Blog
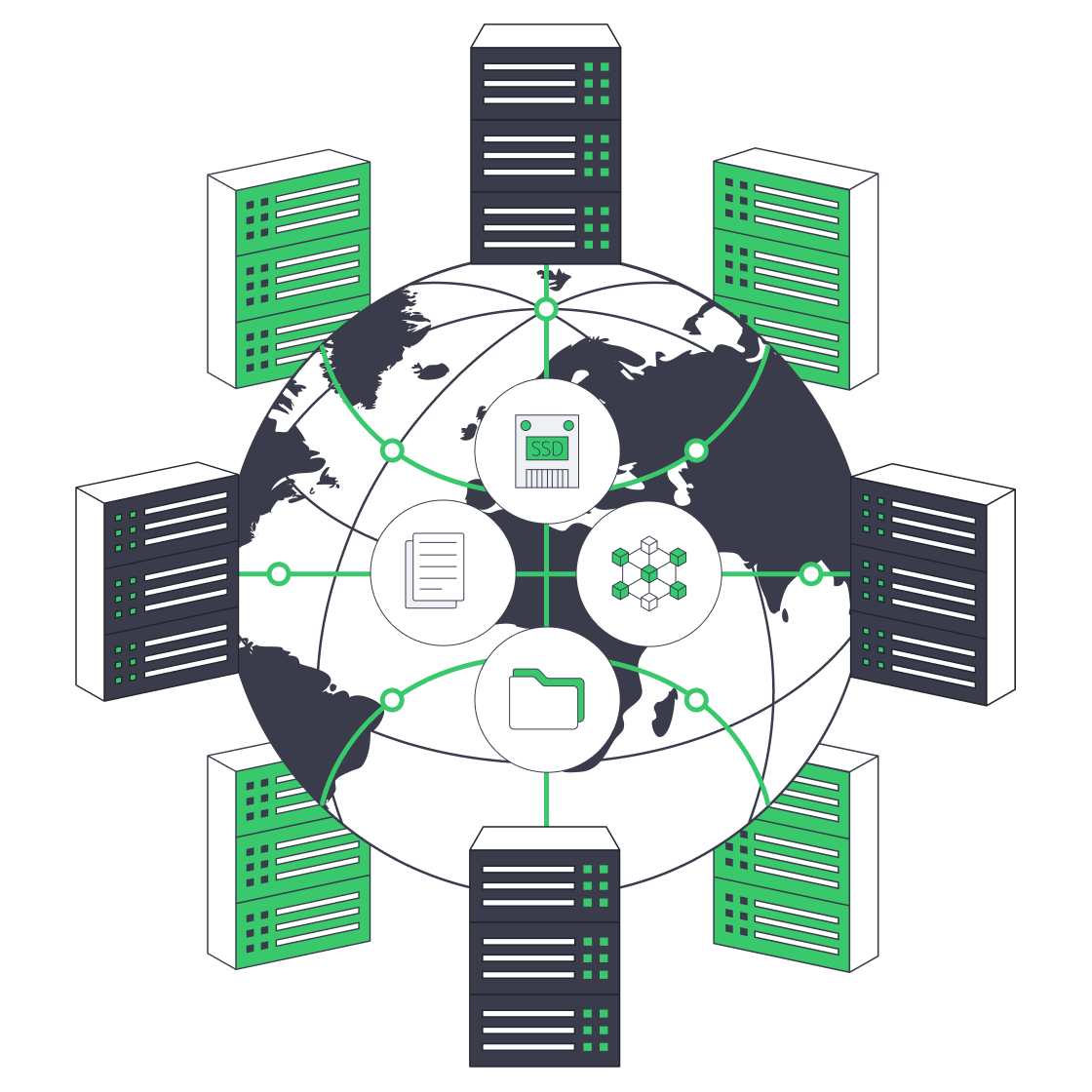
Dedicated Servers for Decentralized Storage Networks
Decentralized storage stopped being a curiosity the moment it started behaving like infrastructure: predictable throughput, measurable durability, and node operators that treat hardware as a balance sheet, not a weekend project. That shift tracks the market. Global Market Insights estimates the decentralized storage market at $622.9M in 2024, growing to $4.5B by 2034 (22.4% CAGR).
The catch is that decentralization doesn’t delete physics. It redistributes it. If you want to run production-grade nodes—whether you’re sealing data for a decentralized storage network or serving content over IPFS—your success is gated by disk topology, memory headroom, and the kind of bandwidth that stays boring under load.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Decentralized Storage Nodes: Where the Real Bottlenecks Live
You can spin up a lightweight node on a spare machine, and for demos that’s fine. But professional decentralized storage providers are solving a different problem: ingesting and proving large datasets continuously without missing deadlines, dropping retrievals, or collapsing under “noisy neighbor” contention.
The scale is already real. The Filecoin Foundation notes that since mainnet launch in 2020,the network has grown to nearly 3,000 storage providers collectively storing about 1.5 exbibytes of data. That’s 1.5 billion gigabytes distributed across thousands of independent nodes—far beyond hobby hardware.
That scale pushes operators toward dedicated servers because the constraints are brutally specific: capacity must be dense and serviceable (drive swaps, predictable failure domains); I/O must be tiered (HDDs for bulk, SSD/NVMe for the hot path); memory must absorb caches and proof workloads without thrashing; and bandwidth must stay consistent when retrieval and gateway traffic spike.
In other words: decentralized cloud storage isn’t “cheap storage from random disks.” It’s a storage appliance—distributed.
Decentralized Blockchain Data Storage

Decentralized blockchain data storage merges a storage layer with cryptographic verification and economic incentives. Instead of trusting a single provider’s dashboard, clients rely on protocol-enforced proofs that data is stored and retrievable over time. Smart contracts or on-chain deals govern payments and penalties, turning “who stored what, when” into a verifiable ledger rather than a marketing claim.
This is where centralized vs decentralized storage stops being ideological and becomes operational. Centralized systems centralize trust; decentralized storage networks distribute trust and enforce it with math. The price is heavier, more continuous work on the underlying hardware: generating proofs, moving data, and surviving audits.
Explaining How Decentralized Cloud Storage Works With Blockchain Technology
Decentralized cloud storage uses a blockchain (or similar consensus layer) to coordinate contracts and incentives among independent storage nodes. Clients make storage deals, nodes periodically prove they still hold the data, and protocol rules handle payments and penalties. The chain anchors “who stored what, when” and automates enforcement—without a single trusted storage vendor.
Under the hood, production nodes behave like compact data centers. You’re not just “hosting files”; you’re running data pipelines: ingest payloads, encode or seal them, generate and submit proofs on schedule, and handle retrieval or gateway traffic. The blockchain is the coordination plane and the arbiter; the hardware has to keep up.
Deployment Is Getting Faster—and More OPEX‑Friendly
The industry trend is clear: shorten the time between “we want to join the network” and “we’re producing verified capacity.” In one Filecoin ecosystem example, partners offering predefined storage‑provider hardware and hosted infrastructure cut time‑to‑market from 6–12 months to 6–8 weeks, turning what used to be a full data‑center build into a matter of weeks. That shift reframes growth: you expand incrementally, treat infrastructure as OPEX, and avoid the “buy everything upfront and hope utilization catches up” trap.
A high‑performance dedicated server model fits that pattern. Instead of buying racks, switches, and PDUs, you rent single‑tenant machines in existing facilities, pay monthly, and scale out node fleets as protocol economics justify it.
| Factor | Build (CAPEX) | Rent (OPEX) |
|---|---|---|
| Upfront Cost | Large hardware purchase | Monthly or term spend |
| Deployment Time | Procurement + staging | Faster provisioning |
| Hardware Refresh | You fund and execute upgrades | Provider manages lifecycle |
| Scaling | Stepwise, slower | Add nodes as needed |
| Maintenance | Your ops burden | Shared support and replacement model |
| Best Fit | Stable, long‑run fleets | Fast expansion or protocol pilots |
Decentralized Content Identification and IPFS Storage

IPFS flips the addressing model: you don’t ask for “the file at a location”; you ask for “the file with this identity.” In IPFS terms, that identity is a content identifier (CID)—a label derived from the content itself, not where it lives. CIDs are based on cryptographic hashes, so they verify integrity and don’t leak storage location. This is content addressing: if the content changes, the CID changes.
In practical terms, decentralized file storage performance often comes down to where and how you run your IPFS nodes and gateways. Popular content may be cached widely, but someone still has to pin it, serve it to gateways, and move blocks across the network. If those “someones” are running on underpowered hardware with weak connectivity, you’ll see it immediately as slow loads and timeouts.
Bringing IPFS into production usually involves:
- Pinning content on dedicated nodes so it doesn’t disappear when caches evict it.
- Running IPFS gateways that translate CID requests into HTTP responses.
- Using S3 storage and CDNs in front of IPFS to smooth out latency + absorb read bursts.
That’s exactly where dedicated servers shine: you can treat IPFS nodes as persistent origin servers with high‑bandwidth ports, local NVMe caches, and large HDD pools—then rely on a CDN to fan out global distribution.
Hardware Demands in Practice: Build a Node Like a Storage Appliance
The winning architecture is boring in the best way: isolate hot I/O from cold capacity, avoid resource contention, and over‑provision the parts that cause cascading failures.
Decentralized Storage Capacity Is a Disk Design Problem First
Bulk capacity still wants HDDs, but decentralized storage nodes are not just “a pile of disks.” Filecoin’s infrastructure docs talk explicitly about separating sealing and storage roles, and treating bandwidth and deal ingestion as first‑class design variables. The pattern is roughly:
- Fast NVMe for sealing, indices, and hot data.
- Dense HDD arrays for sealed sectors and archival payloads.
- A topology that lets you replace failed drives without jeopardizing proof windows.
Memory Is the Shock Absorber for Proof Workloads and Metadata
Proof systems and high-throughput storage stacks punish tight memory budgets. In Filecoin’s reference architectures, the Lotus miner role is specified at 256 GB RAM, and PoSt worker roles are specified at 128 GB RAM—a blunt signal that “it boots” and “it proves on time” are different targets.
Bandwidth Isn’t Optional in a Decentralized Storage Network
Retrieval, gateway traffic, replication, and client onboarding all convert to sustained egress. Filecoin’s reference architectures explicitly call out bandwidth planning tied to deal sizes, because bandwidth is part of whether data stays usable once it’s stored.
A snapshot of what “serious” looks like: the Filecoin Foundation profile of a data center describes a European storage-provider facility near Amsterdam contributing 175PiB of capacity to the network, connected via dark fiber links into Amsterdam, and serving 25 storage clients. That is pro-grade infrastructure being used to power decentralized storage.
Melbicom runs into this reality daily: the customers who succeed in production are the ones who provision for sustained operations, not peak benchmarks. Melbicom’s Web3 hosting focus is built around that exact profile—disk-heavy builds, real memory headroom, and high-bandwidth connectivity tuned for decentralized storage nodes.
Web3 Storage Scales on the Same Basis as Every Other Storage System

Decentralized storage networks are converging on mainstream expectations: consistent retrieval, verifiable durability, and economics that can compete with traditional cloud storage—without collapsing into centralized control. The way you get there is not mysterious: tiered disks, sufficient memory, and bandwidth that can carry both ingest and retrieval without surprises.
Dedicated servers are the pragmatic bridge between decentralized ideals and decentralized cloud storage as a product. They turn node operation into engineering: measurable and scalable. Whether you are running Filecoin storage providers, IPFS gateways, or other decentralized storage network roles, the playbook looks like any serious storage system—just deployed across many independent operators instead of a single cloud.
Practical Infrastructure Recommendations for Decentralized Storage
- Treat nodes as appliances, not pets. Standardize a small number of server “shapes” (e.g., sealing, storage, gateway) so you can scale and replace them predictably.
- Tier storage aggressively. Put proofs, indices, and hot data on NVMe; push sealed or archival sectors to large HDD pools. Avoid mixing hot and cold I/O on the same disks.
- Over‑provision memory for proofs. Aim for RAM budgets that comfortably cover proof processes, OS, observability, and caching—especially on sealing and proving nodes.
- Size bandwidth to your worst‑case retrieval. Design for sustained egress and replication under peaks; use 10+ Gbps ports where retrieval/gateway traffic is critical.
- Plan for regional and provider diversity. Distribute nodes across multiple DCs and regions when economics justify it, to reduce latency and mitigate regional failures.
Deploy Dedicated Nodes for Web3 Storage
Run decentralized storage on single-tenant servers with high bandwidth, NVMe, and dense HDDs. Deploy Filecoin and IPFS nodes fast with top-tier data centers and unmetered ports.
Get expert support with your services
Blog

GPU-Optimized Servers for ZK Proofs & Web3 Research
Zero-knowledge proofs (ZKPs) have moved from “clever crypto demo” to production infrastructure: ZK-rollups, privacy-preserving DeFi, ZK-based identity, and data-availability schemes all rely on generating proofs at scale. That’s a specific hardware problem: parallel compute, huge memory bandwidth, and a predictable environment.
Recent work on GPU-accelerated ZKP libraries shows proof generation speed-ups ranging from roughly 1.2× to over 8× (124%–713% faster) versus CPU-only runs for practical circuits. GPU-centric studies find that well-tuned GPU implementations can drive up to ~200× latency reductions in core proving kernels compared to CPU baselines. And production deployments of CUDA-based ZK libraries report roughly 4× overall speed-ups for real-world Circom proof generation.
Those gains only turn into real-world value when the GPUs sit inside dedicated, well-balanced servers: high-core-count CPUs to orchestrate the pipeline, ample RAM to keep massive cryptographic objects in memory, NVMe storage for chain data and proving keys, and strong networking to move proofs and state quickly.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
This is where Melbicom’s GPU-powered dedicated servers come in. We at Melbicom run single-tenant machines in 21 Tier III+ data centers across Europe, the Americas, Asia, and Africa. For ZK proofs, that combination of GPU density, memory, and predictable network paths is what turns “interesting benchmarks” into production-ready proving infrastructure.
What GPU Configuration Optimizes Zero-Knowledge Proof Performance
The optimal GPU setup for zero-knowledge proof generation combines massive parallelism, high memory bandwidth, and large VRAM capacity. For zk proofs, that means modern NVIDIA GPUs (24–80 GB) in dedicated servers, paired with fast host memory and I/O so the GPU can continuously process MSMs, FFT/NTT steps, and proving keys without stalling.
Most of the heavy lifting in ZK proofs comes from multi-scalar multiplication (MSM) and Number-Theoretic Transform (NTT) kernels. Studies of modern SNARK/STARK stacks show these two primitives can account for >90% of prover runtime, which is why GPU implementations dominate end-to-end performance.
A good GPU layout for ZK proofs focuses on:
- Core count and integer throughput. For large circuits, you want tens of thousands of CUDA cores working in parallel. An RTX 4090, for example, exposes 16,384 CUDA cores and pushes up to 1,008 GB/s of GDDR6X bandwidth.
- VRAM capacity. Real-world ZK benchmarks show curves and circuits that can consume 20–27 GB of VRAM during proof generation. That immediately rules out older 6–8 GB cards for bigger circuits or recursive proofs; 24 GB is a practical minimum, and 48–80 GB becomes essential for very large proving keys or deep recursion.
- Memory bandwidth. Data-center GPUs like NVIDIA A100 80 GB ship with HBM2e and deliver on the order of 2 TB/s memory bandwidth, making them ideal for MSM/NTT-heavy workloads that are fundamentally bandwidth bound.
Topology matters as well. ZK stacks today are usually optimized for one GPU per proof, not multi-GPU sharding of a single circuit. That means:
- One GPU per box works well for single, heavy proofs (zkEVM traces, recursive rollups).
- Multiple GPUs per server are ideal when you want to run many independent proofs concurrently – batched rollup proofs, per-wallet proofs, or proof markets.
We at Melbicom see most advanced teams standardizing on 1–2 high-end GPUs per server, then scaling out horizontally across many dedicated machines instead of fighting the complexity of multi-GPU kernels before the prover stack is ready.
Which Server Specifications Support Large-Scale ZK Computations
A ZK prover node is effectively a specialized HPC box: it streams huge matrices and vectors through heavy algebra kernels under strict latency or throughput requirements. To keep the GPUs saturated, the server around them needs balanced, predictable, stable performance.
The ideal ZK-focused server is built around three pillars: high-core-count CPUs, large RAM pools, and fast storage/networking. The goal is simple: never let the GPU wait on the CPU, memory, or disk—especially when proving windows or test campaigns are time-bound.
ZK Prover Server Baseline
Here’s a concise baseline for ZK proof and ZK-proof blockchain workloads:
| Component | Role in ZK / Blockchain Workloads | Recommended Specs for Heavy ZK Proofs |
|---|---|---|
| GPU | Runs MSM/NTT and other parallel cryptographic kernels; holds proving keys & witnesses | Latest-gen NVIDIA GPU with 24–80 GB VRAM and high bandwidth (e.g., RTX 4090 / A‑class), 1–2+ GPUs per server depending on parallelism needs |
| CPU | Orchestrates proving pipeline, node logic, preprocessing, I/O | Modern 32–64‑core AMD EPYC / Intel Xeon, strong single-thread performance, large cache |
| RAM | Stores constraint systems, witnesses, proving keys, node data | 128 GB+ DDR4/DDR5, with 256 GB recommended for large circuits or multiple concurrent provers |
| Storage | Holds chain data, proving keys, artifacts, logs | NVMe SSDs for high IOPS and low latency; multi‑TB if you keep full history or large datasets |
| Network | Syncs blockchain state, exchanges proofs, connects distributed components | Dedicated 10–200 Gbps port, unmetered where possible, with low-latency routing and BGP options |
CPU and RAM: Feeding the GPU
Even with aggressive GPU offload, the CPU still:
- Builds witnesses and constraint systems
- Schedules batches and manages queues
- Runs node clients, indexers, or research frameworks
- Handles serialization, networking, and orchestration
A low-core CPU turns into a bottleneck as soon as you run multiple concurrent provers or combine node operation with research workloads. Moving to 32–64 cores allows CPU-heavy stages to overlap with GPU kernels and keeps accelerators busy instead of stalled.
RAM is the other hard constraint. Proving keys, witnesses, and intermediate vectors for complex circuits can easily consume tens of gigabytes per pipeline. Once the OS starts swapping, your effective speed-up vanishes. That’s why ZK-focused machines should treat 128 GB as the floor and 256 GB as a comfortable baseline for intensive zk proofs and ZK-proof blockchain experiments.
We at Melbicom provision GPU servers with ample RAM headroom and current-generation EPYC/Xeon CPUs so research teams can keep entire circuits, proving keys, and node datasets resident in memory while running multiple provers side by side.
Storage and Networking: Moving Proofs and State
For ZK-heavy Web3 stacks, disk and network throughput are first-class design parameters:
- Storage: NVMe SSDs cut latency for accessing chain state, large proving keys, and data-availability blobs. This matters when you repeatedly regenerate proofs, replay chain segments, or run ZK proofs crypto experiments across big datasets.
- Networking: Proof artifacts (especially STARKs) can be tens of megabytes. Rollup sequencers, DA layers, and validators all stream data continuously. Without sufficient bandwidth, proof publication and state sync become the new bottleneck.
Melbicom runs its servers on a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs, exposing unmetered, guaranteed bandwidth on ports up to 200 Gbps per server. Because these are single-tenant bare-metal servers in Tier III/IV facilities, Melbicom’s environment avoids hypervisor noise and noisy neighbors. That determinism is particularly important when you’re trying to reproduce ZKP research results or hit on-chain proving SLAs reliably.
How to Select GPUs for Blockchain Research Workloads
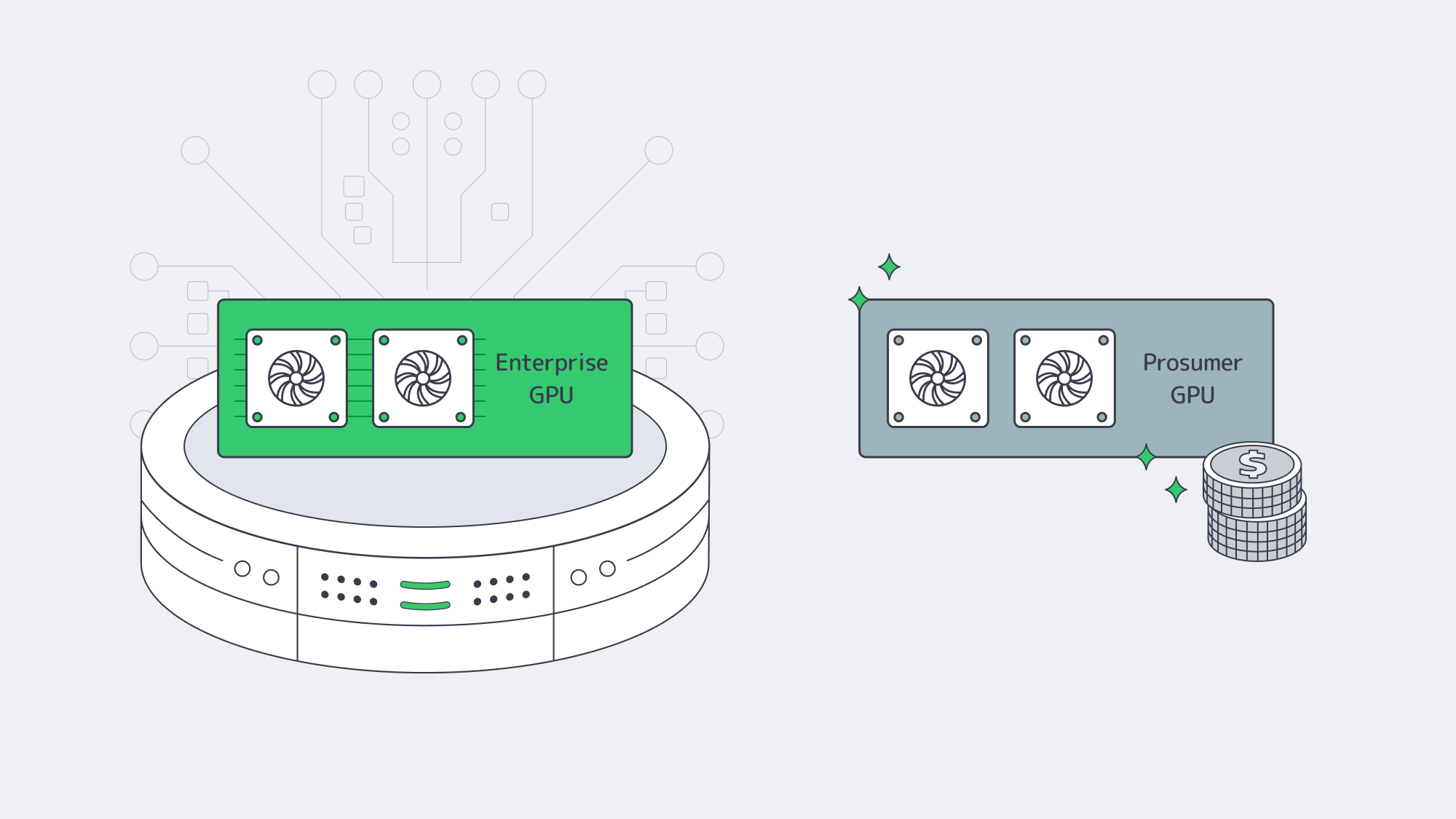
The right GPU for blockchain and ZK research balances compute density, memory capacity, and total cost of ownership. For many ZK workloads, modern NVIDIA GPUs with 24–80 GB VRAM strike the best trade-off, with enterprise GPUs favored for the highest-capacity proofs and prosumer GPUs used where cost efficiency and flexibility matter more than capacity.
In broad strokes:
- For very large circuits, deep recursion, or rollup-scale proofs in production, A‑class data‑center GPUs (such as A100 80 GB) are ideal. They combine 80 GB of high-bandwidth memory and >2 TB/s bandwidth, making them suitable for massive proving keys and wide NTTs.
- For lab clusters and mid-scale prover fleets where proofs fit in ~24 GB, RTX 4090-class GPUs are compelling. A single 4090 offers 24 GB of GDDR6X with ~1,008 GB/s bandwidth and 16,384 CUDA cores, providing excellent throughput at a far lower unit cost than data-center cards.
Economically, this often leads to a two-tier model:
- Development and research fleets built on 24 GB GPUs (e.g., for protocol experiments, circuit iteration, or testnets).
- Production prover clusters that add A‑class GPUs where circuits or recursion depth demand larger memory footprints or higher concurrency.
GPU-accelerated libraries like ICICLE, which underpin production provers, have already shown multi‑× speed-ups at the application level: one case study reports 8–10× speed-up for MSM, 3–5× for NTT, and about 4× overall speed improvement in Circom proof generation after integrating ICICLE. That kind of uplift is what makes it practical to move more proving work off-chain or into recursive layers.
Parallelism strategy also shapes the hardware plan. Because most proving systems today are optimized for one GPU per proof, it’s usually easier to:
- Run multiple independent proofs per server (one per GPU), or
- Scale out across many GPU servers, rather than complex multi-GPU sharding inside a single proof.
We at Melbicom keep dozens of GPU-powered server configurations ready to go—ranging from single‑GPU boxes to multi‑GPU workhorses—and can assemble custom CPU/GPU/RAM/storage combinations in 3–5 business days for more specialized ZK and blockchain research workloads.
Key Infrastructure Takeaways for ZK Proofs
For teams designing serious ZK-proof and ZK proof blockchain infrastructure, a few practical takeaways consistently show up in the field:
- Standardize GPUs as the default proving backend. MSM and NTT dominate proving time and map naturally to thousands of GPU threads; recent work shows GPU-accelerated ZKPs reaching up to ~200× speed-ups over CPU baselines on core kernels.
- Over-provision RAM relative to your largest circuits. Assume per-pipeline working sets in the tens of gigabytes; plan for 128 GB minimum and 256 GB+ on nodes running concurrent provers, to avoid swapping + subtle failures in long-running proof workloads.
- Design networking as part of the proving system. High-throughput links (10–200 Gbps) with good peering are essential when proofs, blobs, and chain state move between sequencers, DA layers, and storage. Melbicom’s 14+ Tbps backbone with strong peering and BGP support is built to keep those paths short and predictable.
- Prefer dedicated, globally distributed infrastructure. Single-tenant GPU servers in Tier III+ sites give deterministic performance and stronger isolation than shared cloud. Combining those with a well distributed CDN lets you pin ZK frontends, proof downloads, and snapshots close to users while keeping origin traffic on-net.
These aren’t abstract “nice-to-haves” – they’re the baseline for hitting proving windows, reproducing research results, and operating complex ZK systems under production load.
Building ZK-Proof Infrastructure on Dedicated GPU Servers
Zero-knowledge proofs may be “just math,” but turning that math into scalable Web3 infrastructure is an engineering exercise in compute, memory, and networking. Dedicated GPU servers are the practical way to get there: they expose raw accelerator performance, enough RAM to keep large cryptographic structures in memory, and the predictable network capacity required to move data and proofs on time.
AsZK systems evolve—ZK-rollups moving more logic off L1, ZK VMs becoming more sophisticated, and more protocols adopting ZK techniques for privacy and scalability—the hardware bar will only rise. Teams that treat GPU-optimized servers as first-class infra today will be better positioned to run fast provers, adapt to new proving systems, and maintain a tight feedback loop between research and production deployments.
Deploy GPU ZK Servers Today
Spin up dedicated GPU servers in 21 Tier III+ locations with unmetered 10–200 Gbps ports. Fast activation for in‑stock hardware and custom builds in 3–5 days to power your ZK proving and blockchain research.
Get expert support with your services
Blog

Dedicated Multi-Region Infrastructure for Oracles and Bridges
Oracle and bridge services live in the gap between deterministic chains and nondeterministic reality: data sources change, networks jitter, servers reboot, and packets occasionally disappear. Yet users and contracts still expect “now,” not “eventually.” In practice, the infrastructure is part of the security model—because when attestations arrive late or inconsistent, trust erodes fast.
Modern oracle and bridge operators already know the hard part isn’t computing the answer; it’s delivering the same answer, everywhere, on time—across multiple chains, regions, and failure modes—without leaking keys or accepting silent data-feed drift.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
The Infra Problem: Trust Dies in the Jitter
Latency for oracle updates and cross-chain messaging isn’t one number. It’s a stack: ingest → normalize → sign/attest → broadcast → observe finality. Each stage has its own tail latency—and tails are where “near-100% uptime” quietly turns into a reliability incident.
The stakes are not theoretical. Infrastructure that enables millions of dollars in transaction value is less about marketing scale and more about operational expectation: once you’re a dependency, your failure modes become other people’s risk. And cross-chain is no longer a niche edge case. Today’s best practices obsess over operational hardening and key custody.
The takeaway: your latency budget and your failure budget are entangled. If you want fast, consistent delivery, you architect for the tail—not the median.
What Dedicated Infrastructure Minimizes Oracle and Bridge Latency

Dedicated infrastructure minimizes oracle and bridge latency by removing noisy-neighbor contention and by keeping hot-path services (ingest, signing, relays, and chain-facing RPC) on single-tenant machines with predictable CPU and I/O. The best setups treat latency like a budget: pin workloads per region, minimize cross-region hops, and keep failover paths warm—not theoretical.
The Practical Latency Budget: Where “Sub-Second” Gets Spent
- Inbound feed variability: API response jitter, rate limits, TLS handshake churn.
- Disk and queue pressure: state persistence, retry queues, log compaction.
- Cross-region coordination: quorum collection, threshold signing, finality watchers.
- RPC variability: shared endpoints, congestion, request throttling.
Dedicated servers help because you can shape the platform: reserve headroom, keep state on local NVMe, and isolate signing and quorum traffic from everything else.
Web3 Server Hosting That Treats the Network as a First-Class Component
If you’re running web3 applications that depend on real-time updates, your web3 infrastructure is not just compute—it’s routing discipline. This is where multi-region dedicated servers plus predictable networking matter.
Melbicom provides the building blocks that map to oracle/bridge needs: 21 Tier IV/III data centers, a 14+ Tbps backbone, and 20+ transit providers plus 25+ IXPs to reduce propagation delays and jitter between regions.
Example: a Concrete Multi-Region Topology
| Layer | Region Examples | What Matters Most |
|---|---|---|
| Ingest + Normalize | Amsterdam, Frankfurt | Keep collectors close to data sources; buffer aggressively; avoid shared queues. |
| Sign/Attest Quorum | Singapore, Los Angeles | Isolate signing; prefer deterministic I/O; keep quorum traffic on private paths. |
| Broadcast + Observe Finality | Tokyo, Stockholm | Fast chain-facing egress; stable RPC; region-local watchers for tail control. |
Locations above reflect some of Melbicom’s data centers and are shown as examples; pick regions that match the chains and venues you’re servicing.
Which Multi-Region Server Setup Ensures Near-100% Uptime
A near-100% uptime setup uses at least two independent regions with active-active service, plus a third region as a cold or warm backstop for disaster recovery. Critical services—signing, relays, and finality observation—should fail over automatically with stable endpoints, while state replication is continuous and tested. Uptime isn’t a promise; it’s engineered behavior.
Active-Active Isn’t Optional for Oracles and Bridges
The “single region + hot standby” model fails a basic reality check: even brief regional network events can create mismatched observations. For oracle operators, that shows up as delayed updates. For bridges, it shows up as relay lag and message backlog.
The modern pattern is:
- Active-active ingest and observation
- Regional quorum for signatures (threshold or multisig)
- Deterministic failover for client endpoints
The point isn’t only uptime. It’s keeping behavior stable under stress: same inputs, same outputs, same latency envelope.
Stable Endpoints: BGP Sessions, BYOIP, and Controlled Failover
If clients, contracts, or counterparties pin to endpoints, IP churn is operational debt. The clean way out is bringing your own IP space and controlling routing.
Melbicom supports BGP sessions (including BYOIP) so operators can keep endpoints stable while engineering regional preference and failover through routing changes rather than “change the URL and pray.”
What most CTOs care about is not that “BGP exists,” but routing safety and hygiene. This is where Melbicom delivers: RPKI validation and strict IRR filtering for customer routes—important guardrails when uptime is tied to the integrity of your route announcements.
State Replica That Doesn’t Become a Latency Tax
Replication is where good architectures die: either you replicate too slowly and failover loses state, or you replicate too eagerly and build a constant cross-region latency bill into every request.
A pragmatic pattern is asynchronous replication with fast catch-up and explicit RPO/RTO targets. That can be as simple as structured logs + object snapshots, or as involved as streaming replication—what matters is predictability and observability.
# Example: lightweight feed-state replication (operator-owned logic) # Goal: ship signed artifacts + last-seen checkpoints, not your entire database. rsync -az --delete /var/lib/oracle/checkpoints/ replica:/var/lib/oracle/checkpoints/ rsync -az --delete /var/lib/oracle/signed-artifacts/ replica:/var/lib/oracle/signed-artifacts/ |
When bandwidth is the constraint, location matters. Melbicom offers per-server port speeds up to 200 Gbps in most locations, which lets operators place replication-heavy tiers where the network headroom actually exists.
What Secure Hardware Protects Bridge Keys and Data Feeds
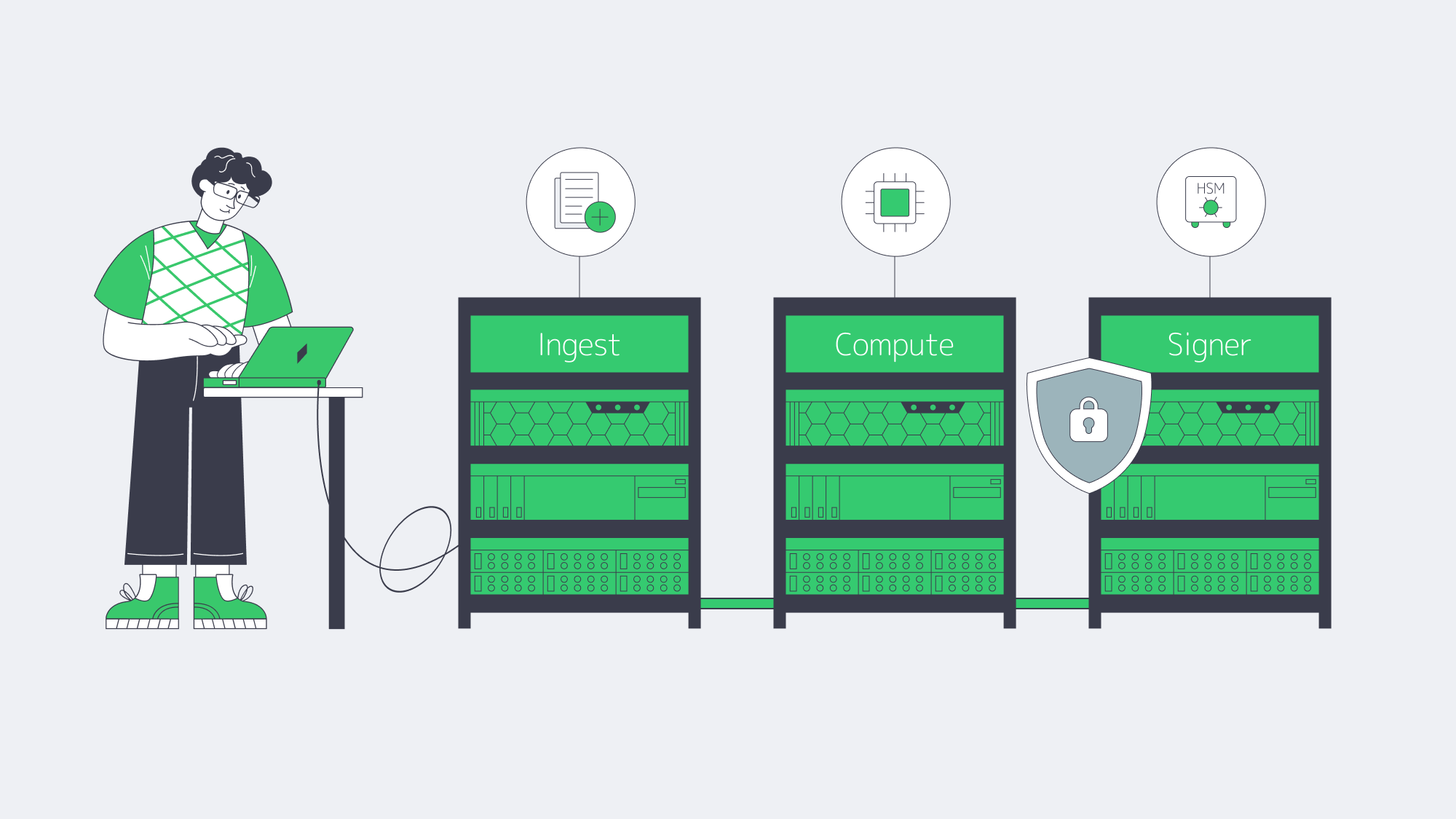
Secure hardware protects bridge keys and data feeds by isolating signing and sensitive processing onto single-tenant machines with locked-down access paths, hardware-backed key custody (such as HSM-backed operations), and strict separation between ingest, compute, and signing roles. The goal is blast-radius control: a compromised service shouldn’t expose keys or rewrite feeds.
Separate the Roles: Ingest ≠ Compute ≠ Sign
Most real incidents start with a “small” compromise: a collector host, a CI runner, a debug port. If ingest and signing share the same blast radius, you don’t have a key-management strategy—you have a hope-based security model.
Best practice is boring and effective:
- Ingest nodes can be replaced quickly; they should not hold signing material.
- Normalization nodes should have restricted egress and strict provenance controls.
- Signing nodes should be isolated, minimal, and auditable.
Dedicated servers make this separation more enforceable because you’re not sharing kernel neighbors or relying on a provider’s abstraction layer for isolation.
Hardware-Backed Key Custody Without Slowing the Hot Path
For bridges and high-stakes oracles, hardware-backed key operations reduce the chance that a software compromise becomes a key compromise. The operational trick is designing it so the signer remains fast and predictable: isolate it, keep it warm, and avoid forcing every request through cross-region round-trips.
Melbicom gives you in-region control and root-level access in Tier III+ DCs, along with stable networking: private links and BGP sessions that help keep the signaling path deterministic.
Data Feed Integrity: “Correct” Must Be Verifiable, Not Just Fast
- Multiple sources with explicit quorum logic
- Signed artifacts with traceable provenance
- Replay protection and deterministic ordering
- Continuous validation (detect drift, missing updates, and timestamp anomalies)
This is the difference between “a fast feed” and “a feed you can defend.”
FAQ
How do I know whether latency is a compute problem or a network problem?
Instrument the hot path end-to-end and split metrics by stage (ingest, normalize, sign, broadcast, finality). If p95 spikes correlate with cross-region hops or RPC response variability, it’s networking and topology—not CPU.
Is multi-region always worth the complexity?
For oracle and bridge operators, yes—because your failure modes are externalized. The complexity is the price of keeping outputs consistent under partial failures.
What’s the minimum multi-region footprint that still behaves well?
Two active regions + one backstop. Anything less turns “failover” into downtime plus cold-start latency.
Where does a CDN fit in this stack
Not for signing or quorum, but for distributing non-sensitive artifacts: dashboards, proofs, snapshots, static content, and client-side assets that should load fast globally. Melbicom’s CDN footprint spans 55+ PoPs across 36 countries.
Bridge Oracle Crypto: Key Takeaways for Low-Latency Trust
- Design for the tail, not the mean. Your p95/p99 latency is what users experience during congestion, RPC turbulence, and partial outages—so measure per stage and budget headroom intentionally.
- Run active-active where correctness matters. Two regions observing and relaying independently reduces “regional truth” drift and prevents one site’s network event from becoming system-wide lag.
- Keep endpoints stable through routing, not DNS scramble. Treat BGP-controlled failover as an operational primitive so clients don’t need reconfiguration during incidents.
- Isolate signing like it’s production finance—because it is. Separate ingest/compute/sign roles and assume any internet-facing node can be compromised.
- Practice failover as a routine operation. Define RPO/RTO, test replay scenarios, and rehearse key procedures so the first “real” failover isn’t also your first experiment.
Trust Is Built at the Speed of Your Infrastructure
Oracles and bridges don’t just use infrastructure—they are infrastructure. When latency spikes, updates arrive late. When uptime wobbles, counterparties lose confidence. And when keys or feeds aren’t protected by design, operational mistakes become systemic risk.
The durable pattern is consistent: dedicated servers for predictable performance, multi-region layouts that keep the hot path close to where it must execute, and hardened signing and data-feed boundaries that keep trust intact even when everything around gets noisy.
Deploy multi-region dedicated servers
Design for the tail with dedicated servers, stable BGP endpoints, and warm failover across regions. Keep keys isolated and updates consistent—without unpredictable jitter.
Get expert support with your services
Blog

Scaling Blockchain Analytics & Indexing with Dedicated NVMe-Powered Servers
Blockchain analytics has hit a true big‑data scale. A pruned Ethereum full node now holds 1.4 TB of data, up more than 22% year‑over‑year, based on Etherscan metrics tracked by YCharts. Archive‑style Ethereum nodes can require over 21 TB of disk, and Solana’s ledger has already exceeded 150 TB of history. Ethereum alone processes roughly 1.5–1.6 million transactions per day, more than 23% higher than a year ago.
On the demand side, the crypto compliance and blockchain analytics market is projected to grow from $4.4 billion in 2025 to nearly $14 billion by 2030 (25.85% CAGR). Put together, that’s more chains, more activity, and far heavier datasets landing on your infrastructure every month.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
Keeping up with that reality requires high‑performance dedicated servers: multi‑core CPUs, large RAM pools, fast NVMe SSDs, and serious bandwidth in predictable, single‑tenant environments. Melbicom builds specifically for this profile with single‑tenant servers across 21 Tier IV/III data centers, a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs, and 55+ CDN PoPs in 36 countries that push data closer to users.
Blockchain and Analytics
A blockchain is an append‑only log of everything that has ever happened: transfers, swaps, liquidations, governance votes, NFT mints. Blockchain analytics is about turning that log into structured data that powers dashboards, risk models, and compliance workflows.
Most serious stacks follow an ETL pattern:
- Extract blocks, transactions, logs, and state diffs from nodes across many chains.
- Transform them into normalized tables (addresses, token transfers, positions, fees).
- Load them into OLAP engines, column stores, or time‑series databases for aggregations.
Academic work on blockchain data analytics repeatedly highlights scalability, data accessibility, and accuracy once datasets reach multi‑terabyte size. Add multi‑chain and multi‑year history, and you’re firmly in big‑data territory.
In practice, modern platforms resemble web‑scale analytics systems: parallel ETL workers feeding NVMe‑backed warehouses, with query engines distributing scans across many cores. The bottleneck stops being “can we parse this?” and becomes “can our infrastructure ingest and query on‑chain data fast enough?”
What Server Specs Maximize Blockchain Indexing Throughput
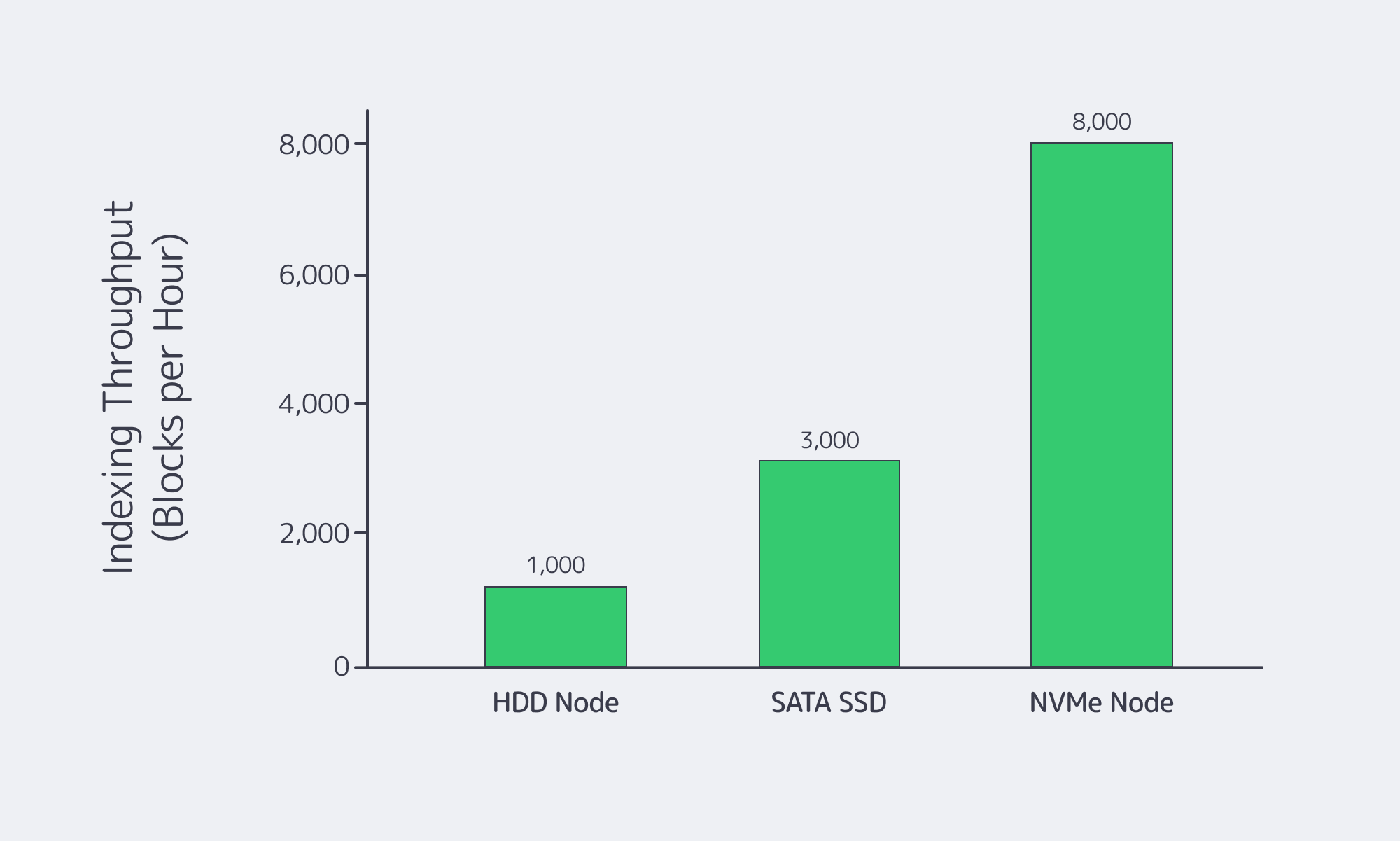
You want high‑core, high‑clock CPUs paired with generous RAM, NVMe SSDs, and high‑bandwidth networking on dedicated servers. That combination lets you parallelize indexing and ETL, keep hot state in memory, and avoid disk or network bottlenecks as chains, users, and queries scale.
CPU and Parallelism
Indexers parallelize naturally: one process per chain, per contract family, or per ETL stage. A 32‑ or 64‑core CPU lets you run many workers concurrently, while single‑thread speed still matters for replaying blocks and verifying signatures.
For Ethereum‑style workloads, the sweet spot is having many strong cores. We at Melbicom lean on the latest‑generation AMD EPYC options in Web3‑optimized builds so multiple nodes and ETL workers can share a host without sacrificing per‑thread performance.
Memory and Caching
Memory is the first line of defense against slow storage. Node clients and indexers cache as much state as RAM allows so they don’t hit disk on every lookup. Operator guides explicitly warn not to “skimp” on memory because extra RAM directly reduces disk I/O.
For multi‑chain analytics, 64–128 GB is a practical baseline, while high‑throughput chains such as Solana often push validators and RPC nodes toward 256 GB+ configurations. That headroom benefits both nodes and analytics engines by keeping large joins in memory instead of thrashing NVMe.
Storage, Network, and Why NVMe Is Non‑Negotiable
Storage and network are where indexing pipelines either fly or stall. Full and archival nodes on major chains now routinely sit in the multi‑terabyte range. That load makes storage throughput and network latency first‑class constraints.
Fast NVMe SSDs are effectively mandatory. Node‑operator guides recommend NVMe over SATA SSDs and warn that network‑attached storage introduces latency that is “highly detrimental” during sustained writes. On the network side, guidance for high‑throughput validators and RPC nodes calls for 10 Gbps or better connectivity and low‑latency routing.
Melbicom’s backbone is designed around those requirements: more than 14 Tbps of capacity, 20+ transit providers, 25+ IXPs, and per‑server ports up to 200 Gbps in most DC locations. That combination keeps nodes in sync with chain heads and absorbs traffic spikes from analytics APIs.
Dedicated, Single‑Tenant Environments
Dedicated servers remove noisy‑neighbor effects and hypervisor overhead that can skew latency and throughput. For long‑running node and ETL processes, that predictability is crucial: when you profile a bottleneck, you know it comes from your schema or code, not someone else’s workload.
Melbicom’s Web3‑ready configurations are single‑tenant by default and spread across 21 Tier IV/III locations in Europe, the Americas, Asia, the Middle East, and Africa, so teams can place heavy analytics nodes close to users and liquidity.
Table 1. Server Components That Actually Move the Needle
| Component | Role in Pipeline | Why High‑End Specs Matter |
|---|---|---|
| CPU (Cores & GHz) | Runs node clients, parsers, ETL workers | More cores and faster threads cut block processing time. |
| RAM | Caches state and query working sets | Large memory reduces disk hits during indexing and queries. |
| NVMe SSD | Stores chain DBs and analytics datasets | High IOPS keeps multi‑TB syncs and scans responsive. |
| Network Uplink | Moves blocks in and query results out | 10–200 Gbps links prevent sync lag and API timeouts. |
| Single‑Tenant Dedicated Hardware | Provides isolated, predictable resources | Dedicated servers avoid noisy neighbors and virtualization drag. |
Which NVMe Configuration Speeds On-Chain Analytics Queries
You want fast, local, enterprise‑grade NVMe—often more than one drive—and a layout that separates hot analytics reads from heavy write paths. Avoid cheap, DRAM‑less or QLC models, and keep network storage out of the critical query path whenever possible if you care about latency, stability, and query speed.
Multiple NVMe Drives for Parallel I/O
Analytics workloads are highly parallel: workers scan different partitions while nodes append new blocks and ETL jobs compact or re‑index tables. Spreading that activity across multiple NVMe drives—via separate volumes or RAID0—lets the kernel and controllers service more I/O queues in parallel.
A practical layout:
- NVMe 0: chain databases (Ethereum, L2s, Solana, etc.)
- NVMe 1: analytics warehouse (columnar or time‑series DB)
- NVMe 2: ETL scratch space and logs
This separation prevents a heavy analytical query from starving the node’s state updates.
Enterprise NVMe Over Consumer Shortcuts
Under indexing loads, you’re writing and rewriting terabytes. Consumer QLC drives often fall off a cliff under sustained writes or hit endurance limits early. Node‑hardware guides recommend fast NVMe and warn that cheaper flash “suffers significant performance degradation during sustained writes,” with network storage adding harmful latency on top.
Enterprise-grade TLC NVMe SSDs with DRAM caches and high TBW ratings are a safer baseline. They help keep IOPS high even while you backfill years of history and serve live queries at the same time.
Local NVMe Plus Object Storage for Cold Data
Not every byte needs NVMe forever. Historical partitions older than a certain horizon may see limited traffic outside audits and backtesting.
A pragmatic design is:
- Keep the active window (recent blocks and hot tables) on local NVMe.
- Offload older partitions and periodic snapshots to S3‑compatible object storage.
Melbicom’s S3‑compatible object storage runs in a Tier IV certified Amsterdam data center, uses NVMe‑accelerated storage, and offers plans from 1 TB to 500 TB with free ingress. That keeps the hot analytics tier lean and fast while still retaining full history for compliance and long‑horizon research.
DeFi Llama and Blockchain Analytics
DeFi Llama shows what scaled blockchain and analytics looks like in production. The platform tracks DeFi metrics across hundreds of chains and thousands of projects and pools, which is only possible because indexing is continuously happening underneath every chart, table, and leaderboard users see.
Much of that work flows through The Graph. Many protocols expose subgraphs; DeFi Llama queries those instead of raw nodes. The Graph’s network has processed more than one trillion queries and supports thousands of active subgraphs across DeFi, NFTs, DAOs, gaming, and analytics.
Behind the scenes sit full and archival nodes, indexers that parse events into structured stores, and query engines that fan out across cores and NVMe to answer user requests. Any team aiming to provide similar multi‑chain views has to assume that per‑chain data volumes, query concurrency, and historical lookback windows will keep climbing—and size infrastructure accordingly.
Scaling Blockchain Analytics With High-Performance Servers

On‑chain data volumes are not slowing down. New L1s, L2s, and app‑chains add their own multi‑terabyte histories, while existing networks keep compounding. The only sustainable way to keep ETL jobs and queries in step with reality is to run them on high‑performance dedicated servers rather than undersized, oversubscribed instances.
Multi‑core CPUs let you parallelize ingestion and transformation. Large RAM footprints keep hot state and query working sets in memory. NVMe SSDs keep multi‑terabyte syncs and scans practical. High‑bandwidth, well‑peered networks prevent your nodes from falling behind chain heads or rate‑limiting analytics traffic.
For teams designing or scaling analytics pipelines, a few principles stand out:
- Design for multi‑chain growth. Plan for dozens of chains and terabytes of new data per year from day one.
- Make NVMe mandatory. Use multiple NVMe drives and clear hot/cold storage tiers; don’t rely on network storage for hot paths.
- Treat bandwidth as a product feature. 10 Gbps+ uplinks and clean peering reduce sync times and API latency under load.
- Choose predictable, single‑tenant servers. Deterministic performance simplifies capacity planning, SLOs, and debugging.
Scale blockchain analytics with Melbicom
Deploy high‑core CPUs, NVMe storage, and 10–200 Gbps networking across 21+ data centers. Get predictable, single‑tenant performance for nodes, ETL, and OLAP.
Get expert support with your services
Blog

Blueprint: Brazil Hub, Regional PoPs, Smarter Routing
South America is no longer a “far edge.” Mobile internet users in Latin America almost doubled from about 230 million to nearly 400 million between 2014 and the mid-2020s. Most of the platforms looking at the region already run their main origins in Europe or the U.S. — and now need a CDN footprint in South America that doesn’t collapse under cross-continent latency.
For those teams, the strategy hinges on three levers: PoP placement across South America, inter‑country routing around a Brazilian hub, and origin consolidation with Europe/US as global cores and Brazil as the regional shield. The rest is plumbing.
South America CDN— Reserve origin nodes in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
Which South American PoP Layout Best Reduces Cross-Continent Latency?
A South America CDN layout should treat São Paulo as the regional hub for traffic coming from existing origins in Europe or the US (let’s use Madrid or Atlanta as examples), then fan out to edge PoPs in cities like Lima, Bogotá, Baires, and Santiago. The objective is simple: keep users in-region while long-haul flows ride the cleanest cables into Brazil.
IX.br’s trajectory explains the role of Brazil. In April 2025, the national IXP fabric hit 40 Tbps peak traffic, with IX.br São Paulo alone exceeding 25 Tbps. That makes SP the natural gravity well for an edge node: place a strong PoP where most of the packets converge.
Modern CDN planning for South America also has to factor in undersea routes. EllaLink’s direct connection between Brazil and Portugal delivers a latency reduction of up to 50% between Latin America and Europe, with RTT under 60 ms between Portugal and Brazil. That turns Brazil into both a regional hub and a clean bridgehead for Madrid‑hosted origins.
For a pan‑regional CDN rollout in South America, a pragmatic pattern looks like this:
- Anchor PoP in São Paulo – which can act as a consolidated regional shield pulling from Madrid or Atlanta origins and feeding the rest of the continent.
- Regional PoPs in Lima, Bogotá, Buenos Aires, and Santiago – existing Melbicom PoPs in these metros shorten last‑mile paths and reduce dependence on long‑haul routes for users outside Brazil.
- Optionally, cable‑adjacent PoPs near landing points (for example on the Brazilian coast) when your cross‑continent flows are especially latency‑sensitive.
The result: users almost always land on a local or near‑local PoP, and the PoPs maintain short, predictable paths into São Paulo and then out to origins in Madrid or Atlanta.
How Should Traffic Be Routed Between Countries Around Brazilian Origin Hubs?
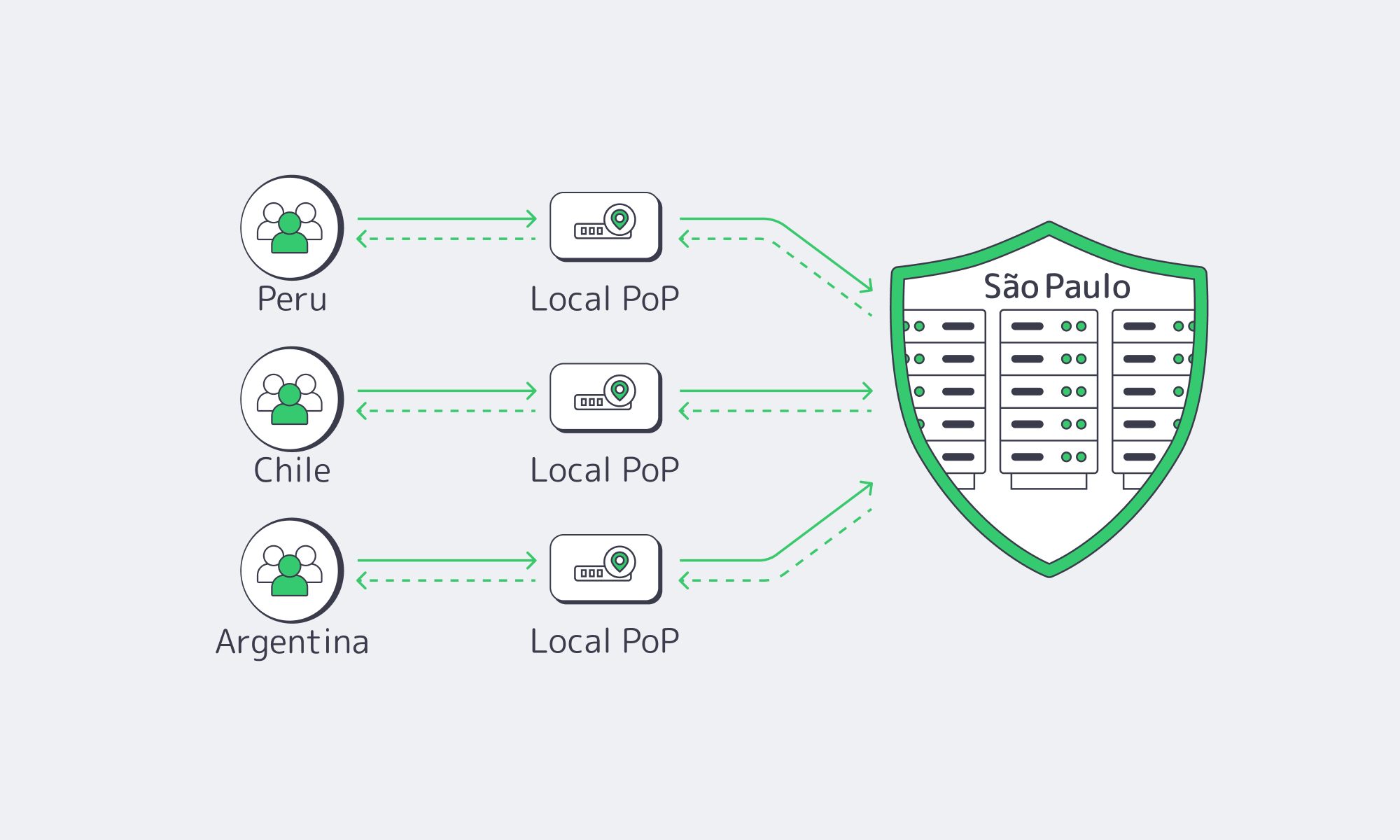
Inter‑country routing should keep packets on South American roads as long as possible. Users attach to the nearest anycast PoP; cache misses travel over regional links to a Brazilian shield in São Paulo, which in turn pulls from European or American origins. BGP policies prevent surprise trombones through distant transit hubs.
The failure mode you want to avoid is classic: a user in Argentina hits content hosted in Spain or the U.S. via a convoluted path that bounces through Miami or random Tier‑2s, turning every click into a 150 ms round‑trip. Properly run, a CDN service in South America does the opposite:
- Anycast on the edge so users in Chile, Peru, or Colombia hit the nearest regional PoP, not North America.
- Brazil as a regional origin hub from the CDN’s perspective: PoPs in Lima, Bogotá, Buenos Aires, and Santiago fetch from a consolidated shield in São Paulo, which in turn talks to Madrid and Atlanta origin clusters over optimized long‑haul.
- Local and regional peering across Latin American IXPs to keep inter‑PoP and PoP‑to‑Brazil traffic inside the continent wherever possible.
This is where routing control matters. A capable CDN provider for South America should expose enough knobs—BGP policies, local‑pref, MEDs—to bias traffic toward regional peers and away from noisy or congested upstreams. Melbicom’s BGP Session service provides free BGP sessions on dedicated servers, IPv4/IPv6, BYOIP, and support for full, default, or partial routes, available in every data center. That’s what allows you to pull Madrid/Atlanta origins into your own routing policy instead of letting transit pick arbitrary paths.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
Resilience rides on multi‑origin thinking. Practically, that means:
- Maintaining at least two independent origin clusters (for example, Madrid + Atlanta) behind the South American shield.
- Using CDN origin pooling and health checks so PoPs fail over cleanly if one of the origin clusters has trouble.
- Defining BGP failover policies that favor alternative regional paths before crossing ocean borders unnecessarily.
From a South American user’s perspective, the priority is consistent, low‑variance RTT—whether the byte actually came from a cache in Santiago or an origin in Madrid via São Paulo is just an implementation detail.
Which KPIs and Traffic Forecasts Should Drive a South America CDN Strategy?

The KPIs that actually move the needle in South America are latency, cache hit ratio, throughput headroom, and availability, all tied to realistic cross‑continent traffic forecasts. Design for video‑heavy, mobile‑first demand, then add capacity and PoPs based on measured TTFB, cache offload, and how quickly long‑haul links saturate.
Latency. Inside Brazil, a realistic target is <50 ms RTT, and <100 ms across major LatAm metros when traffic stays on regional routes and hits a local PoP. With direct systems like EllaLink, Europe–Brazil RTT drops below 60 ms and latency improves by up to 50% versus indirect North American paths.
Cache and origin offload. For a modern CDN in South America, a 90–98% cache hit ratio is achievable on well‑tuned workloads; anything lower usually means TTLs, hierarchy, or routing need work. The practical metric: what % of bytes bound for South American users are served from regional PoPs versus being dragged from Madrid or Atlanta on every miss?
Capacity and per‑server bandwidth. That scale needs serious ports. In Madrid, Melbicom’s dedicated servers come with 1–40 Gbps of bandwidth per unit and more than 100 ready-to-go configurations. Our Atlanta facility supports 1–200 Gbps per server with dozens of stock builds, ideal as a U.S. Southeast origin anchor. Overall, Melbicom offers dedicated servers in 21 Tier III/IV data centers and CDN PoPs in 55+ locations.
Availability and control. Finally, measure per‑PoP uptime, time‑to‑reroute during incidents, and how much routing control you actually have. BGP sessions with BYOIP in every data center let you keep consistent addresses and steer around degraded carriers without touching application code.
Key Metrics and Considerations for a South America CDN Strategy
| Metric/Factor | Target / Example | Strategic Impact |
| Latency (RTT/TTFB) | <50 ms within Brazil; <100 ms across LatAm | Direct regional paths and links like EllaLink cut cross‑continent delay by up to 50% and keep interactive apps usable. |
| Cache Hit Ratio | 90–98%+ | High hit ratios minimize Madrid/Atlanta origin load and long‑haul traffic; bad ratios surface immediately in origin bandwidth graphs. |
| Peak Throughput | At least 2× current peak as headroom | Protects UX during launches and events, especially for video‑heavy workloads; requires 10–100+ Gbps‑class ports at origin and key PoPs. |
| Traffic Mix & Growth | Video ~84% of traffic; IP traffic 18.8 EB/month by 2022 | Justifies deep caching and big pipes—Latin America is already video‑dominant and still growing fast. |
| Availability & Control | 99.9%+ regional availability; BGP + BYOIP everywhere | Lets you treat a CDN provider for South America as programmable network fabric rather than a black box, keeping flows regional and routes predictable. |
Key Design Takeaways for a Pan-Regional CDN South America Footprint
Once you map both infrastructure and demand, a few design patterns show up again and again for CDN South America deployments.
- Localize Aggressively and Peer in-RegionGet traffic onto South American IXPs as early as possible. Peer at IX.br and national exchanges so South America CDN flows don’t hairpin through Miami or random Tier‑2s. The payoff is often 100+ ms shaved off round‑trip times for cross‑border traffic.
- Use Brazil as the Regional Hub, Not the Only OriginKeep PoPs like Madrid and Atlanta as your global origin anchors while treating São Paulo as a regional shield for South America. The São Paulo PoP handles fan-in from long-haul and then fan-out to Lima, Bogotá, Buenos Aires, and Santiago, giving users “local” performance without forcing a full origin migration on day one.
- Design Inter-Country Routing DeliberatelyModel flows between neighbors, not just “user to origin.” Your routing policy should prioritize intra‑LatAm paths, use BGP communities to avoid bad upstreams, and keep return paths symmetric for latency‑sensitive apps.
- Size for Video and Peaks, Not AveragesLatin America’s IP traffic and video share are both on steep, long‑term ramps. Plan capacity around the worst case—launch days, finals, flash sales—backed by ports in the 10–200 Gbps range at origin and PoPs, rather than hoping averages will save you.
- Let KPIs Drive ExpansionTrack TTFB per country, cache hit ratio per PoP, and link utilization into Brazil. Add PoPs, or shift more workloads to forthcoming São Paulo dedicated capacity, when you see those metrics drift, not when users start complaining.
Operationalizing a South America CDN Strategy: Brazil Hub + PoPs
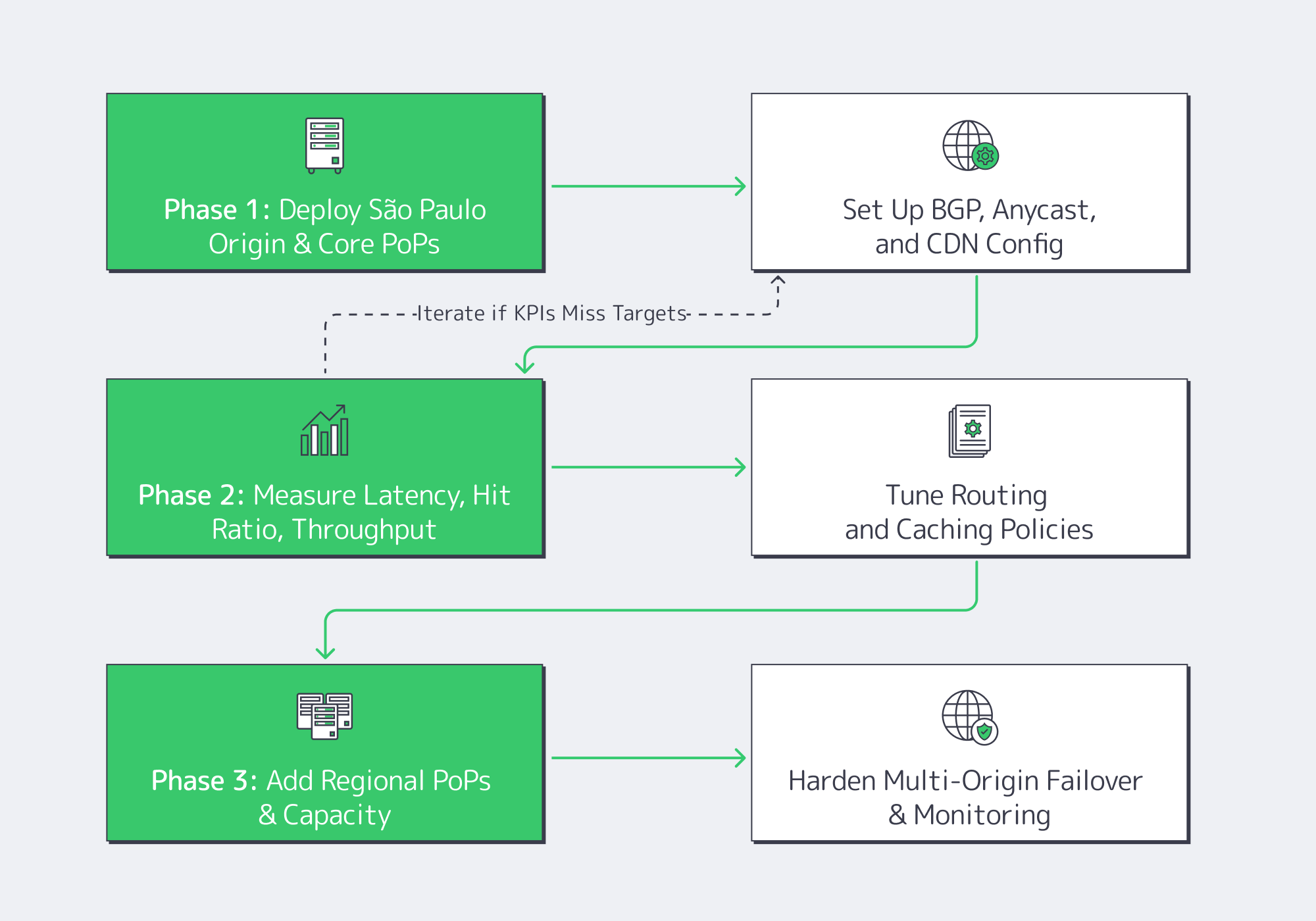
Putting this into practice usually follows a three‑step arc:
- Phase 1 – Core DeploymentStand up your primary origin cluster on dedicated servers in São Paulo, front it with an origin‑shielded CDN configuration, and establish BGP sessions plus BYOIP so routing is under your control. Start with a small ring of South America CDN PoPs that match your initial go‑to‑market countries.
- Phase 2 – Measurement and Policy TuningInstrument p95 latency, hit ratio, and per‑country concurrency. Tighten BGP policies where hairpinning still appears. Adjust cache TTLs and prefetching around traffic patterns (e.g., match‑day surges, trading windows, prime‑time streams).
- Phase 3 – Expansion and HardeningAs traffic grows, add PoPs and capacity in high‑growth markets, introduce secondary origins only where the risk profile justifies it, and harden multi‑origin failover. The result is a fabric that feels local across the continent but behaves like a single, coherent platform.
At that point, the distinction between “Brazil” and “the rest of South America” largely disappears from the user’s perspective — they just experience fast, consistent responses.
How Melbicom Helps You Deploy and Scale in South America
We at Melbicom built our platform for exactly this playbook: global origins plus a programmable edge.

Melbicom operates single-tenant dedicated servers in 21 Tier III/IV data centers spanning Europe, the Americas, Asia, and Africa, backed by a 14+ Tbps backbone, 20+ transit providers, and 25+ IXPs. We keep 1,300+ ready-to-go configurations in stock and deliver custom servers in 3–5 business days, offering per-server ports from 1 up to 200 Gbps depending on location. On top of that, Melbicom’s CDN spans 55+ PoPs in 36 countries, including São Paulo, Lima, Bogotá, Buenos Aires, and Santiago.
If you’re planning or refining your CDN service in South America and want to combine European/African/American origins with a South American edge that you actually control, contact us. We’ll help you translate traffic forecasts and KPI targets into concrete server reservations in existing data center locations and pre-reserved São Paulo capacity, wired directly into our regional CDN PoPs and global backbone.
Deploy Your South America CDN
Build a regional edge in Brazil with origins in Europe or the U.S. Our team can map PoPs, BGP policy, and capacity to your traffic targets across LatAm.
Get expert support with your services
Blog

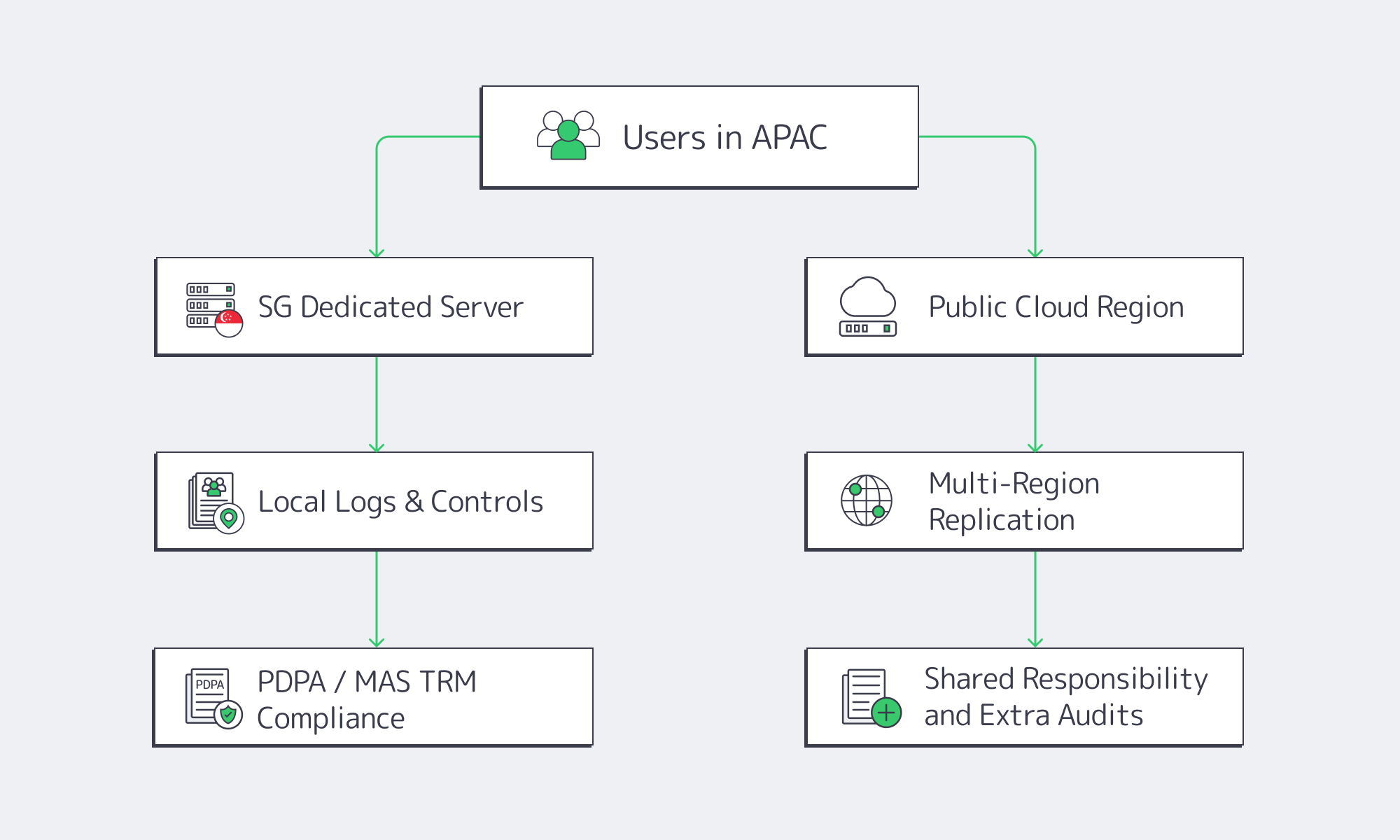
Dedicated vs. Cloud Hosting in Singapore
If you’re running high-growth infrastructure out of Singapore, the “all-in on public cloud” era is already over. Across Melbicom’s own customer base, the typical production stack now mixes public cloud, private cloud, and dedicated servers, with heavy, steady-state workloads quietly moving off hyperscale platforms.
Independent data matches what we see. TechRadar’s analysis found that 86% of companies still use dedicated servers, and 42% have migrated workloads from public cloud back to dedicated servers in the past year. Broadcom’s global survey of VMware customers reports that 93% of organizations deliberately balance public and private cloud, 69% are considering repatriating workloads from public cloud, and 35% have already done so.
Singapore sits at the centre of this rebalancing. The city-state is doubling down on its role as a regional hub, including plans for a 20-hectare, low-carbon data centre park on Jurong Island with up to 700MW of power capacity. For teams serving users across APAC, the real question is no longer “cloud or not?” but which workloads belong on a dedicated server in Singapore, and which should stay on cloud platforms.
Choose Melbicom— 130+ ready-to-go servers in SG — Tier III-certified SG data center — 55+ PoP CDN across 6 continents |
 |
In this article, we combine what we at Melbicom see running infrastructure in Singapore with recent research on performance, cost, and compliance. We’ll unpack where Singapore dedicated servers outperform cloud, where cloud still clearly wins, and how to design a mix that reins in cloud costs without handcuffing product teams. By the end, you should have a decision framework for placing each workload—plus a clear sense of when a dedicated server Singapore strategy is the more sustainable path.
When Do Dedicated Servers in Singapore Outperform Cloud for Performance?
Cloud still wins on sheer flexibility. But for latency-sensitive and throughput-heavy workloads, a well-designed dedicated deployment in SG usually has a structural edge.
Latency-Critical Workloads on Singapore Servers
A dedicated machine means no noisy neighbours, no shared hypervisor, and no surprise throttling. CPU scheduling, NUMA layout, storage IOPS, and network queues are all under your control. When you pin cores to specific services or tune kernel parameters, you actually get the benefit consistently—something far harder to guarantee on multi-tenant cloud hosts in production.
That matters for low-latency trading and pricing engines, real-time fraud detection and risk scoring, multiplayer game backends, WebRTC, live streaming, and interactive AI features. In those cases, a Singapore dedicated server hosted in a Tier III+ facility with strong peering will typically deliver more stable p95/p99 latency than a comparable cloud instance, simply because the stack between your process and the NIC is thinner and less virtualised.
At our Singapore site, we provision 1–200 Gbps of bandwidth per server on Tier III infrastructure, with 130+ ready-to-go configurations. Globally, we operate 21 data centers and a backbone tied into more than 20 transit providers and over 25 internet exchange points, fronted by a CDN delivered through 55+ points of presence in 39 countries. In practice, that combination—local compute plus global edge distribution—is exactly what latency-sensitive apps need: keep state and write paths in Singapore, push static or cacheable content out over the CDN, and avoid shipping every byte through expensive cloud egress on every request.
For European or North American teams expanding into Southeast Asia, this mixed setup often looks like:
- dedicated servers in Singapore for real-time APIs and stateful services,
- regional caches and CDN delivery for media and large payloads, and
- selective use of cloud services where managed functionality (for example, analytics or messaging) outweighs the jitter and cost.
Where Cloud Instances Still Shine
Cloud is still the fastest way to experiment. For bursty, short-lived workloads—ad-hoc analytics jobs, A/B tests, temporary campaign backends—spinning up instances on a cloud server Singapore platform is usually the right call. You get managed services, autoscaling, and platform tools without touching hardware.
For highly variable or unpredictable workloads, especially early in a product’s life, if traffic can swing 10x day-to-day and you haven’t yet stabilised demand, paying the flexibility premium is often cheaper than over-provisioning dedicated capacity.
Financial-sector analysis of cloud migration in Southeast Asia underlines this pattern. Institutions across Indonesia, the Philippines, Singapore, and neighbouring markets are accelerating digital banking, putting pressure on infrastructure but often starting on cloud to move quickly. The mistake isn’t using cloud; it’s leaving everything there once workloads become stable, heavy, and business-critical.
Cost: Dedicated Servers vs. Cloud Bills
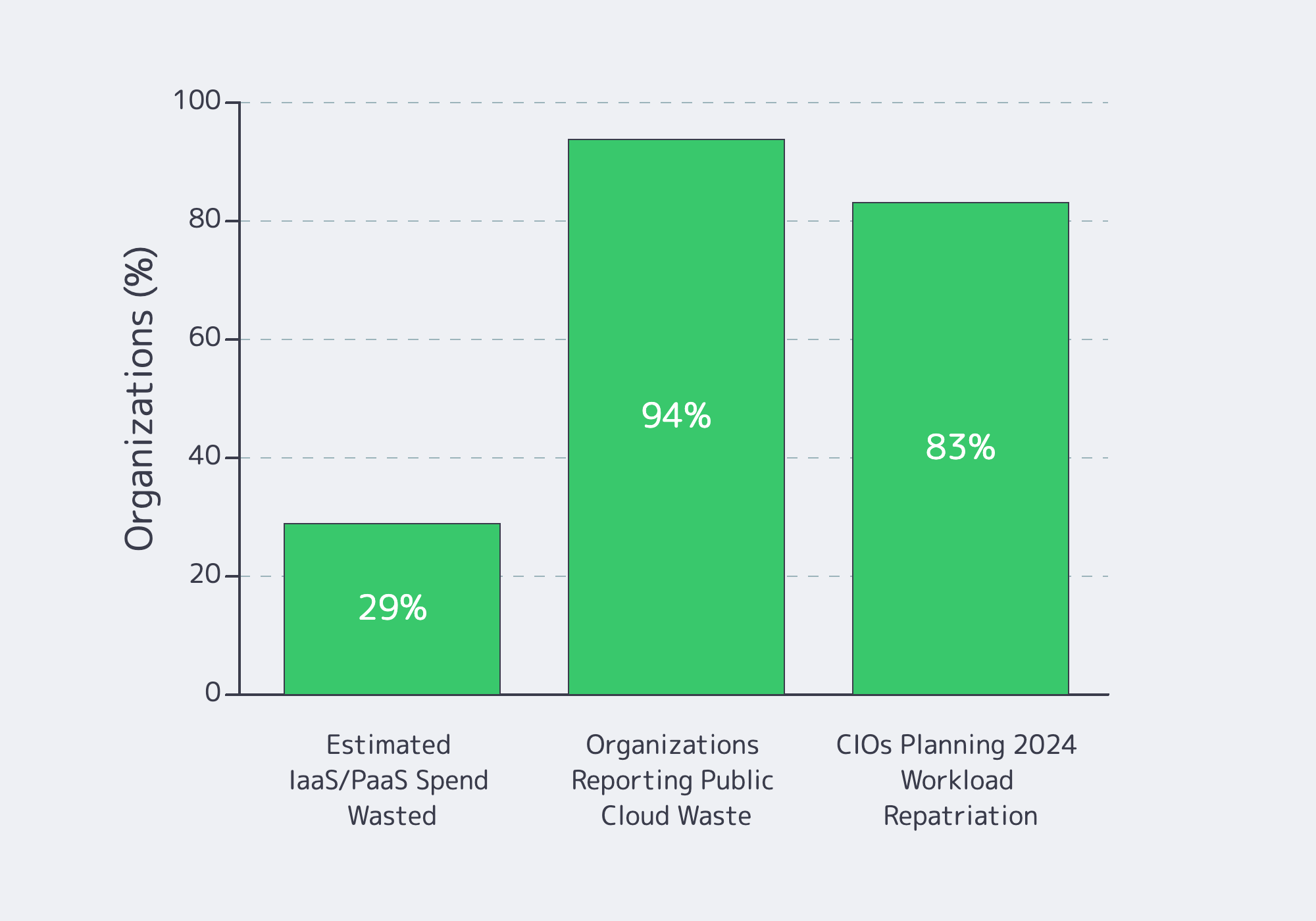
Public cloud pricing looks granular: per vCPU-hour, per GB-month, per million requests. In reality, your invoice tends to consolidate into one of the largest lines in the P&L.
In the same study cited earlier, nearly half of IT leaders reported surprise cloud-related infrastructure costs, and 32% felt a meaningful slice of their infrastructure budget was being wasted on under-used cloud resources.
Flexera’s 2026 State of the Cloud research gives the same cost-control warning in fresher terms: 73% of organizations now operate hybrid cloud estates, and respondents estimate that 29% of IaaS and PaaS spend is wasted.
Cloud Hosting in Singapore and the Actual Cost of Elastic Workloads
Cloud’s economic model is built around elasticity. You avoid upfront CapEx, but you pay a premium for every kWh, vCPU, and GB you consume—forever.
Andreessen Horowitz’s “Trillion-Dollar Paradox” analysis of public software companies found that, for some high-growth firms, committed cloud contracts averaged around 50% of cost of revenue—a level where optimization has a direct, material impact on gross margin. Broadcom’s survey work shows why many teams are re-examining their cloud footprint: 94% of IT leaders report some level of waste in public-cloud spend, nearly half believe more than a quarter of that spend is wasted, and 90% say private cloud offers better cost visibility and predictability.
In Southeast Asia’s financial sector, additional cost layers show up in the migration itself. A recent analysis of cloud migration projects across banks in the region points to high refactoring costs, long transitional periods where on-prem and cloud must be run in parallel, and the need for specialist cloud talent—each of which pushes the all-in cloud bill higher than the raw price list suggests.
High-density GPU nodes, sustained multi-gigabit throughput, and premium storage tiers all carry cloud pricing multipliers that compound as workloads grow. Once you add data-egress charges and inter-AZ traffic for chatty microservices, “just leave it in the cloud” stops being neutral advice.
How Dedicated Servers in Singapore Change the Unit Economics
Dedicated reverses that model. You pay a predictable monthly fee for a known quantity of CPU, RAM, storage, and bandwidth, and you can drive utilisation close to the limit without triggering new pricing tiers.
A Barclays CIO survey found that 83% of enterprises planned to move at least some workloads from public cloud to on-premises or private cloud infrastructure in 2024, up from 43% just a few years earlier—a striking swing driven largely by cost and control concerns. It’s not nostalgia; it’s unit economics.
For Singapore specifically, steady-state workloads such as core databases, ledgers, game backends, and real-time APIs often reach a point where running them on dedicated servers in a local facility is materially cheaper than keeping them on large cloud instances. Bandwidth-heavy services—video, file delivery, AI inference over websockets—benefit from flat-rate or high-included-traffic models. With a dedicated box pushing tens of gigabits and a CDN absorbing global distribution, your marginal cost per additional user often falls over time instead of rising.
At Melbicom, we see this pattern regularly. Teams start in the cloud, then move hot paths—databases, in-memory caches, critical application tiers—to our Singapore dedicated servers once traffic patterns stabilise. In our Singapore data centre alone, there are 130+ ready-to-go configurations, and custom servers can be assembled in roughly 3–5 business days, so there’s no long CapEx-style planning cycle. You keep an OpEx mindset while clawing back the premiums built into hyperscale pricing.
Dedicated vs. Cloud at a Glance
| Aspect | Dedicated Server in Singapore | Cloud Server in Singapore |
|---|---|---|
| Performance | Consistent, low-jitter performance with full control over hardware, network stack, and tuning. Best for latency-sensitive and high-IO workloads. | Good average performance, but more variance due to multi-tenancy, noisy neighbours, and shared hypervisors—especially at higher utilisation. |
| Cost | Fixed monthly pricing with high utilisation potential; better long-term unit economics once workloads are steady and resource-intensive. | Pay-as-you-go and CapEx-free, ideal for experiments and spiky demand; can become one of the largest recurring costs at scale. |
| Control & Compliance | Full control over data locality, access paths, logging, and change management; easier to map to internal policies and audits. | Shared responsibility model with constraints on where and how data is stored and processed; more complex to explain and evidence to regulators. |
Compliance and Data Control: Singapore Dedicated Servers vs. Cloud
Performance and cost are quantifiable. Compliance is more binary: either you can prove you meet your obligations, or you can’t.
PDPA, Financial Regulation, and Data Residency
Singapore’s Personal Data Protection Act (PDPA) has real teeth. The Personal Data Protection Commission (PDPC) can order organisations to stop processing data, delete unlawfully-held information, and impose fines of up to S$1 million, or up to 10% of annual Singapore turnover for organisations with local turnover above S$10 million, whichever is higher. Cross-border transfers are allowed only if the overseas recipient offers “comparable protection” to PDPA standards.
Layer on sectoral rules—such as MAS Technology Risk Management (TRM) guidelines in finance, PCI DSS for payments, and internal risk policies—and the tolerance for opaque control planes shrinks fast. A recent review of cloud migration in Southeast Asia’s financial sector highlights what this looks like in practice:
- overlapping data-protection regimes across markets,
- data-localisation requirements in countries like Indonesia and Vietnam,
- cloud concentration and vendor lock-in risks, and
- significant skill gaps and migration costs.
That mix is driving many institutions toward hybrid models: regulated systems anchored in a clearly defined environment (often in Singapore), with carefully curated use of public-cloud services around the edges.
Building a Defensible Control Story
A Singapore-hosted dedicated environment simplifies the story you tell auditors, regulators, and enterprise customers. You can point to specific racks in a Singapore data centre and document exactly which workloads and datasets run there. Only your team (and selected provider engineers under contract) can access the physical machines; there is no shared control plane and no other tenants on the box. OS images, patch cadence, encryption standards, and logging pipelines are all under your governance, making it easier to map them to PDPA, MAS TRM, PCI DSS, and internal policies.
By contrast, regulated workloads that remain on multi-tenant cloud platforms tend to require substantial additional governance: a carefully designed landing zone, multi-account structure, centralised security policies, and dedicated cloud-spend management tooling are all needed just to keep the environment compliant and economical. None of this negates cloud’s value—but it does highlight that the operational burden sits with you.
We at Melbicom lean into the simpler model where it helps. Our dedicated servers in Singapore run in a Tier III facility with 1–200 Gbps per-server bandwidth and direct connectivity into our global backbone. Regulated or high-risk workloads can stay entirely within Singapore, under your change control, while non-sensitive assets—media, cached responses, static content—are pushed out through our CDN for global reach. That lets you meet data-residency and audit expectations without accepting the cost and jitter of keeping everything in a single public-cloud region.
How Should You Mix Dedicated Servers and Cloud in Singapore?
Use dedicated servers in Singapore for stable, high-traffic, latency-sensitive, or regulated systems, and keep cloud for bursty experiments, managed services, and short-lived capacity. A practical hybrid model anchors stateful workloads locally, then uses CDN distribution for cacheable assets so compute placement, compliance, and bandwidth costs stay predictable.
For most teams, the answer in Singapore isn’t “all-cloud” or “all-dedicated.” The pattern emerging from both industry data and what we see in practice is a deliberate mix: core, steady-state, and regulated workloads on dedicated servers in Singapore; bursty, experimental, or heavily managed components in the cloud; and global reach delivered via CDN rather than by stretching a single compute layer everywhere.
Surveys and case studies point in the same direction. Enterprises worldwide are rebalancing toward private and dedicated infrastructure for their heaviest workloads, while keeping cloud for what it does best: fast iteration, managed services, and short-lived capacity. At the same time, Singapore is expanding low-carbon data-centre capacity and strengthening its role as an anchor for regional infrastructure, making it an obvious hub for that dedicated tier.
If you’re deciding where to place your next tranche of capacity in or around Singapore, a few practical recommendations follow from the analysis above:
- Anchor latency-critical and compliance-heavy systems on dedicated Singapore infrastructure. Real-time trading, risk, payments, game state, and other stateful services that suffer from multi-tenant jitter or complex audit trails belong on single-tenant servers under your direct control, close to your users.
- Use cloud platforms surgically for elasticity and managed primitives. Early-stage products, unpredictable workloads, and specialised managed services (databases, analytics, functions) still fit well on cloud hosting Singapore platforms—provided you set clear thresholds for when to repatriate long-running, resource-intensive components.
- Treat network and data-movement costs as first-class design constraints. For bandwidth-heavy or chatty services, design around high-capacity dedicated links in Singapore plus a CDN tier, rather than assuming cross-region or cross-provider traffic will remain a rounding error on your cloud bill.
Answering those questions honestly usually reveals the shape of your Singapore infrastructure portfolio without the need for ideology.
Get a Dedicated Server in Singapore
Ready to move stable or regulated workloads to Singapore? Deploy high-performance dedicated servers with 1–200 Gbps bandwidth and fast setup, backed by our global network, CDN, and 24/7 support.
Get expert support with your services
Blog

Winning Multinational Rollouts Across Latin America with Dedicated Servers
Latin America is no longer a “remote region” you serve from Miami, Ashburn, or Frankfurt and hope for the best. Investment, new capacity, and user expectations are moving too fast for that. IDB Invest estimates the region’s data center market will nearly double—from roughly $5B (2023) to almost $10B (2029)—and notes ~30 new data centers under construction or recently inaugurated.
But CTOs don’t win LATAM by copy/pasting a global template. They win with a unified rollout playbook that treats the region as it is: multiple regulatory regimes, multiple last-mile realities, and multiple connectivity “truths,” even when the map looks contiguous.
This playbook is focused on three levers that make or break a multinational rollout:
- Procurement: how you standardize hardware decisions while staying locally realistic.
- Network blend: how you keep transit and peering from becoming a black box.
- Monitoring: how you measure latency, loss, and availability the same way everywhere.
And because Brazil is both the biggest prize and the most common misstep, we’ll define when Brazil should be your primary origin and where secondary nodes should live.
Servers in LATAM— Reserve server hardware in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
Why a Global Template Breaks for a LatAm Dedicated Server Rollout
A global template typically assumes three things that fail in Latin America:
- Latency is geographic. In practice, it’s often policy + peering + congestion + last-mile.
- Your origin can sit outside the region. That works until cross-border jitter breaks real-time apps, or regulation demands local processing.
- One monitoring plane is enough. In LATAM, you need coordinated monitoring across countries, not just a single “green dashboard” from a U.S. vantage point.
The fix is not “more regions.” It’s a unified playbook that makes deployments repeatable while letting topology stay locally intelligent.
Procurement: Treat Dedicated Server in South America as a Supply Chain Decision
If you’re expanding fast, procurement is where rollouts quietly die—usually via inconsistent server SKUs, uneven spares strategy, and “temporary” instances that become permanent.

A procurement model that survives LATAM has three layers:
- Standardize server families, not exact SKUs. Pick 2–3 CPU/memory/storage archetypes aligned to your workloads (API, DB, cache/stream). Keep the bill of materials flexible enough to land locally without re-architecting.
- Standardize port and traffic assumptions per role. Origin nodes are not edge nodes. Your origin may need higher sustained egress and predictable routing control; edges need burst-friendly delivery and fast cache turnover.
- Standardize the deployment contract. Imaging, secrets, config management, and observability must be identical whether the node is in Brazil or elsewhere.
For Brazil specifically, plan around the reality that São Paulo is the procurement + connectivity center of gravity. São Paulo is one of the most interconnected hubs and a practical foundation for LATAM architectures.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
Network Blend per Country: Stop Treating “Transit” as a Single Line Item
In LATAM, the network blend is not just cost optimization. It’s your latency distribution, your loss profile, and your incident radius.
A functional model:
- Pin your performance targets to SLOs, not to providers. Your SLO is what matters; providers are just knobs.
- Design for country-local exit where it matters. If your traffic regularly hairpins across borders to find a peering point, you’ll see random “bad days” you can’t reproduce.
- Use BGP only when you can operationalize it. Routing control is powerful, but only if you monitor route changes, maintain prefix hygiene, and have a clear rollback playbook.
On the Melbicom side, BGP sessions are available (including BYOIP) for free on dedicated servers—useful when you want deterministic routing behavior across regions without rewriting your architecture.
Coordinated Monitoring: One SLO, Many Vantage Points

The classic failure mode: your monitoring says “fine,” users in Bogotá say “broken,” and the network team can’t reproduce the problem from outside the region.
Coordinated monitoring means:
- One SLO definition across the rollout (p95 latency, packet loss, HTTP error budgets, stream join time, etc.).
- Multiple vantage points inside the region and across borders so you can distinguish “Brazil is down” from “Argentina-to-Brazil transit is degraded.”
- A single correlation model: BGP changes, CDN cache hit ratio shifts, and origin load must be visible in the same incident timeline.
This is where “global template thinking” fails hardest. LATAM needs a shared measurement language, not a single measurement location.
Brazil Dedicated Server as the Primary Origin: The Rule, the Exception, the Reality
Brazil is the easiest place to overfit. It’s huge, economically central, and network-dense—but it’s not automatically the best origin for every LATAM deployment.
When a Brazil Dedicated Server Should Be Your Primary Origin
Use Brazil/São Paulo as the primary origin when at least one of these is true:
- Brazil is your largest market (user volume, revenue, or regulatory risk).
- Your application is sensitive to peering gravity. São Paulo’s IX.br ecosystem is a real differentiator when you need to reach into Brazilian networks.
- Your workload is latency-sensitive inside Brazil. The 2–3 ms round-trip latency within the São Paulo–Rio corridor is exactly the type of metric that matters for fintech, trading, and real-time iGaming systems.
- You need routing control at the origin. If you’re doing multi-region failover or traffic steering, control belongs at the origin, not only at the edge.
When Brazil Should Not Be Your Only Origin
Brazil-as-only-origin breaks when:
- Your users cluster heavily in Mexico or the northern tier (crossing multiple borders to reach São Paulo creates a wide jitter envelope).
- Your risk model can’t tolerate a single “regional heart.” A São Paulo issue shouldn’t become a LATAM-wide incident.
- Your app’s write-path is globally chatty (e.g., synchronous cross-service dependencies). In that case, the origin must be closer to the majority of your request graph, not just the biggest map country.
Where to Add Secondary Nodes—and What They Should Do
Secondary nodes are not mini-origins by default. Their job is to absorb latency, isolate incidents, and localize delivery.
A practical pattern for LATAM:
- Brazil/São Paulo as primary origin for data gravity
- Secondary nodes as delivery + resilience points in the largest non-Brazil demand centers
For Melbicom specifically, the current LatAm CDN footprint includes PoPs in São Paulo, Santiago, Buenos Aires, Lima, Bogotá, and Mexico City (useful for “near-user” delivery when the origin is centralized). This is how you keep the LATAM delivery redundant even when the origin is in one country.
Table: Practical Topology Patterns for Multinational LATAM Rollouts
| Pattern | Primary Origin | Secondary Nodes (Role) |
|---|---|---|
| Brazil-centric LATAM | São Paulo | Santiago / Buenos Aires / Lima / Bogotá / Mexico City as delivery nodes (cache, acceleration, fail-soft) |
| Split LATAM delivery | São Paulo | Two “anti-hairpin” secondary nodes aligned to demand clusters (e.g., Pacific vs. Southern Cone) |
| Resilience-first | São Paulo | Secondary nodes sized for “read-heavy continuity” during origin degradation (serve cached, degrade writes) |
A Unified LatAm Dedicated Server Playbook
A unified playbook is not a template. It’s a contract:
- Treat LATAM as multiple network domains: build one rollout system, but allow topology to vary by country.
- Choose São Paulo as origin when Brazil traffic/compliance dominates; otherwise, avoid making it your only “regional heart.”
- Add secondary nodes to prevent hairpin latency and to keep incidents local; size them for the failure mode you’re willing to tolerate.
- Make routing control operational (or don’t do it): BGP without monitoring and rollback is just chaos with better vocabulary.
- Run coordinated monitoring with in-region vantage points so you can separate “origin issues” from “cross-border path issues.”
- Lock procurement to server families and role-based bandwidth assumptions so your rollout doesn’t stall on SKU mismatches.
Deploy, Customize, and Scale LatAm Infrastructure With Melbicom

Melbicom can help you finalize this blueprint. We’re opening priority access for teams preparing LatAm rollouts anchored in Brazil. Share your traffic profile, hardware requirements (CPU/GPU, NVMe tier, port targets, redundancy and DDoS posture), and timelines, and we’ll shape a tailored offer and pre-stage capacity across our network and LatAm CDN—with first-wave placement when São Paulo dedicated servers go live.
Plan your LatAm rollout with Melbicom
Share your traffic profile and hardware needs. We’ll validate routes, size capacity, and pre-stage Brazil origin with CDN and DDoS options across LatAm.
Get expert support with your services
Blog

Maximizing Uptime: Redundancy and DDoS Protection for Adult Hosting
Outages on adult platforms tear straight into revenue and brand trust. Industry research on downtime estimates average losses of around $9,000 per minute for digital businesses, with large enterprises absorbing hundreds of millions annually across incidents. For an adult platform that lives or dies on recurring spend and creator loyalty, the real bill includes churn, chargebacks, and ad campaigns to recover reputation.
At the same time, the volume and shape of traffic keep tilting the odds against you. Video already accounts for about 82% of all internet traffic, and that share is still rising as more consumption shifts to streaming. Adult content is massively over‑represented in that stream: multiple independent analyses still converge around roughly 35% of all internet downloads being linked to adult content.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
|
That traffic is increasingly live. In the broader content ecosystem, one recent analysis of social usage found around 70% of social media users now prefer live video over pre‑recorded content, with Gen Z spending about 3.5 hours a day on social platforms and dedicating a big chunk of that to live streams. Adult creators are following the same curve: interactive cam sessions, real‑time shows, and pay‑per‑minute live events.
Meanwhile, the attack surface is getting more hostile, not less. Cloudflare’s telemetry shows how quickly DDoS has escalated: 4.5 million DDoS attacks mitigated in just Q1 2024 — and 36.2 million attacks already mitigated in the first three quarters of 2025, a 170% increase over all of 2024. Many of those are short “hit‑and‑run” bursts; Cloudflare’s Q1 2025 report notes that 89% of network‑layer and 75% of HTTP DDoS attacks end within 10 minutes — far too fast for manual mitigation or ticket‑driven response.
On top of that, DDoS is no longer just about volume. Streaming‑focused security research highlights ransomware, bots, DRM bypass, and data breaches as core threats for media platforms, with bots alone accounting for nearly half of all internet traffic and significantly distorting performance and analytics. For adult platforms, that means every outage or slowdown is a revenue, trust, and compliance event — not just a technical one.
We at Melbicom operate dedicated streaming infrastructure, CDN, S3‑compatible storage, and BGP‑enabled routing for high‑risk verticals. In this article, we combine that experience with current data on DDoS trends, streaming economics, and traffic behavior to answer one question: how do you design adult hosting DDoS protection and redundancy so that attacks, surges, and failures become routine engineering problems, not existential crises?
Key Signals: Why Uptime Is Non‑Negotiable for Adult Platforms
| Factor | Data Point | Why It Matters for Adult Platforms |
|---|---|---|
| Video dominance | Video made up 82% of all internet traffic in 2022 and continues to grow. | Adult platforms are overwhelmingly video‑first; your entire product is exposed to bandwidth and latency shocks. |
| Adult share of downloads | Around 35% of all internet downloads are adult media. | You operate in one of the highest‑volume verticals, with matching visibility to attackers and regulators. |
| 4K streaming cost | Netflix‑style 4K streams run at ~25 Mbps and ~7 GB/hour. | High bitrates make concurrency spikes especially punishing for origin and network if capacity planning is conservative. |
| DDoS escalation | Cloudflare mitigated 4.5M DDoS attacks in Q1 2024 and 36.2M in 2025 YTD, 170% of the 2024 total. | The background noise of attacks is now continuous; you should assume you’ll be hit, repeatedly. |
| Cost of downtime | Oxford Economics‑based analysis pegs average IT downtime at ~$9,000 per minute for large organizations. | Even short outages during peaks can erase months of margin — before you factor in refunds, churn, and brand damage. |
Adult Hosting DDoS Protection: Why Uptime Is Non‑Negotiable
For an adult platform, “five nines” isn’t a purely academic SLA number — it’s a proxy for creator payouts, partner trust, and risk tolerance from payment providers and ad networks.
Attackers understand this leverage. They time campaigns to coincide with:
- High‑profile drops: new series, branded shows, influencer crossovers
- Scheduled live events: cam marathons, paid live streams
- Promo pushes: email, socials, affiliate pushes landing within a narrow window
Modern DDoS traffic is rarely a single brute‑force flood. It’s multi‑vector and time‑boxed, often combining volumetric L3/L4 floods with HTTP‑layer noise and bot activity. Cloudflare’s Q1 2025 data shows that while most attacks are “small” by hyperscaler standards, they still saturate typical enterprise links and crash unprotected servers — and almost all finish before a human can triage.
At the scale of a busy adult tube or premium live platform, that means:
- On‑demand mitigation is effectively obsolete. By the time you’ve paged the on‑call and switched traffic into a third‑party scrubber, the first campaign is over — and the second is warming up.
- Attack and organic surges look similar at the edge. A trending creator or viral promotion can produce request curves that resemble a denial‑of‑service without good instrumentation and rate‑limiting.
Any credible adult hosting DDoS protection strategy therefore has to assume always‑on, automated mitigation at the network and CDN layer, and redundant, high‑bandwidth dedicated servers behind that shield, sized for peak traffic plus a safety margin, not monthly averages.
Adult Video Content and File Hosting
Most serious adult platforms now rely on dedicated streaming servers fronted by a CDN, plus separate object storage for archives and downloads. The objective is simple: keep origin nodes lean, cache everything aggressively, and ensure that no single physical server or rack is a point of failure — even under sustained attack.
Under the hood, this means designing around the realities of high‑bitrate, attack‑prone traffic. From an infrastructure standpoint, resilient adult hosting for this layer looks like:
1. High‑bandwidth dedicated servers close to users
Melbicom offers dedicated servers in 21 Tier III/IV data centers globally, including hubs like Amsterdam, Los Angeles, São Paulo, Lagos, Madrid, and Singapore. Depending on location, per‑server ports range from 1 Gbps up to 200 Gbps, so clusters can be built for everything from regional cam platforms to global video archives.
2. CDN offload as a first‑class requirement, not an add‑on
Melbicom’s CDN is built on 55+ PoPs across, with origin shielding, geographic request routing, and multi‑origin pooling for load balancing and failover. For adult workloads this does three things:
- Keeps hot content local to viewers, reducing TTFB and rebuffering.
- Shields origins behind anycast PoPs so DDoS traffic is handled at the edge.
- Enables regional A/B testing (e.g., moving a subset of traffic to a second origin cluster without DNS flips).
3. S3‑compatible object storage for archives and downloads
For long‑tail catalogs and large downloadable assets, Melbicom’s S3‑compatible storage provides NVMe‑backed storage with erasure coding and IAM controls. That gives you:
- A durable backing store for originals and mezzanine files.
- The ability to serve files via CDN using signed URLs, keeping S3 points private.
- Predictable bandwidth pricing and free ingress, which matters when you’re constantly ingesting new content.
The architectural pattern is straightforward: dedicated servers for transcoding and origin, CDN for distribution, S3 for durability — all stitched together over a backbone that is engineered for DDoS resistance and redundancy end‑to‑end.
Adult Content Hosting Solutions
You can think of a serious adult hosting stack as a set of layers that must all behave correctly under both traffic overload and active attack:
Dedicated Servers as the Backbone of Resilient Adult Infrastructure
Single-tenant servers provide deterministic bandwidth per machine — in Melbicom’s case, anywhere from 1 Gbps to 200 Gbps per server — along with full control over kernel-level network handling, cache hierarchies, and storage layouts. They also offer a predictable cost model, allowing bandwidth and hardware to be sized for worst-case live-event loads rather than averages. From there, true resilience comes from how those servers are arranged.
Anti‑DDoS Dedicated Servers for Adult Sites
Because modern DDoS attacks are surgical and increasingly automated, mitigation has to be inline and always on. The nature of these bursts — often lasting under a minute and mimicking legitimate traffic — turns them into a design constraint. For adult hosting, this means edge defenses must be behavior-aware rather than reliant on default CDN or WAF profiles. Attacks frequently disguise themselves as cached traffic, abuse search and 404 endpoints, or rely on randomized query strings and headers to bypass caching. Effective protection now depends on CDNs that rate-limit both cached and dynamic content, block cache-busting patterns, and aggressively cache or pre-compute expensive endpoints. It also requires behavioral analysis that evaluates request patterns, timing, and headers rather than just IP addresses.
At the network layer, capacity and filtering need to be built directly into the backbone to withstand the hyper-volumetric spikes seen in 2025. Melbicom follows this model by integrating always-on DDoS filtering into its global network, removing hostile traffic as it enters the backbone without billing tenants for attack bandwidth, and ensuring neighboring customers benefit from the same hardened paths. On the server side, resilient architectures typically separate edge-origin and core-origin clusters to protect control-plane and storage systems; isolate login and payment endpoints on hardened origins; and implement strict health checks with circuit breakers so degraded regions are drained quickly rather than flapping between unhealthy nodes.
Redundant Adult Hosting and Global Failover
DDoS is only one failure mode; routine issues like fiber cuts, power problems, regional routing incidents, or deployment mistakes can be just as damaging. For adult platforms operating across North America, Europe, and fast-growing markets, three redundancy patterns consistently work well.
The first is active/active regions for core web and API functions, with at least two regions per continent, each running its own server pools and database replicas. A global CDN routes users to the nearest healthy region, and origin pools are configured so a secondary region can take over within seconds without relying on DNS changes.
The second is BGP-enabled stability: when you own your IP space, BGP sessions with the hosting provider allow your prefixes to be announced across multiple data centers. Melbicom’s BGP Session service lets customers move services between locations while keeping IPs stable, use multiple upstreams with RPKI/IRR protections, and maintain consistent premium/API hostnames for partners that whitelist specific addresses.
The third pattern is separating the hot path from bulk storage. Live and frequently accessed content is served from high-bandwidth origins close to major audiences, while cold archives sit in S3‑compatible storage accessed through signed CDN URLs. During partial outages — such as a regional issue in one data center — this design lets platforms deprioritize high-latency archival fetches and focus on keeping the hot path (live sessions, trending VOD, logins, payments) responsive.
Security trends for streaming underscore why this separation matters. Cybergen’s analysis of streaming threats in 2025 highlights how ransomware, bots, and data breaches can all hit the same platform at once, and that “almost half of internet traffic” now comes from bots that degrade performance and distort analytics if left unchecked. A layered architecture gives you options to contain damage.
Are There Any Reliable Hosting Services Specialized in Adult Content?
Yes — but “reliable” has to mean more than just allowing adult content. You want providers that understand streaming workloads, tolerate payment‑provider and regulatory pressure, and operate their own network, data centers, CDN, and storage, so they can actually deliver on uptime and DDoS resilience.
For adult platforms, due diligence should focus on three questions:
- Does the provider operate its own backbone and CDN, or just resell? Melbicom runs a global backbone with 21 Tier III/IV data centers and 55+ CDN PoPs across 36 countries, giving us direct control over routing, DDoS filtering, and peering. This vertical integration is what makes deterministic latency and failover possible.
- Can they actually absorb and mitigate real‑world DDoS campaigns? With hyper‑volumetric attacks now reaching 22.2 Tbps and ~10.6 billion packets per second, and thousands of >1 Tbps or >1 Bpps attacks recorded in a single year, your provider’s DDoS story has to go beyond “we use a firewall.” Melbicom’s network‑native DDoS filtering and CDN‑level request handling are built specifically for this environment.
- Is there enough hardware variety and capacity to match your growth curve? For adult workloads, we typically see platform teams evolve from a handful of mid‑range servers to dozens of high‑bandwidth configs across regions, often with bespoke builds (deployed within 3–5 business days). We also maintain over 1,300 ready‑to‑go server configs, so scaling isn’t a procurement project every time you cross a new threshold.
When those ingredients are in place — adult‑friendly policies, vertical control over the stack, serious DDoS capacity, and hardware variety — reliable adult hosting stops being a marketing phrase and becomes a measurable property of your platform.
Bringing It All Together: Architecting Always‑On Adult Platforms

Adult platforms now operate at the intersection of three compounding pressures:
- Explosive video and live‑stream growth, with users expecting 4K‑grade experiences on every device.
- A DDoS environment defined by hyper‑volumetric, short‑lived attacks, often combined with bot traffic and fraud.
- Tight regulatory and reputational constraints, where failures quickly ripple into payment friction, affiliate distrust, and creator churn.
The only sustainable answer is to treat redundancy and DDoS protection as first‑order design constraints, not bolt‑ons. That means sizing dedicated servers for peak concurrency, running active/active regions behind a CDN that understands your origin topology, and relying on always‑on, behavior‑aware mitigation that can respond in seconds without human intervention.
At the same time, the threat landscape sketched by DDoS and streaming‑security research is a reminder that you can’t silo DDoS from the rest of your security posture. Ransomware, bots, DRM bypass, and privacy breaches all lean on the same infrastructure choices: where you store data, how you segment networks, which services are exposed publicly, and how your provider’s backbone handles abusive traffic.
For teams making roadmap decisions now, a practical checklist looks like this:
- Multi‑region origins and APIs with health‑checked routing and no single points of failure at the data‑center level.
- Always‑on, multi‑layer DDoS protection: CDN and network filtering tuned for both volumetric floods and subtle cache‑busting or login abuse.
- High‑bandwidth dedicated servers sized for real‑world live event peaks, not monthly averages — with room for 4K and multi‑camera expansion.
- Caching and storage tiers that keep hot content near users and cold content in durable, cost‑effective S3‑compatible storage.
- Operational runbooks and incident drills that assume DDoS, ransomware, and regional outages will intersect — and that human response may lag behind the 1st wave.
- Continuous monitoring of bots and fraud, treating analytics integrity as part of uptime, not a separate problem.
You don’t eliminate risk by doing this, but you change its character: from catastrophic, incidents to bounded engineering challenges you can model, rehearse, and recover from.
Streaming‑optimized servers for uptime
Deploy high‑bandwidth dedicated servers, global CDN, and S3‑compatible storage with always‑on DDoS mitigation. Explore streaming‑focused configurations and deploy quickly.
Get expert support with your services
Blog

iGaming Hosting in LatAm: Brazil + U.S. Southeast Stack for Sub-150 ms Play
If your iGaming platform already runs cleanly in the U.S., LatAm expansion isn’t “add a CDN and call it done.” Brazil changes the physics: payment APIs have sharp timeout cliffs, odds and promos churn hard, and LGPD turns “just replicate it” into a data-class decision.
This is the practical blueprint we at Melbicom recommend when the target is Atlanta as the U.S. origin plus a São Paulo secondary region—with CDN PoPs in South America doing the heavy lifting during peak events, not just serving logos.
iGaming Hosting in LATAM— Reserve servers in São Paulo — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
|
Blueprint for Dual-Region iGaming Stack
The winning pattern is a dual-region core with the CDN edge acting as a traffic governor. Use Atlanta for the U.S.-native platform gravity (core services, analytics, global backoffice), and São Paulo for Brazil-first latency, payment conversion, and LGPD-aligned residency. Then let the CDN absorb bursty reads—especially around live odds and promo pushes.
São Paulo Dedicated Server: What Must Stay Local
A dedicated server in São Paulo isn’t just “closer compute.” It’s where you park the request paths that punish latency and jitter: Brazil login/session edges, cashier initiation, fraud/risk checks that must answer quickly, and the parts of the platform that touch regulated identity data.
CDN in LatAm: Burst Control, Not Just Static
CDN in South America is where you win peak moments: high-concurrency bursts during marquee matches, promo banners flipping, and “refresh the odds” behavior that looks like a denial-of-wallet if you serve it all from origin. Melbicom’s CDN has 55+ PoPs in 36 countries (including Chile, Columbia, Peru, Argentina, and Mexico), which is the baseline you need to keep cache near bettors while the origins stay deterministic.
Atlanta Origin: Where to Consolidate Without Penalizing LatAm
Atlanta works because it’s a U.S. Southeast anchor with strong interconnect potential—and because it lets you treat LatAm as an extension of a U.S. control plane without forcing every bettor’s click to cross an ocean.
How to Reach Sub-150 ms Latency in LatAm?
Sub‑150 ms play comes from pinning Brazil’s latency-sensitive flows to São Paulo, then using the CDN edge to suppress bursty reads across LatAm so that only state-changing requests reach origin. Atlanta remains the system’s authority, but São Paulo becomes the regional execution point for sessions, cashiers, and regulated identity paths.
What “Real Routing” Looks Like in Practice
The goal isn’t a single magical RTT number. It’s ensuring that the longest path is the least frequent path, especially during live events when every extra origin trip stacks.
Brazil: Edge → São Paulo (Regional Origin) → Atlanta (Only When Needed)
For bettors in Brazil, the cleanest route is:
- Nearest CDN Brazil PoP → serves static assets + safe cached API responses
- Misses / state-changing calls → routed to São Paulo dedicated server
- Selective replication → São Paulo emits events upstream to Atlanta (not the reverse)
The São Paulo page calls out direct subsea connectivity and positions São Paulo as LatAm’s interconnect hub. That matters because even when Atlanta is the authority, São Paulo must be able to “phone home” reliably under load.
Chile, Peru, Colombia, Mexico: Edge → Decision Point (São Paulo vs. Atlanta)
For Chile/Peru/Colombia, don’t hardcode everything to São Paulo. Use a simple rule:
- If the flow is cashier/KYC/identity for Brazil accounts → São Paulo
- If the flow is global account management, CMS, reporting → Atlanta
- If the flow is real-time odds reads → edge microcache (and only revalidate as needed)
Latency Budgeting Without Guesswork: Use Floors, Then Engineer for Variance
Measured RTT varies by ISP and peering. But physics gives you a floor—use it to sanity-check whether a proposed routing plan is even plausible.
Hypothetical sample (computed floor; real RTT is higher):
| Market (Anchor City) | RTT Floor to São Paulo (ms) | RTT Floor to Atlanta (ms) | Practical Implication |
|---|---|---|---|
| Brazil (São Paulo) | ~0 | ~75 | Keep “hot path” in São Paulo; don’t bounce through Atlanta |
| Colombia (Bogotá) | ~43 | ~34 | Split by data-class; steer odds reads to edge, writes to appropriate region |
| Peru (Lima) | ~35 | ~52 | São Paulo often wins for LatAm-facing real-time flows |
| Chile (Santiago) | ~26 | ~76 | São Paulo is a strong regional origin; edge does burst suppression |
Which Dual-Region Failover Cuts Downtime?
Use active service in both regions, but don’t force symmetric data ownership. Keep Atlanta as the system authority while São Paulo runs Brazil-first execution paths with replicated state that’s sufficient for continuity. Failover should be edge-driven (CDN + DNS steering), with degraded modes that preserve wagering integrity.
Failover That Doesn’t Create a Second Outage
A dual-region system fails when the failover process triggers its own incidents: cold caches, exploding origin load, inconsistent sessions, or payment retries that double-charge.
The safer failover topology:
- CDN as traffic valve: During São Paulo impairment, edge stops revalidation storms by widening TTLs for non-critical reads and serving “last known good” promo assets.
- Two origins behind one hostname: CDN can route misses to the healthier origin.
- Session strategy that survives a region swap: Store only what must be consistent globally in the shared plane; keep per-region session state small.
On Melbicom’s side, the “2-hour activation” and “3–5‑day custom builds” claim exists as an operational lever for capacity planning around known peak events—especially when you want pre-staged headroom in São Paulo before a live spike.
Peak Events: How São Paulo Dedicated Servers and CDN PoPs Work Together
Peak load in iGaming is not just “more traffic.” It’s more volatility: odds flip, promos rotate, and bettors refresh like humans trying to DoS reality. Here’s the collaboration model:
CDN PoPs cache:
- app shells, static assets
- promotion creatives
- “safe-to-cache” API reads
São Paulo dedicated server handles:
- regional “truth” for Brazil-facing reads (odds snapshots, wallet pre-checks)
- write paths (bets, wallet debits, KYC flows)
Atlanta remains:
- authoritative ledger replication target
- global reporting, segmentation, long-tail service mesh
This avoids the classic peak-event failure where edge handles nothing meaningful and São Paulo becomes a single hot pipe.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
|
What Data Zoning Meets LGPD?
Zone by data class, not by service name. Keep KYC/PII and Brazil-regulated identity paths in São Paulo, and replicate tokenized, minimized, and audit-safe records to Atlanta. Your CDN should never cache PII; it should cache public assets and strictly controlled “safe reads” with rapid invalidation.
Zoning Blueprint: A Data Map You Can Defend
The practical interpretation is: decide what must remain in Brazil versus what can cross borders as minimized data. Recommended split:
Brazil zone (São Paulo)
- PII and KYC artifacts
- identity verification outcomes
- payment initiation metadata (especially PIX rails)
- session attributes that materially identify a person
U.S. zone (Atlanta)
- anonymized gameplay telemetry
- fraud signals that are not directly identifying
- aggregated reporting events
- operational metrics, SLO-style indicators
Payment Gateway Proximity: Why PIX and Cards Belong in the Brazil Hot Path
Payments have a different tolerance curve than gameplay. You can “hide” latency with client-side prediction in some interaction patterns. You can’t hide it when:
- a PIX QR payload is generated and expires,
- a card auth window closes,
- a cashier retries and creates duplicate intents.
The operational advice is simple: terminate Brazil payment orchestration in São Paulo, even if the ledger authority is Atlanta. São Paulo should be close enough to answer fast and avoid jitter-driven timeouts—then replicate the minimal payment event upstream.
High-Frequency Cache Purges for Odds and Promos (Without Melting the Origin)
Odds and promotions are the edge-case where the CDN can either save you or ruin you.
Treat them differently:
- Promos: rotate a version token in the URL so you can publish without broad purges.
- Odds: cache for seconds at the edge; revalidate against São Paulo; keep Atlanta out of the revalidation loop.
- Cache purge storms: use scoped purges by tag/key class; never purge “everything” during live events.
This is where the São Paulo region acts as a regional origin so that cache misses don’t bounce across continents.
FAQ
Do we need two full copies of every service in both regions? No. Duplicate what is required for continuity and compliance. The high-availability goal is consistent wagering integrity, not perfect symmetry. Keep authority in one place (Atlanta), and ensure São Paulo has enough state to serve Brazil hot paths.
What should the CDN cache in iGaming without creating compliance risk? Static assets and tightly controlled read endpoints that are non-identifying. Avoid caching anything that can reveal identity, wallet state, or KYC status. Use microcaching for odds snapshots and short-lived promo metadata.
How do we prevent payment retries from double-charging during failover? Make cashier intentions idempotent and region-aware. São Paulo should mint the intent for Brazil flows; Atlanta should accept replicated intent events and treat repeats as retries, not new purchases.
Does São Paulo help non-Brazil LatAm markets? Often, yes—especially when your alternative is a full U.S. hop. But you still steer by data-class: Brazil KYC and cashier flows to São Paulo; global admin/reporting and non-sensitive flows can remain in Atlanta.
Conclusion: LatAm Should Feel Local Even When Your Stack Is U.S.-Native
Atlanta + São Paulo isn’t about splitting your platform in half. It’s about deciding which flows are latency-sensitive, which flows are compliance-sensitive, and which flows are just bursty—then assigning each to the right layer (edge, São Paulo, or Atlanta) so peak events don’t rewrite your reliability story.
The operational pattern that holds up under real match-day behavior is consistent: edge suppresses reads, São Paulo executes Brazil’s hot paths, and Atlanta stays authoritative without becoming the bottleneck.
Practical Guardrails
- Treat Brazil payments (PIX + cards) as a first-class regional workflow; don’t backhaul cashier orchestration to the U.S.
- Split traffic by data class, not by “service name”; zone KYC/PII and identity artifacts in Brazil, replicate minimized events to the U.S.
- Engineer odds and promos as cache-native: versioned promo assets, microcached odds reads, scoped purges—no global “flush it all” during live spikes.
- Design failover to protect the origin from the edge: widen TTLs and serve last-known-good when regions wobble; recover gradually.
- Keep São Paulo “hot” ahead of predictable peaks: pre-warm caches, stage capacity, and rehearse cache-invalidation mechanics under load.
Design your LatAm iGaming footprint
Get a technical consult on Atlanta + São Paulo architectures, CDN tuning, and LGPD-ready data zoning to keep latency under 150 ms across Brazil and LatAm.
Get expert support with your services
Blog

Singapore Servers as Your APAC Low-Latency Anchor
For many global teams, Asia-Pacific is where latency budgets go to die. The region already has the world’s largest online population, yet penetration is still catching up — which means user growth is shifting east while expectations for “instant” experiences keep rising.
At the same time, Asia-Pacific’s e‑commerce market alone is projected to exceed USD 7 trillion by 2030, making it the world’s largest and fastest‑growing digital commerce region. Real‑time payments, streaming, multiplayer games, and SaaS collaboration tools are all piling onto the network. For any product with global ambitions, slow paths into Southeast Asia and North Asia are now an existential risk, not just a UX blemish.
Underneath that demand, data center and interconnection investment is exploding. The broader Asia-Pacific data center market is expected to grow from about USD 102.45 billion in 2024 to USD 174.81 billion by 2030, at a 9.3% CAGR. Within that, Singapore is a clear outlier: its data center market was valued at roughly USD 948.9 million in 2024 and is forecast to reach USD 2.78 billion by 2033, growing at 12.1% annually.
Choose Melbicom— 130+ ready-to-go servers in SG — Tier III-certified SG data center — 55+ PoP CDN across 6 continents |
|
Singapore’s role is not just about market size. It already hosts more than 1.4 GW of installed data center capacity and is recognized by regulators and industry analysts as a regional hub, backed by a dense regulatory and sustainability framework designed specifically for data centers. At the physical layer, Singapore sits on top of roughly 30 international submarine cable systems with a combined design capacity of about 44.8 Tbit/s, turning it into one of the most interconnected nodes on the planet.
We looked at submarine cable maps, regulatory briefings, data center market forecasts, and interconnection growth figures across Asia-Pacific. Our conclusion: if you need consistent sub‑100 ms round‑trip times across the region without building a custom multi‑country footprint from scratch, Singapore‑based dedicated servers remain the most straightforward backbone for low‑latency reach. This post breaks down how to use it effectively.
Server Hosting in Singapore: a Low-Latency Gateway to Asia-Pacific
At the network level, Singapore behaves like an edge location for most of Asia-Pacific. According to industry and policy analysis, the city‑state handles over 99% of its international data traffic via subsea cables and is currently served by around 28 active cable systems, with at least 13 more in various stages of planning or construction.
That physical density is one reason Singapore’s digital economy already contributes an estimated 17.7% of national GDP — about SGD 113 billion (roughly USD 88 billion). It’s also why latency from a well‑peered Singapore data center to major Asia-Pacific metros can feel “local” even when you’re crossing national borders.
From a practical standpoint, here’s what we at Melbicom typically see when we map latency from our Singapore facility across the region over high‑quality transit and peering:
| Destination Metro | Typical RTT From Singapore (ms) | Practical Use Case |
|---|---|---|
| Jakarta | 30–40 | Mobile games, real‑time payments |
| Bangkok | 35–45 | SaaS collaboration, streaming |
| Manila | 40–50 | Web apps, e‑commerce storefronts |
| Tokyo | 65–80 | Multiplayer games, trading frontends |
| Sydney | 90–110 | Collaboration, content, back‑office SaaS |
These are not lab‑perfect numbers — they’re realistic ranges across premium carriers under normal conditions. For most interactive workloads, staying below ~100 ms RTT is enough to feel “snappy”; below 50 ms tends to feel instant for typical users.
To put that in context: Singapore consistently ranks at or near #1 globally for fixed broadband speeds, with median download speeds above 500 Mbps and single‑digit millisecond last‑mile latency. That local access quality, combined with cable density, is what makes Singapore such a strong control point for dedicated server hosting Asia‑wide.
Melbicom’s Singapore data center sits directly on this fabric: a Tier III facility with 16 MW of power, 1–200 Gbps of dedicated bandwidth available per server, and more than 100 ready‑to‑go dedicated configurations at any given time. When you pair that with a global network spanning more than 20 transit providers and dozens of internet exchange points, you get a platform where the physical distance is as short as the map allows — and the logical distance (hops, congestion, packet loss) is carefully minimized.
Visualizing Latency From Singapore
For engineering teams, the takeaway is simple: if you anchor your Asia-Pacific workloads on a well‑connected dedicated server in Singapore, your “worst” latencies across most of the region will often be comparable to intra‑regional latencies in Europe or North America.
How Do I Choose a Reliable Dedicated Server in Singapore?
Choosing a reliable dedicated server in Singapore comes down to three layers: the physical facility (tier, power, connectivity), the network (transit quality, IXPs, routing policy), and the server profile (CPU, RAM, storage, bandwidth). Focus on latency budgets and traffic patterns first, then pick hardware and bandwidth that can safely absorb peak load with room for growth.
1. Start With Latency and Peering, Not Just Specs
For low‑latency work, a server in SG needs more than a fast CPU. You want:
- Dense, diverse connectivity. Singapore’s subsea hub status only helps you if your provider actually buys quality transit and peers broadly. In our case, Melbicom connects to 20+ upstream carriers and nearly thirty internet exchange points globally, so traffic to users in Jakarta, Seoul, or Sydney can often take direct or near‑direct paths.
- Guaranteed bandwidth, without ratios. Oversubscribed outbound links create surprise latency spikes. Melbicom exposes up to 200 Gbps per server in the Singapore facility, with committed capacity rather than “best effort” share‑and‑pray models.
If you’re evaluating Singapore’s best dedicated server options, always ask for looking‑glass URLs, test IPs, and traceroutes before you sign. Static marketing claims won’t tell you how your real routes behave.
2. Match Server Profiles to Traffic Shape
From Melbicom’s Singapore catalog, you can usually choose among:
- CPU families: modern Intel Xeon and AMD EPYC generations suitable for CPU‑heavy game servers, real‑time analytics, or microservices backends.
- Storage tiers: pure NVMe for latency‑critical databases and queues; mixed SSD/HDD for large asset libraries or logs.
- Network profiles: from 1 Gbps ports for moderate traffic up to 100–200 Gbps for content‑heavy or multiplayer workloads.
We keep hundreds of servers ready for 2‑hour activation globally, with more than 100 stock configurations in Singapore alone. Custom server configurations — for example, high‑frequency CPUs plus large NVMe arrays — can usually be deployed in three to five business days.
For global teams, the sweet spot is often: multi‑core Xeon, 128–256 GB RAM, NVMe primary storage, and at least 10 Gbps dedicated bandwidth per node. That’s enough to consolidate multiple Kubernetes worker roles or large game shards without creating new bottlenecks.
3. Demand Operational Maturity
Specs are easy to copy; operations aren’t. When you look at Singapore dedicated server hosting providers, verify:
- 24/7 support and on‑site engineers. Singapore’s tight regulatory environment means most facilities are robust; the real differentiator is how fast someone can swap a failing DIMM or debug a networking issue at 03:00 local time. Melbicom offers free, round‑the‑clock technical support and on‑site component replacement.
- BGP session support. If you bring your own IP space, you should be able to establish a BGP session to announce prefixes and optimize routing without resorting to GRE tunnels or hacks. Melbicom provides BGP session support across all data centers, including Singapore.
- API and automation. For DevOps‑driven teams, an API‑driven control plane, KVM over IP, and predictable naming for “server sg‑X” nodes are as important as raw clock speed.
What Are the Benefits of Hosting a Website on Singapore Dedicated Servers?
Hosting a website or application on Singapore dedicated servers places your origin close to the fastest‑growing digital economies, on top of some of the world’s densest subsea connectivity and low‑latency interconnection. The result: better page load times, higher conversions, and more consistent performance across APAC without a sprawling footprint.
Closer to the Fastest-Growing Digital Economies
Asia-Pacific will continue to dominate e‑commerce growth, with the region’s online commerce volume expected to surpass USD 6 trillion by the end of the decade. Southeast Asia alone is projected to see its internet economy approach USD 1 trillion in GMV by 2030.
Running your origin in Singapore means your packets spend less time bouncing through distant gateways to reach those economies. For global products, that translates directly into fewer rage‑quits, higher session lengths, and better in‑app monetization.
Latency, UX, and Revenue Are Directly Linked
The correlation between speed and business metrics is no longer theoretical. Deloitte and Google’s “Milliseconds Make Millions” research found that a 0.1‑sec improvement in mobile site speed increased retail conversion rates by 8.4% and travel conversions by 10.1%.
If your Seoul or Jakarta users are running 200–250 ms away from an origin in Western Europe, shaving even 80–100 ms by moving that origin to a Singapore dedicated server is often the cleanest way to unlock similar uplifts — especially once you’ve already exhausted front‑end optimization.
Low-Latency Networks Are the New Baseline
Equinix’s Global Interconnection Index, cited by Telecom Review Asia, projects that interconnection bandwidth in Asia-Pacific will grow at a 46% CAGR, reaching about 6,002 Tbps. That growth is being driven by e‑commerce, digital payments, and real‑time applications — exactly the workloads that suffer most from high latency.
In parallel, surveys show that over 70% of data centers in Asia are now connected to networks offering more than 100 Mbps to enterprises, underlining how quickly “good enough” bandwidth is becoming table stakes.
For your stack, that means user expectations are calibrated by local best‑in‑class experiences. If a competitor’s API or game server is physically closer — or better peered into those networks — your product will feel sluggish by comparison.
Designing a Low-Latency Architecture on Singapore Servers
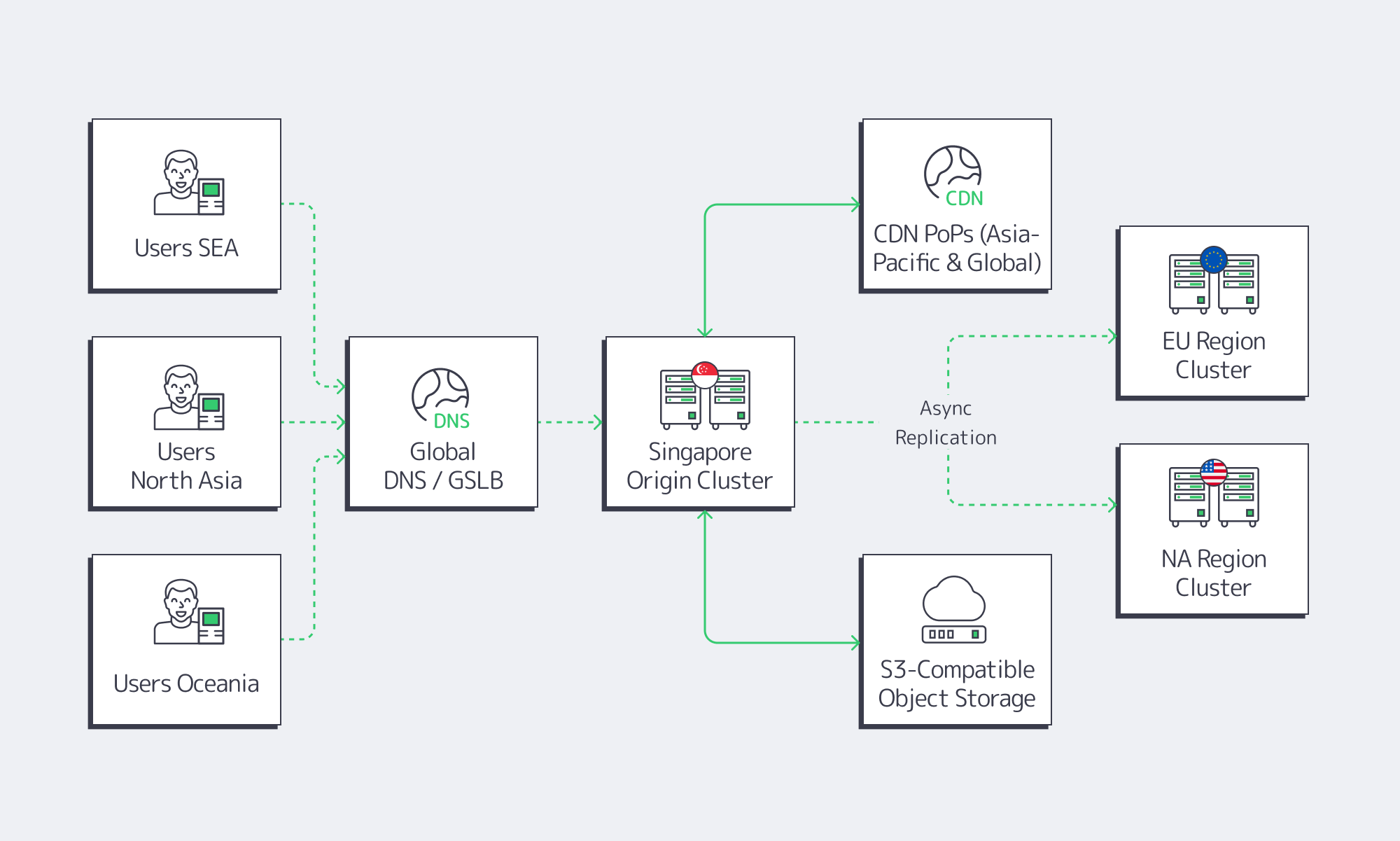
Once you’ve chosen a provider and a hardware profile, the next step is architectural. A single high‑end box in Singapore can still underperform if you treat it like “just another origin.” The goal is to use your Singapore node as a latency anchor for the region.
Map Latency Budgets Across Asia-Pacific
Start by defining clear latency budgets. Real‑time PvP or esports: target sub‑50 ms; acceptable up to ~80 ms. Competitive SaaS UX (dashboards, live collaboration): target sub‑150 ms; acceptable up to ~200 ms. Turn‑based or non‑interactive content: more tolerant, but still benefits from lower jitter.
Overlay those budgets on your traffic map. Most of Southeast Asia and parts of North Asia fall comfortably inside the “green zone” when served from Singapore; farther‑edge users (e.g., rural Australia, Pacific islands) may still exceed some thresholds. That’s where you decide whether one Singapore origin plus CDN is enough, or whether you add secondary footprints (e.g., Seoul or Sydney) as you scale.
Use a Singapore Dedicated Server as APAC Origin, Not a Global Monolith
A common mistake is to treat Singapore as a universal global origin. That leads to sub‑optimal paths for Europe or the Americas. Instead:
- Use Singapore as the Asia-Pacific origin in a broader topology where Europe and North America have their own origin clusters.
- Pin APAC DNS responses (or GSLB rules) so that users from the region hit
apac.example.comresolving to Singapore or nearby POPs. - Keep cross‑regional chatter to a minimum by pushing only the state that truly needs to be global (billing, accounts, leaderboards) to a multi‑region datastore.
This pattern is especially useful for dedicated server hosting Asia gaming workloads: shard per region, use Singapore for Southeast Asia and much of East Asia, and sync only global state asynchronously.
Pair Singapore With CDN and Object Storage
A dedicated server in Singapore gives you CPU, RAM, and bandwidth; it shouldn’t be your universal file store or global cache.
Modern guidance from edge‑delivery vendors is clear: CDNs and edge computing have complementary roles. CDNs excel at caching static assets, reducing origin load and average latency; edge compute is best reserved for custom logic that truly benefits from running within a few milliseconds of the user.
With Melbicom, you can combine:
- CDN with 55+ PoPs across 36 countries. That gives you edge caches close to users while keeping your Singapore origin small and predictable.
- S3‑compatible object storage. Our S3 cloud storage offers up to hundreds of terabytes of scalable, NVMe‑accelerated capacity, ideal for assets, backups, and logs that don’t belong on your origin disks.
In a typical setup:
- Your main application and databases run on one or more Singapore dedicated servers.
- Static assets (game patches, media, JS bundles) live in S3‑compatible storage.
- Melbicom’s CDN pulls from S3 and your Singapore origin, caching at PoPs worldwide.
- Only latency‑sensitive API calls or gameplay traffic hit the Singapore servers directly.
That architecture lets you treat the SG origin as an ultra‑fast control plane for the region.
Singapore as Your APAC Latency Anchor
When you step back from the individual stats, a clear pattern emerges. Asia-Pacific’s digital economy is compounding rapidly; interconnection bandwidth is exploding; and Singapore has positioned itself at the center of that network with dense subsea cables, high‑capacity data centers, and a regulatory framework explicitly tuned for digital infrastructure.
For technical teams, the opportunity is straightforward: treat Singapore not as a checkbox location, but as a strategic latency anchor for the region. Start with a well‑peered Singapore server cluster, wrap it in a CDN and S3 storage layer, and then add complementary regions only where your latency budgets or regulatory needs truly demand it.
Here are a few practical takeaways before you sketch your next architecture diagram:
- Quantify your latency needs first. Decide which user journeys truly require sub‑80 ms latency and which can tolerate more. Let that drive how aggressively you invest in Singapore and where you might need secondary regions.
- Make peering and bandwidth non‑negotiable. Insist on test IPs, traceroutes, and clear per‑server bandwidth guarantees. For high‑growth products, treat 10 Gbps per origin server as a minimum rather than a luxury.
- Separate compute from content. Use Singapore dedicated servers for real‑time logic and state; push heavy assets into S3‑compatible storage and CDN. That keeps your latency‑critical flows tight and predictable.
- Automate region‑aware rollout. Treat Singapore as its own deployment stage with per‑region feature flags, canaries, and observability. Don’t assume a feature that performs well in Frankfurt will behave identically against high‑churn mobile networks in Southeast Asia.
- Plan for regulatory and sustainability shifts. Singapore’s regulators are tightening energy efficiency and resilience standards for data centers, which is good news for uptime — but it also rewards providers who invest in modern, efficient infrastructure. Align your long‑term plans with that direction of travel.
Deploy in Singapore today
If you’re ready to turn these principles into a concrete deployment, we at Melbicom can help you anchor your Asia-Pacific workloads in Singapore. Our Singapore facility offers Tier III infrastructure, up to 200 Gbps per‑server bandwidth, more than 100 ready‑to‑go configurations, and custom builds delivered in 3 to 5 business days — all backed by free 24/7 support and seamless integration with our CDN and S3 storage. Order a server and start turning Singapore into the low‑latency backbone for your next phase of global growth.