Blog

Speed and Collaboration in Modern DevOps Hosting
Modern software teams live or die by how quickly and safely they can push code to production. Current DORA benchmarks still show a wide delivery gap: elite teams deploy on demand, often multiple times per day, while low performers deploy between once per month and once every six months.[1]
To close that gap, engineering leaders are refactoring not only code but infrastructure: they are wiring continuous-integration pipelines to dedicated hardware, cloning on-demand test clusters, and orchestrating microservices across hybrid clouds. The mission is simple: erase every delay between “commit” and “customer.”
Choose Melbicom— 1,400+ ready-to-go server configs — 21 global Tier IV & III data centers — 55+ CDN sites in 39 countries |
 |
Below is a data-driven look at the four tactics that matter most—CI/CD, self-service environments, container orchestration, and integrated collaboration—followed by a reality check on debugging speed in dedicated-versus-serverless sandboxes and a brief case for why single-tenant servers remain the backbone of fast pipelines.
CI/CD: The Release Engine
Continuous integration and continuous deployment have become table stakes—not because deployment frequency alone proves performance, but because DORA now treats deployment frequency, change lead time, failed-deployment recovery time, change-fail rate, and deployment rework rate as a shared set of delivery metrics.[2] The practical target is smaller, safer batches moving through reproducible pipelines without long queues.
Key accelerators
| CI/CD Capability | Impact on Code-to-Prod | Typical Tech |
|---|---|---|
| Parallelized test runners | Cuts build times from 20 min → sub-5 min | GitHub Actions, GitLab, Jenkins on auto-scaling runners |
| Declarative pipelines as code | Enables one-click rollback and reproducible builds | YAML-based workflows in main repo |
| Automated canary promotion | Reduces blast radius; unlocks multiple prod pushes per day | Spinnaker, Argo Rollouts |
Many organizations still host runners on shared SaaS tiers that queue for minutes. Moving those agents onto dedicated machines—especially where license-weighted tests or large artifacts are involved—removes noisy-neighbor waits and pushes throughput to line-rate disk and network. Melbicom activates ready-to-go dedicated servers in under two hours and supports up to 200 Gbps per server, allowing teams to run large builds, security scans, and artifact replication without throttling.
Self-Service Preview Environments
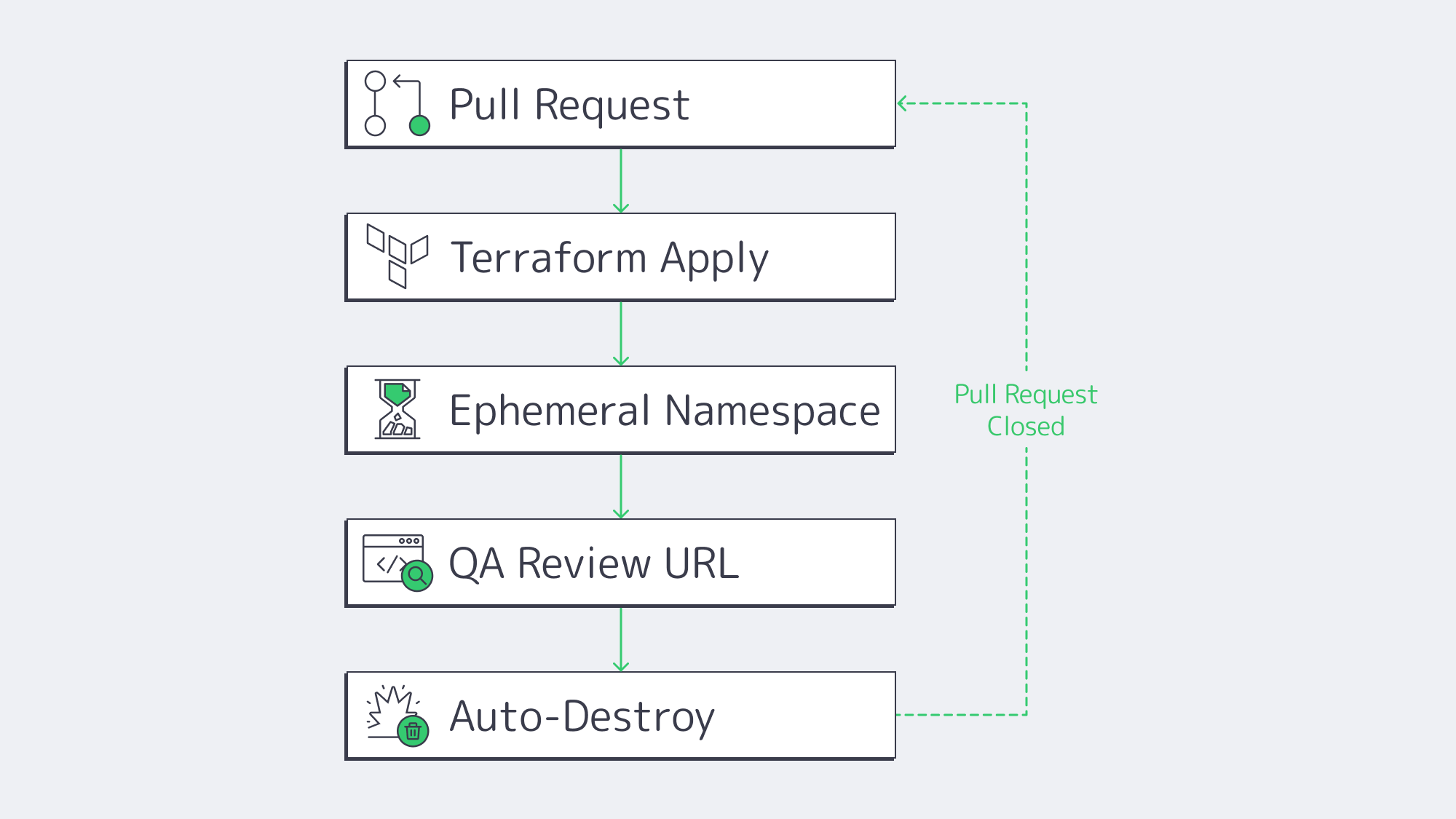
Even the slickest pipeline stalls when engineers wait days for a staging slot. Recent Puppet survey data on DevOps self-service links platform-engineering self-service to improved development velocity for 68% of teams and improved productivity for 59%.[3] The winning pattern is “ephemeral previews”:
- Developer opens a pull request.
- Pipeline reads a Terraform or Helm template.
- A full stack—API, DB, cache, auth—spins up on a disposable namespace.
- Stakeholders click a unique URL to review.
- Environment auto-destroys on merge or timeout.
Because every preview matches production configs byte-for-byte, integration bugs surface early, and parallel feature branches never collide. Cost overruns are mitigated by built-in TTL policies and scheduled shutdowns. Running these ephemerals on a Kubernetes cluster of dedicated servers keeps worker capacity warm while still letting the platform burst into a public cloud node pool when concurrency spikes.
Container Orchestration: Uniform Deployment at Scale
Containers and Kubernetes long ago graduated from buzzword to backbone. CNCF’s 2025 Annual Cloud Native Survey reports that 82% of container users run Kubernetes in production, up from 66% in 2023.[4] For developers, the pay-off is uniformity: the same image, health checks, and rollout rules apply on a laptop, in CI, or across ten data centers.
Why it compresses timelines:
- Environmental parity. “Works on my machine” disappears when the machine is defined as an immutable image.
- Rolling updates and rollbacks. Kubernetes deploys new versions behind readiness probes and auto-reverts on failure, so teams ship multiple times per day safely.
- Horizontal pod autoscaling. When traffic spikes at 3 a.m., the control plane—not humans—adds replicas, so on-call engineers write code instead of resizing.
Yet orchestration itself can introduce operational overhead. Bare-metal clusters remove the virtualization layer, simplify network paths, and improve pod density.
Melbicom racks single-tenant fleets with IPMI access so platform teams can flash exact kernels, CNI plugins, or NIC drivers without waiting on cloud hypervisors.
Integrated Collaboration in DevOps

Speed is half technology, half coordination. Fast teams use shared work surfaces:
- Repo-centric discussions. Whether on GitHub or GitLab, code, comments, pipeline status, and ticket links live in one URL.
- ChatOps. Deployments, alerts, and feature flags pipe into Slack or Teams so developers, SREs, and PMs troubleshoot in one thread.
- Shared observability. Engineers reading the same Grafana dashboard as Ops spot regressions before customers do. Post-incident reports feed directly into the backlog.
DORA’s current metrics guidance warns against siloed ownership and recommends sharing delivery metrics across development, operations, and release teams to avoid friction and finger-pointing.[2] Toolchains reinforce that culture: if every infra change flows through a pull request, approval workflows become social, discoverable, and searchable.
Debugging at Speed: Hybrid vs. Serverless
Nothing reveals infrastructure trade-offs faster than a 3 a.m. outage. When time-to-root-cause matters, always-on dedicated environments beat serverless sandboxes in three ways:
| Criteria | Dedicated Servers (or VMs) | Serverless Functions |
|---|---|---|
| Live debugging & SSH | Full access; attach profilers, inspect syscalls | Usually no SSH; depend on logs, traces, and provider tooling |
| Cold-start behavior | Resident services stay warm; latency depends on app and network path | May add cold-start latency unless warm or provisioned capacity is configured |
| Execution limits | Bound by hardware, OS settings, and your own quotas | Platform quotas apply; AWS Lambda, for example, runs a function for up to 15 minutes with up to 10,240 MB memory[5] |
Serverless excels at elastic front-end API scaling, but its abstraction hides the OS, complicates heap inspection, and enforces provider-specific runtime ceilings. The pragmatic pattern is therefore hybrid:
- Run stateless request handlers as serverless for cost elasticity.
- Mirror critical or stateful components on a dedicated staging cluster for step-through debugging, load replays, and chaos drills.
Developers reproduce flaky edge cases in the persistent cluster, patch fast, then redeploy the same container image to both realms.
This split keeps serverless economics and preserves deep debugging on dedicated servers.
Hybrid Dedicated Infrastructure
With Gartner forecasting worldwide public-cloud end-user spending at $723.4 billion in 2025 and noting that 90% of organizations will adopt hybrid cloud through 2027, it is tempting to assume all workloads belong in public cloud alone.[6] Reasons include:
- Predictable performance. No noisy neighbors means latency and throughput figures stay flat—critical for conversion-sensitive applications and latency-sensitive APIs.
- Cost-efficient base load. Steady 24 × 7 traffic can cost less on fixed-price servers than equivalent public-cloud VM capacity.
- Data sovereignty & compliance. Finance, health, and government workloads may need to reside in certified single-tenant environments.
- Customization. Teams can install low-level profilers, tune kernel modules, or deploy specialized GPUs without waiting for cloud SKUs.
Melbicom underpins this model with 1,400+ ready-to-go configurations across 21 Tier III/IV locations. Teams can anchor their stateful databases in Frankfurt, spin up build runners in Amsterdam, burst front-end replicas into Atlanta, and push static assets through a CDN in 55+ locations across 39 countries. Bandwidth scales up to 200 Gbps per server, eliminating throttles during container pulls or artifact replication. Crucially, ready-to-go servers land online in two hours, not the multi-week procurement cycles of old.
Hosting That Moves at Developer Speed

Fast, collaborative releases hinge on eliminating every wait state between keyboard and customer. Continuous-integration pipelines slash merge-to-build times; self-service previews wipe out ticket queues; Kubernetes enforces identical deployments; and integrated toolchains keep everyone staring at the same truth. Yet the physical substrate still matters. Dedicated servers—linked through hybrid clouds—sustain predictable performance, deeper debugging, and long-term cost control, while public services add elasticity at the edge. Teams that stitch these layers together ship faster and sleep better.
Deploy Infrastructure in Minutes
Order high-performance ready-to-go dedicated servers backed by 21 global data centers and get online in under two hours.