Blog

Navigating Adult VR Hosting Solutions and Why Choose Dedicated Servers
Immersive adult experiences—high-resolution 180°/360° VR scenes, live multi-camera shoots, and interactive adult gaming—are now mainstream engineering problems. What used to be a single HLS ladder is becoming a GPU-accelerated, edge-anchored, multi-protocol pipeline that must hold quality under extreme concurrency while keeping motion-to-photon latency imperceptible inside a headset. Below, we zero in on the infrastructure demands behind these formats and how dedicated servers, paired with an edge CDN and modern codecs, provide the determinism, bandwidth, and compute density needed to deliver them at scale.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
What Makes Immersive Adult Content So Hard to Host Well?
Throughput per viewer is an order of magnitude higher. An 8K 360° VR stream generally sits in the 60–100 Mbps range without viewport optimization or tiling; even well-engineered tiled streaming aims to keep decode within similar envelopes on the device. That’s 10× the bitrates of typical 1080p OTT ladders and still far above most 4K flatscreen profiles. Multiply by thousands of concurrent viewers at release and your origins must sustain multi-terabit bursts without jitter.
Latency budgets tighten dramatically. In VR, “good enough” isn’t seconds—it’s tens of milliseconds. Motion-to-photon (MTP) latency targets around ≤ 20 ms are widely cited in Cloud-VR and academic measurements; commercial headsets measured at 21–42 ms at movement onset require aggressive prediction to keep perceived latency inside comfort thresholds. The network portion of that budget must be shaved via regional ingest and edge-proximate delivery or interaction will feel wrong.
Protocols must match the experience. At one end, WebRTC reliably delivers sub-500 ms glass-to-glass latency for interactivity and live VR cam shows; at the other, Low-Latency HLS (LL-HLS) achieves ~2–5 s (sometimes lower with aggressive tuning) while preserving HTTP scalability and CDN friendliness. A production pipeline for adult VR rarely picks one protocol—it mixes them by workload.
Compute shifts from “nice to have” to “hard requirement.” Real-time HEVC/AV1 encoding for stereoscopic 4K and 8K ladders, AI-assisted upscaling/denoising, multi-angle compositing, and interactive state synchronization all compete for cycles. Hardware encoders (NVIDIA NVENC) now support AV1 and HEVC end-to-end—critical for meeting bitrate targets without sacrificing quality—while modern GPUs add split-frame and tiling modes to lift 8K throughput. Pair that with NVMe storage to avoid I/O stalls when segmenting large VR assets.
Global proximity matters. Moving the session logic and media edge close to the viewer is the only way to keep RTT and jitter inside headset-friendly limits. That means multi-origin deployment across continents and a CDN footprint dense enough to keep last-mile hops short during peaks. Melbicom’s footprint—21 data-center locations, per-server ports up to 200 Gbps, and a CDN with 55+ PoPs across 36 countries—was designed for exactly this pattern: put origins near exchanges, fan out cached segments globally, and place ultra-low-latency nodes where interactivity demands WebRTC.
Brief context: why the old stack fails
Classic OTT stacks assumed seconds of buffer, a handful of renditions, and region-limited audiences. They struggle when 8K stereoscopic assets must be transcoded in real time, and when control channels (camera switching, avatar state, haptic triggers) need sub-second round-trip. The modern answer is not “one giant cloud region,” but single-tenant dedicated servers tuned for throughput, paired with an edge CDN and regionally distributed real-time nodes. (Think: origins in Amsterdam/Ashburn/Singapore, WebRTC SFUs in additional metros, CDN caching everywhere your users are.)
Which Adult VR Hosting Solutions Actually Scale Globally?

1) GPU-optimized dedicated origins for encode, packaging, and authorization
VR ladders drive extreme parallel encodes. Dedicated servers with GPUs (AV1/HEVC via NVENC) cut encoder latency and shrink bitrates at constant quality, improving delivery economics while preserving clarity in head-locked views. NVENC’s current generations support AV1 8/10-bit and HEVC 8/10-bit pipelines; AV1 typically saves ~40% bitrate vs H.264 at comparable quality—meaning the network carries less data per user for the same perceived sharpness. On CPU-heavy workflows (e.g., volumetric preprocessing, AI stabilization), the same box can host CUDA kernels beside encoders to avoid PCIe round-trips. We at Melbicom provision GPU dedicated servers with high-speed NICs so your ingest/encode nodes aren’t starved by the network.
2) Edge CDN for scale; edge compute for interactivity
On-demand VR scenes cache efficiently. Use LL-HLS over a 55+ PoP CDN to keep last-mile latency low while origins focus on cache fill and authorization. For live VR cams and interactive adult gaming hosting, place WebRTC SFUs or micro-services (state sync, avatar presence, telemetry) on dedicated edge nodes. Operators routinely target < 500 ms for two-way interactions and 2–5 s for broadcast-style events; choosing per-workload protocols—and placing servers appropriately—is the difference between “immersive” and “makes you queasy.” Melbicom’s CDN and regional data centers let you anchor compute in the right metros and fan out assets globally.
3) High-bandwidth NICs and deterministic networking
VR peaks aren’t polite. Origins must burst 100 GbE (and above) without head-of-line blocking. Melbicom equips servers with 1–200 Gbps physical ports and ties them into a backbone engineered for high aggregate throughput, so your egress ceiling is the NIC—not the provider’s fabric. Deterministic NICs also reduce jitter into your encoder/packager chain, improving CTS/DTS alignment and reducing player drift.
4) NVMe for asset prep; S3-compatible object storage for libraries
VR masters are enormous. NVMe SSDs keep packaging/transmux and thumbnail/extract steps from blocking on I/O, while S3-compatible storage holds the long tail economically. Melbicom’s S3-compatible storage supports 1–500 TB per tenant/bucket with free ingress, making it natural to stage new scenes from encode nodes to durable storage and let the CDN fetch on demand.
5) Multi-origin layouts (don’t centralize your failure domain)
Spread origins across at least two regions per primary market. That keeps origin RTT short for the CDN, raises cache hit ratios at the edge, and avoids a single encoder pool becoming your global bottleneck when a new interactive release spikes. Melbicom operates in 21 global locations; we routinely place origins at major IX hubs (e.g., AMS-IX, DE-CIX, LINX) so your CDN “first mile” stays short and predictable.
Example workload mapping (adult VR focus)
| Workload | What it demands | What to deploy |
|---|---|---|
| 8K/4K stereoscopic VR VOD | 60–100 Mbps per viewer; large objects; global reach | GPU-equipped dedicated origins for AV1/HEVC; LL-HLS packaging; CDN with 55+ PoPs; NVMe scratch + S3 library. |
| Live VR cam & Q&A | Sub-500 ms interaction; regional ingest; rapid scale-up | WebRTC ingest/SFU on edge dedicated servers; 100 GbE NICs for fan-out; multi-origin failover. |
| Interactive adult gaming hosting (VR worlds/minigames) | 20–50 ms RTT targets; state sync; bursty peaks | Regional game/logic servers; proximity-aware routing; CDN for static assets; telemetry backhaul to origins. |
Architecture building blocks that work in production
- Encode where you ingest. Use regionally distributed GPU-optimized dedicated servers to transcode ladders near cameras and contributors; ship packaged outputs to nearby origins/CDN to minimize first-mile.
- Pick protocols by interaction level. WebRTC for two-way/live control; LL-HLS for scale when chat latency is tolerable. Keep the player’s buffer discipline separate from the control channel.
- Keep the network fat and simple. Favor 1–200 Gbps physical NICs with straightforward routing from origin to CDN. Jitter kills more VR QoE than raw throughput deficits.
- Use NVMe for hot paths; S3 for the library. Stage transcodes on NVMe, publish to S3-compatible storage, and let the CDN fill. This keeps origins autoscalable.
- Exploit AV1 where devices support it. AV1 saves ~40% bitrate at similar quality versus H.264; fall back to HEVC/H.264 as needed by headset/browser.
Why dedicated (single-tenant) servers instead of “just cloud VMs”?
VR delivery is determinism-sensitive. You want guaranteed NIC bandwidth, exclusive CPU caches, and unshared NVMe queues when ladders spike. Dedicated servers give you root-level control to tune queues, congestion control, and driver stacks around real-time behaviors. Melbicom’s dedicated platform offers 1,000+ ready-to-go configurations, ports up to 200 Gbps, and 24/7 support, so you can size machines to the role—encode, origin, edge compute—without noisy-neighbor effects or egress metering surprises. Pair those with 55+ CDN locations so your viewers hit the nearest edge by default.
Reference pipeline
- Ingest/Encode (GPU) → Packager (per-workload: LL-HLS segments + WebRTC tracks) → Regional Origins (Ashburn, Amsterdam, Singapore, etc.) → CDN (55+ PoPs) for VOD/live cache → Edge WebRTC SFUs for sub-second interactions → Players & headsets.
- Storage: NVMe scratch on encode nodes; S3-compatible object storage for masters and long-tail renditions.
Implementation notes you can apply tomorrow
- Viewport-aware or tiled streaming for 8K 360° keeps device decode and network budgets sane. Use AV1 when the device supports it; HEVC otherwise.
- Hybrid live: LL-HLS for the “watch” cohort, parallel WebRTC for a smaller “interact” cohort (tip, vote, switch camera) sharing the same production feed.
- Edge selection: Direct interactive users to the nearest WebRTC SFU; leave VOD to CDN affinity. Melbicom’s multi-region footprint simplifies this split-brain routing.
How Should You Move from Pilot to Production without Re-Architecting Twice?
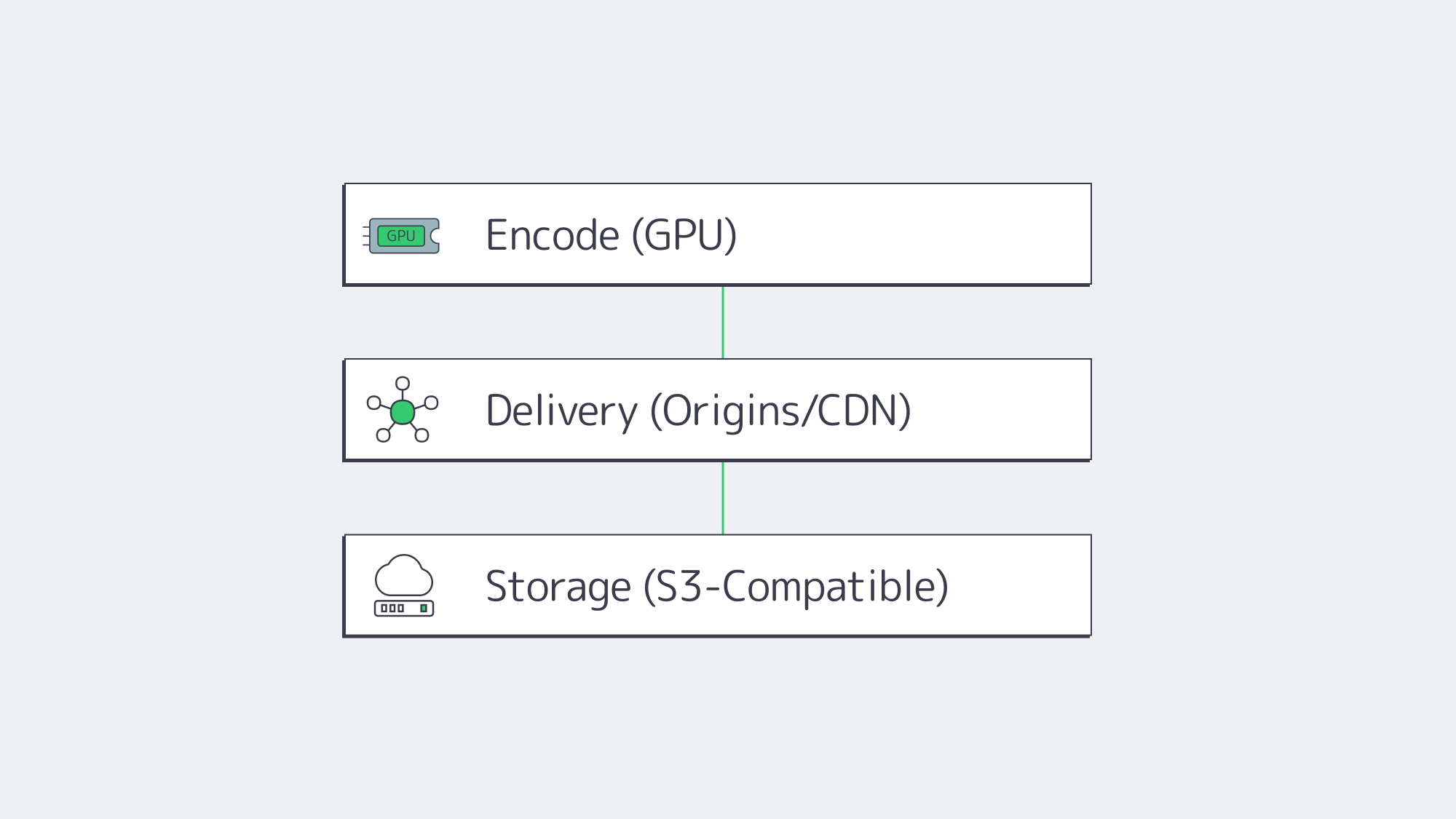
Start by right-sizing the three planes of your system:
- Encode plane: Place GPU encoders in the same metros where you gather content or where creators connect. Prefer AV1 when headsets/browsers decode it; keep HEVC ladders for fallback. Use NVMe for segmenting and thumbnails to maintain deterministic encode-to-publish timing.
- Delivery plane: Publish LL-HLS ladders to local origins (2 per market minimum), then cache via a CDN for scale; route interactive cohorts to edge WebRTC. This keeps your broadcast audience happy while preserving the < 500 ms paths required for presence.
- Storage plane: Keep your library on S3-compatible storage (multi-TB to hundreds of TB per tenant), with lifecycle rules to tier older renditions; serve “first frames” from NVMe caches on origins to minimize startup delay.
The outcome is a pipeline that de-risks growth: you can add origins by region, add encoders by ladder, and drop in new edge compute nodes as interactive formats evolve—without replacing your core.
Launch Your VR Platform
Get servers, storage, and a global CDN deployed within hours—purpose-built for bandwidth-intensive 180°/360° adult VR streaming.