Blog

Scaling Blockchain Analytics & Indexing with Dedicated NVMe-Powered Servers
Blockchain analytics has hit a true big‑data scale. A pruned Ethereum full node now holds 1.4 TB of data, up more than 22% year‑over‑year, based on Etherscan metrics tracked by YCharts. Archive‑style Ethereum nodes can require over 21 TB of disk, and Solana’s ledger has already exceeded 150 TB of history. Ethereum alone processes roughly 1.5–1.6 million transactions per day, more than 23% higher than a year ago.
On the demand side, the crypto compliance and blockchain analytics market is projected to grow from $4.4 billion in 2025 to nearly $14 billion by 2030 (25.85% CAGR). Put together, that’s more chains, more activity, and far heavier datasets landing on your infrastructure every month.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Keeping up with that reality requires high‑performance dedicated servers: multi‑core CPUs, large RAM pools, fast NVMe SSDs, and serious bandwidth in predictable, single‑tenant environments. Melbicom builds specifically for this profile with single‑tenant servers across 21 Tier IV/III data centers, a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs, and 55+ CDN PoPs in 36 countries that push data closer to users.
Blockchain and Analytics
A blockchain is an append‑only log of everything that has ever happened: transfers, swaps, liquidations, governance votes, NFT mints. Blockchain analytics is about turning that log into structured data that powers dashboards, risk models, and compliance workflows.
Most serious stacks follow an ETL pattern:
- Extract blocks, transactions, logs, and state diffs from nodes across many chains.
- Transform them into normalized tables (addresses, token transfers, positions, fees).
- Load them into OLAP engines, column stores, or time‑series databases for aggregations.
Academic work on blockchain data analytics repeatedly highlights scalability, data accessibility, and accuracy once datasets reach multi‑terabyte size. Add multi‑chain and multi‑year history, and you’re firmly in big‑data territory.
In practice, modern platforms resemble web‑scale analytics systems: parallel ETL workers feeding NVMe‑backed warehouses, with query engines distributing scans across many cores. The bottleneck stops being “can we parse this?” and becomes “can our infrastructure ingest and query on‑chain data fast enough?”
What Server Specs Maximize Blockchain Indexing Throughput
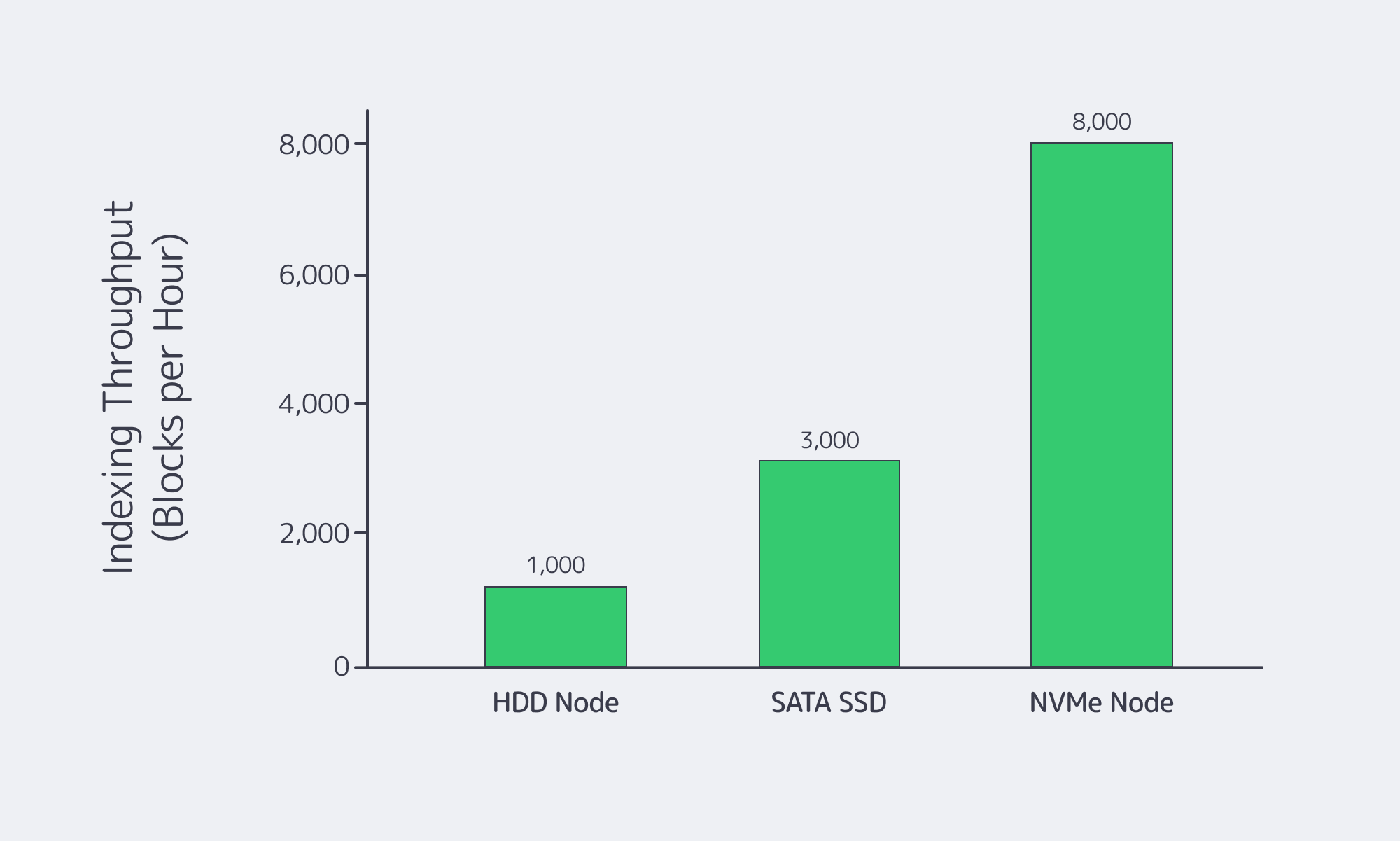
You want high‑core, high‑clock CPUs paired with generous RAM, NVMe SSDs, and high‑bandwidth networking on dedicated servers. That combination lets you parallelize indexing and ETL, keep hot state in memory, and avoid disk or network bottlenecks as chains, users, and queries scale.
CPU and Parallelism
Indexers parallelize naturally: one process per chain, per contract family, or per ETL stage. A 32‑ or 64‑core CPU lets you run many workers concurrently, while single‑thread speed still matters for replaying blocks and verifying signatures.
For Ethereum‑style workloads, the sweet spot is having many strong cores. We at Melbicom lean on the latest‑generation AMD EPYC options in Web3‑optimized builds so multiple nodes and ETL workers can share a host without sacrificing per‑thread performance.
Memory and Caching
Memory is the first line of defense against slow storage. Node clients and indexers cache as much state as RAM allows so they don’t hit disk on every lookup. Operator guides explicitly warn not to “skimp” on memory because extra RAM directly reduces disk I/O.
For multi‑chain analytics, 64–128 GB is a practical baseline, while high‑throughput chains such as Solana often push validators and RPC nodes toward 256 GB+ configurations. That headroom benefits both nodes and analytics engines by keeping large joins in memory instead of thrashing NVMe.
Storage, Network, and Why NVMe Is Non‑Negotiable
Storage and network are where indexing pipelines either fly or stall. Full and archival nodes on major chains now routinely sit in the multi‑terabyte range. That load makes storage throughput and network latency first‑class constraints.
Fast NVMe SSDs are effectively mandatory. Node‑operator guides recommend NVMe over SATA SSDs and warn that network‑attached storage introduces latency that is “highly detrimental” during sustained writes. On the network side, guidance for high‑throughput validators and RPC nodes calls for 10 Gbps or better connectivity and low‑latency routing.
Melbicom’s backbone is designed around those requirements: more than 14 Tbps of capacity, 20+ transit providers, 25+ IXPs, and per‑server ports up to 200 Gbps in most DC locations. That combination keeps nodes in sync with chain heads and absorbs traffic spikes from analytics APIs.
Dedicated, Single‑Tenant Environments
Dedicated servers remove noisy‑neighbor effects and hypervisor overhead that can skew latency and throughput. For long‑running node and ETL processes, that predictability is crucial: when you profile a bottleneck, you know it comes from your schema or code, not someone else’s workload.
Melbicom’s Web3‑ready configurations are single‑tenant by default and spread across 21 Tier IV/III locations in Europe, the Americas, Asia, the Middle East, and Africa, so teams can place heavy analytics nodes close to users and liquidity.
Table 1. Server Components That Actually Move the Needle
| Component | Role in Pipeline | Why High‑End Specs Matter |
|---|---|---|
| CPU (Cores & GHz) | Runs node clients, parsers, ETL workers | More cores and faster threads cut block processing time. |
| RAM | Caches state and query working sets | Large memory reduces disk hits during indexing and queries. |
| NVMe SSD | Stores chain DBs and analytics datasets | High IOPS keeps multi‑TB syncs and scans responsive. |
| Network Uplink | Moves blocks in and query results out | 10–200 Gbps links prevent sync lag and API timeouts. |
| Single‑Tenant Dedicated Hardware | Provides isolated, predictable resources | Dedicated servers avoid noisy neighbors and virtualization drag. |
Which NVMe Configuration Speeds On-Chain Analytics Queries
You want fast, local, enterprise‑grade NVMe—often more than one drive—and a layout that separates hot analytics reads from heavy write paths. Avoid cheap, DRAM‑less or QLC models, and keep network storage out of the critical query path whenever possible if you care about latency, stability, and query speed.
Multiple NVMe Drives for Parallel I/O
Analytics workloads are highly parallel: workers scan different partitions while nodes append new blocks and ETL jobs compact or re‑index tables. Spreading that activity across multiple NVMe drives—via separate volumes or RAID0—lets the kernel and controllers service more I/O queues in parallel.
A practical layout:
- NVMe 0: chain databases (Ethereum, L2s, Solana, etc.)
- NVMe 1: analytics warehouse (columnar or time‑series DB)
- NVMe 2: ETL scratch space and logs
This separation prevents a heavy analytical query from starving the node’s state updates.
Enterprise NVMe Over Consumer Shortcuts
Under indexing loads, you’re writing and rewriting terabytes. Consumer QLC drives often fall off a cliff under sustained writes or hit endurance limits early. Node‑hardware guides recommend fast NVMe and warn that cheaper flash “suffers significant performance degradation during sustained writes,” with network storage adding harmful latency on top.
Enterprise-grade TLC NVMe SSDs with DRAM caches and high TBW ratings are a safer baseline. They help keep IOPS high even while you backfill years of history and serve live queries at the same time.
Local NVMe Plus Object Storage for Cold Data
Not every byte needs NVMe forever. Historical partitions older than a certain horizon may see limited traffic outside audits and backtesting.
A pragmatic design is:
- Keep the active window (recent blocks and hot tables) on local NVMe.
- Offload older partitions and periodic snapshots to S3‑compatible object storage.
Melbicom’s S3‑compatible object storage runs in a Tier IV certified Amsterdam data center, uses NVMe‑accelerated storage, and offers plans from 1 TB to 500 TB with free ingress. That keeps the hot analytics tier lean and fast while still retaining full history for compliance and long‑horizon research.
DeFi Llama and Blockchain Analytics
DeFi Llama shows what scaled blockchain and analytics looks like in production. The platform tracks DeFi metrics across hundreds of chains and thousands of projects and pools, which is only possible because indexing is continuously happening underneath every chart, table, and leaderboard users see.
Much of that work flows through The Graph. Many protocols expose subgraphs; DeFi Llama queries those instead of raw nodes. The Graph’s network has processed more than one trillion queries and supports thousands of active subgraphs across DeFi, NFTs, DAOs, gaming, and analytics.
Behind the scenes sit full and archival nodes, indexers that parse events into structured stores, and query engines that fan out across cores and NVMe to answer user requests. Any team aiming to provide similar multi‑chain views has to assume that per‑chain data volumes, query concurrency, and historical lookback windows will keep climbing—and size infrastructure accordingly.
Scaling Blockchain Analytics With High-Performance Servers

On‑chain data volumes are not slowing down. New L1s, L2s, and app‑chains add their own multi‑terabyte histories, while existing networks keep compounding. The only sustainable way to keep ETL jobs and queries in step with reality is to run them on high‑performance dedicated servers rather than undersized, oversubscribed instances.
Multi‑core CPUs let you parallelize ingestion and transformation. Large RAM footprints keep hot state and query working sets in memory. NVMe SSDs keep multi‑terabyte syncs and scans practical. High‑bandwidth, well‑peered networks prevent your nodes from falling behind chain heads or rate‑limiting analytics traffic.
For teams designing or scaling analytics pipelines, a few principles stand out:
- Design for multi‑chain growth. Plan for dozens of chains and terabytes of new data per year from day one.
- Make NVMe mandatory. Use multiple NVMe drives and clear hot/cold storage tiers; don’t rely on network storage for hot paths.
- Treat bandwidth as a product feature. 10 Gbps+ uplinks and clean peering reduce sync times and API latency under load.
- Choose predictable, single‑tenant servers. Deterministic performance simplifies capacity planning, SLOs, and debugging.
Scale blockchain analytics with Melbicom
Deploy high‑core CPUs, NVMe storage, and 10–200 Gbps networking across 21+ data centers. Get predictable, single‑tenant performance for nodes, ETL, and OLAP.