Blog

Emerging Web3 Infrastructure Trends & Future-Proof Solutions
Web3 is entering its infrastructure era. The biggest risk now isn’t token volatility—it’s operational fragility: where critical nodes live, how fast they can talk to each other, and what happens when a single region or upstream network goes dark. As more value and real usage shifts on-chain, web3 infrastructure stops being “just hosting” and starts behaving like protocol design.
Three forces are shaping the next wave: (1) decentralized multi-region deployments that reduce dependence on any single provider, (2) rapid expansion of oracle and cross-chain nodes as apps go multi-chain by default, and (3) new performance, reliability, and scaling demands from liquid staking and Layer-2 growth.
Choose Melbicom— 1,400+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
How Should Web3 Teams Design Multi-Region Hosting for Redundancy?
Web3 teams should design multi-region hosting by placing critical nodes in independent Tier III/IV facilities across continents, connecting them with resilient network paths, and using BGP-based routing patterns so endpoints stay stable during failover. The result is fewer single-provider outages, lower global latency, and cleaner regulatory segmentation.
The case for multi-region architecture is less theoretical than it sounds. The October 2025 AWS US-EAST-1 incident rippled into crypto operations because too many “decentralized” services still depend on centralized infrastructure (see this incident study). Current Ethereum node data reinforces the concentration risk: Ethernodes lists more than half of synced consensus-layer nodes in hosting environments, with Hetzner, OVH, and Amazon-related entities making up a large share of hosted nodes (see Ethernodes’ network-type data and hosting-ISP breakdown).
Melbicom supports this pattern with BGP sessions and multi-region placement across 21 Tier III/IV data centers. For teams building active-active RPC gateways, oracle endpoints, or cross-chain relays, that stability is the difference between graceful degradation and a broken application.
What Infrastructure Do Cross-Chain Oracle Nodes Need to Stay Reliable?
Cross-chain oracle nodes need low-latency peering to multiple chains, predictable bandwidth for state sync and proof relays, and redundant endpoints that stay stable through maintenance. Dedicated bare metal also keeps signing, indexing, and mempool monitoring deterministic when traffic spikes or relayer queues build up.
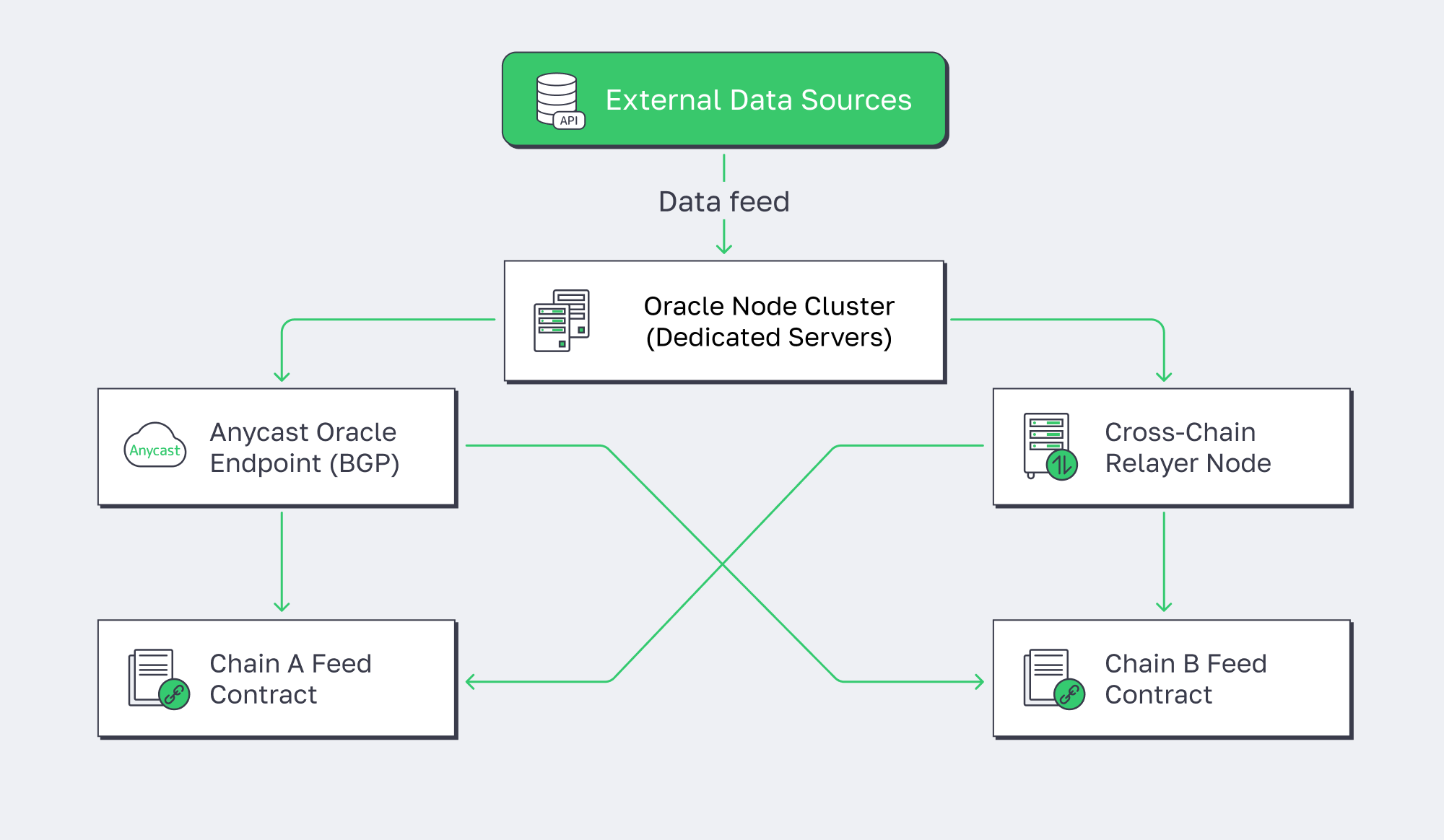
Oracles and bridges aren’t optional middleware anymore—they’re core production dependencies. As adoption rises, so do the consequences of missed updates, stalled relays, and overloaded endpoints. The scale of this shift shows up in hard numbers (see the metrics table at the end, sourced to public data sources), but the operational takeaway is simpler: cross-chain services are “multi-network” by definition, so their web3 infra must be multi-network in practice.
The winning pattern is predictable networking plus deterministic compute. Dedicated servers reduce noisy-neighbor variance for steady workloads (signing, indexing, state sync), while a well-peered backbone reduces tail latency and timeouts across ecosystems. Melbicom’s network and CDN map cleanly to the reality that cross-chain services are API-heavy and globally distributed: 55+ CDN PoPs across 39 countries help pull API surfaces closer to users.
Which Providers Scale Best for Liquid Staking Protocols
Liquid staking and validator fleets demand “boring” infrastructure at extreme scale: rapid provisioning for new validators, multi-region redundancy to reduce slashing risk, and operational tooling that recovers quickly from failures. Providers that pair large ready-to-deploy inventory with fast custom builds and 24/7 support can keep protocols ahead of deposit surges and upgrades.
Liquid staking has turned staking into a high-availability service business. By May 2026, nearly 39 million ETH was staked, according to MacroMicro’s Ethereum staking chart. As staking concentrates into large pools and liquid staking derivatives, infrastructure mistakes stop being local problems—they become ecosystem-level risks. Downtime isn’t just lost uptime; it’s missed attestations, degraded trust, and real economic penalties.
Infrastructure strategy here is straightforward but demanding: scale out quickly while tightening operational control. Teams increasingly prefer dedicated web3 server environments for consistent I/O across validator clients, execution clients, and monitoring stacks. Multi-region deployment reduces the blast radius of outages; stable endpoint design reduces the operational pain of failover and maintenance.
The other constraint is speed. Melbicom offers 1,400+ ready-to-go server configurations, so protocols can add capacity without long procurement cycles. When requirements are specialized, custom configurations are delivered in 3–5 business days—useful for scaling ahead of network upgrades or sudden deposit inflows.
Layer-2 Growth Is Forcing a New Class of Web3 Hosting
Layer-2 networks are quickly becoming the default execution layer for many user-facing apps. Current L2BEAT activity data shows rollups materially outpacing Ethereum mainnet user operations (see the exact past-day UOPS figures below, sourced to L2BEAT). That flips the operational center of gravity: L2 components—sequencers, provers, indexers, batch submitters—become mission-critical alongside L1 validators.
Chart 1: Ethereum Activity by Network Layer (Past-Day UOPS)

The horizon trend is decentralization-by-design: more operators, more regions, more independent infrastructure. ZK rollups add another pressure point because proving is compute-heavy and sensitive to jitter; teams are pushing critical workloads onto dedicated machines where performance stays predictable. This is also where web hosting starts to resemble a global systems problem: you’re not just running nodes, you’re managing latency budgets, failover behavior, and cross-region data movement as first-class product requirements.
Future-Proof Web3 Infrastructure Patterns
Most “next-gen” outcomes come from disciplined engineering applied to crypto-shaped constraints: global users, adversarial environments, and always-on economics. Here’s the condensed checklist that’s emerging as table stakes for resilient web3 infrastructure:
- Treat provider concentration as a design flaw, not a cost optimization. Set minimum region diversity for validator/RPC/oracle footprints, and rehearse failovers on a schedule—not just during incidents.
- Make endpoints effectively immutable. Architect around stable ingress (BGP policies + health-based routing) so maintenance doesn’t become an emergency DNS migration.
- Separate deterministic workloads from bursty ones. Keep signing, sequencing, and proving isolated from indexing/analytics to prevent “background load” from becoming consensus-impacting jitter.
- Make recovery a first-class workflow. Use snapshot-driven rebuilds so resyncs, rollbacks, and region moves are measured in hours—not days.
- Operate cross-chain like an SRE problem. Define per-chain SLOs (latency, update cadence, error budgets), monitor relayer queues, and capacity-plan around bridge and L2 batch spikes.
Conclusion: Future-Proofing Web3 Infrastructure Before the Next Wave
The Web3 conversation is getting less speculative and more infrastructural—and that’s where the real moat forms. Multi-region redundancy is a direct response to systemic concentration and outage risk. Oracles and cross-chain nodes are scaling into high-throughput, low-latency workloads. Liquid staking and Layer-2 growth are raising the bar for deterministic performance, rapid expansion, and operations that survive bad days without drama.
Teams that treat infrastructure as part of protocol design—choosing dedicated compute when determinism matters, distributing across regions, and investing in stable network primitives—will ship faster and break less as usage patterns evolve.
Deploy resilient Web3 infrastructure
Launch on dedicated, multi-region hardware with stable BGP ingress, 55+ PoPs, and S3-compatible storage. Get rapid provisioning and 24/7 support for validators, RPC, oracles, and L2 workloads.
Key Web3 Infrastructure Metrics
| Metric or Trend | Recent Figures (Year) | Source |
|---|---|---|
| Ethereum node hosting concentration | 53.06% of synced consensus-layer nodes classified as Hosting; largest hosted ISPs include Hetzner, OVH, and Amazon-related entities (May 2026) | Ethernodes / Hosting ISPs |
| Oracle network adoption (Chainlink) | $27T+ transaction value enabled; 19B+ verified messages onchain (Jan. 2026) | Chainlink |
| Cross-chain bridge volume | $18.835B 1-month volume (May 2026) | DeFiLlama |
| Ethereum staking / liquid staking scale | Nearly 39M ETH staked; stETH circulating supply ~8.8M tokens (May 2026) | MacroMicro / CoinGecko |
| Layer-2 vs. Layer-1 activity | Rollups: 1.26K past-day UOPS; Ethereum: 22.90 past-day UOPS (May 2026) | L2BEAT |