Month: December 2025
Blog

iGaming Hosting in LatAm: Brazil + U.S. Southeast Stack for Sub-150 ms Play
If your iGaming platform already runs cleanly in the U.S., LatAm expansion isn’t “add a CDN and call it done.” Brazil changes the physics: payment APIs have sharp timeout cliffs, odds and promos churn hard, and LGPD turns “just replicate it” into a data-class decision.
This is the practical blueprint we at Melbicom recommend when the target is Atlanta as the U.S. origin plus a São Paulo secondary region—with CDN PoPs in South America doing the heavy lifting during peak events, not just serving logos.
iGaming Hosting in LATAM— Reserve servers in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
Blueprint for Dual-Region iGaming Stack
The winning pattern is a dual-region core with the CDN edge acting as a traffic governor. Use Atlanta for the U.S.-native platform gravity (core services, analytics, global backoffice), and São Paulo for Brazil-first latency, payment conversion, and LGPD-aligned residency. Then let the CDN absorb bursty reads—especially around live odds and promo pushes.
São Paulo Dedicated Server: What Must Stay Local
A dedicated server in São Paulo isn’t just “closer compute.” It’s where you park the request paths that punish latency and jitter: Brazil login/session edges, cashier initiation, fraud/risk checks that must answer quickly, and the parts of the platform that touch regulated identity data.
CDN in LatAm: Burst Control, Not Just Static
CDN in South America is where you win peak moments: high-concurrency bursts during marquee matches, promo banners flipping, and “refresh the odds” behavior that looks like a denial-of-wallet if you serve it all from origin. Melbicom’s CDN has 55+ PoPs in 36 countries (including Chile, Columbia, Peru, Argentina, and Mexico), which is the baseline you need to keep cache near bettors while the origins stay deterministic.
Atlanta Origin: Where to Consolidate Without Penalizing LatAm
Atlanta works because it’s a U.S. Southeast anchor with strong interconnect potential—and because it lets you treat LatAm as an extension of a U.S. control plane without forcing every bettor’s click to cross an ocean.
How to Reach Sub-150 ms Latency in LatAm?
Sub‑150 ms play comes from pinning Brazil’s latency-sensitive flows to São Paulo, then using the CDN edge to suppress bursty reads across LatAm so that only state-changing requests reach origin. Atlanta remains the system’s authority, but São Paulo becomes the regional execution point for sessions, cashiers, and regulated identity paths.
What “Real Routing” Looks Like in Practice
The goal isn’t a single magical RTT number. It’s ensuring that the longest path is the least frequent path, especially during live events when every extra origin trip stacks.
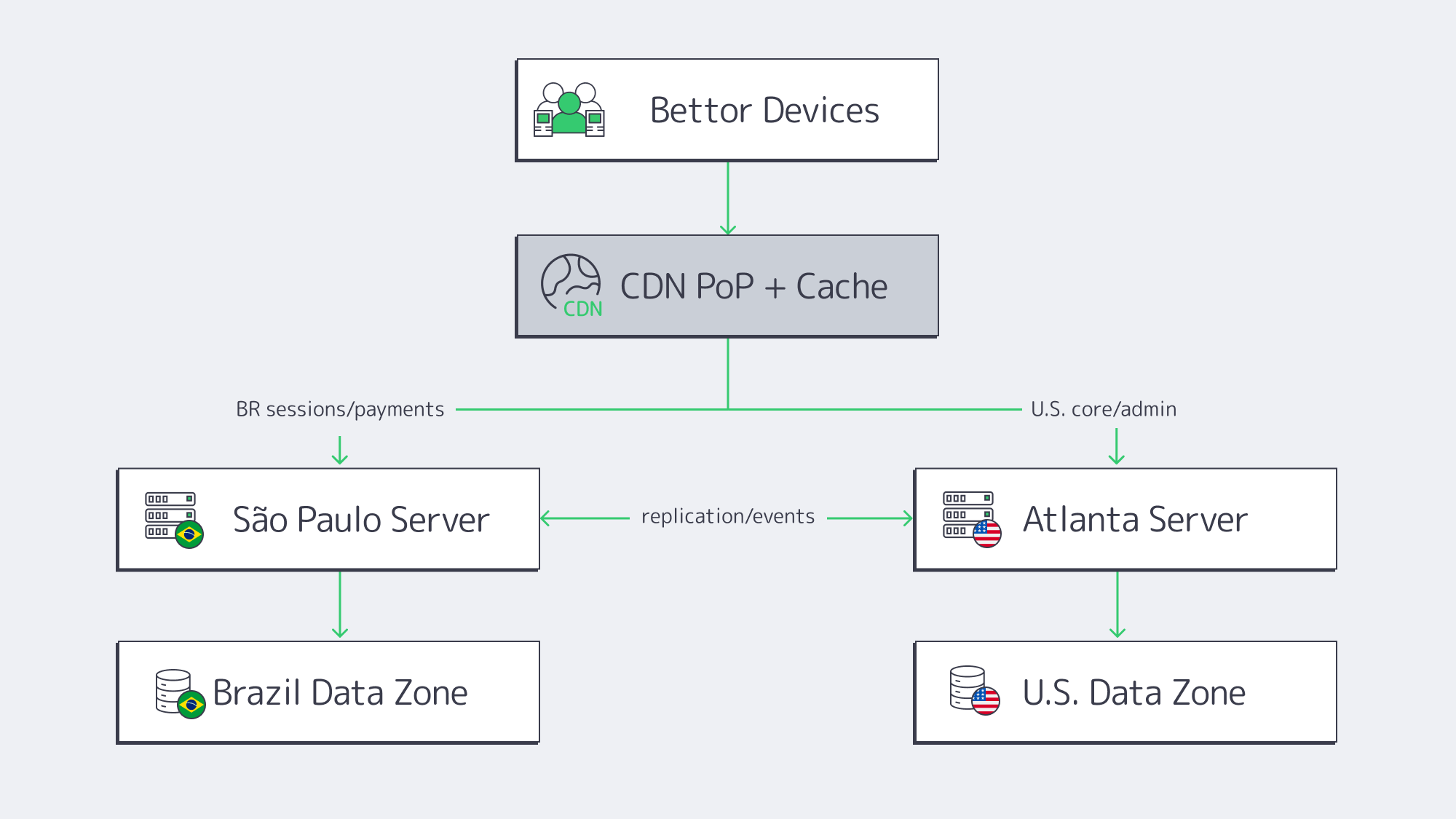
Brazil: Edge → São Paulo (Regional Origin) → Atlanta (Only When Needed)
For bettors in Brazil, the cleanest route is:
- Nearest CDN Brazil PoP → serves static assets + safe cached API responses
- Misses / state-changing calls → routed to São Paulo dedicated server
- Selective replication → São Paulo emits events upstream to Atlanta (not the reverse)
The São Paulo page calls out direct subsea connectivity and positions São Paulo as LatAm’s interconnect hub. That matters because even when Atlanta is the authority, São Paulo must be able to “phone home” reliably under load.
Chile, Peru, Colombia, Mexico: Edge → Decision Point (São Paulo vs. Atlanta)
For Chile/Peru/Colombia, don’t hardcode everything to São Paulo. Use a simple rule:
- If the flow is cashier/KYC/identity for Brazil accounts → São Paulo
- If the flow is global account management, CMS, reporting → Atlanta
- If the flow is real-time odds reads → edge microcache (and only revalidate as needed)
Latency Budgeting Without Guesswork: Use Floors, Then Engineer for Variance
Measured RTT varies by ISP and peering. But physics gives you a floor—use it to sanity-check whether a proposed routing plan is even plausible.
Hypothetical sample (computed floor; real RTT is higher):
| Market (Anchor City) | RTT Floor to São Paulo (ms) | RTT Floor to Atlanta (ms) | Practical Implication |
|---|---|---|---|
| Brazil (São Paulo) | ~0 | ~75 | Keep “hot path” in São Paulo; don’t bounce through Atlanta |
| Colombia (Bogotá) | ~43 | ~34 | Split by data-class; steer odds reads to edge, writes to appropriate region |
| Peru (Lima) | ~35 | ~52 | São Paulo often wins for LatAm-facing real-time flows |
| Chile (Santiago) | ~26 | ~76 | São Paulo is a strong regional origin; edge does burst suppression |
Which Dual-Region Failover Cuts Downtime?
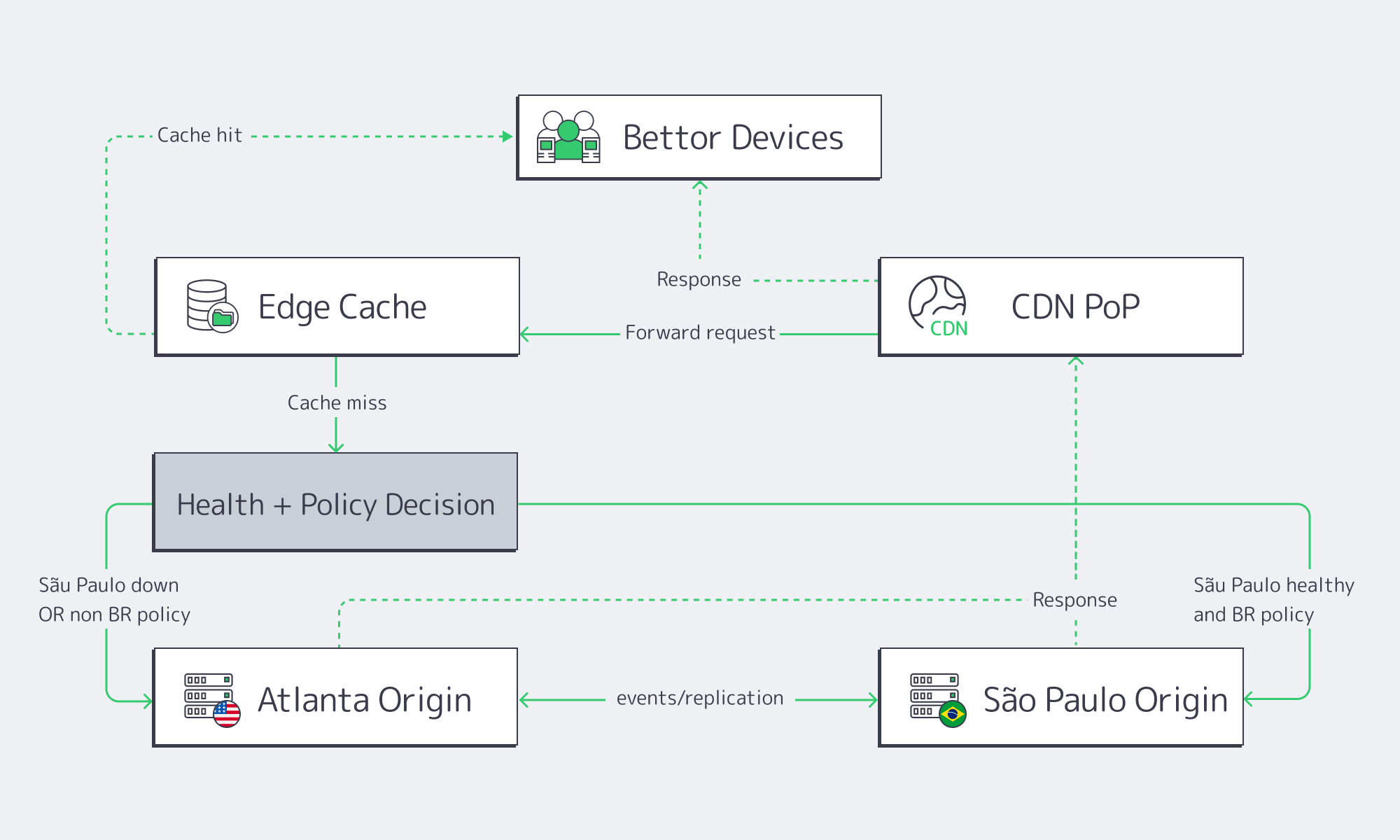
Use active service in both regions, but don’t force symmetric data ownership. Keep Atlanta as the system authority while São Paulo runs Brazil-first execution paths with replicated state that’s sufficient for continuity. Failover should be edge-driven (CDN + DNS steering), with degraded modes that preserve wagering integrity.
Failover That Doesn’t Create a Second Outage
A dual-region system fails when the failover process triggers its own incidents: cold caches, exploding origin load, inconsistent sessions, or payment retries that double-charge.
The safer failover topology:
- CDN as traffic valve: During São Paulo impairment, edge stops revalidation storms by widening TTLs for non-critical reads and serving “last known good” promo assets.
- Two origins behind one hostname: CDN can route misses to the healthier origin.
- Session strategy that survives a region swap: Store only what must be consistent globally in the shared plane; keep per-region session state small.
On Melbicom’s side, the “2-hour activation” and “3–5‑day custom builds” claim exists as an operational lever for capacity planning around known peak events—especially when you want pre-staged headroom in São Paulo before a live spike.
Peak Events: How São Paulo Dedicated Servers and CDN PoPs Work Together
Peak load in iGaming is not just “more traffic.” It’s more volatility: odds flip, promos rotate, and bettors refresh like humans trying to DoS reality. Here’s the collaboration model:
CDN PoPs cache:
- app shells, static assets
- promotion creatives
- “safe-to-cache” API reads
São Paulo dedicated server handles:
- regional “truth” for Brazil-facing reads (odds snapshots, wallet pre-checks)
- write paths (bets, wallet debits, KYC flows)
Atlanta remains:
- authoritative ledger replication target
- global reporting, segmentation, long-tail service mesh
This avoids the classic peak-event failure where edge handles nothing meaningful and São Paulo becomes a single hot pipe.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
What Data Zoning Meets LGPD?
Zone by data class, not by service name. Keep KYC/PII and Brazil-regulated identity paths in São Paulo, and replicate tokenized, minimized, and audit-safe records to Atlanta. Your CDN should never cache PII; it should cache public assets and strictly controlled “safe reads” with rapid invalidation.
Zoning Blueprint: A Data Map You Can Defend
The practical interpretation is: decide what must remain in Brazil versus what can cross borders as minimized data. Recommended split:
Brazil zone (São Paulo)
- PII and KYC artifacts
- identity verification outcomes
- payment initiation metadata (especially PIX rails)
- session attributes that materially identify a person
U.S. zone (Atlanta)
- anonymized gameplay telemetry
- fraud signals that are not directly identifying
- aggregated reporting events
- operational metrics, SLO-style indicators
Payment Gateway Proximity: Why PIX and Cards Belong in the Brazil Hot Path
Payments have a different tolerance curve than gameplay. You can “hide” latency with client-side prediction in some interaction patterns. You can’t hide it when:
- a PIX QR payload is generated and expires,
- a card auth window closes,
- a cashier retries and creates duplicate intents.
The operational advice is simple: terminate Brazil payment orchestration in São Paulo, even if the ledger authority is Atlanta. São Paulo should be close enough to answer fast and avoid jitter-driven timeouts—then replicate the minimal payment event upstream.
High-Frequency Cache Purges for Odds and Promos (Without Melting the Origin)
Odds and promotions are the edge-case where the CDN can either save you or ruin you.
Treat them differently:
- Promos: rotate a version token in the URL so you can publish without broad purges.
- Odds: cache for seconds at the edge; revalidate against São Paulo; keep Atlanta out of the revalidation loop.
- Cache purge storms: use scoped purges by tag/key class; never purge “everything” during live events.
This is where the São Paulo region acts as a regional origin so that cache misses don’t bounce across continents.
FAQ
Do we need two full copies of every service in both regions? No. Duplicate what is required for continuity and compliance. The high-availability goal is consistent wagering integrity, not perfect symmetry. Keep authority in one place (Atlanta), and ensure São Paulo has enough state to serve Brazil hot paths.
What should the CDN cache in iGaming without creating compliance risk? Static assets and tightly controlled read endpoints that are non-identifying. Avoid caching anything that can reveal identity, wallet state, or KYC status. Use microcaching for odds snapshots and short-lived promo metadata.
How do we prevent payment retries from double-charging during failover? Make cashier intentions idempotent and region-aware. São Paulo should mint the intent for Brazil flows; Atlanta should accept replicated intent events and treat repeats as retries, not new purchases.
Does São Paulo help non-Brazil LatAm markets? Often, yes—especially when your alternative is a full U.S. hop. But you still steer by data-class: Brazil KYC and cashier flows to São Paulo; global admin/reporting and non-sensitive flows can remain in Atlanta.
Conclusion: LatAm Should Feel Local Even When Your Stack Is U.S.-Native
Atlanta + São Paulo isn’t about splitting your platform in half. It’s about deciding which flows are latency-sensitive, which flows are compliance-sensitive, and which flows are just bursty—then assigning each to the right layer (edge, São Paulo, or Atlanta) so peak events don’t rewrite your reliability story.
The operational pattern that holds up under real match-day behavior is consistent: edge suppresses reads, São Paulo executes Brazil’s hot paths, and Atlanta stays authoritative without becoming the bottleneck.
Practical Guardrails
- Treat Brazil payments (PIX + cards) as a first-class regional workflow; don’t backhaul cashier orchestration to the U.S.
- Split traffic by data class, not by “service name”; zone KYC/PII and identity artifacts in Brazil, replicate minimized events to the U.S.
- Engineer odds and promos as cache-native: versioned promo assets, microcached odds reads, scoped purges—no global “flush it all” during live spikes.
- Design failover to protect the origin from the edge: widen TTLs and serve last-known-good when regions wobble; recover gradually.
- Keep São Paulo “hot” ahead of predictable peaks: pre-warm caches, stage capacity, and rehearse cache-invalidation mechanics under load.
Design your LatAm iGaming footprint
Get a technical consult on Atlanta + São Paulo architectures, CDN tuning, and LGPD-ready data zoning to keep latency under 150 ms across Brazil and LatAm.
Get expert support with your services
Blog

Singapore Servers as Your APAC Low-Latency Anchor
For many global teams, Asia-Pacific is where latency budgets go to die. The region already has the world’s largest online population, yet penetration is still catching up — which means user growth is shifting east while expectations for “instant” experiences keep rising.
At the same time, Asia-Pacific’s e‑commerce market alone is projected to exceed USD 7 trillion by 2030, making it the world’s largest and fastest‑growing digital commerce region. Real‑time payments, streaming, multiplayer games, and SaaS collaboration tools are all piling onto the network. For any product with global ambitions, slow paths into Southeast Asia and North Asia are now an existential risk, not just a UX blemish.
Underneath that demand, data center and interconnection investment is exploding. The broader Asia-Pacific data center market is expected to grow from about USD 102.45 billion in 2024 to USD 174.81 billion by 2030, at a 9.3% CAGR. Within that, Singapore is a clear outlier: its data center market was valued at roughly USD 948.9 million in 2024 and is forecast to reach USD 2.78 billion by 2033, growing at 12.1% annually.
Choose Melbicom— 130+ ready-to-go servers in SG — Tier III-certified SG data center — 55+ PoP CDN across 6 continents |
 |
Singapore’s role is not just about market size. It already hosts more than 1.4 GW of installed data center capacity and is recognized by regulators and industry analysts as a regional hub, backed by a dense regulatory and sustainability framework designed specifically for data centers. At the physical layer, Singapore sits on top of roughly 30 international submarine cable systems with a combined design capacity of about 44.8 Tbit/s, turning it into one of the most interconnected nodes on the planet.
We looked at submarine cable maps, regulatory briefings, data center market forecasts, and interconnection growth figures across Asia-Pacific. Our conclusion: if you need consistent sub‑100 ms round‑trip times across the region without building a custom multi‑country footprint from scratch, Singapore‑based dedicated servers remain the most straightforward backbone for low‑latency reach. This post breaks down how to use it effectively.
Server Hosting in Singapore: a Low-Latency Gateway to Asia-Pacific
At the network level, Singapore behaves like an edge location for most of Asia-Pacific. According to industry and policy analysis, the city‑state handles over 99% of its international data traffic via subsea cables and is currently served by around 28 active cable systems, with at least 13 more in various stages of planning or construction.
That physical density is one reason Singapore’s digital economy already contributes an estimated 17.7% of national GDP — about SGD 113 billion (roughly USD 88 billion). It’s also why latency from a well‑peered Singapore data center to major Asia-Pacific metros can feel “local” even when you’re crossing national borders.
From a practical standpoint, here’s what we at Melbicom typically see when we map latency from our Singapore facility across the region over high‑quality transit and peering:
| Destination Metro | Typical RTT From Singapore (ms) | Practical Use Case |
|---|---|---|
| Jakarta | 30–40 | Mobile games, real‑time payments |
| Bangkok | 35–45 | SaaS collaboration, streaming |
| Manila | 40–50 | Web apps, e‑commerce storefronts |
| Tokyo | 65–80 | Multiplayer games, trading frontends |
| Sydney | 90–110 | Collaboration, content, back‑office SaaS |
These are not lab‑perfect numbers — they’re realistic ranges across premium carriers under normal conditions. For most interactive workloads, staying below ~100 ms RTT is enough to feel “snappy”; below 50 ms tends to feel instant for typical users.
To put that in context: Singapore consistently ranks at or near #1 globally for fixed broadband speeds, with median download speeds above 500 Mbps and single‑digit millisecond last‑mile latency. That local access quality, combined with cable density, is what makes Singapore such a strong control point for dedicated server hosting Asia‑wide.
Melbicom’s Singapore data center sits directly on this fabric: a Tier III facility with 16 MW of power, 1–200 Gbps of dedicated bandwidth available per server, and more than 100 ready‑to‑go dedicated configurations at any given time. When you pair that with a global network spanning more than 20 transit providers and dozens of internet exchange points, you get a platform where the physical distance is as short as the map allows — and the logical distance (hops, congestion, packet loss) is carefully minimized.
Visualizing Latency From Singapore
For engineering teams, the takeaway is simple: if you anchor your Asia-Pacific workloads on a well‑connected dedicated server in Singapore, your “worst” latencies across most of the region will often be comparable to intra‑regional latencies in Europe or North America.
How Do I Choose a Reliable Dedicated Server in Singapore?
Choosing a reliable dedicated server in Singapore comes down to three layers: the physical facility (tier, power, connectivity), the network (transit quality, IXPs, routing policy), and the server profile (CPU, RAM, storage, bandwidth). Focus on latency budgets and traffic patterns first, then pick hardware and bandwidth that can safely absorb peak load with room for growth.
1. Start With Latency and Peering, Not Just Specs
For low‑latency work, a server in SG needs more than a fast CPU. You want:
- Dense, diverse connectivity. Singapore’s subsea hub status only helps you if your provider actually buys quality transit and peers broadly. In our case, Melbicom connects to 20+ upstream carriers and nearly thirty internet exchange points globally, so traffic to users in Jakarta, Seoul, or Sydney can often take direct or near‑direct paths.
- Guaranteed bandwidth, without ratios. Oversubscribed outbound links create surprise latency spikes. Melbicom exposes up to 200 Gbps per server in the Singapore facility, with committed capacity rather than “best effort” share‑and‑pray models.
If you’re evaluating Singapore’s best dedicated server options, always ask for looking‑glass URLs, test IPs, and traceroutes before you sign. Static marketing claims won’t tell you how your real routes behave.
2. Match Server Profiles to Traffic Shape
From Melbicom’s Singapore catalog, you can usually choose among:
- CPU families: modern Intel Xeon and AMD EPYC generations suitable for CPU‑heavy game servers, real‑time analytics, or microservices backends.
- Storage tiers: pure NVMe for latency‑critical databases and queues; mixed SSD/HDD for large asset libraries or logs.
- Network profiles: from 1 Gbps ports for moderate traffic up to 100–200 Gbps for content‑heavy or multiplayer workloads.
We keep hundreds of servers ready for 2‑hour activation globally, with more than 100 stock configurations in Singapore alone. Custom server configurations — for example, high‑frequency CPUs plus large NVMe arrays — can usually be deployed in three to five business days.
For global teams, the sweet spot is often: multi‑core Xeon, 128–256 GB RAM, NVMe primary storage, and at least 10 Gbps dedicated bandwidth per node. That’s enough to consolidate multiple Kubernetes worker roles or large game shards without creating new bottlenecks.
3. Demand Operational Maturity
Specs are easy to copy; operations aren’t. When you look at Singapore dedicated server hosting providers, verify:
- 24/7 support and on‑site engineers. Singapore’s tight regulatory environment means most facilities are robust; the real differentiator is how fast someone can swap a failing DIMM or debug a networking issue at 03:00 local time. Melbicom offers free, round‑the‑clock technical support and on‑site component replacement.
- BGP session support. If you bring your own IP space, you should be able to establish a BGP session to announce prefixes and optimize routing without resorting to GRE tunnels or hacks. Melbicom provides BGP session support across all data centers, including Singapore.
- API and automation. For DevOps‑driven teams, an API‑driven control plane, KVM over IP, and predictable naming for “server sg‑X” nodes are as important as raw clock speed.
What Are the Benefits of Hosting a Website on Singapore Dedicated Servers?
Hosting a website or application on Singapore dedicated servers places your origin close to the fastest‑growing digital economies, on top of some of the world’s densest subsea connectivity and low‑latency interconnection. The result: better page load times, higher conversions, and more consistent performance across APAC without a sprawling footprint.
Closer to the Fastest-Growing Digital Economies
Asia-Pacific will continue to dominate e‑commerce growth, with the region’s online commerce volume expected to surpass USD 6 trillion by the end of the decade. Southeast Asia alone is projected to see its internet economy approach USD 1 trillion in GMV by 2030.
Running your origin in Singapore means your packets spend less time bouncing through distant gateways to reach those economies. For global products, that translates directly into fewer rage‑quits, higher session lengths, and better in‑app monetization.
Latency, UX, and Revenue Are Directly Linked
The correlation between speed and business metrics is no longer theoretical. Deloitte and Google’s “Milliseconds Make Millions” research found that a 0.1‑sec improvement in mobile site speed increased retail conversion rates by 8.4% and travel conversions by 10.1%.
If your Seoul or Jakarta users are running 200–250 ms away from an origin in Western Europe, shaving even 80–100 ms by moving that origin to a Singapore dedicated server is often the cleanest way to unlock similar uplifts — especially once you’ve already exhausted front‑end optimization.
Low-Latency Networks Are the New Baseline
Equinix’s Global Interconnection Index, cited by Telecom Review Asia, projects that interconnection bandwidth in Asia-Pacific will grow at a 46% CAGR, reaching about 6,002 Tbps. That growth is being driven by e‑commerce, digital payments, and real‑time applications — exactly the workloads that suffer most from high latency.
In parallel, surveys show that over 70% of data centers in Asia are now connected to networks offering more than 100 Mbps to enterprises, underlining how quickly “good enough” bandwidth is becoming table stakes.
For your stack, that means user expectations are calibrated by local best‑in‑class experiences. If a competitor’s API or game server is physically closer — or better peered into those networks — your product will feel sluggish by comparison.
Designing a Low-Latency Architecture on Singapore Servers
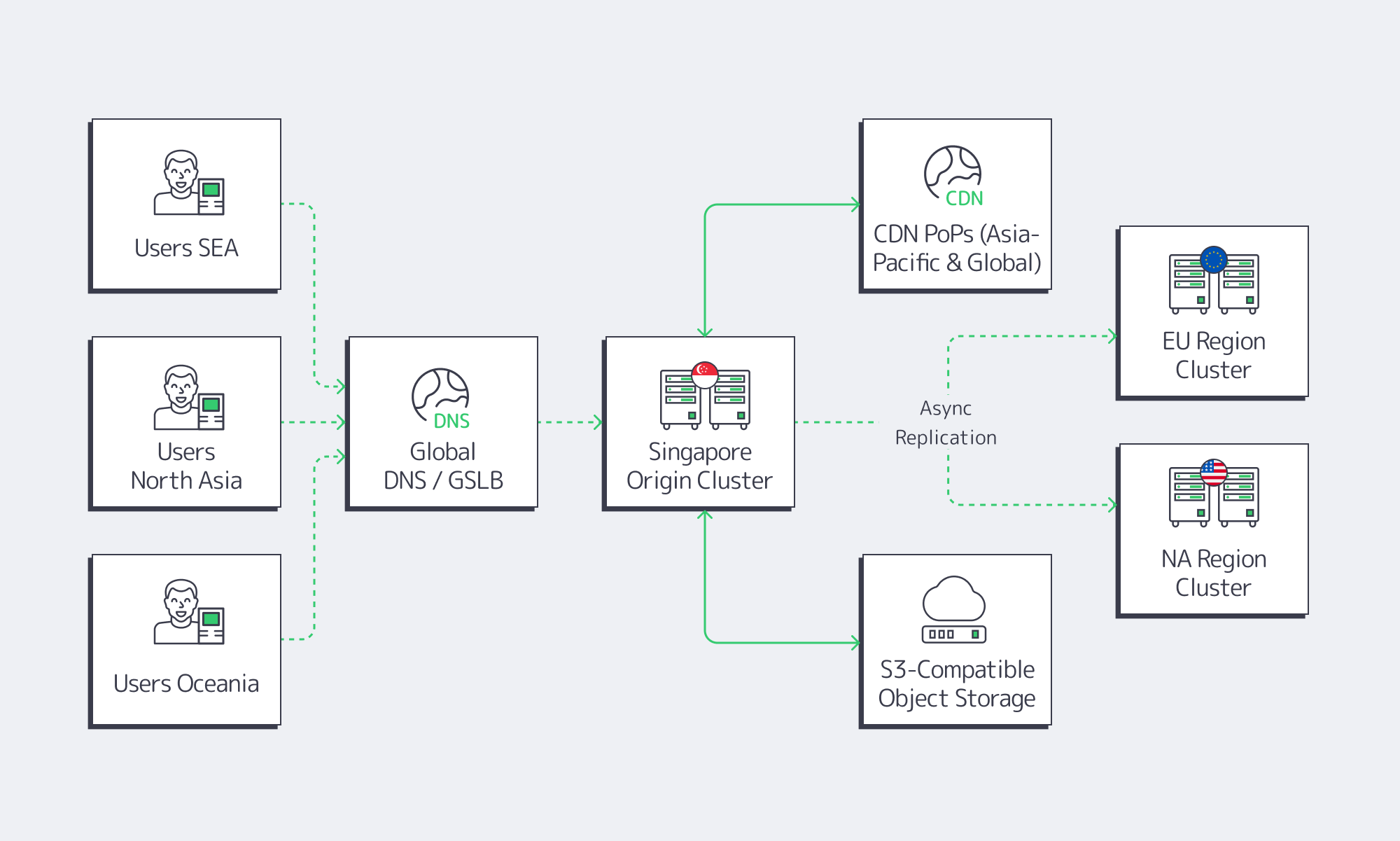
Once you’ve chosen a provider and a hardware profile, the next step is architectural. A single high‑end box in Singapore can still underperform if you treat it like “just another origin.” The goal is to use your Singapore node as a latency anchor for the region.
Map Latency Budgets Across Asia-Pacific
Start by defining clear latency budgets. Real‑time PvP or esports: target sub‑50 ms; acceptable up to ~80 ms. Competitive SaaS UX (dashboards, live collaboration): target sub‑150 ms; acceptable up to ~200 ms. Turn‑based or non‑interactive content: more tolerant, but still benefits from lower jitter.
Overlay those budgets on your traffic map. Most of Southeast Asia and parts of North Asia fall comfortably inside the “green zone” when served from Singapore; farther‑edge users (e.g., rural Australia, Pacific islands) may still exceed some thresholds. That’s where you decide whether one Singapore origin plus CDN is enough, or whether you add secondary footprints (e.g., Seoul or Sydney) as you scale.
Use a Singapore Dedicated Server as APAC Origin, Not a Global Monolith
A common mistake is to treat Singapore as a universal global origin. That leads to sub‑optimal paths for Europe or the Americas. Instead:
- Use Singapore as the Asia-Pacific origin in a broader topology where Europe and North America have their own origin clusters.
- Pin APAC DNS responses (or GSLB rules) so that users from the region hit
apac.example.comresolving to Singapore or nearby POPs. - Keep cross‑regional chatter to a minimum by pushing only the state that truly needs to be global (billing, accounts, leaderboards) to a multi‑region datastore.
This pattern is especially useful for dedicated server hosting Asia gaming workloads: shard per region, use Singapore for Southeast Asia and much of East Asia, and sync only global state asynchronously.
Pair Singapore With CDN and Object Storage
A dedicated server in Singapore gives you CPU, RAM, and bandwidth; it shouldn’t be your universal file store or global cache.
Modern guidance from edge‑delivery vendors is clear: CDNs and edge computing have complementary roles. CDNs excel at caching static assets, reducing origin load and average latency; edge compute is best reserved for custom logic that truly benefits from running within a few milliseconds of the user.
With Melbicom, you can combine:
- CDN with 55+ PoPs across 36 countries. That gives you edge caches close to users while keeping your Singapore origin small and predictable.
- S3‑compatible object storage. Our S3 cloud storage offers up to hundreds of terabytes of scalable, NVMe‑accelerated capacity, ideal for assets, backups, and logs that don’t belong on your origin disks.
In a typical setup:
- Your main application and databases run on one or more Singapore dedicated servers.
- Static assets (game patches, media, JS bundles) live in S3‑compatible storage.
- Melbicom’s CDN pulls from S3 and your Singapore origin, caching at PoPs worldwide.
- Only latency‑sensitive API calls or gameplay traffic hit the Singapore servers directly.
That architecture lets you treat the SG origin as an ultra‑fast control plane for the region.
Singapore as Your APAC Latency Anchor
When you step back from the individual stats, a clear pattern emerges. Asia-Pacific’s digital economy is compounding rapidly; interconnection bandwidth is exploding; and Singapore has positioned itself at the center of that network with dense subsea cables, high‑capacity data centers, and a regulatory framework explicitly tuned for digital infrastructure.
For technical teams, the opportunity is straightforward: treat Singapore not as a checkbox location, but as a strategic latency anchor for the region. Start with a well‑peered Singapore server cluster, wrap it in a CDN and S3 storage layer, and then add complementary regions only where your latency budgets or regulatory needs truly demand it.
Here are a few practical takeaways before you sketch your next architecture diagram:
- Quantify your latency needs first. Decide which user journeys truly require sub‑80 ms latency and which can tolerate more. Let that drive how aggressively you invest in Singapore and where you might need secondary regions.
- Make peering and bandwidth non‑negotiable. Insist on test IPs, traceroutes, and clear per‑server bandwidth guarantees. For high‑growth products, treat 10 Gbps per origin server as a minimum rather than a luxury.
- Separate compute from content. Use Singapore dedicated servers for real‑time logic and state; push heavy assets into S3‑compatible storage and CDN. That keeps your latency‑critical flows tight and predictable.
- Automate region‑aware rollout. Treat Singapore as its own deployment stage with per‑region feature flags, canaries, and observability. Don’t assume a feature that performs well in Frankfurt will behave identically against high‑churn mobile networks in Southeast Asia.
- Plan for regulatory and sustainability shifts. Singapore’s regulators are tightening energy efficiency and resilience standards for data centers, which is good news for uptime — but it also rewards providers who invest in modern, efficient infrastructure. Align your long‑term plans with that direction of travel.
Deploy in Singapore today
If you’re ready to turn these principles into a concrete deployment, we at Melbicom can help you anchor your Asia-Pacific workloads in Singapore. Our Singapore facility offers Tier III infrastructure, up to 200 Gbps per‑server bandwidth, more than 100 ready‑to‑go configurations, and custom builds delivered in 3 to 5 business days — all backed by free 24/7 support and seamless integration with our CDN and S3 storage. Order a server and start turning Singapore into the low‑latency backbone for your next phase of global growth.
Get expert support with your services
Blog

Cheap Dedicated Server in Sweden: Balancing Cost and Reliability
Managing tight IT budgets without sacrificing performance is a familiar challenge for small and mid‑size enterprises. The appeal of a cheap dedicated server in Sweden is obvious—especially when you want a fast foothold in the Nordics—but ultra‑low prices often hide brutal trade‑offs. Amazon famously found that every extra 100 milliseconds of latency cost about 1% of sales; if a bargain server adds that kind of drag or instability, the “savings” evaporate immediately.
This article looks at how to balance cost with reliable performance when choosing dedicated servers in Sweden. We’ll focus on where ultra‑cheap offers go wrong—outdated hardware, fragile networks, weak support—and how modern workloads like real‑time services expose those weaknesses. Then we’ll outline how Melbicom builds cost‑optimized Swedish infrastructure that stays affordable without quietly hollowing out quality.
Choose Melbicom— Tier III-certified DC in Sweden — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
|
What Cheap Dedicated Server Strategy in Sweden Balances Cost With Reliable Performance for SMEs?
The right strategy is to chase value, not the absolute lowest price: combine modern hardware, Tier III+ data centers, and a well‑peered network at a sensible monthly cost, instead of betting your stack on the rock‑bottom offer that cuts these corners.
Price filters are easy; outages are expensive. For SMEs, the real metric is total cost of ownership: what performance and uptime you get per dollar. A rock‑bottom server in a weak facility may save a few euros a month yet cost thousands in lost sales and remediation when it falls over. Industry studies peg small‑business downtime at about $427 per minute on average—roughly the price of a decent server for an entire month. If a single incident takes you down for an hour, you can wipe out months of “savings” from the cheapest Swedish host.
Data center quality is the first sanity check. Tier III and IV sites are engineered for high availability—around 99.982% to 99.995% uptime, or roughly 1.6 hours to under half an hour of downtime per year. Sub‑tier rooms with single power or cooling paths are cheaper, but every failure becomes your outage. That’s not a bet most SMEs really want to make.
Support is the other line item that doesn’t show up on pricing pages. Ultra‑cheap providers often mean slow, best‑effort ticket queues. When a power supply dies at 2 a.m., your team ends up alone. At Melbicom, free 24/7 support and rapid hardware replacement are part of the platform, because a low‑cost server with no one behind it isn’t actually low‑risk.
Enterprises are voting with their feet. A Barclays CIO survey found 83% of enterprise CIOs plan to repatriate at least some workloads in the mid-2020s, up from 43% in 2020. That reflects a pivot toward more predictable, controllable infrastructure once cloud bills and performance variability pile up.
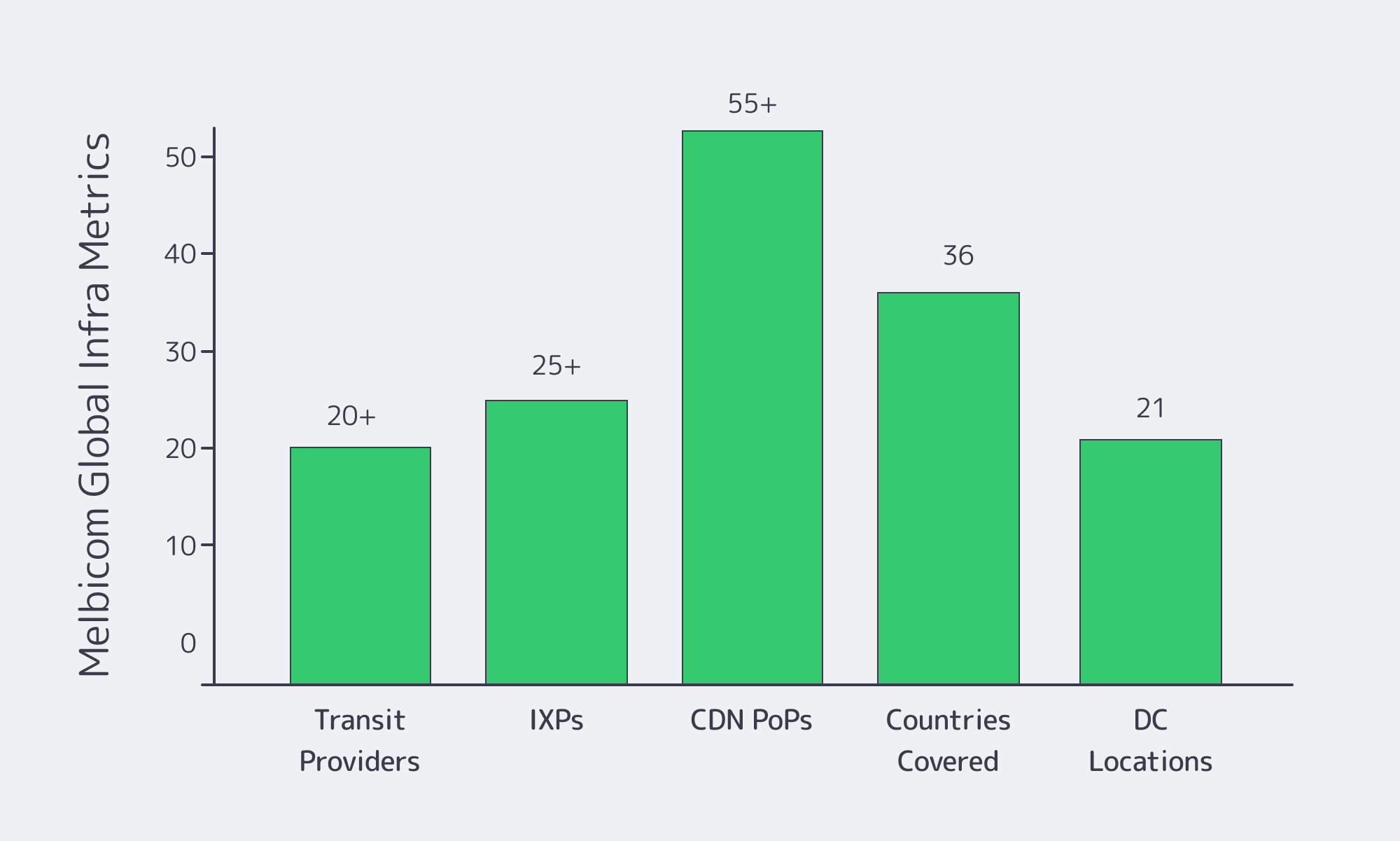
In Sweden, that trade‑off is particularly attractive: excellent connectivity, strong data‑center standards, and competitive power costs. We at Melbicom run dedicated servers in Sweden out of a Tier III facility, connected to major internet exchanges like Netnod and Equinix. That Swedish presence is part of a global network of 20 other data center locations, underpinned by 25+ internet exchange points, and a CDN delivered through 55+ PoPs in 36 countries.
Which Hardware and Network Specs Matter Most When Choosing a Low-Cost Dedicated Server in Sweden?

The must‑have specs are modern multi‑core CPUs, ample ECC RAM, SSD or NVMe storage, at least a 1 Gbps port with honest bandwidth, and a Tier III‑grade facility behind it—all backed by 24/7 support that actually answers when things break.
CPU and RAM. Many “budget” dedicated offers hide decade‑old Xeons and minimal DDR3. That’s fine for test boxes, but modern app stacks, container platforms, and even light ML inference want newer Intel or AMD CPUs with more cores and better instruction sets. Pair them with ECC DDR4/DDR5 so flipped bits don’t silently corrupt databases or logs.
Storage. Affordable shouldn’t still mean spinning disks. If a cheap configuration is HDD‑only, you’re buying latency. SSDs, ideally NVMe, are now the sensible baseline for OS, databases, and hot data. At Melbicom we build Sweden configs around enterprise SSD/NVMe, with RAID options where needed, so the bottleneck isn’t your disk subsystem.
Network port and throughput. The classic ultra‑cheap pattern is a 100 Mbps port or contended 1 Gbps uplink that collapses at peak. Look instead for a dedicated 1 Gbps port with clear upgrade paths. In Stockholm, Melbicom’s data center supports 1–100 Gbps per server, which comfortably covers most SME workloads.
Data center and power. Hardware specs are only as reliable as the room they sit in. Tier III+ facilities add redundant power and cooling, plus maintenance without downtime.
Support and provisioning. Even the best spec is useless if you wait weeks for delivery or days for a reply. We keep more than a dozen ready‑to‑go dedicated server configurations in Stockholm, so servers can be activated within 2 hours. Custom configurations can be deployed in 3–5 business days, still with the same 24/7 engineering support behind them.
Put together, these aspects separate “cheap but solid” from “cheap and fragile.” Table 1 is a quick reality check.
| Aspect | Ultra-cheap server | Quality affordable server |
|---|---|---|
| CPU & RAM | Older CPU; minimal non-ECC DDR3 | Modern multi-core CPU; ample ECC DDR4/DDR5 |
| Storage | Single HDD or low-end SSD | Enterprise SSD/NVMe, RAID options |
| Network | 100 Mbps or contended 1 Gbps uplink | Dedicated 1+ Gbps port; scalable capacity |
| Data center | Unspecified / sub-Tier III facility | Tier III/IV data center with redundancy |
| Support | Slow, “best effort” responses | Included 24/7 support; fast hardware replacement |
Table 1: What you usually give up when you chase the very lowest price.
A low‑cost server that still looks like the right‑hand column is usually one where the provider has done real engineering work instead of just slashing quality.
Which Cost-Optimized Dedicated Hosting Architectures in Sweden Can Support AI and Real-Time Workloads?

The most effective architectures pair modern dedicated servers in Sweden with GPU options, fast networking, and CDN/object storage offload—so AI, streaming, and transactional workloads get low latency and high throughput without hyperscaler bills and with predictable monthly costs for SMEs.
AI and GPU‑ready servers. AI demand is exploding; one recent analysis suggests AI‑ready data center capacity must grow about 33% per year between 2023 and 2030. For SMEs, that means the hardware floor keeps rising. Renting a GPU-equipped dedicated server in Sweden gives you a fixed, predictable monthly cost for training smaller models or serving inference, instead of volatile hourly cloud bills. At Melbicom, we can deliver GPU-powered servers in Sweden within 3–5 business days, which can be paired with the CPU-only ready-to-go nodes we keep in stock—so you can start lean and add accelerators only when you truly need them.
Low‑latency network design. Real-time platforms—trading, gaming, live collaboration—care about milliseconds. Stockholm is a dense internet hub, so a well-peered Swedish server can reach much of Europe in low double-digit milliseconds when the network is engineered correctly. Melbicom’s network is built on 20+ transit providers and 25+ IXPs, and we provide free BGP sessions on dedicated servers from all locations, including Stockholm.
CDN and storage offload. Instead of making one origin server push every asset worldwide, put a CDN in front and move heavy, static, or streaming content to the edge. Our CDN has 55+ PoPs in 36 countries, so content originating in Sweden is served from nearby metros across Europe, the America, and beyond. Cold data, backups, and large logs can move to S3 object storage in EU Tier IV DCs, leaving your Swedish servers focused on live workloads.
Distributed but simple. You don’t need hundreds of microservices to benefit from this. A small, opinionated layout is usually enough:
- 1–2 dedicated application/database servers
- Optional GPU node(s) for AI workloads
- CDN in front of everything user‑facing
- S3‑compatible storage for backups and bulk data
- BGP or smart routing if latency is business‑critical
That pattern keeps operations understandable while still hitting demanding availability and response‑time targets, and it avoids both unpredictable hyperscaler bills and the brittle edges of the very cheapest hosting.
Conclusion: Getting Real Value From Cheap Dedicated Servers in Sweden

The real question isn’t “How cheap can we go?” but “How much performance and reliability do we get for every dollar we spend?” For SME IT teams, the answer for long‑term server hosting in Sweden lies in combining Tier III‑class facilities, modern hardware, and a serious network with a pricing model that doesn’t require an enterprise budget.
Look past sticker prices and a pattern appears: ultra‑cheap servers cut corners on hardware age, data‑center quality, bandwidth, and support. Those shortcuts show up as lag, outages, and late‑night firefights your team didn’t plan for. A thoughtfully engineered, affordable dedicated server—backed by current‑generation infrastructure and responsive experts—lets you keep latency low, uptime high, and bills sane.
When you evaluate “cheap” offers, treat them as design inputs, not just numbers on a page:
- Benchmark cost against outage risk. Compare monthly savings to realistic downtime costs; if one bad incident wipes out a year’s savings, the offer isn’t truly cheap.
- Set a hardware baseline you won’t cross. Require modern CPUs, ECC RAM, and SSD/NVMe; anything older should be relegated to labs, not production.
- Treat network as a first‑class spec. Ask for per‑server bandwidth and peering details, not just “fast” — especially if you serve real‑time or media workloads.
- Use the ecosystem to stay lean. Offload heavy content to CDN and backups to object storage so your Swedish servers stay focused and right‑sized.
- Assume something will break. Choose providers whose 24/7 support and replacement policies you’d trust at 3 a.m., not just at procurement time.
These aren’t just checkboxes; they’re the difference between a cheap dedicated server that quietly drags on your business and one that becomes a reliable backbone for growth.
Get Reliable Swedish Dedicated Servers
Deploy in a Tier III Stockholm facility with modern hardware, guaranteed bandwidth, and 24/7 support. Start with ready-to-go configs or customize to fit your workload and budget.
Get expert support with your services
Blog

Why Sweden Is Your Next Dedicated Server Hub
Choosing where to place your infrastructure is now as strategic as what hardware you buy. For many organizations, Sweden has quietly become one of the most compelling places in the world to deploy a dedicated server: legally safe, politically stable, and wired into Europe’s core internet exchange routes.
This piece walks through why Sweden punches above its weight as a dedicated server location, how Stockholm’s connectivity compares to other European hubs, and what all of that means for high‑demand, compliance‑sensitive workloads.
Choose Melbicom— Tier III-certified DC in Sweden — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
|
What Are the Key Advantages of Dedicated Hosting in Sweden vs. the Rest of the EU?
Hosting dedicated servers in Sweden combines three levers you rarely get in one place: strong EU‑grade data protection with clear residency options, a pro‑infrastructure policy environment that supports long‑term cost control, and network infrastructure that rivals Europe’s biggest capitals while benefiting from a cooler climate and low‑carbon power.
Sweden’s privacy and data‑protection posture starts with GDPR but is reinforced by a strong local culture around data ethics and sovereignty. For organizations dealing with Schrems II fallout and cross‑border transfer headaches, keeping sensitive EU data on a dedicated server in Sweden is a clean way to stay under EU jurisdiction and reduce exposure to non‑EU surveillance laws.
On the cost side, Sweden has historically made decisive moves to keep large digital infrastructure affordable. A previous electricity‑tax incentive cut the rate for data centers by 97%, down to 0.005 SEK (≈ $0.00054) per kWh, signalling that compute belongs alongside heavy industry. Even as that specific scheme has changed, industrial power in Germany has averaged around €0.16 per kWh, and Nordic operators still report up to 80% lower TCO than comparable setups in central Europe, with power costs often 40–50% below the wider European average.
Sweden is also an innovation hub. Stockholm’s tech ecosystem—fintech, GamDev, SaaS, AI—demands modern, high‑density, and highly connected data centers. That pressure has created a market where Tier III+ facilities, strict physical security, and advanced connectivity options are table stakes, not nice‑to‑have extras.
Sweden vs. Typical EU Hosting at a Glance
| Factor | Sweden’s Advantage |
|---|---|
| Data Residency & Privacy | EU jurisdiction, strong enforcement culture, straightforward GDPR‑compliant hosting. |
| Power & Sustainability | Historically ~97% tax cut to 0.005 SEK/kWh; today Nordic sites still enjoy cheaper power and a cool climate for extensive free cooling. |
| Network Connectivity | Major European hub; rich peering; low‑latency reach across Europe and beyond. |
| Business Climate | Politically stable; pro‑tech policies; long‑term commitment to digital infrastructure. |
Which Swedish DC Features Matter for High-Demand, Compliance-Sensitive Workloads?
For high‑demand, compliance‑sensitive workloads, Swedish data centers offer a combination of Tier III+ redundancy, strong physical and logical security, and a legal framework that makes EU data residency straightforward, wrapped in an energy‑efficient environment that can economically support dense compute, AI, and data‑heavy applications over the long term.
From an engineering perspective, you’re typically looking at fully redundant power and cooling, with N+1 or better designs and expected uptime in the 99.99% bracket. Sweden’s grid is resilient and well‑connected, which reduces the risk of brownouts or extended outages. For mission‑critical workloads—trading systems, healthcare platforms, real‑time analytics—that reliability is non‑negotiable.
Compliance is where Sweden quietly shines. A dedicated server Sweden deployment keeps your data on EU soil, making GDPR alignment and Schrems II risk assessments more straightforward. Many Swedish facilities are certified against standards like ISO 27001 and PCI‑DSS and follow SOC‑style security practices, giving you a strong base for audits in finance, healthcare, and public‑sector use cases.
Sweden is also pushing operators to stay efficient. A new law requires data centers to disclose energy‑performance information and report their energy usage into a European DB, in line with the updated EU Energy Efficiency Directive. That effectively bakes continuous efficiency improvements into the market—good for optics and for long‑term hosting costs.
On the hardware side, Swedish facilities are comfortable with high‑density racks, GPU nodes, and custom configurations. In Stockholm, we at Melbicom keep dozens of ready‑to‑deploy servers, and can assemble custom builds within 3–5. That kind of agility matters when a new workload or region needs to be spun up fast without compromising on locality or compliance.
Which Connectivity Benefits Do Stockholm-Based Servers Offer for Global Apps?
Stockholm’s position as a Nordic network hub means a dedicated server there can serve hundreds of millions of users with low latency, plug into multiple tier‑1 carriers and internet exchanges, and integrate cleanly with global clouds, CDNs, and private backbones—all from a jurisdiction that still gives you full EU data residency.
Geographically, Stockholm sits at a sweet spot—350 million users are reachable within 30 ms round‑trip latency from the city. That captures most of Scandinavia, large parts of Western and Central Europe, and the Baltics. Even to the U.S. east coast, latency is typically in the ~80–90 ms range—usable for many web and API workloads.
On the peering side, Stockholm is home to major internet exchanges. Netnod’s IX platform in Sweden has hit all‑time traffic peaks around 2.35 Tbps, and maintains > 2 Tbps peak traffic with 200+ connected networks, underscoring how much regional traffic is exchanged locally rather than backhauled through distant hubs. For a Sweden dedicated server deployment, that translates into fewer hops, more direct paths, and better performance.
Major carriers operate dense fiber backbones through Sweden, making Stockholm an anchor point on routes to Amsterdam, Frankfurt, Paris, and Warsaw with sub‑20 ms latencies, as well as to Helsinki and the Baltics. There are multiple subsea and terrestrial paths in and out of the country, so fiber cuts or route failures have less chance of isolating your workloads.
For content and latency‑sensitive applications, origin placement in Sweden pairs well with global edge delivery. Melbicom’s CDN runs over 55+ Points of Presence in 36 countries, so you can keep authoritative data and sensitive logic on your Sweden dedicated servers while caching content closer to users worldwide.
Why a Sweden Dedicated Server Belongs in Your Roadmap
Sweden has quietly become one of the most rational places to pin your European infrastructure strategy. You get EU‑grade data protection with clear residency, a maturing regulatory framework that rewards efficient operators, and a network position that can hit hundreds of millions of users with low latency—all while running on a predominantly renewable grid.
For companies facing tightening privacy rules, rising energy costs, and ever‑heavier workloads, a Sweden dedicated server isn’t a niche Nordic experiment. It’s a pragmatic way to de‑risk compliance, stabilize long‑term operating costs, and anchor performance‑critical services in a location that’s politically and technically built for the next decade of infrastructure growth.
Key Takeaways and Recommendations

- Treat Sweden as a default EU landing zone for workloads that must remain under GDPR with minimal cross‑border transfer risk, and only add non‑EU regions where business requirements truly demand it.
- Shift energy‑intensive, high‑density compute (AI training, analytics, streaming origins) toward Sweden to benefit from structurally lower Nordic power costs and efficient cooling, reserving higher‑cost regions for only the most latency‑sensitive users.
- Use Stockholm as a pan‑European hub: design routing so that a single Sweden region serves most Nordic, Baltic, and Central European users within ~30 ms RTT, and pair it with CDN caching at the edge when you need ultra‑low TTFB.
- Anchor compliance‑sensitive and mission‑critical services in Tier III Swedish facilities, then layer global redundancy (secondary regions, CDN, or cloud failover) on top instead of depending solely on a single hyperscale cloud region.
When choosing Sweden as a dedicated server hosting hub, you get a location that’s not just “good enough,” but actively aligned with where infrastructure and policy are heading. The practical outcome: predictable performance, cleaner compliance narratives, and less guesswork about where your next region should live.
Order a Sweden Dedicated Server
Place your next build in Stockholm with EU data residency, Tier III reliability, and low‑latency reach across Europe. Deploy ready configs or custom servers in 3–5 days backed by 24/7 support.
Get expert support with your services
Blog

Hosting in the Nordics: Dedicated Server in Stockholm for Speed & Uptime
If milliseconds of delay can make or break your application, it’s time to look north. Stockholm has become a prime hub for low-latency, ultra-stable hosting. A dedicated server in Sweden’s capital sits on dense carrier infrastructure, mature data centers, and one of Europe’s most reliable power grids – a stack that often separates “fast enough” from genuinely best‑in‑class.
Choose Melbicom— Tier III-certified Stockholm DC — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
|
What Dedicated Hosting Setup in Stockholm Delivers the Best Speed and Stability?
The fastest, most stable option is a single-tenant dedicated server in a Tier III+ Stockholm data center, wired directly into high-capacity uplinks. You get exclusive CPU, RAM and NVMe storage, hosted close to Nordic users and connected through low-latency routes, which reduces both jitter and failure risk for demanding workloads.
A modern dedicated server in Stockholm pairs three things: single-tenant hardware, a Tier III+ facility, and direct access to the local network core. Tier III design (N+1 power and cooling) targets 99.982% availability by industry standards, keeping workloads online even during component failures or maintenance.
Local presence turns that reliability into visible speed. Nordic traffic served from Central European hubs crosses several countries and networks. Moving workloads to a Stockholm data center can reduce regional latency by up to 40%.
Why a Stockholm Dedicated Server Means Low Latency and High Uptime
- Proximity to Users: Hosting in Stockholm brings Nordic traffic onto short paths. Typical pings to nearby capitals can land in the sub‑20 ms range.
- Dedicated Resources: Single‑tenant servers avoid noisy neighbors, ensuring consistent CPU time and low jitter for time‑sensitive workloads.
- Instant Scalability With Stability: Rapid provisioning and on‑site support let you scale out while keeping the same latency profile and uptime characteristics.
Which Network Peering & Exchange Options Minimize Latency for Nordic Workloads?

Stockholm’s low latency comes from deep interconnection: exchanges like Netnod, STHIX, and major IX platforms host hundreds of networks in a few buildings. When a Stockholm server peers locally, traffic to Nordic ISPs, CDNs and cloud services can travel in just a few hops, which sharply reduces latency and jitter for end users.
Netnod is the cornerstone of this fabric. Its Stockholm nodes let ISPs, content networks and carriers exchange traffic inside the region rather than hauling packets to other European hubs. One operator reported that by peering at Netnod, they could reach about 15% of global IPv4 routes and 40% of IPv6 routes directly and cut latency to some Asian destinations by 20 ms, according to Netnod. For real‑time apps, that’s the difference between “smooth” and “laggy.”
Stockholm doesn’t rely on a single exchange, which is key for resilience. Alongside Netnod, platforms like Equinix and other large commercial IXes aggregate hundreds of participants. This density means a Stockholm dedicated server can sit one hop away from most Nordic eyeball networks and major cloud on‑ramps. If one path fails, BGP shifts traffic to another local peer, often without any noticeable performance hit.
Melbicom’s backbone is built to exploit this environment. The network spans 14+ Tbps of global capacity and connects to 25+ Internet exchanges and 20+ transit providers. From a Stockholm dedicated server, traffic can flow via multiple Tier‑1s and regional carriers at once, with BGP steering it over the lowest‑latency available path. For customers that bring their own IP ranges, we can establish custom BGP sessions.
The result is a topology where Nordic users rarely leave the region to reach your services. Requests from Stockholm to nearby markets typically stay within Scandinavian and Baltic networks, while routes to Central Europe take short, direct paths. Latency becomes more predictable, packet loss remains low, and traffic spikes are absorbed by a mesh of peers rather than a single congested transit link.
Which DC Specs Make Stockholm Dedicated Servers Ideal for High-Demand Apps?

Nordic data centers combine Tier III engineering, an exceptionally reliable power grid, and a naturally cool climate. In Stockholm, that means dedicated servers run on redundant power and cooling, backed by nearly fossil‑free electricity and year‑round efficient cooling, which keeps high‑demand hardware stable even at sustained high utilization.
Tier III facilities in Stockholm are designed for concurrent maintainability: any single power feed or cooling unit can be taken offline without interrupting IT load. The formal target of 99.982% availability translates to infrastructure built around dual utility feeds, UPS systems, diesel generators and multiple chillers. Melbicom’s Stockholm deployment sits in such a Tier III environment and carries certifications such as PCI DSS/SOC audits, reflecting robust physical and procedural security across the network.
There is also the regulatory and geopolitical layer. Sweden scores highly on political stability and rule of law, and operates within the EU’s GDPR framework. For workloads handling European personal data, hosting in Stockholm simplifies data residency and privacy considerations; Swedish customer data can stay on Swedish soil, in line with guidance around Schrems II and GDPR compliance. Nordic data protection culture and multi‑layer security controls in modern facilities reduce the risk of regulatory surprises that could affect uptime.
Nordic Data Center Advantages at a Glance
To see how these factors line up for infrastructure teams, it helps to map them directly to operational impact:
| Feature | Stockholm/Nordic Advantage | Impact on Hosting |
|---|---|---|
| Tier III Data Centers | Redundant power and cooling with 99.982% uptime design | High availability for mission‑critical services; maintenance and single faults do not interrupt production workloads. |
| Local Internet Exchanges | Dense IX ecosystem including Netnod and other platforms | Ultra‑low latency to Nordic users; local rerouting options in case of fiber or carrier issues. |
| High Bandwidth Pipes | Up to 100 Gbps per server | No artificial limits for bandwidth‑heavy apps; supports large‑scale streaming, data sync and replication. |
| Reliable Power Grid | Fossil‑free, highly stable electricity with minimal outages | Consistent supply for dense compute; reduced risk of downtime due to grid instability or energy rationing. |
| Cool Climate Efficiency | Year‑round cool ambient temperatures enable free cooling | Efficient, predictable cooling keeps servers at optimal temperatures, even under sustained high utilization. |
Melbicom builds on this foundation with operational practices oriented around high‑demand workloads. Hardware is standardized for fast replacement, logistics are tuned for rapid provisioning in Stockholm, and technical teams operate on a true 24×7 model. That operational discipline is often the last piece missing when teams try to run latency‑critical apps in regions where DC and power infrastructure are less forgiving.
Why a Dedicated Server in Stockholm Is a Strategic Move

All of this adds up to a simple conclusion: putting critical workloads on dedicated servers in Stockholm is no longer just about local presence in the Nordics. It is a way to anchor latency‑sensitive systems in one of the world’s most interconnected, power‑stable and cooling‑efficient regions, with predictable performance under real‑world load.
For architectures that depend on microseconds and nines – trading platforms, online games, SaaS backends, video delivery, AI inference – the location of the hardware can be as important as the code running on it. Stockholm’s mix of dense peering, Tier III design and Nordic grid stability gives infrastructure teams a clean, scalable base for building high‑demand services that feel fast and stay online.
For infrastructure leaders planning next steps, three practical recommendations follow:
- Use Stockholm for latency‑critical Nordic segments to keep RTTs near single‑digit or low‑double‑digit milliseconds.
- Treat peering at Netnod, Equinix and other IXs plus multi‑homed BGP as baseline network hygiene, not a premium feature.
- Require Tier III design, resilient power, efficient cooling and built‑in Swedish data residency when placing high‑demand nodes.
Stockholm Dedicated Servers: Start Today
Deploy in a Tier III Stockholm facility with 1–100 Gbps ports, low latency to Nordic users, and 24/7 support. Provision fast and scale on demand.
Get expert support with your services
Blog
Designing High-Throughput Web3 RPC Infrastructure
The Web3 market is estimated at roughly $3.47 billion in 2025, with projections toward $41+ billion by 2030—a compound annual growth rate above 45%. Wallets like MetaMask report 30+ million monthly users and 100 million transactions per month flowing through dApps.
Every one of those interactions crosses a remote procedure call (RPC) boundary between application and chain. Misjudge that layer and users experience “decentralization” as blank balances, timeouts, and stuck swaps.
We at Melbicom see these trends from the infrastructure side: validator fleets, full and archival nodes, indexers, and dApp backends pushing RPC infrastructure hard across Ethereum, Solana, BNB Chain, and other networks. In this article, we’ve combined our own telemetry with industry benchmarks on dedicated nodes, Web3 DevOps practices, API architecture research, and software-supply-chain security to answer a practical question: “What does reliable, high‑throughput, low‑latency RPC infrastructure for modern Web3 apps actually look like—and what kind of dedicated server footprint does it require?”
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
The Limits of Public RPC Endpoints
Public RPC endpoints are indispensable for experimentation and small projects. They’re also structurally misaligned with serious production workloads.
Many official or foundation-backed public endpoints are deliberately rate-limited to discourage production use. For example, one L1’s free RPC tier caps traffic around 50 queries per second and ~100,000 calls per day, with paid tiers increasing limits to ~100 QPS and ~1 million calls per day. Another major network has public endpoint limits around 120 requests per minute (≈2 RPS) for mainnet, again to deter production usage.
For high‑throughput chains like Solana, public docs and provider comparisons put free/public endpoints roughly in the 100–200 RPS per‑IP range, often with 2–5 seconds of data freshness lag and no uptime guarantees. Polygon-focused analyses make similar points: public endpoints are free but frequently congested or briefly unavailable.
In practice, public endpoints are ideal for:
- Local development and testnets
- Lightweight wallets
- Prototyping and small internal tools
But once you’re serving real traffic, you quickly hit rate limits, jitter, and opaque throttling.
Typical RPC Demand vs Public Endpoint Limits
Below is a simplified view of how real workloads compare to typical free RPC constraints:
| Workload Type | Peak RPC Load (RPS) | Fits on Public/Free RPC? |
|---|---|---|
| New Ethereum DEX (mainnet, modest volume) | ~80–150 | Barely; quickly rate‑limited on 50–100 QPS and 100k–1M daily caps |
| NFT mint + reveal on high‑throughput L1 | 500–2,000 for bursts | No; bursts exceed per‑IP & per‑method limits, cause 429s and retries |
| On‑chain analytics API (archival reads) | 30–60 steady | Unreliable; archival/trace methods often throttled or paywalled |
| Self‑hosted dedicated RPC node or cluster | 500–1,500+ sustained (per node) | Yes, if hardware, bandwidth, and caching are sized correctly |
Dedicated nodes move the bottleneck from someone else’s shared infrastructure to your own capacity planning—where you have actual control.
Building Reliable RPC Infrastructure for Web3 Applications
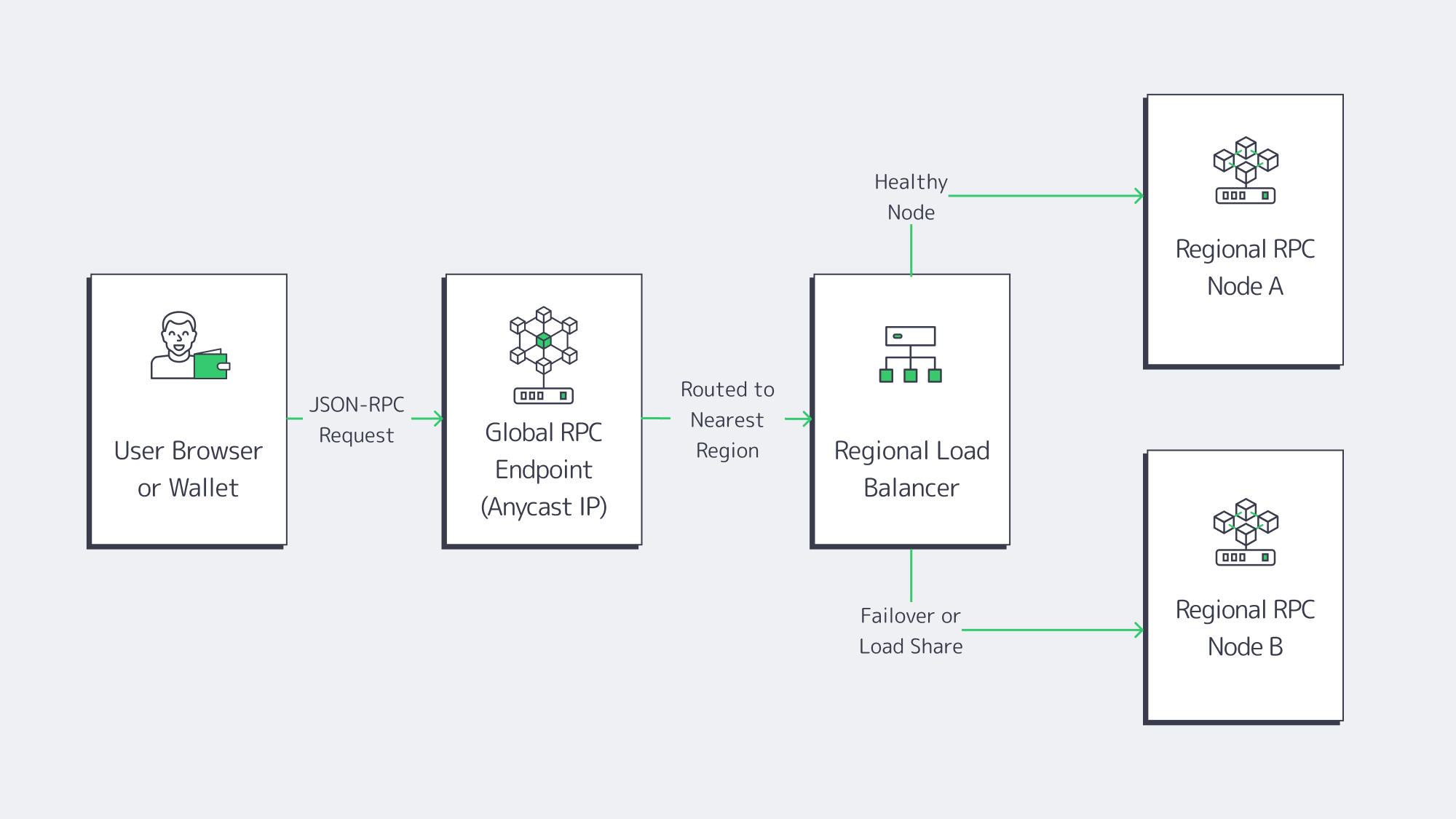
The core design principle is simple—treat RPC infra as a first‑class, multi‑region API platform (backed by dedicated blockchain nodes), not as a single endpoint you “just point the dApp at.”
Modern API architecture guides stress that the interface (REST, GraphQL, gRPC, or pure JSON‑RPC) should match your data access patterns and be designed with clear performance budgets. For Web3, the RPC layer is that API edge.
Sizing Dedicated RPC Nodes for Real Workloads
We see three broad RPC node classes:
Core full nodes (per chain)
- 8–16 cores, 64–128 GB RAM
- 2–4 TB of NVMe (or more for archival)
- 1–10+ Gbps ports, depending on chain and use case
High‑throughput RPC nodes (Solana, high‑volume EVM)
- 16–32+ cores, 128–256 GB RAM
- NVMe-only storage, often in RAID for extra IOPS
- 10–40 Gbps ports per node, sometimes higher for Solana/MEV strategies
Indexers and analytics backends
- CPU-heavy, often more RAM than the RPC nodes
- Mixed NVMe + large HDD or object storage
- High east–west bandwidth for ETL and querying
Web3 infra teams increasingly package these roles into microservices running in containers, for cleaner deployment workflows and easier rollbacks. But the physical envelope—CPU, RAM, NVMe, bandwidth—still comes from the dedicated servers under the cluster.
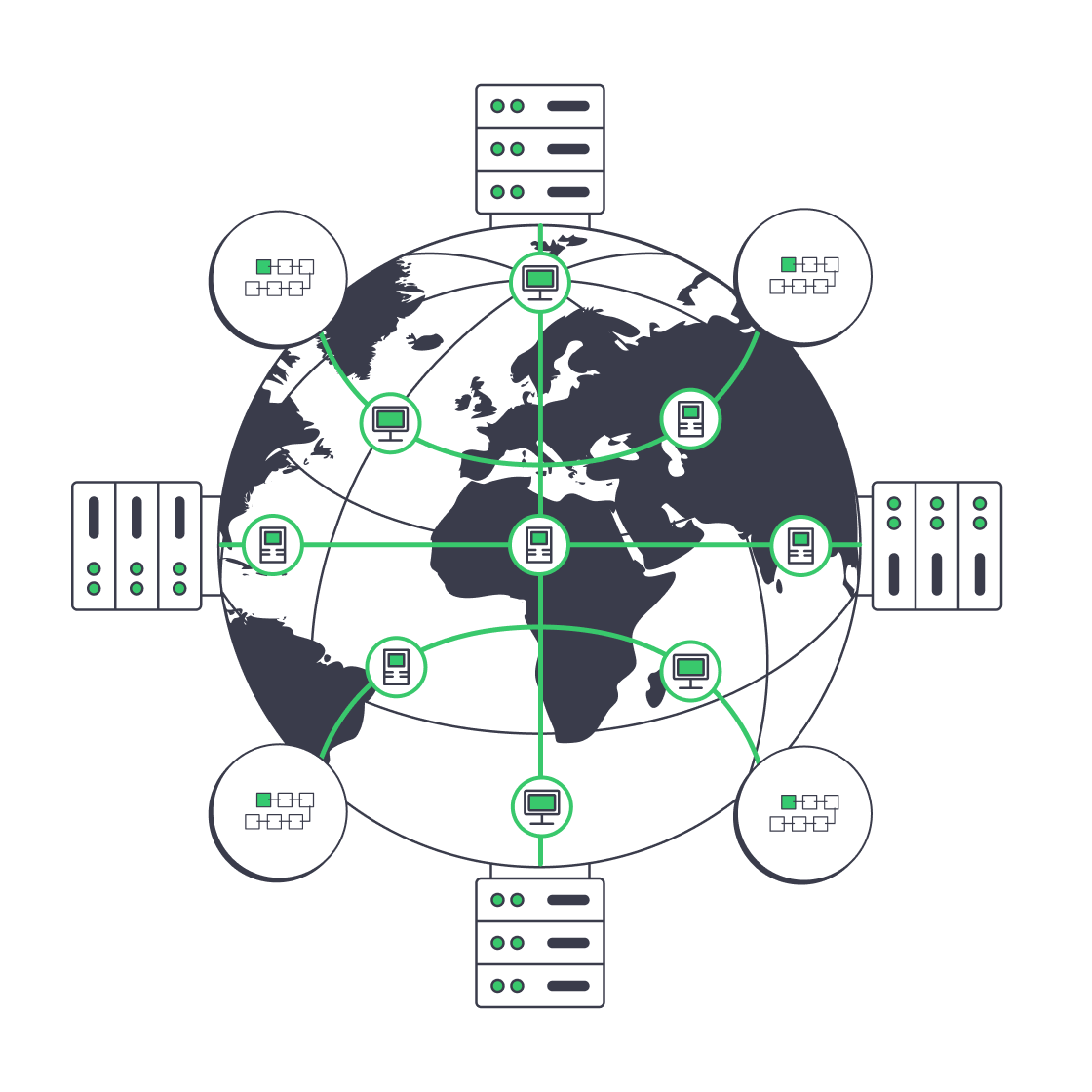
Designing Geo‑Distributed RPC Clusters
Once you can saturate a single node, the next bottleneck is where your nodes live and how clients reach them.
Best practice looks like this:
- At least two regions per major chain you depend on (for example, Western Europe + US East for Ethereum; plus Asia for truly global apps).
- Local RPC for latency‑sensitive paths—trading engines, orderbooks, and latency‑critical DeFi flows should hit the closest regional cluster.
- Global routing and failover, using DNS, an L7 load balancer, or BGP anycast, so that if one region degrades, traffic drains to healthy nodes without changing client code.
If an API (including RPC) doesn’t have clear p95/p99 latency budgets, uptime targets, and error‑rate thresholds, it’s a liability. Web3 teams add chain-specific signals—slot times, reorgs, mempool depth—to the same observability graph.
A typical routing pattern we see:
- North American users → RPC nodes in Atlanta and Los Angeles
- European users → RPC nodes in Amsterdam and Frankfurt or Warsaw
- Asian users → RPC nodes in Singapore and Tokyo**
With Melbicom, those regions map to 21 data centers across Europe, the Americas, Asia, Africa, and the Middle East, with per‑server ports from 1 Gbps up to 200 Gbps.
Security, API Design, and Observability Around RPC
Security research on Web3 supply chains calls out RPC endpoints explicitly: compromised node infrastructure or RPC gateways can feed falsified state to thousands of dApps at once. That doesn’t just break availability; it can trick users into signing malicious transactions with valid wallets.
That reality drives a few architectural choices:
- Own at least one RPC path per chain. Even if you rely on managed RPC providers, run your own dedicated nodes as a “ground truth” path for critical ops and monitoring.
- Instrument RPC like any other core API. Collect p95/p99 latency, error codes, method-level throughput, and node sync lag into a single telemetry stack with host metrics.
- Front RPC with a stable API surface. Many teams expose REST or GraphQL APIs to frontends and internal services, then fan out calls to JSON‑RPC behind the scenes. That pattern borrows from modern API design (where GraphQL shines for complex query patterns) while keeping node infrastructure replaceable.
This is where Web3 infra stops being a buzzword and starts looking like production backend engineering plus blockchain expertise.
Comparing Dedicated Servers Suitable for Hosting Web3 Apps and Blockchain Nodes
A good RPC infrastructure stack uses dedicated servers with enough CPU, RAM, NVMe, and bandwidth to keep full and archival nodes, RPC gateways, and indexers in sync—even under spikes. The right setup balances per‑node performance, cluster redundancy, and operational simplicity so that scaling Web3 applications doesn’t mean constantly fighting the infrastructure.
Network and Bandwidth: Why 10–40 Gbps Per Node Matters
For many Web3 applications, the network link—not the CPU—is the first thing to saturate.
High‑throughput chains and latency‑sensitive use cases (market makers, liquid staking, order‑book DEXs) rely on flat, predictable latency and the ability to fan out large volumes of node‑to‑node gossip and user traffic without hitting egress caps. Latency-focused RPC tuning guides point out that every extra 100 ms on the RPC path shows up directly as worse execution prices and more failed transactions.
With Melbicom, that translates into:
- Ports from 1 to 200 Gbps per server, depending on data center
- A backbone above 14 Tbps with 20+ transit providers and 25+ internet exchange points (IXPs), engineered for stable block propagation and gossip performance
- Unmetered, guaranteed bandwidth (no oversubscription ratios), which is crucial when RPC traffic spikes during mints, liquidations, or airdrops
For most RPC nodes, 10 Gbps is a comfortable baseline; 25–40 Gbps ports make sense for Solana and for multi‑tenant RPC clusters serving many internal services.
Storage and State Growth: NVMe Is Non‑Negotiable
EVM archival nodes, Solana RPC nodes, and indexers all punish slow storage. NVMe is becoming mandatory for running Polygon, Ethereum, and similar nodes, not an optimization (especially for archival or tracing workloads). On top of that, indexing pipelines and analytics workloads add their own databases, column stores, and caches.
A practical pattern:
- Hot state and logs on NVMe (2–8 TB per node, often more for archival)
- Cold archives and snapshots in object storage, such as S3-compatible buckets, plus a CDN for distributing snapshots to new nodes and remote teams
- Periodic state snapshots to accelerate resyncs after client bugs or chain rollbacks
Melbicom’s S3-compatible object storage, for example, runs out of a Tier IV Amsterdam data center with NVMe‑accelerated storage and is explicitly positioned as a home for chain snapshots, datasets, and rollback artifacts, with no ingress fees. That aligns well with how mature Web3 teams handle backup, disaster recovery, and reproducible environments.
CPU, RAM, and Virtualization Choices
Finally, there’s the compute envelope. The industry has mostly converged on a few norms:
- Validators and RPC nodes: run on single‑tenant dedicated servers, not on shared VMs, to avoid noisy neighbors and unpredictable I/O throttling.
- Indexers, ETL, and analytics jobs: often containerized and orchestrated as microservices, but still benefit from high‑core dedicated hosts.
- Dev and staging environments: can live on smaller dedicated servers or on cloud virtual machines, but should mirror production topology closely enough to catch performance regressions.
From a cost and operational perspective, the healthiest pattern is using dedicated servers for anything that touches chain state or user transactions directly (RPC, validators, bridges, oracles), and reserve generic cloud elasticity for bursty or experimental workloads.
Who Offers Reliable Servers for Web3 and RPC Infrastructure?
Reliable RPC and Web3 infrastructure comes from providers that focus on single‑tenant servers, global low‑latency networking, and tooling built for validators, RPC nodes, and indexing workloads—rather than generic cloud instances. You want a partner that can supply thousands of cores, dozens of regions, and high‑bandwidth ports without introducing rate limits or per‑GB egress surprises that mirror the very public endpoints you’re trying to escape.
Web3‑Focused Server Footprint and Bandwidth
We at Melbicom built our Web3 server hosting platform around exactly these constraints.
Melbicom operates 21 Tier III/IV data centers across Europe, the Americas, Asia, Africa, and the Middle East, with ports up to 200 Gbps per server, depending on location. The global backbone exceeds 14 Tbps, backed by 20+ transit providers and 25+ IXPs, giving Web3 apps the routing diversity and peering depth they need to keep RPC and validator traffic stable under load.
On top of that, Melbicom runs an enterprise CDN delivered through 55+ PoPs in 36 countries, optimized for low TTFB and unlimited requests. That matters directly for Web3 applications distributing frontends, NFT assets, proofs, or rollup snapshots close to users.
For RPC infrastructure specifically, this translates into:
- Web3 server hosting configurations tuned for validators, full/archival nodes, and indexers, with more than 1,300 ready‑to‑go dedicated servers activated in 2 hours
- Custom server builds that can be deployed in 3–5 business days, for specialized high‑RAM, GPU, or storage‑heavy setups
- BGP sessions (including BYOIP) available in every data center, allowing anycast or fast failover for RPC endpoints and validator IPs without changing client configuration.
With Melbicom you keep full control over clients, smart contracts, and application code, while we handle the physical layer and global routing.
Owning the RPC Layer as Web3 Scales

The last few years have made one thing clear: Web3 systems are only as decentralized as their invisible dependencies. Public RPC endpoints with tight rate limits, single‑region deployments, and opaque third‑party infrastructure all create hidden centralized failure points. When they fail, users don’t see consensus breaking—they see their favorite Web3 applications freeze.
At the same time, research on Web3 software supply chains highlights the risk of delegating too much trust to third‑party RPC layers: a compromised endpoint can subtly manipulate balances, transaction histories, or contract state in ways that are hard to detect but catastrophic in impact.
Owning your RPC infrastructure on dedicated servers doesn’t mean ignoring managed services or decentralized networks. It means using them on your terms, behind an architecture that assumes any one provider, network, or region can fail without taking your application down.
Practical Recommendations for RPC Infrastructure
To turn that philosophy into an actionable roadmap:
- Plan around the end‑to‑end latency, not just gas. Budget for latency from UI → API → indexer → RPC → chain and place latency‑sensitive components in the same region on similarly performant dedicated servers.
- Run your own nodes alongside 3rd‑party RPC. Treat self‑hosted full/archival nodes as both a production path and a reliable observability probe against external providers.
- Design for multi‑region by default. Start with at least two regions per critical chain and make region failover an early design decision, not an afterthought.
- Instrument RPC like a product, not a utility. Track method‑level throughput, error codes, node sync lag, and p95/p99 latency; correlate those metrics with chain conditions and user‑level incidents.
- Use CDN + object storage for snapshots and assets. Keep chain snapshots, rollbacks, and heavy datasets in S3‑compatible storage, and front user‑facing assets with a CDN so RPC nodes focus on signing and state reads, not static file serving.
These practices give you an RPC layer that behaves like any other well‑run production platform: observable, resilient, and predictable under stress—without sacrificing the decentralization properties that make Web3 worth building on in the first place.
Melbicom’s Dedicated Servers for Web3 RPC Infrastructure
If you’re planning the next iteration of your RPC infrastructure—whether that’s a Solana RPC cluster, Ethereum or BNB Chain archival nodes, or multi‑region indexers—Melbicom’s dedicated servers, global backbone, CDN, S3 storage, and BGP sessions are built to support that design. With 21 Tier III+ data centers, 1,300+ ready‑to‑go configurations, ports up to 200 Gbps per server, and 55+ CDN PoPs across 36 countries, you can design, test, and scale reliable Web3 infrastructure on hardware that behaves deterministically under load.
Order a Server
Ready to move beyond public endpoints and shared RPC bottlenecks? Order a dedicated server and explore Web3‑focused configurations for validators, RPC nodes, and indexing workloads—or talk with us about a custom build you need.
Get expert support with your services
Blog
Dedicated Servers for dApp Backends and Off-Chain APIs
In Q2 2025, the dApp ecosystem averaged 24.3M daily active wallets, up 247% versus early 2024, according to industry tracking. That’s huge load growth for infrastructure that was never designed to serve interactive user traffic in the way a web or mobile app does.
User expectations, however, are still Web2-fast: Google’s research shows 53% of mobile visitors abandon a site if it takes longer than three seconds to load. If your dApp’s UI is waiting on an overloaded RPC endpoint, a slow indexer, or a congested on-chain call, users don’t care that “the blockchain is busy” – they just leave.
Base-layer constraints make this worse. Ethereum mainnet still processes only around 15 transactions per second, while traditional payment networks comfortably execute thousands of TPS. When popular early dApps like CryptoKitties pushed all logic and metadata on-chain in 2017, they famously congested Ethereum and slowed down unrelated applications. That experiment proved a point: the chain is a consensus engine and settlement layer, not a general-purpose application runtime.
Even “off-chain” isn’t automatically safe. In October 2025, a multi-hour outage in a major US cloud region froze thousands of apps – including Web3 platforms – because too much critical infrastructure depended on a single provider and region. And in November 2020, an outage at a leading Ethereum infrastructure provider rippled through wallets and dApps that had standardized on a single RPC backend.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
We at Melbicom see – modern dApps that feel “instant” to users are almost always hybrid systems: minimal on-chain logic, plus powerful dedicated servers for backends, databases, APIs, indexing, storage, and observability. In this article, we unpack what that hybrid stack looks like in practice and why dedicated servers are such a strong fit for dApp backends.
Decentralization Meets Reality: Why dApps Need Off-Chain Backends
Blockchains are fantastic append-only ledgers; they are terrible primary data stores for interactive applications. Research on blockchain indexing is blunt: chains are optimized for integrity and consensus, not querying – most ledgers store data sequentially, which makes complex queries slow and expensive without specialized indexers.
Protocols like The Graph emerged specifically because directly querying chain state from UIs does not scale. The Graph’s own docs describe it as a decentralized indexing protocol that turns raw blockchain data into subgraphs – structured, queryable APIs dApps can hit using GraphQL instead of scanning blocks themselves. Those subgraphs are not magic; they run on servers, with CPUs, memory, and storage under someone’s ops budget.
The same is true for RPC nodes. They are essentially specialized servers exposing a JSON-RPC surface between your application and the chain. Studies on Web3 infrastructure point out that every interaction – checking a balance, submitting a swap, fetching an NFT list – ultimately travels through RPC nodes that must stay online, current, and low-latency. When those fail, on-chain contracts keep existing, but your app becomes unusable.
Monitoring all this isn’t trivial either. Web3 observability guides highlight that teams must track both classic infrastructure metrics (CPU, RAM, disk IO, p95 latency) and blockchain-specific signals (block times, gas usage, reorgs, mempool depth). Those metrics live in logs, traces, and time-series databases – again, off-chain systems running on servers.
Many protocols now formalize “off-chain agents” as part of their architecture. The Ergo ecosystem, for example, relies on watchers and bots that continuously scan blocks, update databases, and trigger on-chain actions when conditions are met. Bridges, oracle networks, and cross-chain messaging systems follow similar patterns: long‑running services process events in real time and only occasionally commit back to the chain.
- On-chain is slow, expensive, secure, and authoritative.
- Off-chain is fast, flexible, observable, and where most UX and business logic live.
The question is not whether you need an off-chain backend – you already do. The question is what that backend runs on and whether it is architected for the scale and reliability Web3 usage now demands.
Best Backend Services for dApp Management
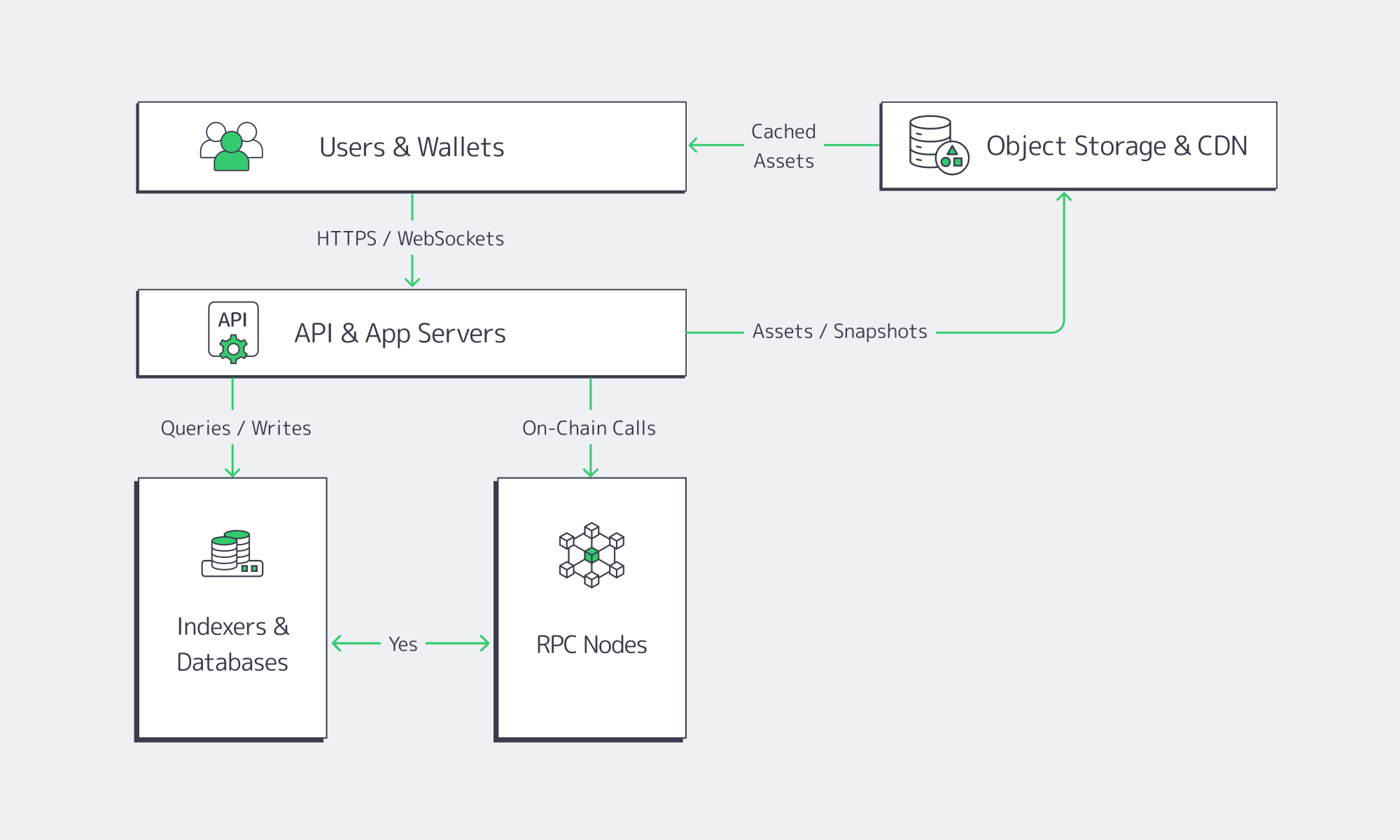
In practice, the best backend services for dApp management share three traits:
- They are close to the chain (low-latency RPC and indexers).
- They are close to the users (global delivery, caching, and storage).
- They run on infrastructure you can understand, observe, and control.
For most teams, that means building dApp backends on high‑performance dedicated servers and layering in specialized services – RPC providers, decentralized storage networks, DePIN, and so on – rather than replacing dedicated infrastructure with them.
What Runs Off-Chain in a Modern dApp Backend
A realistic dApp backend typically includes:
- RPC gateways and full / archival nodes serving JSON-RPC and websockets.
- Indexers and subgraphs that transform blockchain events into queryable views.
- Business-logic APIs (authentication, rate limits, portfolio views, risk rules).
- Job schedulers and bots publishing transactions, refreshing oracle feeds, or monitoring bridge events.
- Databases and caches for user profiles, sessions, non-critical metadata, and analytics.
- Observability stacks (logs, metrics, traces) correlating RPC performance, chain conditions, and app-level incidents.
All of that is “just software,” but it’s software with very particular needs: predictable IOPS and latency, high memory ceilings, fast recovery after a crash or resync, and a lot of network throughput.
Blockchain Infrastructure for Next-Gen dApps
Infrastructure for next‑gen dApps increasingly looks like a hybrid between Web3 protocols and Web2‑style distributed systems:
- Indexing layers – Teams often run their own indexers alongside or instead of public networks like The Graph, using the same ideas: consume chain data once, store it in a fast DB, expose a clean API. Even decentralized indexing still requires CLI tools, build pipelines, and servers to host the indexers themselves.
- Decentralized storage – IPFS, Arweave, and Filecoin store content-addressed blobs across distributed networks. But Web3 storage guides are explicit: you still need gateways, pinning services, and caching layers to make this usable in real-time applications. Typically, that means pairing decentralized storage with S3-compatible object storage and a CDN for hot assets – all hosted on robust server infrastructure.
- RPC and node fleets – setting up blockchain nodes requires certain hardware requirements: multi-core CPUs, large RAM, SSD or NVMe storage, and high-speed 1–10+ Gbps networking, especially for full or archival nodes. Those profiles line up extremely well with dedicated servers that we deliver at Melbicom.
dApp infrastructure maintenance is the ongoing work of keeping this stack patched, upgraded, observant, and ready for protocol changes. That work is drastically easier when the underlying platform is predictable single-tenant hardware instead of opaque shared virtual machines.
Comparing Dedicated Server Options Suitable for Scalable dApp Infrastructure
For most production dApps, the most scalable option is single-tenant dedicated servers with SSD or NVMe storage, high-bandwidth ports, and direct networking features such as BGP and private links. Virtual machines and serverless still help at the edges, but latency‑sensitive RPC, indexers, and APIs tend to belong on dedicated hardware.
As dApps mature, the architecture conversation usually isn’t “on-chain vs off-chain”; it’s “how much do we run on dedicated servers, and how do we combine them with managed services and decentralized networks?” The table below sketches typical patterns:
| Use Case | Pure On-Chain Approach | Hybrid With Dedicated Servers (Recommended) |
|---|---|---|
| Simple DeFi farm / staking UI | Contracts hold state; front-end reads directly via shared RPC. | Contracts stay minimal; API and indexer on dedicated servers handle positions, rewards history, and analytics. |
| NFT marketplace | All metadata on-chain; client queries chain directly. | Contracts store identifiers; metadata, search, and recommendations live in DBs and indexers on dedicated servers, fronted by CDN. |
| Cross-chain bridge or oracle | On-chain light clients only. | Off-chain watchers, relayers, and risk engines run on dedicated servers across regions, with occasional on-chain commitments. |
Dedicated infrastructure also plays a key role in DePIN and decentralized compute. Emerging reports show decentralized physical infrastructure networks can significantly undercut hyperscale cloud pricing – in some cases by up to 85% – and are projected by the World Economic Forum to reach trillions in value by 2028. But these networks still depend on physical servers; they are another layer in the stack, not a replacement for operating your own backbone for mission-critical workloads.
The pragmatic pattern we see: teams run core dApp backends, RPC, and indexers on dedicated servers, then selectively integrate decentralized compute or storage where it aligns with their risk and cost models.
Who Provides Reliable Servers for Running dApp Backends?

Melbicom focuses on dedicated infrastructure for Web3: single-tenant servers in 21 Tier III/IV data centers, a global backbone above 14 Tbps, and a CDN with 55+ PoPs across 36 countries. Combined with S3-compatible storage and 24/7 support, this gives dApp teams a predictable, latency-optimized platform for backends.
We designed our platform specifically around the workloads described above:
- Global footprint, local latency – Web3-ready configurations are available across 21 data centers in Europe, the Americas, Asia, Middle East, and Africa.
- Network tuned for blockchain – A backbone with more than 14 Tbps of capacity, over 20 transit providers, and 25+ internet exchanges is engineered to keep block propagation, gossip, and RPC traffic stable.
- Capacity when you need it – Web3 teams can choose from more than 1,300 ready-to-go server configurations, with custom builds delivered in 3–5 business days. This mix lets you spin up testnets quickly and then migrate to bespoke GPU, high-memory, or high‑storage configurations as projects grow.
- Integrated delivery and storage – An enterprise CDN with 55+ PoPs and unlimited requests, plus S3-compatible object storage in a Tier IV Amsterdam data center, makes it straightforward to ship dApp frontends, snapshots, proofs, and NFT assets close to users while keeping authoritative copies on resilient storage.
In practice, teams often run dApp backends on our servers, while also integrating multiple third-party RPC providers for redundancy. Unmetered, guaranteed bandwidth and stable IPs make it feasible to keep self‑hosted RPC, indexers, and subgraphs in the loop without unpredictable egress bills or IP changes.
Because Melbicom focuses on the infrastructure layer – servers, networking, CDN, S3 storage, and BGP – your team keeps full control over node clients, smart contracts, and app code. That aligns well with the operational reality many Web3 teams want: sovereign control over critical infrastructure, without having to also build data centers and global networks from scratch.
Conclusion: Hybrid Infrastructure Is How dApps Reach Scale

The last few years have been a stress test for Web3 infrastructure. Congested chains, RPC outages, and centralized cloud incidents all exposed the same weakness: if your “decentralized” application depends on a single region, a single provider, or a single endpoint, users will discover that weakness at the worst possible time.
At the same time, the core blockchain model is not going away. On-chain consensus is still the best tool we have for global, tamper-resistant state. The way forward is not to push everything into smart contracts, but to treat the chain as the final source of truth and surround it with robust, observable, regionally distributed off‑chain infrastructure.
Dedicated servers, global networks, CDNs, and S3-compatible storage are the pieces that let you build that hybrid model with the determinism and performance users expect.
Practical Takeaways for dApp Backends
- Design around end-to-end latency, not just gas. Map the full request path – UI → API → cache → indexer → RPC – and place latency-sensitive components (RPC, indexers, APIs) in the same region and on similarly performant dedicated servers.
- Run your own critical infrastructure, even if you use managed services. Use multiple RPC providers plus self‑hosted nodes, and design failover so no single provider can take your dApp offline.
- Invest early in observability. Capture metrics for block times, gas costs, RPC error rates, node sync lag, and p95/p99 API latency. Correlate them so you can distinguish chain-level issues from infrastructure or code regressions.
- Treat indexing and storage as first-class concerns. Whether you use decentralized indexing protocols or roll your own, budget dedicated servers and S3/object storage for subgraphs, search indexes, and historical analytics – and front them with a CDN for user-facing workloads.
- Adopt decentralized compute and storage incrementally. DePIN and decentralized storage networks can meaningfully cut costs and reduce centralization, but they still sit atop physical servers. Start by offloading appropriate workloads (e.g., archives, non-critical compute) while keeping core dApp backends on infrastructure you can control.
Taken together, these practices get you close to the original Web3 vision – applications that remain usable and trustworthy even when individual components fail – without sacrificing the performance and observability today’s users demand.
Scale Your dApp Backend on Dedicated Servers
Build low‑latency RPC, indexers, and APIs on single‑tenant hardware with global bandwidth and S3 storage. Explore configurations or request a custom build for your Web3 stack.
Get expert support with your services
Blog

Make IP Space Portable With BYOIP, BGP And RPKI
The global border gateway protocol routing table now carries roughly 950,000–1,000,000 IPv4 prefixes, adding more than 50,000 new entries in 2024 alone.
In parallel, over half of all routes are now covered by RPKI Route Origin Authorisations (ROAs), and an estimated 74% of traffic flows toward prefixes protected by RPKI.
That scale and shift toward cryptographic validation are changing how serious operators think about address space. Public cloud egress still commonly costs $0.08–$0.12 per GB; a multi‑region database that replicates just 100 GB/day between three regions can burn through about $30,000 per year in transfer fees alone. Moving workloads between providers or regions without changing IPs—and without breaking reputation or access controls—starts to look less like a luxury and more like risk management.
Industry guidance on IP transit and addressing is clear: provider‑independent (PI) space + an autonomous system number (ASN) gives you portability and the ability to multi‑home; provider‑assigned space ties you directly to an ISP’s routing and commercial terms.
In this article, we combine those industry trends with what we at Melbicom see (running BGP sessions and dedicated servers across 21 Tier III/IV data centers, backed by 20+ transit providers, 25+ IXPs, and a CDN with 55+ PoPs. You’ll get a practical blueprint for:
- The prerequisites and workflow for BYOIP using border gateway protocol BGP
- How BYOIP compares to renting provider IPs
- The security controls that matter now that RPKI and IRR filtering are mainstream
- A concrete border gateway protocol configuration example you can adapt
Choose Melbicom— BGP sessions with BYOIP — 1,300+ ready-to-go servers — 21 global Tier IV & III data centers |
|
What Is the Main Purpose of BGP in Computer Networks?
The border gateway protocol (BGP) is the Internet’s inter‑domain routing protocol. Its main purpose is to let autonomous systems exchange reachability information and select paths based on policy, not just distance. That’s what enables multi‑homing, traffic engineering across transit providers, and global reachability for your own IP space.
Under the hood, BGP is a policy engine. Each autonomous system (AS) advertises IP prefixes it can reach, attaching attributes like AS_PATH, local preference, and MED. These attributes let operators express business and technical policies—prefer cheaper transit, avoid certain countries, keep local traffic on local links vs. just “shortest path wins.”
In practical terms, border gateway routing protocol sessions between your ASN and your upstreams are how you turn address space into a globally reachable, multi‑homed asset. For BYOIP, that’s exactly the mechanism you use to make your own prefixes visible at scale.
BYOIP Prerequisites and Workflow: From Allocations to Global Reach
At a high level, BYOIP means: you own the addresses, you originate them from your ASN, and your infrastructure provider re‑announces them through its edge. Getting there is a four‑part workflow.
1. Own an ASN and Provider‑Independent Prefixes
You need:
- A public ASN from your regional internet registry
- Provider‑independent (PI) IP blocks, typically at least a /24 in IPv4 and /48 in IPv6
PI space is assigned directly to your organization by an RIR and is portable across providers; PA space is allocated by an ISP, is typically aggregated within their larger block, and can’t follow you when you change providers.
That portability is the foundation of BYOIP: the same prefixes can be originated from different data centers, different providers, or both. It does, however, commit you to running BGP border gateway protocol sessions somewhere in your stack—on your own routers, on dedicated servers, or both.
2. Publish IRR Route Objects and AS‑SETs
Internet Routing Registries (IRRs) are DBs that describe which AS is authorized to announce which prefixes (ROUTE/ROUTE6 objects), and which ASNs belong to a given organization (AS‑SETs). They’re still widely used by transit providers for prefix‑list and filter generation.
For BYOIP with Melbicom, the operational baseline is:
- Each prefix has a correct, current ROUTE/ROUTE6 object referencing your ASN
- You maintain an AS‑SET that lists your customer or internal ASNs
- IRR data is present in major DBs like RIPE, ARIN, APNIC, AFRINIC, LACNIC, RADB, or IDNIC
Melbicom validates customer prefixes against these IRRs and only accepts announcements that match published objects. It’s a straightforward step that dramatically reduces accidental route leaks and spoofed announcements.
3. Secure Routes with RPKI
IRRs are useful, but they’re essentially signed with a password. RPKI adds cryptographic proof that the holder of a prefix has authorized a specific ASN to originate it.
Using your resource certificate from the RIR, you create ROAs (Route Origin Authorisations) that state:
- Prefix (and maximum prefix length)
- Authorized origin ASN
When other networks perform BGP Origin Validation, each route targeting your prefix is classified as: VALID, INVALID, or UNKNOWN, depending on how it lines up with your ROAs.
RIPE and MANRS both now treat RPKI deployment as table‑stakes routing hygiene, and more than half of global IPv4 and IPv6 routes are RPKI‑covered. LACNIC’s guidance is clear: prefix holders—not transit providers—are responsible for creating ROAs, and multi‑homed prefixes can authorize multiple origin ASNs if needed.
Two practical rules for your RPKI setup:
- Keep max‑length fields tight (e.g., /24 on a /24) to avoid unintentionally blessing over‑specific hijacks
- Treat ROA management as part of change control whenever you add regions/providers
Melbicom enforces RPKI origin validation and rejects announcements with INVALID status, so ROAs are not optional in a BYOIP workflow.
4. Establish a BGP Session with Melbicom
With IRR and RPKI in place, the next step is to bring up one or more BGP sessions between your router and Melbicom’s edge.
Operationally, that means:
- You run a BGP daemon (BIRD or FRRouting are common choices) on a dedicated server or edge appliance
- We at Melbicom provision a BGP peering in the requested data center(s) for your ASN
- You export only your authorized prefixes; we import them after IRR and RPKI checks and propagate them to transit and peering neighbors
Melbicom offers free BGP sessions on dedicated servers, with IPv4 and IPv6 support and up to 16 prefixes per session by default. We also support full, default‑only, or partial route feeds, and BGP communities you can use to influence how we advertise your routes upstream, including which transit providers receive them and how they are prioritized.
5. Announce via Melbicom’s Global Edge
Once your prefixes are accepted, we re‑announces them from a globally distributed edge:
- 21 Tier III/IV data centers across the Americas, Europe, Asia, and Africa
- Per‑server bandwidth options up to 200 Gbps, depending on location
- A backbone with 20+ transit providers and 25+ IXPs, tuned for short, stable paths
- A CDN with 55+ PoPs in 35+ countries to keep content close to users
From your perspective, this means your PI space keeps its reputation and access lists while your workloads move between Melbicom locations or grow into multi‑region architectures. Combine that with BGP communities for provider and region preference (a pattern widely used in operator backbones), and you can dial in how traffic enters your network at a fairly granular level—without ever surrendering ownership of the addresses.
BYOIP vs. Provider‑Assigned IPs
From a distance, both BYOIP and renting IPs end in the same place: packets flow. But the economic and operational profiles are almost opposites. Guidance on PI vs. PA space from operator‑focused sources all lands on the same trade‑off: PA is simpler and cheaper; PI plus border gateway protocol buys you control and portability.
Here is a condensed comparison for planning purposes:
| Decision Factor | Provider‑Assigned IPs (PA) | Bring Your Own IPs (PI + BGP) |
|---|---|---|
| Ownership & Lock‑In | Addresses belong to provider; renumbering required when you leave. | Addresses belong to you; portable across providers and regions. |
| Migration & Multi‑Cloud | DNS changes, TTL tuning, and gradual cutovers every time you move. | Same prefixes follow workloads; DNS changes become optional or minimal. |
| Security & Reputation | Reputation tied to provider’s overall hygiene and other tenants. | You control RPKI, IRR, and abuse handling for long‑lived, “clean” ranges. |
| Operational Overhead | No BGP required; provider handles routing. | Requires BGP expertise and ongoing border gateway protocol configuration hygiene. |
| Best Fit | Single‑provider, regional, or cost‑sensitive deployments. | Multi‑cloud, multi‑region, or compliance‑sensitive systems with long planning horizons. |
If you already operate an ASN and PI space, the marginal cost of BYOIP over Melbicom’s edge is almost entirely operational—getting the routing right once and keeping it clean.
What Are the Main Security Considerations for BGP?

BGP was designed for a smaller, more trusting Internet. The main security issues are route hijacks, route leaks, and plain misconfiguration that causes traffic to be mis‑routed or black‑holed. Modern best practice combines IRR filtering, RPKI origin validation, prefix‑limit controls, and careful policy design to mitigate these risks.
Even with RPKI adoption crossing the 50% mark, real‑world incidents show how fragile global routing can be. Datasets built from BGP‑monitoring tools record thousands of anomalies—many accidental, some malicious—impacting major technology firms and even government networks.
For BYOIP deployments, a secure posture typically includes:
- RPKI and IRR at the same time. IRR data is still widely used to build prefix filters; RPKI adds cryptographic checks and standardized VALID/INVALID/UNKNOWN states.
- Tight export policies. Your routers should only ever announce your PI prefixes and, where relevant, any customer prefixes you’ve explicitly agreed to originate.
- Inbound route filtering and max‑prefixes. Protect your own infrastructure from a misbehaving upstream and from accidental full‑table floods. Operator BCPs emphasize that the main scalability pressure on BGP is the growth of the routing table and churn from updates; enforcing sensible limits is table stakes.
- Conservative use of BGP communities. Communities are powerful for traffic engineering and provider selection; widespread measurement shows that most global prefixes now carry at least one community tag. Melbicom supports both our own and pass‑through communities but does not offer BGP blackhole services, keeping policies focused on routing rather than DDoS signaling.
For our part, Melbicom runs RPKI‑validated routing, strict IRR filtering across all major registries, and controlled acceptance of more‑specific routes (only /24s that are individually registered), which significantly reduces the risk of hijacks propagating through our edge.
BGP Configuration Example
At a high level, a BYOIP border gateway protocol configuration does three things: establishes a session with your provider, originates your prefixes, and applies import/export filters. The example below uses BIRD, which is what many Melbicom customers run on dedicated servers. It assumes you already have your PI prefix on eth0.
| # /etc/bird/bird.conf (IPv4) router id X.X.X.X; # Your server’s IPv4 protocol static static_byoip { route YOUR.PREFIX.IP/MASK via “eth0”; } protocol bgp melbicom_ipv4 { local as YOUR_ASN; neighbor X.X.X.X as MELBICOM_ASN; # Provided by Melbicom import all; # Or add filters here export where net ~ [ YOUR.PREFIX.IP/MASK ]; next hop self; } |
| # /etc/bird/bird6.conf (IPv6) router id X.X.X.X; # Still an IPv4 address protocol static static_byoip_v6 { route YOUR:V6::/MASK via “eth0”; } protocol bgp melbicom_ipv6 { local as YOUR_ASN; neighbor XXXX:XXXX::1 as MELBICOM_ASN; import all; export where net ~ [ YOUR:V6::/MASK ]; next hop self; } |
From there, you can extend the configuration with BGP communities for traffic engineering—tagging routes to prefer certain upstreams, limit propagation, or steer traffic via specific regions, mirroring the patterns documented in operator training materials.
Key Takeaways: Why BYOIP with BGP Is Worth the Effort
If you already hold PI space and an ASN, treating those addresses as a strategic asset rather than just plumbing changes how you build infrastructure. Based on industry data and what we see in production environments, a few practical recommendations emerge:
- Align IP strategy with multi‑region reality. Latency‑sensitive and regulated workloads increasingly span regions, and even small amounts of cross‑region traffic can become a major line item at public‑cloud egress prices. BYOIP over BGP lets you move or duplicate workloads without repeatedly paying in downtime and address churn.
- Make RPKI and IRR first‑class citizens. With more than half of global routes now RPKI‑covered, failing to publish ROAs and maintain IRR objects is no longer a harmless omission—it’s a security and reachability risk. Build ROA and IRR updates into your normal deployment and change‑management processes.
- Invest once in routing expertise, reap benefits for years. Standing up robust border gateway protocol routing—with filters, communities, prefix‑limits, and monitoring—takes time, but the payoff is cumulative: every future migration, new region, or new provider is easier because your IP space is already portable.
- Choose providers that amplify, not dilute, your control. BYOIP only delivers if upstreams respect RPKI and IRR, give you useful BGP community hooks, and operate a well‑peered, low‑latency edge. Look for clear documentation of filtering policies, RPKI support, and route‑control options—not just raw bandwidth numbers.
Turn Routing into a Strategic Capability
The combination of PI address space, an ASN, and a well‑designed border gateway routing protocol deployment turns IP addressing from a sunk cost into a strategic lever. Instead of re‑numbering every time you change providers, you re‑pin BGP sessions. Instead of accepting whatever path your upstream picks, you use communities and policy to shape how traffic enters and leaves your network.
As routing tables grow and RPKI deployment crosses critical thresholds, the gap between “best effort” and “engineered” Internet connectivity is widening. Operators who treat BGP as a first‑class system—complete with security controls, telemetry, and clear ownership—will be able to adopt new regions, hardware generations, and commercial models without renegotiating their identity on the network. BYOIP is the natural endpoint of that mindset.
Deploy BYOIP on Melbicom’s Global Edge
Announce your own prefixes over free BGP sessions on dedicated servers worldwide. Keep reputation, reduce migrations, and steer traffic with communities.