Blog
Build Stable Solana Validator, RPC, and Archive Nodes
Solana behaves less like a generic daemon and more like a real-time system under sustained write pressure. With roughly 400ms slots, the margin for CPU jitter, NIC queueing, storage stalls, and replay lag is tiny. In production, the breakage point is usually tail latency, burst handling, and resource contention—not average throughput.
That is why node hosting is effectively protocol design. Solana’s own guidance says production on virtualized platforms is possible but usually harder to keep stable than single-tenant infrastructure. For multi-region validator and RPC fleets, Melbicom aligns with that model: Melbicom runs 21 Tier III and Tier IV data centers, supports ports up to 200 Gbps per server depending on location, and pairs dedicated servers with a network built around 20+ transit providers and 25+ IXPs plus BGP sessions when stable endpoints matter.
Best Servers for Crypto Exchanges— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
How Solana Validator, RPC, and Archive Node Requirements Differ
Validators, RPC nodes, and archive nodes run the same client, but each role stresses a different subsystem. Validators are constrained by consensus-time networking and replay. RPC nodes add query concurrency and indexing pressure. Archive designs are really history-retention architectures, where long-term storage economics matter as much as CPU or RAM.
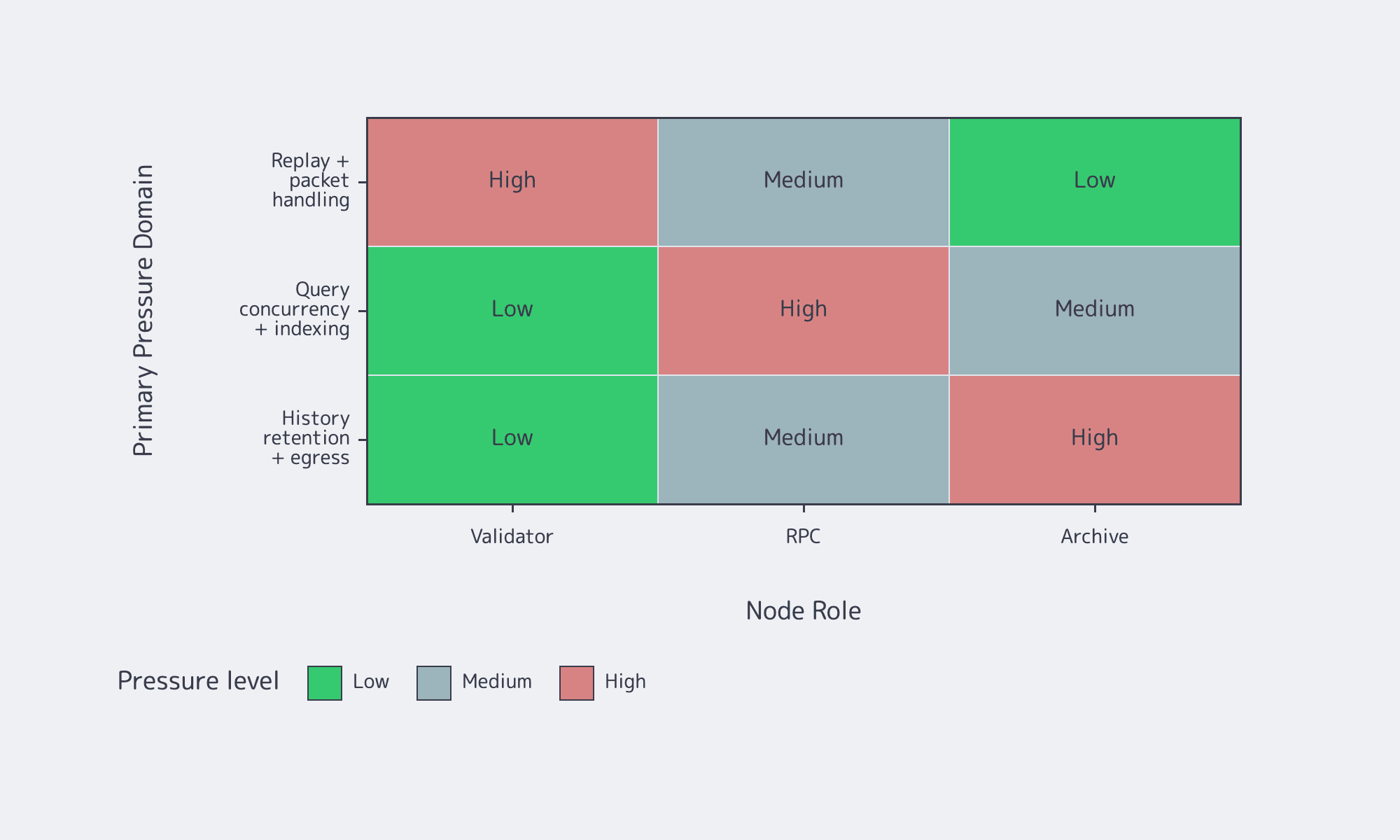
A validator is the consensus-facing machine. An RPC node usually runs with --no-voting and spends its budget on JSON-RPC, WebSockets, simulation, and indexes; Solana’s docs explicitly discourage combining full RPC and voting on one production host. “Archive” is less a formal node class than an operator pattern: either keep more history locally, or offload older ledger data into a historical backend such as Bigtable.
Production Baseline by Role
| Role | Main bottleneck | Practical production baseline |
|---|---|---|
| Consensus validator | Replay, packet handling, vote-path stability | Fast CPU with AVX2 and SHA extensions, roughly 12 cores / 24 threads or more, 256GB+ RAM, separate NVMe for accounts and ledger, and at least 1 Gbit/s symmetric networking, with 10 Gbit/s preferred. |
| Full Solana RPC node | Query concurrency, indexing, and deeper history | Similar CPU class with more headroom, often 16 cores / 32 threads or better, 512GB+ RAM if all account indexes are enabled, separated NVMe tiers, and enough network capacity to absorb both chain sync and client traffic. |
| Archive / warehouse pattern | Storage economics and historical reads | Hot-path compute similar to RPC, but paired with a long-term historical backend or very large local storage footprint. The main planning question is how far back queries must go and what that retention costs over time. |
The bottleneck moves with the role: validators are consensus-time systems, RPC nodes are user-time systems, and archive designs are storage-and-egress systems. That is the core reason one-size-fits-all Solana infrastructure usually fails.
What Production-Grade Solana Node Hosting Needs for Storage, RAM, & Failover
Production-grade Solana node hosting starts with isolation. Put AccountsDB, ledger, and snapshots on different NVMe devices; size RAM around your indexing plan, not a generic server tier; keep clean symmetric bandwidth and predictable routing; and treat failover as a routine operating pattern, not an incident-only playbook.
Storage Architecture: Separate NVMe or Accept Self-Inflicted Throttling
The official requirements are blunt because Solana is storage-sensitive. A practical plan is:
- AccountsDB NVMe for latency-sensitive random reads and writes
- Ledger NVMe for sustained writes, compaction, and cleanup
- Snapshots NVMe for bootstrap and recovery traffic
That separation matters because snapshots are full-state artifacts, not tiny exports. The AccountsDB deep dive describes them as compressed archives that must be decompressed, unpacked, and memory-mapped before the node can resume. Put snapshot traffic on the same disk as hot state and the box starts competing with its own recovery path.
Memory, Network, and Failover
RAM planning is an indexing decision. Solana’s baseline is 256GB+, but the official guidance moves to 512GB+ when you want all account indexes. Network planning is similar: the requirement is not just “fast internet,” but stable p99 packet handling across gossip, repair, and QUIC-based ingress, with 1 Gbit/s symmetric service as the floor + 10 Gbit/s preferred.
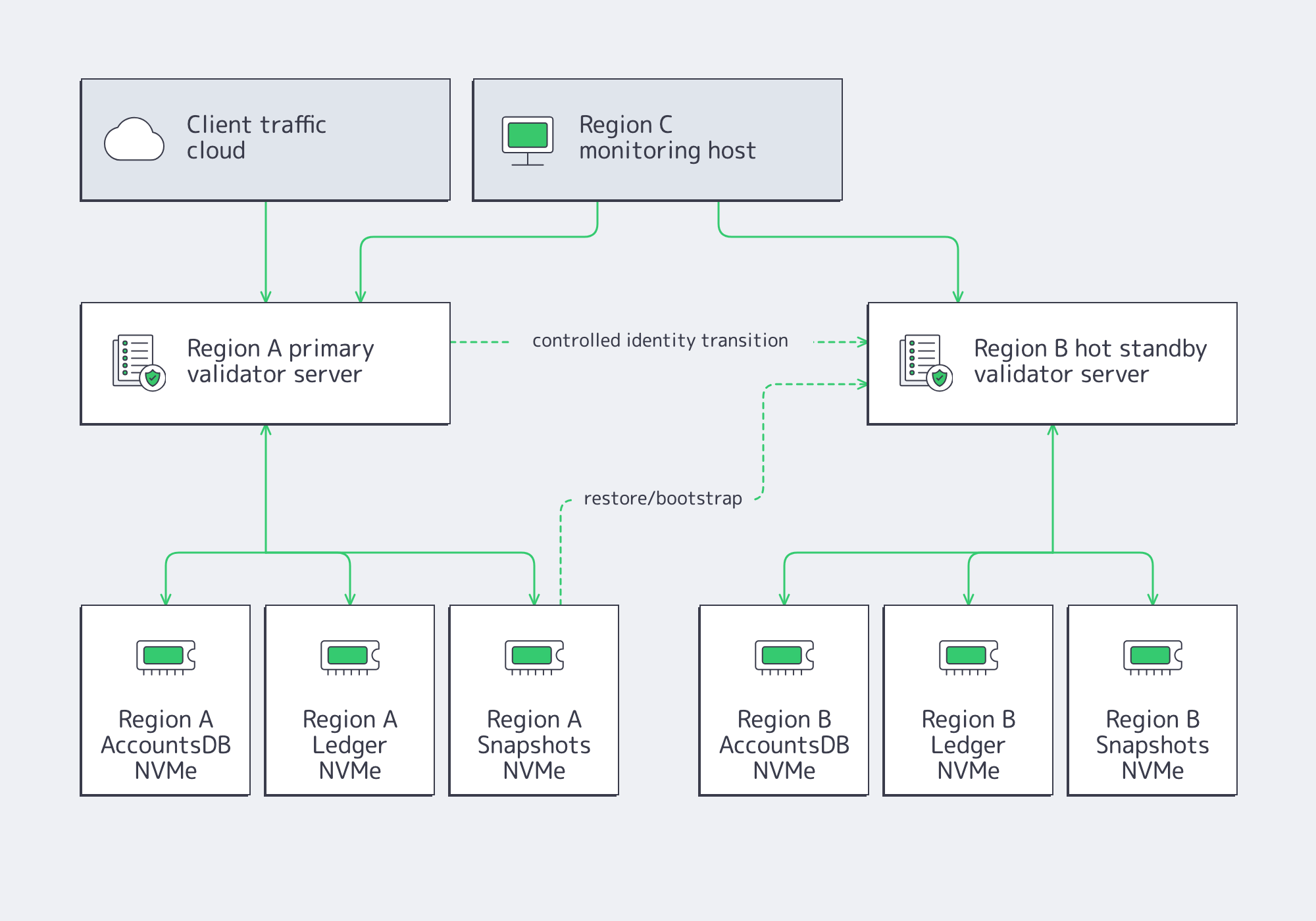
For validators, the two-machine failover pattern remains the safest model:
- Primary validator in Region A
- Hot standby validator in Region B
- Independent monitoring host in Region C
- Controlled identity transition using the identity-symlink and tower-file workflow
For RPC, failover is about endpoint continuity more than validator identity. That is where Melbicom’s BGP session service, global footprint, and networking layer become useful: routing changes are cleaner, state movement is easier to plan, and ports scale high enough that failover does not have to mean immediate bandwidth compromise.
Operations Essentials That Keep Nodes Alive Under Real Traffic
Production stability on Solana is operational. Snapshots need provenance and storage discipline. Monitoring has to track freshness, not just process uptime. Release cadence matters because software changes frequently. Security still matters, but it should match the role of the machine.
- Snapshots: use trusted peers and know how quickly you can restore without saturating hot disks. Solana’s exchange guide documents
-known-validatorand when-no-snapshot-fetchhelps preserve continuity. - Monitoring: run watchtower-style monitoring from a separate host and alert on replay lag, block-height drift, and delinquency.
- Upgrade cadence: stage, fail over, upgrade, and roll back if needed. Do not treat in-place patching as a maintenance strategy.
- Security: patch regularly, avoid running as root, minimize exposed ports, and keep sensitive keys off the validator.
- Data-plane scaling: when analytics becomes a real workload, move it off generic polling; indexing guidance increasingly points operators toward Geyser-based streaming.
When Dedicated Solana RPC Infrastructure Makes More Sense Than Managed RPC
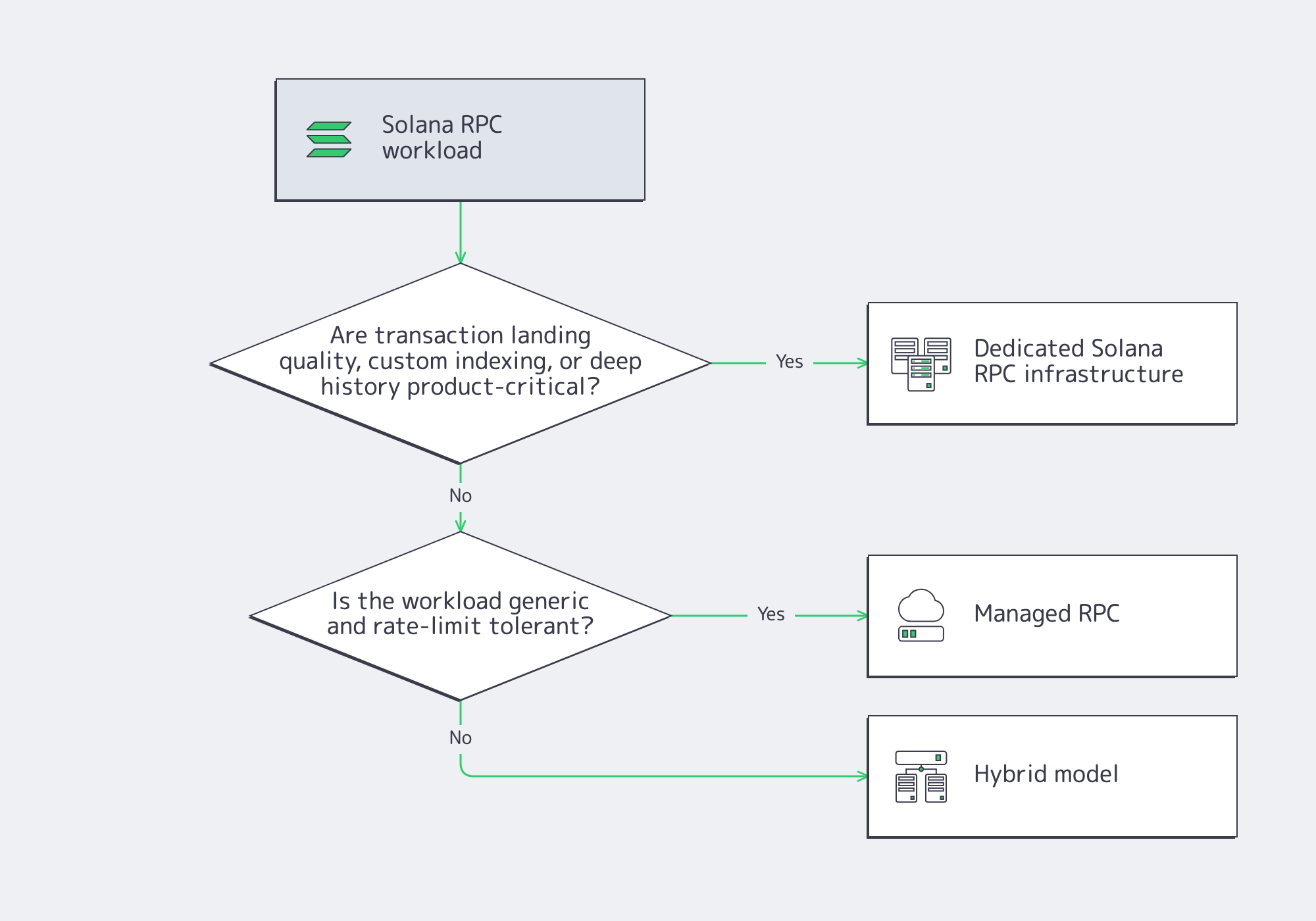
Dedicated Solana RPC infrastructure makes sense when failure-mode control matters more than convenience. If transaction landing under congestion, custom indexing, stable routing, or stream-based ingestion is part of the product, a shared endpoint becomes a constraint. Managed RPC is easier to start with; dedicated RPC is safer once the workload becomes specific, spiky, or operationally expensive to misroute.
The Real Question Is Control of Failure Modes
Solana’s retry guidance documents several common RPC failure modes: backends in the same pool can drift, rebroadcast queues can overflow, and user-visible failures often look like “RPC is broken” even when the process is technically up. If you operate the fleet, you can isolate sendTransaction traffic from heavy reads, choose indexing depth, and decide which nodes are allowed to absorb expensive history queries.
Where a Solana RPC Node Benefits Most From Dedicated Infrastructure
A dedicated Solana RPC node becomes more compelling when one of three things is true: transaction landing quality is a customer-facing issue, downstream systems need low-latency streaming and indexing, or capacity planning has to be deterministic instead of rate-limit-driven. In each case, the value is not just speed. It is control over queueing, routing, memory budgets, and method mix.
Buy vs. Build: What You Actually Pay For
Self-hosted RPC buys control over hardware class, NVMe layout, routing, observability, and upgrade timing. It also buys responsibility for release testing, snapshot strategy, and on-call response. Managed RPC buys simplicity and faster setup, but it usually gives up some control over metering, historical depth, and tail-latency behavior during network-wide spikes. A hybrid often works best: dedicated RPC for critical paths, managed access for less sensitive workloads.
Costs and Service-Level Checklist for Solana Node Hosting
Operating cost on Solana is mostly infrastructure cost, plus recurring protocol overhead for validators. RPC nodes add RAM, IOPS isolation, and client-serving headroom. Archive patterns move the cost center again toward long-term storage, read amplification, and egress. That is why cost modeling should follow role separation, not node count alone.
Internal Checklist for Treating a Node Like a Service
- Separate roles before you scale: keep voting, public RPC, and deep-history workloads from competing for the same box.
- Budget RAM for indexes, not headlines: account indexing and historical query depth should decide memory size, not generic “blockchain server” tiers.
- Protect the write path: split AccountsDB, ledger, and snapshots across separate NVMe devices before you add more CPU.
- Rehearse failover, don’t just document it: a standby validator, external monitoring, and controlled identity movement should be tested, not assumed.
- Measure service quality by freshness and landing rate: process uptime is not enough if replay lags or
sendTransactionsuccess degrades under burst traffic. - Keep upgrades boring: release cadence, rollback discipline, and trusted snapshot sources are operational features, not afterthoughts.
Design Around Role Clarity & Recoverability

The right question is not “How large a server do I need?” but “Which failure mode am I paying to avoid?” Validators, RPC nodes, and archive designs all run the same software, yet each turns a different subsystem into the bottleneck. Good production architecture works when roles are separated, NVMe is separated, monitoring is externalized, and failover is rehearsed before a region or disk actually fails.
That is also where the managed-versus-self-hosted decision gets clearer. If the workload is generic, managed RPC can be enough. If it is latency-sensitive, history-heavy, or tightly coupled to transaction landing and endpoint stability, dedicated infrastructure is usually the more honest design.
Deploy Solana on Dedicated Servers
Run validators, RPC, and archive nodes on high-bandwidth dedicated servers across 21 global data centers. Configure AMD EPYC, RAM, NVMe, and ports up to 200 Gbps for stable, low-latency performance.