Blog

Scaling Streaming Services with Dedicated Servers
Over 80% of total daily internet traffic is for video streaming. With the majority of us watching around 100 minutes on average every single day, it is easy to see why it now dominates the internet. Those statistics from industry analyses are augmented further by live streaming events; we are now seeing peaks of around 65 million concurrent streams. For platforms, it is no longer a question of whether or not they will receive a huge audience, but more a question of whether or not they can handle it. Without the right architecture buffering, outages and crippling costs arise. Streaming audiences have very little tolerance when it comes to delays; network latency of just 100 ms results in a measurable drop of 1% in engagement, which at scale can really affect revenue.
When audiences are large and traffic spikes are common, you need a scaling strategy in place to keep up with demands. Today, we will delve into the ideal blueprint that uses dedicated servers as an anchor to ensure performance and reliability, and load-balanced horizontal scaling with high-availability clusters and multi-region failover. This includes a hybrid infrastructure that keeps steady loads on dedicated servers and bursts to the cloud during peaks, reducing costs by around 40%. We will also explore hardware acceleration and next-gen codecs for dealing with 4K+ streaming efficiently.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Why Use Dedicated Servers to Anchor Streaming at Scale?
Streaming services with high traffic have a high throughput and bandwidth. Heavy activities require consistency and predictability, which multi-tenant environments can’t provide. Often, they are affected by “noisy neighbors” and a hypervisor overhead, which means the network can’t guarantee the same throughput consistency. A fleet of dedicated servers delivers consistent CPU, predictable I/O, and stable latency at scale—even when millions tune in—because load is spread across many single-tenant nodes rather than contending in a multi-tenant environment. Single-tenant machines are also more economically viable for heavy bandwidth services because platforms can lock in high-capacity ports at a flat price instead of paying per-GB egress premiums and cloud tax on steady, always-on traffic.
Melbicom offers over 1,300 ready-to-go server configurations, including compute- and GPU-optimized profiles. We deploy servers in 21 global locations, and our network backbone provides up to 200 Gbps per server. We engineer across diverse carriers to ensure high-capacity upstreams, giving your teams the headroom to aggregate terabits at the cluster level without the instability of shared-tenancy environments. We also provide around-the-clock support at no extra cost because incidents rarely obey business hours, and rapid action protects revenue.
With a hybrid model that reserves cloud use only for unpredictable spikes, you also keep the costs down considerably while you scale. The steady portion of traffic is, after all, what dominates bills, and by keeping it on dedicated servers, you can consolidate spend and reduce TCO. Bandwidth drives cost up, and the figures vary according to workloads, but many large-scale studies show that by shifting sustained workloads from public clouds to dedicated servers, there are savings of 30–50% to be made.
Scaling Horizontally: A Server Fleet Design for High Traffic Streaming
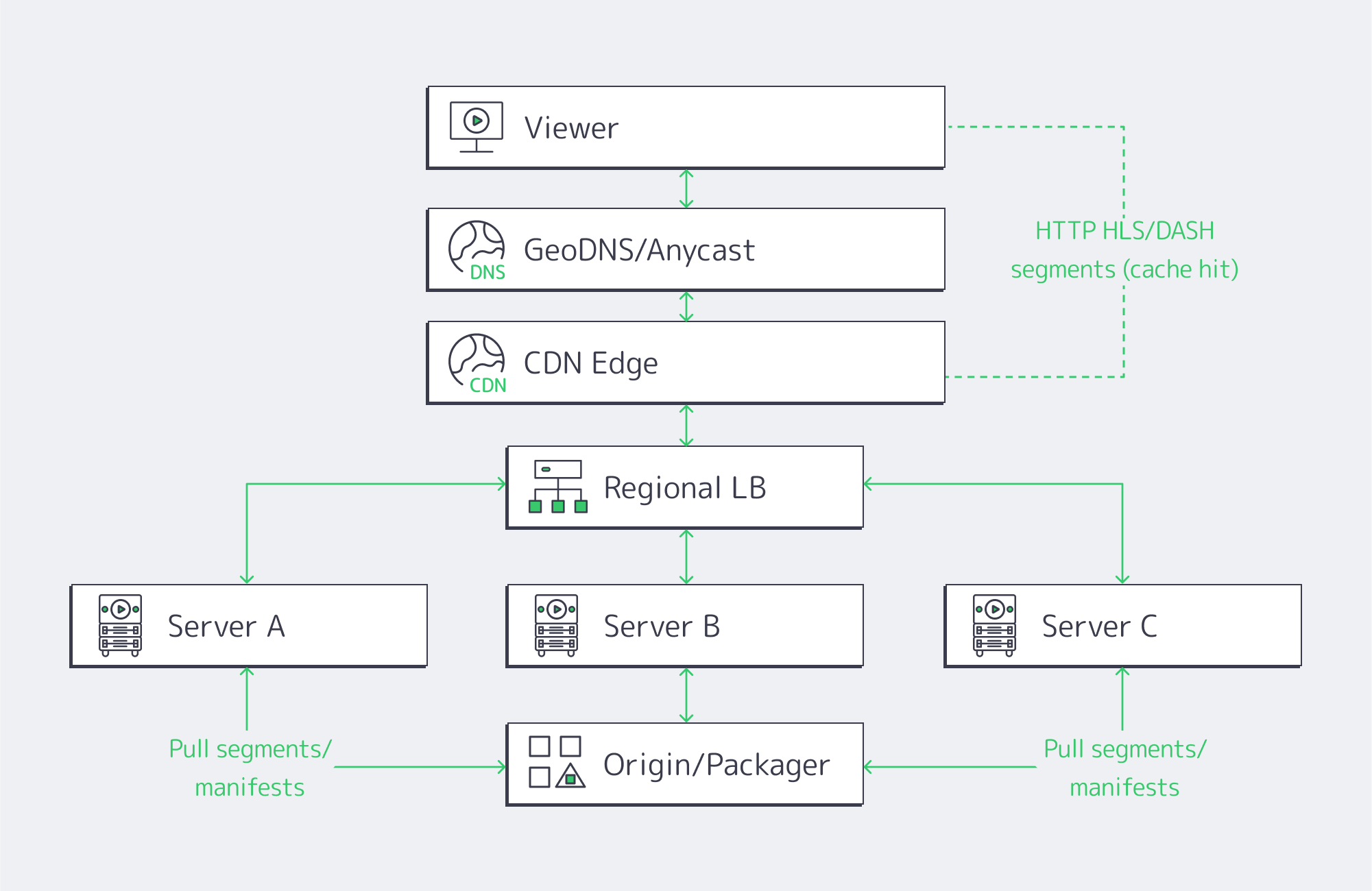
Horizontal scaling is simple. The core idea is that, rather than having to upgrade to an enormous server, you use many small, identical servers with a layer of load balancers across them to distribute. You essentially add nodes to grow your capacity, making it a natural choice for scaling up your streaming because HLS and DASH cut the video into chunks, and the player fetches them over HTTP, and segment requests can be handled by any server.
The balancing works best in two tiers:
- Global routing: Viewers are steered via GeoDNS or anycast to the nearest healthy region, be it Atlanta, Amsterdam, or Singapore.
- Local balancing: Traffic is spread across the server pool within the region using L4/L7 appliances or software on dedicated balancers using algorithms such as least-connections and slow-start.
Key design elements
- Statelessness/ light state: By keeping session state either in the client itself or a distributed store, any node can serve any segment. You can evade creating hard coupling and help localize caches through this short-lived operation.
- Back-pressure and shedding: Traffic is prevented from oversaturating nodes through health checks, circuit breakers, and queue depth signals. This ensures viewers don’t suffer at peak.
- Cache locality: Origin hits are minimized because each node serves from memory segments cached in RAM/NVMe, keeping startup fast.
- Rolling deploys: Node subsets can be drained, upgraded, and brought back before proceeding, which eliminates global maintenance windows.
With this design, the system degrades gracefully. When a node drops, you lose headroom, but the stream continues—unlike the failure cliff of traditional monoliths.
At Melbicom, we see horizontally scaling clusters achieve better p95 start times again and again simply because per-node contention is removed from the equation. And with the full OS/network control that single tenancy provides, teams can tune TCP stacks, IRQ affinity, and NIC queues. This allows for fine-grained optimizations that you simply don´t have the luxury of within shared environments.
Clusters, Regions, and Network Factors Needed for High Availability
The capacity to scale requires high availability and the ability to survive any failures along the way. High availability (HA) starts at the node requiring ECC memory, redundant PSUs, and mirrored NVMe, but the real key to ensuring availability relies on clustered service operation and a multi-region design.
- Use active-active clusters for origins and packagers to ensure that either node can serve the full load if its peer fails. Using stateless tiers facilitates things further; auth, catalogs, and watch history require consensus stores or primary-secondary with failover.
- Deploying in multiple regions prevents single point of failure if there is an incident at the data center itself. Regions can be rapidly pulled out using health-checked DNS/anycast, and you can shift viewers in seconds to the closest healthy site.
- Tiered redundancy shaves downtime considerably; top facilities, such as Tier IV-certified ones, aim for an uptime target of around 99.995% which equates to an acceptable 26 minutes of annual downtime, protecting revenue. Melbicom’s fleet includes Tier IV & III facilities in Amsterdam, while other locations meet Tier III, giving you the robust baseline needed for practical streaming SLAs.
The network also plays a huge role in maintaining high availability. To make sure your live streams flow regardless of a carrier having a bad day, you need multi-homed upstreams and enough route diversity, with rapid convergence. Single points can be eliminated within a site through redundant switching and NIC bonding, and BGP-based policies steer cross-site traffic around any regionally based issues. This is where having Melbicom’s dedicated multihomed backbone with its wide CDN truly pays off; it is already engineered for the high-volume, low-loss delivery that streaming platforms need at scale.
A Hybrid Infrastructure Solution: Steady Loads Kept Dedicated, Spikes to the Cloud

The capacity differences between a typical day of around 50k concurrents and a championship match explosion of 500k bring a capacity–cost dilemma. A hybrid model can help solve the volatile traffic patterns associated with streaming:
- Run the steady base on dedicated servers to keep latency predictable and benefit from a flat-rate bandwidth and tight cost per stream.
- Burst any spikes to the cloud by autoscaling groups or serverless entry points, so that you absorb overflow as and when needed.
- Leverage CDN and global routing with multiple origins—one pool on dedicated servers and another in the cloud—so you can shift percentages based on health and utilization.
Execution details for hybrid operation
- One artifact, two substrates: containerize the streaming stack so the same image runs on both dedicated servers and the cloud.
- Automate scale-out triggers by setting a threshold for the CPU/bandwidth so that burst capacity launches when traffic surges and drains when it subsides.
- Partition traffic, keeping existing sessions stable and only routing new sessions to the cloud when on-prem cluster limits are approached to avoid churn.
With the above model, bandwidth-heavy platforms regularly yield savings that hit double-digit percentages; up to 40% is common, considering a large chunk of the bill is driven by base traffic. There is no need to seek additional procurement, either, as the dedicated setup grows with you deliberately, while the cloud handles the unpredictable side.
Melbicom operates with 21 global locations, provisioning dedicated servers with an integrated CDN in 50+ locations to simplify the pattern, letting you anchor your origins local to your audience on our dedicated hardware, bursting only when needed.
Hardware Acceleration & Next-Gen Codecs
Scaling up means more servers, but more importantly, it means smarter servers to do the heavy lifting, which in modern streaming is transcoding single contribution feeds into renditions for adaptive bitrate ladders. Real-time 4K ladders are a tough task for CPUs alone; hardware encoders make it a different ball game.
- GPUs deliver throughput at a higher magnitude, allowing multiple 4K ladders per node with headroom to become a reality. Published tests show ~270 FPS vs ~80 FPS for certain 4K pipelines, almost triple the speed.
- AV1 and HEVC bring 30–50% bitrate savings when compared to older codecs; however, without hardware assist, software AV1 encoders can crawl at ~0.032 FPS, implying ~746× the compute for real-time 24 FPS.
- I/O and NICs. With multi-10-GbE and 25/40/100 GbE NICs, a single node is able to push tens of gigabits. That can be paired with NVMe and RAM caches to pull popular segments from memory-speed storage. Melbicom’s per-server ports reach up to 200 Gbps, preventing bottlenecks in the network.
All of this can then be tightened through edge placement. RTT can be trimmed by moving caches and GPU-assisted transcoders closer to viewers. The difference between a distant origin and a regional edge is dramatic; 200–300 ms round-trip times can be reduced to around 25 ms. When serving from closer metro-edge nodes, platforms report latency reductions in the region of 20–40%. The hardware acceleration and minimization of distance work hand in hand to reduce start times and lower rebuffer ratios during surges.
Delivering Content Globally via CDN + Distributed Origins

You can’t serve all viewers the same experience from a single facility, but CDNs can cache segments in the users’ region and keep experiences smooth. That way, the origin doesn’t serve each request, and each major region is served by distributed origins. For VOD, hot content is held by edges, and for live, edges relay segments seconds after creation.
Design aspects that scale well:
- Multiple origins per region eliminate single-point failures locally.
- Geo-routed entry ensures sessions land near viewers, preventing long-haul congestion.
- Efficient replication makes sure that published titles and live ladders appear at edges without thrashing the origin.
Creating this origin-plus-edge footprint is easy with Melbicom’s CDN that spans 50+ locations, integrated with dedicated servers in 21 data centers. Opting for Melbiсom means cross-continental consistency without multiple vendors and an origin that is controlled during surges.
Blending Everything Together
High-traffic streaming can be problematic for systems which have a direct impact on business. Coping with the bandwidth-heavy throughput requires a reliable, cost-effective plan that looks like this: Dedicated servers for predictable, always-on loads; horizontal fleets with load balancing; HA clusters and multi-region failover; and a hybrid infrastructure that sends rare spikes to the cloud. You also need hardware acceleration to assist with 4K/AV1 and CDN-first delivery. Following this blueprint, you have an architecture engineered to absorb audience spikes without any disgruntled viewers or soaring bills.
The right architecture also needs the right operational posture; the best hardware in the world can´t help you handle those high-traffic streams if it isn´t being utilized correctly. So be sure to measure your p95 start time, rebuffer ratios, and per-region error budgets. You can wire autoscaling to real signals and practice failover to stay ahead. Remember to place capacity near demand, which will naturally lower latency; the compounding effect is higher engagement that justifies broader distribution, which lowers latency further. Single-tenant hardware is the bedrock for scaling.
Scale with Dedicated Servers
Provision high-performance dedicated servers worldwide and handle traffic surges with confidence.