Blog

Why Production dApps Fail in the RPC Layer, Not the Chain
Consensus rarely fails first. A chain can keep producing blocks while an app appears down because its RPC tier is overloaded, rate-limited, privacy-leaky, or inconsistent. Users hit the endpoint, queue, and indexer before consensus failure, which makes RPC design and observability the real uptime story.
An NDSS study showed the RPC layer is materially less decentralized than the peer-to-peer network and that abusing read-only simulation can raise latency by 2.1x to roughly 50x; at a few hundred requests per second, the same pattern slowed block sync by 91%. Separate work reported more than 95% deanonymization success against normal RPC users, and newer research found previously unknown context-dependent RPC bugs across major clients. Add API attack volumes that reached 258 per day, and the lesson is simple: production dApps fail in the data plane first.
Best Servers for Web3— 1,300+ ready-to-go servers — Custom configs in 3–5 days — 21 global Tier IV & III data centers |
 |
What Production Blockchain Infrastructure Includes beyond RPC Endpoints
Production blockchain infrastructure is not a node plus an endpoint. It is a stack: dedicated RPC capacity, method-aware admission control, an indexing tier for historical reads, caches for safe read traffic and artifact delivery, telemetry for tail latency, and key handling that does not depend on a public endpoint staying healthy.
Crypto infrastructure layer for RPC reliability
Reliable RPC starts with deliberate redundancy: multiple nodes, ideally multiple client implementations, and separate pools for reads, writes, and expensive methods. N-version research shows client failures are often asymmetric. The practical rule is to budget the dangerous methods. eth_call, tracing, and wide log scans need gas caps, range limits, and hard timeouts so one pathological request cannot poison the queue.
Dedicated endpoints and stable routing
Public endpoints are fine for development. They are poor production infrastructure because you do not control noisy neighbors, burst admission, or method restrictions. Dedicated endpoints put the bottleneck back into your own capacity plan. Stable endpoint identity matters once partners or internal systems whitelist your RPC. Melbicom’s Web3 hosting is built around single-tenant servers for RPC nodes, indexers, and backends, while Melbicom’s BGP sessions add BYOIP and route control.
Indexing strategy instead of abusing eth_getLogs
A production node is not an analytics database. The web3.py docs note that eth_getLogs paginates blocks, not events, and clients often end up shrinking windows and retrying. Geth issue reports show the same timeout pattern on self-run nodes. If the product depends on search, history, or entity discovery, build an indexer.
- Canonical ingestion should pull only the data you need: blocks, receipts, traces, logs.
- Materialization should be reorg-aware, commit derived records after an explicit horizon.
- Query stores should match the product: address-centric, contract-centric, time-series, or graph-like.
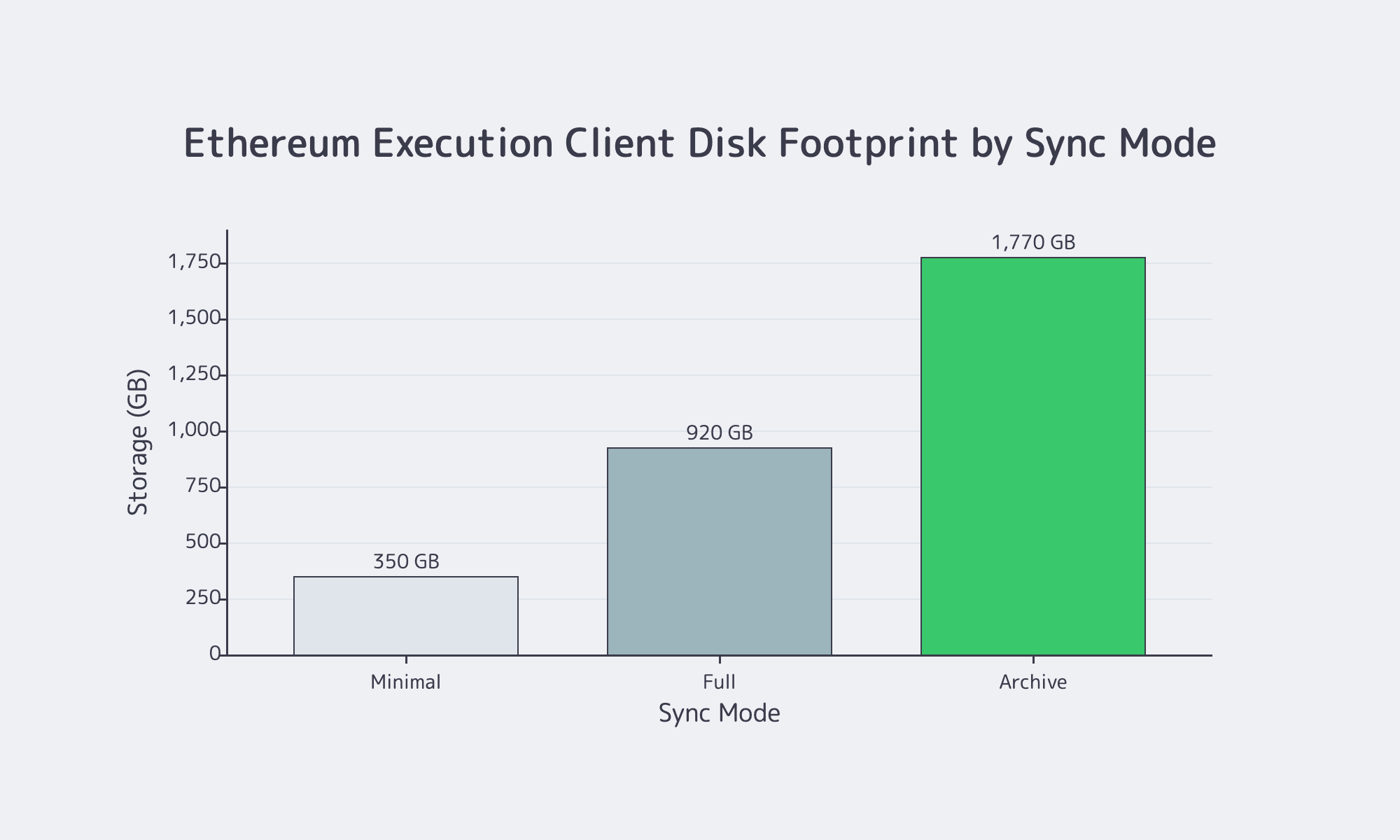
Storage: archive data is a design constraint
Self-hosting is “operate a database that only gets larger.” Current Ethereum mainnet storage is roughly 350 GB for minimal, 920 GB for full, and 1.77 TB for archive—before adding a consensus client, index database, metrics retention, or snapshots. That is why indexing is architecture, not optimization.
Observability, key management, and rate limiting
If RPC is a product surface, it needs product-grade telemetry. OpenTelemetry provides the right model: metrics, traces, and logs tied to the same request path. For blockchain operations, that means method-level latency, sync lag, queue depth, and submission success. NIST guidance remains the baseline for key isolation and rotation. OWASP now treats unrestricted resource consumption as a top API risk, and DDoS attacks have already reached 31.4 Tbps.
What to Choose: Public RPC, Managed RPC, Dedicated Nodes, and Self-Hosting
Choose by failure ownership, not by per-request price. The important variables are burst tolerance, method coverage, historical depth, operational control, and who gets paged when p99 latency spikes. Public endpoints minimize setup; self-hosting maximizes control; dedicated nodes are the middle ground where capacity planning becomes predictable.
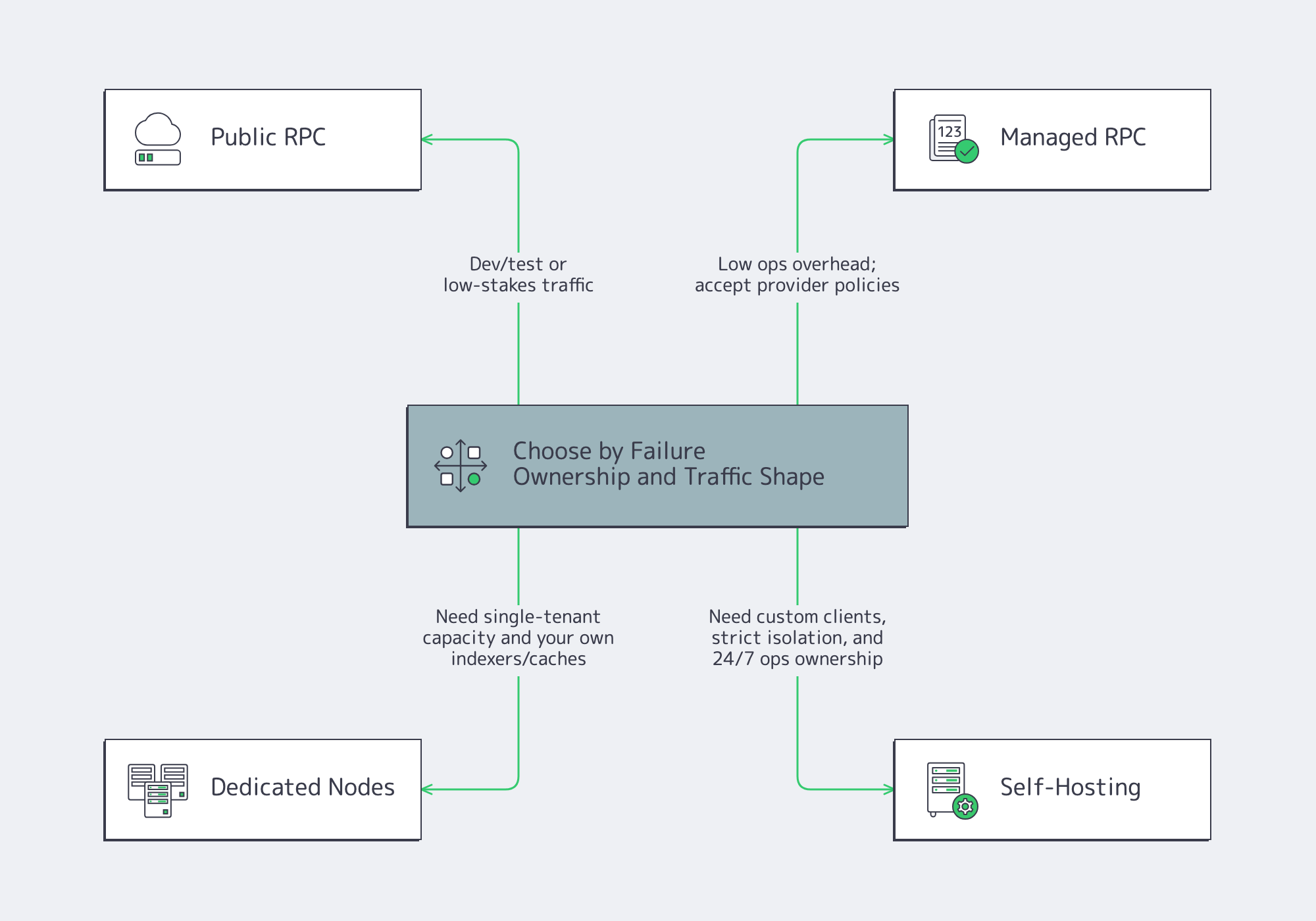
Public endpoints
Use public endpoints for development, testing, and low-stakes traffic. They are easy to adopt, but they usually come with opaque rate limits, uneven method coverage, and little control over overload behavior.
Managed RPC
Managed RPC removes the work of running nodes. The tradeoff is policy inheritance: timeout budgets, archival depth, burst caps, and method restrictions are the provider’s call. On fast chains, that matters. One Solana infrastructure checklist notes that stake-weighted QoS can reserve 80% of leader connections for staked nodes, so network position can matter more than simply buying a higher plan.
Dedicated nodes
Dedicated nodes are where blockchain infrastructure starts behaving like infrastructure. Single-tenant capacity removes the worst noisy-neighbor effects, makes performance budgets easier to reason about, and lets teams run their own indexers and caches against predictable compute. Melbicom fits this model well, with a ready-to-go catalog that spans 1,300+ location-specific server configurations and custom builds in 3–5 business days.
Self-hosting
Self-hosting makes sense when you need control that cannot be rented away.
- Strict data isolation requirements.
- Non-standard client or tracing configurations.
- Custom admission control and abuse defenses.
- A real 24/7 incident response model.
It is a poor choice when the plan is basically, “We can probably maintain it.”
Indexing Strategy for Blockchain Infrastructure w/o Overloading Endpoints
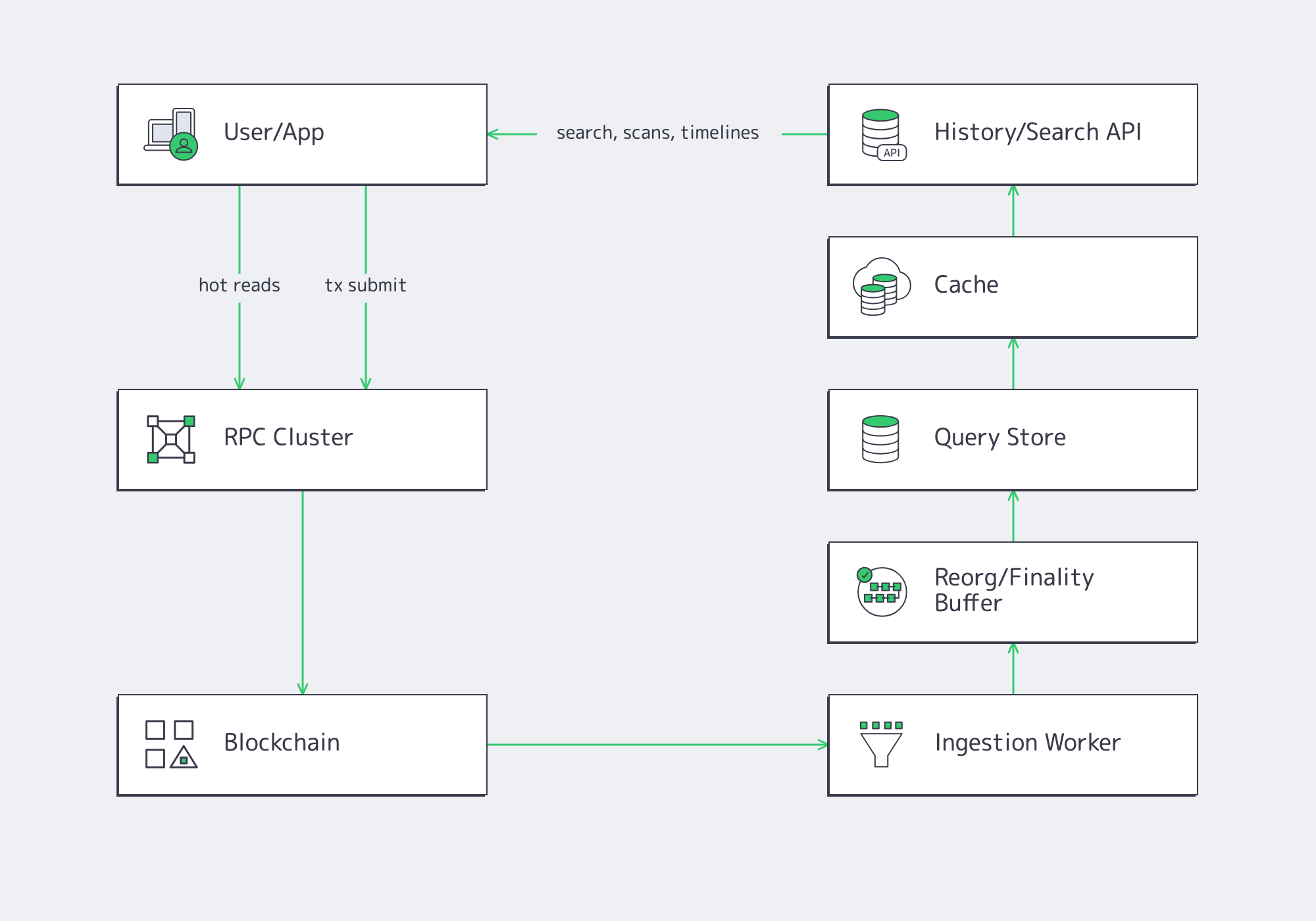
Use RPC for current state and transaction submission; use an indexer for history, discovery, portfolio views, and replayable analytics. Once a product depends on long-range log queries or search-style reads, the node should feed a pipeline—not answer every historical question directly.
Designing the data plane
A clean production split separates reads into three classes:
- Hot-path reads for balances, quotes, and user actions.
- Integrity-critical reads for simulation and preflight.
- History and discovery reads for scans, search, and long timelines.
The third class is where JSON-RPC becomes fragile and expensive. Design the data plane around that fact instead of learning it at peak traffic.
Reorgs, finality horizons, and “when is data real?”
Indexers that ignore reorgs will eventually publish the wrong answer. Near the chain tip, “confirmed” is not the same as “safe enough to materialize forever.” Production pipelines usually need two horizons:
- A fast-but-revisable horizon for immediate UX.
- A safer horizon for accounting, reconciliation, and exports.
The exact block count varies by chain/workload. What matters is making the policy explicit.
Snapshots and artifact pipelines
Fast recovery depends on artifacts, not optimism.
- Periodic snapshots of the index store.
- Client-compatible execution and consensus snapshots.
- Rollback artifacts and replay logs for incident recovery.
This is why S3 compatibility keeps showing up in modern crypto infrastructure. Snapshot tooling and restore jobs already assume that API.
Which MSA, Latency, and Data-Retention Questions Matter When Evaluating Blockchain Infrastructure Providers
Do not evaluate a provider by uptime language alone. The questions that matter in production map directly to real failure modes: overload, tail latency, method restrictions, historical depth, and what evidence you will get when something breaks. If the answers are vague, the risk has simply moved off the invoice and into your pager rotation.
| Evaluation question | What to look for | Why it matters |
|---|---|---|
| What does the MSA actually cover? | Scope by region or service, exclusions, measurement method, and incident communication. | “Uptime” claims often miss partial degradation, timeouts, and method-level failures. |
| Where are the lowest-latency regions? | Region list, routing model, peering posture, and jitter under load. | Geography helps, but routing and congestion usually decide p95 and p99. |
| What are burst limits and overload behaviors? | Explicit per-key or per-IP limits, backpressure rules, and whether overload fails with clear errors or silent timeouts. | Graceful degradation is engineered; meltdowns happen by default. |
| What is the data-retention model? | Pruned vs. full vs. archive support, historical depth, and request-log retention. | History-dependent features fail quietly when retention assumptions are wrong. |
| How do observability and debugging work? | Request logs, metrics, trace correlation, and access to incident evidence. | Without telemetry, outages turn into guesswork. |
A Minimal Production Stack, Wired for Dedicated Servers

A minimal production stack has three planes. The control plane owns endpoint identity, routing, admission control, and configuration. The execution plane owns RPC nodes and transaction submission paths. The data plane owns indexing, query stores, snapshots, and cache distribution. That architecture turns a fragile endpoint into an operable system.
Operational recommendations:
- Keep the hot path small: use RPC for current state and submission, and move search, scans, and long timelines into an indexer before JSON-RPC becomes your query engine.
- Budget pathological methods separately from average traffic: cap
eth_call, tracing, and wide log windows with explicit timeouts, payload limits, and range guards. - Plan storage together with recovery: archive footprint, index growth, snapshot cadence, and restore time should be sized as one system, not four separate problems.
- Choose the deployment model by pager ownership: if your team cannot absorb 24/7 node, indexer, and networking incidents, the cheapest option is usually the most expensive one in production.
When the node, the indexer, and the artifact pipeline all matter, single-tenant capacity and stable routing stop being luxuries and start being the difference between a tolerable incident and a customer-visible outage.
Dedicated servers for blockchain infra
Single-tenant capacity, stable routing, and global deployment options give RPC nodes, indexers, and snapshot pipelines a practical production base.