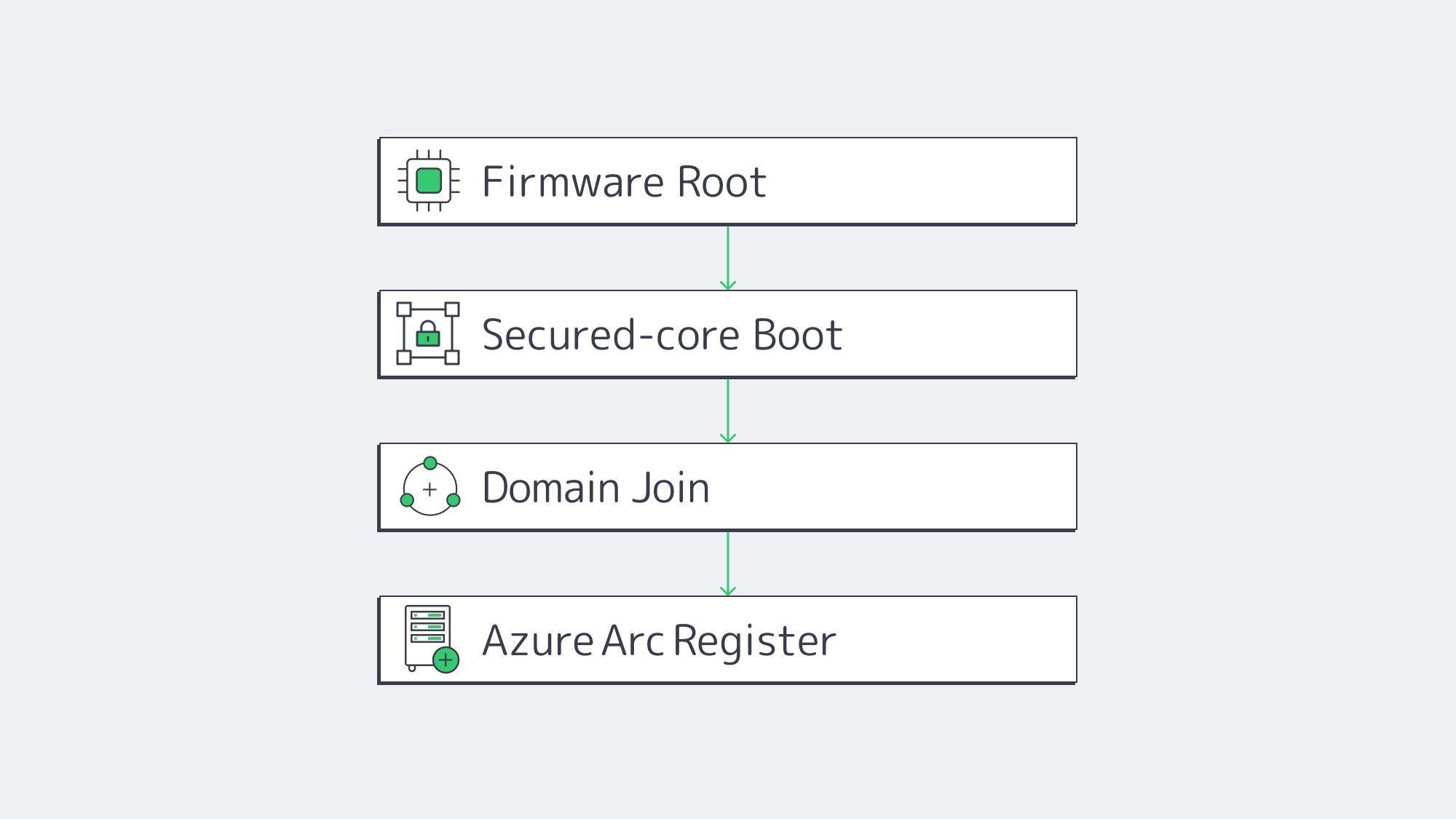
Harden the Foundation with Secured-core
Firmware attacks are no longer hypothetical; over 80 percent of enterprises have experienced at least one firmware attack in the last two years.[2] Secured-core in Windows Server 2022 locks that door by chaining TPM 2.0, DRTM, and VBS/HVCI at boot and beyond. Intel Xeon systems have the hypervisor isolate kernel secrets, and hardware offload ensures that performance overhead remains in the single-digit percentages in Microsoft testing.
Windows Admin Center is point-and-click configuration, with a single dashboard toggling on Secure Boot, DMA protection, and memory integrity, and auditing compliance. The good news, as an integration architect, is that you can trust the node that you intend to domain-join or add to a container cluster.
Join (and Extend) Active Directory
Domain join remains a two-command affair (Add-Computer -DomainName). Both 2019 and 2022 honor the most up-to-date AD functional levels and replicate through DFS-R. The new thing is the way 2022 treats containers: Group-Managed Service Accounts can now be used even when the host is not domain-joined, eliminating security holes in perimeter zones. That by itself can cut hours out of Kubernetes day-two ops.
In case you operate a hybrid identity, insert Azure AD Connect into the same AD forest—your dedicated server will expose cloud tokens without any additional agents.
Treat On-prem as Cloud with Azure Arc
Azure Arc converts a physical server into a first-class Azure resource in terms of policy, monitoring, and patch orchestration. Windows Server 2022 includes an Arc registration wizard and ARM template snippets, allowing onboarding to be completed in 60 seconds. After being projected into Azure, you may apply Defender for Cloud, run Automanage baselines, or stretch a subnet with Azure Extended Network.
Windows Server 2019 is still able to join Arc, but it does not have the built-in hooks; scripts provide a workaround, but they introduce friction. In the case that centralized cloud governance is on the roadmap, 2022 will reduce the integration glue code.
Run Cloud-Native Windows Workloads
Containers are mainstream, with 93 percent of surveyed organizations using or intending to use them in production, and 96 percent already using or considering Kubernetes.[3] Windows Server 2022 closes the gap with Linux nodes:
- Image sizes are reduced by as much as 40 percent, and patch layers are downloaded progressively.
- HostProcess containers enable cluster daemons to be executed as pods, eliminating the need for bastion scripts.
- The support of GPU pass-through and MSDTC expands the catalogue of apps.
If you have microservices or GitOps in your integration strategy, the new OS does not allow Windows nodes to be second-class citizens.
Licensing in One Paragraph
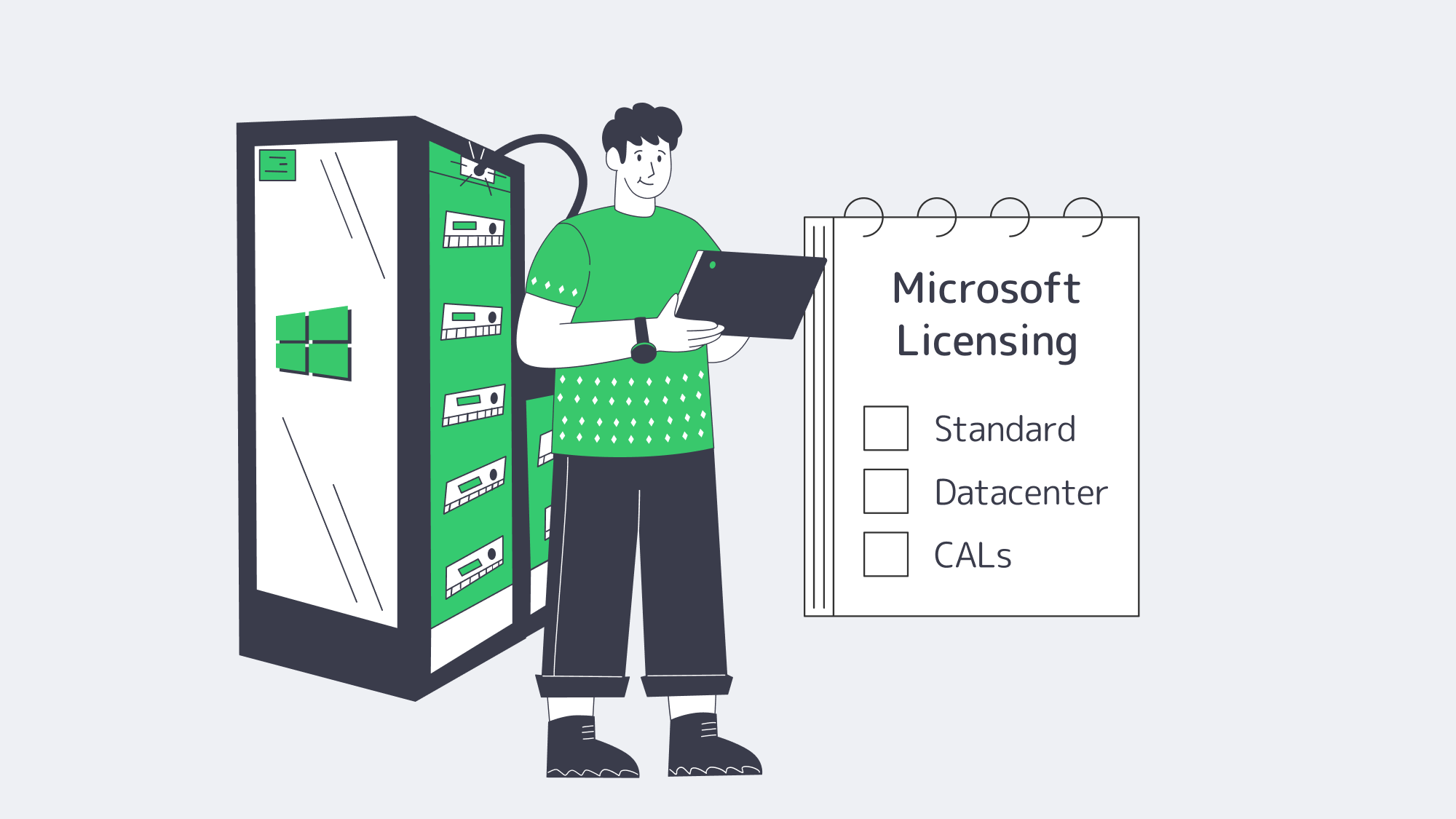
Microsoft’s per-core model remains unchanged: license every physical core (minimum of 16 cores). Standard Edition provides two Windows guest VMs per 16 cores; Datacenter provides unlimited VMs and containers. Add additional Standard licenses only when you have three or four VMs; otherwise, Datacenter is more cost-effective in the long run. Client Access Licenses (CALs) still apply to AD, file, or RDS access. Bring-your-own licenses (BYOL) can be used, but are limited by Microsoft mobility regulations; please note that portability is not guaranteed.
Infrastructure: Where Integration Bottlenecks Appear
A Windows server will just not fit in unless the fabric around it is up to date.
- Bandwidth & Latency: At Melbicom, we install links of up to 200 Gbps in Tier IV Amsterdam and Tier III locations worldwide. Cross-site DFS replication or SMB over QUIC will then feel local.
- Global Reach: A 14+ Tbps backbone and CDN in 55+ PoPs is fed by 21 data centers in Europe, the U.S., and major edge metros, meaning AD logons or API calls are single-digit-millisecond away to most users.
- Hardware Baseline: All configurations run on Intel Xeon platforms with TPM 2.0 and UEFI firmware, Secured-core ready, out of the crate. More than 1,300 servers can be deployed in two hours, and KVM/IPMI is standard to handle low-level management.
- 24/7 Support: When the integration stalls at 3 a.m., Melbicom employees can quickly exchange components or redirect traffic, without requiring a premium ticket.
How to Integrate a Windows Dedicated Server into a Hybrid System

The blueprint of integration now appears as follows:
- Choose the edition: Use Server 2022 unless you have a legacy workload or certification that flatlines on 2019.
- Select the license: Standard when you require 2 VMs or fewer; Datacenter when the server has a virtualization farm or Windows Kubernetes nodes.
- Order Intel hardware that has TPM 2.0, Secure Boot, and a NIC that supports USO/RSC.
- Turn on Secured-core in Windows Admin Center; check in msinfo32.
- Domain-join, in case of container hosts, use gMSA without host join.
- Register with Azure Arc to federate policy and telemetry.
- Install container runtime (Docker or containerd), apply HostProcess DaemonSets if using Kubernetes.
- Confirm network bandwidth with ntttcp – should be line rate on 10/40/200 GbE ports due to USO.
Then follow that checklist and the new Windows dedicated server falls into the background a secure policy-driven node that speaks AD, Azure and Kubernetes natively.
What’s Next for Windows Dedicated Servers in Hybrid IT?

Practically, a Server 2022 implementation bought now gets at least six years of patch runway and aligns with current Azure management tooling. Hybrid demand continues to rise; the 2024 breach report by IBM estimates the average cost of an incident at 4.55 million dollars, a 10 percent YoY increase[4]—breaches in integration layers are costly. The most secure bet is to toughen and standardize today instead of waiting until the next major Windows Server release.
Integration as an Engineering Discipline
Windows dedicated servers are no longer static file boxes; they are nodes in a cross-cloud control plane that can be programmed. When you select Windows Server 2022 on Intel, you get Secured-core as a default, zero click Azure Arc enrollment, and container parity with Linux clusters. Pair that OS with a data center capable of 200 Gbps throughput per server and able to pass Tier IV audits, and your hybrid estate will no longer care where the workload resides. Integration is not a weekly fire drill but a property of the platform.
Deploy Windows Servers Fast
Spin up Secured-core Windows dedicated servers with 200 Gbps uplinks and integrate them into your hybrid fabric in minutes.
Get expert support with your services
Blog

Finding an Unmetered Dedicated Server Plan in Amsterdam
A decade ago, it was necessary to count every gigabyte and keep your fingers crossed that the 95th-percentile spike on your invoice wasn´t horrendous in order to plan your bandwidth. For video platforms, gaming labs, and other traffic-heavy businesses, this was a genuine gamble and required calculus to keep within budget limitations. These days, thankfully, the math is no longer a caveat. Fixed monthly prices and hundreds of terabytes are on tap thanks to the AMS-IX exchange based in Amsterdam. The high-capacity network serves as the main crossroad for most of Europe and can hit a 14 Tbps peak.[1]
Choose Melbicom— 400+ ready-to-go servers configs — Tier IV & III DCs in Amsterdam — 55+ PoP CDN across 6 continents |
|
Definition Matters: Unmetered ≠ Infinite
Jargon can confuse matters; it is important to clarify that unmetered ports refer to the data and not the speed. Essentially, the data isn’t counted, but that doesn´t mean that the speed is unlimited. If saturated 24 x 7, a fully dedicated 1 Gbps line should be capable of moving 324 TB each month. That ceiling climbs to roughly 3.2 PB with a 10Gbps line. So you need to consider how much headroom you need, which could be considerable if you are working with huge AI datasets or operating a multi-regional 4K streaming. If you are using shared uplinks, it is wise to read through the service agreements, one line at a time, or you will find out the hard way how “fair use” throttle affects you:
- Guaranteed Port: Our Netherlands-based unmetered server configurations indicate that the bandwidth is solely yours, with language such as “1:1 bandwidth, no ratios.”
- Zero Bandwidth Cap: The phrase “reasonable use” should raise alarm bells. It often means the host can and will slow you at will. If limitations are in place, look for hard numbers to understand potential caps.
- Transparent overage policy: The legitimacy of an unmetered plan boils down to overage policies. Ideally, there should be an explicit statement, such as “there isn’t one.”
How Does Amsterdam’s AMS-IX Multipath Deliver Low Latency?
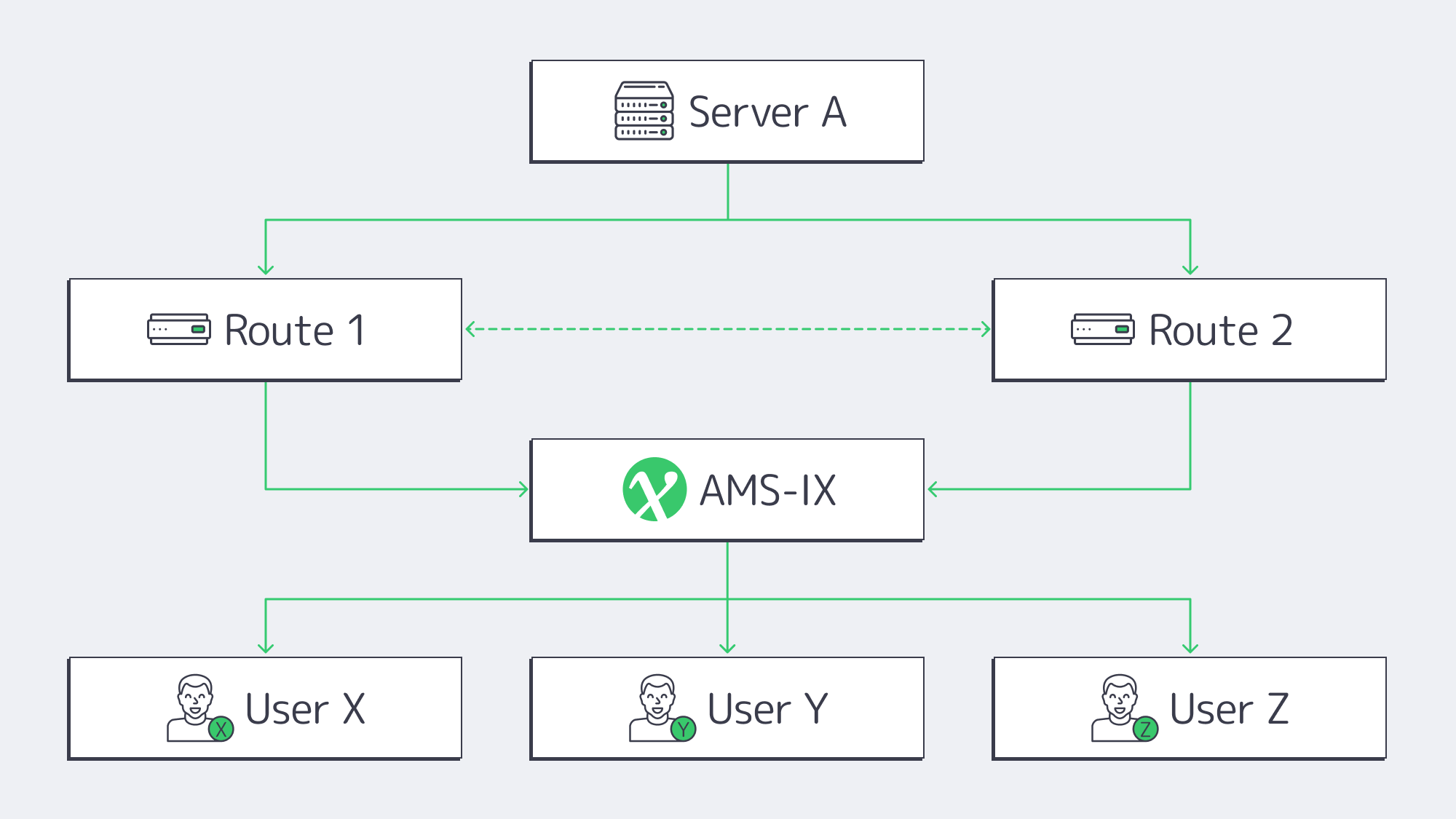
The infrastructure provided by Amsterdam’s AMS-IX connection unites over 880 networks operating at the 14 Tbps mark. Theoretically, that sort of power can serve almost a million concurrent 4K Netflix users at once. Traffic is distributed via multiple carrier-neutral facilities, automatically rerouting if there is any delay at a single site. Hiccups. Fail-over is afforded without ticket requests or manual BGP surgery when providers peer on at least two physical AMS-IX points at a time.
We at Melbicom, rack into 3 IXPs and operate via 7 Tier-1 transit providers, so flow is easily automatically shifted should a cable cut on one path appear for whatever reason. The shift occurs in a single-digit-millisecond ping across Western Europe with respectable latency round-trip at all times. New York and back pings in under ~75 ms, ideal for those providing live feeds that must meet low glass-to-glass latency demands.
What Can You Run on 1–10 Gbps Unmetered Bandwidth Ports?
| Port speed | Concurrent 4K streams* | Max data/month** |
|---|---|---|
| 1 Gbps | ≈ 60 | 324 TB |
| 5 Gbps | ≈ 300 | 1.6 PB |
| 10 Gbps | ≈ 600 | 3.2 PB |
*In accordance with Netflix’s 15 Mbps UHD guideline.[2] **Theoretical, 100 % utilization.
Streaming & CDN nodes: According to Cisco’s forecasts, video streaming is expected to make up more than 80 % of global IP traffic in the years to come.[3] Currently, the edge boxes feeding Europe max out nightly at 10 Gbps, and live streaming of a single 4K live event at 25 Mbps hits a gigabit with just 40 viewers.
AI training bursts: GPT-3 by OpenAI used ≈ 45 TB of text before preprocessing.[4] To put things into perspective, copying such a dataset takes around five days across nodes on a 1 Gbps line or half a day on a 10 Gbps line. Without GPUs bolstered by generous unmetered pipes, parameter servers can easily spike during distributed training.
How to Verify a Genuine Unmetered Dedicated Server in the Netherlands
- Dedicated N Gbps + port in writing.
- SLA with no traffic ceiling and no “fair use” policy unless clearly defined.
- Dual AMS-IX peerings (minimum) and diverse transit routes.
- Tier III or IV facility to ensure sufficient power and cooling redundancy.
- Real-world test file demonstrates that it hits 90 % of the stated speed.
- Complimentary 24/7 support (extra ticket fees are common with budget plans).
If the offer doesn´t meet at least four out of the six above-mentioned criteria, then steer clear because you are looking at throttled gigabits.
How to Balance Price and Performance for Unmetered Plans
Search pages are littered with “cheap dedicated server Amsterdam” adverts, but headline prices and true throughput can be widely disparate. You have to consider the key cost lenses to know if you are getting a good deal. When you hone in on the cost per delivered gigabit, a €99/month “unmetered” plan that delivers 300 Mbps after contention works out pricier than a plan for €179 that sustains 1 Gbps. Consider the following:
- Effective €/Gbps – Don´t let port sizes fool you, sustainable speed tests are more significant.
- Upgradability – How easy is it to bump from 1 to 5 Gbps next quarter? Do you need to migrate racks? Not with us!
- Bundles – The total cost of ownership may include hidden add-ons, Melbicom bundles in IPMI, and BGP announcements, keeping costs transparent.
The sweet spot for the majority of bandwidth-heavy startups is either an unmetered 1 Gbps or 5 Gbps node. Either 10 Gbps or 40 Gbps is required for traffic-heavy endeavors such as gaming and streaming platforms that are expecting petabytes. With U.S metros, costs can be high, but the carrier density on offer in Amsterdam keeps tiers cheaper.
What’s the Upgrade Path from 10G to 100G–400G?
The rise of AI and ever-increasing popularity of video has meant that AMS-IX has seen an eleven-fold jump in 400 Gbps member ports during last year.[5] Trends, forecasts and back end capacity dictate all points towards 25 G and 40 G dedicated uplinks becoming the new standard. At Melbicom, we are prepped and ahead of the curve with 100 Gbps unmetered configurations and hints at 200 G on request.
With our roadmap developers can rest assured that they won’t face detrimental bottlenecks with future upgrade cycles because it is waiting and ready to go regardless of individual traffic curves. Whether your climb is linear with a steady subscriber base or lumpy surging at the hands of a viral game patch or a large sporting event, a provider that scales beyond 10 Gbps is insurance for a steady future.
What Else Should You Check—Latency, Security, Sustainability?
Don’t overlook latency: High bandwidth means nothing if there is significant packet loss; low latency is vital to be sure to test both.
Security is bandwidth’s twin: A 200 Gbps DDoS can arrive as fast as a legitimate traffic surge. Ask if scrubbing is on-net or through a third-party tunnel.
Greener operations have better uptime: Megawatt draw is monitored by Dutch regulators and power can be capped, causing downtime. Tier III/IV operators that recycle heat or buy renewables are favorable, which is why Melbicom works with such sites in Amsterdam.
How to Choose an Unmetered Dedicated Server in Amsterdam

Amsterdam’s AMS-IX is the densest fiber intersection on the continent; the infrastructure’s multipath nature ensures that a single cut cable won’t tank your operations. For a dedicated server that is truly unmetered, you have to go through the SLA behind it with a fine-tooth comb. Remember proof of 1:1 bandwidth is non-negotiable, look for zero-cap wording, and diagrammable physical redundancy. Additionally, you need verifiable, sustained live speed tests; only then can you sign a contract with confidence that your server is genuinely “unmetered.”
Ready for unmetered bandwidth?
Spin up a dedicated Amsterdam server in minutes with true 1:1 ports and zero caps.
Get expert support with your services
Blog
Building a Predictive Monitoring Stack for Servers
Downtime is brutally expensive. Enterprise Management Associates pegs the average minute of an unplanned IT outage at US $14,056, climbing to US $23,750 for very large firms.[1] Stopping those losses begins with smarter, faster observability—far beyond yesterday’s “ping-only” scripts. This condensed blueprint walks step-by-step through a metrics + logs + AI + alerts pipeline that can spot trouble early and even heal itself—exactly the level of resilience we at Melbicom expect from every bare-metal deployment.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
From Pings to Predictive Insight
Early monitoring checked little more than ICMP reachability; if ping failed, a pager screamed. That told teams something was down but said nothing about why or when it would break again. Manual dashboards added color but still left ops reacting after users noticed. Today, high-resolution telemetry, AI modeling, and automated runbooks combine to warn engineers—or kick off a fix—before customers feel a blip.
The Four-Pillar Blueprint
| Step | Objective | Key Tools & Patterns |
|---|---|---|
| Metrics collection | Stream system and application KPIs at 5-60 s granularity | Prometheus + node & app exporters, OpenTelemetry agents |
| Log aggregation | Centralize every event for search & correlation | Fluent Bit/Vector → Elasticsearch/Loki |
| AI anomaly detection | Learn baselines, flag outliers, predict saturation | AIOps engines, Grafana ML, New Relic or custom Python ML jobs |
| Multi-channel alerts & self-healing | Route rich context to humans and scripts | PagerDuty/Slack/SMS + auto-remediation playbooks |
Metrics Collection—Seeing the Pulse
High-resolution metrics are the vitals of a dedicated server: CPU load, 95th-percentile disk I/O, kernel context switches, TLS handshake latency, custom business counters. Exporters pull these numbers into a time-series store—most shops adopt the pull model (Prometheus scraping) for its simplicity and discoverability. Labels such as role=db-primary or dc=ams make multi-site queries easy.
Volume is real: a single node can emit hundreds of series; dozens of nodes create billions of data points per day. Tool sprawl reflects that reality—two-thirds of teams juggle at least four observability products, according to Grafana Labs’ latest survey.[2] Consolidating feeds through OpenTelemetry or alloy collectors reduces overhead and feeds the same stream to both dashboards and AI detectors.
Log Aggregation—Reading the Narrative
Metrics flag symptoms; logs give quotes. A centralized pipeline (Vector → Loki or Logstash → OpenSearch) fans in syslog, app, security, and audit streams. Schema-on-ingest parsing turns raw text into structured JSON fields, enabling faceted queries such as “level:error AND user=backend-svc-03 in last 5 m”.
Unified search slashes Mean Time to Detect; when an alert fires, a single query often reveals the root cause in seconds. Correlation rules can also raise proactive flags: repeated OOMKilled events on a container, or a surge of 502s that precedes CPU spikes on the front-end tier.
Because Melbicom provides servers with up to 200 Gbps of burst headroom per machine in global Tier III/IV sites, IT operations staff can ship logs continuously without throttling production traffic.
AI-Driven Anomaly Detection—From Rules to Learning

Static thresholds (“alert if CPU > 90%”) drown teams in noise or miss slow burns. Machine-learning models watch every series, learn its daily and weekly cadence, and raise alarms only when a pattern really breaks. EMA’s outage study shows AIOps users trimming incident duration so sharply that some issues resolve in seconds.[3]
- Seasonality-aware CPU: nightly backup spikes are normal; a lunchtime jump is not.
- Early disk failure: subtle uptick in ata_errors often precedes SMART alarms by hours.
- Composite service health: hairline growth in p95 latency + rising GC pauses + error-log rarity equals brewing memory leak.
Predictive models go further, projecting “disk full in 36 h” or “TLS cert expires in 10 days”—time to remediate before SLA pain.
Multi-Channel Alerts—Delivering Context, Not White Noise
Detection is moot if nobody hears it. Modern alert managers gate severity bands:
- Info → Slack channel, threads auto-closed by bot when metric normalizes.
- Warn → Slack + email with run-book links.
- Critical → PagerDuty SMS, voice call, and fallback escalation after 10 m.
Alerts carry metadata: last 30-minute sparkline, top correlated log excerpts, Grafana explore link. This context trims guesswork and stress when bleary-eyed engineers get woken at 3 in the morning.
Companies with full-stack observability see 79 % less downtime and 48 % lower outage cost per hour than peers without it.[5] The right payload—and less alert fatigue—explains much of that edge.
Self-Healing Workflows—When the Stack Fixes Itself
Once alerts trust ML accuracy, automation becomes safe. Typical playbooks:
- Service restart when a known memory-leak signature appears.
- IPMI hard reboot if node stops responding yet BMC is alive.
- Traffic drain and container redeploy on Canary errors > threshold.
- Extra node spin-up when request queue exceeds modelled capacity.
Every action logs to the incident timeline, so humans can audit later. Over time, the books grow—from “restart Nginx” to “migrate master role to standby if replication lag stable”. The goal: humans handle novel problems; scripts squash the routine.
Distributed Insight: Why Location Still Matters
Metric latency to the collector can mask user pain from the edge. Dedicated nodes often sit in multiple regions for compliance or low-latency delivery. Best practice is a federated Prometheus mesh: one scraper per site, federating roll-ups to a global view. If trans-Atlantic WAN links fail, local alerts still trigger.
External synthetic probes—HTTP checks from Frankfurt, São Paulo, and Tokyo—verify that sites are reachable where it counts: outside the data-center firewall. Combined with Melbicom’s 21 locations and CDN pops in 55+ cities, ops teams can blend real user measurements with synthetic data to decide where to expand next.
Incident Economics—Why the Effort Pays
Tooling is not cheap, but neither is downtime. BigPanda’s latest benchmark shows every minute of outage still burns over $14k, and ML-backed AIOps can cut both frequency and duration by roughly a third.[4] Grafana adds that 79 % of teams that centralized observability saved time or money.[5] In plain terms: observability investment funds itself the first time a production freeze is shaved from an hour to five minutes.
Putting It All Together

Build the stack incrementally:
- Instrument everything—system exporters first, app metrics next.
- Ship every log to a searchable index.
- Enable anomaly ML on the full data lake, tune until noise drops.
- Wire multi-channel alerts with rich context.
- Automate the obvious fixes, audit, and expand the playbook.
- Test failovers—simulate host death, packet loss, disk fill—until you trust the automation more than you trust coffee.
Each phase compounds reliability; skip one and blind spots emerge. When executed end-to-end, ops teams shift from firefighting to forecasting.
Conclusion — From Reactive to Resilient

A modern monitoring stack turns servers into storytellers: metrics give tempo, logs provide narrative, AI interprets plot twists, and alerts assign actors their cues. Tie in automated runbooks and the infrastructure heals before the audience notices. Companies that follow this blueprint bank real money—downtime slashed, reputations intact, engineers sleeping through the night.
Launch Your Dedicated Server
Deploy on Tier III/IV hardware with up to 200 Gbps per server and 24×7 support. Start today and pair your new machines with the monitoring stack above for unbeatable uptime.
Get expert support with your services
Blog

Database Hosting Services for Low Latency, High Uptime & Lower TCO
Modern database hosting services span far more than the racks that once anchored corporate IT. Today, decision-makers juggle dedicated servers, multi-cloud Database-as-a-Service (DBaaS) platforms, and containerized deployments—each promising performance, scale, and savings. The goal of this guide is simple: to show how to pick the right landing zone for your data by weighing five hard metrics—latency, uptime guarantees, compliance, elastic scaling, and total cost of ownership (TCO). Secondary considerations (feature sets, corporate politics, tooling preferences) matter, but they rarely outrank these fundamentals.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Which Database Hosting Services Are Available—and How Do They Differ?
Before public clouds, running a database meant buying hardware, carving out space in an on-prem data center, and hiring specialists to keep disks spinning. That model still lives in regulated niches, yet most organizations now treat on-prem data centers as legacy—valuable history, not future direction. The pressures shaping current choices are sovereignty rules that restrict cross-border data flow, hybrid resiliency targets that demand workloads survive regional failures, and a CFO-driven insistence on transparent, forecastable economics.
Three modern options dominate
| Model | Core Idea | Prime Strength |
|---|---|---|
| Dedicated server | Single-tenant physical host rented or owned | Predictable performance & cost |
| Cloud DBaaS | Provider-managed database instance | Rapid deployment & elastic scale |
| Container platform | Database in Kubernetes or similar | Portability across any infrastructure |
Each model can power QSL database hosting, web hosting MySQL database clusters, or high-volume postgres database hosting at scale; the difference lies in how they balance the five decision metrics that follow.
How Does Latency Affect Database Hosting—and How Do You Reduce It?
Every extra millisecond between application and datastore chips away at user experience. Dedicated servers let teams drop hardware into specific metros—Amsterdam for pan-EU workloads, Los Angeles for West-Coast startup—bringing median round-trip times under 5 ms within region and avoiding multi-tenant jitter.
DBaaS instances are just as quick when compute lives in the same cloud zone, but hybrid topologies suffer: shipping queries from an on-prem app stack to a cloud DB 2 000 km away adds 40-70 ms and invites egress fees. Container clusters mirror their substrate; run Kubernetes on bare metal in a regional facility and you match dedicated latencies, run it on VMs across zones and you inherit cloud hop counts.
For global audiences, no single host sits near everyone. The low-latency playbook is therefore:
- Pin read-heavy replicas close to users. Cloud DBaaS makes this almost one-click; dedicated nodes can achieve the same with streaming replication.
- Keep write primaries near business logic. It minimizes chatter on chatty OLTP workloads.
- Avoid forced detours. Private links or anycast routing outperform public-internet hops.
Melbicom pairs twenty Tier III–IV facilities with 200 Gbps server uplinks, so we can land data exactly where users live—without virtualization overhead or surprise throttling.
Is Your Database Hosting Highly Available—and What Should You Verify?
Dedicated servers inherit their facility rating: Tier IV promises <26 minutes of annual infrastructure downtime, Tier III about 1.6 hours. Hardware still fails, so true availability hinges on software redundancy—multi-node clusters or synchronous replicas in a second rack. Melbicom mitigates risk by swapping failed components inside 4 hours and maintaining redundant upstream carriers; fail-over logic, however, remains under your control.
Cloud DBaaS automates much of that logic. Enable multi-zone mode and provider target 99.95 %-plus availability; failovers finish in <60 s. The price is a small performance tax and dependence on platform tooling. Region-wide outages are rare yet headline-making; multi-region replication cuts risk but doubles cost.
Container databases ride Kubernetes self-healing. StatefulSets restart crashed pods, Operators promote replicas, and a cluster spread across two sites can deliver four-nines reliability—provided storage back ends replicate fast enough. You’re the SRE on call, so monitoring and rehearsed run-books are mandatory.
Rule of thumb: platform automation reduces human-error downtime, but the farther uptime is outsourced, the less tuning freedom you retain.
Compliance & Data Sovereignty: Control vs Convenience

- Dedicated servers grant the clearest answers. Choose a country, deploy, and keep encryption keys offline; auditors see the whole chain. European firms favor single-tenant hosts in EU territory to sidestep cross-border risk, while U.S. healthcare providers leverage HIPAA-aligned cages.
- DBaaS vendors brandish long lists of ISO, SOC 2, PCI, and HIPAA attestations, yet true sovereignty is fuzzier. Metadata or backups may leave region, and foreign-owned providers remain subject to their home-state disclosure laws. Customer-managed keys, private endpoints, and “sovereign-cloud” variants ease some worries but add cost and sometimes feature gaps.
- Containers let teams codify policy. Restrict nodes by label, enforce network policies, and pin PostgreSQL clusters to EU nodes while U.S. analytics pods run elsewhere. The trade-off is operational complexity: securing the control plane, supply-chain-scanning images, and documenting enforcement for auditors.
When sovereignty trumps all, single-tenant hardware in an in-country facility still rules. That is why we at Melbicom maintain European data centers and make node-level placement an API call.
How Do Database Hosting Services Scale—Vertical, Horizontal, or Serverless?
Cloud DBaaS sets the benchmark: resize a MySQL instance from 4 vCPUs to 16 vCPUs in minutes, add replicas with one API call, or let a serverless tier spike 20× during a flash sale. It’s difficult to match that zero-touch elasticity elsewhere.
Dedicated servers scale vertically by swapping CPUs or moving the database to a bigger box and horizontally by adding shard or replica nodes. Melbicom keeps > 1,000 configurations on standby, so extra capacity appears within hours, not weeks, but day-scale elasticity cannot copy second-scale serverless bursts. For steady workloads—think ERP, catalog, or gaming back-ends—predictable monthly capacity often beats pay-per-peak surprises.
Container platforms mimic cloud elasticity inside your footprint. Kubernetes autoscalers launch new database pods or add worker nodes when CPU thresholds trip, provided spare hardware exists or an underlying IaaS can supply it. Distributed SQL engines (CockroachDB, Yugabyte) scale almost linearly; classic Postgres will still bottleneck on a single writer. Good operators abstract most of the ceremony, but hot data redistribution still takes time and IO.
In practice, teams often blend models: burst-prone workloads float on DBaaS, while core ledgers settle on right-sized dedicated clusters refreshed quarterly.
How Much Do Database Hosting Services Cost—and What Drives TCO?
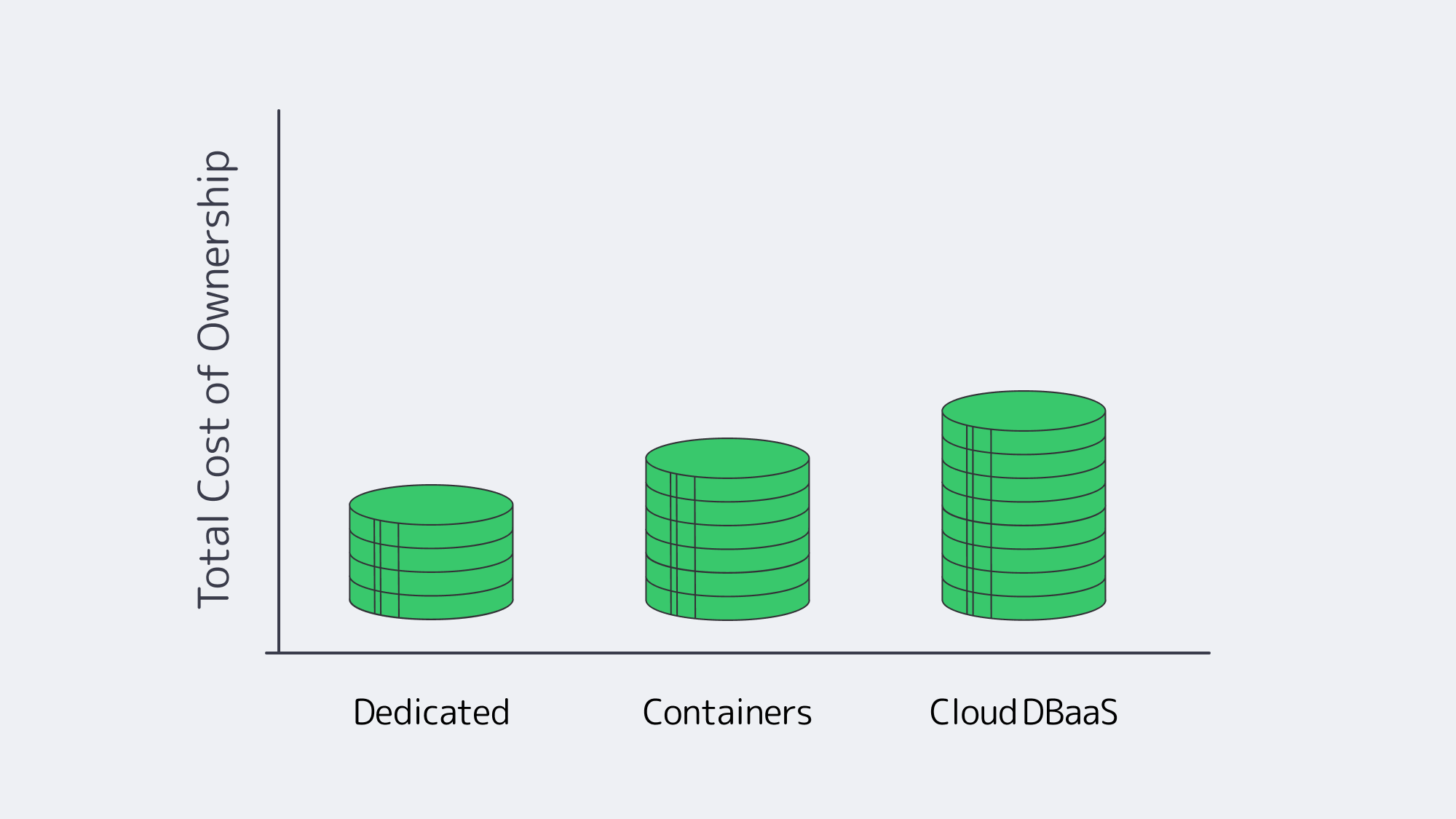
Price tags without context are dangerous. Evaluate three buckets:
- Direct infrastructure spend. Cloud on-demand rates can be 2-4× the monthly rental of an equivalently specced dedicated host when utilized 24 / 7. Transferring 50 TB out of a cloud region can cost more than leasing a 10 Gbps unmetered port for a month.
- Labor and tooling. DBaaS bundles patching, backups, and monitoring. Dedicated or container fleets need DBAs and SREs; automation amortizes the cost, but talent retention counts.
- Financial risk. Over-provision on-prem and you eat idle capital; under-provision in cloud and burst‐pricing or downtime hits revenue. Strategic lock-in adds long-term exposure: repatriating 100 TB from a cloud can incur five-figure egress fees.
A common pattern: startups prototype on DBaaS, stabilize growth, then migrate stable workloads to dedicated hardware to cap expenses. Dropbox famously saved $75 million over two years by exiting cloud storage; not every firm hits that scale, yet many mid-sized SaaS providers report 30–50 % savings after moving heavy databases to single-tenant hosts. Transparent economics attract finance teams; we see customers use Melbicom servers to fix monthly costs for core data while keeping elastic analytics in cloud Spot fleets.
Which Database Hosting Service Fits Your Use Case? Decision Matrix
| Criterion | Dedicated server | Cloud DBaaS | Container platform |
|---|---|---|---|
| Latency control | High (choose metro, no hypervisor) | High in-zone, variable hybrid | Mirrors substrate; tunable |
| SLA responsibility | Shared (infra provider + your cluster) | Provider-managed failover | You + Operator logic |
| Compliance sovereignty | Full control | Certifications but shared jurisdiction | High if self-hosted |
| Elastic scaling speed | Hours (new node) | Seconds–minutes (resize, serverless) | Minutes; depends on spare capacity |
| Long-term TCO (steady load) | Lowest | Highest unless reserved | Mid; gains from consolidation |
How to Choose a Database Hosting Service: A Balanced Framework
Every serious database platform evaluation should begin with hard numbers: latency targets per user region, downtime tolerance in minutes per month, regulatory clauses on data residency, scale elasticity curves, and projected three-year spend. Map those against the strengths above.
- If deterministic performance, sovereign control, and flat costs define success—bank transactions, industrial telemetry—dedicated servers excel.
- If release velocity, unpredictable bursts, or limited ops staff dominate, cloud DBaaS delivers fastest returns—think consumer apps, proof-of-concepts.
- If portability, GitOps pipelines, and multi-site resilience are priorities, container platforms offer a compelling middle road—particularly when married to dedicated nodes for predictability.
Hybrid architectures win when they let each workload live where it thrives. That philosophy underpins why enterprises increasingly mix clouds and single-tenant hardware rather than betting on one model.
Conclusion

The Path to Confident Database Hosting
Choosing a home for critical data is no longer about picking “cloud vs. on-prem.” It is about aligning latency, availability, compliance, elasticity, and cost with the realities of your application and regulatory environment—then revisiting that alignment as those realities shift. Dedicated servers, cloud DBaaS, and containerized platforms each bring distinct advantages; the smartest strategies orchestrate them together. By quantifying the five core metrics and testing workloads in realistic scenarios, teams reach decisions that hold up under growth, audits, and budget scrutiny.
Launch Your Database on Dedicated Servers
Provision a high-performance, low-latency dedicated server in hours and keep full control of your data.
Get expert support with your services
Blog
Why SMBs Need a Dedicated Backup Server Now
Ransomware attacks now seem to be focusing on smaller businesses. Reports from within the industry show that over a third of infections now hit companies with fewer than 100 employees, and nearly 75 % face permanent closure following prolonged outage. According to Verizon, human error is also still a big culprit when it comes to many breaches, so a solid backup plan is evidently needed. Unfortunately, many small and mid-size businesses (SMBs) rely on consumer-grade cloud sync as a backup or worse still, rest their bets on a USB drive. When faced with a worst-case scenario, these recovery plans will leave them in a very unfavorable position when regulators, courts, and customers come knocking.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
A much better plan is to reap the benefits of a dedicated on-prem backup server to capture and store data that can be re-hydrated if there is a mishap. Having a single, hardened box specifically to handle data backup gives SMBs the following:
- Self-controlled protection without third-party retention policies, API limits, or hidden egress charges.
- Predictable costs with a fixed hardware or rental fee, with the ability to scale storage on your terms.
- Low-latency recovery flow is restored at LAN or dedicated-link speed rather than over a public pipe that may be congested.
Additionally, backup software ecosystems have evolved to provide an array of modern tools that were previously reserved for much larger enterprises. This means SMBs with even the leanest IT teams can pass compliance audits. Combining tools such as incremental-forever data capture, built-in immutability, and policy-driven cloud synchronization is a surefire protection plan to reduce ransomware risk, avoid accidental deletion crises, and satisfy security regulators.
Technology Evolution: Why USB & Tape Backups No Longer Suffice
Before we go any further, it is important to take a moment to highlight how legacy technologies that were once useful are no longer adequately capable of defending against modern risks:
| Medium | Weaknesses | Consequences |
|---|---|---|
| USB/external drives | Manual plug-in, no centralized monitoring, easy to mistakenly overwrite | Backup gaps, silent corruption |
| Tape rotation | Slow restores, operator error, single-threaded jobs | Extensive RTOs, unreliable for frequent restores |
Theft and fire are also a concern with either medium and, more importantly, both are defenseless against ransomware because it encrypts writable drives. Sadly, although these legacy technologies were once a first-line defense, with modern threats, they serve as little more than a reminder of how far we have come.
Rapid Deployment, Modest Budgets: Hardware is the Answer
Once upon a time setting up a dedicated backup server was a lengthy process, but with over 1,300 ready-to-go configurations on the floor at Melbicom, we can offer rapid deployment. The majority of our configurations can be racked, imaged, and handed over with a two-hour turnaround. We offer 21 global Tier III/IV data centers to provide a local presence. Alternatively, you can park the server on-site and tether it back to Melbicom for off-site replication. With either option, per-server pipes scale to 200 Gbps, so regardless of how large your datasets are, nightly backup windows remain controllable.
The hands-off operation is a bonus for those with limited IT teams. Hardware health is monitored on our end, and SMART alerts automatically trigger disk reboots. With Melbicom, you can control your infrastructure via IPMI without driving to the rack. The elimination of maintenance labor and the inevitable depreciation offsets the rental premiums in the long run of buying a chassis outright.
How Do Incremental-Forever Backups Save Disk and Bandwidth?
Traditionally, the typical practice was to perform a full backup every weekend, with increments in between, but that can hog bandwidth and disk space. With solutions such as Veeam Backup & Replication, MSP-focused offerings like Acronis Cyber Protect, or the open-source tool Restic, incremental-forever backups have become the new standard:
- Initial synthetic full backup.
- Block-level deltas thereafter.
- Background deduplication to identify duplicate chunks helping to shrink stored volume by 60–95 %.
Independent lab tests show that even a 10 TB file share can be kept well within a gigabit maintenance window, as we see around 200 GB of new blocks nightly. This can be really beneficial to SMBs with growing data needs, with no need to double down on storage needs.
How to Sync Off-Site Without High Cloud Overheads (the 3-2-1 Rule)
Depending on a single copy is risky, it is better to follow the 3-2-1 rule. This means to have three copies, in two distinct media, and keep one stored off-site. A dedicated backup server delivers rapid copies for instant restoration, two local copies: production and local backup, and a third copy stored following policy:
- First, data is encrypted and then synced to object storage. Melbicom’s high-performance S3 cloud storage is recommended in this instance.
- Uploads are scheduled during off-peak hours making sure there is throttle to spare and plenty of daytime bandwidth.
- Where upstream links are small, the first TB is seeded via a shipped disk.
Operating in this manner keeps cloud storage bills down, as the deltas travel compressed without any duplications. The copy stored in the off-site vault eliminates expensive multi-site clustering or DR orchestration and guarantees the data is protected against unexpected events such as flood, fire, or burglary occurring in the primary site.
How Does Built-In Immutability Defeat Ransomware?
Attackers often go straight for the backups, scanning the networks and rapidly encrypting the data or deleting it entirely. This can be effectively countered with immutability locks. Our backup stacks enable write-once-read-many (WORM) retention. Once set, even admin accounts are unable to purge until the window expires. A 14- to 30-day lock window is recommended as a timer. This immutability can be bolstered further with certain products such as Linux-based hardened repositories that serve as an air gap. They are imperceptible to SMB/CIFS browsing but separate production credentials from stored backups.
Organizations leveraging immutable copies restore operations in half the time of those using non-hardened repositories. They also slash their ransomware recovery costs considerably. Studies by Sophos and IDC suggest they save over 60 %.
Lightweight, Automated Day-to-Day Ops
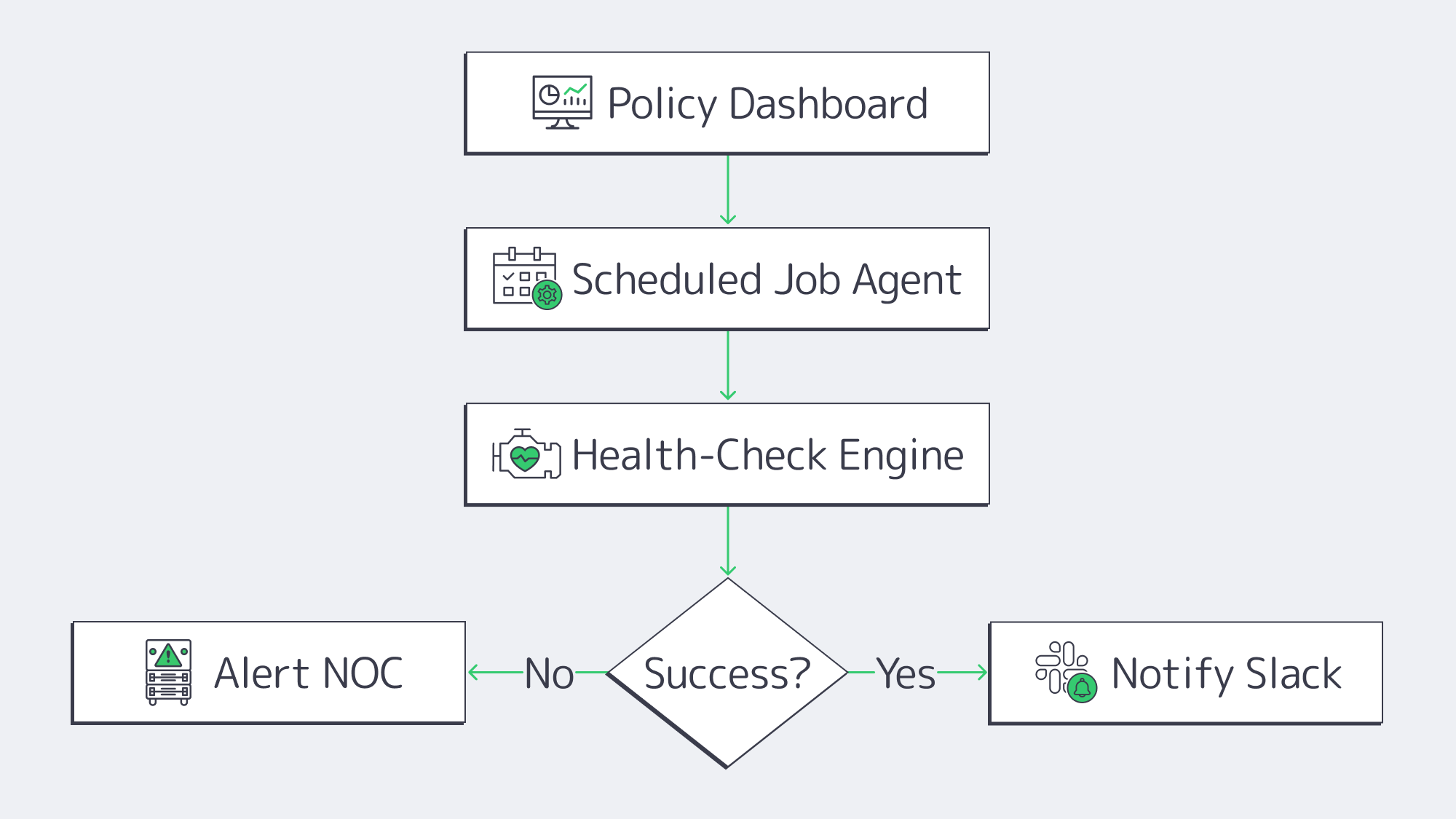
In SMBs where IT resources are constrained backup babysitting can be a real headache, but with modern engines operations and IT workloads are streamlined:
- Job scopes are defined with policy-first dashboards. Agents inherit RPOs, retention, and encryption once settings are applied.
- Restore points are constantly verified through automated health checks ensuring data is bootable.
- Success and failure events are automatically forwarded to Slack or SIEM through API hooks and webhooks.
Workflow times for quarterly test restores are significantly reduced, as most software can automate 90 % of the work. It is simple to select a VM and a handful of files and verify hashes, comparing them with production by spinning them up and tearing them down in an isolated VLAN or sandbox.
A Brief Overview of Best Hardening Practices
- Isolating networks: You can reduce unnecessary port exposure by placing the backup server on a VLAN of its own or operating on a separate subnet.
- MFA as standard: Secondary forms of authentication are required for both console and software access.
- In flight and at rest encryption: Replication paths should employ TLS and stored blocks should leverage AES-256 encryption as standard.
- Frequent patching: Hardened backup appliances need to be regularly patched to reduce the attack surface; if self-patching, follow a 30-day update SLA.
The above steps make your infrastructure less of a target for ransomware attacks. Should you fall prey, these extra precautions ought to raise alarm bells tripping SIEM before the damage is done and they don’t cost any extra to put in place.
Checklist: Implement a Dedicated Backup Server with Confidence
| Step | Outcome |
|---|---|
| Size capacity & retention | Enough headroom for 12–18 mo. growth |
| Select incremental-forever capable software | Faster jobs, smaller footprint |
| Enable immutability locks | Protect recent backups against deletion |
| Configure cloud sync or second site | Satisfy 3-2-1 without manual media rotation |
| Schedule quarterly test restores | Prove backups are usable |
Follow the list and the gap between a compliance breach and a clean audit narrows dramatically.
Make Your SMB Data Protection Future-Proof with a Dedicated Backup Server

Backup efforts need to take the following into consideration: ransomware, compliance scrutiny, and raw data growth. Modern-day digital operations have gone beyond cloud SaaS and tape silos. The simplest, safest solution is a dedicated backup server for full control. With a dedicated server solution, incremental-forever captures run in the background, syncs are automatic, and deltas are stored off-site, bolstered by advanced encryption. This keeps data sealed, and all restore points are protected by immutable locks that prevent tampering. For SMBs, this modern model grants recoveries akin to those of a Fortune 500 company without hefty budgets, global clustering overheads, or complex DR orchestration.
Making the move to a dedicated setup is far less of a headache than it sounds. Simply provision a server, deploy backup software and point agents on it, and leave policy engines to do the hard work for you. For very little outlay and effort, you get airtight retention and rapid restoration at LAN speed should disaster strike. With this type of modern setup and the best practices in place, ransomware actors have a hard time getting their hands on anything of any use to exploit and corrupt, and it demonstrates secure operations to compliance auditors and customers. Organizations with smaller IT teams will also benefit from a higher return on uptime than ever before.
Order a Backup Server
Deploy a purpose-built backup server in minutes and safeguard your SMB data today—with Melbicom’s top-line infrastructure.
Get expert support with your services
Blog
Dedicated Hosting Server: a Path to Greater Control
Modern jurisdictional boundaries continue to put increasing pressure on data transmission and storage. Many organizations were quick to jump on the “cloud-everything” bandwagon only to realize it simply doesn´t suffice for latency critical workloads, resulting in a shift back to physically located infrastructure. Hence we are seeing dedicated hosting servers with their endless tweakability, ideal for the most rigorous of audits.
IDC’s late-2024 workload-repatriation pulse found that 48 % of enterprises have already shifted at least one production system away from hyperscale clouds, and 80 % expect to do so within two years.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Market spending is also following suit; the estimated total revenue according to Gartner’s Dedicated Server Hosting Market Guide is projected to be $80 billion by 2032. The majority of the capital is used by providers to work on integrating cloud-like automation with single-tenant hardware. Which is exactly what we do at Melbicom. We use that revenue flow to provide customers with over 1,300 ready-to-go configurations in 21 Tier III and Tier IV data centers, delivering 200 Gbps of bandwidth per server. Procurement is a painless online process that can be up and running in less than two hours, and is easily managed via API.
Melbicom infrastructure is founded on five fundamentals that address data sovereignty and control anxieties; root access, bespoke software stacks, custom security, compliance tailoring, and hardware-level performance tuning.
Repatriation and Sovereignty Fuelling the Return to Dedicated Server Solutions
Across the board, data residency has become a genuine concern, state privacy statutes have tightened considerably and Europe has Schrems II in place. Following this data shift in focus, data sovereignty is now a top buying criteria for 72 % of European enterprises and 64 % of North-American firms. Regionally pinned public-cloud VMs can help with proof of sovereignty to an extent but with a dedicated server, every byte is accounted for, better satisfying auditors. sits on hardware you alone occupy. With Melbicom, our clients can show hardware tenancy proving they alone occupy whether it is by positioning analytics nodes in Amsterdam’s Tier IV hall to adhere to GDPR demands, or anchoring U.S. customer PII inside our Los Angeles facility.
A dedicated server also provides more clarity of sovereignty demonstrating where control boundaries lie. With VMs the root is exposed from within its guest but there are many invisible elements at play such as firmware patches, hypervisor policy, and out-of-band management. With dedicated hosting everything from BIOS to application runtime is sovereign. Intel SGX can be toggled via the BIOS flag for enclave encryption and management traffic can be locked to an on-prem VPN by simply binding the BMC to a private VLAN. Compliance language demands “demonstrable physical isolation,” and with single-tenant hosting you can demonstrate beyond doubt that nobody else is using your server or resources.
Root Access Liberation
Arguably one of the biggest benefits of hosting with a dedicated server is the advantage of full root access for engineers. microsecond deterministic trading is possible by recompiling the kernel with PREEMPT_RT, you can follow packets at nanosecond resolution by dropping in eBPF probes and rapidly deploy a hardened Gentoo build with ease. Kubernetes can be run directly on the host, via physical CPU cores in place of virtual slices, and strip jitter is significantly reduced helping with latency-sensitive microservices.
Workflows are cleanly translated in terms of infrastructure as code and you can PXE-boot, image, and enroll just as easily as a cloud VM using Terraform or Ansible on a physical host. With sole tenancy, the blast radius is contained should an experiment brick the kernel, only your sandbox alone is affected lowering systemic risk. There are also no hypervisor guardrails dictating rescue procedures giving full autonomy and accelerating iteration.
How Does Root Access Unlock Bespoke OS and Software Stacks?
Public clouds often limit OS and software stacks forcing organizations to find a workaround rather than load what they prefer to use. With sole tenancy and full root access the operating system is customizable to your needs. Those in media can optimize their network speeds using FreeBSD, for example, whereas fintech teams requiring certified crypto libraries might load CentOS Stream. The latest CUDA drivers can be placed on Rocky Linux with AI lab, whatever image you want can be tested and then copied to other machines.
You only have to look to open-source databases to understand the upside. Marketplace defaults are usually layered upon virtualized disks and typically have less sustained writes than a self-compiled PostgreSQL tuned for huge pages and direct I/O which routinely delivers 25–40 % more. With a dedicated server there is nothing forcing snapshots or stealing cache lines and so, even a low cost setup often beats the performance of a pricy multi-tenant option.
How Does a Dedicated Hosting Server Clarify Security and Compliance?
A dedicated server provides a very clear attack surface with crisp boundaries far more transparent environment provided by multi-tenant environments and preferred by CISOs for their black-and-white nature. There is physical separation whether disk encryption keys reside in an on-board TPM or are harbored on an external hardware security module reached over a private fiber cross-connect. Air Gapping separates packet captures en route to SOC appliances and they are allowed or blocked by firewalls operating within your own pfSense chain.
The clarity of separation provided by a dedicated hosting server satisfies PCI DSS, HIPAA, and GDPR demands. Single tenant, audits are a doddle, the hardware is tagged and cables are traced. The posture is further strengthened at Melbicom through optional private VLANs and we are also capable of replacing hardware within a four-hour window further satisfying regulators. Essentially, Melbicom takes care of the plumbing, freeing up your security teams to enforce policies.
Hardware‑Level Performance Engineering
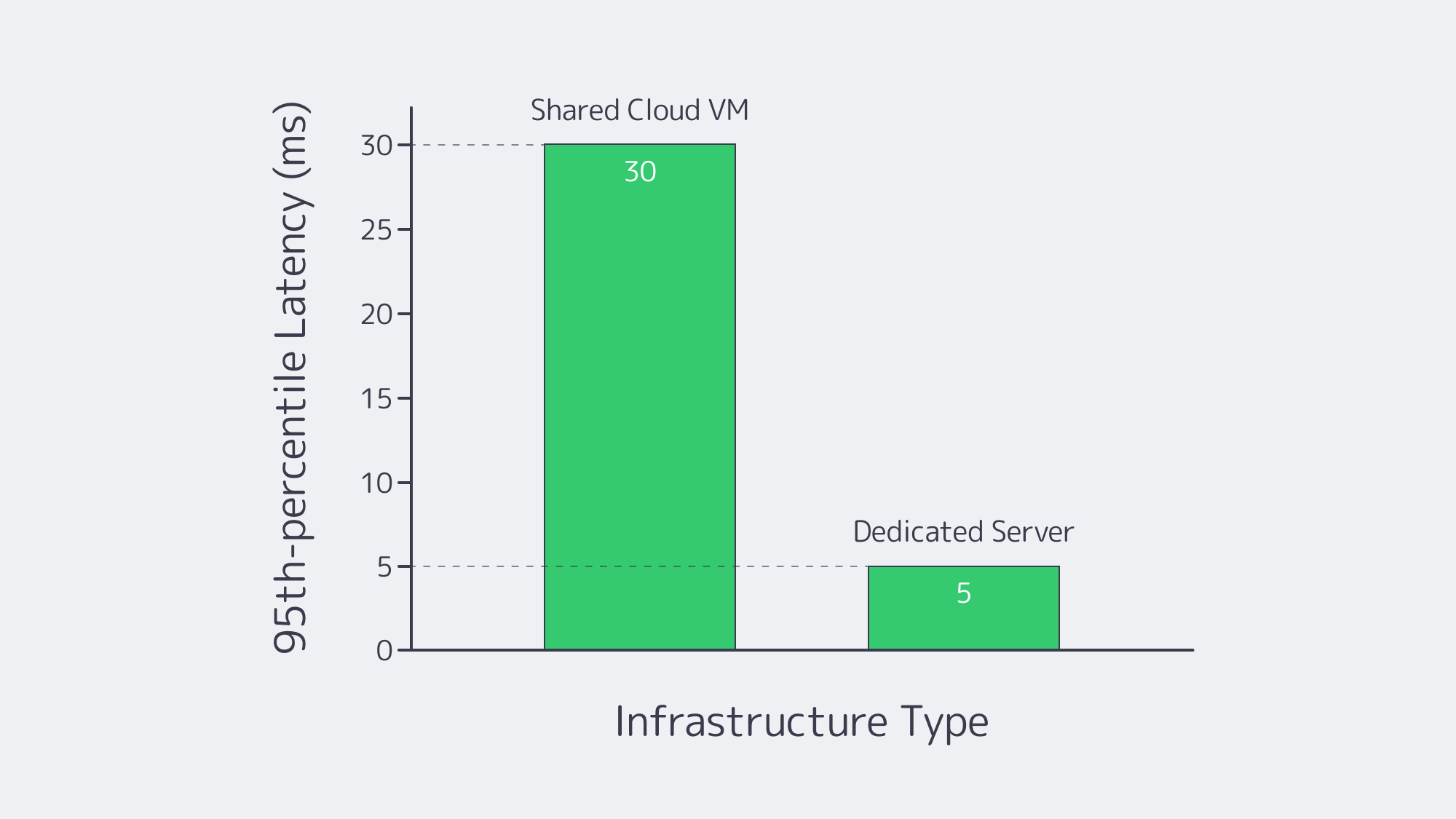
Performance goes beyond merely raw speed, with VMs engineers have to architect with unfriendly neighbors in mind but this statistical multiplexing is avoided through a dedicated server. With single tenancy you have worst-case predictability because CPU cycles, cache lines, and NVMe interrupts are yours exclusively. This shrinks long-tail latency and improves performance dramatically.
You also unlock performance preferences, be it 56-core Intel Xeon processors for parallel analytics or a front end burst focus with fewer but higher-GHz cores. With Melbicom choices are readily available to you. With a dedicated 200 Gbps throughput per server, without the throttling often experienced with noisy neighbors real-time video or massive model-training pipelines are easily supported and sustained. We also offer flexible storage tiers; NVMe RAID-10 for OLTP, spinning disks, or Ceph surfaced hybrid pools.
These capabilities are afforded to the SKUs of even our most economic options. Our dedicated servers are fully transparent and also benefit from SMART telemetry and provide full IPMI access. That way if a disk trending toward failure is spotted engineers can request a proactive swap.
Performance Levers on Dedicated vs. Shared Hosting at a Glance
| Layer | Shared Cloud VM | Dedicated Hosting Server |
|---|---|---|
| CPU | Noisy-neighbor risk | 100 % of cores, NUMA control |
| Disk | Virtual, snapshot overhead | Raw NVMe/SAS with custom RAID |
| NIC | Virtual function, capped bandwidth | Physical port, up to 200 Gbps |
A Familiar Story: Historical Vendor Lock-In
Historically, the industry is all too familiar with the promises of frictionless scalability touted by proprietary databases and serverless frameworks. Promises that were dashed by egress fees, licensing traps, and deprecations. Architects learned the hard way that anchoring critical data on hardware they can relocate was necessary for a smoother exit. Fortunately, the PostgreSQL provided by a dedicated hosting server is portable, Kafka is upstream, and it is more or less painless to move Kubernetes clusters. All of which makes it a great middle ground solution should history repeat itself strategies shift in the years to come. With a dedicated server moving data from one center or provider to another is possible without rewriting fundamental services, something which will undoubtedly pique the interest of CFOs.
How to Make Infrastructural Autonomy Your New Baseline

Without the assurance of how stacks cope under pressure and a guarantee on where the data lives, fast features are ultimately worthless. Leveraging a dedicated server for hosting solves both issues. The hardware is transparent, ensuring latency is predictable and this hand in hand with highly customizable security keeps regulators happy in terms of data sovereignty and compliance. Unrestricted roots leave space for innovation, bespoke software performs better, and cloud elasticity is retained lending a competitive advantage ideal for experiments.
Ready to Order?
Get yourself the perfect blend of control and convenience by opting for a dedicated server with Melbicom. We have multiple Tier III/IV locations on three continents, housing an inventory of over 1,300 configurations for easy deployment in less than two hours.
Get expert support with your services
Blog

Finding the Right Fit: MySQL Database Hosting Service
The majority of the world’s busiest applications rely on the relational database powers of MySQL. While it has many merits that have earned it its global popularity, hosting and scaling it effectively is no easy feat, and the heavier the load, the harder the task.
Your basic single-instance setups that use a solitary machine running one are pretty outdated for modern needs. These setups lack failover, and scaling them horizontally is limited. Moreover, the downtime can be catastrophic should the lone server fail.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
A flexible, distributed architecture that can deliver speed is required to cope with the demands of high-traffic workloads.
So let’s discuss and compare the respective advantages and disadvantages of the three leading infrastructure models for a MySQL database hosting service: managed cloud, containerized clusters, and dedicated servers. By focusing on performance, scaling replicas, automated failover, observability, and cost as key aspects, the strengths and drawbacks of each soon become clear.
What Are the Key Requirements for a MySQL Database Hosting Service?
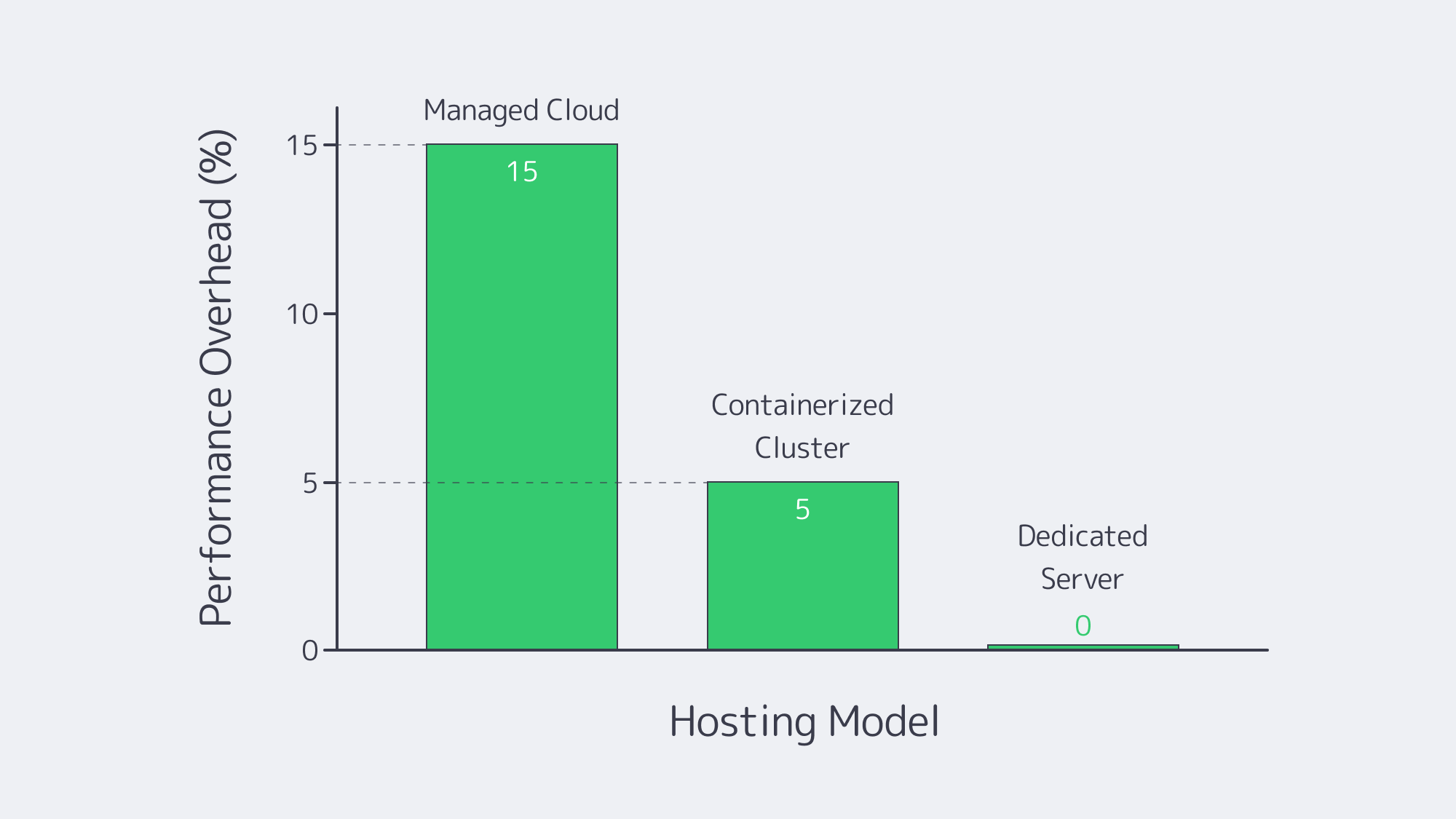
Performance
Low latency and sustained throughput are needed for adequate performance during peak loads in high-traffic environments, and the performance boils down to the infrastructure in place. When compared against physical hardware, virtualized MySQL implementation typically has a 5–15% overhead, which grows concurrently. Dedicated servers, on the other hand, eliminate the use of virtualization layers, granting access to all CPU and I/O resources. Although they perform well, containerized clusters such as Kubernetes throw extra variables in the mix to consider. They require more in terms of platform setup, such as storage drivers and network overlay.
Scaling Replicas
MySQL deployments use read replicas to deal with large query volumes. This replication is simplified by cloud providers through the use of point-and-click. Similarly, container-based clusters can be scaled using Kubernetes operators. However, multi-primary, large shard counts, and other specific topologies typically require some manual work. For real freedom, dedicated infrastructure offers the best scaling because you can just deploy more physical nodes as needed. This means there is no imposed hard limit on replica counts, and advanced replication patterns are no trouble.
Automated Failover
Downtime can result in less than favorable UX and ultimately means a loss in revenue, making failover extremely important. The architecture behind modern managed cloud MySQL deployments, such as Amazon RDS or Google Cloud SQL, can switch to standby instances automatically. This is typically completed within 60–120 seconds of downtime. Container platforms like Percona, Oracle MySQL Operator leverage orchestrators or specialized MySQL operators to detect node failures and promote replicas. However, the Orchestrator or MySQL Group Replication tackles failovers in seconds when hosted via a dedicated server solution, so long as redundancy and monitoring are in place.
Observability
Sophisticated monitoring is needed to successfully run MySQL at scale. It is important to observe CPU, RAM, and disk server metrics as well as query insights such as latency, locks, and replication lag. Often, dashboards are provided by managed services, but they often only display common metrics for those with low-level access. Container-based setups provide granular data through robust stacks like Prometheus or Grafana, but if your in-house expertise isn´t up to scratch may be tricky to maintain. With a dedicated server, you have total control over the OS, which means you can install any monitoring system, such as Percona’s PMM, ELK stacks, or custom scripts for a detailed overview.
Cost Modelling
As with any business decision, cost is often a major deciding factor. Opting for a managed service means less work in terms of maintenance and requires little to no knowledge, but you can expect premium rates for CPU, memory, and I/O, plus bandwidth and storage fees. While it can be beneficial for smaller workloads, for anyone sustaining high traffic, the costs are going to rack up quickly. Surveys in recent years have uncovered that almost half of the cloud users’ costs have been far higher than initially expected. These overheads can be potentially reduced for operations sharing resources across multiple apps if you opt for container-based MySQL, but only if they run on existing Kubernetes clusters. The underlying nodes still require outlay, and you have many other components at play that all incur costs of their own. To avoid unexpected charges, a dedicated server with a predictable monthly or yearly rate can prevent nasty surprises. Renting or owning hardware works out the most economical in the long run at scale; there are no cloud markups or data egress fees to contend with.
What Is Managed Cloud MySQL Hosting and When Should You Use It?
Choosing a managed cloud service (also referred to as DBaaS) to host MySQL databases can simplify the process significantly. These platforms handle OS patching, backups, software updates, and have basic failover automation in place.
So if you don´t have extensive DBA or are lacking DevOps resources, then a managed cloud service on such as platforms like Amazon RDS or Google Cloud SQL, can be a lifesaver. A simple API call adds replicas with ease, and you can enable high availability by just checking a box.
Managed Cloud Performance: Regardless of how powerful the hardware it must be noted that these services share a virtualized environment and many vendors have parameter limits in place. You may also find that specialized configurations are not permitted. In benchmark testing, raw overhead has been shown to degrade throughput by up to 15% where workloads are demanding.
Scaling Replicas: While creating multiple read replicas is allowed, multiple primary replicas and custom topologies might not officially be supported. So, depending on how heavy your read-only workload is, managed clouds may or may not be right for you. Amazon RDS supports up to 15 for MySQL, which could well be sufficient for some.
Automated Failover: The biggest advantage that managed cloud options have to offer is a swift automated failover. Standby replicas in different zones maintain synchronicity, taking roughly a minute or two, meeting the majority of SLAs.
Observability: The dashboards offered by the top managed cloud solutions might not give O-level access, but they do provide basic metrics and are easy to track. Deep kernels and file system tweaks are unavailable, but users still get access to slow query logs.
Cost: Most of these platforms operate in a pay-as-you-go manner, which is attractive to new users and convenient, but costs can soon mount. Add to that storage IO, data transfer, and backup retention, and like the majority of organizations leveraging these services, you could be in for a shock. Those with consistently heavy traffic will ultimately find that renting a physical machine saves them money collectively in the long run.
What Are the Trade-Offs of Hosting MySQL in Containerized Clusters?
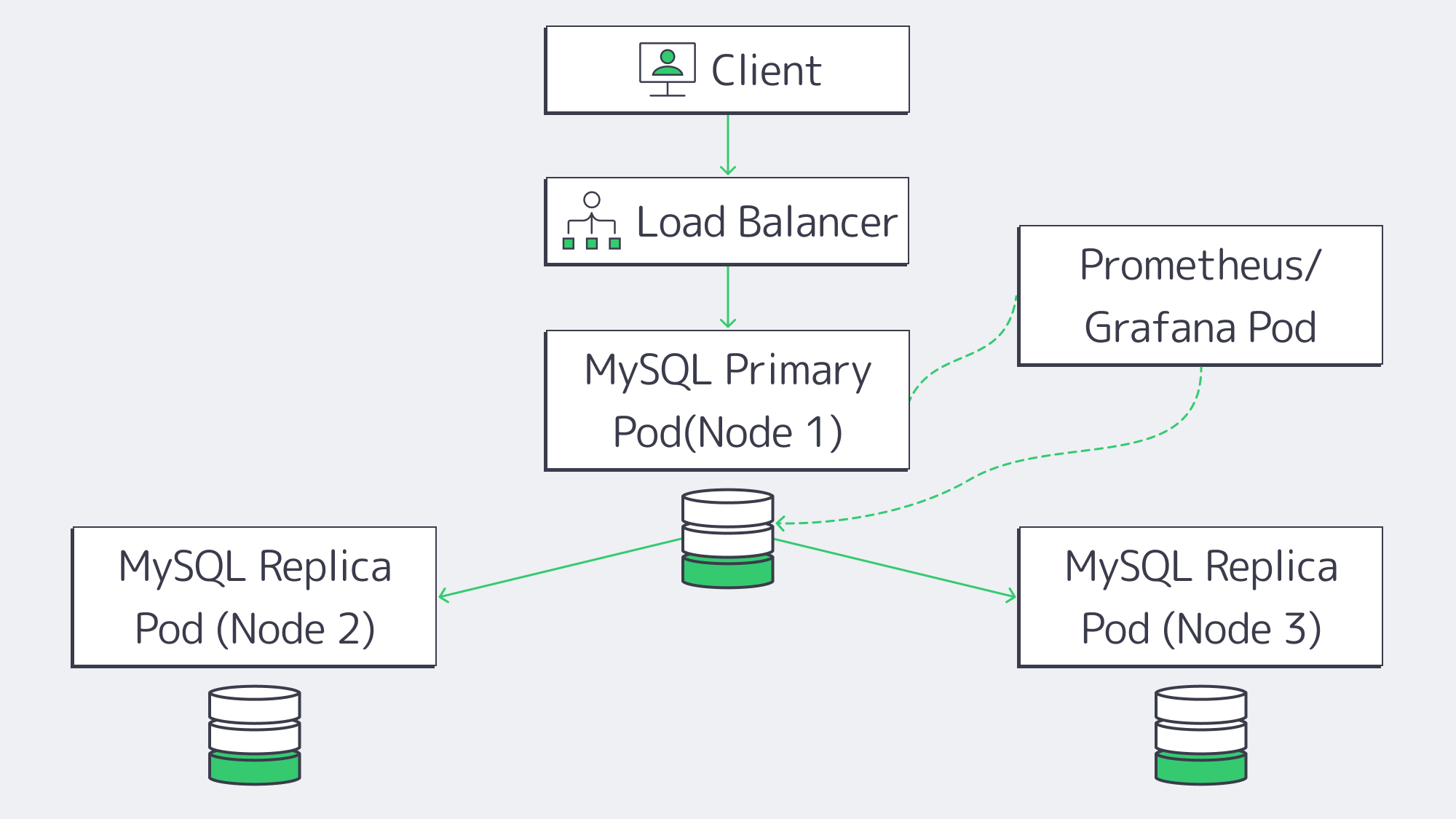
Containerized clusters are considered a good middle ground option, and for those already operating with other microservices, it can be the most sensible solution. Orchestration platforms like Kubernetes can help automate replicas and backups, helping considerably with MySQL management.
Containerized Performance: The typical overhead with container operation is often less than full VMs, but you have to consider that if Kubernetes itself sits on virtual nodes, then abstraction comes into the picture, adding complexity to the performance situation. As does the network itself and any storage plugins.
Scaling Replicas: With a MySQL operator, you can handle replication set-up and orchestrate failovers. They can spin up and remove rapidly, but large multi-primary or geo-distributed clusters need customizing, which could be out of your wheelhouse.
Automated Failover: Failed pods are quickly identified and restarted, and a replica can be converted to primary automatically, but fine-tune readiness checks are needed to make sure everything is in sync, which can harm reliability. Without the right checks in place, split-brain scenarios are possible.
Observability: Logging stacks and granular monitoring tools such as Prometheus or Grafana can be easily integrated with Kubernetes, giving plenty of metrics. However, the node networks must be monitored in addition to keep track of cluster health properly.
Cost: Those with Kubernetes in place for other operations will find they can cost-effectively piggyback MySQL onto an existing cluster, so long as resources are available. If you are starting totally from scratch and just want Kubernetes to cover your MySQL needs and nothing else, then, in all honesty, it is probably overkill. The infrastructure outlay will set you back, and managing the cluster adds further complexity.
Why Choose Dedicated Servers for MySQL Database Hosting?
If you have high-traffic needs and require control, then the raw power on offer from a dedicated server often makes it the best MySQL database hosting service choice. Through Melbicom, you can rent physical servers housed in our Tier III or Tier IV data centers situated worldwide. This gives you unrestricted access to single-tenant hardware without hypervisor overhead.
Dedicated Server Performance: As there is no virtualization, users get full CPU, memory, and disk I/O. When compared directly with cloud VMs benchmarks, dedicated server solutions demonstrate performance gains of around 20–30%. Query latency for I/O-heavy workloads is also dramatically reduced when local NVMe drives are hosted on dedicated machines.
Scaling Replicas: Read replicas are unlimited, and advanced MySQL features such as Group Replication, multi-primary setups, or custom sharding are unrestricted depending on how many servers are deployed.
Automated Failover: With open-source tools like Orchestrator, MHA, or Group Replication, you can configure your failover however you choose. With the right configuration, failover matches any cloud platform, and multi-datacenter replication is globally available.
Observability: With dedicated server hosting, you have full OS-level access, meaning you can use any stack, be it Percona PMM or ELK, etc. This allows you to monitor a better variety of aspects, such as kernel tuning, file system tweaks, and direct hardware metrics.
Cost: Dedicated infrastructure has an initial outlay, but it remains predictable; there are no nasty surprises, regardless of any unexpected spikes. Those with a substantial workload will find that the total is generally far lower than equivalent cloud bills. Melbicom offers large bandwidth bundles with generous allowances up to 200 Gbps per server. We also provide 24/7 support as standard with any of our plans.
Trade-Offs: The only real caveat is that OS patches, security, backups, and capacity planning need to be handled on your end, but most find it an acceptable overhead considering the performance, control, and TCO predictability benefits that a dedicated server presents.
MySQL Hosting Models Compared: Cloud vs. Containers vs. Dedicated
Take a look at the following table for a concise comparative overview of each model:
| Model Type | Advantages | Disadvantages |
|---|---|---|
| Managed Cloud | – Simple startup- Integrated HA & backups | – Virtualization overhead- Limited configurations available- Costs can mount |
| Containerized (K8s) | – Portable across clouds- Automated with operators- Good union if you use K8s already | – Requires previous expertise- Storage/network complexities- Fluctuating overhead |
| Dedicated Servers | – Unbeatable raw performance- Full control, no hypervisor- Costs are predictable | – In-house management needed- Can’t be scaled instantly- Requires hands-on setup |
How to Choose the Best MySQL Database Hosting Service

Ultimately, to choose the best MySQL database hosting for your needs, you need to consider your workload, budget, and in-house expertise. Each of the top three models has benefits and drawbacks. A managed cloud might be convenient, but it can be costly to scale. If teams are already invested, then containerization provides sufficient automation, but may not handle complex needs. For reliable performance, a dedicated server is a powerful, dependable, cost-effective solution that won´t let you down.
When it comes to high-traffic applications that hit resource ceilings or cost ceilings, the blend of speed, control, and predictable expenses that a dedicated server solution brings to the table is unbeatable. With a dedicated server running MySQL, organizations can avoid premium charges and cloud lock-ins resiliently with the right failover configurations in place for truly dependable, scalable, managed services.
Ready for Faster MySQL Hosting?
Deploy your MySQL on high-performance dedicated servers with predictable pricing.