Author: Melbicom
Blog

Hybrid Wins: Cost, Control, Performance In Atlanta
The cloud is easy to start with, but costs can rise quickly and performance can fluctuate. The modern question isn’t “cloud or not,” but “what runs best where.” Dedicated server hosting in high‑connectivity hubs such as Atlanta has evolved into a predictable, high‑performance alternative to multi‑tenant cloud.
Below, we focus on cost, control, and performance—and show why a hybrid strategy anchored in Atlanta dedicated server hosting often proves highly effective.
Choose Melbicom— 50+ ready-to-go servers in Atlanta — Tier III-certified ATL data center — 55+ PoP CDN across 6 continents |
 |
Why Are Teams Re‑Evaluating All‑Cloud Strategies?
Current planning is dominated by two realities: spend uncertainty and performance variability. Across enterprises, cloud spend governance remains the top challenge, and multi‑cloud complexity has become the norm. Independent surveys indicate organizations self‑estimate roughly 30–32% of cloud spend as waste—idle or abandoned capacity, over‑provisioned instances, forgotten services, and egress surprises.
Simultaneously, hard figures have made a hole in the myth that clouds are always less expensive. Free surveys indicate that organizations are self-estimating cost on their cloud wastages at about three times their cloud costs abandoned capacity trees, over provisioned instances, forgotten services and egress surprises. And there are top-notch examples of firms reclaiming spending through the transfer of steady workloads off public clouds. Dropbox reported nearly $75 million in infrastructure savings over two years after repatriating substantial storage from the public cloud. 37signals projects about $10 million in savings over five years (~$1–2 million per year) from moving remaining workloads off the public cloud.
The next phase of architecture movement is practical: hybrid. Organizations embrace a right fit model – have elastic or experimental scales in the cloud, but fix steady, bandwidth intense, or provide very low latency loads to dedicated servers. Polls indicate that hybrid/ multi cloud is the new reality: 88% of those who purchase clouds are or run hybrid clouds.
What Makes Atlanta a Strategic Hub for Dedicated Infrastructure?
Density and reach. Atlanta hosts 140+ data centers, with key interconnection at 56 Marietta Street (Digital Realty ATL13), the Southeast’s largest carrier hotel with hundreds of networks. The mesh provides low‑tens‑of‑milliseconds paths to the East Coast, Midwest, and Latin America, with abundant options for private and public peering.
Economics. Georgia’s commercial electricity rates are in the low‑teens cents per kWh, a structural advantage that translates into competitive server pricing. The region is growing rapidly: hyperscalers are expanding, and AWS has announced at least $11 B of new DCs in Georgia to meet cloud and AI demand. That development is the foundation of extended network and supply chain robustness that could be tapped by committed clients.
Melbicom in Atlanta. Melbicom operates a Tier III Atlanta facility with 1–200 Gbps per‑server connectivity and a 14+ Tbps global backbone. Provisioning is fast—ready‑to‑go servers can be online within hours—and component replacement is completed within 4 hours, with free 24/7 technical support. Additional options include BGP sessions and private networks for advanced routing.
Costs Compared in Practice
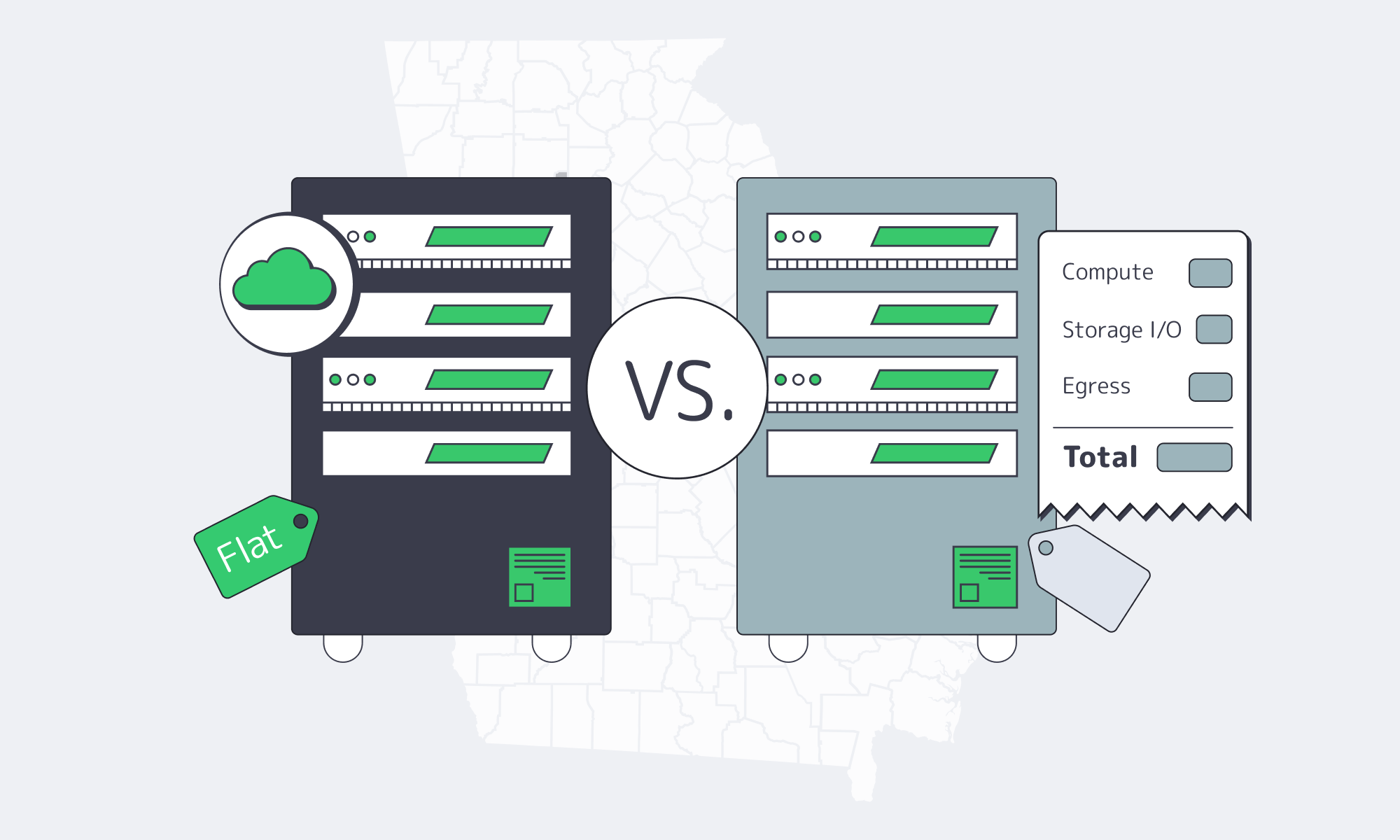
A spiky workload suits the cloud, whereas steady 24/7 loads are penalized as CPU, storage, and especially egress rack up line items. Because dedicated resources are reserved, dedicated servers flip the equation: pricing is predictable, and generous or unmetered transfer often neutralizes egress shocks. The outcome is proper budgeting and a reduction of what just happened scenarios where traffic goes crazy.
The macro picture matches what finance sees on invoices: cost management is the top cloud challenge, and roughly one‑third of spend is waste without disciplined FinOps, whereas dedicated servers enable deliberate capacity planning—you right‑size, run hot as needed, and aren’t charged extra when more users show up.
Case evidence: Dropbox saved $75M and 37signals wrote a series titled ‘We Left the Cloud’ is an illustration of the consistent workloads which is advantageous to owning or renting dedicated capacity. To most teams, an Atlanta dedicated server is the cost anchor: 24/7 throughput is flat and cloud means automatically the elasticity is a pay-off.
Cost model at a glance
| Cost factor | Public cloud (on‑demand) | Dedicated server (Atlanta) |
|---|---|---|
| Pricing model | Per hour compute, storage I/O, egress. Bills vary with consumption. | Highly desired CPU/RAM/Storage, flat monthly; immensely high transfer |
| Scalability vs. cost | Elastic but scale linearly with peak demand; bill spikes potential. | Fixed capacity at a fixed monthly price; no per‑use bill spikes within your port limits. |
| Bandwidth charges | Egress is usually $/GB; high transfers prevail. | No per‑GB charges within plan; often unmetered or high‑quota transfer included. |
| Long‑term TCO | Economical in short lived or infrequent activities; expensive in 24/7 base load | Lower TCO when the workload remains constant; easier monthly budget planning. |
Dedicated Servers: Consistent Performance
On cloud instances, you share the physical host with other tenants, which can introduce variability. This phenomenon is extensively studied in literature and in trade knowledge bases and still presents a source of variation even with mitigation done by the providers.
With a dedicated server, there is no other tenant—100% of the CPU, RAM, disk, and NIC capacity are yours, eliminating hypervisor‑level contention and burst‑credit throttling. In high throughput pipelines, training jobs, high throughput pipelines or large streamers, that consistency can have a better value than the theoretical burst of a cloud VM. In Atlanta specifically, Melbicom offers 1–200 Gbps per‑server ports, providing far higher line‑rate headroom than typical VM tiers.
Dedicated Servers: Greater Control and Customization
The advantage of clouds is abstraction, and the disadvantage is a lack of control over the underlying stack. You can’t tune firmware settings, choose specific RAID topologies, or attach hardware outside a cloud provider’s catalog. With dedicated servers, you are in control of the environment, the OS, kernel parameters, storage layout and network stack. Need BGP to announce your own prefixes or private L2 between nodes? Melbicom assists with those scenarios while handling the heavy lifting (remote hands, component swaps, facility operations).
Specificity matters: a Tier III facility in Atlanta, GA with defined access policies and physical security controls is easier to attest than an abstracted cloud region. Regulated data or deterministic forensics to regulated data or deterministic forensics, it is often the case that this specific machine in this specific building becomes the short route to green light.
Hybrid Deployments: Combining Cloud and Atlanta Dedicated Servers?

The sensible middle ground Hybrid, stack your elastic, event driven bits in cloud; Pin steady baseload -databases, origin servers, batch engines -on Atlanta dedicated servers, flat cost and predictable performance. It has become a thing: the use of multi clouds is almost universal and hybrid implementations are indicated by the vast majority of buyers.
Atlanta plays both a technical and geographic role: interconnection at 56 Marietta enables cross‑connects to carriers, CDNs, and cloud on‑ramps, and the metro’s fiber mesh reaches the Southeast and East Coast in low‑tens‑of‑milliseconds. The global CDN (55+ PoPs) of Melbicom allows pinning an Atlanta dedicated server as the origin and pushes the content closer to users all over the world.
Which Should You Choose: Dedicated Servers or Cloud?
Architecture to workload reality: Use this checklist to balance architecture to workload:
- Workload profile & predictability. 24/7 continual demand → support Atlanta dedicated server hosting due to cost/TCO, sudden/short-term → cloud.
- Budget control. Require flat and predictable OPEX and no egress surprises? Dedicated fits. Cloud demands aggressive FinOps lest it run out of control; the most reported issue is spend control.
- Performance sensitivity. Throughput‑bound or latency‑critical systems (real‑time analytics, trading, MMO backends, media origin) prioritize single‑tenant consistency over multi‑tenant burst. Risk of noisy neighbor effects tilts toward dedicated.
- Geography. Atlanta dedicated server placement offers advantages to users in the southeast of the U.S.; the 56 Marietta backbone has more variety to further path selection to the larger ISPs.
- Control & compliance. Seeking firmware level tuning, custom network or more restrictive data residency? Dedicated. Melbicom facilitates BGP, private network and full control of an OS in a tier III Atlanta location.
- Long‑term economics. In the case of baseloads, the example given by Dropbox and 37signals indicate sustained savings in making the transition off of on demand cloud to owned/rented capacity.
Balancing Cloud Elasticity with Atlanta’s Dedicated Server Predictability

The pay as you go concept of the cloud is indispensable- test it, short lived loads, and especially, global managed services. There is no change in the economics or physics of compute, though: stable, bandwidth intensive, and latency sensitive systems are cheaper and more stable when running on the hardware alone. That’s why the strongest architectures today are hybrid, with Atlanta dedicated servers anchoring baseload capacity and the public cloud providing on‑demand elasticity. The outcome would be budget predictability, head room of performance, and control over operations- without compromising agility that the teams would require.
Atlanta adds to those profits. The intensive connection network, competitive power economy, rich carrier options, and extensive support ecosystem has meant that you will be able to locate compute in any place it will be of the most benefit to your users. And Melbicom completes the puzzle with the missing components—Tier III facility standards, fast provisioning, and a backbone built for high throughput—so you aren’t trading convenience for control.
Deploy Atlanta Dedicated Servers
Order high‑bandwidth dedicated servers in Atlanta with fast setup, 24/7 support, and BGP options for predictable cost and consistent performance.
Get expert support with your services
Blog
Why UAE Hosting Delivers Speed, Compliance, and Scale
Enterprises serving customers across the Gulf now face a simple infrastructure question with complicated consequences: where should the origin servers live? For years, many hosted in Europe or North America and absorbed the cost of distance—triple‑digit‑millisecond round trips and cross‑border data exposure. Between London and Dubai alone, typical latency hovers around ~130 ms. Today, a dedicated server in the UAE places compute inside the region’s network core, aligning with data‑residency rules and delivering ultra‑low latency for fintech, e‑commerce, AI inference, streaming, and collaborative apps. This is no incremental tweak; it’s the difference between “fast enough” and instant—and between “legally acceptable” and locally compliant.
Choose Melbicom— Dozens of ready-to-go servers — Tier III-certified DC in Fujairah — 55+ PoP CDN across 6 continents |
|
Why Are Digital Demands in the Middle East Surging?
Two secular shifts define the region’s new reality. First, digital consumption and online commerce are exploding; Deloitte estimates Middle East e‑commerce will reach roughly US$50 billion in the near term, propelled by mobile adoption and pro‑digital policy. Second, data center capacity is ramping hard: PwC projects regional capacity to triple—from ~1 GW to ~3.3 GW—over five years, driven by cloud, AI, and sovereign data strategies. In other words, the demand side (users, transactions, streams) and the supply side (local compute, power, and interconnects) are meeting in the UAE and its neighbors, making a regional hosting footprint both practical and advantageous.
What Do Strict Data‑Residency Laws Mean for Your Hosting Strategy?
Compliance has moved infrastructure decisions from “best practice” to “must have.” In the UAE, sector rules make the stakes explicit:
- Payments: The Central Bank’s Retail Payment Services and Card Schemes Regulation requires payment service providers to store and maintain personal and payment data within the UAE, with secure backups retained locally.
- Healthcare: The Health Data Law (Federal Law No. 2 of 2019) limits the transfer or processing of UAE health data outside the country except under defined exceptions.
- IoT: The national IoT regulatory policy requires Secret/Sensitive/Confidential data—especially for government or critical infrastructure—to remain in the UAE.
Leading firms summarize the risk plainly: non‑compliance may trigger fines, service suspensions, or even criminal penalties—and cross‑border transfers face stricter scrutiny.
Creating Measurable Advantage via Ultra‑Low Latency

Latency is not an abstraction; users feel it. Human‑factors research shows three crucial thresholds: ~0.1 s feels instantaneous, ~1 s remains flow‑friendly, and >10 s breaks focus—guardrails that translate directly to web and app UX. For revenue‑producing funnels, the numbers are unforgiving: a 100‑ms delay can cut conversions by up to 7%, and 53% of mobile visitors abandon pages exceeding three seconds.
The geography of your origin matters more than any front‑end micro‑optimization. Hosting in Europe or the U.S. keeps round‑trips in the triple‑digit milliseconds for Gulf users (e.g., London–Dubai ~133 ms), whereas a UAE origin collapses that to tens of milliseconds. The regional UAE‑IX exchange (operated by DE‑CIX) keeps traffic local and has demonstrated latency reductions of up to 80% for gaming and interactive content—precisely the workloads most sensitive to jitter and lag.
For industries where milliseconds decide outcomes, the bar is even higher. As DataBank’s Gregory Ryman notes, “Whereas milliseconds were once acceptable, microsecond responses are now required” for trading, payments, and real‑time analytics. AI inference pipelines and personalization engines show similar sensitivity; moving model scoring closer to users reduces tail latency and bandwidth costs, enabling richer on‑page experiences without the penalty of long‑haul calls.
Local UAE Server vs. Overseas Hosting: What changes in practice?
| Factor | UAE Dedicated Server | Overseas Hosting (EU/US) |
|---|---|---|
| Data compliance | Meets UAE localization (payments, health, IoT), keeping sensitive records on UAE soil. | Cross‑border exposure; additional legal burden for transfers and higher penalty risk if localization applies. |
| Latency to Gulf users | Tens of milliseconds via in‑country peering and regional IXs (UAE‑IX). Up to 80% lower vs. out‑of‑region. | 100–200+ ms transcontinental RTT common; sluggish UX under load. |
| User experience | Faster pages and APIs → higher conversions and engagement. | Slower flows → bounce and cart abandonment. |
| Network resilience | Local exchanges + diverse subsea routes keep Gulf traffic in‑region. | Long‑haul dependency raises risk from cable events and congestion. |
| Operational control | Local time‑zone support and auditability under UAE standards. | Remote operations across time zones and jurisdictions. |
What Makes UAE Data Centers Genuinely World‑Class?
Three ingredients: tiered facilities, dense interconnects, and subsea diversity.
- Tiered reliability at scale. The UAE hosts multiple Tier III+ sites, including in Fujairah and Dubai, designed for concurrent maintainability and enterprise uptime.
- A heavyweight Internet core. UAE‑IX (DE‑CIX) now connects 110+ networks and pushes terabit‑scale peaks, keeping content, cloud, and eyeballs local—explicitly to reduce latency and improve experience.
- A cable‑landing powerhouse. Fujairah is the Middle East’s largest subsea landing hub, with systems like AAE‑1, EIG, GBI, SEA‑ME‑WE variants, and the 2Africa mega‑cable adding more diversity via the UAE’s east coast (Kalba). This translates to east‑west path optionality and fast failover when one route degrades.
On top of the physical network, capacity headroom is real. We at Melbicom operate dedicated servers in Fujairah with 1–40 Gbps dedicated port options locally, and per‑server bandwidth up to 200 Gbps in select global locations, with a CDN spanning 55+ PoPs to accelerate static/video workloads outside the Gulf. Free 24/7 support remains standard for dedicated servers.
Why Choose a UAE Dedicated Server Strategy Over “Host Elsewhere and Hope”?

Because distance and jurisdiction now impose hard costs. The UAE offers a rare combination—lawful locality, tens‑of‑milliseconds proximity, and carrier‑dense interconnects—that few offshore options can match for Gulf user bases. The result is not just faster pages; it’s fewer abandoned checkouts, snappier banking flows, and smoother AI‑assisted experiences.
When is dedicated server hosting in UAE non‑negotiable:
- You process regulated data (payments, health, government/IoT), or must prove records stay in‑country.
- You sell or trade in real time (fintech, marketplaces, gaming) where milliseconds—or microseconds—matter.
- Your conversion engine depends on speed (retail, subscriptions, ads), and you can’t afford 100‑ms tax from offshore origins.
- You need scale and resilience with in‑region peering and subsea path diversity—not single‑continent bets.
Where Does the UAE Stand vs. Saudi Arabia and Qatar?
All three markets are modernizing fast and tightening oversight of personal data. Saudi Arabia’s PDPL and sector frameworks (e.g., SAMA) restrict cross‑border transfers and increasingly enforce localization—making in‑KSA hosting advisable for Saudi‑resident datasets. Qatar’s PDPPL also limits transfers and prescribes fines.
What makes the UAE uniquely useful is its function as the GCC interconnect fabric—home to UAE‑IX and Fujairah’s cable landings—so UAE servers serve the wider region with lower latency, even as organizations stand up country‑specific clusters where laws require. Many enterprises therefore adopt hybrid regional topologies: a UAE origin for GCC‑wide proximity and shared workloads, plus in‑country nodes where sectoral laws demand.
Local Infrastructure Has Become Table Stakes
Data sovereignty and user experience are now board‑level issues in the Gulf. The shortest, safest path to both is to run your origin in the UAE—within the jurisdiction that governs your customers and close enough to render the network invisible. With e‑commerce growth, AI‑heavy applications, and payments modernization all accelerating, the performance and compliance dividend from UAE hosting compounds year over year.
The strategic calculus is simple: if your revenue, risk, or reputation depends on speed and lawful processing in the GCC, a UAE dedicated server is no longer optional. It’s the foundation for the services your users already expect.
Deploy a UAE dedicated server
Place your workloads in Fujairah for low latency, local compliance, and carrier‑dense connectivity. Choose from ready configurations and 1–40 Gbps ports, backed by 24/7 support.
Get expert support with your services
Blog
Dedicated Servers Powering Real-Time Web3 Gaming Worlds
The vision for Web3 games is shifting from simple collectibles to persistent, living worlds where thousands of people can play together in real time. Nonetheless, it has already become quite visible in terms of demand by the activity of the blockchain. Today, blockchain games account for about 28% of Web3 dApp users, with roughly 2.8 million daily unique active wallets (dUAW) and the leading gaming chains now seeing millions of daily users. Ronin averaged ~1.9M dUAW in Q2, with Polygon at ~1.5M and NEAR at ~1.0M.
Although these are Web3‑specific metrics, they indicate the same concurrency ceiling that mainstream gaming has demonstrated. The Otherside tech demo at Yuga labs had filled the simulated space (not a screen of shards) with 7,200 people using a special custom-built multiple servers architecture as a 3D environment. Culturally, Fortnite’s Travis Scott event drew 12.3 million concurrent participants, showing that real‑time virtual spectacle scales with infrastructure.
So, what does that imply for infrastructure? Future Web3 worlds must prioritize latency, concurrency, and data distribution, and on‑chain features must not slow the gameplay loop. This is where dedicated servers—single‑tenant machines deployed in the right regions—do the heavy lifting.
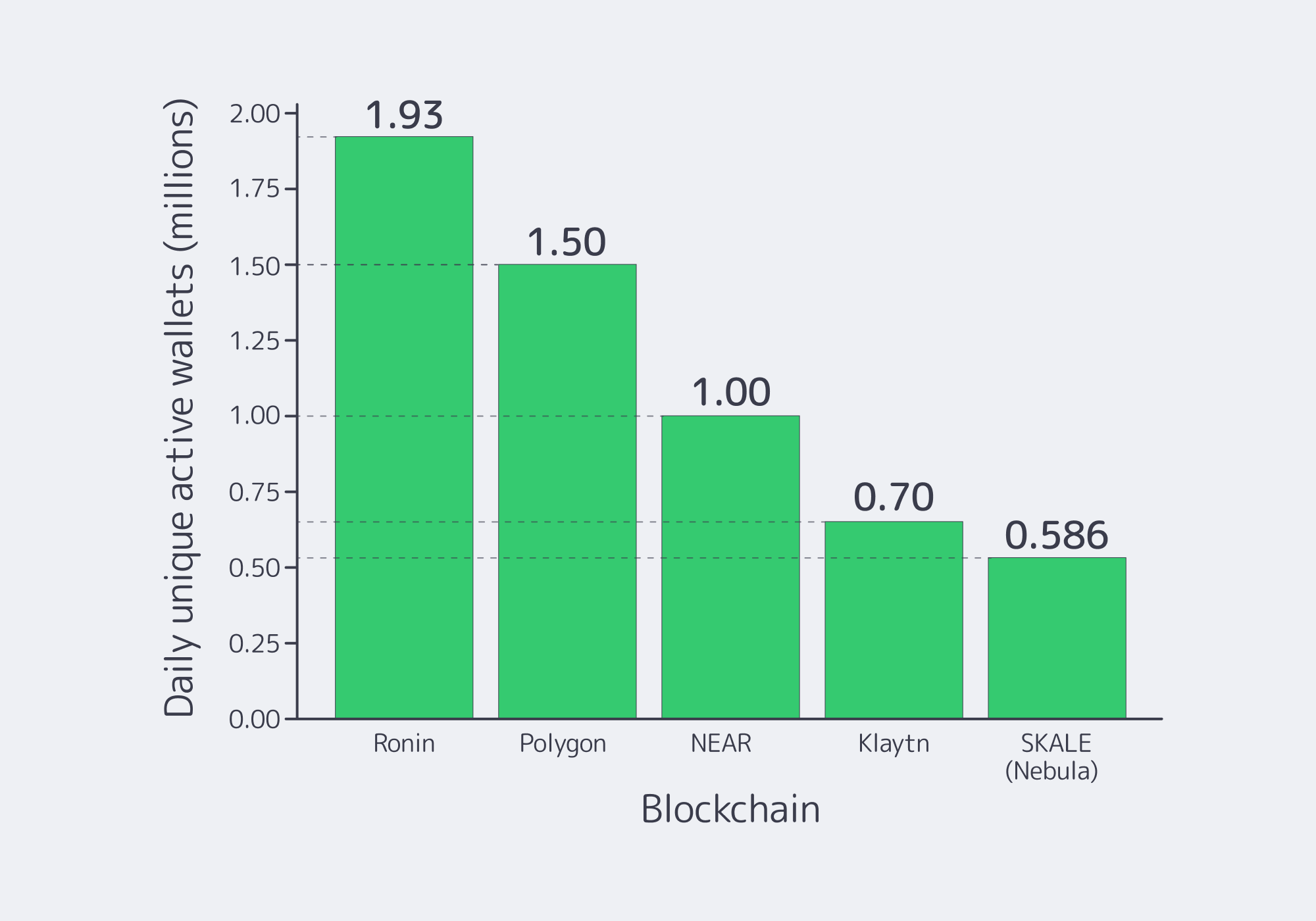
Best gaming blockchains by unique daily active wallets (Q2 2024). Source: DappRadar.
What Infrastructure Challenges Do Web3 Games Need to Solve?
Concurrency at event scale. Live metaverse events—concerts, tournaments, open‑world festivals—can drive spikes from thousands to tens of thousands of participants in a single space. The simulation and networking need to scale across many cores and machines without degrading the authoritative consistency of the world. The prototype signal is the Otherside demo: the team demonstrated 7,200+ users in one world.
Ultra‑low latency. Life and death are every millisecond in immersive play (VR, specifically). In immersive play (especially VR), milliseconds matter. Players begin to notice latency around 50 ms, and performance degrades through the 50–100 ms range; for XR, ~20 ms motion‑to‑photon is a comfort target, with sub‑15 ms enabling step‑changes in streamed VR quality. Achieving these budgets globally requires placing servers close to players and minimizing network hops.
Global reach and edge distribution. A single event of a metaverse can attract bidders or players across Los Angeles, London, Lagos and Singapore, simultaneously. Local ingress, intelligent routing (anycast/DNS) and edge caching are required such that each of them denotes a local origin, regions are synchronized.
Throughput & content gravity. These worlds move heavy data—3D assets, voice, and real‑time state updates—so origin bandwidth must absorb bursts (5–10× normal load) while the CDN keeps assets near users.
Frictionless on‑chain integration. Users expect NFT mints, trades, and in‑game ownership updates to feel instant, so the backend should decouple gameplay from settlement and rely on reliable full‑node/RPC infrastructure to cut request latency.
Why Choose Dedicated Servers for Web3 Gaming Now?
Because single tenant machines deliver predictable performance when it matters the most, i.e. live performances, region openings and market surges, and because they also give you total control over the ops interface.
Exclusive services, equal tick rates. With the availability of its own CPUs, RAM and NVMe, it does not have a noisy neighbor to steal simulation and blockchain indexing processes. This reduces jitter and causes ticks of the authoritative servers to be stable where there are thousands of connections.
High‑throughput networking and peering. Melbicom offers ports up to 200 Gbps per server and a backbone connected to 20+ transit providers and 25+ IXPs.
Global footprint to cut RTT. Melbicom boasts of 20+ Tier III/IV EU/US/Asia data centers and co-locates a CDN with 55+ PoPs providing you the power to bring simulation to the players and push assets to the edge.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Provisioning scale and speed. Pre‑warm for mints, season resets, or in‑game concerts: Melbicom maintains 1,300+ ready‑to‑go configurations with 2‑hour activation time.
Endpoint stability & network control. Teams can use BGP sessions to implement BYOIP and anycast/failover so RPC, matchmaking, and ingress IPs remain stable during maintenance and scaling.
24/7 support when minutes matter. Replacement of Hardware, rack and stack, and troubleshooting 24/7.
Bottom line: Dedicated servers give Web3 studios low latency, high concurrency, and tight on‑chain integration under full operational control.
Mapping Dedicated Servers to Real‑Time Web3 Requirements
| Requirement | Why it matters now | Dedicated server solutions |
|---|---|---|
| Ultra‑low latency | Games with ultra low latency are possible with about 50ms latency; VR comfort is about 20ms and sub-15ms gives jumps in the quality of streamed VR. | Regional and wide peering placement of multi DCs minimizes paths and fast NVMe and high clock CPUs is the configuration that makes server work stay within milliseconds range. |
| High concurrency | Virtual‑world events can involve thousands (and sometimes tens of thousands) of users in a single space; infrastructure must scale horizontally without tick collapse. | Deploy identical server pools per location; shard/partition state and distribute simulation across multi‑core servers behind load balancers. |
| On‑chain integration | Gameplay NNT state is to be instantaneous on block confirmation. | Gameplay state should feel instantaneous; run your own full nodes on dedicated machines for low‑latency reads/writes, and expose private RPC pools behind stable IPs (BGP/BYOIP) to prevent shared‑endpoint congestion. |
| Throughput & asset delivery | 3D deliveries, voice, telemetry and patches spike the origin links. | Absorb bursts with 1–200 Gbps ports, and serve redundant edge-cached content across 55+ CDN PoP locations. |
| Reliability | Reliability Trust is brought about by reliable economies of players. | Tier III/IV facilities and single‑tenant isolation reduce failure domains; multi‑region redundancy is straightforward globally. |
How Should You Architect Real‑Time Metaverse Worlds?
Place regions deliberately and push latency‑sensitive work to the edge. Use global DNS/anycast to route players to the nearest region, then synchronize regions over private inter‑DC links as needed. This Web3 hosting infrastructure of Melbicom is not supposed to fail in what it is 21 DCs and edge heavy CDN.
Decompose the backend. Split the game server, which contains matchmaking, profile/inventory, blockchain I/O, etc to allow each tier to scale up (and down) independently. Stateless API can be duplicated with ease, but stateful elements (simulation, databases) must be distributed among a cluster and without care.
Run your blockchain layer locally. Deploy full/archival nodes (and indexers) on dedicated servers with NVMe and high‑bandwidth ports; front them with load‑balanced private RPC to reduce timeouts and keep latency predictable.
Turn the CDN into a force multiplier. Keep origins lean and let the CDN serve textures, snapshots, metadata, patches, and UGC while origins handle simulation and real‑time APIs.
Instrument like an exchange. Capture server tick timing, queue depths, p95/p99 latencies, and mempool/RPC health in real time. This is where “real‑time metaverse infrastructure” intersects with ops: anomaly detection and predictive scaling (including AI‑assisted) help you add capacity before users feel pain.
Blockchain game hosting: patterns that work now
- To address inventory / ownership queries, local region replicas keep read replicas.
- Settle on‑chain asynchronously; provide an optimistic UX with background confirmation.
- Not only it utilizes multi chain RPC pools, it also pins IPs on BGP on the same client endpoint to minimize churn on whitelisting.
Real‑time metaverse infrastructure: edge and AI
- Edge placement helps meet ~20 ms XR comfort targets by trimming round‑trip time.
- AI assisted operations can inspect the telemetry and find p95s on the upwards trend, triage traffic (utilizing resources more effectively) by region or automatically scale up chat/voice/services before a live event exceeds a soft threshold.
Key Takeaways for Technical Leaders
- Make latency the first metric. Aim for <50 ms for mainstream play and ~20 ms for XR; place servers locally and minimize cross‑ocean paths.
- Plan for event‑level concurrency. Expect thousands in single spaces (and millions platform‑wide) and architect horizontal scale with load‑shedding and back‑pressure.
- Decouple gameplay from settlement. Run your own nodes to keep RPC latency flat and resilient, and queue/reconcile on‑chain actions.
- Exploit bandwidth + CDN. Give origins 10–200 Gbps headroom and let a 55+ PoP CDN handle asset gravity.
- Control the network. Endpoints scaling and maintenance by BGP/BYOIP; a feasible viable tool of accountability and reliability.
- Provision fast. Melbicom provides over 1,300 ready‑to‑go server configurations with 2‑hour activation.
Where Should Teams Build Next?
The short term aspect of Web3 games as its name suggests is larger shared space, reduced latency loops and larger on-chain state of being that demand low latency regional compute that is well coupled with high throughput networking and predictable RPC. Dedicated servers are the most direct path to that outcome. They provide network control that shared environments can’t match. DappRadar’s usage curves and the concurrency of flagship events tell the same story: scale is here; now the infrastructure must match it.
Melbicom’s approach is to make that foundation turnkey: place authoritative servers close to your audience; front assets with a global CDN; keep on‑chain calls local and stable; and scale horizontally in hours, not weeks.
Launch low‑latency Web3 infrastructure
Get dedicated servers, global CDN, and stable BGP endpoints with rapid provisioning to power real‑time Web3 games and metaverse events.
Get expert support with your services
Blog

CDN Edge + Dedicated Server Origin: Speeding Up Brazil & South America
South American audiences are impatient with slow‑loading content, and distant origins mean time‑to‑first‑byte (TTFB) and rebuffering both hinge on physical distance, while routing complicates matters and can result in poor engagement and loss of revenue. Fortunately, deploying CDN edge PoPs close to the region’s largest audience hubs, such as Buenos Aires, Santiago, Bogotá, and pairing them with a Brazil‑based origin shield on a local dedicated server can be a good workaround. If approached correctly, TTFB can drop from triple digits to tens of milliseconds, and rebuffer spikes are a non-issue.
Host in LATAM— Reserve servers in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
Why Distance Still Dominates Streaming Quality in South America
Despite huge numbers of users, most streams for those based in Brazil or Argentina originate from the U.S. East Coast. Hopping that distance adds on average ≈120–130 ms to the round‑trip time (São Paulo `sa‑east‑1` ↔ N. Virginia `us‑east‑1`, median inter‑region RTT), a figure that excludes any server processing or application work. Neighboring South American capitals, on the other hand, are far closer in network terms and see considerably reduced latency; São Paulo↔Buenos Aires pings cluster around ~29 ms.
Mobile QoE datasets highlight where latency is an issue affecting users. Chile’s latency is pegged at ~52 ms, which is too high considering that Singapore has been measured near ~30.7 ms, and that figure is considered a lower‑bound proxy for what “excellent” looks like on well‑peered networks.
TTFB is higher, the higher the latency, which can significantly delay startup, and modern viewers expect seamless streams. Research tells us that when a startup delay exceeds ~2 s, global abandonment rises by 5 or 6% per additional second. This means that by the time you reach the 10-second mark, nearly 46% have given up. The only solution is to keep that first byte local.
Changing the Game with a CDN Strategy

Historically, the blueprint was to combine a Latin America PoP with a distant origin, which was fine when the web was mostly images and pages, but that blueprint falls short with modern demands such as 4K live. Now, multi‑PoP coverage across the population centers is favored to ensure things start and stay local. This pattern can be deployed effortlessly with Melbicom as we have an extensive CDN that already covers Buenos Aires, São Paulo, Santiago, Bogotá, Mexico, Lima, and 50+ other global PoPs, guaranteeing you a nearby edge for hot segments and eliminating the latency of constantly traversing undersea circuits.
An overview of latency scenarios
| Delivery scenario | Typical RTT | Performance impact |
|---|---|---|
| Origin in North America, user in South America | ~120–130 ms | High TTFB; higher rebuffer risk over long paths. |
| Regional origin in Brazil (e.g., São Paulo) | ~30–50 ms (in‑region) | ~3× faster round trips; startup and seeks feel immediate. |
| Local in‑country edge cache (e.g., Buenos Aires PoP) | ~5–30 ms | Near‑instant TTFB; rebuffers suppressed by short refill times. |
Edge Caching Paired with a São Paulo Origin Shield on a Local Dedicated Server
While hits can be handled with edge caching, a fast origin is still needed for misses and cache fills. Therefore, an origin shield should be placed in São Paulo on a local dedicated server to keep that “fill traffic” within South America’s fiber rather than hair‑pinning to North America. This winning combo has the following material benefits:
- Lower miss penalty. The shorter path fetching from an edge in Santiago or Buenos Aires (30–50 ms) means snappier service when compared to intercontinental RTT paths (~120 ms), even at first glance.
- Thundering herds shielding. With a designated origin shield in Brazil, you coalesce duplicate misses from multiple edges.
- Spike Headroom. You can also saturate the edge tier with a dedicated origin sized with 40/100/200 Gbps, keeping origins free during major events.
All of this comes built in: no public cloud region required, only a well-connected, high-bandwidth dedicated origin in São Paulo with strong peering to the edge.
Which Protocol and Media Optimizations Actually Make a Difference?
TLS and HTTP versions
Encrypted streams require regular handshakes that add time, and corners can’t be cut when it comes to security, but the trip can. TLS 1.3 has a noticeably lower setup time at the edge when compared directly to TLS 1.2, reducing the handshake to one RTT (with 0‑RTT resumption for repeat connections). The handshake cost is mere tens of milliseconds if you terminate TLS at in‑region edges such as São Paulo or Bogotá. HTTP/2 remains a staple, but loss recovery can be improved with HTTP/3/QUIC. Essentially, you want your protocol mix for a CDN in Brazil to be TLS 1.3 everywhere; H2/H3 at all LATAM PoPs by default.
Image and video: Optimizing at the edge
Images: To make the most of the latency wins that are associated with using a Brazilian CDN network, convert images to WebP/AVIF wherever supported, resize for specific devices, and apply Brotli for text and manifests.
Video: keep popular renditions warm by caching HLS/DASH segments at edges and regionalize packaging/transcoding by creating and holding bitrate ladders near São Paulo if feasible. That way, you can avoid hauling mezzanine assets, cutting down first‑segment delay, improving ABR stability at higher sustained bitrates, and lowering rebuffers.
Route packets regionally
If peering is sparse, South American traffic can sometimes route wildly through Miami, so an ideal CDN provider in Brazil must:
- Keep flows local. Peer at IX.br (São Paulo) and local IXPs in Buenos Aires, Santiago, Bogotá, Lima, and Mexico City.
- Have regional parents to handle cache misses locally: Bogotá → São Paulo shield.
- Steer with telemetry demands as navigation: (RTT, loss, 95th‑percentile TTFB). For example, should a transient loss be seen between Chile and Brazil, a warm Buenos Aires cache should be able to take over.
The bottom line is to keep delivery short by using predictable paths that keep TTFB and loss‑triggered bitrate downshifts low.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
An Ideal Rollout Plan
- Map your audience density: Evaluate viewers and growth by metros, and remember most lists should include São Paulo, Mexico City, Buenos Aires, Bogotá, Santiago, Lima.
- Start with a regional origin shield in Brazil: With a dedicated origin in/near São Paulo using SSD/NVMe and 40–200 Gbps headroom, you can coalesce misses and serve edges over shorter routes.
- Place edges local to users: Ensure Buenos Aires, São Paulo, Santiago, Bogotá, Mexico City, Lima are on‑net and healthy.
- Use TLS 1.3 + H2/H3 everywhere: Terminate TLS at the nearest PoP, and leverage session resumption to improve repeat starts.
- Optimize media for the edge: Format images by converting and resizing, aggressively cache ABR segments, and keep hot titles pre‑warmed.
- Pin routes regional: Peering and backhaul shouldn’t leave LATAM for LATAM viewers, so build a cache‑parent hierarchy for edges with a São Paulo shield.
- Instrument and iterate: Country‑level TTFB and rebuffer ratio need analyzing; if a market shows >80–100 ms TTFB or spikes in rebuffers, you may need to add capacity or bring new PoPs online.
- Forecast capacity: To make sure live events don’t stress your shields, size them adequately. Push tens of Gbps per origin and fan out through edges.
Reducing Rebuffers with CDN and Brazil Origin Shields

Combining a CDN and a dedicated server origin shield attacks every contributor to end‑to‑end stalling in the following ways:
- First byte times: Terminating TLS at in‑country PoPs prevents the need to cross any oceans at setup, and handshake times can be reduced to negligible with 1‑RTT TLS 1.3.
- Segment fetches: Keeping ABR player requests at the edges significantly lowers segment fetch round-trip times.
- Miss penalty: Having a shield in São Paulo keeps fill latency caused by cache miss occurrences in the tens of milliseconds, not ~120+ ms.
Addressing all of the above translates to higher stable bitrates, faster seeks, and significantly lower rebuffering, improving quality in ways that QoE data shows correlate with longer session length and better LTV.
Where in Broader Roadmaps Should a CDN with São Paulo & Other PoPs Sit?
The demand in Latin America is clear, and its video streaming market CAGR is projected to rise by 21.7% before 2030. With expanding audiences come higher expectations when it comes to quality, so it is vital to plan resiliently:
- Serve Brazil and neighbors locally first (edge + São Paulo shield).
- Expand edges to secondary metros as country‑level TTFB and rebuffer telemetry dictate.
- Use in‑region packagers/transcoders to reduce cold‑start penalties on hot titles.
The CDN service in Brazil is maturing, and once it goes from a “first edge” to a “mesh of edges,” fewer cold starts are a given. Each marginal PoP will mean steadier ABR and less variance under load.
Why This “Edge + Origin” Design Wins in South America

Edge nodes where people actually live—and an origin shield in Brazil that keeps traffic in‑region—directly reduce first‑byte delay and the miss penalties that drive buffering. The approach also lowers long‑haul exposure, shrinks cost variance on undersea routes, and simplifies failover: if a national route degrades, a nearby LATAM PoP can serve the same cached segments while the shield refreshes over short paths. Most importantly, the telemetry tends to agree with user sentiment: the closer the content, the higher the average bitrate and the fewer rebuffers, which means longer sessions and better retention.
Melbicom can help you do just that as our CDN already places PoPs in Buenos Aires, São Paulo, Santiago, Bogotá, Mexico City, and Lima. Origins with dedicated servers in Brazil/South America are on the horizon, so you will be first in line, pairing that capacity with the existing CDN footprint for maximum offload and minimum TTFB.
We offer infrastructure freedom—dedicated servers in 21 Tier III/IV data centers, high-bandwidth options up to 200 Gbps per server, and fully custom hardware configurations. You get deployment freedom (spin up what you want, where you need it), configuration freedom (tailor hardware and network scale), operational freedom (single-tenant, no lock-in), and experience freedom (direct control, simple onboarding, 24/7 support).
Be first to host in Brazil with Melbicom
Explore our current dedicated options (servers and data centers) and edge footprint (CDN), then share your traffic volumes and exact technical specs. We’ll shape a tailored origin-plus-edge offer as our Brazil capacity comes online—so you can be among the first to host in Brazil on special terms.
Get expert support with your services
Blog
High-Performance Servers for Crypto Exchanges and Trading Platforms
Milliseconds and credibility determine the life or death of cryptocurrency exchanges. Matching engines need to respond to events almost in real time, APIs must broadcast massive quantities of market data, and the system must withstand demand peaks while staying online. It is not just a best‑effort web workload; it is an ever‑running financial system. Here, the most reliable way to achieve low‑latency execution, sustained high throughput, and high uptime is to use high‑performance servers, which also provide the operational control required to meet emerging security and compliance demands.
The size of the market is the reason why the bar continues to go up. CoinGecko’s annual report shows that global crypto trading volume in 2023 was $36.6 trillion, a strong reminder that demand is not only huge but constant. And the expectations of performance resemble traditional finance. Industry guidance for digital‑asset venues focuses on microseconds‑to‑low‑milliseconds tick‑to‑trade tolerances (from price tick to order fill), and fairness demands tight dispersion around those figures.
Best Servers for Crypto Exchanges— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
What Does Low‑Latency Really Mean for Crypto Trading?
Low latency isn’t a single number; it’s end‑to‑end from the user edge to the matching engine and back, with the distribution (p50/p95/p99) mattering as much as the mean. Two imperatives stand out:
Geographical distance and clean routing. The geography and the quality of paths dominate the round trip times. Placing exchange entry points and caching of non critical assets in the edge can reduce tens of milliseconds to distant users. As illustrated in the plot below: the spread of entry points and content has the benefit of decreasing slope and variance of RTT with distance.

Illustrative latency vs. distance for exchange users (non‑measured model).
Compute and network stacks with low jitter. Each microburst of garbage collection, each context switch from a noisy neighbor, and each network‑path buffer burst adds dispersion that traders perceive as slippage. Industry guidance for digital‑asset platforms addresses this fair‑access constraint: HFT paths run in microseconds, broader flows in single‑digit milliseconds, and variance matters as much as the mean.
Low‑latency trading servers. Fast CPU cores, local NVMe and predictable NIC interrupts on dedicated servers provide a consistent time-of-program execution, unlike a hypervisor. Melbicom’s regional placement, together with anycast or fast‑failover BGP, allows participants to keep users as close to ingress as possible while maintaining routing policy.
Real‑time market data feeds. Low latency entails line-rate fans-out as well. Web‑based market‑data services must send order‑book deltas to millions of sockets on demand. Headroom is sufficient even with volatility spikes with 10/25/40/100/200Gbps server ports and multi-provider transit with Tier III/IV sites. The CDN PoPs should primarily carry static UI assets, snapshots, and historical files to bring bytes closer to users and offload origins.
How Do Dedicated Servers Handle Surging Trading Volumes?
Cryptocurrency activity does not increase gradually, but it comes with a bang. Traffic bursts of 5× can occur when token listings, liquidations, or macro headlines hit. Coinbase recorded an event where traffic increased fivefold in four minutes—faster than autoscaling—so error rates spiked briefly, offered here not as a history lesson but as a warning data point. The response of the design is multi-layered:
Provision of the peak, rather than the average. Publicly stated capacities for matching engines at major venues are on the order of ~1.4 million orders per second—an ambitious but useful engineering goal. This is achievable with dedicated servers that let teams tune cores, frequency, RAM, and NVMe layout for the hot path, without multi‑tenant interference.
Scale horizontally under load. They include stateless gateways, partitioned order books as well as stateless replicated market-data publishers, which distribute loads among nodes. Servers provide the predictable per‑node ceiling; orchestration provides the elasticity.
Keep bandwidth slack. Computing is less challenging than egress. Melbicom helps ensure message storms don’t back up queues with per‑server ports up to 200 Gbps.
Exchange matching engine hosting. The engine benefits from high clocks and cache‑resident data structures, low‑latency NICs, and predictable storage‑flush paths; specialized tuning (interrupt coalescing, user‑space networking stacks, CPU pinning) is possible because dedicated servers avoid the variability of shared hypervisors—an advantage when managing microseconds end to end.
Ensuring 24/7 Uptime in an Always-On Market Environment

Crypto doesn’t close. Financial outages are costly in the millions of dollars per hour; an industry investigation of trading floor downtimes puts the number at about $9.33 million/hour, which highlights the importance of the platforms which earn per trade. There are 3 pillars of uptime discipline, namely:
- Facility resilience. Tier III/IV hosting where power/cooling is redundant and carrier type is not limited to a single carrier minimizes the risk of hardware or utility servicing interrupting the service. According to the listing provided in the Melbicom estate, Tier III/IV locations such as Amsterdam, Los Angeles, Singapore, Tokyo and so on are combined with on-site engineer to swap components.
- Duplications on functions and lack of points of failure. Active‑active load balancers, clustered gateways, hot‑standby matching engines, and geo‑redundant databases mean a single server failure is not noticeable to the user.
- Operational control. Such features as dedicated servers and 24/7 support allow continuing and running rolling upgrades, implementing kernel patches, and carrying out hardware upgrades without downtime.
Security & Compliance: What Defines a Secure Crypto Exchange Infrastructure?
Compliance is inseparable from performance and security posture. Single tenant servers are provided, which provide isolation, ownership of the OS/kernel, and controlled change, and this results in easier process of auditing and hardening:
Secure crypto exchange infrastructure. Dedicated servers avoid multi‑tenant hypervisors and enable strict host‑level controls: hardened baselines, minimized attack surface, hardware‑backed keystore/HSM policies, and full‑fidelity logging. BGP sessions (with BYOIP) enable stable addressing and anycast/fast‑failover ingress control, supporting deterministic routing and policy enforcement.
Finally, the certified processes and facilities facilitate compliance. Melbicom is audited against the ISO/IEC 27001:2013 standard, which governs an information security management system (ISMS). The foundation and the selection of the regions and data residency help the teams to document the controls to the regulators.
Architecture Patterns That Matter the Most

Modern architectures center on a plan that maximizes determinism and control.
Regional ingress + local bursts. Place gateways and partial services near users, while the authoritative matching engine runs in one or more core regions. UI and read‑heavy endpoints should be close to traders using Melbicom’s 21‑site footprint and 55+ CDN PoPs, while hot paths stay on tuned servers.
Data‑path separation. Individual market‑data publishers and internal risk engines are isolated so a burst in one plane does not choke another service.
Network‑level control. Use BGP‑based anycast and regional failover so source IPs remain stable during maintenance, and prefer short, reliable paths to common client geographies.
Challenges and how high‑performance dedicated servers answer them
| Exchange challenge | Impact if under‑engineered | Dedicated‑server answer |
|---|---|---|
| Uptime & maintenance | Lost fees and reputation; high-risk upgrade | Tier III/IV site, hot standby and rolling upgrades ensure trading remains online. |
| Low‑latency execution | Unfair dispersion, slippage, dissatisfied market makers | Regional placement, high clock CPU, deterministic single tenancy; small latency dispersion. |
| Security & compliance | High breach/audit risk | Single tenant isolation, OS-control and ISO/IEC 27001:2013 certification/basis. |
| Volume spikes & fan‑out | Queue surge, timeouts, crumbly data feeds | Horizontal clusters on predictable nodes; up to 200 Gbps per server of market‑data bursts; and fast capacity additions. |
What Capacity and Throughput Targets Should an Exchange Set?
The objectives are based on the product’s different combinations and the final users, but anything that can be consumed by a mass market is useful. Binance cites a matching‑engine ceiling of approximately 1.4 million orders per second, a useful target for optimizing the most critical paths. A pragmatic planning model:
- Size order intake for the peak number of concurrent sessions plus 20–40% headroom.
- Size matching so peak bursts clear with no tail buildup.
- Size market‑data egress for worst‑case deltas, not averages.
- Provision storage for write spikes and fast‑recovery snapshots.
Melbicom can add capacity quickly with 1,300+ ready configurations and ~2‑hour activation windows, allowing teams to provision for the spike rather than the average.
A Practical Deployment Checklist
- Pin your latency budget. The p50/p95/p99 change targets that would be used in order entry, matching and publication of market‑data. Bring users close to exchange entry points via regional ingress.
- Right‑size the engine. Faster clock CPU, cache books and local NVMe, preferable in case of logs/ snapshots in single tenant nodes.
- Design for the surge. Pre‑warm extra gateways and publishers for storm conditions, and size egress for those peaks. Target capacity above the mean.
- Separate planes. Separate order entry, matching, market‑data, and admin networks; no planes are shared.
- Engineer for failure. Use active‑active load balancers, hot‑standby engines, rack‑ and region‑level replication, and tested cutovers.
- Control your routes. The BGP session (BYOIP may need to be used) should utilize stable endpoint routes and anycast and use fast routing.
- Prove compliance. Obtain a mapping of controls to ISO/IEC immense stretches of 27001:2013 ISMS and have proof at a fresh place.
Conclusion: Dedicated Servers are the Backbone of Trustworthy Crypto Trading
Exchanges compete on speed, reliability, and stability. It demands infrastructure with low‑jitter latency, high sustained throughput, and measured resilience—not just in normal periods but in the exact minutes when markets are most volatile. The data justifies the investment: the size of the crypto volumes, the assumption that the execution routes will take only microseconds, the real price of the downtime, etc., all indicate the single-tenant level of performance and the control of the network on the network level.
Dedicated servers, acting upon a globally dispersed, professionally operated platform, fulfill those needs and create architectural freedom: decide regions, actualize hardware to workloads, push content to the edge, and have your routes. Thus, day in, day out, trading venues keep books fair, UIs responsive, and reputations intact.
Build a low‑latency crypto exchange
Provision tuned, single‑tenant hardware in key regions to cut jitter, handle volume spikes, and meet uptime targets for your trading platform.
Get expert support with your services
Blog

Brazil Dedicated Server Buying Guide: Performance & MSA
Brazil has a huge user base, and with today’s demands for latency‑sensitive apps, basing a dedicated server locally is no longer wishful thinking or a nice added bonus. In 2023, over 84% of the population was online, creating more traffic in the area than ever before and making São Paulo one of the world’s most active interconnection hubs. IX.br traffic peaks above 31 Tb/s, with São Paulo peaking above ~22 Tb/s; hosting in Brazil cuts round‑trip times versus North American backhaul options such as the Seabras‑1 route (~105 ms RTT between New York and São Paulo), and in‑country paths are lower still.
Host in LATAM— Reserve servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
Brazil Dedicated Server Configuration: Recommendations
When purchasing a Brazil‑based dedicated server, there are four main considerations—CPU/GPU, storage, network, and terms/upgrade path—each of which needs to be validated against price‑to‑performance, redundancy, and DDoS exposure risks to make a wise infrastructure investment.
Matching CPU class to workloads
Forget the brand and pick the CPU required for the job. In other words, analyze your needs and the strengths:
| CPU Type | Key Strengths | Ideal For |
|---|---|---|
| AMD EPYC | High core counts, strong throughput/watt, abundant PCIe lanes, and memory bandwidth. EPYC has been shown in independent reviews to lead multi‑threaded throughput at similar power envelopes. | Virtualization (VM density), high‑concurrency SaaS, analytics, and mixed microservices. |
| Intel Xeon | Competitive per‑core turbo, integrated accelerators (e.g., AMX/QuickAssist) that can outpace EPYC on select code paths when software takes advantage. | Latency‑sensitive or accelerator‑aware workloads such as real‑time APIs, certain inference, compression/crypto, etc. |
| AMD Ryzen | High clocks (≈4.5–5 GHz boosts) without breaking the bank, providing an impressive per‑thread snap on 8–16 cores. | Budget‑restricted game servers, small web/app nodes. Cases where single‑thread speed matters more than socket scale. |
CPU Guidance:
- If you have many containers/VMs to consolidate, EPYC’s cores/PCIe lanes often provide better overall VM density.
- If the stacks you operate with require Intel accelerators or the highest turbo, scope Xeon SKUs. Then use those blocks and verify the relevant code paths for efficiency.
- If your work is lightly-threaded and you need the cheapest dedicated server in Brazil, Ryzen might be an idea, but remember to inform yourself, because while fast, there are ECC/support trade‑offs.
Do GPUs change unit economics?
The short answer is yes. Lots of work processes are GPU‑amenable, such as training/inference, vision, transcoding, HPC, GIS rendering, and data pipelines in modern times assume GPU offload. A single GPU server is able to replace racks of CPU‑only nodes working on tasks in parallel, which cuts latency considerably and power per unit of work. However, if you have no GPU‑eligible jobs, the upfront cost is unnecessary and many with lower budgets skip it. The wise approach is to keep an upgrade path available for GPUs later—plan for additional power/cooling and available PCIe slots.
Storage tiers: NVMe vs. SATA vs. HDD
Hot data should be stored on NVMe as it speaks PCIe directly and doesn’t have the same bottlenecking issues that arise with SATA/AHCI. A quick glance at the manufacturer’s guidance shows a night and day difference with SATA around ~550 MB/s while PCIe 4×4 NVMe shows delivering ~7–8 GB/s, with IOPS in the low millions and protocol overhead measured in microseconds. Operating in microseconds makes databases, searches, queueing, and any log‑heavy microservices much more efficient. SATA SSD, or HDD, can be reserved for cold tiers and backups.
Port Speed: Do You Actually Need 1/10/100/200 Gbps?

Monthly sums don’t really help; instead, you should think in peaks and use the following as a baseline:
- 1 Gbps can adequately cope with moderate traffic and the control plane.
- 10 Gbps is the typical choice for serious origin workloads because it supports multi‑TB/day transfer and has the headroom needed for spikes.
- 100–200 Gbps is usually reserved for large streaming, high‑fanout APIs, and big file distribution, and is often required when a single origin seeds a CDN or large clusters.
Unmetered vs. metered: Although transit in Brazil is improving all the time, the prices at scale are aggressive. An unmetered fixed setup is preferable where traffic is harder to predict and bursts go hand in hand with your field; if not, overages can be a nasty surprise. If your traffic is steady, then committing to a metered server might be economical.
Quality routing: With São Paulo’s IX.br scale, exceptional local delivery is possible with the right peering from providers. Just be sure to validate by testing and checking IP, traceroutes, and ensure the design is apt for multi‑uplinks, as the IX.br system has dozens of nationwide IXPs and an aggregate peak above 31 Tb/s, with São Paulo being the largest.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
How to Map Price‑to‑Performance without Compromising Resilience
For a dedicated server hosted in Brazil, you need a sensible evaluation worksheet:
- CPU class vs. utilization: EPYC’s price/performance often wins when cores are >70% busy during normal hours, but if p99 latency is dominated by a few threads, prioritize top‑turbo Xeon or Ryzen and tune the scheduler.
- NVMe everywhere for UX: All databases, caches, search indexes, and write‑heavy services should be kept live on NVMe, and SATA/HDD should be reserved for archival object stores or long‑tail logs.
- Bandwidth that changes UX: If origins saturate at 60% or more at peak, then step up the port as well as the commit. To ensure continent‑wide reach, terminate your origin in São Paulo, push to the edge with Melbicom’s wide CDN reach that covers São Paulo, Buenos Aires, Santiago, Bogotá, Lima, etc.
- DDoS risk and coverage: Attacks are prevalent, and it is worth remembering that the largest H1 event (919 Gbps) landed in‑country. So investigate your chosen provider’s capacity, scrubbing options, and incident playbooks, whether or not your surfaces are DDoS‑prone.
Which Contract Terms Matter the Most?

Flexible MSA, monthly billing. When entering new territory, it’s best to avoid long lock‑ins and seek monthly terms with providers that can ensure simple change orders for upgrades.
Speed to capacity. Pick providers with API‑ and panel‑driven deployment so you don’t have to wait weeks for parts.
Scale‑up and scale‑out. Prioritize platforms that allow you to scale up easily—adding RAM/NVMe/GPU and uprating ports—and to manage scale‑out with consistent sibling nodes across regions. Both patterns can be handled by Melbicom with high‑bandwidth server lines and identical builds across regions without the need to re‑platform.
Why Local Presence in Brazil Changes Performance Math
The user base in Brazil is large and connections are in place, but intercontinental RTTs are physics‑bound, meaning an origin in São Paulo can remove ~100 ms compared to average U.S. round‑trips, which makes a difference for cart conversion, stream stability, game tickrates, and fraud or KYC API responsiveness.
The ideal playbook:
- For transactional APIs and low‑latency trading: Employ Xeon (high turbo) or high‑clock Ryzen, keep storage on NVMe, use a 10–40 Gbps port, and add a CDN for static assets; maintain a warm standby node.
- SaaS with many concurrent sessions: EPYC (cores/VM density); NVMe + generous RAM; 10–40 Gbps; CDN for assets; warm standby node.
- Streaming / file distribution: EPYC or Xeon; NVMe cache tier; 40–200 Gbps at origin; CDN mandatory; segment traffic to protect origin.
- ML inference/vision: Xeon with AMX or EPYC + discrete GPUs depending on stack; NVMe scratch; 10–40 Gbps; plan GPU swap/expansion.
Tip: If you’re weighing a cheap dedicated server in Brazil, ensure it still checks the boxes that affect UX the most: modern disks, a realistic port, and access to a South American CDN.
Key Takeaways You Can Act On
- Put servers where users are: Brazil’s dense interconnection (31 Tb/s+) and direct U.S. routes (~105 ms RTT) make local origin hosting the default choice for responsiveness.
- Match CPUs to code paths: EPYC for thread‑rich concurrency and PCIe fan‑out; Xeon/Ryzen for high‑clock responsiveness or accelerator‑aware stacks. Validate with your own profiles.
- Make NVMe non‑negotiable: SATA caps near ~550 MB/s while PCIe 4×4 NVMe reaches ~7–8 GB/s with dramatically higher IOPS — the difference users feel.
- Buy the port you need for peaks: Most origins should start at 10 Gbps; grow to 40/100/200 Gbps for heavy media or fan‑out.
- Assume DDoS exposure: Brazil’s share of regional attacks and the 919 Gbps event argue for in‑country capacity and clear mitigation paths.
- Keep terms agile: Monthly billing, fast stock, and no re‑platforming to scale are worth more than a one‑time discount.
Thinking About Hosting in Brazil with Us?

Melbicom can help you finalize this blueprint as we are opening priority access for teams preparing Brazil rollouts: tell us your traffic profiles, exact technical specifications (CPU/GPU preferences, NVMe tiers, port targets, redundancy/DDoS posture), and timelines, and we’ll shape a tailored offer and pre‑stage capacity via our network and South American CDN — with first‑wave placement when São Paulo dedicated servers go live. Contact us.
Why Melbicom
What sets Melbicom apart is infrastructure freedom. We operate our own network and deliver high‑bandwidth solutions globally, with custom hardware setups almost anywhere and an international, remote‑first team built for speed. In practice that means deployment freedom (run anything, anywhere, at any scale), configuration freedom (tune CPU/GPU, NVMe tiers, and ports to fit your workload), operational freedom (no shared tenancy or lock‑in), and experience freedom (clean onboarding and transparent control). Share your expected volumes and failure domains now; we’ll validate routes, right‑size ports, and lock in the upgrade path so day‑one in Brazil is smooth, predictable, and reversible.
Plan your Brazil dedicated server rollout
Tell us your CPU/GPU, NVMe, and port needs. We’ll validate routes, size capacity, and prepare São Paulo servers with CDN options and DDoS coverage.
Get expert support with your services
Blog

Secure & Low-Latency Infrastructure for DeFi Platforms
Stablecoin rails and decentralized exchanges have turned into always‑on, high‑throughput markets. In the past year alone, stablecoins processed more than $27.6 trillion of on‑chain transactions—a milestone that eclipsed card‑network volumes. In October, DEX volume set a record above $613B as market share shifted toward on‑chain execution. In this environment, infrastructure becomes strategy: milliseconds determine if liquidations trigger on time, arbitrage captures spread, and user trust holds through volatility.
This article focuses on the two levers that consistently move the needle for DeFi operators: ultra‑low latency and robust security. We’ll show how dedicated, high‑performance servers—deployed across geographically distributed locations and paired with hardware‑backed key protection—deliver that edge.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Why Does Ultra‑Low Latency Matter in DeFi?
Speed is an economic value. When slots or blocks tick quickly—Solana slots are ~400–600 ms—even modest network delays can mean missing a block window and the price that came with it. The same principle applies across L2s and parallelized chains whose finality targets are measured in sub‑seconds.
Three latency domains usually dominate:
- Mempool & propagation. If your transactions or oracle updates hit builders/validators after competitors’, your fill quality degrades. Private order flow paths and fast peers materially reduce that race (more on this below).
- User‑facing APIs. A few dozen extra ms. between a trader and your RPC/API endpoint can push them past a price move. For latency‑sensitive flows, in‑region endpoints and short network paths are the difference between taking and missing liquidity.
- Off‑chain components. Indexers, sequencers, matching engines, risk services—anything off‑chain behaves like a low‑jitter trading system. Here, exclusive access to CPUs, memory, and NICs matters. Public, shared endpoints routinely show p99 latencies in the 50–500 ms range, while dedicated pipelines land in the 5–50 ms band; colocation and private links push lower still.
Bottom line: every hop and every shared layer adds variance. Dedicated servers placed close to users and chain nodes, on clean network paths, cut that variance to size.
Designing Low‑Latency DeFi Hosting

The architecture is surprisingly consistent across high‑performing teams:
Geographically distributed nodes/servers. Place RPC, validators, indexers, and app backends in multiple strategic regions so users and services reach a nearby endpoint. This minimizes round‑trips and smooths block/gossip propagation. With Melbicom’s 21 Tier III/IV data centers on a 14+ Tbps backbone and 50+ CDN PoPs, teams place infrastructure precisely where latency is lowest and failover is clean. Melbicom offers 1–200 Gbps ports per server, which keeps spikes from queuing.
Direct, high‑quality connectivity. Keep routes short and stable. In practice that means peering and BGP sessions to hold constant IPs (useful for RPC/validator endpoints), and to steer traffic over better paths. Melbicom provides free BGP sessions on dedicated servers with BYOIP and community support so you can engineer for speed and consistency.
Edge acceleration where it helps. Wallet assets, ABIs, snapshots, and UI bundles shouldn’t traverse oceans on every request. Push reads to the edge via a 50+ PoP CDN, keep writes local, and right‑size origins to back hot regions.
Run your own nodes for critical paths. Public RPCs are convenient but multi‑tenant queues add jitter. Dedicated single‑tenant nodes eliminate shared contention and rate limits, unlocking deterministic fetch/submit times. Melbicom’s Web3 page details dedicated RPC for dApps and NVMe tiers for archival/full nodes with unmetered bandwidth—practical choices that shorten sync windows and keep p95 latency flat.
Hardening a Secure DeFi Platform Infrastructure
Performance without protection is a liability. Modern stacks are converging on two complementary controls:
1) Hardware‑backed key custody. Hardware Security Modules (HSMs) generate and store keys in tamper‑resistant hardware; keys never appear in server memory. Secure enclaves (confidential computing) restrict access to decrypted key material to attested code only—so even a root‑level OS compromise can’t exfiltrate secrets. This is now standard practice at institutional custody and increasingly common for DeFi admin/oracle keys. The effect is simple: keys stay out of reach, signatures remain valid, and governance or bridge operations become dramatically safer.
2) Private transaction paths to limit MEV exposure. Public mempools leak intent; searchers reorder and sandwich transactions. Private RPCs and relays route transactions straight to builders/validators, bypassing the public mempool and reducing front‑running risk. Wallets and dApps widely support these routes today. For sensitive flows—liquidations, large swaps, sequencer inputs—this is now table stakes.
Resilience is security, too. Fault‑tolerant DeFi platforms spread critical services across regions and vendors so no single facility or network interruption halts the system. Melbicom operates Tier III/IV facilities with 1–200 Gbps per‑server networking across EU/US/Asia, plus 24/7 support and fast hardware replacement—practical ingredients for active‑active designs and rolling upgrades without downtime.
Dedicated Servers for DeFi Performance: Where Does the Edge Come From?

Exclusive resources, predictable timing. Dedicated servers remove noisy‑neighbor effects. CPU cycles, RAM bandwidth, NVMe IOPS, and NIC queues are yours alone—critical for consistent block ingestion, indexing, and order handling. Shared instances might average fine; tail latency is what breaks liquidations and market‑data pipelines.
Bandwidth and topology you can engineer. With ports up to 200 Gbps and guaranteed throughput, you scale horizontally without egress shocks or surprise throttles. Add BGP with BYOIP to keep endpoint IPs stable through maintenance and region changes.
Full‑stack control. You choose OS hardening, kernel parameters, I/O schedulers, and monitoring. You decide how your enclaves and HSMs integrate. You pin inter‑DC replication on private links. That control translates into faster incident response and easier audits.
Global footprint, local latency. Melbicom lists 21 data centers across key hubs with a 14+ Tbps backbone and 50+ CDN PoPs, so you can put validators, RPC, and app backends near users and chain peers rather than pulling everything through a single region.
DeFi infrastructure challenges and solutions
| DeFi infrastructure challenge | Risk if unaddressed | Dedicated‑server solution |
|---|---|---|
| High network latency to users/validators | Slippage, missed blocks; competitors see/act first | Geo‑distributed nodes/servers with BGP‑steered routing and 1–200 Gbps ports reduce hops and queuing. |
| Shared/public RPC bottlenecks | Rate limits, multi‑tenant p99 spikes | Single‑tenant RPC and local full nodes on exclusive hardware; deterministic throughput. |
| Single‑region dependency | Regional failure = global outage | Active‑active regions in Tier III/IV DCs with fast failover and steady IPs via BGP/BYOIP. |
| Private key exposure | Irreversible loss of funds/governance | HSMs + secure enclaves isolate keys and signing; enclaves run attested code only. |
| MEV front‑running | Worse execution; failed transactions | Private RPC/relays send orderflow directly to builders, bypassing the public mempool. |
What Should Teams Actually Build?
- Prioritize “nearby” everything. Place RPC/validators/indexers in the same region as your users and counterparties; keep propagation paths short.
- Adopt private orderflow paths. Route sensitive transactions through private RPC/relays to curb MEV exposure and reduce revert waste.
- Use dedicated servers for deterministic performance. Aim for 5–50 ms end‑to‑end service targets on critical paths; eliminate multi‑tenant p99 tails.
- Make hardware do security work. Store keys in HSMs; run signers in secure enclaves; restrict management to isolated networks.
- Engineer for failure. Active‑active multi‑region, BGP for sticky IPs, private inter‑DC links for state replication, and 24/7 ops so failovers are boring.
Why This All Matters Right Now

Block production windows are short—hundreds of milliseconds on some chains—and on‑chain volume is rising. In practical terms, latency and security are revenue, not line items. Teams that deploy geographically distributed nodes/servers on dedicated hardware, and that seal keys in hardware, consistently ship faster execution and fewer surprises. The best DeFi platforms today feel instant and stay online through chaos because their infrastructure is designed to do exactly that.
For operators, the path is clear: own the critical path—where your latency and trust originate. That means single‑tenant servers close to users and chain peers, private orderflow routes, and hardware‑backed key protection.
Deploy low‑latency DeFi hosting
Launch dedicated servers with 1–200 Gbps ports, BGP sessions, and Tier III/IV data centers to cut latency and boost resilience for nodes, RPC, and backends.
Get expert support with your services
Blog

How Dedicated Servers Power Seamless Live Streaming
Live streaming at scale is ruthless on infrastructure. Millions of viewers can arrive within seconds; every additional millisecond of delay compounds into startup lag, buffer underruns, and churn. Decades of QoE research show the audience has little patience: abandonment begins when startup delay exceeds ~2 seconds, rising ~5.8% for each additional second—a brutal slope for real‑time broadcasts.
This piece examines how dedicated server infrastructure delivers seamless live streaming for events and real‑time broadcasts: why single‑tenant performance matters under concurrency stress, how edge computing and a CDN pull content closer to viewers to minimize lag, and which failover patterns keep streams online through faults.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Why Is “Seamless” Live Streaming So Hard?
Concurrency and bandwidth. Peaks are spiky and simultaneous. If 10,000 viewers watch a 4K ladder at ~20 Mbps, origin egress must sustain ~200 Gbps instantly. At a million viewers, that arithmetic hits tens of Tbps—well beyond any single facility’s comfort zone. And the payloads are heavy: Netflix’s own guidance pegs 4K at ~7 GB per hour per viewer—petabytes evaporate quickly at audience scale.
Physics and protocol trade‑offs. The farther a viewer is from origin, the larger the buffer needed to ride out jitter. Traditional HLS/DASH favored stability over speed; newer modes (LL‑HLS/LL‑DASH) trade smaller chunks and partial segment delivery for 2–5 second end‑to‑end delays—only if the network and servers keep up.
Viewer intolerance for interruptions. The research is unambiguous: seconds of startup or rebuffering drive measurable abandonment and revenue loss. That’s why platforms that win on live events are the ones that engineer for steady latency under unpredictable demand, not just average throughput.
What Makes a Live Streaming Dedicated Server the Right Foundation?
Dedicated servers give streaming teams exclusive, predictable performance—no hypervisor jitter, no “noisy neighbors,” and full control of CPU, RAM, NIC queues, storage layout, and kernel networking. When tuned for live media (fast NVMe for segments and manifests; large socket buffers; modern congestion control), dedicated hosts push line‑rate 10/40/100+ Gbps consistently, which is the difference between a stable 2‑sec ladder and a stuttering one at peak.
Melbicom’s platform illustrates the point: 1,300+ ready‑to‑go configurations across 21 global data centers (Tier III/IV) enable precise right‑sizing and regional placement; per‑server bandwidth options reach up to 200 Gbps in select sites; and free 24/7 support plus 4‑hour component replacement keep incidents from turning into outages.
Cost and predictability also tilt in favor of dedicated as you scale: flat‑priced ports (rather than per‑GB egress) and the ability to drive them at capacity let teams provision for the peak rather than the median—critical when a broadcast goes viral.
Comparison at a glance
| Key factor | Dedicated server infrastructure for streaming | Cloud VM infrastructure for streaming |
|---|---|---|
| Performance under load | Exclusive hardware; stable CPU/I/O and line‑rate 10–200 Gbps per server when available. | Multi‑tenant variability; hypervisor overhead can add jitter under peak. |
| Latency & routing | Full control of stack, peering, and placement; regions chosen to minimize RTT to viewers. | Less control over routing; regions may not align with audience clusters. |
| Customization | Tune OS, NICs, storage, and encoders; add GPUs for real‑time transcode. | Constrained instance shapes; less low‑level tuning; GPU/storage premiums. |
Why it matters: LL‑HLS/LL‑DASH only hold low single‑digit‑second latency at scale when origin and mid‑tier nodes can serve small segments immediately and the upstream routes stay clean. That favors single‑tenant boxes on fast ports in the right metros.
How Does Edge Computing Cut Latency?
The single most reliable way to reduce live delay and buffering is to shorten the distance between content and viewer. A CDN/edge layer fetches each segment once from origin, then serves it from nearby points of presence—collapsing round‑trip time and stabilizing last‑mile variability. Industry analyses attribute step‑function latency gains to pushing compute and cache deeper into the network; the architectural goal is simple: keep media within a handful of hops of the player.
Melbicom’s CDN spans 55+ PoPs across 36 countries and 6 continents, with HTTP/2, TLS 1.3, and video delivery features (HLS/DASH). In practice, that lets teams park origins on dedicated hosts in a few strategic metros and let the edge take the fan‑out load—especially during flash crowds.
Low‑latency protocols amplify the benefit. LL‑HLS relies on small parts and chunked transfer; when those parts originate from an edge 15–30 ms away instead of a core 150–300 ms away, live delay stays in budget and rebuffer risk collapses. Apple’s LL‑HLS design notes and independent guidance consistently place live latency targets around 2–5 seconds for scalable HTTP‑based delivery—achievable only with strong edge proximity.
Where should the best streaming server sit?
- Place dedicated origins in the same continent (often the same country) as your largest live cohorts; use secondary origins where you see sustained daily concurrency.
- Put a CDN/edge in front; prefer footprints with PoPs near your audience (and peering with their ISPs).
- Keep origins lean: hot segments on NVMe; manifest/segment I/O localized; avoid mixing heavy analytics or ad‑decision engines on the same hosts.
Melbicom’s model—21 origin locations and a 55+ PoP CDN—is designed for that split‑brain: origins where compute belongs, distribution where distance matters.
Keeping Streams Online When Things Break
No single point of failure—that’s the operational mantra for live. The core patterns:
- Multi‑origin, multi‑region. Two or more independent origin clusters pull the same live feed and package segments concurrently. A CDN config lists both; on health‑check failure, fetches shift automatically.
- Smart routing. DNS steering or BGP anycast (where appropriate) places viewers at the nearest healthy entry point; a failed site simply stops announcing and traffic drains to the next‑closest.
- Encoder redundancy. Dual ingest pipelines (primary/backup) keep the feed flowing even if one encoder or network path fails.
- Rapid repair and human cover. When a host does fail, 4‑hour component replacement and 24/7 on‑call engineers mean the cluster’s redundancy window is short—and viewers never notice. Melbicom documents both practices for streaming workloads.
Testing matters: schedule controlled “chaos” during low‑stakes windows—kill an origin, yank a transit, drop an encoder—until failover is boring. That’s the only path to confidence on show day.
Low Latency and Stability During Live Events
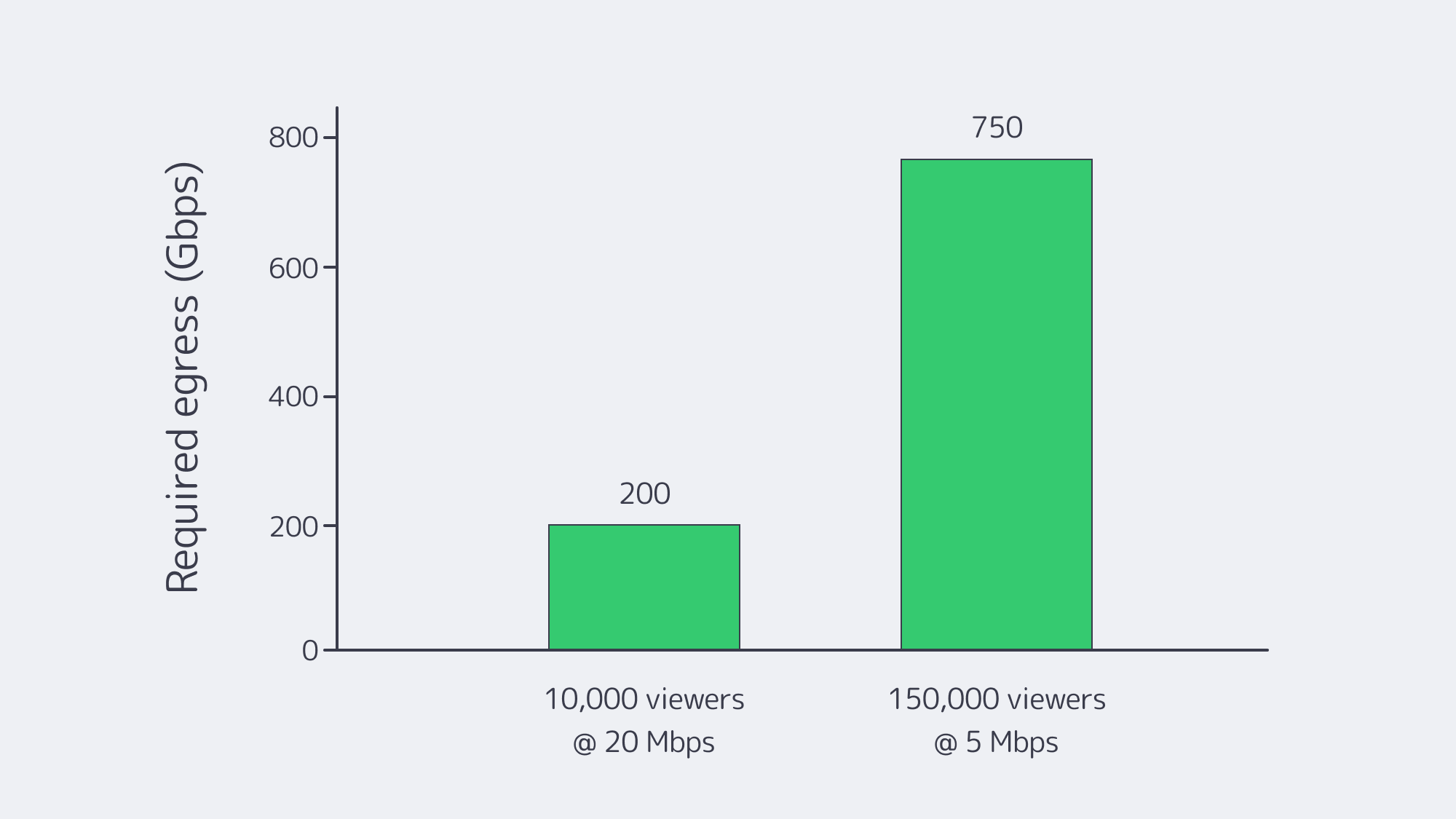
A pragmatic capacity rubric for live events:
- Work backward from concurrency × bitrate. Example: a marquee match with 150,000 viewers at 1080p (~5 Mbps) implies ~750 Gbps sustained across your edge, plus headroom for ABR steps and spikes.
- Provision origin ports for miss traffic and first‑segment storms. LL‑HLS/LL‑DASH means many tiny requests; NIC interrupt coalescing, TCP autotuning, and modern CC (BBR) help maintain microburst stability.
- Keep buffers honest. Target 2–5 second live latency end‑to‑end; avoid masking slow servers with oversized player buffers, which trades perceived “stability” for unacceptable delay.
- Monitor what viewers feel, not just what servers see. Track startup time, rebuffers per hour, edge cache‑hit ratio, and per‑region RTT to the player. Set alerts on deviation, not just thresholds.
A note on payload planning: at ~7 GB/hour per 4K viewer, turnover can be staggering on cross‑region peak nights. Build object storage and inter‑PoP replication policies that keep hot ladders close to viewers and cold renditions out of the way.
Choosing the Best Video Streaming Server Configuration
- CPU vs. GPU for encode/transcode. Software x264/x265 on high‑clock CPUs is flexible, but real‑time multi‑ladder pipelines often benefit from GPU offload (NVENC/AMF) to cap per‑channel latency.
- NICs and queues. Favor 10/25/40/100 GbE with sufficient RX/TX queues and RSS; pin interrupts and leave CPU headroom for packaging.
- NVMe everywhere. Manifests, parts, and recent segments should live on low‑latency NVMe to avoid I/O becoming your bottleneck.
- Network placement beats pure horsepower. A “big” server in a far‑away DC is worse for latency than a “right‑sized” box near the viewers behind a good CDN.
Melbicom supports these patterns with per‑server bandwidth up to 200 Gbps, 21 origin metros, and a CDN with 55+ PoPs—so teams can pair the best server for streaming workloads with the right geography and delivery fabric.
Key Takeaways You Can Act On
- Place servers near demand. Stand up origins in the same continent as your biggest live cohorts; let the CDN handle the fan‑out.
- Engineer for the peak, not the average. Provision ports and hosts to absorb first‑minute storms; keep 20–30% headroom during events.
- Hit the latency budget. Design for 2–5 second live latency with LL‑HLS/LL‑DASH; verify via synthetic beacons from viewer ISPs.
- Remove single points of failure. Multi‑origin, multi‑region; automatic health‑checked failover; periodic game‑day drills.
- Watch what viewers feel. Startup delay and rebuffer minutes drive churn; know per‑region QoE every minute.
- Use infrastructure that scales with you. Melbicom offers 1,300+ configurations, 21 locations, up to 200 Gbps per server, 55+ CDN PoPs, and 24/7 support—the raw materials to keep latency tight and streams steady as you grow.
Powering a Seamless Live Experience?

Focus relentlessly on distance and determinism. Put deterministic performance (dedicated servers) where your encode, package, and origin cache must never stall; then erase distance with a CDN and edge placement aligned to your audience map. Use low‑latency ladders only when your end‑to‑end chain—from NVMe to NIC to route to edge—is tuned for microbursts. Finally, accept that failures will happen and practice the failovers until they are invisible to the viewer. Do that, and you’ll meet the modern bar for live streaming: ultra‑low latency, stable startup, and no buffering during the moments that matter.
Melbicom’s fit for live streaming
Build a low‑latency stack on dedicated origins and a global CDN. Our team can help size ports, place servers in the right metros, and get you online fast.
Get expert support with your services
Blog

Atlanta Dedicated Servers: Bandwidth-First, Budget-Friendly
Atlanta is a case study in how infrastructure economics and competition can tighten hosting costs without compromising quality. With over 130 data centers in the metro, providers sharpen rates and add value to win deals. Add in Georgia’s ~$0.10/kWh commercial power rates and state tax incentives for data center investments, and you get a market where dedicated servers with high‑bandwidth allocations are available at double‑digit monthly prices, often with tens of terabytes of data transfer included. Such a combination—budget‑sensitive economics, competitive bandwidth, and a network crossroads hosted in Tier III+ facilities—is rare in the southeastern United States.
Choose Melbicom— 50+ ready-to-go servers in Atlanta — Tier III-certified ATL data center — 55+ PoP CDN across 6 continents |
|
Why Is Atlanta’s Hosting Market So Competitively Priced?
Density drives competition: Atlanta’s large data‑center footprint—over 130 facilities—keeps prices under sustained pressure. The area continues to see new construction—for example, a $1.3B QTS campus, a 36‑MW Flexential expansion, and a 40‑MW DataBank build—which adds capacity and moderates pricing even as demand grows. Meanwhile, robust carrier coverage, peering, and fiber routes support high throughput at favorable rates.
How do Georgia’s power rates and incentives reduce monthly bills?
Georgia’s average commercial rate of ~$0.10/kWh gives Atlanta providers structural savings on compute and cooling, which they can pass through in server pricing. On top of that, Georgia’s 2018 sales‑and‑use tax exemption (HB 696) cut capital and equipment costs for qualifying data centers. One policy analysis, citing the state’s evaluation, attributes roughly 90% of Georgia’s data center activity to these incentives—evidence that public policy materially expanded local capacity and competition. Together, inexpensive power plus tax relief help explain why “affordable” in Atlanta does not mean “compromised.”
What Should a Cheap Dedicated Server in Atlanta Plan Include Today?
In Atlanta, “cheap” refers to value, not corner‑cutting. Entry‑level packages commonly include generous bandwidth—10 TB or even unmetered—in the base price. The providers achieve this with the help of the Peering and providers operating at the metro level with fiber available due to the fact that the cost per gigabit delivered decreases with the bandwidth added. Legacy plans that billed per GB of data have largely given way to bandwidth‑first packages. At entry level, the total cost of a dedicated server in Atlanta often beats an equivalently provisioned VPS once realistic bandwidth needs are factored in.
Dedicated server hosting in Atlanta: bandwidth‑first economics
Expect practical configurations such as 1–10 Gbps ports paired with terabytes per month of transfer and rapid turn‑up. The market has since lost the majority of the archaic types of pricing (huge initial minimums, significantly small pieces of data, very long lock-ins), to embrace foreseeable monthly arrangements in line with the existing shape of traffic.
Which Modern Cost‑Saving Technologies Are Doing the Heavy Lifting?
Hardware efficiency. Successive generations of x86 processors deliver more compute per watt, enabling more‑spec boxes in the same rack footprint and power envelope.
Automated and fast provisioning. Standardized ready‑to‑go configurations image quickly and consistently, reducing labor and time‑to‑value for customers. For example, we can activate standard Atlanta servers within 2 hours from a bench of 50+ on‑hand configs.
Transit and peering of high capacity. Suppliers are able to give the big transfer quotas, even unmetered on 1Gbps, at sustainable price with multi-Tbps backbones and wide choice of carriers. Melbicom’s network supports 14+ Tbps aggregate capacity, with per‑server ports up to 200 Gbps as required.
Facility engineering. Modern Tier III+ data centers standardize redundancy and efficiency practices (hot/cold aisle containment, high‑efficiency UPS, intelligent cooling). That reduces PUE and levels the costs despite the variability in the power markets -advantages that translate into consistency in performance where prices are affordable.
Atlanta’s Cost Levers for Affordable Dedicated Servers
| Cost Lever | What it means for you |
|---|---|
| Power economics | ≈$0.10/kWh commercial power reduces OPEX for compute and cooling, enabling lower monthly server pricing. |
| Market competition | Over 130 Atlanta data centers drive competitive pricing; new supply and expansions (QTS, Flexential, DataBank) strengthen buyer leverage. |
| Tax incentives | HB 696 (2018) exempts sales/use tax on qualifying data‑center equipment; an analysis ties ~90% of Georgia’s data‑center activity to these incentives, expanding capacity and choice. |
| Network abundance | Network abundance provides tens-of-TB or unmetered plan support at favorable rates and with good throughput. |
| Facility maturity | Tier III+ Atlanta facilities emphasize efficiency and reliability; many providers maintain ready‑built configurations for rapid, low‑touch delivery. |
How Should Buyers in Atlanta Control Total Cost without Losing Performance?
- Bandwidth is more important than raw CPU counts. The users of Atlanta dedicated server hosting normally choke the egress and not the cores. Target plans with 10+ TB of monthly transfer and at least a 1 Gbps port.
- Choose the suppliers whose delivery will take the shortest possible time. Atlanta ready designs not only save time-to-launch, but the total cost of ownership as well. Choose providers that offer rapid delivery; we can provision 50+ Atlanta configurations within 2 hours.
- Determine the level of redundancy and facility. A Tier III+ Atlanta data center helps protect uptime and power/cooling efficiency, supporting predictable OPEX.
- Utilize network architecture. Pair your dedicated server in Atlanta with a CDN to offload global traffic bursts and reduce last‑mile latency.
- Re-platform, step-up are not to occur. Favor vendors that enable clean upgrades—1→10→40 Gbps ports and higher transfer quotas—without migrations; Melbicom offers 1–200 Gbps per‑server options in Atlanta.
- Maintain low management overheads. Automated OOB provisioning and remote tools save time on the common operations. Evaluate whether the provider includes 24/7 support—a safety net that matters when you run a lean team.
Is Atlanta the Right Choice for Your Workload?

In the case of teams that consider value per dollar, Atlanta can fit oddly well: there is a deep provider base, power that is cheap(er), and capacity expansion through policy that ensures that offerings remain competitive. The fiber and peering ecosystem enables providers to include generous transfer (10 TB or unmetered) at prices that are difficult to match in more expensive metros along the coastlines—which is ideal when bandwidth is your primary cost driver. In case your users are located in the U.S. East Coast (or you share transatlantic flows), the trade-off on latency against costs in Atlanta is difficult to overcome.
Launch Atlanta dedicated servers in hours
Provision 1–200 Gbps ports on 50+ pre‑configured servers over our 14+ Tbps network with free 24/7 support. Deploy in a Tier III Atlanta facility and scale bandwidth as you grow.
Get expert support with your services
Blog

Ensuring Low Latency with LA‐Based Dedicated Servers
Live experiences rely on more than bandwidth, and real‑time experiences rely on low latency. A couple of milliseconds can determine the difference between a smooth user session and an irritating one in competitive iGaming, live streaming, and time‑sensitive analytics. This article traces the network strategies that deliver ultra‑low latency with Los Angeles dedicated servers, explains why Los Angeles’s transpacific position matters, and shows how to evaluate providers that can turn geography into quantifiable performance for West Coast and Asia‑Pacific users.
Choose Melbicom— 50+ ready-to-go servers — Tier III-certified LA facility — 55+ PoP CDN across 6 continents |
 |
What Can Latency (Not Bandwidth) Tell Us About User Experience?
Latency is the round‑trip time between user and server. In real‑time applications, greater delay worsens interactivity and performance (e.g., gameplay responsiveness, live video quality, voice clarity, and trade execution). Reduced latency enhances interaction; organizations that optimized routing policies recorded clear response‑time improvements. The implication for infrastructure leaders is that, to compete on experience, you must design for the fewest, fastest network paths.
What Makes Los Angeles a Prime Low‑Latency Hub?
Geography and build‑out converge in LA
Roughly one‑third of Internet traffic between the U.S. and Asia passes through Los Angeles, with One Wilshire as the hub. It is one of the most interconnected buildings on the West Coast, supporting 300+ networks and tens of thousands of cross‑connects, including nearly every major Asian carrier. Such a density condenses hop count and makes traffic local.
Distance still matters: adding 1,000 km of fiber distance increases round‑trip delay by roughly 5 ms. Shorter great‑circle routes from LA to APAC, enabled by direct subsea landings, visibly reduce ping. Benchmark Examples:
| City (Destination) | Latency from LA (ms)Approx. | Latency from NYC (ms)Approx. |
|---|---|---|
| Tokyo, Japan | 80 | 165 |
| Singapore | 132 | 238 |
| Hong Kong, China | 117 | 217 |
The chart below shows how consistently LA outperforms New York on APAC round trips.
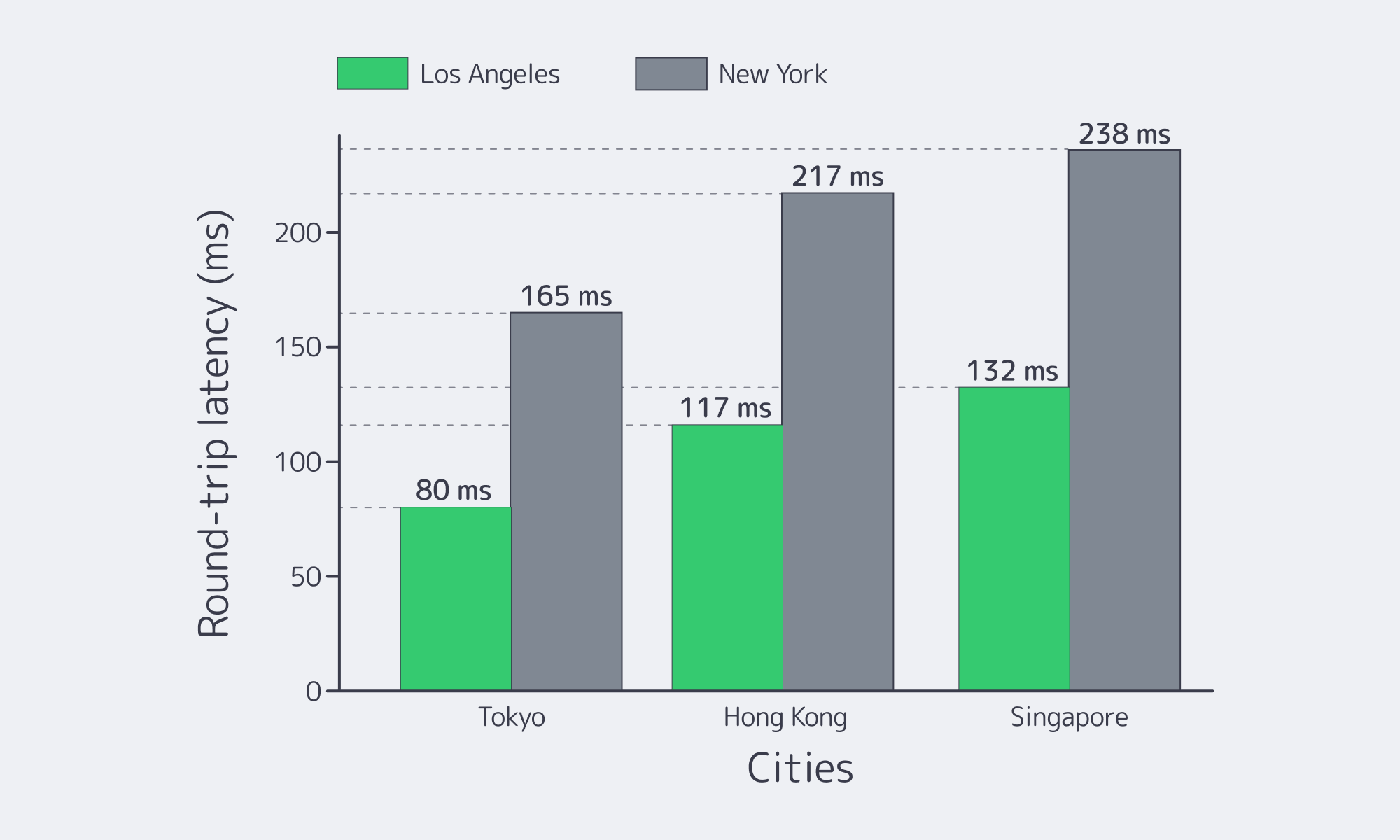
Latency from Los Angeles versus New York to APAC hubs (smaller is better). The west coast position of LA provides significantly shorter transpacific routes.
The infrastructure story is also conclusive
Legacy and next‑gen cables land in or backhaul to LA—for example, the Unity Japan–LA 8‑fiber‑pair system terminates at One Wilshire. More modern constructions increase capacity and operation strength: JUNO connects Japan and California with up to 350 Tbps and latency‑minded engineering, and Asia Connect Cable‑1 will offer 256 Tbps over 16 pairs on a Singapore–LA route. Carrier hotels continue to upgrade (e.g., power to ~20 MVA and cooling enhancements) to maintain high‑density interconnection.
Melbicom’s presence in Los Angeles is in a Tier III‑certified site with substantial power and space, ideal for terminating high‑capacity links and hosting core routers. Practically, this means fast, direct handoffs to last‑mile ISPs and international carriers, reducing detours that introduce jitter.
Why Are LA Dedicated Servers Ideal for Achieving the Lowest Latency?
Direct peering and local interconnectivity
Each additional network jump is time consuming. Direct peering shortens the path by interconnecting with target ISPs/content networks within LA’s exchanges, which can enable one‑hop delivery to end users. This prevents long‑haul detours, congestion, and points of failure. Melbicom is a member of numerous Internet exchanges (out of 25+ in the world), and peers with access and content networks in Los Angeles. In the case of a Los Angeles dedicated server serving a cable‑broadband user, packets leave our edge and hand off to the user’s ISP within the metro.
Public IX peering is augmented by private interconnects (direct cross‑connects), providing deterministic microsecond‑level handoff on high‑volume routes. This approach is especially effective for dedicated servers in Los Angeles serving streaming applications and multiplayer lobbies, where the first hop sets the tone for the entire session.
Optimized BGP routing (intelligent path selection)
Default BGP prefers the fewest AS hops, not the lowest latency. To ensure that the BGP routing tables are optimized, the BGP route optimization platforms constantly probe multiple upstreams and direct the traffic to the minimal-delay and minimal-loss path. Traffic is redirected when a better path becomes available (or an old path fails). The network shifts to the new path within seconds. Tuning BGP policies has reduced latency for 65% of organizations.
Melbicom maintains multi‑homed BGP with numerous Tier‑1/Tier‑2 carriers and can announce customer prefixes and use communities to control traffic flow. In practice, when a Los Angeles dedicated server can egress via a San Jose route or a Seattle route to reach Tokyo, we at Melbicom prefer the better‑measured route—particularly during peak times—so players or viewers see steady pings rather than oscillations.
Low-contention high bandwidth connectivity
Bandwidth headroom prevents queues; bandwidth is not the same as latency. Link saturation creates queues and increases latency. The fix is large, dedicated ports that have a significant backbone capacity. Melbicom also provides 1 G–200 Gbps per server and supports a global network of more than 14 Tbps. Guaranteed bandwidth (no ratios) reduces contention as traffic rises. To the group that needs a 10G dedicated server in Los Angeles, the advantage of this in practice is that bursts do not cause bufferbloat; the 99th-percentile latency remains nearly the same as when they are not busy.
Modern data‑center fabrics (including cut‑through switching) and tuned TCP stacks further reduce per‑hop and per‑flow delay. And that is it; broad pipes and forceful discipline over the overuse of the broadband result in the steady small latency.
Edge caching as latency complement and CDN
A CDN will not replace your origin, but it shortens the distance to users for cacheable content. With 55+ locations through our CDN, Melbicom has deployed the assets to the users leaving the bulk of the work to the dynamic call on your LA origin on a quick local path. In Los Angeles deployments of dedicated servers, such as video streaming platforms or iGaming apps with frequent patch downloads, caching heavy objects at the edge while keeping stateful gameplay or session control in Los Angeles is the best of both worlds.
How to Choose a Low Latency Dedicated Server LA Provider
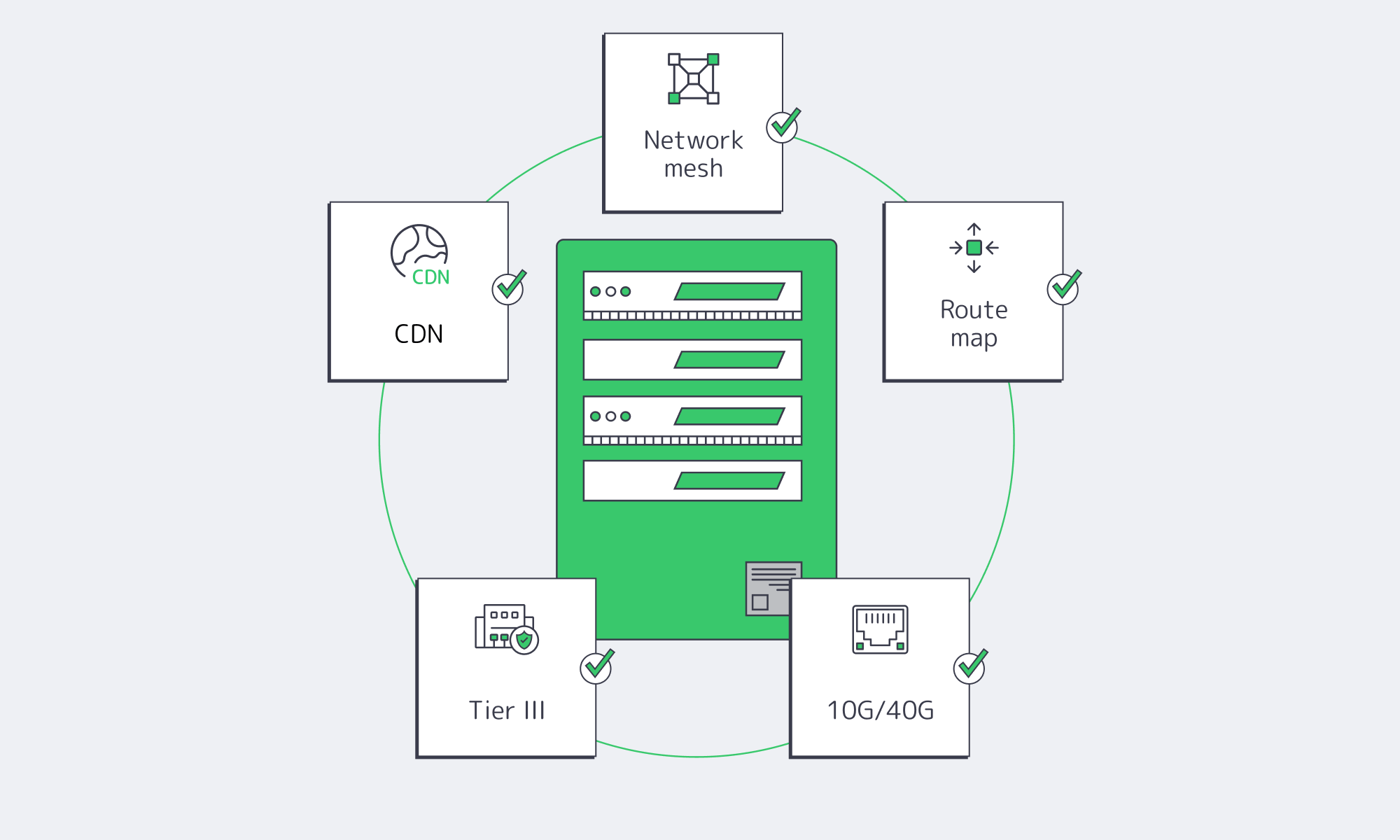
Reduce checklist to that which makes the latency needle move:
- Leverage LA’s peering ecosystem. Prefer providers with carrier‑dense coverage (One Wilshire adjacency, strong presence at Any2/Equinix IX). Melbicom peers extensively in Los Angeles to keep routes short.
- Demand route intelligence. Enquire about multi‑homed BGP and on‑net performance routing; route control is associated with reduced real‑world pings. Melbicom provides communities/BYOIP with the ability to tune flows.
- Purchase bandwidth in the form of latency insurance. Even better, use 10G+ ports even when you are unsure; the capacity margin prevents queues. With Melbicom, this sits on a guaranteed‑throughput network engineered for up to 200 Gbps per‑server bandwidth.
- Confirm facility caliber. Power/cooling capacity and Tier III design minimize risk. The LA facility at Melbicom qualifies that bar and is in favor of high density interconnects.
- Localize heavy objects with the help of CDN. Offload content to 55+ PoPs, leaving stateful traffic at your LA origin.
LA Low-Latency Networking, What Next?
Transpacific fabrics are becoming thinner and quicker. JUNO launches 350 Tbps Japan-California capacity w/ latency-sharing architecture; Asia Connect Cable‑1 launches 256 Tbps on a Singapore–LA arc. Investment in subsea systems is also rapid across the industry, $13billion in 2025-2027, and the global bandwidth has tripled since 2020, due to cloud and AI. At the routing layer, SDN and segment‑routing technologies are coming of age, enabling latency‑aware path control at large scale. Within the data center, quicker NICs and kernel‑bypass stacks shave microseconds that add up across millions of packets within the networking stack.
The practical note: the solution to APAC -facing workloads and West Coast user bases will continue to be a first-choice hub in LA, with increased direct routes, improved failover, and reduced jitter, each year.
Where LA Servers Make Latency a Competitive Advantage
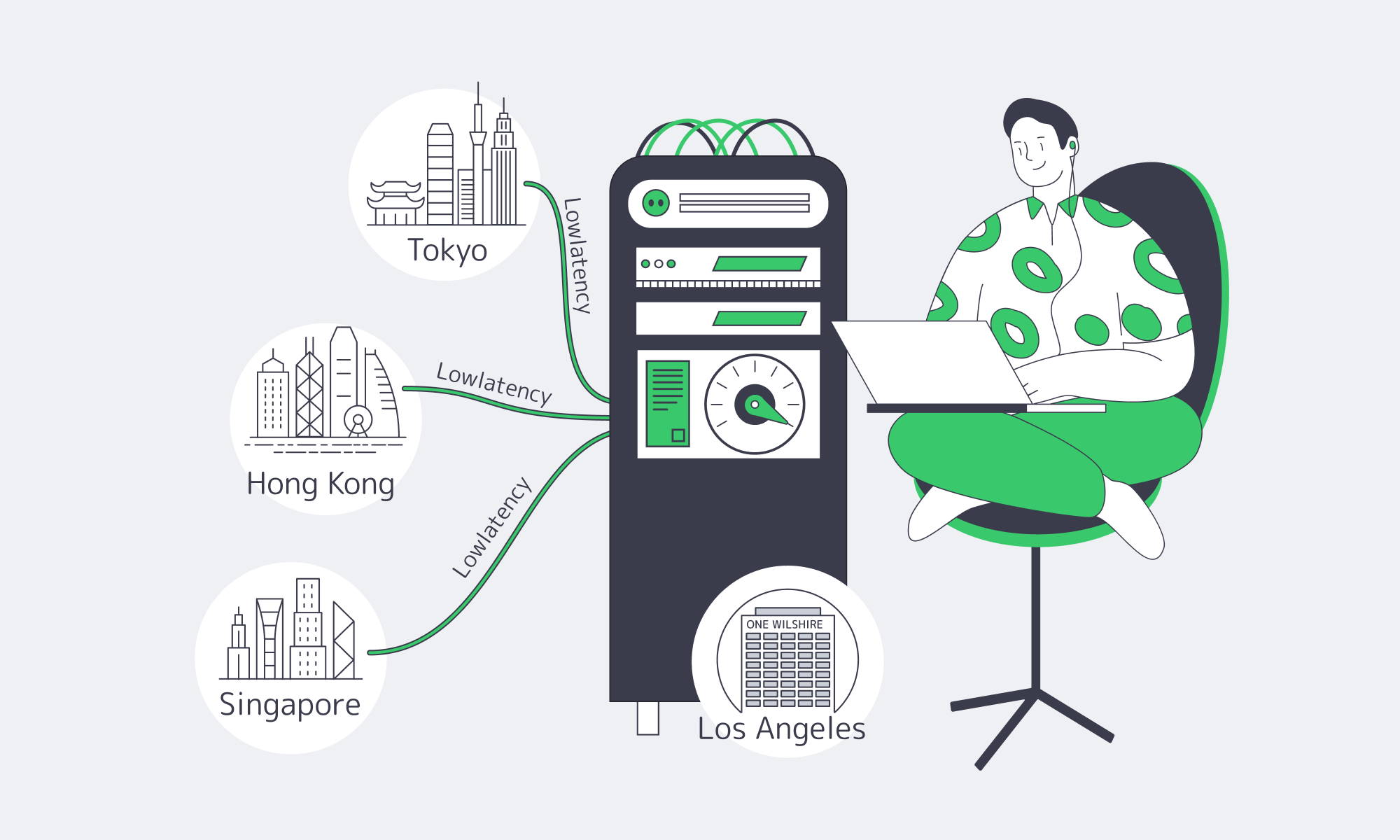
Assuming that milliseconds determine your success, Los Angeles makes geography an SLA-quality asset – without route deviations. The playbook is settled: co‑locate near Pacific cables, peer aggressively within the metro, deploy smart BGP to keep paths optimal, and provision ports and backbone capacity to avoid queues. Add CDN to localize heavy objects, and you can provide real-time experience that is localized to the West Coast and acceptable to East Asia. In the case of teams intending to acquire a dedicated server in Los Angeles (or increase an existing West Coast presence), the low-latency benefit is calculable in terms of engagement, retention, and revenue.
That is the result we at Melbicom are designing for: the physical benefits of LA plus network engineering that squeeze out wasted milliseconds. Hosting a dedicated server in Los Angeles—well‑peered and high‑bandwidth—remains among the most defensible infrastructure moves you can make.
Deploy in Los Angeles today
Launch low‑latency dedicated servers in our LA facility with multi‑homed BGP, rich peering, 55+ CDN PoPs, and up to 200 Gbps per server.