Month: August 2025
Blog

Why Dedicated Server Hosting Is the Gold Standard for Reliability
Digital presence and revenue go hand in hand in the modern world, and as such, the concept of “uptime” is no longer simply a technical metric; it is now a critical business KPI. When literally every second of availability counts, you have to be strategic when it comes to infrastructural choices, and although the solutions have broadened as the hosting landscape has evolved over the years, dedicated server hosting remains the definitive gold standard when it comes to unwavering reliability without compromise.
Though appealing for many reasons, multi-tenant environments often have an underlying compromise in terms of predictability; they are subject to service disruption, degradation, and failure that the dedicated model evades and trumps simply by being isolation-based. This isolation means it can provide a stable, resilient foundation that is structurally immune to the challenges that shared systems face. To fully understand why dedicated is still considered the gold standard, we need to dive deeper than a surface-level analysis of the architectural and operational mechanics and look to the specific resilience techniques that are preventing downtime and helping clients meet availability targets head-on.
Resource Contention: The Invisible Shared Infrastructure Threat
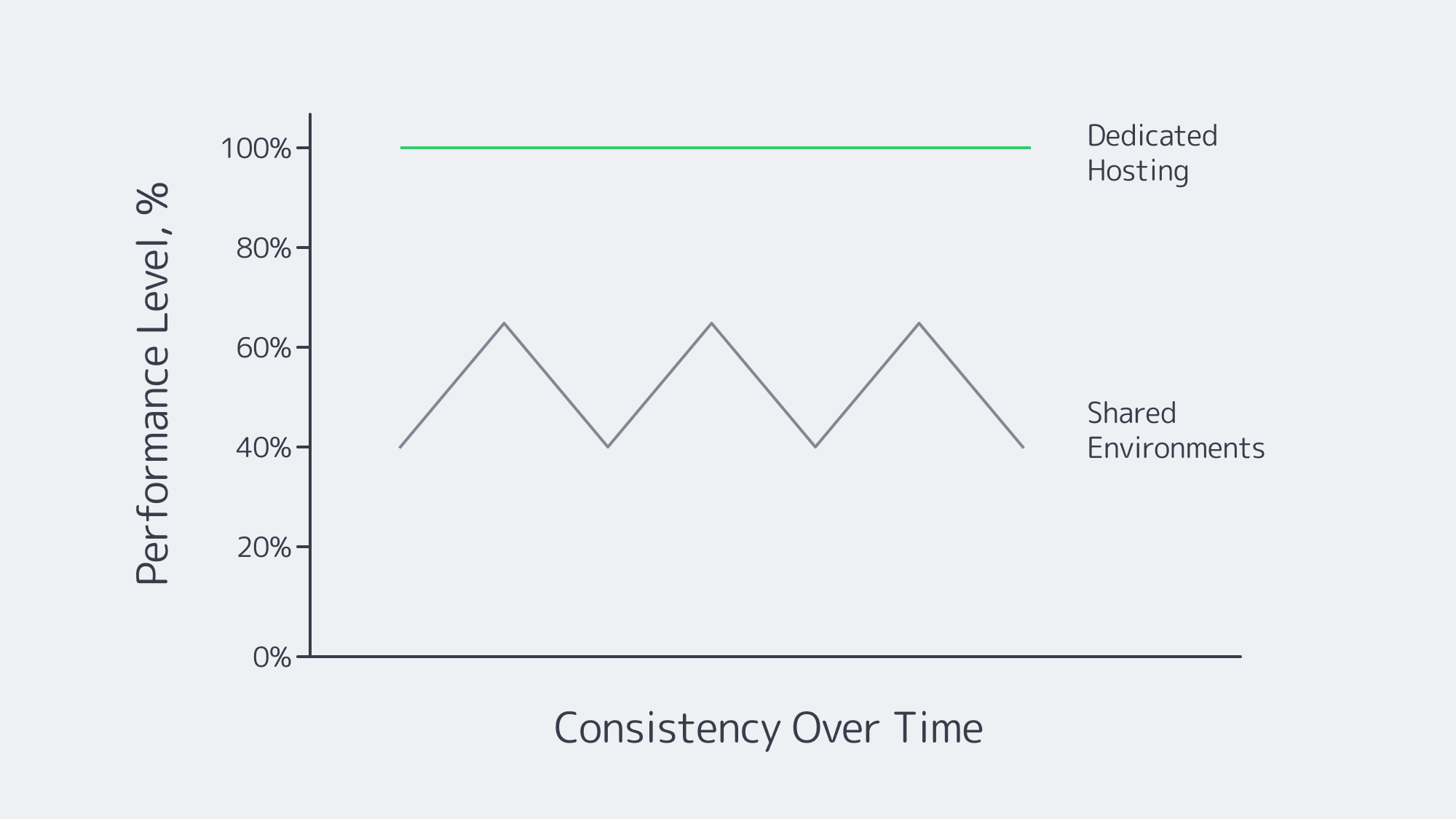
When multiple tenants reside within a shared or virtualized hosting environment on a single physical machine, they share the same resource pool. CPU, RAM, and I/O resources are essentially a “free-or-all,” which creates the “noisy neighbor” effect. The unpredictable workload demands of a single tenant can degrade the performance of everyone else relying on the same hardware because a high-demand workload consumes the resources disproportionately.
Demanding operations, with unpredictable high traffic surges such as e-commerce, will monopolize disk I/O during activity spikes, resulting in fluctuations and even a halt to critical database applications for other businesses. If your enterprise requires high availability and your workloads are mission-critical, then these unpredictable and uncontrollable performance fluctuations are more than merely an inconvenience; they are a risk you simply cannot afford to take.
The risk is eliminated altogether by leveraging the exclusive hardware that a dedicated server solution provides. As a sole tenant, all CPU cores, all gigabytes of RAM, and the full I/O bandwidth of the disk controllers are yours, which equals high performance that is consistent and predictable.
Predictability as Foundation
Performance predictability is the foundation of reliability, and a dependable performance is needed for applications such as real-time data processing and financial transactions, as well as the backend for critical SaaS platforms. Without consistent throughput and latency, these critical and time-sensitive operations can be costly. Shared and virtual environments add layers of abstraction and contention that are removed by choosing a dedicated server to host, guaranteeing smooth operations.
Virtual machines (VMs) are managed by hypervisors, which also introduce a small but measurable overhead with each individual operation. Granted, it is more or less negligible in instances where tasks are low intensity, but when it comes to I/O-heavy applications, it can become a significant performance bottleneck. This is once again prevented with a dedicated server, as the operating system runs directly on the hardware, and there is no “hypervisor tax” to contend with.
In a practical context, the raw, direct hardware access provided by dedicated servers is the reason they remain the platform of choice when millisecond-level inconsistencies are crucial, such as high-frequency trading systems, large-scale database clusters, and big data analytics platforms.
Resilient Hardware and Infrastructure: The Bedrock of Uptime
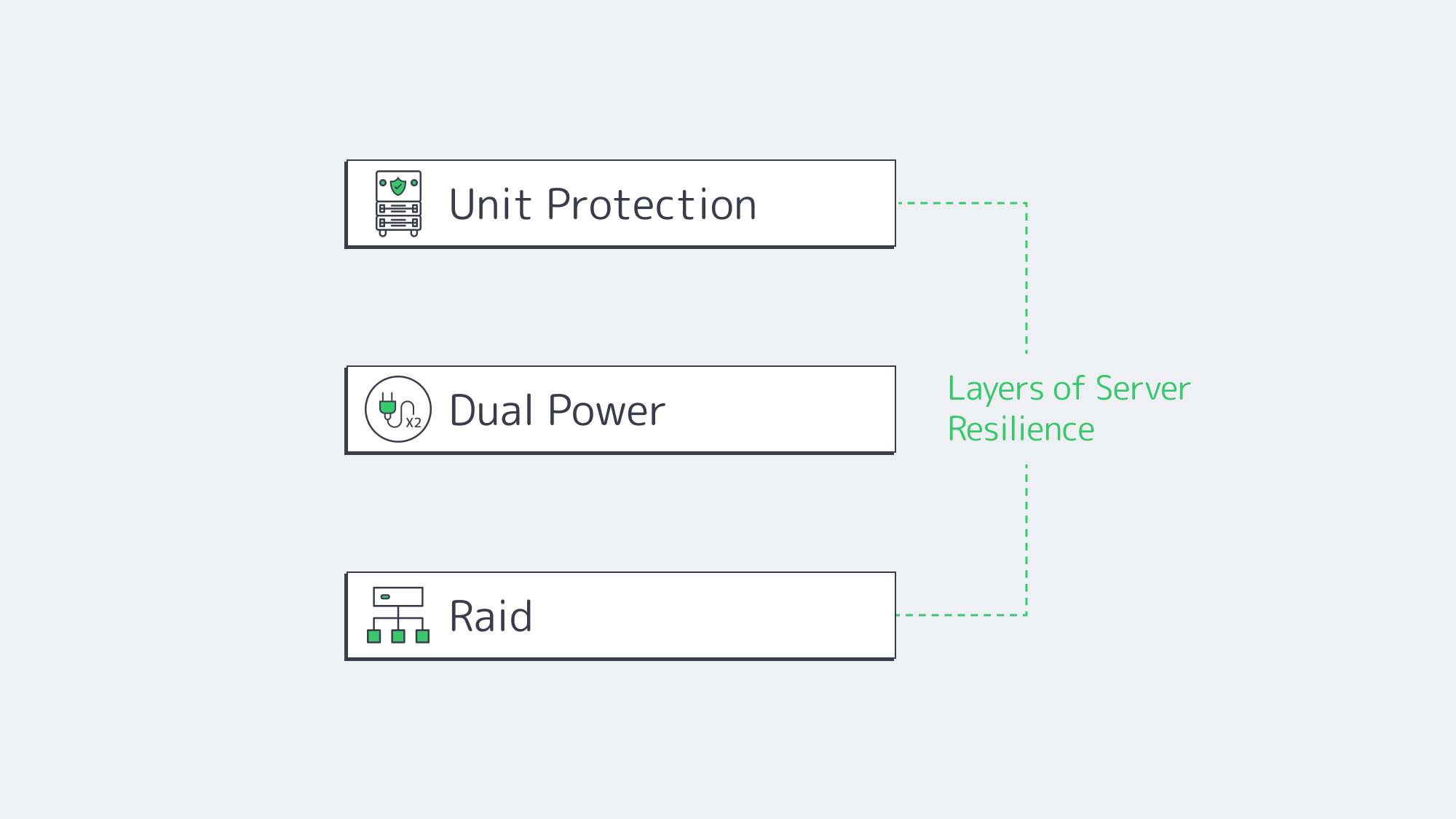
True reliability is engineered in layers, starting with the physical components as the foundation. With a dedicated server, you have the backbone to structure and bolster the resilience of the data center environment itself with features that shared platform models often abstract.
RAID for Data Integrity
Uptime metrics are also dependent on data integrity. Considering that a single drive failure can lead to catastrophic data loss and downtime, combining multiple physical drives into a singular unit through Redundant Array of Independent Disks (RAID) is essential to performance.
Dedicated servers utilize enterprise-grade RAID controllers and drives capable of 24/7 operation. Below are two popular configurations:
- RAID 1 (Mirroring): Writes identical data to two drives; if one fails, the mirror keeps the system online while the failed disk is replaced and the array rebuilds (redundancy, not backup).
- RAID 10 (Stripe of Mirrors): Provides high performance and fault tolerance by combining the speed of striping (RAID 0) with the redundancy of mirroring (RAID 1), ideal for critical databases.
With the ability to specify the exact RAID level and hardware, businesses have the advantage of being able to tailor their data resilience strategy to their specific application needs.
Preventing Single Points of Failure Through Power and Networking
Problems with a single component can also affect hardware redundancy, whether it’s a PSU issue or a network link. This risk is once again mitigated when choosing an enterprise-grade dedicated server:
- Dual Power Feeds: By equipping two PSUs, each with an independent power distribution unit (PDU), you have a failsafe should an entire power circuit fail.
- Redundant Networking: Continuous link availability can be achieved by configuring multiple network interface cards (NICs). Network traffic can be rerouted seamlessly through active remaining links if one card, cable, or switch port fails.
These redundant system features are key to architecting truly reliable infrastructure and are provided by Melbicom‘s servers, housed in our Tier III and Tier IV certified facilities in over 20 global locations.
Continuous High Availability Architecture
If your goal is performance reliability that sits in the upper echelon, then that single server focus needs to be switched to architecture resilience. Running multiple servers through high-availability (HA) clusters created on a dedicated server keeps service online even in the case of a complete server failure.
This can be done with an active-passive model or active-active, as explained below:
Active-Passive: A primary server actively handles traffic and tasks, while a second, identical passive server monitors the primary’s health on standby. Should the primary fail, the passive automatically kicks in as a failover, assuming its IP address and functions, making it ideal for databases.
Active-Active: In this model, all servers are online, actively processing traffic, and the requests are distributed between them via a load balancer. If it detects a server failure, it removes it from the distribution pool and redirects the traffic and tasks accordingly. This keeps availability high and helps facilitate scaling.
These sophisticated architectures provide the resilience needed for consistently high performance but require deeper hardware and network control, which is only achievable within the exclusive domain of dedicated server hosting.
Building the Future of Reliable Infrastructure with Melbicom

The strategic advantages that dedicated server hosting provides for operations that depend on unwavering uptime and predictable performance are undeniable, and the architectural purity they bring to the table through isolation makes them far more than a legacy choice. A dedicated server eliminates resource contention and gives granular control over hardware-level redundancy. With ground-level access comes the ability to construct sophisticated HA clusters that ensure a level of reliability that can’t be matched by shared platform structures. As the world continues to become increasingly digital and application demands grow, downtime will only be all the more costly for operators, and as such, the need for isolation and control is more important than ever.
Deploy Your Dedicated Server Today
Choose from thousands of ready-to-deploy dedicated configurations across our Tier III & IV data centers worldwide.
We are always on duty and ready to assist!
Blog

Four Forces Driving Growth in the Application Hosting Market
The most recent analyst consensus estimates the application hosting market at approximately USD 80 billion in current annual spending, with a projected compound annual growth rate of approximately 12 percent, a trend that would increase the total market size more than threefold over the next ten years. (Research and Markets) It is driven by four mutually reinforcing forces, i.e., unstoppable SaaS adoption, compute-hungry AI, an accelerating edge build-out, and a worldwide compliance clamp-down. All these factors are compelling businesses to reevaluate where and on what they are willing to host their critical applications.
Four Forces Behind Double-Digit Expansion
SaaS demand keeps surging to new heights
The global SaaS spend is currently on a trajectory to reach USD 300 billion in the short term and more than double, as nearly every enterprise is moving away from license fees to subscriptions. (Zylo) Such ubiquity translates directly into backend capacity requirements: providers have to support millions of tenants with high availability and low latency.
AI workloads are reshaping infrastructure economics
According to researchers, demand is growing at an annual rate of over 30 per cent in AI-ready data-center capacity, and seven out of every 10 megawatts constructed is devoted to advanced-AI clusters. (McKinsey & Company) GPUs, high-core CPUs, and exotic cooling increase per-rack power density and leave older facilities crushed, generating new interest in single-tenant servers where hardware can be tuned without hypervisor overhead.
Edge computing stretches the network perimeter
Edge AI revenue alone is expected to triple by the end of the decade as companies shift analytics closer to the devices to gain privacy and achieve sub-second response times. (Grand View Research) Physics matters: ~10 ms round-trip latency is added for every 1,000 kilometers of physical distance, and research from GigaSpaces indicates that every 100 milliseconds costs 1 % of online purchases. Enterprises are thus pushing apps to dozens of micro-points of presence, a trend that favours hosts that can provision hardware in numerous locales and combine it with a global CDN.
Compliance has turned out to be architectural.
Tighter privacy and data-sovereignty laws are forcing workloads to be within the physical jurisdiction. Current usage of cloud computing in EU businesses is approximately 42–45 percent, in part due to regulatory conservatism, whereas in the U.S., businesses demonstrate near-ubiquitous adoption, with roughly three-quarters using cloud infrastructure. (TechRepublic, CloudZero) Multi-region design is not an option anymore; it is a prerequisite for legal certainty.
Divergent Adoption Paths: U.S. vs. Europe

North-American organizations were early adopters of public cloud; over nine in ten large companies surveyed have meaningful workloads in the cloud, and around three-quarters of large enterprises use cloud infrastructure services. (CloudZero) The environment is rather homogeneous, which allows easy roll-outs at the national level.
Europe stays cautious. The penetration of cloud is in the low to mid-40 percentiles and even lower in some industries. (TechRepublic) Data-residency requirements and distrust of non-EU hyperscalers are causing many enterprises to split stacks: regional clouds or dedicated hardware to host regulated data, U.S. platforms for elastic needs.
Result: architects will be asked to operate on two default patterns: U.S. cloud-first; EU hybrid-first, and provision multi-provider orchestration.
Provider Segments in Flux
| Segment | Core Value | Growth Signal |
|---|---|---|
| Hyperscalers | Massive on-demand scalability and bundled managed services | Keep holding the majority of net-new workloads yet experience cost-control backlash |
| Colocation & Dedicated | Fixed-fee economics, single-tenant control and custom hardware | The market is expected to nearly double over the next five years (~USD 100 billion to >USD 200 billion) (GlobeNewswire) |
| Edge & CDN Nodes | Proximity and cached delivery | Each year, hundreds of micro-sites are being powered on to support latency budgets of less than 25 ms |
Pre-cloud, the server rental was commoditised; one rack was the same as another. In the present day, the focus of differentiation is based on network gravity, compliance badges, power density, and human expertise. That transition reopens space for specialists — especially in dedicated servers.
Why Dedicated Servers Are Back in the Spotlight Today

The new default is multi-cloud, 81 % of enterprises already use two or more clouds to run workloads. (HashiCorp | An IBM Company) But it is the strategic workloads that are moving to, not out of, physical single-tenancy:
- Performance & Cost – Fixed-capacity applications (high-traffic web services, large databases) can be cheaper to run on a monthly basis than on a per-second basis, and the noisy-neighbour jitter of shared utility environments is removed in single-tenant physical servers.
- AI Training & Inference – Owning entire GPU boxes enables teams to optimise frameworks and avoid the low availability and high cost of cloud GPU instances.
- Compliance & Sovereignty – Auditors like it when there is a single customer in control of BIOS to board; dedicated boxes are easier to audit.
- Predictable Throughput – Streaming, collaborative, and gaming platforms appreciate the up to 200 Gbps pipes that high-end hosts can ensure.
We at Melbicom observe these patterns daily. Clients run AI clusters on our Tier IV Amsterdam campus and replicate regulated workloads in Frankfurt to support GDPR compliance, bursting to the cloud only in case of unforeseeable spikes. Since we run 20 data-center facilities and a 50-site CDN, they are on the edge and do not need to patch together three or four vendors.
Market Snapshot
| Segment | Current Market Size (USD) | CAGR |
|---|---|---|
| Application hosting (overall) | ~80 B | 12 % (Research and Markets) |
| SaaS software | ~300 B | 20 +% (Zylo) |
| Data-center colocation | 104 B | 14 % (GlobeNewswire) |
| Edge-AI infrastructure | 20–21 B | 22 +% (Grand View Research) |
Dedicated Opportunity in a Hybrid World
Cloud elasticity remains unrivaled for handling variable loads, but CIOs are increasingly seeking steady performance. Finance teams prioritize predictable depreciation over opaque egress fees; engineers value BIOS-level control for kernel tweaks; risk officers rest easier with single-tenant attestations. As AI accelerates power densities and edge nodes multiply, dedicated servers are becoming a linchpin rather than a legacy hold-over, especially when those servers can be provisioned in minutes via an API and live in Tier III/IV halls with zero-cost human support.
Melbicom is responding by pre-staging 1,000+ server configurations, ready to roll out with a backbone in terabits rather than megabits. Customers set CPU, GPU and memory to task, pin latency-sensitive micro-services to regional DCs and replicate data across continents using the same console. The effect of this is that the dedicated servers allow the agility of the cloud without the cloud tax.
Strategic Takeaways

The application hosting market is gaining pace, and there is no doubt about it; workloads are increasing, data gravity is on the rise, and compliance is getting tougher. Growth is not homogeneous but functions in a broad-based manner. North America is still in a cloud-first race, whereas Europe is at a slower pace, with hardware control points being inserted as a measure of sovereignty. There is no longer a binary choice of provider; IT leaders are using hyperscaler scale with dedicated-server accuracy and edge-like agility to achieve cost, latency, and governance objectives simultaneously.
The ease with which organisations navigate the next wave of SaaS, AI, and compliance requirements will be determined by the choice of partners that cover these layers, global footprints, single-tenant options, and edge capacity.
Deploy Dedicated Servers Today
Launch customizable dedicated servers in any of our 20 global data centers and tap up to 200 Gbps bandwidth with 24×7 support.
We are always on duty and ready to assist!
Blog

Choosing the Right Infrastructure for iGaming Success
iGaming mechanics operate in milliseconds; for anyone looking to run an online casino, poker room, or sportsbook, you simply can’t risk a delay of any sort. With thousands of live wagers, a delay/outage can literally cost millions in an industry where revenue already hovers near $100 billion and is compounding at double-digit rates, according to Statista. With the stakes so high, infrastructural decisions are vital. Both customer trust and regulatory standing hang in the balance, and so it is important to make the right choices early on. Today, we will compare cloud and dedicated servers and discuss where each excels, calculate the total costs in conjunction with the performance, and weigh in on the emerging hybrid models.
The Key Differences Between Cloud and Dedicated Servers for iGaming
| Factors | Cloud Hosting | Dedicated Server Hosting |
|---|---|---|
| Scalability | Instant elasticity; you can spin up nodes in minutes and scale down after events. | Capacity fixed per box; new hardware requires a provisioning cycle (hours to days). |
| Performance Consistency | Good average latency, but virtualization and noisy neighbors cause jitter. | Low, stable latency and predictable throughput because resources aren’t shared. |
| Cost Model | Pay-as-you-go; attractive for bursts but pricey at steady high load (egress fees add up). | Fixed monthly/annual fees; lower TCO for stable, high-traffic workloads. |
| Control & Compliance | Shared-responsibility security, limited hardware visibility, and data may traverse regions. | Full root access, single-tenant isolation, and easier compliance with data-sovereignty rules. |
| Time-to-Market | Launch in a new jurisdiction overnight through regional cloud zones. | Requires a host with a local data center; lead time shrinks if inventory is pre-racked as provided by Melbicom. |
Reliable Performance of Your Services: When Milliseconds Matter
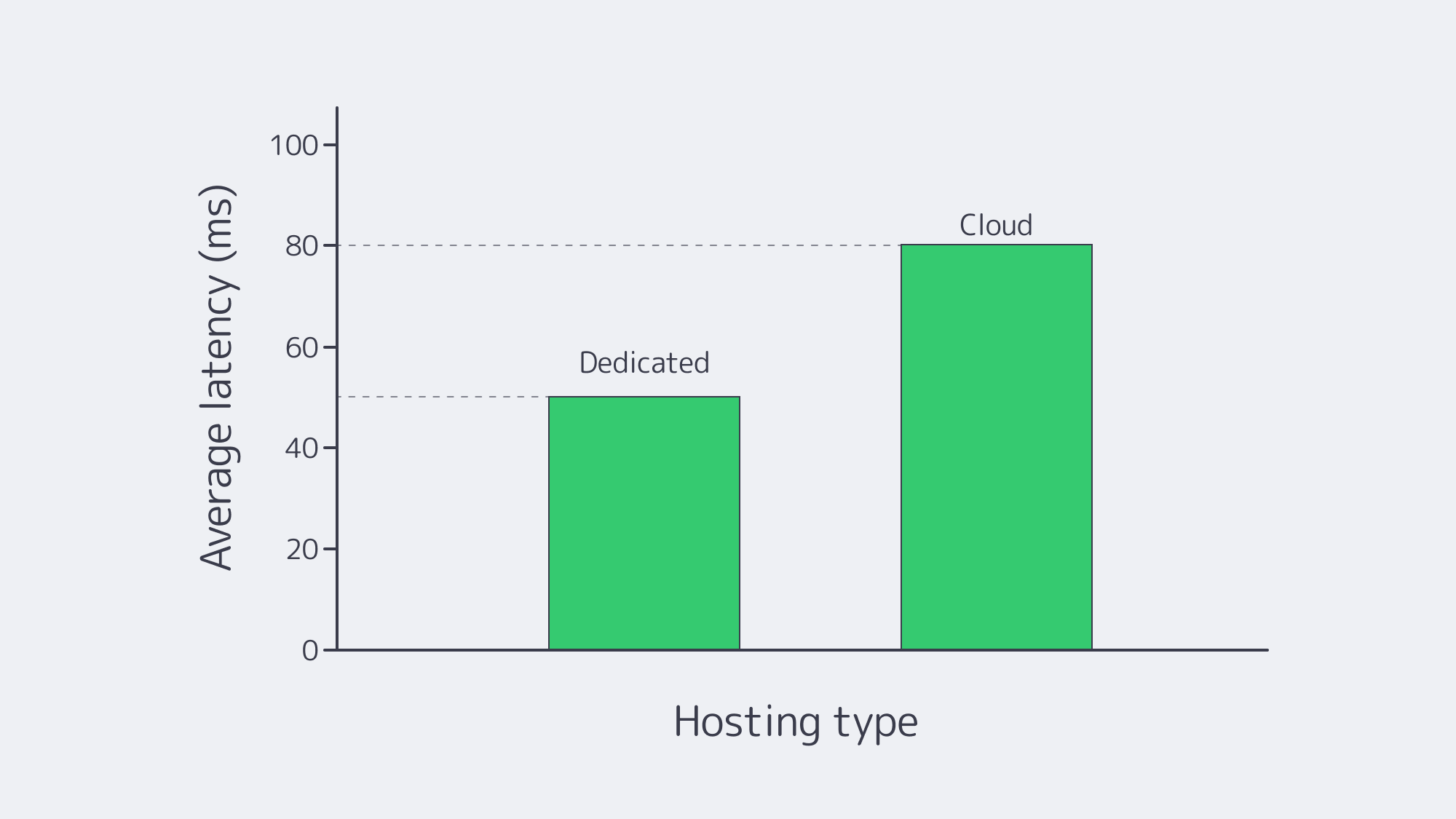
- Cloud server strengths: many top-tier cloud servers have NVMe storage and can provide <2 ms intra-zone latency, which is ample for back-office microservices.
- Cloud server weaknesses: there can be a lot of jitter with hypervisor overheads and lack of sole tenancy, potentially causing odds suspensions, which can lead to backlash on social media, etc.
- Dedicated server strengths: noise from neighbors is eliminated completely with single-tenant boxes, which ensures sub-millisecond consistency ideal for concurrent streaming. Melbicom delivers up to 200 Gbps per server, and we have 20 Tier IV/III data centers worldwide, providing throughput that stays flat regardless of demands.
- Dedicated server weaknesses: resilience and redundancy need to be manually designed; resilience is not “auto-magicked” by a provider’s zones, as with many clouds.
With the strengths and weaknesses apparent, it is easy to see why the best modern practice is to pair a redundant cluster of dedicated machines (for odds, RNG, payment) with cloud-hosted stateless front ends. That way, you retain control of critical path processes while the web tier floats elastically.
Infrastructure Scalability & Agility: Elasticity Versus Predictability
Cloud Server Advantages
- Auto-scaling groups handle instant surge capacity changes.
- Cloning takes minutes, making QA or A/B sandbox creation a breeze, helping with development and testing.
- Nodes can be dropped in a freshly regulated state while licensing paperwork clears, which facilitates global pop-ups.
The Evolution of Dedicated Server Setups
The gap has been narrowed by modern server providers. At Melbicom, for example, we keep hundreds of pre-built server setups that can be deployed in under two hours. They are controlled by the same APIs DevOps teams expect from cloud dashboards, able to handle architects’ forecasts for Super Bowl or Euro finals loads, and hardware can be booked days ahead rather than months.
Going Hybrid
A pattern is emerging with iGaming and streaming providers merging the two options together by keeping the baseline on dedicated hardware and leaving bursts to the cloud. At Melbicom, our gaming and casino sector clients can configure dedicated clusters to run below saturation (around 70% CPU, a threshold common in autoscaling guidance) while relying on the Kubernetes HPA or Cluster Autoscaler to add cloud nodes should the threshold be exceeded.
Economics: Pay-As-You-Go vs. Fixed Power
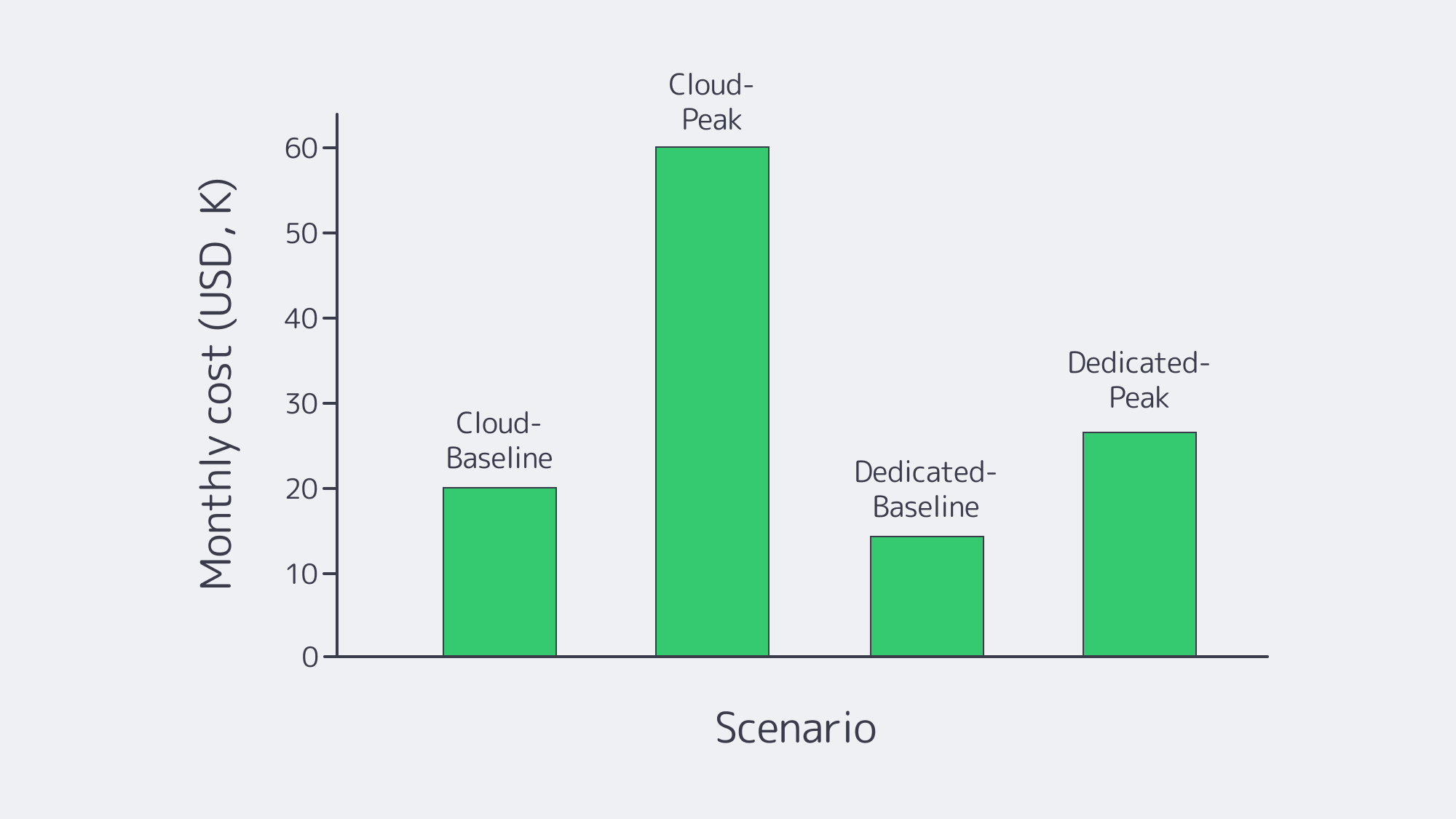
Cloud Server Cost Dynamics
- OpEx freedom, appealing to startups and those piloting new markets.
- Hidden costs, data-egress fees, unexpected premiums for high-clock CPUs, and surcharges for managed databases.
- Higher waste, unused cloud spending is pegged at around ~25 % across industries. Often in the bid to protect latency, over-provision is the default, which can be costly.
Dedicated Server Cost Dynamics
- The billing is flat and predictable, the price includes all costs, meaning no nasty surprises for CFOs during viral promos or DDoS spikes.
- Lower at-scale unit costs once bandwidth is factored in, a dedicated unit costs less. A steady 24/7 poker network that spends $50 k/month in cloud compute is typically below $20 k on equivalent dedicated racks.
Modern Trends
When analyzed, many operators repatriate compute in terms of stabilized daily player concurrency and baseline demand. Although we are seeing evidence and further predictions of planned pull-back from public cloud operation, most are not abandoning it entirely, choosing instead to retain it primarily for variable or ancillary workloads where it excels and for cost control. A recent CIO survey found that 83% of organizations plan to repatriate at least some workloads from public cloud, primarily for cost control. However, we expect many will be reserving it for variable or ancillary workloads, where it excels.
Control, Compliance & Security: The Assurance of Single-Tenancy
- Cloud: While some providers offer ISO 27001 and PCI zones, physical-host opacity remains an issue; many gaming authorities insist on disk-level auditability, and some even request data hall entry.
- Dedicated: Audits are simple with single-tenant servers; hardware serials, sealed racks, and local key storage are easily verifiable. Regulations differ from region to region, but with Melbicom, cross-border data-sovereignty challenges are mitigated by deploying in Tier III facilities across Europe and North America and a Tier IV flagship in Amsterdam, where regulations are stricter.
- Security posture differences: Hypervisor patching is offloaded by the cloud’s shared-responsibility model, but perfect IAM hygiene is needed. With dedicated hardware, the OS and firmware must be patched, but this enables custom HSMs or proprietary anti-fraud sensors. It is now becoming common to encrypt databases with on-server HSMs and mirror anonymized analytics to the cloud.
Hybridizing Architecture: Reaping the Best of Both Worlds
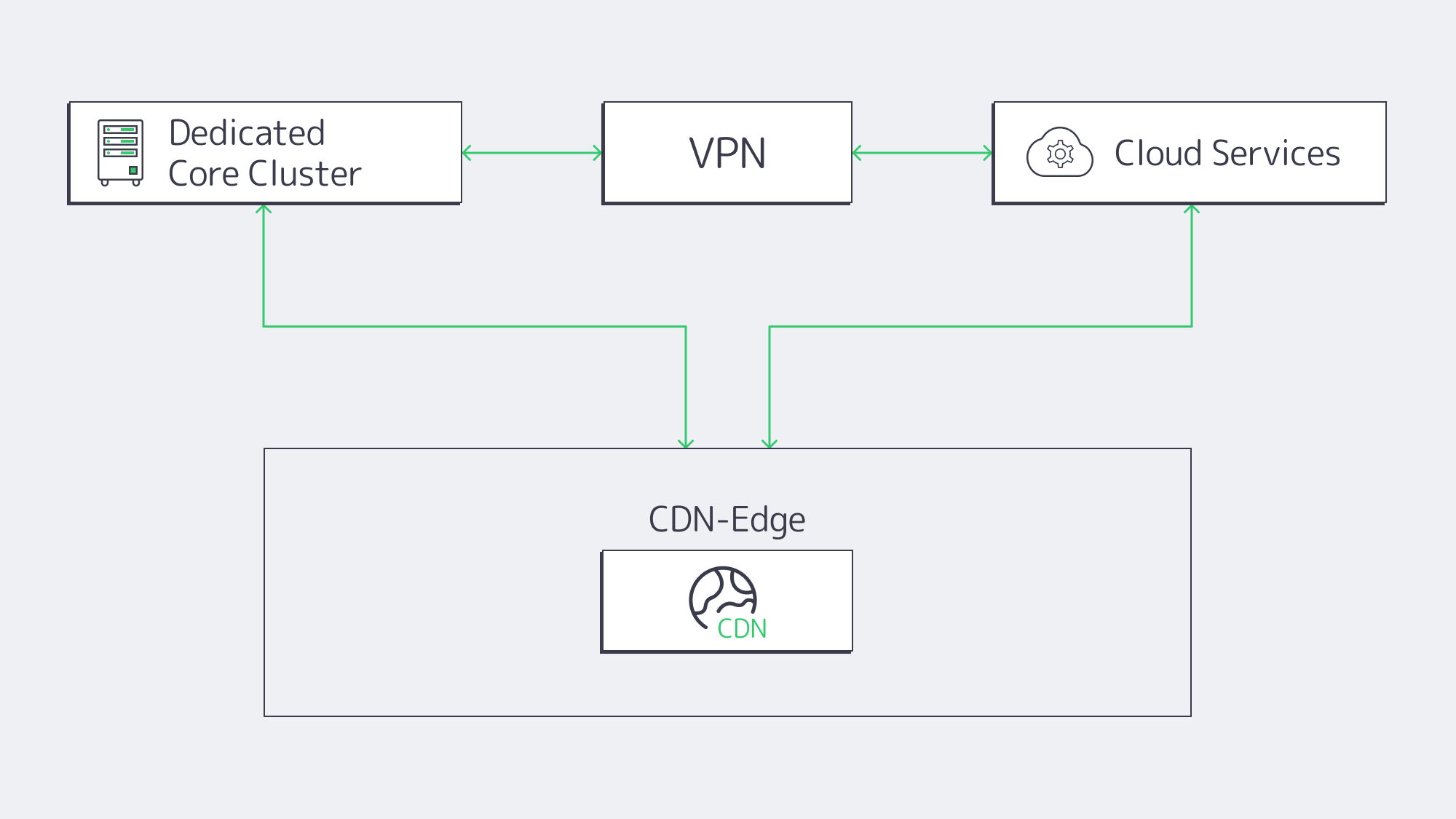
- Dedicated Core, Cloud Edge Leverage dedicated clusters near the main user base for real-money game logic, RNGs, and payment gateways while utilizing low-latency cloud regions for stateless APIs, UIs, and CRM microservices.
- Cloud Burst Operating via six high-spec servers for baseline needs, with behind-the-scenes auto-scaling cloud containers ready to spring into action when triggered by a surge that dissolves post-match.
- Dev in Cloud, Prod on Dedicated Spinning up test environments with CI/CD pipelines, running tests, and deploying approved builds to hardened dedicated servers to shrink time-to-market without the associated multi-tenant exposure risks.
- Splitting For Geo Compliance At Melbicom, dedicated nodes can be used to process bets by sending anonymized aggregates to a central cloud data lake for BI and ML, an ideal solution for instances where data must stay in-country.
How the Debate Has Shifted: A Summary of Historical Context
The ideological fight that was in full swing just a decade ago has reached a stalemate. Cloud emergence once promised to “kill servers,” and the loyalists waved latency graphs in defense and exasperation. Then Moore’s Law slowed, and providers added premium SKUs, and the cloud prices plateaued. Dedicated automation also changed the argument with IPMI APIs, and inventories that can be deployed in an instant, bringing better agility to dedicated servers.
Final Word: A Winning Infrastructure Hand

The choice between cloud and dedicated is ultimately subjective; each has its merits. If uncertainty is high or the need is urgent, the cloud earns its keep, especially in situations where experimentation drives revenue, but for long-term cost efficiency, dedicated infrastructure wins hands down. It also has deterministic performance and provides the isolation that regulators look for. For iGaming demands, adaptability is key to keep up with shifting traffic and adhere to rules without economic challenges.
A forward-thinking solution is to structure your architecture to utilize the best of both worlds. With latency-critical engines locked down on high-bandwidth single-tenant servers, you have powerful, solid infrastructure that aligns with compliance, and then you can exploit the elasticity provided by cloud servers to cope with unexpected spikes, peripheral microservices, and handle experimental rollouts and ventures into new markets.
Deploy Dedicated Servers Now
Spin up high-performance single-tenant nodes in minutes and give your players the low-latency experience they expect.
We are always on duty and ready to assist!
Blog

Database Server Acquisition: Should You Buy or Rent?
Before modern innovations came along, the default was to buy a database server, bolt it into your rack, and run it into depreciation. This, of course, made scaling economically challenging, and as the world has become increasingly more digitally demanding, the pressure to scale is tremendous. Now, the traditional reflex to buy and bolt in has been shattered, but many still remain on the fence as to whether to buy or rent.
So, in an effort to clarify doubts and help with your decision, we have written a digestible data-driven guide. Let’s look at the capital-expense (CapEx) path of owning hardware and compare it with the operating-expense (OpEx) model of renting dedicated or cloud-hosted nodes. With the cost exposure, refresh cycles, burst capacity, and operational overheads laid out alongside legacy in-house server rack models, it soon becomes clear why they are no longer the standard for modern operations.
The True Cost of Buying a Database Server
How much is a database server? The price goes beyond sticker price. The price tag is merely an opening bid, but let’s begin with a rough idea of initial outlay. A budget of $4,000–$8,000 will get you a modest 2-socket machine with 256 GB RAM and mirrored NVMe. Somewhere in the region of $15,000 and upwards is needed for an enterprise-grade build with high-core-count CPUs, terabytes of RAM, and PCIe Gen4 storage.
The kicker comes when you have to factor in warranties, sufficient power and cooling, and an annual service contract. There is also rack space to consider and spares. Realistically, you are looking at a three-year TCO of $54,000 for a single mid-range box ($1,500 monthly) according to industry analysts.
Rather than parting with a huge lump sum, you can rent for metered costs; comparable rented database server plans will set you back approximately $500–$650 a month with a one-year term. Granted, public-cloud analogs cost more per core-hour, but they scale down to zero. When analyzed over a three-year period, the cash converges, yet with OpEx you can exit, downgrade, and relocate without writing off any stranded capital. With these economic benefits, it is unsurprising that in 2022, upwards of 60 % of enterprises began accelerating the shift in IT spending from CapEx to OpEx through service contracts.
The nuances in accounting can make all the difference in operating efficiently without wasted expenses. Procurement committees, asset-tracking, and depreciation schedules are triggered by CapEx assets. OpEx flows better with operating budgets streamlined, cash flow smoothed, and approval loops reduced. That way, spending is truly aligned with genuine business demands.
The Economics At A Glance
| Dimension | Buy Once (CapEx) | Rent or Cloud (OpEx) |
|---|---|---|
| Up-front outlay | High (hardware, setup) | Low (first month) |
| Balance-sheet impact | Capital asset, depreciation | Operating expense |
| Flexibility | Locked to spec & location | Scale up/down per hour |
| Refresh cycle | 3–5 years, manual | Continuous, provider-driven |
Refresh Cycles: Avoiding the Inevitable Treadmill

Server silicon doesn’t age well, CPU road-maps peg ~20 % performance-per-watt annually, and there is an unavoidable plunge each generation with NVMe latency as well. Despite the fact, a 2024 Uptime Institute survey divulged that 57 % of operators now keep hardware for five years or more, which is twice the share revealed in a similar survey in 2016. Downtime risks increase with every additional year, modern software features are limited, and you are essentially burning kilowatts at last-gen efficiency.
That treadmill can be avoided altogether with the decision to rent. Server hosts regularly refresh inventories, and at Melbicom, we can migrate tenants to fresher nodes with very little friction. Want to accelerate SQL Server compression with AVX-512? Melbicom shoulders disposal burdens and facilitates replacement logistics, allowing you to clone, test, switch over, and retire the old iron without the remorse of sunk costs.
Traditional models centered on legacy in-house data centers complicate the process. Freight delays are almost inevitable when making your new hardware order, cabling diagrams can be complex, and sometimes the upgrade requires building-wide power upgrades to boot. When hosts such as Melbicom can place a freshly imaged server, fully racked in a Tier IV or Tier III hall in around two hours, why go through such a headache?
Workload Utilization and Burst Capacity
Typically, the utilization of a database server stored on the premises is low. Industry studies place average use at somewhere between 12–18 %, but we buy for peak and idle for months. The average utilization of hyperscale clouds is ~65 % due to multiplexing demand, and dedicated hosts approach that figure because the hardware is almost never idle.
Idle capital can be converted by OpEx into measured consumption, taking care of surges. For example, if a gaming launch pushes reads per second tenfold, replicas or higher-IOPS nodes materialize as needed, disappearing from the bill once the surge ends. With 1,000+ ready configurations across 20 global markets (LA to Singapore, Amsterdam to Mumbai) stocked and ready to go, Melbicom can ensure capacity bursts land nearby with sub-10 ms latency. You can say goodbye to network bottlenecks as the bandwidth envelope reaches 200 Gbps per server, and the pace of modern OLTP demands is met with NVMe arrays.
Surges aside, sizing challenges are still faced by those with steady workloads. Oversizing your infrastructure worsens utilization and total cost of ownership, as underused capacity ties up capital without delivering proportional value. By renting your hardware capacity, you have a bidirectional safety valve, allowing you to scale both up and down as needed.
Understanding Operational Overheads: Who Does the Heavy Lifting?

Owning the hardware outright also brings additional operational overhead to maintain the infrastructure. Firmware needs patching, and backups need switching. Someone has to guard loading docks against humidity and human error. Having someone on hand to swap drives at 3 a.m. is integral to keeping things operational. IBM reckons that sysadmins spend roughly a third of their week caring for infrastructure, and this is often undifferentiated. By renting through Melbicom, operational hardware maintenance is passive, and the overheads are included in your monthly rate, so you can sleep at night knowing there are no nasty bills for a new fan tray headed to your email.
Auditors also prefer dedicated hosts for regulated workloads, helping you meet compliance standards because it ensures encryption keys are in your sole hands. Renting a server in a certified environment offloads documentation whilst preserving isolation.
The Subscription Mindset Continues to Follow Trend Predictions
An arc was traced a decade ago, and infrastructural spending tracks it to a T. Service-based IT is up from where it was pegged in 2022 (at 41%) and has been forecast by Gartner to surpass half of enterprise outlays mid-decade. Morgan Stanley data backed that prediction from the alternate perspective, showing that the share of workloads running on company-owned hardware fell to roughly one-third by 2022/23. The subscription mindset is clearly taking hold, and the gravitational pull is unmistakable.
Hybrid deployment makes for a great landing zone. Dedicated rentals with predictable costs are ideal for steady, latency-sensitive transactional databases, while analytics bursts, dev/test, and edge caches that spin up and down as economics dictate are better suited to cloud infrastructure. This shift aligns with licensing needs, such as subscription-based Microsoft SQL Server.
As subscription becomes the new normal, lease terms crucially become measured in months, rather than years. Letting clients adopt ARM CPUs when they cross the performance-per-watt tipping point or relocate data also satisfies sovereignty laws that are becoming more complex; on-prem servers simply can’t keep up, as they are often frozen in purchase orders, unable to pivot.
Striking a Balance
CapEx still has an edge in niche cases—such as ultra-stable OLTP clusters housed in campuses with surplus power, or where regulators require certain workloads to run in owned, physically secured cages—but overall, the burden of proof has flipped; justifying ownership is harder with a backdrop of flexible, cancel-any-time services that refresh hardware without extra cost.
That’s where OpEx engines shine; sunk-cost anxiety is eliminated, and teams can therefore pour energy into schema design, query tuning, and generating insight. A cost/performance sweet spot can be easily struck by exploiting PCIe Gen5 storage or emergent CPU instructions, and eliminating weekend hardware swaps prevents any dips in morale.
Conclusion: Agility Over Ownership

If you operate with a data-driven strategy, the last thing you want is to have it undermined by the infrastructure. For workloads that arrive faster than procurement cycles, renting dedicated servers or cloud nodes is the surest way to prevent your infrastructure from becoming a depreciated asset.
Whether you are running PostgreSQL, Oracle, or buying Microsoft SQL Server licenses, you want modern solutions that scale with ease and can be refreshed and relocated as fast as the market moves.
Ready to Deploy Your Database Server?
Choose from 1,000+ high-performance dedicated configurations and have your database server online in hours.
We are always on duty and ready to assist!
Blog
Milliseconds Matter: Build Fast German Dedicated Server
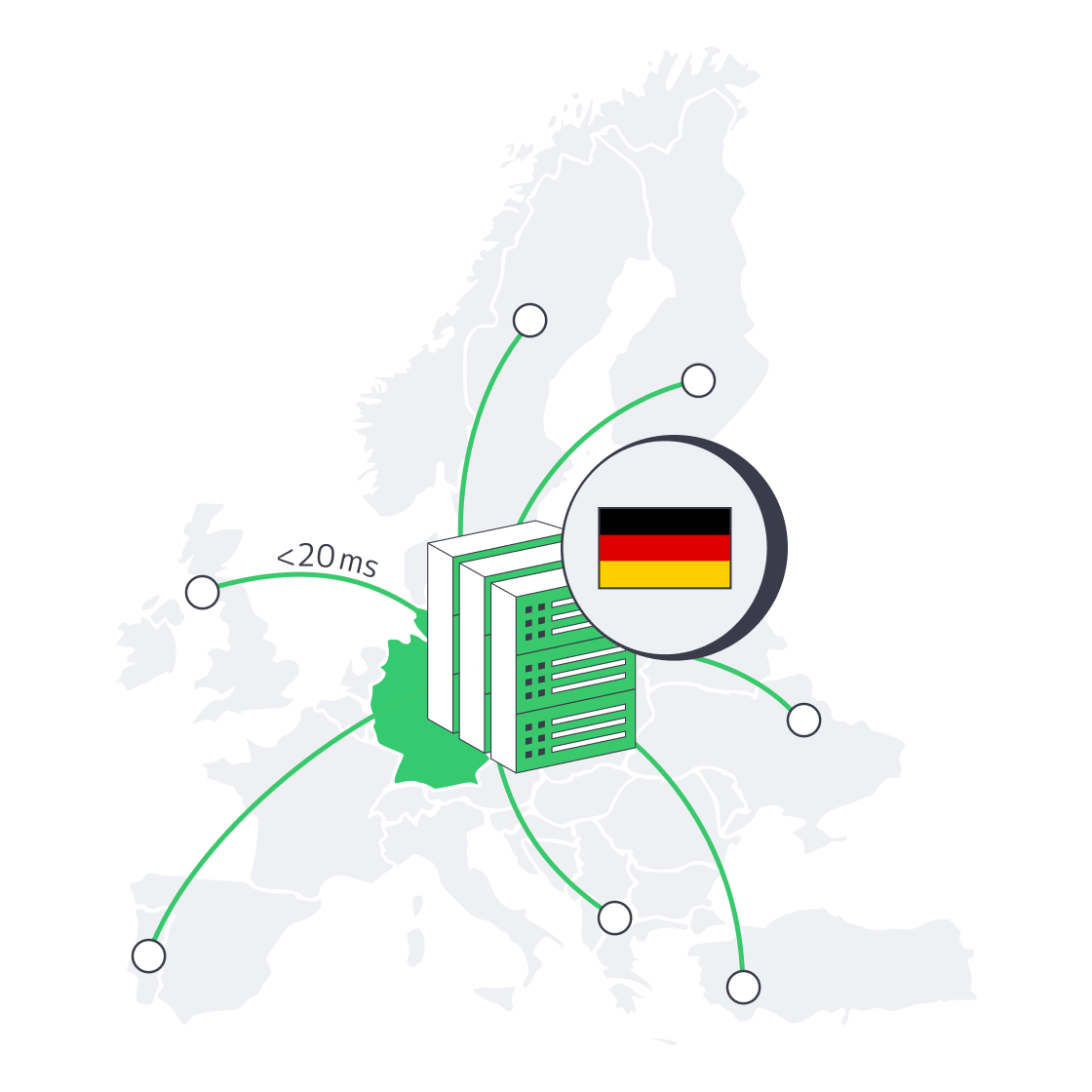
Modern European web users measure patience in milliseconds. If your traffic surges from Helsinki at breakfast, Madrid at lunch, and New York before dawn, every extra hop or slow disk seek shows up in conversion and churn metrics. Below is a comprehensive guide on putting a dedicated server in Germany to work at peak efficiency. It zeroes in on network routing, edge caching, high-throughput hardware, K8 node tuning, and IaC-driven scale-outs.
Germany’s Network Edge: Why Milliseconds Disappear in Frankfurt
Frankfurt’s DE-CIX hub is the world’s busiest Internet Exchange Point (IXP), pushing tens of terabits per second across hundreds of carriers and content networks. Placing workloads a few hundred fiber meters from that switch fabric means your packets jump straight into Europe’s core without detouring through trans-regional transit. When Melbicom peers at DE-CIX and two other German IXPs, routes flatten, hop counts fall, and RTT to major EU capitals settles in the 10–20 ms band. That alone can shave a third off time-to-first-byte for dynamic pages.
GIX Carriers and Smart BGP
A single peering fabric is not enough. Melbicom blends Tier-1 transit plus GIX carriers—regional backbones tuned for iGaming and streaming packets—to create multi-path BGP policies. If Amsterdam congests, traffic re-converges via Zurich; if a transatlantic fiber blinks, packets roll over to a secondary New York–Frankfurt path. The failover completes in sub-second, so your users never see a timeout.
Edge Caching for Line-Speed Delivery
Routing is half the latency story; geography still matters for static payloads. That’s where Melbicom’s 50-plus-PoP CDN enters. Heavy objects—imagery, video snippets, JS bundles—cache at the edge, often a metro hop away from the end-user. Tests show edge hits trimming 30–50 % off total page-load time compared with origin-only fetches.
Hardware That Erases Bottlenecks
Packet paths are useless if the server stalls internally. In Melbicom’s German configurations today, the performance ROI centers on PCIe 4.0 NVMe storage, DDR4 memory, and modern Intel Xeon CPUs that deliver excellent throughput for high-traffic web applications.
PCIe 4.0 NVMe: The Disk That Isn’t
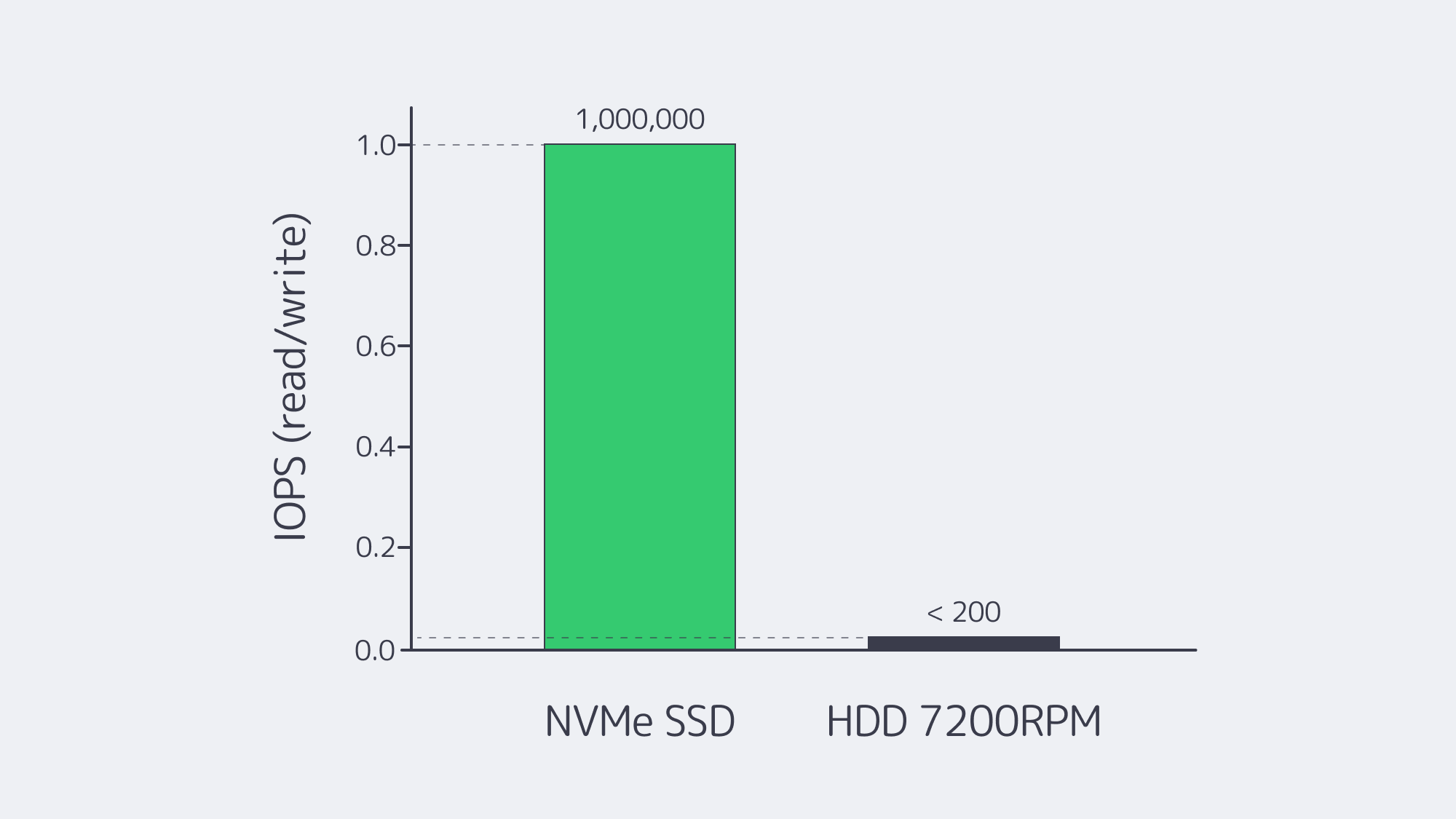
Spinning disks top out near ~200 MB/s and < 200 IOPS. A PCIe 4.0 x4 NVMe drive sustains ~7 GB/s sequential reads and scales to ~1 M random-read IOPS with tens of microseconds access latency, so database checkpoints, search-index builds, and large media exports finish before an HDD hits stride. For workloads where latency variance matters—checkout APIs, chat messages—NVMe’s microsecond-scale response removes tail-latency spikes.
| Metric | NVMe (PCIe 4.0) | HDD 7,200 rpm |
|---|---|---|
| Peak sequential throughput | ~7 GB/s | ~0.2 GB/s |
| Random read IOPS | ~1,000,000 | < 200 |
| Typical read latency | ≈ 80–100 µs | ≈ 5–10 ms |
Table. PCIe 4.0 NVMe vs HDD.
DDR4: Memory Bandwidth that Still Delivers
DDR4-3200 provides 25.6 GB/s per channel (8 bytes × 3,200 MT/s | DDR4 overview). On 6–8 channel Xeon servers, that translates to ~150–200+ GB/s of aggregate bandwidth—ample headroom for in-memory caches, compiled templates, and real-time analytics common to high-traffic web stacks.
Modern Xeon Compute: High Core Counts and Turbo Headroom
Modern Intel Xeon Scalable CPUs deliver strong per-core performance with dozens of cores per socket, large L3 caches, and AVX-512/AMX acceleration for media and analytics. For container fleets handling chat ops, WebSocket fan-out, or Node.js edge functions, these CPUs offer a balanced mix of high single-thread turbo for spiky, latency-sensitive paths and ample total cores for parallel request handling (Intel Xeon Scalable family).
Leveraging Kubernetes at the Metal: Node-Level Fine-Tuning
Running containers on a dedicated server beats cloud VMs for raw speed, but only if the node is tuned like a racecar. Three adjustments yield the biggest gains:
- CPU pinning via the CPU Manager — Reserve whole cores for latency-critical pods while isolating system daemons to a separate CPU set. Spiky log rotations no longer interrupt your trading API.
- NUMA-aware scheduling — Align memory pages with their local cores, preventing cross-socket ping-pong that can add ~10 % latency on two-socket systems.
- HugePages for mega-buffers — Enabling 2 MiB pages slashes TLB misses in JVMs and databases, raising query throughput by double digits with no code changes.
Spinning-disk bottlenecks vanish automatically if the node boots off NVMe; keep an HDD RAID only for cold backups. Likewise, allocate scarce IPv4 addresses only to public-facing services; internal pods can run dual-stack and lean on plentiful IPv6 space.
IaC and Just-in-Time Scale-Out
Traffic spikes rarely send invitations. With Infrastructure as Code (IaC) you script the whole server lifecycle, from bare-metal provisioning through OS hardening to Kubernetes join. Need a second dedicated server Germany node before tonight’s marketing blast? terraform apply grabs one of the 200+ ready configs Melbicom keeps in German inventory, injects SSH keys, and hands it to Ansible for post-boot tweaks. Spin-up time drops from days to well under two hours—and with templates, every node is identical, eliminating the “snowflake-server” drift that haunts manual builds.
IaC also simplifies multi-region redundancy. Because a Frankfurt root module differs from an Amsterdam one only by a few variables, expanding across Melbicom’s global footprint becomes a pull request, not a heroic night shift. The same codebase can version-control IPv6 enablement, swap in newer CPUs, or roll back a bad driver package in minutes.
Spinning Disks and IPv4: The Brief Necessary Warnings
Spinning disks still excel at cheap terabytes but belong on backup tiers, not in hot paths. IPv4 addresses cost real money and are rationed; architect dual-stack services now so scale-outs aren’t gated by address scarcity later. That’s it—legacy mentioned, future focus retained.
Cut Latency, Boost Capacity, Future-Proof Growth with Melbicom

Germany’s position at the crossroads of Europe’s Internet, coupled with the sheer gravitational pull of DE-CIX, makes Frankfurt an obvious home for latency-sensitive applications. Add in GIX carrier diversity, edge caching, PCIe 4.0 NVMe, DDR4 memory, and modern Xeon compute, then wrap the stack with Kubernetes node tuning and IaC automation, and you have an infrastructure that meets modern traffic head-on. Milliseconds fall away, throughput rises, and scale-outs become code commits instead of capital projects. For teams that live and die by user-experience metrics, that difference shows up in retention curves and revenue lines almost immediately.
Order a German Dedicated Server Now
Deploy high-performance hardware in Frankfurt today—PCIe 4.0 NVMe, 200 Gbps ports, and 24/7 support included.
We are always on duty and ready to assist!
Blog
Blueprint For High-Performance Backup Servers
Exploding data volumes—industry trackers expect global information to crack 175 zettabytes (Forbes) within a few short cycles—are colliding with relentless uptime targets. Yet far too many teams still lean on tape libraries whose restore failure rates exceed 50 percent. To meet real-world recovery windows, enterprises are pivoting to purpose-built backup server solutions that blend high-core CPUs, massive RAM caches, 25–40 GbE pipes, resilient RAID-Z or erasure-coded pools, and cloud object storage that stays immutable for years. The sections below map the essential design decisions.
Right-Sizing the Compute Engine
High-Core CPUs for Parallel Compression
Modern backups stream dozens of concurrent jobs, each compressed, encrypted, or deduplicated in flight. Tests show Zstandard (Zstd) compression running across eight cores can outperform uncompressed throughput by 40 percent. That scale continues almost linearly to 32–64 cores. For a backup dedicated server, aim for 40–60 logical cores—dual-socket x86 or high-core ARM works—to keep CPU from bottlenecking nightly deltas or multi-terabyte restores.
RAM as the Deduplication Fuel
Catalogs, block hash tables, and disk caches all live in memory. A practical rule: 1 GB of ECC RAM per terabyte of protected data under heavy deduplication, or roughly 4 GB per CPU core in compression-heavy environments. In practice, 128 GB is a baseline; petabyte-class repositories often scale to 512 GB–1 TB.
25–40 GbE Networking: The Non-Negotiable Modern Backbone
Why Gigabit No Longer Cuts It
At 1 Gbps, transferring a 10 TB restore takes almost a day. A properly bonded 40 GbE link slashes that to well under an hour. Even 25 GbE routinely sustains 3 GB/sec, enough to stream multiple VM restores while performing new backups.
| Network Throughput | Restore 10 TB |
|---|---|
| 1 Gbps | 22 h 45 m |
| 10 Gbps | 2 h 15 m |
| 25 Gbps (est.) | 54 m |
| 40 Gbps | 34 m |
| 100 Gbps | 14 m |
Dual uplinks—or a single 100 GbE port if budgets allow—ensure that performance never hinges on a cable, switch, or NIC firmware quirk. Melbicom provisions up to 200 Gbps per server, letting architects burst for a first full backup or a massive restore, then dial back to the steady-state commit.
Disk Pools Built to Survive

RAID-Z: Modern Parity Without the Drawbacks
Disk rebuild times balloon as drive sizes hit 18 TB+. RAID-Z2 or Z3 (double or triple parity under OpenZFS) tolerates two or three simultaneous failures and adds block-level checksums to scrub silent corruption. Typical layouts use 8+2 or 8+3 vdevs; parity overhead lands near 20–30%, a small premium for long-haul durability.
Note: RAID-Z on dedicated servers requires direct disk access (HBA/JBOD or a controller in IT/pass-through mode) and is not supported behind a hardware RAID virtual drive. Expect to provision it via the server’s KVM/IPMI console; it’s best suited for administrators already comfortable with ZFS.
Erasure Coding for Dense, Distributed Repositories
Where hundreds of drives or multiple chassis are in play, 10+6 erasure codes can survive up to six disk losses with roughly 1.6× storage overhead—less wasteful than mirroring, far safer than RAID6. The CPU cost is real, but with 40-plus cores already in the design, parity math rarely throttles throughput.
Tiered Pools for Hot, Warm, and Cold Data
Fast NVMe mirrors or RAID 10 capture the most recent snapshots, then policy engines migrate blocks to large HDD RAID-Z sets for 30- to 60-day retention. Older increments age into the cloud. The result: restores of last night’s data scream, while decade-old compliance archives consume pennies per terabyte per month.
Cloud Object Storage: The New Off-Site Tape
Immutability by Design
Object storage buckets support WORM locks: once written, even an administrator cannot alter or delete a backup for the lock period. That single feature has displaced vast tape vaults and courier schedules. In current surveys, 60 percent of enterprises now pipe backup copy jobs to S3-class endpoints.
Bandwidth & Budget Considerations
Seeding multi-terabyte histories over WAN can be painful; after the first full, incremental forever plus deduplicated synthetic backups shrink daily pushes by 90 percent or more. Data pulled back from Melbicom’s S3 remains within the provider’s network edge, avoiding the hefty egress fees typical of hyperscalers.
End-to-End Architecture Checklist
- Compute: 40–60 cores, 128 GB+ ECC RAM.
- Network: Two 25/40 GbE ports or one 100 GbE; redundant switches.
- Disk Landing Tier: NVMe RAID 10 or RAID-Z2, sized for 7–30 days of hot backups.
- Capacity Tier: HDD RAID-Z3 or erasure-coded pool sized for 6–12 months.
- Cloud Tier: Immutable S3 bucket for long-term, off-site retention.
- Automation: Policy-based aging, checksum scrubbing, quarterly restore tests.
With that foundation, server data backup solutions can meet aggressive recovery time objectives without the lottery odds of legacy tape.
Why Dedicated Hardware Still Matters

General-purpose hyperconverged rigs juggle virtualization, analytics, and backup—but inevitably compromise one workload for another. Purpose-built server backup solutions hardware locks in known-good firmware revisions, isolates air-gapped management networks, and lets architects optimize BIOS and OS tunables strictly for streaming I/O.
Melbicom maintains 1,000+ preconfigured servers across 20 Tier III and Tier IV facilities, each cabled to high-capacity spines and world-wide CDN pops. We spin up storage-dense nodes—12, 24, or 36 drive bays—inside two hours and back them with around-the-clock support. That combination of hardware agility and location diversity lets enterprises drop a backup node as close as 2 ms away from production.
Choosing Windows, Linux, or Both
- Linux (ZFS, Btrfs, Ceph): Favored for open-source tooling and native RAID-Z. Kernel changes in recent releases push per-core I/O to 4 GB/sec, perfect for 25 GbE.
- Windows Server (ReFS + Storage Spaces): Provides block-clone fast-cloning and built-in deduplication; best won when deep Active Directory trumps everything else.
- Mixed estates often deploy dual backup proxies: Linux for raw throughput, Windows for application-consistent snapshots of SQL, Exchange, and VSS-aware workloads. Networking, storage, and cloud tiers stay identical; only the proxy role changes.
Modernizing from Tape: A Brief Reality Check
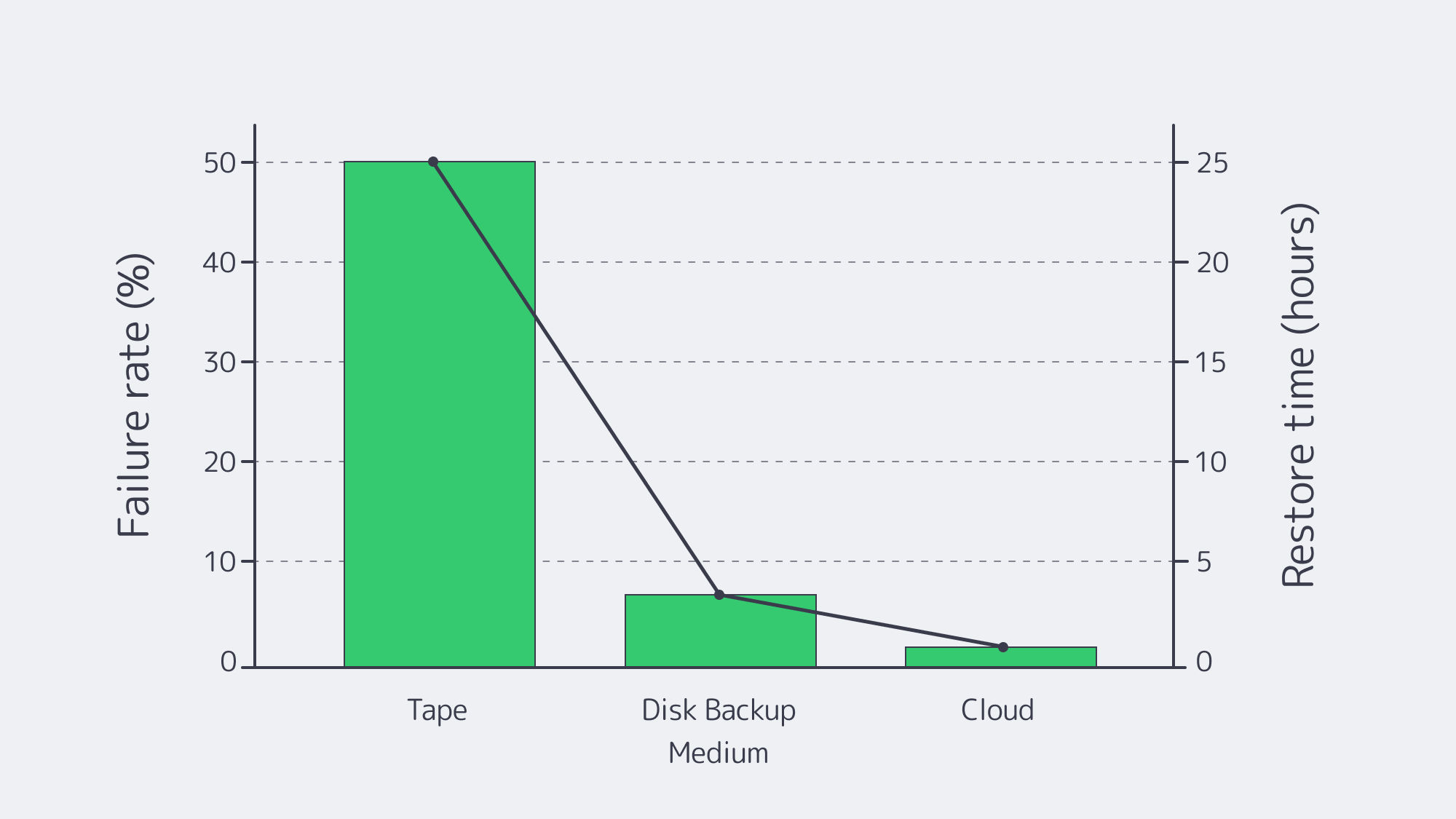
Tape once ruled because spinning disk was expensive. Yet LTO-8 media rarely writes at its promised 360 MB/sec in the real world, and restore verification uncovers 77 % failure rates in some audits (Unitrends). Transport delays, stuck capstan motors, and degraded oxide layers compound risk. By contrast, a RAID-Z3 pool can lose three disks during rebuild and still read data, while a cloud object store replicates fragments across metro or continental regions. Cost per terabyte remains competitive with tape libraries once you factor robotic arms, vault fees, and logistics.
Putting It All Together
Purpose-built server backup solutions now start with raw network speed, pile on compute for compression, fortify storage with modern parity schemes, and finish with immutable cloud tiers. Adopt those pillars and the nightly backup window shrinks, full-site recovery becomes hours not days, and compliance auditors stop reaching for red pens.
Conclusion: Blueprint for Next-Gen Backup
High-core processors, capacious RAM, 25–40 GbE lanes, RAID-Z or erasure-coded pools, and an immutable cloud tier—this blueprint elevates backup from an insurance policy to a competitive advantage. Architects who embed these elements achieve predictable backup windows, verifiable restores, and long-term retention without the fragility of tape.
Order Your Backup Server Now
Get storage-rich dedicated servers with up to 200 Gbps connectivity, pre-configured and ready to deploy within hours.