Blog

Implementing HA Storage on Dedicated Servers for Zero Downtime
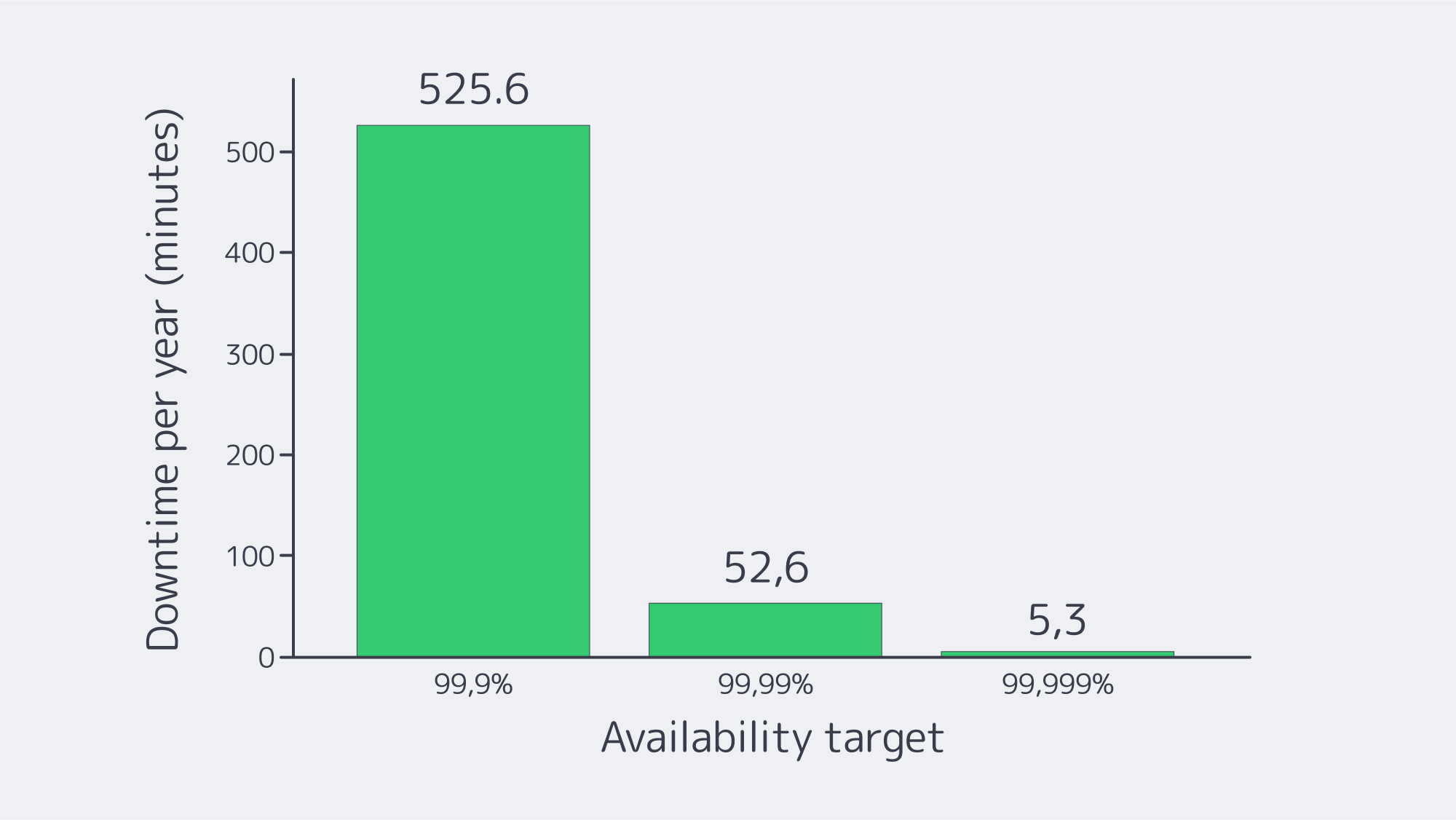
Downtime must be considered more than an inconvenience; it is an existential risk. The average cost of an outage is approximately $9,000/minute. In this modern technological era, many companies are looking for 99.98% availability for their major systems. The path to those numbers is not a rigid SAN or manual runbooks; it is a cohesive blueprint that treats failure as routine and plans for it.
This article distills the blueprint for HA dedicated storage on dedicated servers, featuring RAID 10 for local resilience, synchronous replication across nodes, quorum-based clustering to prevent split-brain failure, and automated failover orchestration to ensure instant and deterministic recovery. We will also cover GlusterFS and DRBD-based mirroring for zero-downtime updates, and briefly contrast legacy single-controller SANs to reinforce the case for why the distributed model has won out.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Blueprint: HA Dedicated Storage that Assumes Failure
- Local protection on each server (RAID 10).
- Synchronous replication across peers (no data-loss failover).
- Quorum + Witness to arbitrate (leadership) & avoid split-brain.
- Automated failover to switch service endpoints with no human intervention.
This “defense in depth” transforms disk, server, or network failures into non-events while preserving performance.
RAID 10: Local Redundancy without the Rebuild Penalty

RAID 10 (mirrors striped across pairs) has two benefits that are vital to HA – rapid rebuilds and low write latency. When a disk fails, the array does not use parity math; instead, it mirrors, so rebuilds are faster and risk windows are shorter. That’s important in clusters, because you never want a node degraded for long in production. RAID 10 also maintains throughput and predictable latency under load, which prevents the synchronous replication pipeline from stalling. On modern dedicated servers, combining RAID 10 with enterprise SSDs or NVMe drives provides sufficient IOPS headroom for replication and client I/O to coexist without contention.
Synchronous Replication: Zero-Data-Loss Failover Design
RAID is a protection for the node, and replication is a protection of the service. With synchronous replication, a write is acknowledged only when it lands on both nodes, resulting in an RPO of zero. In a two-node design, if a node fails (Node A), Node B has a bit-for-bit current copy of the data and can take over immediately.
This requires a high-speed deterministic interconnect between nodes – dedicated 10/25/40 GbE or faster, preferably isolated from client traffic. In designs that demand strict separation, Melbicom can provide the use of VLAN-segregated links for replication and heartbeat, ensuring storage traffic remains clean and predictable. Low, consistent latency avoids write stalls; plenty of bandwidth absorbs bursts. Melbicom’s dedicated servers can be provisioned with high-throughput links (up to 200 Gbps per server, where available), which provide the headroom that replication traffic needs while applications run at full speed. Keep cabling, NICs, and switch paths symmetric across nodes to prevent asymmetric latency that can pass itself off as “flaky storage.”
Two proven approaches:
- Block-level mirroring (DRBD): Mirroring disk blocks in lockstep, in essence, a networked implementation of a form of RAID1. Commonly deployed in an active-passive configuration: one node mounts the volume, the peer tracks every write, and is promotable in the event of failover.
- Replicated file storage (GlusterFS): Files are replicated across nodes, and any node can serve files from any replica (active-active). Clients continue through surviving nodes in outages; self-healing processes fill gaps on return of a node.
Two-node + witness (sync replication)
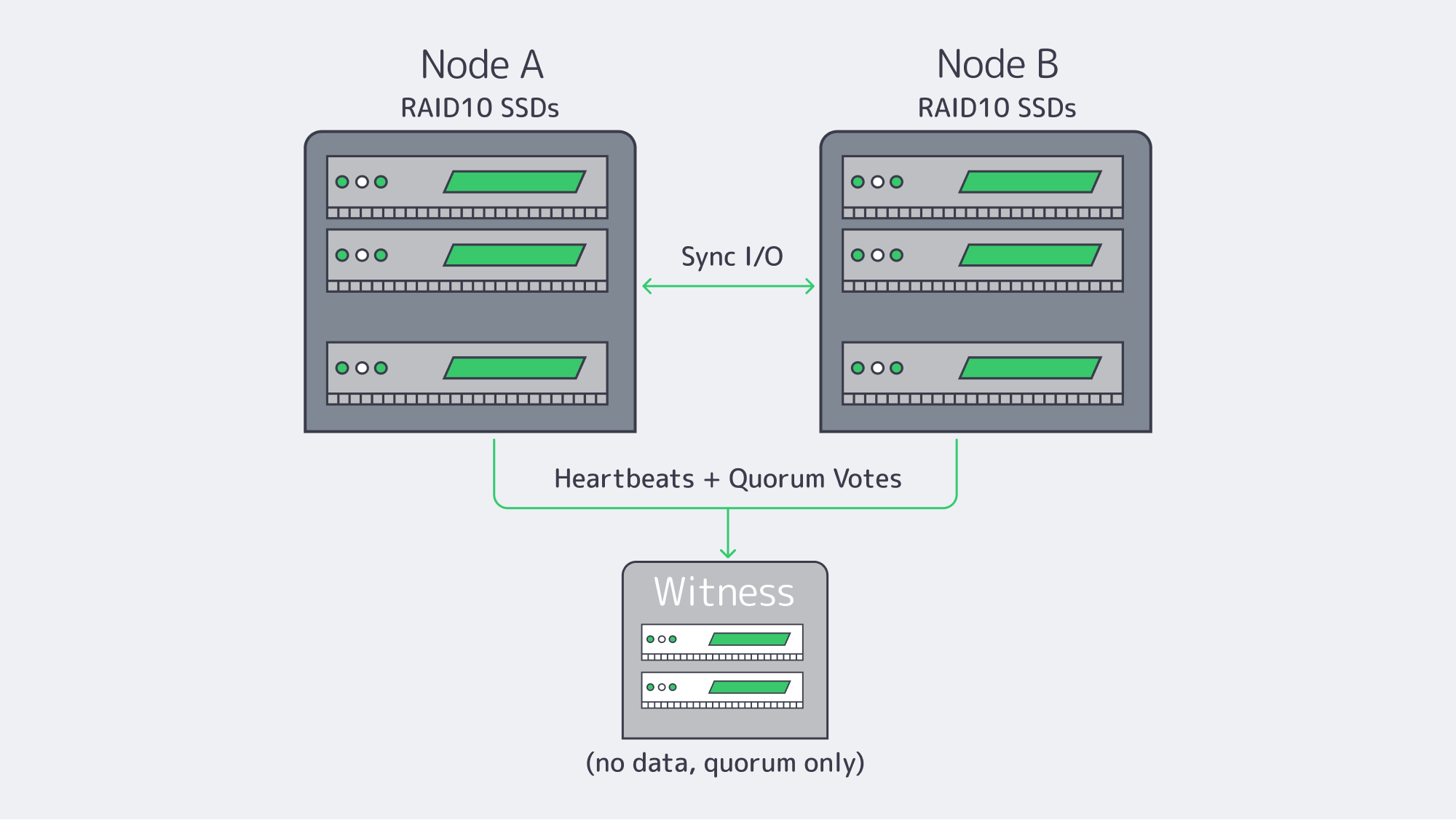
Quorum, Witness Placement, and Split-Brain Prevention Essentials
Nothing torpedoes an HA storage system quicker than split-brain – two nodes accepting writes independently after a partition. The antidote is quorum; actions that could change the data require a majority of votes. In a two-node storage cluster, you should add a witness (qdevice/arbiter) so there are three votes. If Node A and Node B lose contact, the side still in contact with the witness remains authoritative. The other stands down and is fenced if required. This maintains one linear history of writes.
Placement definitely matters a lot. Place the witness in a separate fault domain, ideally, a different rack/room or even a different Melbicom site, so that the loss of one location doesn’t also take out the tiebreaker. The witness is light-weight (no application data), so a tiny VM is all that is needed. For N>=3 data nodes, make sure there is an odd number of votes or add an external quorum device.
Fencing (STONITH) is the second part of the safety net. If a node loses quorum or is unresponsive, the cluster must power off or isolate it before promoting a peer. This removes “zombie” writes and ensures that when the node returns, it returns as a clean follower and is ready to resync. For this reason, use IPMI or an out-of-band API independent of the data network to ensure fences succeed even if there is a network incident.
Automated Failover Orchestration and Consistent State Recovery
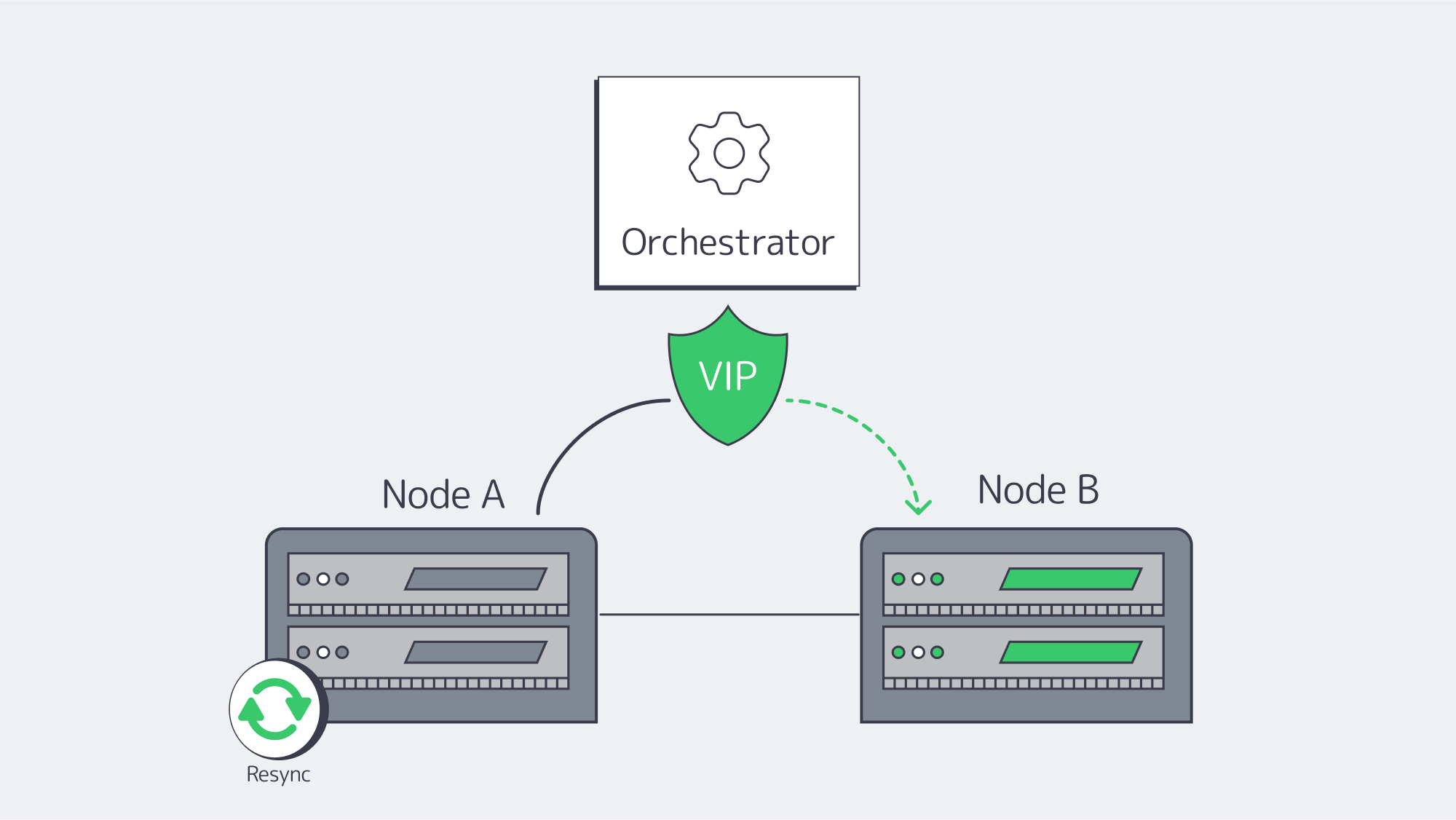
High availability doesn’t work if a human has to step in. Automated orchestration identifies failures and migrates service identities (virtual IPs/exports/LUNs) to healthy nodes within seconds. On Linux, Pacemaker + Corosync is the canonical stack: Corosync is responsible for membership/heartbeat; Pacemaker handles resources, ordering and constraints.
A common DRBD+filesystem+export failover workflow:
- Fence the failed primary.
- Promote DRBD on the secondary to Primary.
- Mount the filesystem and start the export service.
- Assign a service IP (or flip DNS/LB target).
For consistent state recovery, whenever nodes are returning, they cannot ever serve stale data. Depend on the built-in journals and resyncs of the storage layer:
- DRBD does an incremental resync of changed blocks.
- GlusterFS self-heals to reconcile file replicas.
Keep orchestration conservative: wait for “UpToDate” replication states before re-admitting a node, and codify stringent resource-ordering to prevent timing races. Finally, test: simulate power pull, NIC failures, split links, until metrics (failover time, resync duration) are predictable.
Distributed File Systems vs. DRBD Mirroring for Zero-Downtime Updates
Both designs allow rolling maintenance and upgrades without any downtime. Select based on the access model, concurrency, and operational style.
| Technology | Best fit | Notes |
|---|---|---|
| DRBD + FS + Export | Block-level consistency for databases or single-writer filesystems, deterministic failover | Simple active-passive; pair with Pacemaker; add a cluster filesystem only if multi-writer is unavoidable (adds overhead) |
| GlusterFS (replicated) | Shared file namespace with active-active access; NFS/SMB/POSIX clients | Rolling upgrades node-by-node; automatic self-heal; Plan for a small consistency window during heal; tune for small-file or large-file patterns. |
| Ceph (optional) | Scale-out object/block/file; many nodes; multi-tenant | Operationally richer, with more moving parts; strongest in cases where you need elastic capacity and mixed protocols. |
Zero downtime updates applied
- Using DRBD, deliberately migrate primacy: intentionally fail over cleanly to the secondary, patch and reboot the primary, resync and (optionally) fail back. Client I/O notices a short pause during the switch; retries are used to mask it at the app layer.
- With GlusterFS, upgrade one node at a time. The volume is kept online by peers. After nodes return, they check for completion of the healing process before proceeding.
Legacy single-controller SANs struggled here: the box itself had to be upgraded and often required a maintenance window. Distributed HA turns that model on its head; service remains up while parts change.
Operational Checklist
- Homogeneous builds: drives, NICs, and controllers are identical across nodes.
- Dedicated replication fabric: min of 10GbE, isolated from client traffic, symmetric paths, consider dual links.
- Quorum discipline: odd votes; external witness in a separate fault domain; enforce STONITH fencing
- Health gates: only re-admit nodes after full resync/heal; degrade health if the file system is not in good condition (e.g., if the data on a LUN is unreadable) or replication is not running smoothly.
- Fire-drills: quarterly failover drills for power, NIC, and process level faults; Document RTO/RPO.
- Security & compliance: isolate cluster traffic; encrypt where appropriate; keep immutable backups to meet retention mandates; consider S3-compatible offsite copies, cold copies via SFTP backup.
- Geo strategy: keep synchronous pairs metro-close; async replication for regional DR; witness out-of-band placement.
Conclusion: Bringing the Parts Together

Zero-downtime storage isn’t a single technology; it’s a system that anticipates component failures and makes continuity routine. The pragmatic blueprint is fairly clear: RAID 10 for on-box resilience, synchronous replication for node loss, quorum, and a well-placed witness for preventing split-brain, and automated failover to keep humans off the critical path. Add GlusterFS or DRBD-based mirroring to enable rolling updates without maintenance windows and ensure consistent-state recovery, allowing repaired nodes to rejoin safely. The payoff is measured in avoided losses (think $9,000 a minute) and in the quiet confidence of systems that simply don’t blink.
If you are planning a refresh, start small: two identical servers, a dedicated replication fabric, a third witness, and a clear runbook for failover tests. Expand from there as needs expand. The architecture has a nice scale, and adding any node to the system decreases the likelihood of a single fault becoming an incident.
Launch your HA cluster
Deploy dedicated servers with high-availability storage engineered for zero downtime.