Blog
Web3 Hosting: Infrastructure Patterns for Reliable Nodes, RPC, and dApps
Web3 infrastructure usually fails before it fails cryptographically: state healing trails chain growth, indexers saturate disks, relayers confuse finality, and sequencer failover changes ingress identity. Reliable Web3 hosting isolates those failure modes before sync lag or API timeouts become outages.
What Web3 Hosting Requires
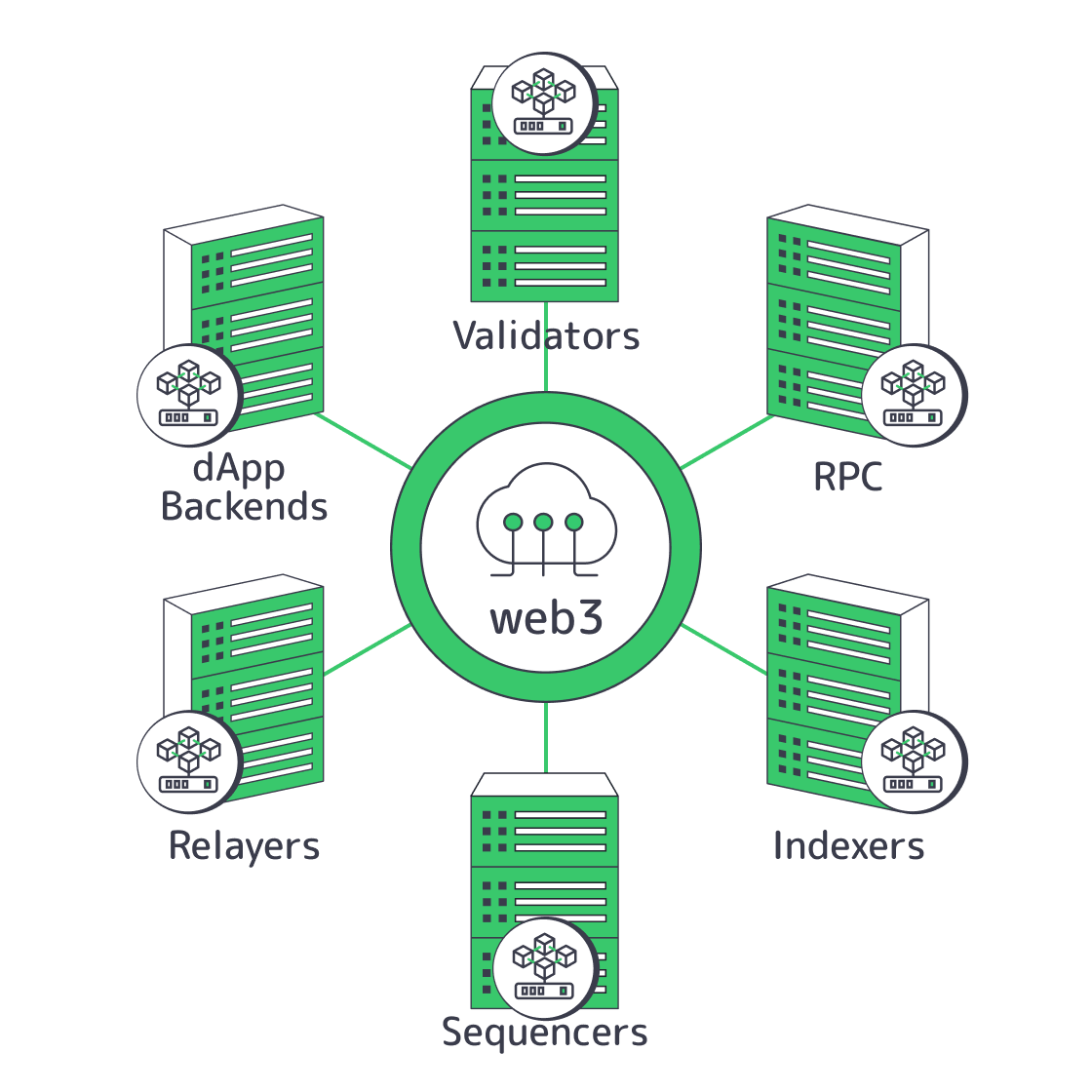
Web3 hosting requires separate failure domains for validators, public RPC, indexers, sequencers, relayers, and app backends. A practical design targets one critical path per server role, local NVMe for state-heavy workloads, and regional networking so overload does not spread stale reads or API failures.

The mistake is calling everything “a node.” Validators and sequencers are consensus-adjacent systems where freshness is the first reliability metric. Public RPC is a read-serving tier where p95 and p99 latency define user experience. Indexers and archives are ingestion systems. Relayers are finality-aware workflow engines. dApp backends are fan-out systems that should never turn one cache miss into a retry storm.
That separation follows protocol design. Solana RPC docs state that shared public RPC endpoints are not intended for production apps, while Agave validator requirements distinguish validator capacity from added RPC capacity. Sui full node documentation says validators push committed transactions to full nodes, which then serve client queries.
| Workload | What Usually Breaks First | Preferred Infrastructure Pattern |
|---|---|---|
| Validator or sequencer | Head freshness, vote production, unsafe-head continuity | Single-tenant dedicated server, isolated from public traffic, fast local storage, explicit failover controls |
| Public RPC node | p95/p99 latency, WebSocket stability, expensive method timeouts | Separate read tier, private upstreams, method-aware routing, safe/finalized serving paths |
| Indexer or archive tier | Catch-up speed, disk amplification, retention growth | Dedicated ingestion and query paths, snapshot restores, planned storage tiers |
| Relayer | Wrong finality timing, duplicate submissions, nonce drift | Queue-backed workers, route-specific finality policy, multi-upstream verification |
| dApp backend | Fan-out storms, cache misses, user-visible spikes | Stateless app layer, private RPC, async jobs, caches, region-local ingress |
Dedicated Servers vs Cloud for Web3
Dedicated servers fit Web3 infrastructure when the role is stateful, latency-sensitive, and I/O-heavy; cloud instances fit elastic ingress, orchestration, and stateless control planes. The tradeoff is simple: validators, hot RPC nodes, and indexers need predictable CPU, memory, NVMe, and bandwidth, while application edges benefit from burstable deployment velocity.
Choose Melbicom– Dedicated nodes for Web3 – Regional failover – High-bandwidth capacity |
 |
The hardware guidance is blunt. Agave requirements call for at least 12 cores and 24 threads for validators, 16 cores and 32 threads with RPC, 256 GB of RAM for validators, 512 GB for all account indexes, separate NVMe devices for accounts, ledger, and snapshots, and at least 2 Gbps symmetric bandwidth for staked nodes, with 10 Gbps recommended. The same guidance warns that cloud operation requires greater expertise and that live validators in Docker are generally not recommended.
Sui validator guidance asks for 24 physical cores, 128 GB memory, 4 TB NVMe, and 1 Gbps networking. A Sui full node still wants 8 physical cores, 128 GB RAM, and a 4 TB NVMe drive. Geth hardware guidance recommends at least 16 GB RAM and a 2 TB SSD, warning that HDDs and cheaper SSDs can struggle.
That is why single tenancy matters in Web3 server hosting. These are stateful systems shaped by disk write amplification, peer churn, historical retention, and recovery bandwidth. The durable pattern is hybrid: keep chain-state roles on dedicated servers; keep API gateways, deploy pipelines, metrics, and stateless dApp services in orchestration.
Reduce Sync Lag and API Timeouts
Reducing sync lag, API timeouts, and centralization risk in Web3 hosting means restoring from checkpoints or snapshots, separating hot reads from historical backfills, and diversifying both regions and client implementations. A useful threshold is keeping no client or region above one-third of critical production capacity, matching Ethereum’s 33% resilience target.Sync lag is mostly a recovery-path problem. Geth snap sync is faster than full block-by-block sync, but state healing must outpace chain growth or the node never catches up. Geth keeps only the most recent 128 block states in a full node, with older state regenerated on request. Lighthouse checkpoint sync is substantially faster than syncing from genesis and is required by default.
Historical access is a separate tier. The February 24, 2026 Geth archive mode update says legacy hash-based archives can exceed 20 TB and take months to synchronize. Newer path-based archives need around 2 TB for full flat-state history, about 6.5 TB with historical trie data, and roughly two weeks to bootstrap.

API timeouts are often designed in. Ethereum JSON-RPC supports safe and finalized block tags, so reads that do not need the latest unsafe head can go to calmer backends. Current eth_getLogs documentation warns that large ranges or high-activity contracts can time out and recommends keeping fromBlock to toBlock under 2,000 blocks. Heavy history belongs on indexers and backfill workers, not on the wallet-facing edge.
Sui shows where this is going. Its data stack update says legacy JSON-RPC sunsets on July 31, 2026, while gRPC, GraphQL RPC, and the Archival Store become the production path. Web3 hosting must treat indexing as a first-class serving plane, not a background process competing with live traffic.
Centralization risk is also about who serves data and which client code paths everyone trusts. Clientdiversity.org sets a goal of keeping each Ethereum client below 33% and flags 66% as dangerous. A March 2026 APIDiffer paper evaluated all 11 major Ethereum clients and found 72 API bugs, with 90.28% already confirmed or fixed. Production RPC should shadow-read or canary critical methods across at least two client stacks.
Regional Web3 Failover
Regional diversity matters, but every role fails over differently. Validators and sequencers need state continuity and explicit leadership. Public RPC needs stable ingress identity and short cutovers. Relayers need independent confirmation paths and route-specific timers. Indexers need restore bandwidth more than edge routing.
OP Conductor documentation is unusually concrete: a standard HA setup assumes three sequencers, one active leader, Raft state, health checks, blue/green deployment, no unsafe reorgs, no unsafe-head stall during partition, and 100% uptime with no more than one node failure. It also says the design is not Byzantine fault tolerant. Real failover requires state transfer and leadership handoff.
Relayers need stricter timing discipline. CCTP block-confirmation documentation shows hard-finality attestation windows of about 8 seconds on some chains, about 25 seconds on Solana, about 75–120 seconds on Polygon PoS, and about 13–19 minutes for Ethereum-finalized rollups. Queue-backed relayers should encode those windows per route and make retries idempotent.
Web3 Hosting Is a Failure-Domain Decision
The pattern is now clear: isolate validators and sequencers, split RPC reads from indexing and archive backfills, make restoration faster than replay, diversify clients, and make regional failover preserve identity where partners, wallets, or allowlists depend on stable ingress. Latency still matters, but the larger win is preventing one overloaded path from becoming a correlated outage.
Use this checklist when evaluating Web3 server hosting:
- Put validator or sequencer roles on their own dedicated servers.
- Keep public RPC, indexing, and backfill traffic outside that failure domain.
- Restore from checkpoints, snapshots, or archive fallback instead of genesis replay.
- Route sensitive reads to safe or finalized tiers, then diversify regions and clients.
- Preserve endpoint identity with BGP where static ingress matters; offload snapshots, proofs, and static dApp assets away from node disks.
For teams applying that pattern, provider topology becomes part of the reliability model, not a procurement afterthought.
Explore Web3 Server Hosting
Melbicom’s Web3 server hosting, data center, and network footprint supports single-tenant dedicated servers across 21 Tier III and Tier IV data centers, 1,100+ ready-to-go configurations, custom configurations delivered in 3–5 business days, 20+ transit partners, 25+ IXP peering hubs, and per-server bandwidth up to 200 Gbps depending on location.
Deploy Web3 Servers
Choose Melbicom—run Web3 node, RPC, relayer, and dApp roles on dedicated infrastructure with regional capacity.