Blog
Gaming Infrastructure: Build Low-Ping Multiplayer & Resilience
Newzoo’s report puts the games business at $188.8 billion and 3.6 billion players. At that scale, every technical choice matters: where sessions run, how patches move, and whether DDoS turns a live event into an outage.
Melbicom maps to the practical workload split: 21 global Tier III and Tier IV data centers, a 14+ Tbps backbone, 20+ transit providers, 25+ IXPs, 55+ CDN PoPs across 39 countries, and 1,400+ server configurations with up to 200 Gbps per server.
Deploy Game Hosting— Low-latency dedicated servers — CDN for patch delivery — DDoS protection for launches |
 |
Why Gaming Infrastructure Is Now a Live-Ops Discipline
Gaming infrastructure is now a live-ops system because multiplayer, voice, telemetry, content delivery, and DDoS defense move at different speeds. The reliable pattern is separation: control-plane services handle identity and intent, session servers preserve frame time, CDN handles bytes, and security layers absorb abuse before disruption reaches players or origins.
The old mental model – “rent servers, open ports, scale when full” – fails because planes break differently. Matchmaking fails as queues and bad assignments. Session simulation fails as frame-time variance. Voice fails as jitter. Telemetry can back-pressure gameplay, and patch traffic can overwhelm origin capacity.
That is why current matchmaker guidance separates tickets, pools, match functions, evaluators, and dedicated-server assignment instead of one service owning everything. Melbicom supports that split with regional, network, CDN, and DDoS options for control, simulation, media, data, and delivery planes stay separate.
Design Low-Ping Gaming Infrastructure and Stable Tickrates

Design low-ping gaming infrastructure from the tick outward: set the maximum playable RTT, reserve CPU and network headroom per server, and place session nodes in regions that keep most players under that envelope. Routing quality matters, but no backbone can cheat distance, jitter, packet loss, or overloaded frame budgets.
Match Loop Latency Budgets Inside Gaming Infrastructure
IBM defines latency as delay across a path, and distance still matters. A 64 Hz server has 15.6 ms per tick; a 128 Hz server has 7.8 ms. Those numbers are not end-to-end promises. They are the local budget for simulation, networking, serialization, anti-cheat hooks, packet queues, and operating-system scheduling inside the tick.
| Workload Plane | Practical Target Band | Placement Rule |
|---|---|---|
| Matchmaking and lobbies | Feels immediate, but queue/state work can tolerate controlled delay | Keep region-aware, sticky, and isolated from simulation |
| Session simulation | 64 Hz = 15.6 ms; 128 Hz = 7.8 ms | Keep frame time below the tick budget with headroom |
| Voice and presence | Opus commonly uses 20 ms frames; quality depends on jitter and one-way delay | Place media relays close to parties and track voice separately |
| Telemetry and replays | Buffered ingest is acceptable; blocking the match thread is not | Use regional collectors plus durable object storage |
| Patch and CDN | Edge should serve the bulk of bytes; origins should serve misses and metadata | Separate content delivery from gameplay endpoints |
The operator’s job is to keep the simulation server boring. Avoid co-locating telemetry transforms, replay compression, patch endpoints, or analytics with match loops. Leave CPU headroom, pin noisy services elsewhere, and treat jitter as seriously as mean RTT because players feel every desync spike.
Reference Architecture for Authoritative Session Servers
A modern reference architecture starts with global DNS or anycast entry, regional login and party services, ticket-based matchmaking, a server allocator, and warm dedicated session nodes. Agones autoscaling guidance favors maintaining buffer capacity before demand arrives, because launch-time cold provisioning is too late.
The launch-scaling case study is predictable: tickets pile up, allocators time out, parties flap, and players call it “lag.” The fix is architectural: keep matchmaking stateless where possible, make placement regional, pre-warm session pools, and use overflow only when latency tradeoffs are visible.
Gaming Infrastructure Checklist for Live-Ops Planes
A useful checklist treats each multiplayer component as its own failure domain. Matchmaking owns fairness and intent, session allocators own placement, voice owns media quality, telemetry owns buffered ingest, and patch delivery owns origin shielding. The target is not one giant cluster; it is a set of regional services with clear blast-radius boundaries around each workload plane.
Voice deserves its own lane. Browser WebRTC implementations are required to support Opus, and Opus can scale from 6 kbit/s to 510 kbit/s. For practical speech, RTP guidance puts the 20 ms frame-size sweet spot around 16-20 kbit/s for wideband and 28-40 kbit/s for fullband. That makes voice efficient per user but unforgiving about jitter and relay placement.
Telemetry is the silent tick killer. Session nodes should emit to regional collectors and object storage, not synchronously enrich every event. Patch delivery is even more separate: platform documentation shows content delivered over HTTP, with third-party caches and external CDNs improving download speed.
A new-season rollout can push patch traffic far above gameplay traffic, so the CDN should absorb hot objects while origins stay private and predictable.
DDoS and Cheating Resilience for Modern Gaming Infrastructure

Resilient gaming infrastructure narrows the public surface area and assumes attacks will coincide with the worst traffic moments: launches, tournaments, and new-season rollouts. Place scrubbing inline, separate IP pools, keep patch origins hidden, and validate gameplay server-side so abuse and cheating remain separated.
The volume curve is brutal. A recent threat report counted 47.1 million DDoS attacks over its measurement period, averaging 5,376 mitigations per hour; the disclosed peak reached 31.4 Tbps during the period.
For operators, “call someone when attacked” is not a plan. Protection has to sit in normal traffic flow, especially for UDP-heavy gameplay, login, voice, and patches.
The new-season case study is familiar: patch downloads spike, login surges, social media amplifies failures, and attackers add volumetric noise when every queue is hot. The resilient version keeps public entry points minimal, splits IP pools by service, protects gameplay separately from web delivery, and prevents CDN misses from exposing origins. Melbicom’s DDoS and CDN services support that split.
Cheating resilience belongs in the same blueprint. Public engine guidance still says the quiet part plainly: do not trust clients with final gameplay decisions, validate client messages server-side, and avoid host models where one player’s machine becomes the authority. DDoS and cheating are different threats, but both punish architectures with too much trust at the edge.
When Dedicated Servers Beat Cloud Burst for Multiplayer
Dedicated servers beat cloud burst when concurrency is steady, regional demand is known, and bandwidth is a recurring cost rather than an exception. Burst capacity still belongs in the model, but it should cover launch uncertainty, overflow regions, and rare events – not replace predictable capacity for stable daily ticks.
A 128-tick engineering write-up makes the economics visible: high tick targets are CPU-budget problems before they are bandwidth problems. Cache contention, NUMA locality, scheduler overhead, and instance density decide whether a node can host one more match without variance. Bursting into different capacity may solve admission while hurting match quality during play.
The cleaner pattern is baseline-plus-burst. Run predictable regional CCU on dedicated servers, use cloud burst for uncertain peaks, and push patch bytes through CDN rather than session infrastructure. Ready-to-go pools include Amsterdam, Singapore, Los Angeles, and 17 other locations; specs span Intel and AMD EPYC/Ryzen, RAM up to 1.5 TB, 1-200 Gbps per-server bandwidth, and custom builds in 3-5 business days.
Melbicom’s CDN pricing is bandwidth-based, with a 55+ PoP premium footprint from 0.15 €/GB and a 14-PoP volume option from 0.002 €/GB, so teams can separate global reach from bulk download costs during launches.
Use this checklist to scope the node plan:
- Quantify normal, launch-peak, season-reset, and regional-failover CCU by region; reserve dedicated capacity for predictable baselines and label the rest burst.
- Define day-one primary and overflow regions; never let overflow placement hide a latency penalty.
- Map each mode to session model, tickrate, players, bots, authoritative entities per node, and the RTT ceiling that breaks fairness.
- Split voice, telemetry, replays, and patch origins from session hosts; colocate only when latency demands it.
- Estimate full-build, delta, and first-24-hour hot-update terabytes; size CDN origin shielding before launch.
- Decide which endpoints need stable IP identity for reconnects, tournaments, or anti-fraud controls.
- Put DDoS protection in front of gameplay, login, voice, and patch endpoints; keep origins private wherever possible.
- Track per-region server counts, CPU class, RAM, and bandwidth; validate ready-to-go supply and custom lead time before publishing launch dates.
Build Gaming Infrastructure That Keeps Games Online

The modern stack is not a bigger box; it is a placement model. Put authoritative simulation close to players, keep ticks below their CPU budget, let CDN absorb patch bytes, and treat DDoS as a standing live-ops condition. That is how low ping survives real launches rather than controlled lab tests.
Melbicom gives teams room to design that model with 1,400+ ready-to-go dedicated servers, custom builds delivered in 3–5 days, global network reach, CDN options, and DDoS protection without forcing every workload into the same failure domain.
For a launch, hotfix, or seasonal rollout, the practical question is simple: which nodes must exist before players arrive?
Get expert support with your services
Blog
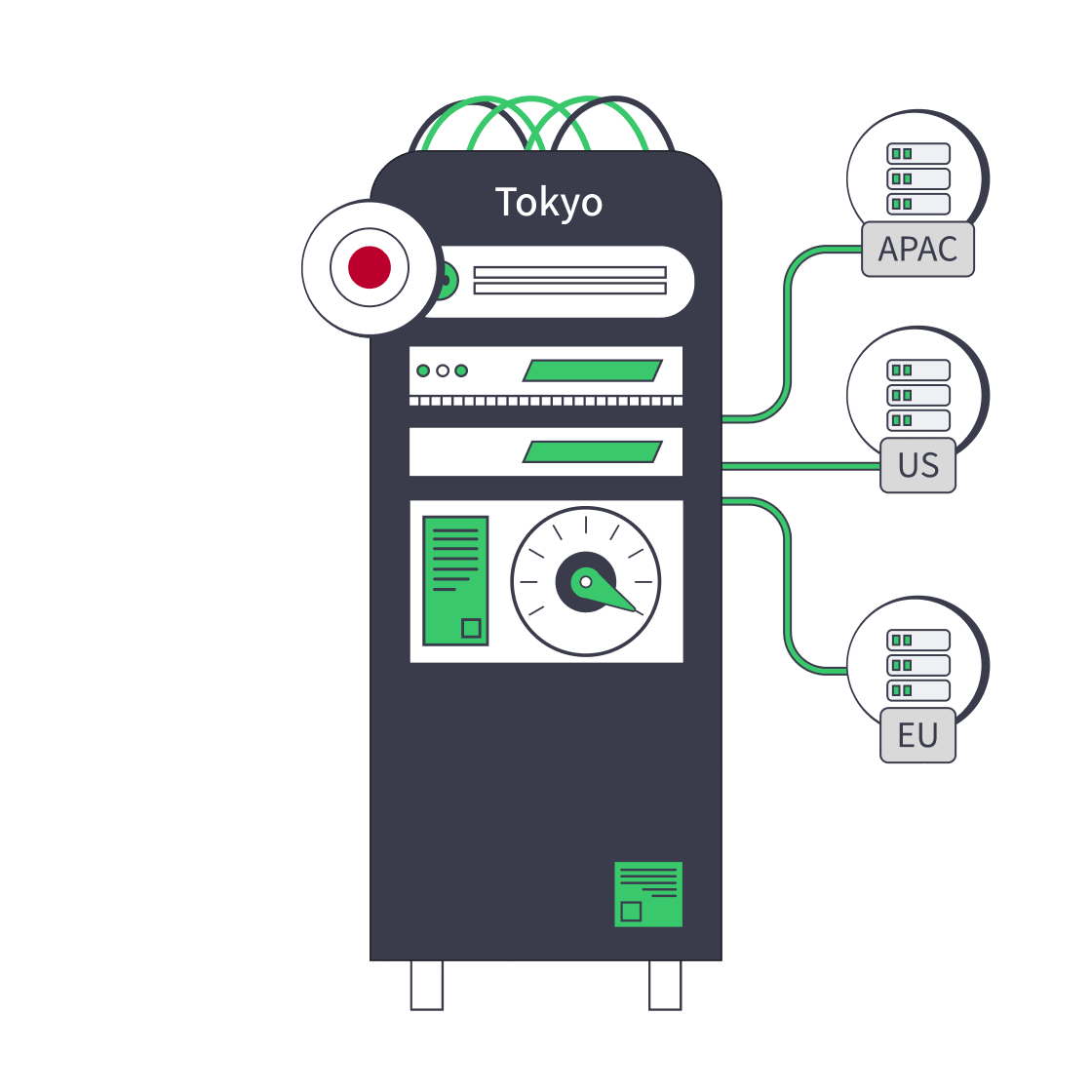
Japan Dedicated Server: Compliance, Latency Policy, & Multi-Region Failover
Buying a Japan dedicated server is really buying a latency envelope, a route-quality profile, and a governance boundary. On continuous backbone measurements, Tokyo-region workloads sit near Korea and Hong Kong, mid-range to Singapore and Sydney, and far enough from the US and Europe that synchronous failover becomes a design smell. Treat those figures as clean-network baselines, not user promises: last-mile routing, congestion, and application queues still decide what users feel.
The old “Asia bandwidth is scarce” story is outdated. The Internet Society’s IXP tracker reports Japan has 25 active IXPs, 676 members, 94% domestic network coverage through IXPs, and 92% local cache/server reachability for the 1,000 most-visited sites. The modern question is sharper: does your Tokyo route, tail-latency profile, data-transfer model, and failover plan match the workload?
Deploy in Tokyo— Tokyo-ready dedicated servers — Asia routes and failover — CDN reach across Japan |
|
Why a Japan Dedicated Server in Tokyo Is Not an APAC Shortcut
Tokyo is a premium latency market because it is local to Japan and Northeast Asia, not because it sits in the middle of APAC. A Japan dedicated server should be chosen when Japanese users, nearby Korea/Hong Kong traffic, or Japan-regulated workflows justify a local hot path.
The table below uses continuous P50 round-trip backbone measurements as a planning baseline. It is useful for architecture, but insufficient for procurement; buyers still need provider-specific MTR, traceroute, TCP, and UDP tests from key access networks.
| Path from Tokyo Region | Indicative Median RTT | Architectural Read |
|---|---|---|
| Tokyo ↔ Seoul | 21–29 ms | Strong fit for fast session control and competitive play |
| Tokyo ↔ Hong Kong | ~53 ms | Good for regional control planes and latency-tolerant user paths |
| Tokyo ↔ Singapore | ~73 ms | Viable for failover and support services; not local for Japan |
| Tokyo ↔ Sydney | ~104 ms | Better for async replication than tight interactive commits |
| Tokyo ↔ US West | ~108–146 ms | Sensible warm recovery; risky for synchronous user-path writes |
| Tokyo ↔ Frankfurt / Western Europe | ~219–235 ms | DR, replay, analytics, or sovereignty partitioning, not chatty active-active |
That is why Tokyo-first architecture should be selective. Keep the match state, payment decision, signaling service, or inference hop close to Japanese users. Push static delivery into CDN, regionalize bulky analytics, and resist the instinct to make Tokyo the default home for every non-interactive component.
How to Choose a Japan Dedicated Server for Tokyo Latency-Sensitive Workloads
Choose a Japan dedicated server by starting with the user-visible latency budget, then checking route evidence, compute isolation, data-flow rules, and failover behavior. Tokyo fits hot session paths, trading/payment-adjacent systems, real-time collaboration, and user-path inference. Static delivery, batch jobs, and cached content usually do not need it.
Dedicated Server Japan Workload Fit: When Tokyo Is the Right Call
Gaming is the bluntest test. A study of FPS gameplay found that even network latency under 100 ms degrades performance and quality of experience; QoE dropped about 0.7 points on a five-point scale per additional 100 ms in the experiment. For authoritative game state, anti-cheat checks, matchmaking, or voice tied to the same session, latency is product design, not hosting cosmetics.
Real-time apps have a different ceiling but the same problem. APNIC’s working-latency analysis shows why an idle ping can be misleading once a connection is loaded; for conferencing, it leaves only about 130–340 ms of network RTT budget after application processing. The classic tail-latency research explains why p99 breaks systems before averages look alarming, while ITU planning guidance treats highly interactive voice, video, and data as delay-sensitive well below broad upper limits.
Fintech adds governance. METI reported Japan’s cashless payment ratio reached 42.8% of consumer spending, with the total reported as ¥141.0 trillion, or roughly US$900 billion. That makes payment, fraud, brokerage, and risk flows mainstream workloads. For these systems, a dedicated server in Japan is about predictable RTT, auditability, and pre-approved cross-border handling as much as speed.
For AI inference, ask whether the model blocks the user path. If it gates a voice turn, moderation decision, fraud score, ranking result, or retrieval step, Tokyo placement protects perceived responsiveness. If the job is offline enrichment or training, send it where capacity economics are better.
Japan Hosting Due Diligence: Route Quality and Cross-Border Data Transfer Checks
Advertised port speed is not due diligence. For Japan hosting, validate paths from the access networks your users actually use, measure peak-hour p95/p99 and working latency, and map every cross-border personal-data flow. APPI often allows transfer, but it requires governance, not casual replication.
Route quality should be tested, not inferred from a Tokyo postcode. Ask for test IPs and run MTR or traceroute from Japanese mobile, broadband, office, and partner networks. Test TCP and UDP separately if the product uses sockets, media, game traffic, or custom transport. Japan’s IX fabric is deep enough that poor Tokyo routing is often a provider-design issue, not an unavoidable geography problem.
Data residency and cross-border transfer are related but not identical. Japan’s APPI requires security controls, processor supervision, leak reporting, third-party transfer governance, and specific controls for foreign-country transfers under Articles 23, 25, 26, 28, and 31. In practice, define which data must remain Japan-authoritative, which data can be tokenized or pseudonymized, and which observability or model-training pipelines can leave Japan under documented consent, contractual, or equivalent-protection paths.
Financial workloads should also account for sector expectations. FISC says its security guidelines are voluntarily observed by most Japanese financial institutions, so vendor oversight, contingency planning, and incident handling need to be part of the hosting decision from day one.
How to Design Japan-to-US/EU Failover for Gaming, Fintech, and Real-Time Apps
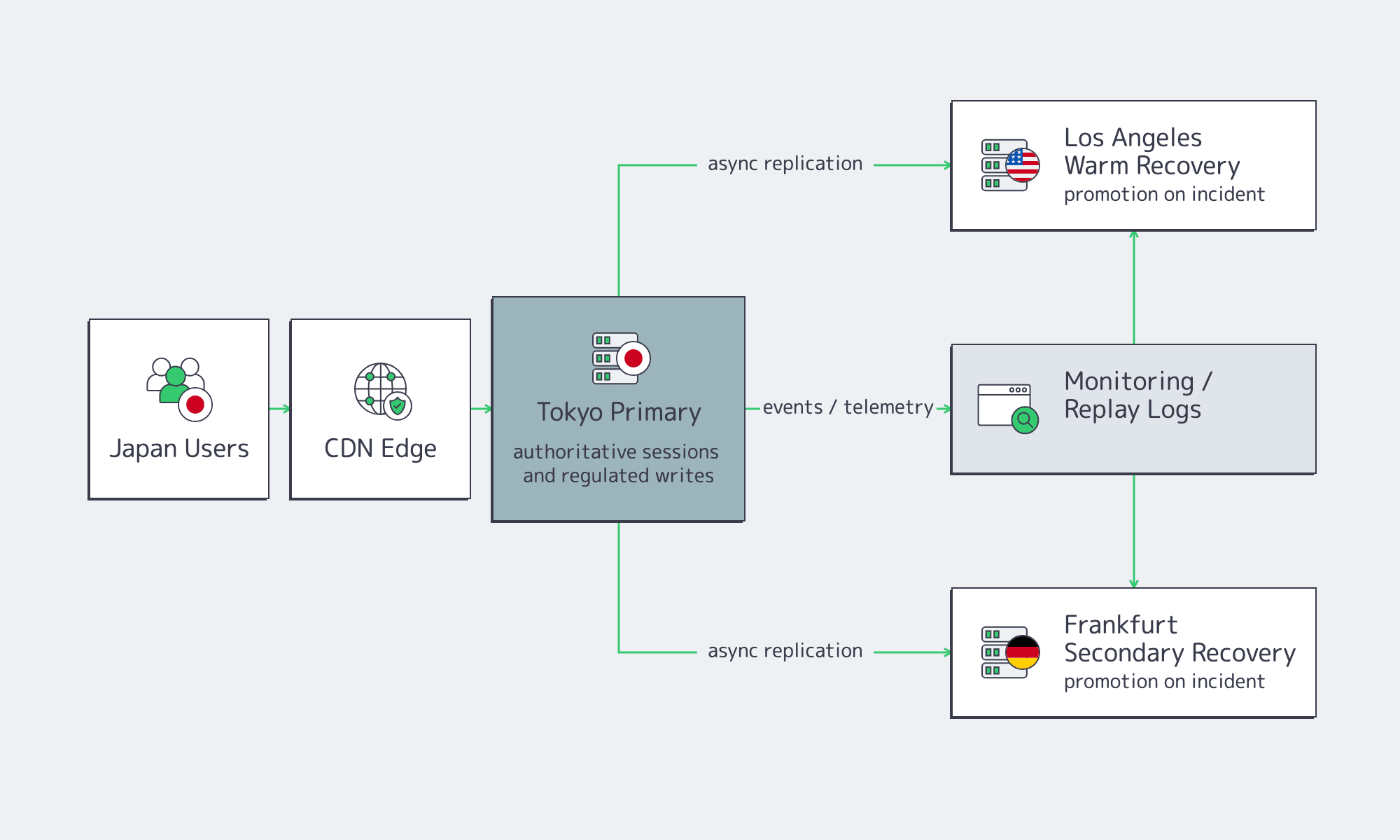
Japan-to-US/EU failover works when Tokyo stays authoritative for the latency-sensitive and compliance-sensitive path, while distant regions receive asynchronous state, replay logs, artifacts, and warm capacity. Treat the US West as Pacific recovery and Europe as a secondary operating sphere, not as synchronous extensions of Tokyo sessions unless the workload explicitly tolerates that latency.
Japan’s official business-continuity guidance stresses management-owned planning, flexible strategy, online decisions, information security, training, and supply-chain awareness. Infrastructure should mirror that: rehearse failover, document stale data, and decide which functions stop instead of crossing an ocean synchronously.
A practical Japan-US pattern keeps Tokyo authoritative for sessions and regulated writes, then replicates event logs, account state, model artifacts, and recovery images to Los Angeles for Pacific recovery. Atlanta can be a deeper US operating sphere for North American continuity.
A practical Japan-EU pattern treats Frankfurt, Madrid, Amsterdam, or another listed European location as warm recovery, analytics, support tooling, or partitioned customer operations. Melbicom’s Europe presence supports that planning model. The EU path is valuable, but not as a normal synchronous extension of a Tokyo session.
Provisioning Checklist for a Japan Dedicated Server Shortlist
A credible shortlist should translate the strategy into evidence: routes, measurements, data-flow controls, failover staleness rules, and deployable capacity. For Tokyo, that also means checking available configurations, per-server bandwidth, and the lead time for custom builds before the launch plan depends on them.
Capacity check matters before architecture hardens.
- Require real route evidence from Japanese access networks during peak hours, including p95/p99 and working-latency behavior.
- Classify the hot path: session state, fraud checks, payment decisions, voice signaling, match logic, or user-path inference.
- Inventory all cross-border transfers, including logs, analytics, support access, model features, and backup restores.
- Define failover staleness: what can replay, what must remain Japan-authoritative, and what should stop during an incident.
- Test US/EU recovery as async promotion; avoid active-active.
- Keep Tokyo focused on what users or regulators actually feel; move cacheable, batch, and support functions elsewhere.
Conclusion: Make Tokyo the Hot Path, Not the Whole Platform

A Japan dedicated server strategy works when Tokyo becomes the authoritative place for the work that must be close, predictable, and governed. It fails when teams treat Tokyo as a universal APAC shortcut or assume intercontinental regions can behave like a local extension under pressure.
The smarter pattern is narrower and stronger: Tokyo for the hot path, nearby Asia where regional reach matters, CDN for delivery, and US/EU regions for recovery or secondary operations. That design gives product teams room to serve Japan seriously without turning every component into a latency-sensitive component.
Explore Japan Dedicated Servers
Plan Tokyo-centered hosting with Melbicom’s Japan coverage, US/EU recovery, 21 locations/data centers, 20+ transit providers, 25+ IXPs, 55+ CDN PoPs across 39 countries, 1,400+ configs, and custom builds in 3–5 days.
Get expert support with your services
Blog
Server Dedicated USA: Provider Comparison Checklist
In the US dedicated-infrastructure market, the real differentiator is no longer the processor line on a product page. It is whether a provider can move from quote to production quickly, keep bandwidth and IP behavior predictable under pressure, and reduce the manual work your team inherits after the order is placed. Recent data-center market research says 64% of North American capacity under construction now sits outside traditional mature markets, while operators report rising costs and tighter power constraints. In that environment, “available now,” “automatable now,” and “stable endpoint now” matter more than another raw-hardware headline.
Melbicom gives that decision a practical shape through its Atlanta and Los Angeles locations. The current US ready-configuration list includes dozens of servers in Atlanta and 50+ in Los Angeles. At network level, Melbicom operates 21 data-center locations globally, works with 20+ transit providers and 25+ IXPs, and runs 55+ CDN PoPs across 39 countries.
USA Servers Ready— Atlanta and LA inventory — Guaranteed bandwidth — Crypto-friendly billing |
|
Why a Server Dedicated USA Shortlist Is Now an Operations Decision
A modern USA dedicated server shortlist should start with route behavior, deployment workflow, and trust boundaries before CPU bins. The useful question is not “Which server is fastest on paper?” It is “Which US location and provider keep latency stable, endpoints consistent, and recovery scriptable when traffic, maintenance, or incidents arrive?”
That shift changes procurement. City names are not enough; teams should test from the geographies that feed the workload. We at Melbicom publish test hosts and downloadable files for both Atlanta and Los Angeles, which lets buyers run packet-loss, path, and throughput checks before committing. The second screen is deployability: stock status, activation time, API access, and a clear support boundary are leading indicators of whether production will run by workflow or ticket queue.
How to Evaluate USA Dedicated Server Offers for Bandwidth, API, and Support

A strong USA dedicated server offer should make five things explicit: bandwidth terms, DDoS posture, IP policy, automation surface, and support scope. API-first survey data says 82% of organizations now use at least some API-first practice, with a quarter fully API-first, so manual-only provisioning is now incident risk.
What a Dedicated Server in USA Should Prove Before You Sign
Bandwidth is where “high bandwidth” often becomes slippery. Separate port speed from guaranteed throughput, oversubscription language, metered versus unmetered terms, and the treatment of attack traffic. For instance, Melbicom offers guaranteed bandwidth and flat monthly pricing tied to hardware and chosen port speed.
| Area | Provider Proof to Request | Deployment Implication |
|---|---|---|
| Bandwidth model | Port speed; guaranteed throughput; metering; attack-traffic billing | Confirms the real sustained channel |
| DDoS posture | Scrubbing mode; telemetry visibility; handoff process; billing impact | Shows behavior under hostile traffic |
| IP policy | IPv4/IPv6; BYOIP; BGP; RPKI/ROA process | Protects endpoints and allowlists |
| Automation and support | Provisioning API; rebuilds; auth model; KVM/IPMI; 24/7 scope | Keeps failover replayable |
| Crypto procurement | Settlement asset; invoice currency; confirmations; renewals; credits/refunds | Prevents renewal friction |
Support needs the same scrutiny. “24/7 support” can mean anything from remote hands to useful help during OS installs, rebuilds, and maintenance windows. DDoS posture belongs in the same pass. Threat telemetry recorded more than 8 million DDoS attacks in a six-month period, and the operational question is not whether a badge says “protected.” It is where scrubbing happens, what telemetry remains visible, and whether attack traffic can distort billing or capacity planning.
Managed vs. Unmanaged US Dedicated Servers for Nodes and Apps
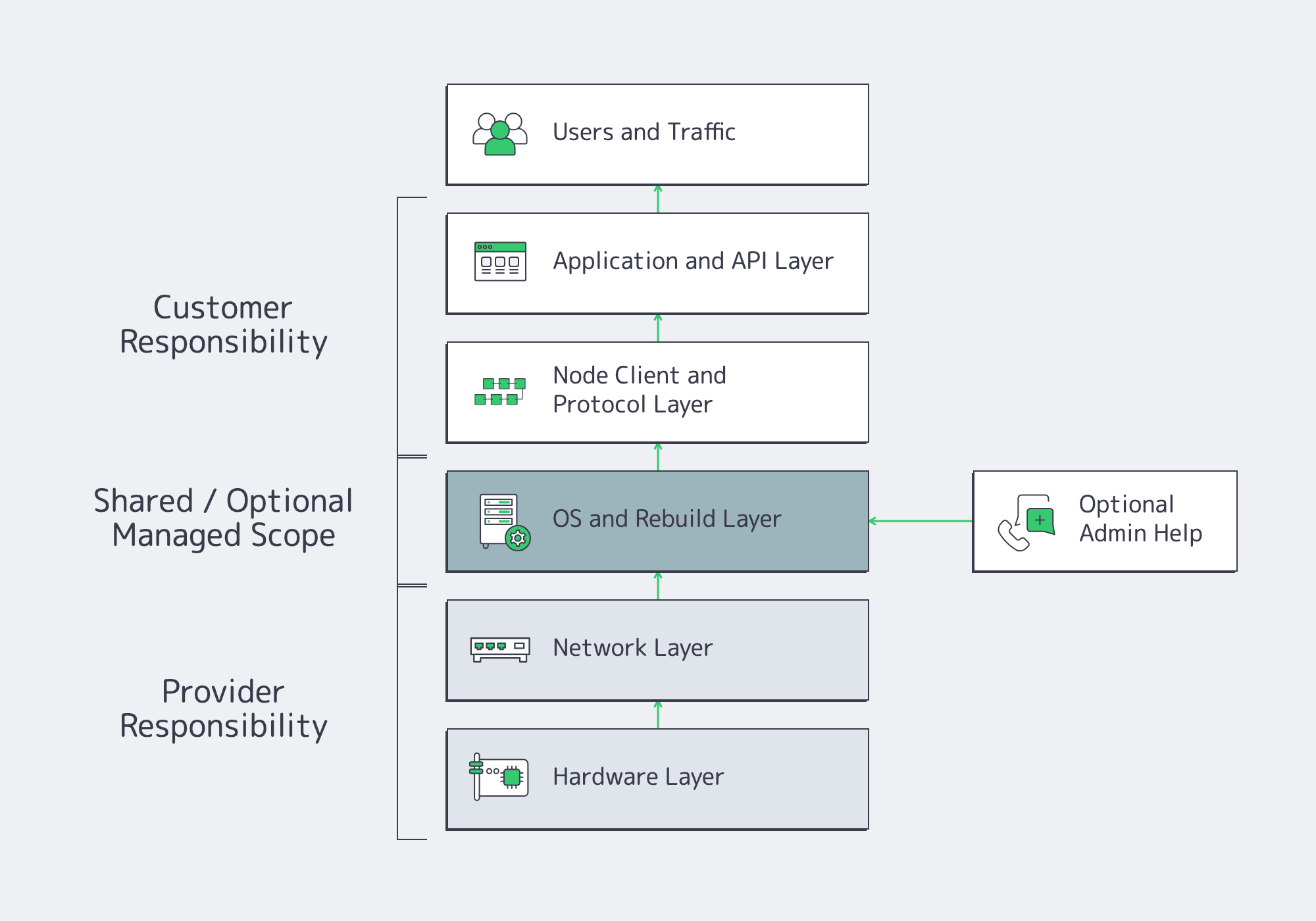
For node workloads and production apps, managed versus unmanaged is too blunt. The practical question is which layers the provider operates and which layers your team retains. The common target is provider-operated hardware and network, customer-controlled protocol and application logic, plus optional administration help for OS work, rebuilds, and patch windows.
For instance, in Web3, that split matters in node and RPC deployment hardening. A resilient layout separates authoritative node paths from public RPC fan-out, keeps replication on private paths, and uses BGP or BYOIP when endpoint continuity matters during maintenance or regional failover. Melbicom offers BGP/BYOIP and private inter-data-center links, horizontally scaled multi-region RPC patterns, and migration paths designed to avoid endpoint changes.
The same logic applies to exchange backends and wallet-adjacent systems. Customer-facing APIs, payment orchestration, and customer-data stores should not share a trust zone with signing systems or withdrawal controls. Blockchain-crime analysis put stolen funds at $2.2 billion and found private-key compromises accounted for 43.8% of losses. The practical takeaway is basic but unforgiving: keep public ingress away from key material, limit systems that can touch signing flows, and use hardware-backed cryptographic controls when asset value justifies them.
BTC Billing, IP Policy, and Security for Dedicated Server Deployment
BTC billing, IP policy, and security baselines should be decided before a dedicated server is deployed, because all three shape production risk. Billing affects renewal continuity, IP policy affects endpoint stability, and management security affects the blast radius of routine operations. Treat them as architecture inputs, not back-office cleanup.
When a USA Dedicated Server with BTC Is Really a Treasury Workflow Decision
A USA dedicated server with BTC should be framed as procurement flexibility, not a compliance shortcut or branding gimmick. The point is whether the payment rail fits how operations and treasury already move. Melbicom’s FAQ says crypto payments are available and can be enabled for new orders or renewals through an account manager, while US pages advertise monthly billing. Before the first invoice, clarify settlement asset, invoice currency, pricing source, quote-lock period, confirmation threshold, renewal workflow, and refund or credit-note path.
For teams that already hold digital assets, crypto billing can remove conversion steps and reduce weekend, cross-border, or card-approval friction. The privacy-friendly version is boring in the best way: clean invoices, clear ownership records, limited exposure of payment credentials, and fewer manual handoffs between treasury and infrastructure.
Dedicated Server USA IP Policy Requirements
IP policy is now architecture. Public registry guidance says the ARIN IPv4 free pool is depleted, new networks should request IPv6, and organizations seeking IPv4 should expect transfer workflows or pre-approval. Public IPv6 measurement puts global adoption around 46.5%, with US capability near 60%, so dual-stack is no longer a side quest. A dedicated server in USA should be evaluated for IPv6 readiness, BYOIP BGP sessions, route objects, RPKI, ROAs, route-origin validation, and prefix filtering. NIST routing guidance points in the same direction: stable endpoints require verifiable routing practice, not just address space.
Security baselines should be written before the server goes live. Management paths should stay off the public internet, VPN access should use MFA and narrow feature exposure, and cryptographic workflows should favor controlled key handling over convenience. For exchanges, wallets, and node operators, the minimum baseline is segmented ingress, hardened management, separate signing surfaces, auditable privileged access, and rebuild automation that can reproduce a known-good state.
Straight to Deployment with a Dedicated Server in USA
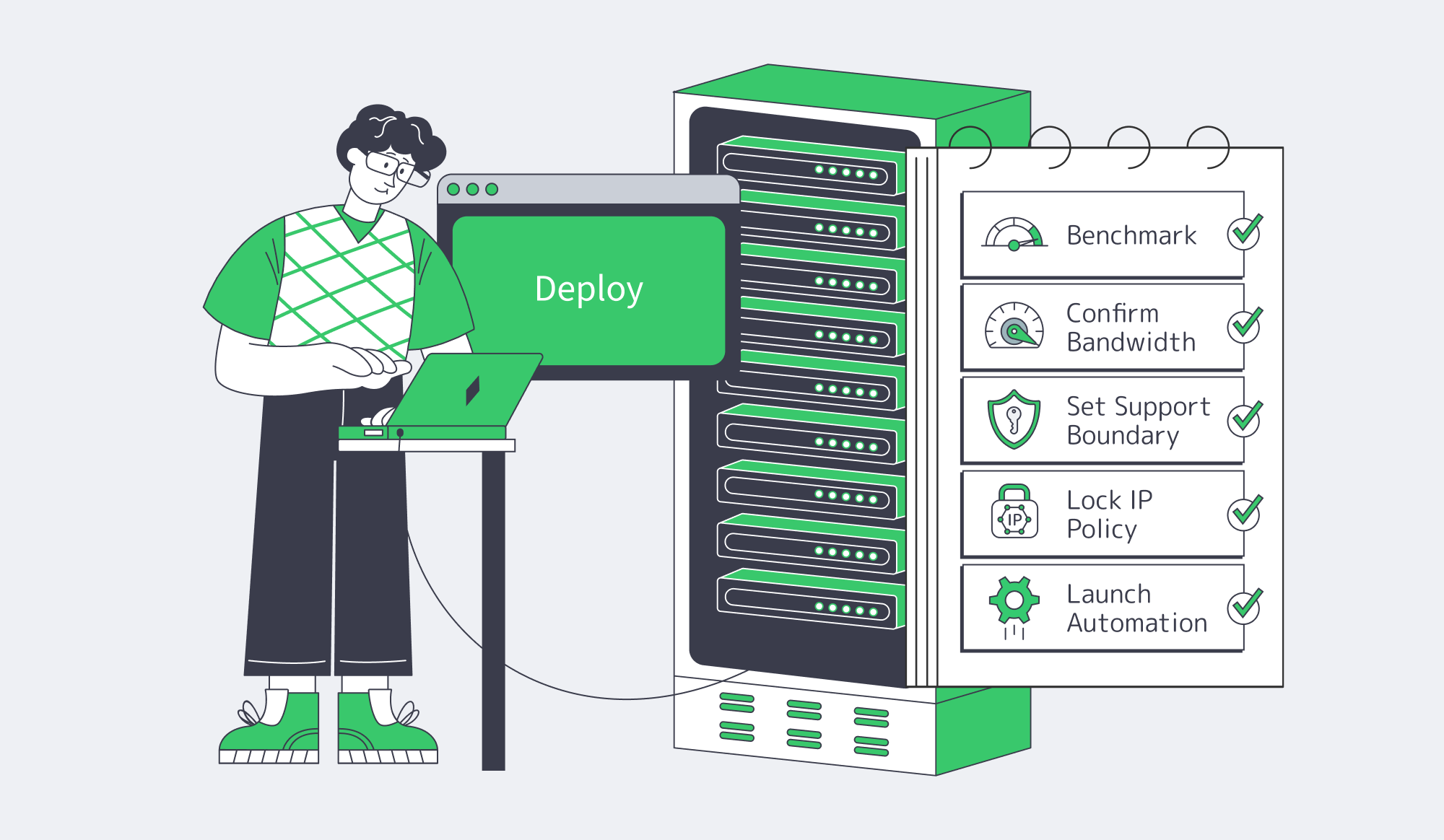
The fastest way to buy well is to turn the shortlist into an execution plan. A dedicated server in USA should be benchmarked from real traffic origins, matched to documented bandwidth and IP terms, deployed through repeatable automation, secured before exposure, and procured through a billing rail that will not interrupt renewals.
- Benchmark both US locations from real traffic origins; use published test files and path tests rather than a city name alone.
- Put bandwidth into writing: port speed, guaranteed throughput, oversubscription language, metered or unmetered terms, and attack-traffic treatment.
- Decide the ownership boundary: let the provider operate hardware and network reliability, while your team controls protocol, client, and release logic.
- Treat IP policy as architecture: require dual-stack readiness, decide whether BGP/BYOIP matters, and ask how routing-security controls are handled.
- Keep management off the public internet and require VPN plus MFA for KVM, IPMI, VPN, and privileged accounts.
- Separate public APIs from signing, payments, and customer-data systems; use hardware-backed cryptographic handling where key risk is material.
- Confirm crypto procurement before the first invoice: settlement asset, invoice currency, pricing source, confirmation threshold, renewal workflow, and credits or refunds.
- Use API hooks or infrastructure-as-code for provisioning, rebuilds, and failover; if deployment cannot be replayed automatically, it is not production-ready.
That is the practical meaning of a modern server dedicated USA purchase. It is not a hunt for the lowest monthly number or the loudest bandwidth claim. It is a search for infrastructure that is deployable, automatable, supportable, and compatible with the way security and finance already work.
Deploy in the USA
Compare US locations, bandwidth, APIs, routing, stock, and BTC billing.
Get expert support with your services
Blog
Dedicated Server United States: East vs. West, SLAs, and Cost Control
Buying a dedicated server in the United States is no longer a coastal shortcut. The old rule – East for Europe, West for Asia, one region for savings – breaks once dynamic APIs, replication traffic, media control planes, and recovery events carry real cost. Microsoft’s Azure latency tables put scale on the problem: representative median RTTs are about 73 ms from East US to West US, 79 ms from East US to UK South, 107 ms from West US to Japan East, and 147 ms from West US to UK South.
Melbicom makes the decision concrete: Atlanta and Los Angeles, both are Tier III facilities, with 1-200 Gbps per server, control panel, API, KVM, IPMI, and bandwidth and data-transfer filters. The framework is simple: place latency-sensitive work first, decide whether the second coast is for performance or disaster recovery, then optimize the bill.
Choose a U.S. Coast— Atlanta or Los Angeles — 1-200 Gbps per server — Ready or custom builds |
|
How to Choose East vs. West for a Dedicated Server in the United States
Choose east or west by locating the traffic that cannot hide behind a cache: writes, authentication, API calls, operator actions, and hard dependencies. East usually fits Europe-adjacent and Eastern/Central U.S. demand; West fits Pacific and Asia-facing paths. When both matter, assign each coast a role instead of chasing a single compromise metro.
The table uses Microsoft medians, not Melbicom measurements, as a proxy for the routing penalty distance still imposes.
| Representative Pair From Published Tables | Median RTT | Buying Implication |
|---|---|---|
| East US to West US | 73 ms | Coast-to-coast synchronous write paths will feel it immediately. |
| East US to UK South | 79 ms | An eastern U.S. location keeps Europe-linked traffic materially closer. |
| West US to Japan East | 107 ms | A western U.S. location is the better Pacific-facing launch point. |
| West US to UK South | 147 ms | Serving Europe from the West adds a substantial trans-U.S. penalty first. |
For a dedicated server in the United States, east vs. west is shorthand for the long-haul penalty on every uncached request. Single-region placement should remove the most expensive user-visible path. Once both paths matter, split roles across coasts instead of forcing one metro to impersonate the country.
Mapping Latency and Service-Level Targets to a Dedicated Server in the United States
Map the server plan to internal service targets: p95 latency, recovery time, and acceptable data loss. Keep synchronous replicas and quorum-heavy services near each other, where regional latency can stay low. Use coast-to-coast links for disaster recovery, read locality, stateless absorption, and staged failover, not default chatty writes.
Microsoft says availability zones target inter-zone round-trip latency below roughly 2 ms, recommends multiple availability zones for production workloads, and points mission-critical workloads toward multi-zone plus multi-region architecture. That is the line: same-region zones can protect tightly coupled systems; coast-to-coast replication is a different operating mode.
The economic case is just as sharp. Uptime Institute reports that 54% of respondents said their most recent significant outage cost more than $100,000, while one in five put the figure above $1 million. At that price point, a second region stops looking like decorative redundancy and starts looking like usable insurance.
When Multi-Region Replication Is Worth It for SaaS, Media, and API Backends
Multi-region replication is worth it when it reduces real user latency, contains outage cost, or lets a national platform absorb uneven demand without sending every transaction across the continent. SaaS decisions hinge on write authority, media decisions on origin pressure, and API decisions on dynamic ingress and state boundaries.
SaaS
For SaaS, the decisive variable is where the write path lives. If users, support teams, and core transactions lean eastward, keep primary writes there and use the opposite coast for asynchronous disaster recovery, read locality, search copies, object replication, and fast failover capacity. Cross-region replication becomes wasteful when it turns a transactional database into active/active behavior before the application can resolve conflicts.
Media
For media, the old one-origin-plus-CDN pattern is weaker than it looks because manifests, entitlement checks, live spikes, and packaging pipelines do not cache away cleanly. AppLogic Networks says video remains the largest application category by volume, users download an average 5.6 GB per day, and live-streamed sports can spike traffic 3-4x above normal usage. Place origins and control planes near the heaviest egress region, keep the opposite coast warm, and use CDN plus object storage so origins carry less.
API Backends
For API backends, a second coast becomes useful early because traffic is dynamic and often impossible to hide behind cache. Postman’s API report says 82% of organizations use some level of API-first development, 65% generate revenue from APIs, 46% plan to increase API investment, and 93% still struggle with collaboration. A practical east-to-west split is active/active stateless ingress, local queues and caches, and one deliberate source of truth for mutable state unless the platform can reconcile active/active writes.
US Dedicated Hosting Checklist: Carriers, Bandwidth Caps, and Remote Console
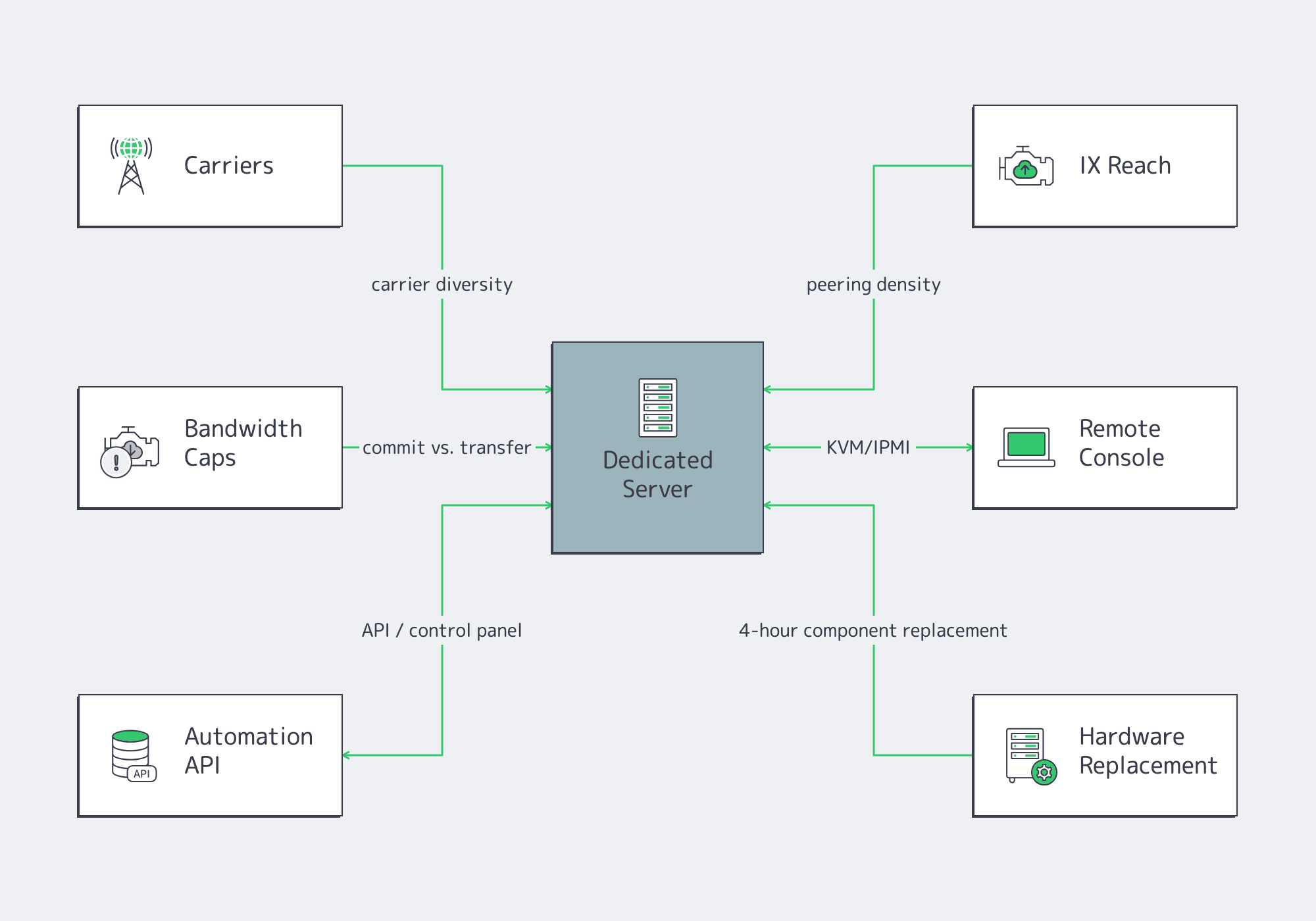
Do not buy a U.S. dedicated server by port speed alone. Route quality comes from carrier diversity, peering density, transfer model, and operational tooling. Verify network reach, translate bandwidth into monthly volume, confirm remote console and automation access, and know the hardware-replacement path before the incident starts.
The Internet Society explains why peering and IX participation matter: they shorten routes, reduce latency, and lower cost. PeeringDB shows a dense exchange presence in Los Angeles, including Any2West with 266 peers and BBIX US-West with 82 peers; Atlanta also has exchange options, including CIX-ATL and Equinix Atlanta. The right question is which metro matches your upstreams, eyeball networks, partners, and CDN paths.
Bandwidth caps are where cost control becomes math. One gigabit per second sustained for 30 days is about 324 TB; 10 Gbps is about 3.24 PB; 40 Gbps is about 12.96 PB. Port speed, commit, bundled transfer, and metered traffic are different decisions. Operational readiness is just as concrete: remote console plus automation is how teams recover from a bad kernel, bootloader, or network change without waiting in a ticket queue. Melbicom’s U.S. pages advertise control panel, API, KVM, IPMI access, and replacement of failed server components within four hours.
| U.S. Location | Melbicom’s Current Ready-to-Go Range | Planning Signal |
|---|---|---|
| Atlanta | Dozens of configurations; Intel Xeon E5 v4 and Scalable G1-class CPUs; 32-256 GB RAM; 1-40 Gbps bandwidth with 50 TB or unmetered plans; public location network options up to 1-200 Gbps per server. | East/Southeast anchor for primary writes, Europe-adjacent traffic, analytics, and DR counterpart to Los Angeles. |
| Los Angeles | 50+ configurations; Intel Xeon E5 v4 and Scalable G1-class CPUs; 128-256 GB RAM; 1-40 Gbps bandwidth with 50 TB or unmetered plans; public location network options up to 1-200 Gbps per server. | West/Pacific anchor for media origins, API ingress, APAC-facing routes, and DR counterpart to Atlanta. |
Custom server configurations can be deployed in 3-5 business days when the ready-to-go list does not match the workload. Where BGP matters, evaluate support for announcing your IP networks and route-change operations; routing features should complement, not replace, a tested disaster-recovery runbook.
Cost Control for a Dedicated Server in the United States
Cost control is topology discipline, not a hardware shopping exercise. The efficient U.S. design often starts with one authoritative region, then adds a narrow second region for stateless ingress, caches, replicated assets, and recovery capacity. That captures latency and resilience gains without paying a permanent active/active tax.
For media, move cacheable bytes to CDN before buying more origin port speed. For SaaS, split transactional writes from analytics, exports, search indexing, and file distribution before mirroring the whole stack. For APIs, split ingress east/west before splitting every database east/west. These choices keep the bill rational while improving user experience.
Use this sequence before committing spend:
- Put the primary write path on the coast where interactive users, operator actions, and latency-sensitive dependencies already live.
- Keep synchronous replication inside one region; treat coast-to-coast links as disaster recovery, read locality, or stateless traffic distribution unless active conflict handling is already built.
- Add the second coast when outage cost, national user spread, or Pacific- versus Europe-facing traffic patterns justify it.
- Price network capacity by monthly transfer volume and event peak shape, not by the port label.
- Validate carrier and IXP quality with tests from each metro, because peering depth turns advertised capacity into usable performance.
- Require remote console and automation from day one; API plus KVM/IPMI is resilience, not an upsell.
- Replicate only the layers that buy latency or recovery: cacheable media to CDN, assets to object storage, stateless ingress to both coasts, and stateful tiers only as far as service targets require.
Applying the Framework to Melbicom’s USA Dedicated Server Options
Melbicom makes the framework practical by giving U.S. buyers two real placement choices: Atlanta and Los Angeles. Use those metros to test routes, model transfer economics, decide whether disaster recovery needs a second coast, and validate operational readiness before the architecture hardens.
At Melbicom, we pair those U.S. metros with 19 other global data centers, 1,400+ ready-to-go configurations, 20+ transit providers, 25+ IXPs, 14+ Tbps of network capacity, and a CDN footprint in 55+ PoPs across 39 countries. Start with the coast that protects user latency, then add the opposite coast when recovery design or traffic mix proves the need.
Compare USA Servers
Compare Atlanta and Los Angeles options for routes, bandwidth, and recovery.
Get expert support with your services
Blog

Choosing Country, Network, and Compliance in Europe
Choosing a dedicated server in Europe is no longer a “pick the closest metro” decision. Data residency, RTT budgets, transfer pricing, and grid-linked capacity now shape the result more than raw server specs. Europe’s core exchanges move traffic at planetary scale—DE-CIX reported 79 exabytes globally and 48 exabytes in Frankfurt, while AMS-IX reported 35.66 exabytes and a 14.2 Tb/s peak. That changes how placement/bandwidth should be bought.
Choose Melbicom— Tier III/IV-certified data centers — 1,000+ ready-to-go servers — 55+ PoP CDN across 36 countries |
|
Dedicated Server Europe: The Decision Constraints That Matter Now
Europe is not one infrastructure zone. It is a mix of jurisdictions, peering ecosystems, and power conditions, so country choice, network design, and compliance now behave like one architecture problem. Get one dimension wrong, and the cost shows up somewhere else: latency, transfer spend, or operational risk.
Bandwidth economics feel different in Europe because the interconnection fabric is different. Dense peering and market maturity pull costs down in major hubs, while Euro-IX’s reporting shows operational IXPs in Europe grew 89%, from 144 to 273, over a decade. But the physical layer still matters. REN21 estimates data centers consumed about 460 TWh globally, around 2% of electricity demand, and the OECD has warned that grid bottlenecks can constrain large new loads. The result: the best metro on a map is not always the best metro to scale.
How to Choose the Right Country for a Dedicated Server in Europe
Choose a country the way you choose a platform dependency: by matching legal boundaries, network reach, and latency budgets to the workload. The right answer is often one primary site plus a deliberate secondary or edge strategy, not a single “Europe” location expected to do everything.
Data residency basics: map data, not servers
“EU residency” usually breaks in telemetry, backups, and admin paths, not in the production database. Under the GDPR’s transfer rules and the EDPB’s guidance on supplementary measures, the important question is where personal data goes and who can reach it. For dedicated servers, residency mapping should include databases, object storage, snapshots, logs, monitoring, and the human access layer.
Latency as a placement budget: physics first, routing second
Location still sets the lower bound. A standard engineering rule of thumb is that light in fiber moves at roughly 200,000 km/s, so every 1,000 km adds about 5 ms one-way, or roughly 10 ms RTT before routing overhead. A RIPE Atlas-based longitudinal study found delay fell for 80% of European city pairs, but that does not erase geography. It makes smart geo more valuable. Buy for your real user metros, not for a central Europe abstraction.
Network density and power availability: pick your trade-off deliberately
Dense hubs can beat physically closer sites because they offer better peering and fewer ugly routes, but they can also face sharper capacity pressure. Country selection is a trade-off between legal fit, practical RTT, and infrastructure headroom.
A Practical Country-and-Metro Selection Table
| Country / metro archetype | Why teams pick it | What to model as the trade-off |
|---|---|---|
| Netherlands / Amsterdam | Dense connectivity and strong Western European reach. | Core hubs can face intense demand; add a second site if one-metro failure is unacceptable. |
| Germany / Frankfurt | Central geography plus heavyweight interconnection. | Centrality is still a compromise; proximity beats “middle of the map” for strict low-latency targets. |
| France / Paris | Good reach into Western and Southern Europe. | Residency leaks often happen through observability or support tooling, not the core database. |
| Spain / Madrid | Useful for Iberia and some transatlantic path variants. | Southern placement can stretch RTT north and east, so a central secondary site may be worth it. |
| Sweden / Stockholm | Strong northern reach and good separation from southern hubs. | Cross-continent consistency often needs a second site or CDN layer. |
| Poland / Warsaw | Helpful for eastern reach and for spreading failure domains. | East-west replication and failover design matter more than buyers expect. |
Dedicated Server Europe Placement: Low-Latency Single-Site vs. Multi-Site

Single-site is right when state is centralized, the user base is concentrated, and cross-site coordination would cost more than it saves. Multi-site becomes the better product decision when latency variance, jurisdictional boundaries, or resilience requirements are now part of the application itself.
The key distinction is state. Put authoritative writes where they are easiest to keep correct; then move stateless layers closer to users. Uptime Institute has described the broader shift from single-site hardening toward distributed, replicated resilience, and its survey work shows more than half of workloads are off-premises in some capacity. In practice, that often means one primary EU site, one secondary site for failover or lower-latency reads, and an edge layer for cacheable traffic.
A common rollout is simple: start with one central site, add a second EU site when latency or resilience justifies it, then move static and bursty delivery outward. On the infrastructure side, Melbicom supports private networking between different data centers. If routing control matters, Melbicom’s BGP Sessions gives teams a path to customer-managed prefix announcements and traffic steering. That is more useful when the network underneath it is deep enough to matter; Melbicom’s current commercial materials describe 20+ transit providers and 25+ IXPs across the broader platform.
Europe Dedicated Server Cost Comparison: Metered vs. Unmetered Bandwidth

Metered bandwidth works when traffic is uncertain or still small. Unmetered bandwidth works when steady egress, high cache-miss rates, or traffic spikes make predictability more valuable than pure utilization. The decision is who carries the tail risk: you, or the contract.
The market backdrop favors larger committed capacity. TeleGeography found weighted median 100 GigE IP transit port prices in major cities falling at roughly 12% annually over a recent three-year window. That helps explain why unmetered offers are increasingly common in Europe. But port speed is not the bill. A 10 Gbps or 40 Gbps port is capacity; billed transfer is a separate question.
The cheapest bandwidth decision is often architectural. Keep dynamic requests on the dedicated server. Push bulk objects into S3-compatible storage. Put cacheable traffic behind a CDN. That reduces repeated origin egress and improves user experience at the same time.
EU Dedicated Server Due Diligence Before Signing: Residency, Security, & Migration Fit

Due diligence is where theory meets invoices and incident response. Before signing, verify that data stays inside the intended boundary, security baselines are enforceable, DDoS and segmentation assumptions are real, and migration economics still work after transfer, replication, and operational overhead are counted.
Residency due diligence should prove control, not intent: map every transfer and every access path. Security should start with CIS Benchmarks for configuration and the SANS Linux hardening checklist for patching, services, and permissions. Segmentation should be default: production, admin, replication, and monitoring should not share one trust zone. Migration fit should be judged workload by workload. Uptime’s survey data shows hybrid delivery is normal, not transitional. The best candidates for repatriation are usually steady-state databases, predictable background processing, and egress-heavy services where public-cloud transfer pricing overwhelms flexibility.
Vendor-neutral checklist before you sign
- Map databases, backups, logs, traces, monitoring, and admin access before you talk about “residency.”
- Build a latency budget using user geography, distance, and routing variance.
- Decide single vs. multi-site based on where state lives and what failure you can tolerate.
- Separate port speed from billed transfer when comparing metered vs. unmetered offers.
- Apply CIS-aligned baselines, SANS-style hardening, and segmentation from day one.
- Ask how abuse response, filtering, and routing controls are governed.
- Start migration with one workload that can prove cost, latency, and compliance fit.
Configure Now: A Clear Path From Requirements to a Melbicom Order

The fastest path is to turn architecture into filters: country boundary, target RTT, transfer model, and security posture. Shortlist one core metro and one secondary or edge candidate, test real paths, then lock hardware and network. That sequence keeps procurement from getting ahead of design.
Start with Melbicom’s Europe dedicated server catalog: Amsterdam, Frankfurt, Madrid, Palermo, Paris, Riga, Sofia, Stockholm, Vilnius, and Warsaw. Then check the live location inventory instead of assuming every metro has the same depth. If the design is multi-site, validate private interconnect needs on Melbicom’s network page and decide whether BGP sessions belong in the ingress strategy. Keep bulk objects and cacheable traffic off the origin where it makes economic sense by pairing the server with S3 storage and CDN.
Explore Europe Dedicated Server Options
Compare European server locations, network options, and bandwidth models to match your latency, residency, and compliance requirements.
Get expert support with your services
Blog
Buy Amsterdam for Bandwidth and Control
Amsterdam is no longer a “pick a central city and you’re done” decision. The modern trap is subtler: you can buy a strong dedicated server and still ship a slow product because the network path is wrong, the port is “unmetered” only on paper, the abuse workflow is a surprise, or the remote console is available but unsafe to rely on when an incident lands.
This guide is built around a simpler reality: for latency-sensitive platforms, bandwidth is now a product feature because it is tied to peering, backhaul capacity, route control, and how fast your team can regain control when something breaks. The goal is to make Amsterdam measurable before you migrate, not merely attractive on a spec sheet.
Choose Melbicom— 400+ ready-to-go servers configs — Tier IV & III DCs in Amsterdam — 55+ PoP CDN across 6 continents |
|
Dedicated Server Amsterdam: Why the Network Has Become the Product
Amsterdam’s edge is network gravity, not central geography. AMS-IX says its Amsterdam platform handled 35.66 exabytes of traffic in the most recent full year, reached 69.57 Tb/s of active port capacity, and logged a 65% annual increase in 400G ports. EXA Infrastructure also launched a 1,200 km route and the first new North Sea subsea cable in 25 years. Those are not vanity metrics; they show why exchange density and path diversity now matter as much as rack space.
Capacity pressure is the other half of the story. CBRE expects Europe’s vacancy rate to close at 9% amid strong demand and a “lack of available power,” which is exactly why fast provisioning matters. In Amsterdam, Melbicom’s dedicated server footprint spans Tier III and Tier IV data centers in Amsterdam, and both facilities enable up to 200 Gbps per server. This is not a chassis decision first; it is a network-position decision.
How to Choose a Dedicated Server in Amsterdam for EU Low-Latency Traffic
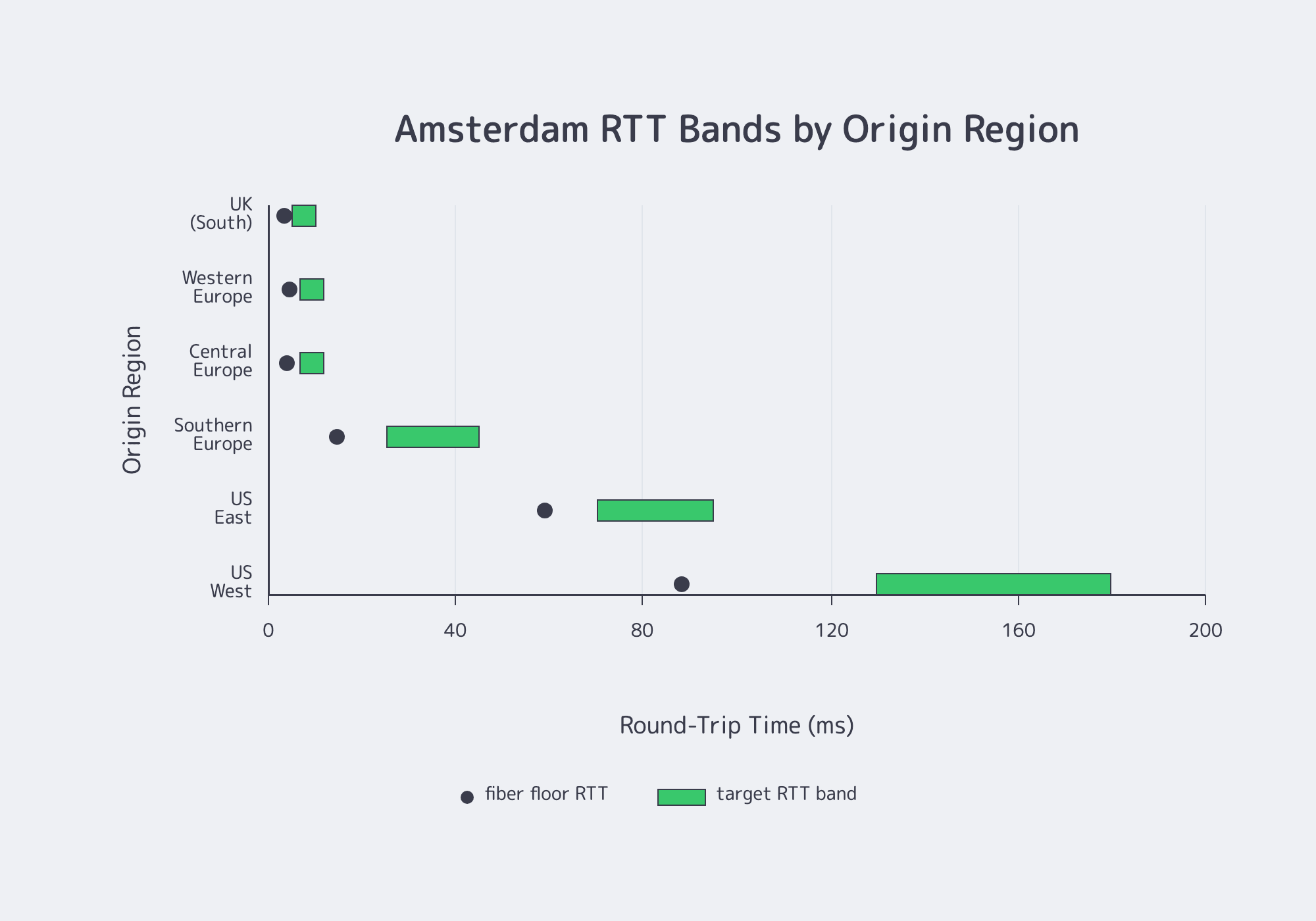
Start with latency mapping, not hardware browsing. For a dedicated server in Amsterdam, the first pass is whether EU, UK, and transatlantic routes stay inside your target RTT bands under real ISP conditions. If paths miss the band, extra cache or compute rarely fixes the user experience.
A useful model separates physics from routing. Physics gives you the floor: a quick rule of thumb for single-mode fiber is roughly 4.9 microseconds per kilometer. Routing determines the lived experience: RIPE Labs notes that “close” according to BGP and geographically close are not always the same thing.
Use the table below as a planning model. The floor RTT uses the fiber rule of thumb; the goal band adds routing overhead, peering variation, and congestion margin. Melbicom publishes an Amsterdam test endpoint and download payload so you can validate the model before migration.
Latency Mapping for a Dedicated Server in Amsterdam
| Origin Region | Distance / Floor RTT | Goal RTT Band | If You’re Above the Band |
|---|---|---|---|
| Western Europe | 450 km / 4.4 ms | 7–12 ms | Test multiple ISPs and avoidable hops |
| Central Europe | 400 km / 3.9 ms | 7–12 ms | Verify reverse-path consistency |
| Southern Europe | 1,500 km / 14.7 ms | 25–45 ms | Watch congested interconnects |
| US East | 6,000 km / 58.8 ms | 70–95 ms | Validate transatlantic diversity |
| US West | 9,000 km / 88.2 ms | 130–180 ms | Prioritize route stability |
The point is simple: Amsterdam is an excellent EU hub, but US performance still depends on path quality, not map distance alone.
A practical decision playbook:
- Define at least two acceptance bands: EU core and transatlantic.
- Test from multiple networks inside each band, not just one office ISP.
- Treat traceroute as diagnostic, not truth; RIPE Labs notes that traceroute shows the forward path while RTT reflects both forward and reverse paths, which can differ.
- If results drift, ask for levers you can actually control, such as BGP policy or a different transit mix.
True Unmetered vs. Capped Ports in Amsterdam Dedicated Server Offers
“Unmetered” matters only if the port stays clean under sustained, parallel load. Ignore headline burst numbers and verify multi-stream throughput, loss, retransmits, and any time-based shaping during real traffic windows. An Amsterdam dedicated server should clear those checks before you move a production origin or API tier.
What matters in practice is port speed, sustained throughput, and policy reality. That matters more now because AMS-IX traffic keeps rising and 400G ports are scaling fast, while Melbicom’s Amsterdam PoP offers high-bandwidth server options with guaranteed bandwidth, without ratios. For a buyer, this matters more than a burst number on a banner.
How to Validate “True Unmetered” on an Amsterdam Dedicated Server
Treat unmetered as a claim to verify. The three failure modes worth catching early are a single-flow ceiling, multi-flow collapse, and time-based shaping after several mins of load.
A pragmatic acceptance test:
- Run ping and MTR baselines for at least 30 minutes.
- Use 8–32 parallel streams, not one optimistic transfer.
- Repeat during local peak windows.
- Hold throughput long enough to reveal shaping, usually 10–20 minutes.
- Track retransmits and packet loss, not just headline Mbps.
- Save the result as your known-good baseline.
A streaming-origin relocation works best when bandwidth verification is treated like release engineering: run the bake, verify that sustained multi-stream load stays flat, then roll traffic in stages. That is how “unmetered” stops being marketing language and becomes operationally believable.
Which Amsterdam Dedicated Server Checks Matter before Migration & Incident Response
Before migration, focus on the checks that still matter at 2 a.m.: remote console recovery, DDoS and abuse workflow, IPv4/IPv6 readiness, and route control. Those are the controls that turn fast provisioning into a safe server deployment instead of a risky cutover.
Remote Management on a Dedicated Server
Remote management is the difference between fixing a bootloader issue in minutes, recovering from a firewall mistake without losing the host, and diagnosing a kernel panic from a real console instead of partial telemetry.
Melbicom’s servers have a dedicated IP-KVM port connected to an isolated management network, with customer access via VPN. That matches NSA guidance that management interfaces should never be directly exposed to the Internet and helps explain why exposed BMC/IPMI surfaces remain a bad idea: NIST still documents high-impact cases such as “cipher zero” authentication bypasses. Looking forward, Redfish-style REST-based out-of-band automation is increasingly the cleaner control plane, even when classic IPMI/KVM remains the break-glass tool.
DDoS and Abuse-Policy Fit Is an Ops Requirement
This is not about selling DDoS features. It is about workflow: what happens to your traffic, your ports, and your support path when pressure starts.
The Netherlands is still a strong jurisdiction for internet operations: Freedom House describes internet freedom there as robust, while the OECD’s Netherlands notice-and-take-down document outlines a structured, intermediary-oriented process for handling alleged unlawful content, with compliance framed as voluntary but procedural. On the DDoS side, NBIP’s NaWas has operated since 2014 and says it provides automatic 24/7 mitigation for connected participants. The takeaway is not “buy a badge”; it is “choose an operating model you can execute quickly.”
What to check before you migrate:
- What triggers suspension versus a remediation request?
- Who can answer an abuse or attack escalation around the clock?
- Are logs, timestamps, and ownership already wired into your playbook?
IPv4/IPv6 Strategy and BGP Control
Addressing is now part of the bandwidth decision. RIPE NCC says its remaining IPv4 pool was exhausted in 2019, while APNIC reports the global average IPv6 capability at around 40%, with adoption still uneven by region. The practical answer is straightforward: treat dual-stack as default, preserve IPv4 where compatibility still matters, and make sure observability and security tooling are IPv6-aware.
Routing control is the next lever. Melbicom’s BGP session service lists BYOIP, IPv4 and IPv6 support, BGP communities, and full, default, or partial routing, and it states that BGP sessions are free on dedicated servers. For a latency-sensitive SaaS cutover, the clean pattern is provision Amsterdam, baseline latency and throughput, then shift traffic in stages while keeping rollback ability. Teams that can announce or re-announce prefixes avoid brittle DNS-only moves and keep endpoint control during change windows.
Fast Deployment Checklist and Acceptance Test Plan

Amsterdam is a location with abundant inventory. Melbicom’s Amsterdam facility provides over 500 ready-to-go server configurations, offering up to 200 Gbps per server. Available stock is prompted for 2-hour activation, and custom configs are deployed within 5 days.
A fast deployment is only “fast” if it includes verification.
Deployment checklist:
- Confirm facility, port size, and redundancy plan.
- Pre-map latency from EU, UK, and US vantage points.
- Decide your minimum IPv4 need and enable IPv6 from day one.
- Define unmetered proof: parallel streams, sustained duration, peak-hour reruns.
- Lock remote-console access behind VPN and document break-glass use.
- Pre-wire abuse handling, ownership, and logging.
- Plan BGP before migration day if route control matters.
Acceptance test plan:
- Validate remote console access while everything is healthy.
- Run 30-minute latency baselines and capture jitter.
- Test single-stream and multi-stream throughput.
- Repeat throughput tests at peak hours.
- Use the Amsterdam test payload as a sanity check.
- Verify IPv6 end to end.
- If using BGP, test propagation and rollback.
Key Takeaways for a Bandwidth-First Amsterdam Buy
- Approve Amsterdam only after three RTT bands are baselined: EU core, UK, and transatlantic.
- Treat unmetered as unproven until sustained multi-stream testing says otherwise.
- Keep remote console on an isolated management path with VPN-only access, and rehearse it before change windows.
- Plan dual-stack early; IPv4 scarcity is structural, not temporary.
- Predefine DDoS and abuse workflow before launch, because policy surprises cost more than latency misses.
- Buy Amsterdam for controllability: path quality, port integrity, and fast recovery must clear the bar together.
Buy the Network Position, Not Just the Dedicated Server

The Amsterdam decision is no longer a hardware beauty contest. It is a routing and ops decision: can the network hold your RTT budget, does the port behave honestly under sustained load, and can you regain console access the moment a change goes wrong?
That is why the best Amsterdam deployments look boring on launch day. Paths were mapped, unmetered was tested, dual-stack was planned, DDoS and abuse workflow was documented, and rollback access was already rehearsed. Do that work up front, and Amsterdam becomes a controllable hub instead of a latency gamble.
Deploy in Amsterdam
Explore Amsterdam dedicated servers with high-bandwidth options, fast activation, and network controls designed for low-latency deployments.
Get expert support with your services
Blog
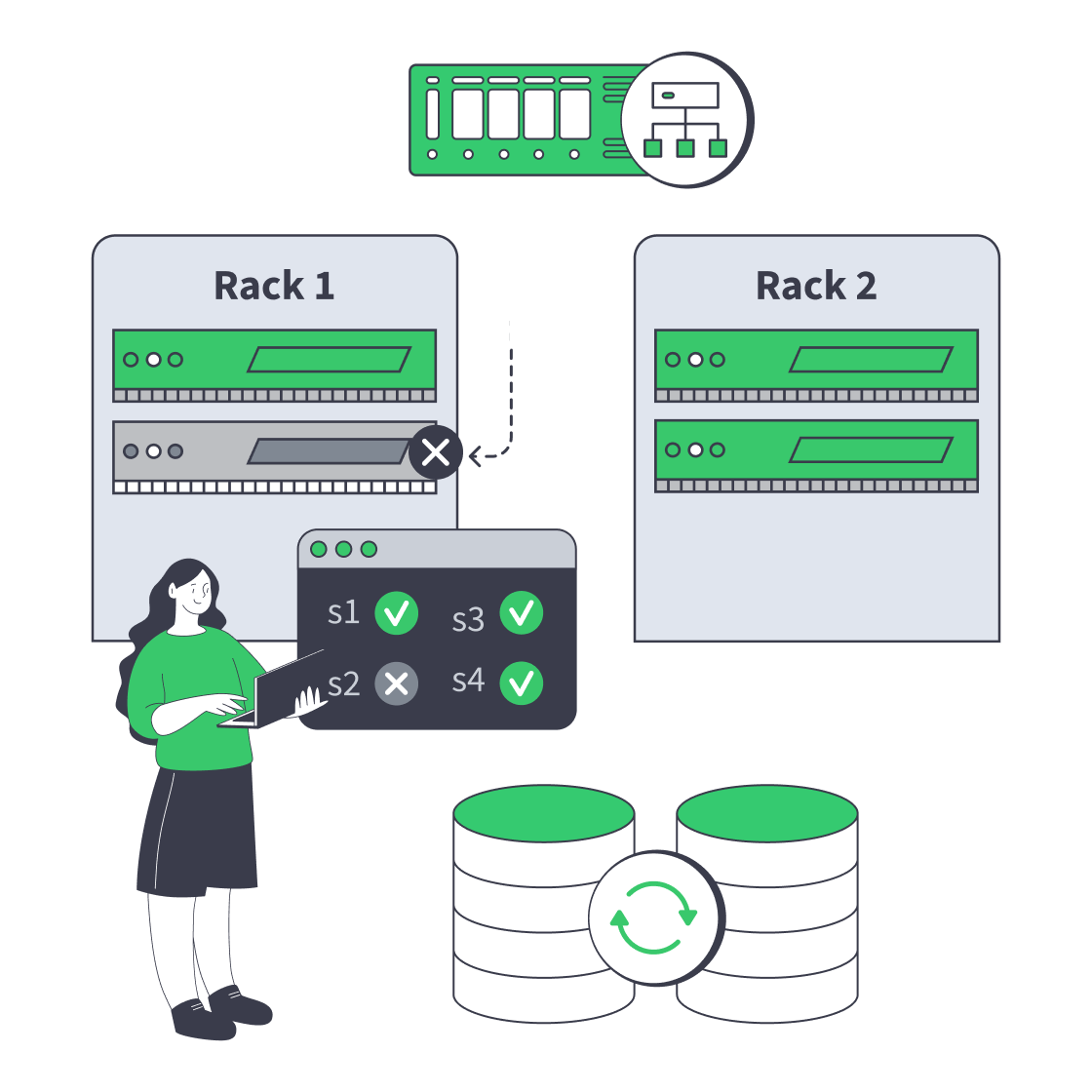
Designing High-Availability Clusters That Fail Safely
High availability becomes concrete once downtime gets priced. An ITIC survey found that more than 90% of mid-size and large organizations now lose over $300,000 per hour of downtime, while 41% put the hit at $1 million to more than $5 million. Uptime Institute data reinforces the point: more than half of respondents said their most recent serious outage cost over $100,000, and one in five said it exceeded $1 million.
That is why availability targets are architecture constraints, not branding. Google’s SRE availability table turns the choice into a hard downtime budget, and each extra 9 narrows the room for slow failovers, sloppy maintenance, or optimistic recovery assumptions.
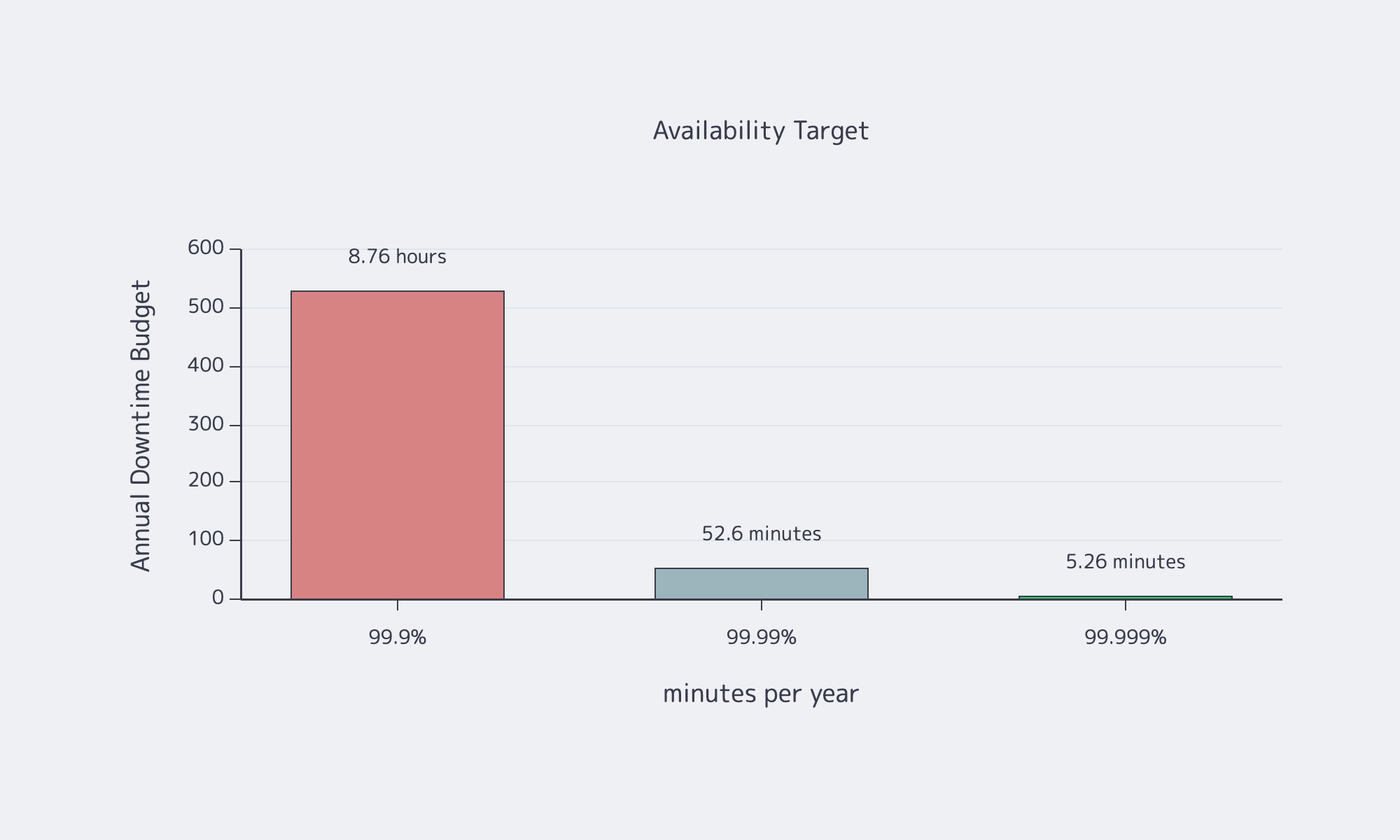
Source: Google SRE availability table.
How Server Clustering Works on Dedicated Hardware for High Availability
Server clustering on dedicated hardware means multiple servers behave like one service, with explicit rules for failover, traffic flow, and data ownership. The aim is predictable behavior when a node, switch, rack, or site fails—without turning every fault into a manual rescue or a risky improvisation.
On dedicated hardware, you choose the failure domains and define how the application, data, and network layers react. The application layer decides whether work is stateless or stateful, the data layer decides whether failover is fast or safe or a trade between the two, and the network layer decides whether users can actually reach the healthy side. N+1 headroom, patching, and hardware rotation belong in the design.
The Web Almanac reports that 97.3% of mobile homepages are served over HTTPS, and more than 98.8% of mobile requests already use HTTPS. That pushes more HA responsibility into the load-balancing tier: TLS termination, certificate rotation, session handling, and app-aware health checks are now part of the failure path, not edge details.
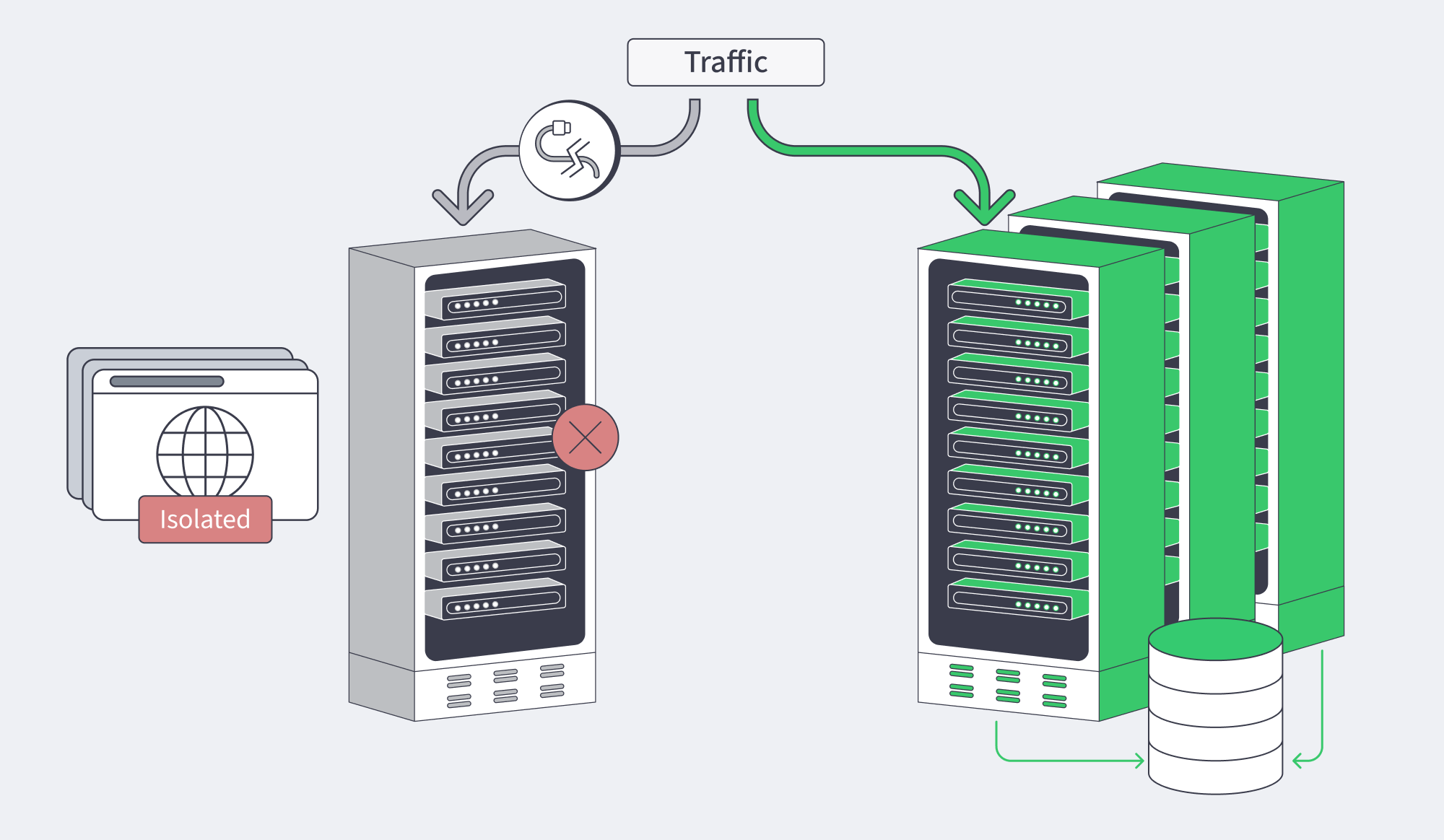
How to Design Active-Active and Active-Passive Clusters Without Split-Brain Risk

Active-passive and active-active answer the same question in different ways: who may serve traffic and write state when the system is stressed? The safe pattern is the same in both: quorum grants authority, fencing removes ambiguity, and any node that cannot prove ownership must stop taking writes.
Active-passive is simpler, but only if false failover is prevented. A split-brain event happens when a standby promotes itself during a partition while the original primary is still alive. Active-active uses capacity better, but it also raises the cost of bad coordination. The practical rule is simple: never allow writes on a node that cannot prove it still has quorum. Raft formalizes majority-based progress, MongoDB operationalizes that with majority write concern and warnings around weak arbiter layouts, and Red Hat’s guidance is blunt that any node that might still touch shared data must be fenced first.
Load Balancing and Failover Patterns for Server Clusters
Load balancing is where users feel the cluster. It decides whether healthy capacity is reachable, not just whether it exists.
L4 balancing fits services where any healthy node can answer any request. L7 matters when correctness depends on cookies, headers, affinity, canaries, or TLS-aware routing. The bigger mistake is shallow health checking. A socket that accepts connections is not the same thing as a node that can safely serve traffic, which is why modern HA designs need shallow process checks, deep dependency checks, and role-aware checks that confirm whether a node may accept reads or writes in its current state.
For active-passive services, a virtual IP via VRRP is still a clean pattern because clients keep one address while leadership moves underneath. For larger failover, DNS can steer broadly, edge layers can select the best entry point, and BGP can move reachability itself. That is why the network matters as much as the nodes: Melbicom’s network enables redundant switching with VRRP-protected L3 connectivity, Melbicom’s CDN supports geographic request routing and origin pooling, and our BGP Sessions support BYOIP plus full, default, or partial routes across all locations—useful building blocks when failover has to survive both server faults and path changes.
Replicated Storage and State Consistency in Server Clusters

Compute is easy to duplicate. State is where HA becomes discipline.
The core trade-off is still RTO versus RPO. The MySQL Reference Architectures for High Availability frame HA and DR as service-level design choices, not as a single “best” topology. Distance adds physics to the argument. As an ITU reference notes, signals in optical fiber move at roughly 200,000 km per second, or about 5 milliseconds per 1,000 kilometers; a 6,000-kilometer path costs roughly 30 milliseconds one way. Synchronous cross-site replication can protect data, but latency still sends the invoice.
Keep voting members odd in number, keep replicas provisioned consistently, and do not hide all copies behind the same dependency. A SAN, storage shelf, or network choke point can quietly turn “replication” back into a single point of failure. If the design includes shared-write storage, split brain is existential, not cosmetic.
Operating Server Clusters: Health Checks, Maintenance, and Incident Workflows
Most HA failures are not dramatic hardware crashes. They are lagging replicas, certificate expiry, partial dependency failure, mis-sequenced maintenance, and configuration drift.
The healthier operating pattern is drain, replace, verify, rejoin. Observability also has to catch brownouts, not just outages, which is why Google’s SRE guidance and MongoDB’s production guidance both push teams toward indicators such as replication lag, stale reads, queue growth, and capacity pressure instead of relying on binary “up/down” checks.
The useful chaos-engineering questions are still the obvious ones:
- Will health checks detect the right failure fast enough?
- Will failover pick the right winner based on quorum, fencing, and data freshness?
- Can the system return to a stable state without a split-brain hangover?
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
|
When Server Clustering Is the Right Answer Instead of Kubernetes or Vertical Scaling
Server clustering is the right answer when a small number of critical services need explicit failover, bounded blast radius, and clear leadership rules. Kubernetes fits broader platform standardization across many services. Vertical scaling fits workloads that mostly need more headroom on one box, not more distributed machinery.
Kubernetes is mainstream; the CNCF reports that 82% of container users now run it in production. But popularity is not a design argument. Stateful reliability still depends on quorum, storage, routing, and failure handling whether the workload runs inside a cluster manager or not.
| Decision Trigger | Prefer This Approach | Why It Fits |
|---|---|---|
| Predictable failover for a small number of critical services | Server clusters | You can define leadership, quorum, storage behavior, and routing rules explicitly, with a smaller operational surface area. |
| Many services, frequent deploys, standardized scheduling | Kubernetes | A common control plane improves fleet operations, but stateful availability still depends on the same storage and quorum fundamentals. |
| CPU or RAM limits on one system, with restart tolerance | Vertical scaling | It is the simplest model, but it keeps single-node failure in play, so some failover plan is still required. |
Design Checklist for Server Clusters
- Design for the failure domains you can actually isolate: node, rack, path, storage tier, or full site.
- Elect leadership with quorum or a witness; heartbeat loss alone is not enough to justify promotion.
- Fence before you fail over any service that can still touch shared-write state.
- Size active-active for degraded mode, not for sunny-day utilization.
- Make health checks role-aware and dependency-aware, especially for write paths.
- Prefer maintenance playbooks that drain, verify, and rejoin instead of “patch in place and hope.”
- Track replication lag, queue depth, route convergence, and recovery time as first-class reliability signals.
- Rehearse partitions and operator mistakes before production rehearses them for you.
Conclusion: Design for Failure You Can Name
The strongest HA clusters are not the ones with the most layers. They are the ones that make failure behavior obvious. If leadership is explicit, writes are gated by quorum, fencing removes doubt, and health checks understand role as well as liveness, failover becomes a property of the design instead of a hopeful script.
That is why the clusters-versus-Kubernetes-versus-vertical-scaling decision matters. Pick the model that matches the workload, then design the failure path with as much care as the happy path.
Dedicated Servers for HA Clusters
Explore dedicated servers in 21 Tier III and IV data centers with high-capacity ports, BGP sessions with route control, CDN support, and fast deployment for high-availability clusters.
Get expert support with your services
Blog
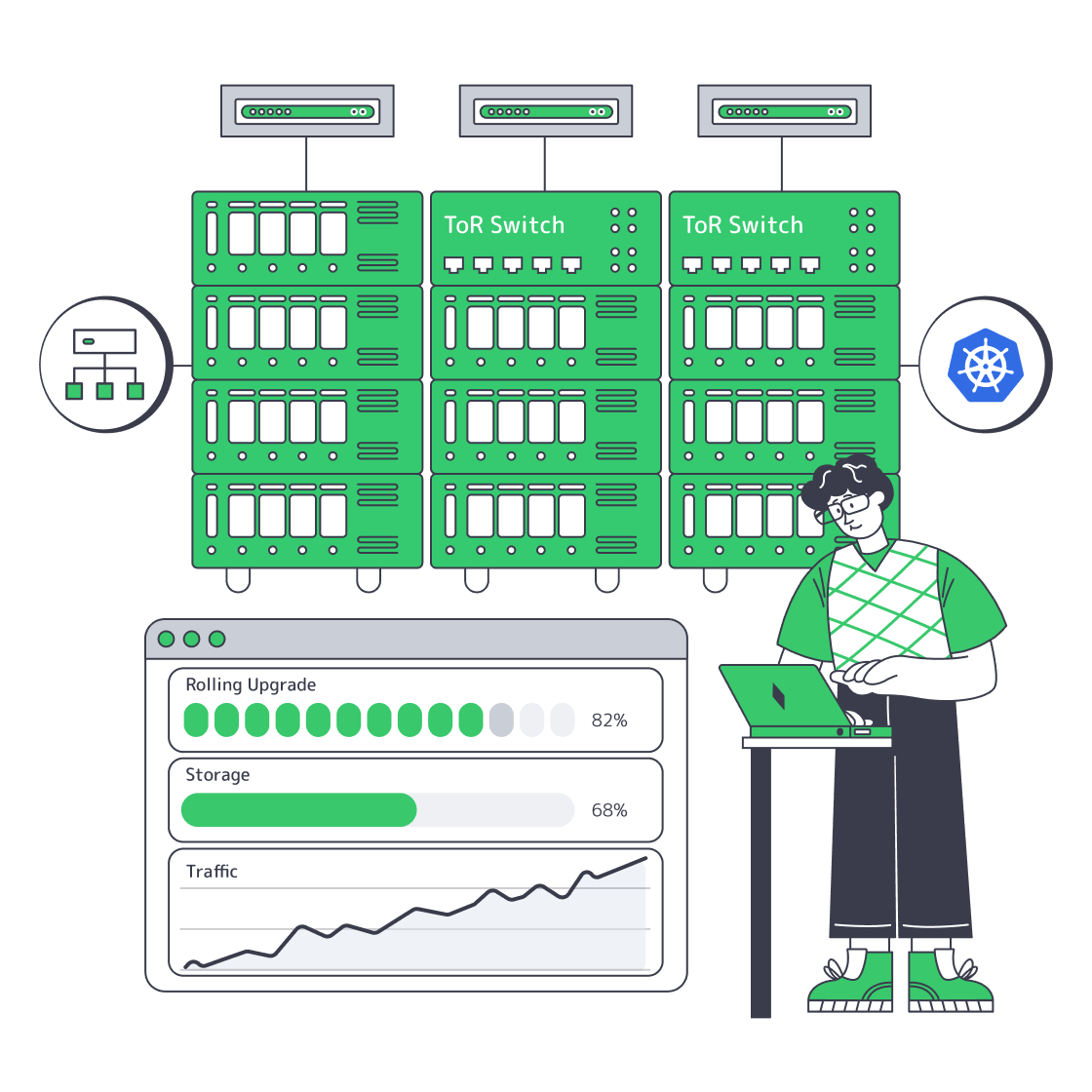
Operating Big Bare Metal Kubernetes Clusters
Running Kubernetes on physical servers stops being routine once the cluster has to survive racks, top-of-rack switches, power feeds, and upgrade waves that touch thousands of workloads. That is where managed abstractions can start working against you.
CNCF reports that 82% of container users run Kubernetes in production, and Flexera says 76% of large enterprises spend more than $5 million per month on public cloud. For bandwidth-heavy platforms, the question becomes predictability.
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
|
What Is a Big Bare-Metal Kubernetes Cluster?
A big bare-metal Kubernetes cluster is not defined by node count alone. It becomes “big” when topology, automation, and change management become the main reliability controls, because racks, switches, control-plane pressure, and upgrade sequencing matter more than simply adding workers.
Kubernetes can scale to 5,000 nodes, 110 pods per node, 150,000 pods, and 300,000 containers. Useful envelope, wrong operating definition. In practice, a cluster feels big earlier, when the dominant problems change:
- Failure domains must become scheduling inputs.
- API bursts and watch fan-out must not swamp etcd.
- Version skew and API removals become SLO risks.
- Fleet boundaries matter as much as cluster size.
That is where dedicated servers start to make sense: not because they simplify K8s, but because they let you make topology, networking, and lifecycle management intentional.
What Makes a Bare-Metal Kubernetes Cluster “Big” from an Operations and Failure-Domain Perspective?
A bare-metal Kubernetes cluster becomes operationally “big” when failures are correlated rather than isolated. The platform has to survive rack loss, control-plane locality shifts, and rolling maintenance without manual rescue, because the real risk is shared fate across infrastructure, networking, and the systems meant to heal both.
Failure domains become schedulable topology
On physical infrastructure, the blast-radius stack is concrete:
- a single server
- a rack
- an aggregation domain
- a data-center domain
That is why topology stops being optional. Pod Topology Spread Constraints exist so replicas can be distributed across real boundaries instead of pretending every node is interchangeable. Melbicom’s network design is exactly the kind of physical layout Kubernetes should understand.
Control-plane traffic locality matters
Nodes do not automatically steer API traffic to a same-zone endpoint. In a large multi-rack cluster, locality therefore belongs in the load-balancing design, not in hopeful assumptions about the scheduler.
Upgrade blast radius is a first-order SLO risk
Big clusters are dominated by change: kernels, runtimes, CNI, CSI, Gateway implementations, policy engines, and Kubernetes itself. Two upstream rules shape every serious upgrade plan:
- version skew limits how far components can drift
- API deprecation explains why minor upgrades can still break workloads
On dedicated servers, staged upgrades are possible only if you have spare capacity, rollback room, and placement discipline.
Correlated failures: the “shared fate” problem
Large clusters fail in waves. A ToR pair flaps, a storage path saturates, or routing shifts just enough to turn healthy control-plane traffic into a storm. That is why API Priority and Fairness matters: protecting the API is part of self-healing.
How to Design Networking, Storage, and Control-Plane HA for Bare-Metal K8s Clusters
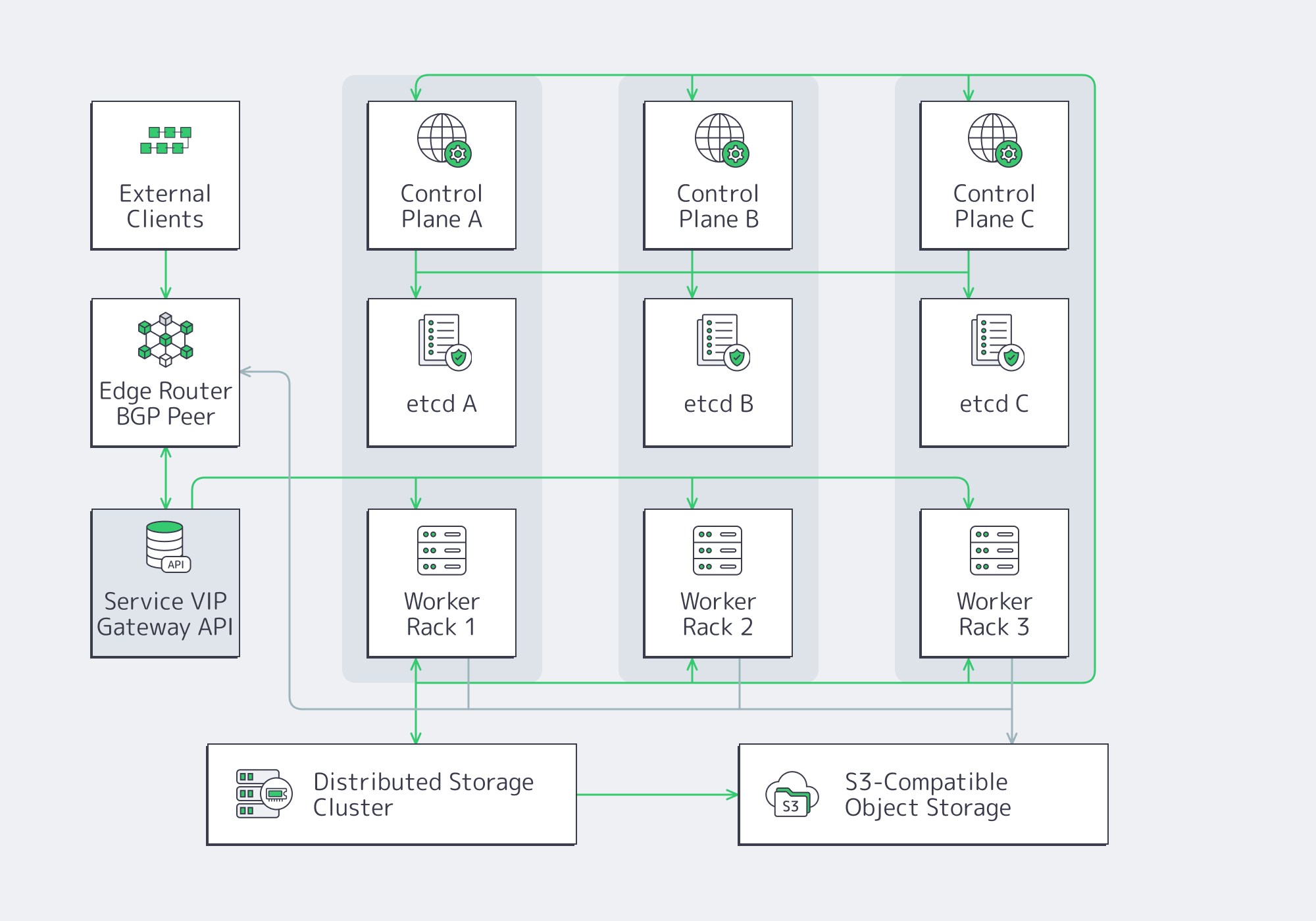
The right reference architecture optimizes for predictable behavior under failure and change. Large bare-metal clusters need an HA control plane placed across real failure boundaries, a data plane built for L3 multi-rack networking, a load-balancing strategy based on VIPs or BGP, and storage tiers aligned to recovery goals rather than convenience.
Control plane and etcd: HA that is actually operable
Place at least one control-plane instance per failure zone, then protect etcd like the latency-sensitive system it is. etcd hardware guidance calls for roughly 500 sequential IOPS for heavily loaded deployments versus about 50 for minimal viability, and its tuning docs warn that long fsync latency can trigger missed heartbeats and leader elections.
Kubernetes also recommends a separate etcd for Event objects in large environments, so high-churn data does not compete with the objects that keep the platform alive.
Networking baseline: assume L3, assume multi-rack, assume failure
At this size, Kubernetes networking is data-center engineering expressed through a CNI. Start from L3, assume east-west traffic will cross racks, and design for the path that fails first under load.
Kubernetes on bare metal: modern CNI and service routing choices
CNI choice at scale is really three decisions:
- how service load balancing works
- how network policy is enforced and debugged
- how observable the datapath is under real traffic
That is why modern designs gravitate toward eBPF data paths. Cilium’s kube-proxy replacement pushes service routing into the kernel, supports consistent hashing, and reduces iptables churn.
Load balancing: treat BGP as an infrastructure primitive, not a workaround
Bare metal Kubernetes has to create its own LoadBalancer semantics. In practice, that usually means:
- MetalLB advertising service VIPs over BGP
- kube-vip managing virtual IPs for the control plane and, where needed, services
At large scale, BGP is not a cloud substitute. It is the cleanest way to make Kubernetes endpoints participate in the wider network, which is why Melbicom’s BGP session service matters in this architecture.
North-south traffic: Gateway API is the “big cluster” control surface
Gateway API is the better north-south contract for large clusters because it separates infra ownership from route ownership and reduces cluster-wide ingress contention.
Storage strategy: performance tiers + failure domains + operable recovery
State punishes wishful thinking, so large clusters usually settle on three tiers:
- Local high-performance storage for low-latency workloads that can replicate at the application layer.
- Distributed block or file storage where transparent failover matters more than peak performance.
- Object storage for snapshots, backups, artifacts, and long-term telemetry.
VolumeSnapshots turn recovery into an API operation. Rook gives distributed storage a Kubernetes-native control loop. Thanos assumes object storage as the long-term metrics layer. Melbicom’s S3-compatible storage fits that third tier cleanly for backups, retention, and artifact pipelines.
How Day-2 Ops on Bare Metal Kubernetes Compare with Managed Kubernetes
Day-2 is the real trade. Managed Kubernetes removes part of the control-plane burden, but large bare-metal clusters give you more control over cost shape, routing, storage behavior, and lifecycle timing. The catch is simple: every convenience the cloud hides has to be replaced with automation that is reliable enough to become boring.
Patching and upgrades: make change boring or the cluster won’t survive
The core loop is straightforward: drain safely, reboot deliberately, validate aggressively. kubectl drain respects PodDisruptionBudgets, and Kured turns required reboots into a controlled DaemonSet workflow.
Node replacement automation: treat servers as replaceable, not precious
The sustainable posture is declarative lifecycle management for physical nodes:
- Tinkerbell for provisioning workflows
- Cluster API for cluster lifecycle
- Metal3 for bare-metal-oriented cluster management
Replacements have to preserve identity, labels, certificates, provider IDs, and topology membership. Melbicom’s dedicated-server platform matters here because hardware turnover is part of the design, not the exception path.
Observability at scale: the data plane is easy; the telemetry plane hurts
Prometheus is explicit that local storage is single-node in scope, which is why large clusters converge on remote or object-storage-backed metrics. In community discussion, users report query pain around roughly 10 million series, and the default --query.max-samples guardrail is 50 million. The durable pattern is short-term local TSDB plus long-term object storage, with a normalized pipeline such as the OpenTelemetry Collector.
Security: enforce intent at the platform layer
Large clusters need portable defaults and cluster-wide guardrails. Pod Security Standards and Pod Security Admission set the namespace baseline. NetworkPolicy remains the portable segmentation API. Audit logging turns cluster actions into evidence.
Cost and complexity: the honest comparison
Managed Kubernetes shrinks the platform surface area you own, but it does not remove responsibility for workload design, policy, observability, or most storage decisions. The economic case for dedicated infra is strongest when network-heavy workloads punish usage-based pricing. One arXiv cost study modeled a monthly example at about $4,800 for a managed, usage-priced network path versus $176.66 for a fixed-capacity 1 Gbps link.
The trade is honest: dedicated infrastructure can change the cost shape, but only if provisioning, reboots, placement, and recovery are automated.
| Area | Large bare-metal Kubernetes (self-managed) | Managed Kubernetes |
|---|---|---|
| Control plane | You design HA, etcd hygiene, and API protection. | The provider runs more of the control plane, but clients and workloads can still overload it. |
| Networking | You supply load balancing, routing integration, and CNI policy behavior. | More primitives are prebuilt, but low-level control is narrower. |
| Node and storage lifecycle | You own patching, replacements, backup design, and performance isolation. | More integration is available, but application resilience and data design are still yours. |
Key Takeaways and Melbicom Fit
A big cluster is an operations boundary. Once racks, storage paths, and upgrade waves matter more than node count, the architecture has to privilege topology, routing, and automation over convenience. The best designs isolate failure domains, keep etcd fast, move traffic intentionally, tier storage, and treat hardware turnover as normal, because routing control, storage, and replacement cadence become part of the operating model.
- Model rack, power, and aggregation boundaries as first-class topology labels before maintenance turns into a shared-fate event.
- Reserve spare capacity and rollback room for every kernel, CNI, storage, and Kubernetes upgrade; blast radius should define rollout order.
- Standardize on L3 multi-rack networking and explicit service exposure so failures show up as routable problems instead of opaque “cluster weirdness.”
- Separate hot-path, failover, and retention storage into distinct tiers; one plane rarely satisfies latency, recovery, and telemetry economics at once.
Build on Bare Metal
Explore dedicated servers, BGP sessions, and S3-compatible storage for large Kubernetes clusters that need predictable networking, recovery, and upgrade headroom.
Get expert support with your services
Blog
Crypto Hosting Buyer’s Guide: Dedicated Servers for Nodes & Trading
Crypto hosting is no longer shorthand for “rent a box and keep it online.” Modern crypto workloads concentrate risk in three places: private keys, network reachability, and stateful data that is slow to rebuild. The latest NETSCOUT DDoS report says global attack counts topped 8 million and peak demonstrations reached 30 Tbps, which is why resilience has to start upstream rather than at the server edge alone.
The dependency story changed, too. Stripe cites research showing that 35.5% of global security breaches were linked to third parties. In crypto, that matters because externally managed nodes, shared infrastructure, and opaque platform layers expand the trust boundary. In proof-of-stake Ethereum, validators must stake 32 ETH—roughly $68,000 at recent ETH/USD prices—and operate on a fixed 12-second slot and 32-slot epoch cadence, so uptime is directly tied to economic outcomes.
Best Crypto Hosting— 1,300+ ready-to-go servers — Custom configs in 3–5 days — 21 global Tier IV & III data centers |
 |
What Crypto Hosting Means for Node Ops, Trading Workloads, and Secure Infra
Crypto hosting usually means one of three things: running nodes and validators, placing trading systems close to market data and liquidity, or hosting ASIC mining hardware. The first two are secure compute-and-network problems with very different failure modes. The third is mostly a power-and-cooling business, so this guide only mentions it in passing.
For node operations, crypto server hosting means validators, full nodes, RPC endpoints, indexers, and archival systems. Those are stateful workloads. On Ethereum, a production validator means an execution client, a consensus client, and a validator client. On Solana, the infrastructure profile is more explicit: Agave calls for high-clock CPUs, 12 cores / 24 threads or more for validators, 16 cores / 32 threads or more for additional RPC capacity, 256 GB or more of RAM, 512 GB for full account indexes, multiple NVMe devices, and at least 1 Gbit/s symmetric Internet, with 10 Gbit/s preferred.
For trading, crypto server hosting is less about chain state and more about deterministic networks. Trading systems fail when paths lengthen, packets queue, clocks drift, or endpoints move. That is a different problem from “keep the node in sync.” The buying process gets cleaner once those workloads are separated. ASIC mining hosting sits in the same search bucket, but it is fundamentally about facility power, thermals, and rack operations, not the secure infrastructure decisions covered here.
How to Evaluate Crypto Hosting for Security, Compliance, and Uptime

Evaluate crypto hosting in this order: key custody and signing, isolation and routing control, compliance evidence, and failure tolerance. CPU and RAM still matter, but they rarely decide outcomes alone. In production, the real question is whether the environment lets you sign safely, contain blast radius, and stay correct when components fail or networks get noisy.
Start with key management. If the workload can sign anything of value—validator duties, treasury actions, withdrawals, or custody operations—its risk profile starts there. Where the compliance footprint is higher, buyers should map HSM and KMS choices against FIPS 140-3 and NIST SP 800-57, not as future enhancements but as day-one design constraints.
Then look at isolation. Single-tenant infrastructure narrows the blast radius and reduces noisy-neighbor risk. Network isolation matters just as much: the management plane should be separate from production traffic, and private links should be available where state replication or multi-site failover matters. Melbicom enables private networking between data centers and an isolated management network reached through VPN. On the routing side, Melbicom offers BGP at every data center, enforces RPKI validation, and accepts only prefixes with valid IRR entries. In a world where DDoS demonstrations now reach 30 Tbps, those upstream controls matter more than checkbox language.
Compliance should be evidence-led, not promise-led. Ask for audit artifacts such as PCI DSS, ISO 27001, or SOC 2 Type II reports, plus incident-response and disaster-recovery procedures. Crypto-specific rules push that further: FATF’s virtual-asset guidance applies Recommendation 16—the travel rule—to VASP transfers and requires originator and beneficiary data handling. Uptime works the same way. Tier III means concurrently maintainable; Tier IV means fault tolerant. For validators and critical RPC, that distinction is operational, not cosmetic.
When Dedicated Servers Make More Sense Than Generic Hosting for Crypto Workloads
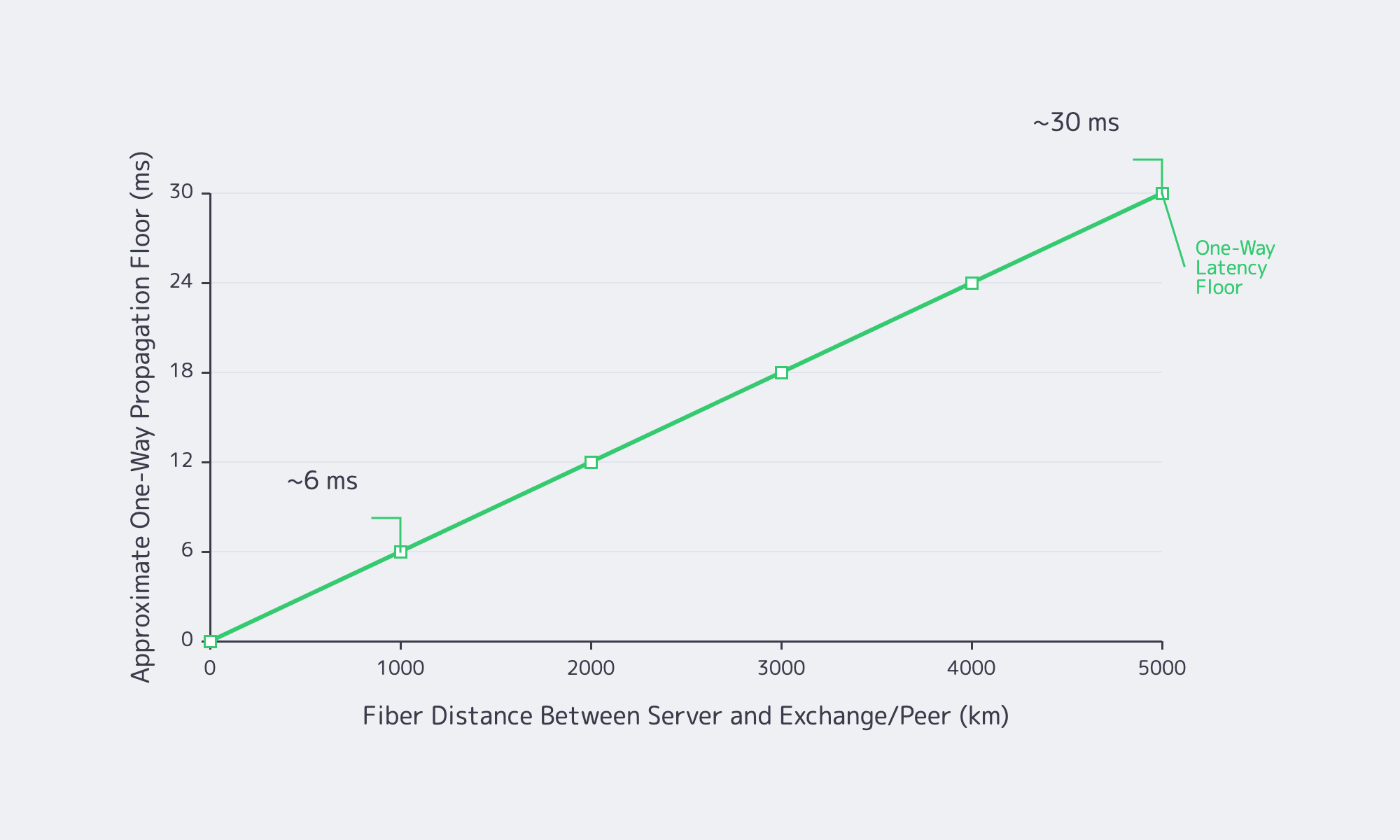
Dedicated servers make more sense when the bottleneck is predictability rather than burst capacity: fast local storage for sync-heavy nodes, stable routing for public endpoints, known tenant boundaries for sensitive operations, and deterministic paths for trading. When failure cost is measured in missed duties, stale data, or unstable ingress, generic hosting stops being cheap.
That is especially obvious in node operations. Ethereum’s node guidance centers storage and bandwidth: recommended specs are a fast CPU with 4+ cores, 16 GB or more of RAM, fast SSD storage with 2+ TB, and 25+ MBit/s bandwidth, while full-history footprints can climb from roughly 2.2 TB to 12 TB or more depending on client. Solana’s Agave guidance is blunter still: cloud deployment requires materially more operational expertise to achieve comparable stability and performance. Dedicated infrastructure wins when you need known disk behavior, cleaner tenant boundaries, and better control over public exposure.
Crypto Server Hosting for Validators and RPC
The table below condenses the latest published hardware guidance from Ethereum and Agave into a buying view.
| Workload | Baseline Hardware Profile | Storage / Network Posture |
|---|---|---|
| Ethereum node | Fast CPU, 4+ cores; 16 GB+ RAM | Fast SSD with 2+ TB; 25+ MBit/s bandwidth |
| Ethereum full-history / archive node | Client-dependent CPU and memory footprint | Roughly 2.2–12 TB+ depending on client, plus ~200 GB for beacon data; bandwidth caps still matter during sync |
| Solana Agave validator | 12 cores / 24 threads+; 256 GB+ RAM; ECC suggested | NVMe for accounts, ledger, and snapshots; at least 1 Gbit/s symmetric, 10 Gbit/s preferred |
| Solana Agave RPC | 16 cores / 32 threads+; 512 GB for full account indexes | Separate high-IOPS NVMe layout; dedicated public IP preferred |
The next design question is how the system fails. Signing should be isolated where possible, and distributed-validator patterns are worth evaluating because they reduce single points of failure. SSV argues that splitting validator operations across multiple independent nodes improves resilience and supports active-active redundancy. Recovery matters, too. Fast local storage should be paired with object storage for snapshots, rollback bundles, and long-retention logs; Melbicom’s S3-compatible storage is relevant here because it is designed as a drop-in S3 service that scales from 1 TB to 500 TB.
Crypto Server Hosting for Low-Latency Trading
Trading infrastructure is a network-placement problem first. Physics sets the floor, then routing and congestion determine how close you stay to it. In optical fiber, a useful planning model is roughly 6 microseconds per kilometer one way. That is why routing control, path quality, and endpoint stability often matter more than another benchmark win on CPU.
This is where Melbicom’s footprint becomes practical rather than decorative. Melbicom offers single-tenant servers across 21 global data centers, a 14+ Tbps backbone, 20+ transit providers, 25+ IXPs, and per-server bandwidth tiers up to 200 Gbps depending on location. BGP is available in every data center.
Key Takeaways
- Classify the workload before pricing servers. A validator, an RPC estate, and a latency-sensitive trading stack should not be bought against the same checklist.
- Put signing architecture ahead of server architecture. If key handling is weak, better CPUs and faster ports do not reduce the real risk.
- Buy bandwidth against failure budgets, not average throughput. Sync bursts, market volatility, and public-endpoint abuse all show up at the worst possible moment.
- Design the recovery path before production cutover. Snapshots, rollback artifacts, and retained logs are part of the platform, not afterthoughts.
- Use real location and routing data when evaluating providers. Ask for concrete stock examples, actual port tiers by site, and the timeline for custom builds.
Buy for Failure, Not Just for Throughput

The best crypto hosting decision is rarely the one with the lowest monthly line item or the highest advertised core count. It is the one that matches the workload’s actual failure modes. For nodes and validators, that usually means safe signing, storage behavior, sync and recovery paths, and bandwidth headroom. For trading, it means distance, routing control, endpoint stability, and the ability to keep latency variance under control.
That is why “crypto hosting” should never be treated as one category. A validator cluster, an RPC layer, and a latency-sensitive trading stack may all run on servers, but they do not fail the same way. Buy around that reality, and the infra conversation gets more honest.
Dedicated servers for crypto workloads
Browse ready-to-order and custom dedicated servers for validators, RPC workloads, and low-latency trading across Melbicom’s global data centers.
Get expert support with your services
Blog
Bare Metal Server vs Cloud: Checklist for Performance, Compliance, and Cost
The old “bare metal vs cloud” argument was mostly about raw speed. That frame no longer holds. Published MLPerf Inference submissions on the same Dell PowerEdge XE9680 / 8x H200 platform show only low-single-digit differences between bare-metal and virtualized results on several throughput figures. The bigger differences now show up in tail latency, noisy-neighbor risk, auditability, and cost predictability.
That change tracks the market. Gartner forecast public cloud end-user spending at about $723.4 billion, Synergy Research Group estimated cloud infrastructure services revenue at $419 billion, and Flexera reported 29% wasted cloud spend alongside 58% usage of generative AI as a public cloud service. At this scale, picking the wrong substrate becomes an operating-model problem, not just a hosting preference.
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
|
How Bare Metal, Dedicated Servers, and Cloud Instances Differ in Practice
Use cloud instances when elasticity and managed-service adjacency matter most. Use a bare metal server when you need physical determinism plus automation. Use dedicated server abstraction when you want single-tenant hardware as a stable, long-lived substrate with predictable cost and provider support. The choice is less about “fast versus slow” than about variance, control, and operational ownership.
Definitions that survive contact with production
A cloud instance is compute behind an API. You choose a shape, launch quickly, and pair it with managed services, but usually with less visibility into placement and contention.
A modern bare metal server is single-tenant hardware delivered with cloud-like expectations: API-driven lifecycle, fast rebuilds, and fleet-style management. Tools such as OpenStack Ironic + Metal3 exist to make physical hosts behave more like declarative infra.
A dedicated server is also single-tenant hardware, but the operational intent is different. It is a durable node in a known location, rented for stability, support, predictable economics.
Bare metal server vs dedicated server: where the line actually is
The overlap is tenancy; the split is lifecycle. Bare metal is usually treated like part of a rebuildable fleet. Dedicated is usually treated like a stable substrate that you tune, keep, and plan around. “Cloud-like provisioning” on bare metal also does not mean instant by magic. It means automating the boot path and accepting more lifecycle responsibility.
When Bare Metal Is the Better Choice for Performance, Compliance, or Control
Bare metal is the better choice when performance debugging keeps pointing to placement, jitter, I/O contention, or specialized hardware paths. It can also simplify audit and residency conversations because tenancy boundaries are explicit. The value is not automatically higher average throughput; it is fewer hidden neighbors, fewer hidden schedulers, and clearer control over the machine itself.
Deterministic performance is about tail behavior
Performance-sensitive systems fail at P99, not at the median. Distance through fiber adds unavoidable delay before routing inefficiencies and queueing even enter the picture. Shared infrastructure adds another layer of uncertainty. That is why the strongest case for bare metal is often not headline throughput, but fewer surprises in the tail.
Noisy neighbors and hardware paths are the real differentiators
In a recent Kubernetes multi-tenant testbed study, researchers reported I/O-bound degradations of up to about 67% under combined noisy-neighbor stress. Even if your own environment never gets that bad, the structural risk is obvious. If your stack depends on stable cache behavior, known topology, predictable storage latency, or specialized NIC and accelerator paths, single-tenant hardware is easier to reason about. (arXiv)
Compliance and control often get simpler
Single-tenancy does not create compliance by itself, but it can make controls easier to explain. Gartner projected about $80 billion in sovereign cloud IaaS spending and described a shift of 20% of current workloads from global to local providers. That is a sign that locality, change control, and clearer boundaries are becoming design requirements.
What Automation + Operational Trade-Offs Come With Moving From VMs to Bare Metal
Moving from VMs to bare metal replaces clone-based convenience with hardware-aware operations. You gain determinism, but you also inherit the boot path, firmware lifecycle, BMC hardening, and spare-capacity planning. Teams that do this well automate provisioning early, treat host loss as normal, and move the noisiest or most control-sensitive services first.
Provisioning changes from “clone a VM” to “own the boot path”
On bare metal, provisioning becomes control plane to BMC to network boot or virtual media to OS image to configuration management. Ironic and Metal3 matter because they turn that sequence into an API-backed workflow instead of a rack-by-rack ritual.
Lifecycle, lead time, and BMC security become architecture concerns
Hardware is visible again: capacity planning, host replacement, firmware updates, and failure domains stop being somebody else’s abstraction. So does out-of-band management. NIST SP 800-193 and joint NSA/CISA guidance are clear that BMCs are highly privileged control planes and need separate hardening, segmentation, and patch discipline.
Migration friction is sometimes more expensive than compute
Leaving cloud is often less about CPU and more about data gravity, identity wiring, and the loss of VM-native conveniences. The UK Competition and Markets Authority has explicitly treated egress fees and related switching barriers as a competition problem. That makes data movement a first-class architecture cost.
Bare Metal Server Decision Checklist for Performance, Compliance, and Cost
Use the matrix below as a biasing tool, not a rigid rule. It is most useful when the real constraint is easy to name: variance, governance, hardware specificity, or cost shape.
| Decision Signal | Bias Toward | Why It Matters |
|---|---|---|
| Tail latency or jitter drives the SLO | Bare metal server or dedicated server | Physical isolation makes P99 tuning more predictable. |
| Shared I/O contention is the pain point | Bare metal server or dedicated server | Noisy neighbors can collapse disk or network behavior long before average CPU looks busy. |
| Audit, residency, or hardware-control requirements dominate | Bare metal server or dedicated server | Explicit single-tenancy and known hardware boundaries simplify evidence collection and change control. |
| You need known topology or specialized NIC/GPU behavior | Bare metal server or dedicated server | Repeatable hardware paths matter more than generic flexibility. |
| You want fleet-style hardware automation | Bare metal server | Ironic- and Metal3-style workflows fit rebuildable physical fleets. |
| You need fast burst capacity or managed-service adjacency | Cloud instances | Elasticity remains cloud’s clearest strength. |
| Your stack still depends on snapshots, quick clones, or live migration | Cloud instances, unless replaced at the app layer | VM-native workflows need redesign before metal feels natural. |
| Steady demand and volatile egress bills dominate the economics | Dedicated server | Flat monthly pricing and reserved port capacity make baseline cost easier to plan. |
A quick reality check on performance
The common myth is that bare metal wins mainly by avoiding the hypervisor. The more useful lesson from MLPerf Inference is narrower: average compute overhead can be modest, while placement and contention still dominate the user-visible outcome. On the same Dell PowerEdge XE9680 / 8x H200 platform, several published virtualized results sit within a few percentage points of the bare-metal submissions.
Migration Notes from VM-First Environments
- Identify the actual bottleneck. Move the workload constrained by jitter, storage latency, hardware visibility, or compliance pressure, not the one that is easiest politically.
- Start where single-tenancy buys down variance. Datastores, gateways, schedulers, and ingestion layers are common first moves.
- Keep adjacent interfaces stable. Melbicom’s S3 storage and CDN can let teams move sensitive compute first without rebuilding every data and delivery pattern at once.
- Treat network control as part of the design. Melbicom’s dedicated servers pair single-tenant hardware with API and KVM access, and Melbicom’s BGP sessions — including BYOIP — are available from all locations and free on dedicated servers when routing behavior is part of the product.
Key Takeaways for the Next Architecture Review
- Measure P95/P99, jitter, and storage variance before changing platforms. Median throughput alone is not a decision framework.
- Move the workloads that suffer from hidden contention, hardware opacity, or audit friction first; leave bursty, disposable, or service-adjacent pieces in cloud until the application layer is ready.
- Price migration as a systems change, not a server swap. Data movement, identity rewiring, and the loss of snapshot-heavy workflows can outweigh any compute savings.
- Do not scale bare metal operationally until provisioning, firmware policy, and BMC isolation are standardized. Otherwise every performance gain turns into day-two debt.
Conclusion: Choose for Variance, Control, and Operating Model
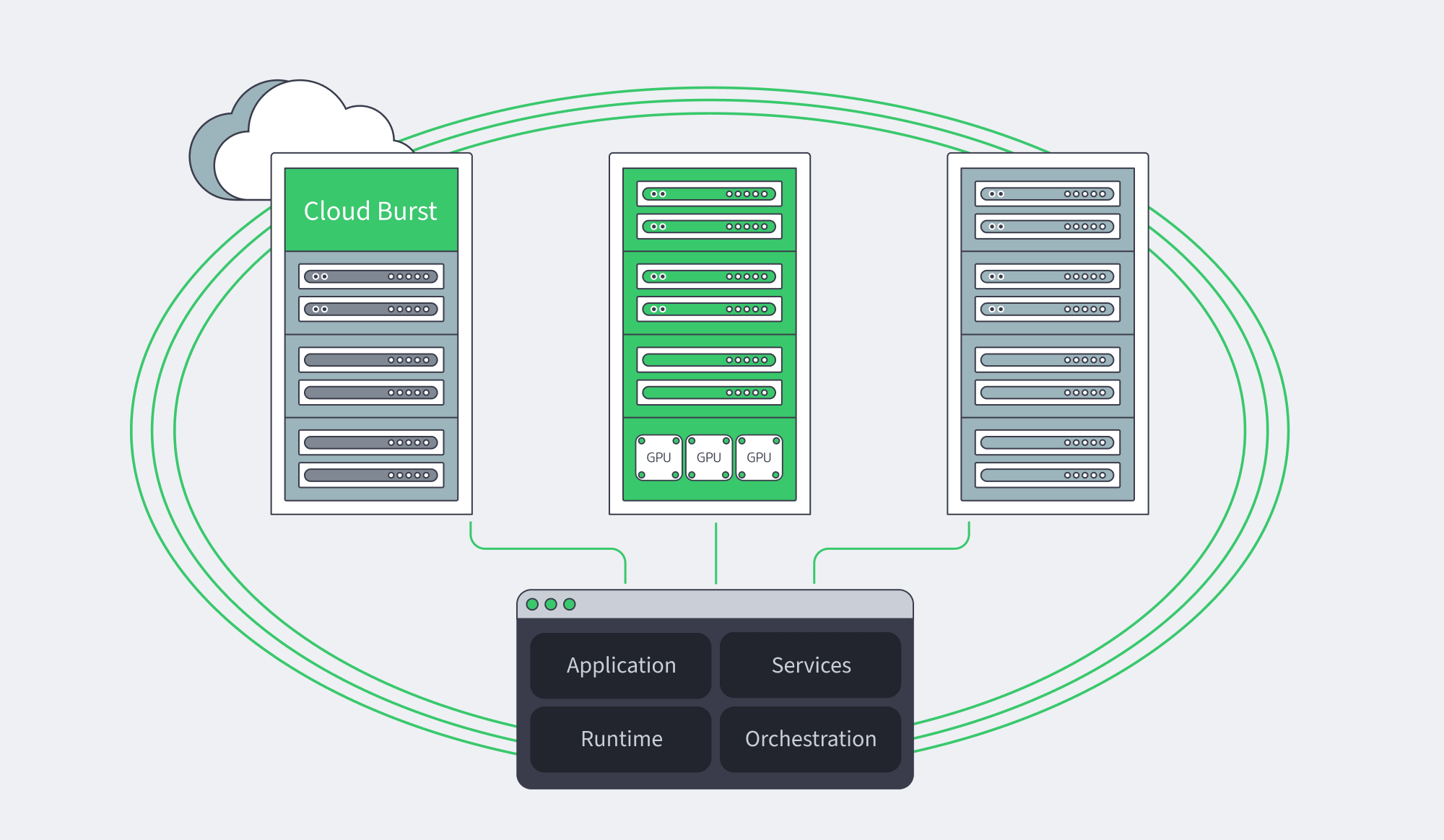
The best answer is rarely “cloud everywhere” or “metal everywhere.” It is usually a split: cloud where elasticity and managed services create real leverage, dedicated servers where single-tenant stability and predictable monthly cost matter most, and bare metal where hardware-level determinism and automation justify the extra operational ownership.
That is also why this comparison keeps returning. Performance-sensitive platforms do not need a slogan about bare metal being universally faster. They need a practical way to decide when variance, compliance, hardware control, and migration economics are important enough to justify moving down the abstraction ladder.
Explore dedicated servers
Compare single-tenant server options for performance-sensitive workloads that need predictable monthly cost, hardware control, and global deployment.