Blog
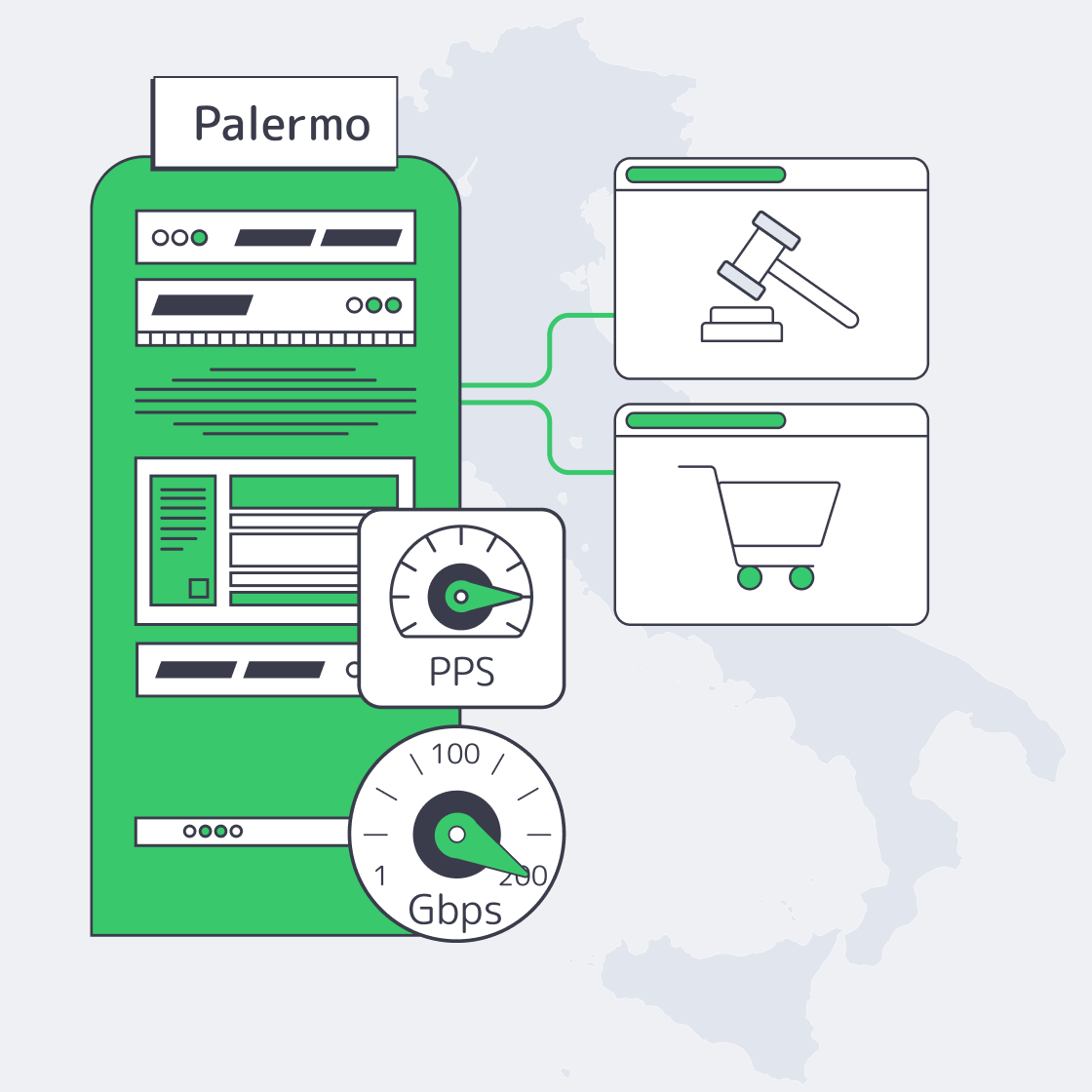
Designing Predictable Egress for Italy Servers
Ultra‑HD streaming and programmatic advertising share a constraint: egress you can actually deliver. Video represents 80%+ of global internet traffic, while AdTech stacks drive bursts of small requests where packet handling—not raw bandwidth—sets the ceiling. Italia is increasingly viable for both when you treat the server, kernel, NIC, and upstream connectivity as one system.
Here’s the practical playbook: metered vs. unmetered egress, how to measure real throughput (`iperf3` and HTTP), how to reason about PPS limits, and how the results map to NIC choice, kernel tuning, peering/IX strategy, and origin‑to‑CDN design.
Choose Melbicom— Tier III-certified Palermo DC — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
 |
Sizing a Server in Italia for Predictable Egress
Plan for two bottlenecks: throughput (Gbps) for origin fill and video delivery, and packet rate (PPS) for auctions, beacons, and fan‑out control traffic. A port can look huge on paper but underperform if the cost model is metered, the kernel is untuned, the NIC can’t parallelize queues, or upstream paths are congested.
Which Italy Servers Offer Best Unmetered Egress Rates

Unmetered egress is usually the most defensible answer when outbound traffic is high and spiky: you pay for a fixed-capacity port instead of per‑GB fees, so costs stay stable while performance becomes an engineering problem you can measure, tune, and forecast—rather than a billing surprise that explodes during peaks.
Cloud egress metering turns traffic volatility into budget volatility. The same workload can be cheap one month and painful the next—and finance doesn’t care that the spike was “a good problem.” The simplest way to de-risk is to buy capacity as capacity.
Metered vs. Unmetered: The Part Your Budget Actually Feels
(For the metered examples below, we’re using an Oracle public egress-cost reference point to illustrate how quickly per‑GB pricing turns spikes into line items.)
| Traffic scenario | Metered cloud cost (est.) | Unmetered capacity needed |
|---|---|---|
| Steady 10 TB outbound / month | ≈ $880 (Oracle) | ~0.3 Gbps port |
| Surging 100 TB outbound in one month | ≈ $7,000 (at ~$0.07/GB) | ~3 Gbps port |
| Massive 300 TB peak traffic event | ≈ $20,000+ (at ~$0.06/GB) | ~10 Gbps port |
On the unmetered side, the key question is: does the provider deliver the port rate to real networks, consistently? Melbicom’s Palermo facility is listed at 1–40 Gbps per server and frames bandwidth as guaranteed (no ratios). That matters for streaming origins and ad delivery systems that can’t “pause” egress when a bill looks scary.
Why an Italy Dedicated Server Can Be a Cost-Control Lever
- Mediterranean geography: Palermo sits on major subsea routes and can cut 15–35 ms versus mainland Europe for parts of Africa and the Middle East. Less tail latency means fewer retries and more stable delivery.
- Operational burst capacity: Melbicom offers dozens of servers ready for activation within 2 hours, which helps when a “temporary” spike becomes the new normal. Custom configurations are deployed in 3–5 business days.
Traffic Spikes: Capacity + Cost Worksheet
Use this worksheet to translate a spike into required port headroom and metered egress exposure. Keep inputs honest: peak origin rate, duration, and your cache hit ratio (because cache misses are what light up origins).
Sanity checks: 1 Gbps sustained is ~10 TB/day; 10 Gbps is ~324 TB/month at full tilt.
| Peak outbound (Gbps) | Duration (hours) | Data moved (TB) | Metered egress cost ($) | Recommended port (Gbps) |
|---|---|---|---|---|
| 10 | 6 | 27.0 | TB×1024×$/GB | 10–20 |
| 20 | 3 | 27.0 | TB×1024×$/GB | 20+ |
Formulas:
- Data(TB) ≈ Gbps × 0.45 × hours
- Metered cost($) ≈ Data(TB) × 1024 × ($/GB)
How to use it: If you rely on a CDN, plug in the origin rate during cache-miss storms (deploys, cold edges, token rotation, regional outages). That number is usually higher than your “average day” dashboards suggest.
What Kernel Tuning Optimizes Streaming Throughput And Latency
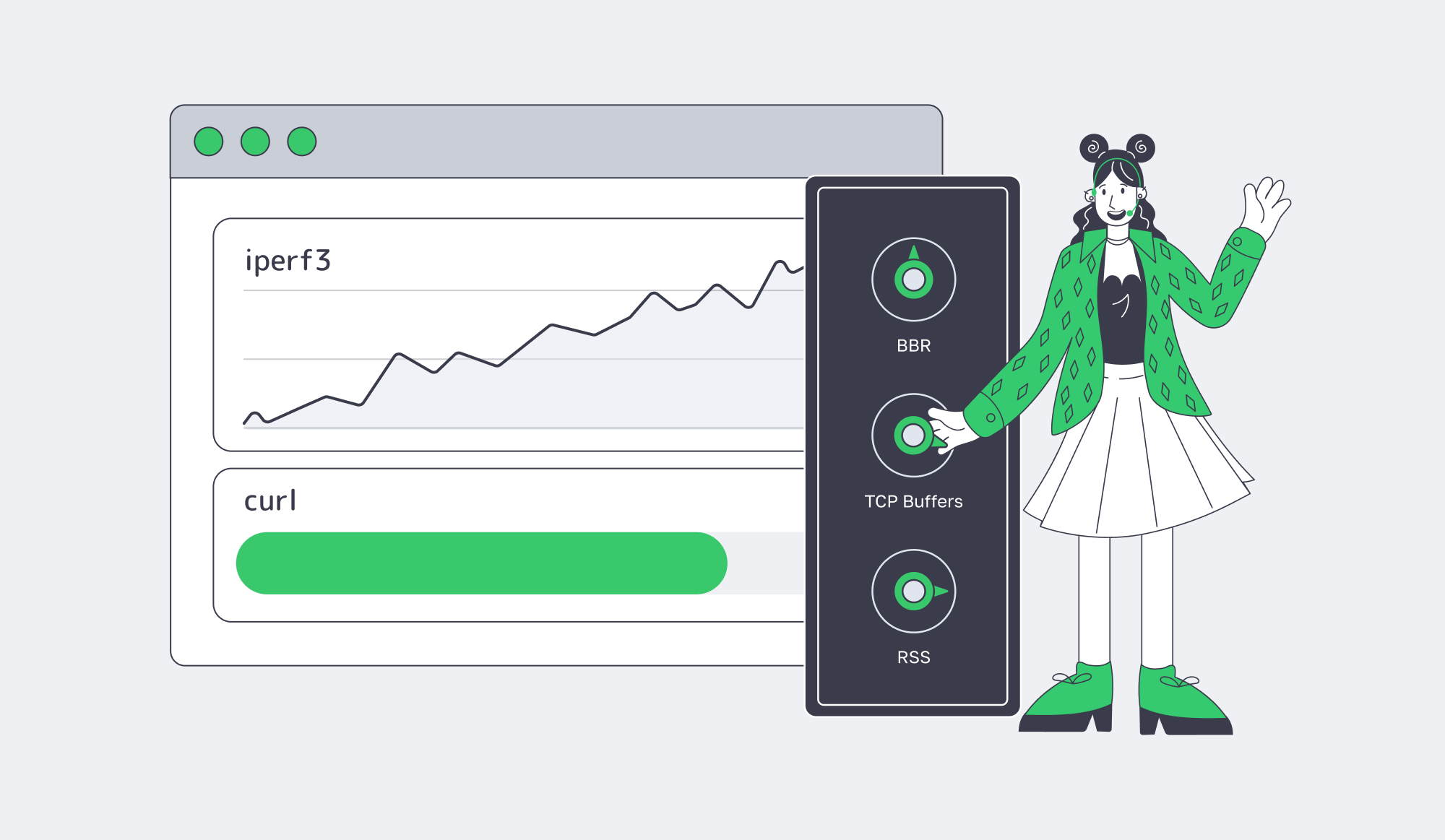
Kernel tuning that matters removes invisible ceilings: pick a modern congestion control (often BBR), increase TCP buffers/window scaling, and spread NIC work across CPU cores so a single interrupt queue doesn’t cap throughput or inflate latency under load—especially under high concurrency and real-world RTT variance.
Start by proving you have a ceiling. Untuned 10 Gbps tests often stall around 6–7 Gbps with iperf3, including a reported plateau at 6.67 Gbps until ring buffers and CPU affinity were adjusted. That’s why you benchmark with both synthetic tests and application-layer pulls, and only trust results you can reproduce under realistic concurrency.
Benchmark an Italy Server: iperf3 + HTTP
| # On the server (receiver) iperf3 -s # On the client (sender): parallel streams to fill the pipe iperf3 -c <server_ip> -P 8 -t 30 # HTTP throughput: parallel pulls to simulate segment delivery curl -o /dev/null -L –parallel –parallel-max 16 https://<host>/bigfile.bin |
Then tune what actually moves the needle:
- Congestion control: In results published by Google Cloud, BBR delivered 4% higher throughput and 33% lower latency versus CUBIC, and the same work was credited with 11% fewer video rebuffers.
- Buffers and windowing: Use Red Hat’s high-throughput checklist for
tcp_rmem,tcp_wmem, and socket limits. - CPU/IRQ hygiene: Enable RSS and multi-queue; isolate IRQ handling from hot app cores; raise NIC rings when microbursts drop packets (the “4096 ring” theme shows up in the same tuning thread).
Which NIC Hardware Handles High PPS AdTech Workloads
High-PPS workloads live or die on queues, offloads, and CPU scheduling: choose server-grade NICs with multiple hardware queues and stable drivers, enable RSS and multi-queue early, and validate packet-rate ceilings with synthetic tests so you don’t discover a 1 Mpps wall during a bid flood or beacon storm.
A 10 GbE link can theoretically push 14.88 million packets/sec at minimum-sized frames. Real systems hit software walls: Cloudflare engineers have pointed out vanilla Linux can top out around ~1 Mpps, while modern 10 GbE NICs can do “at least 10 Mpps”. With kernel bypass, the ceiling moves again—MoonGen/DPDK can saturate 10 GbE with 64‑byte packets on a single CPU core.
PPS Reality Check (10 GbE, small packets)

For an Italy server handling AdTech traffic, the practical playbook is: parallelize queues first (RSS + multi-queue), treat offloads as knobs (validate latency impact), and tune rings + interrupt moderation so microbursts don’t turn into drops.
When global routing matters, BGP becomes an architecture tool. Melbicom offers BGP sessions with BYOIP, BGP communities, and full/default/partial route options, which enables routing patterns where path control is part of performance—not a last-min rescue.
Peering, IX Strategy, and Origin-to-CDN Infrastructure Design
Latency budgets are shrinking. Google’s ad exchange requires bid responses within 100 ms, and the same analysis notes many flows aim to keep network transit well under 50 ms to stay safe. That’s why peering and IX presence are performance features: they reduce hop count, avoid congested transit, and make latency variance less random.
Melbicom positions upstream diversity and exchange reach as first-order network inputs: a 14+ Tbps backbone with 20+ transit providers and 25+ IXPs. For streaming, that improves origin-to-CDN fills by reducing “weird paths” and congested transit. For AdTech, it reduces the chance auction traffic detours through oversubscribed routes right when determinism matters most.
CDN design is where the bytes get disciplined. Melbicom runs a CDN delivered through 55+ PoPs in 36 countries. The durable pattern is simple: keep stateful logic on dedicated origins, push cacheable payloads to the CDN, and size origins for the days the CDN isn’t warm—deploys, outages, or sudden audience migration.
Key Takeaways for Predictable High Egress
- Treat egress like a capacity product: pick port tiers that match your peak profile, then measure and tune until you can reproduce the target rate on real paths.
- Benchmark both failure modes early—Gbps (fills/segments) and PPS (auctions/beacons)—because they collapse for different reasons and require different fixes.
- Use `iperf3` to find ceilings, then remove them systematically: congestion control, buffers, IRQ/RSS/affinity, and ring sizing—validated under realistic concurrency.
- Turn PPS into a budget: define “safe” Mpps targets per service, map them to NIC queues/cores, and decide when you need kernel bypass versus “just better tuning.”
- Design origin-to-CDN for the ugly days: cache-miss storms, deploy waves, and sudden traffic migration—then run the worksheet so spikes are planned engineering events, not billing incidents.
Conclusion: Building a Predictable Server in Italia Stack
High-bandwidth delivery isn’t a single purchase decision; it’s a chain. Metered egress can punish success, untuned kernels can quietly cap throughput, and PPS-heavy services can collapse on the wrong NIC or queue setup. The fix is to engineer for predictability: measure, tune, and design for the ugly days—spikes, cache misses, and latency pressure.
That’s where Italia fits: strong geographic positioning for EMEA traffic, viable high-capacity ports, and an ecosystem where the right provider can make egress predictable and performance measurable.
Deploy high‑egress servers in Italy
Ready-to-go dedicated servers in Palermo with 1–40 Gbps unmetered ports, rapid activation, and 24/7 support. Ideal for streaming origins and AdTech workloads that demand predictable egress and low latency across EMEA.