Blog

Pragmatic Cloud Repatriation for Hybrid, Low-Risk Migrations
The public cloud is still expanding, but infrastructure strategy is no longer about moving everything in one direction. It is about placing each workload where its unit economics, latency profile, and control requirements make sense, then preserving the option to move again. Gartner forecasts worldwide public-cloud end-user spending reaching roughly $723 billion and points to hybrid as the mainstream operating model, with data synchronization becoming a central challenge.
The FinOps Foundation likewise reports survey data covering more than $69 billion in cloud spend and shows cost governance widening from cloud-only optimization into a broader Cloud+ model spanning SaaS, licensing, and private infrastructure. Even the repatriation signal is selective: Flexera says only 21% of cloud workloads have been repatriated. That is the point. Repatriation is not a belief system. It is portfolio engineering for workloads whose physics, risk, and spend profile no longer match public-cloud billing.
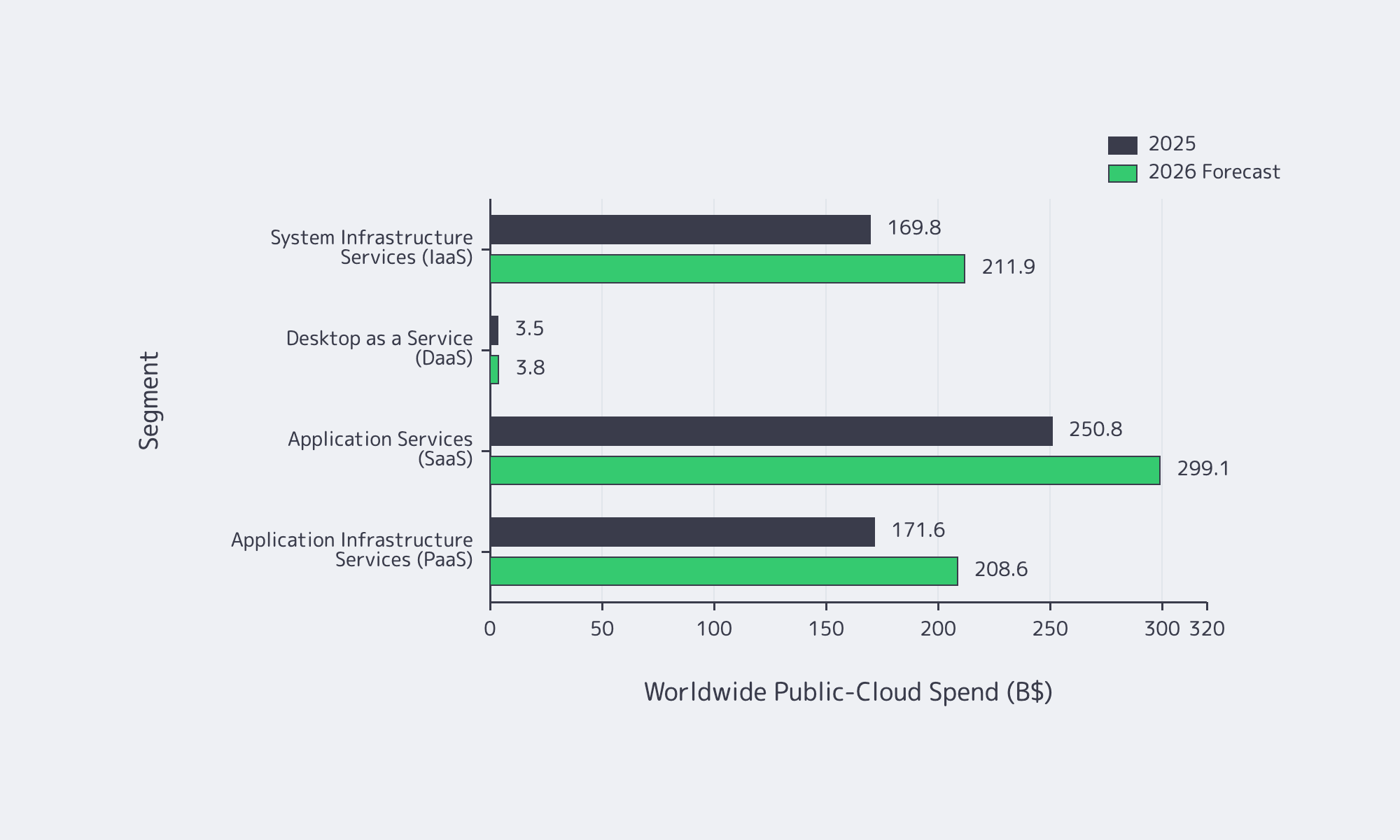
Public Cloud Spend by Segment, Baseline vs. Forecast. Source: Gartner.
How to Identify Which Workloads Are Good Candidates for Cloud Repatriation
Start by scoring each workload on five signals: steady utilization, data gravity, latency sensitivity, sovereignty or compliance demands, and egress pain. Then apply hard disqualifiers, including proprietary managed-service dependence, extreme burstiness, or global edge requirements. The aim is selective placement inside a hybrid estate, not a theatrical cloud exit.
A practical decision framework still does two jobs:
- Identify workloads where dedicated infrastructure improves unit economics, control, and performance predictability.
- Screen out false positives where cloud elasticity, managed-service coupling, or globally distributed execution still wins.
Steady utilization: the shape that breaks pay-as-you-go
Always-on services are where cloud pricing often stops matching workload physics. The signal is simple: utilization charts that look like a skyline, not a seismograph. If the baseline is flat, peaks are small, and the service is sized to a known SLO, the right comparison is steady-percentile unit cost, not list price and not burst pricing. This is where dedicated servers usually become economically legible.
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
 |
Data gravity, latency, and egress pain
Some workloads become expensive not because compute is special, but because the dataset has become the platform. Computer Weekly, citing Wasabi research, reports that 47% of cloud-storage billing is tied to data and usage fees, including operations, retrieval, and egress, and that more than half of respondents exceeded budget. Add distance to the problem and it gets physical fast: a useful rule of thumb is about 5 ms one-way per 1,000 km in fiber. If analytics pipelines, customer exports, partner feeds, or real-time APIs are constantly moving data across regions or out of cloud, the motion itself becomes the tax.
Sovereignty, compliance, and the disqualifiers
For regulated systems, the question is rarely whether cloud is secure. It is whether your team can prove residency, control boundaries, access lineage, and reversibility on demand. CIO’s coverage of repatriation argues that exit plans need to be designed and evidenced through rehearsals, tests, and audit artifacts, not waved away in architecture diagrams.
Treat these as hard disqualifiers, or at least hybrid-only constraints:
- Heavy dependence on proprietary managed primitives that require system redesign rather than migration
- Extreme burstiness or uncertain growth where infrastructure overprovisioning will cost more than elasticity
- Global edge requirements that would force you to rebuild a footprint you cannot yet operate safely
How to Model the Cost of Moving Workloads from Cloud to Dedicated Infrastructure
Model repatriation in three layers: run costs, change costs, and risk costs. Compute, storage, and network matter, but so do staffing, platform tooling, dual-run overhead, and downtime exposure. The real comparison in cloud vs dedicated servers is billing shape plus operating load, not a simplistic server-bill-versus-cloud-bill spreadsheet.
Cloud vs dedicated servers: the real comparison is billing shape and operating load
This is where finance and platform teams usually talk past each other. The useful questions are: do you want variable unit cost or predictable unit cost for this workload shape, and which environment meets the SLO with less operational drag? Flexera reports that multi-cloud adoption sits around 89%, which means many estates already pay an invisible tax in duplicated tooling, cross-environment data movement, and fragmented accountability. The surprise charges tend to sit below the waterline: API calls, retrieval, telemetry, and day-to-day egress.
A cost model table that finance and platform teams can both live with
Use this as a working baseline.
| Cost component | How to model it | Forecast breaker |
|---|---|---|
| Compute run cost | Dedicated server costs by environment, plus growth headroom, compared against the cloud commitments the workload already uses | Teams compare against an optimized cloud future state but fund repatriation as if change is free |
| Storage run cost | Primary, replica, backup, and snapshot or object-storage retention | Storage is not just GB-month; operations, retrieval, and data path design can dominate |
| Network and data movement | Internet transit, private connectivity, and recurring north-south and east-west traffic | Egress is rarely a one-time migration event; it often becomes a chronic operating cost |
| Platform tooling | Observability, CI/CD, artifact storage, secrets, and security tooling | Dual-run often inflates license counts and telemetry volume precisely when budgets are under the most scrutiny |
| Labor and on-call | Permanent run staffing plus temporary migration staffing and incident coverage | Repatriation creates a temporary two-platform problem; underfunding it turns migrations into incident factories |
| Migration and risk buffer | Discovery, dependency mapping, rehearsals, cutover windows, rollback reserves, and downtime exposure | Programs budget for the final cut, then discover too late that rehearsal cadence is what made rollback real |
Where Melbicom fits into the cost model
Melbicom becomes relevant when the dedicated layer has to be forecastable as well as technically usable. We offer more than 1,300 ready-to-go dedicated server configurations, custom builds in 3–5 business days, and deployment across 21 global locations in Tier III and Tier IV facilities, which is exactly what matters when a team needs production-like replicas, dual-run capacity, and a migration calendar that does not reopen procurement every week.
How to Execute Cloud Repatriation with Low Downtime and Rollback Protection
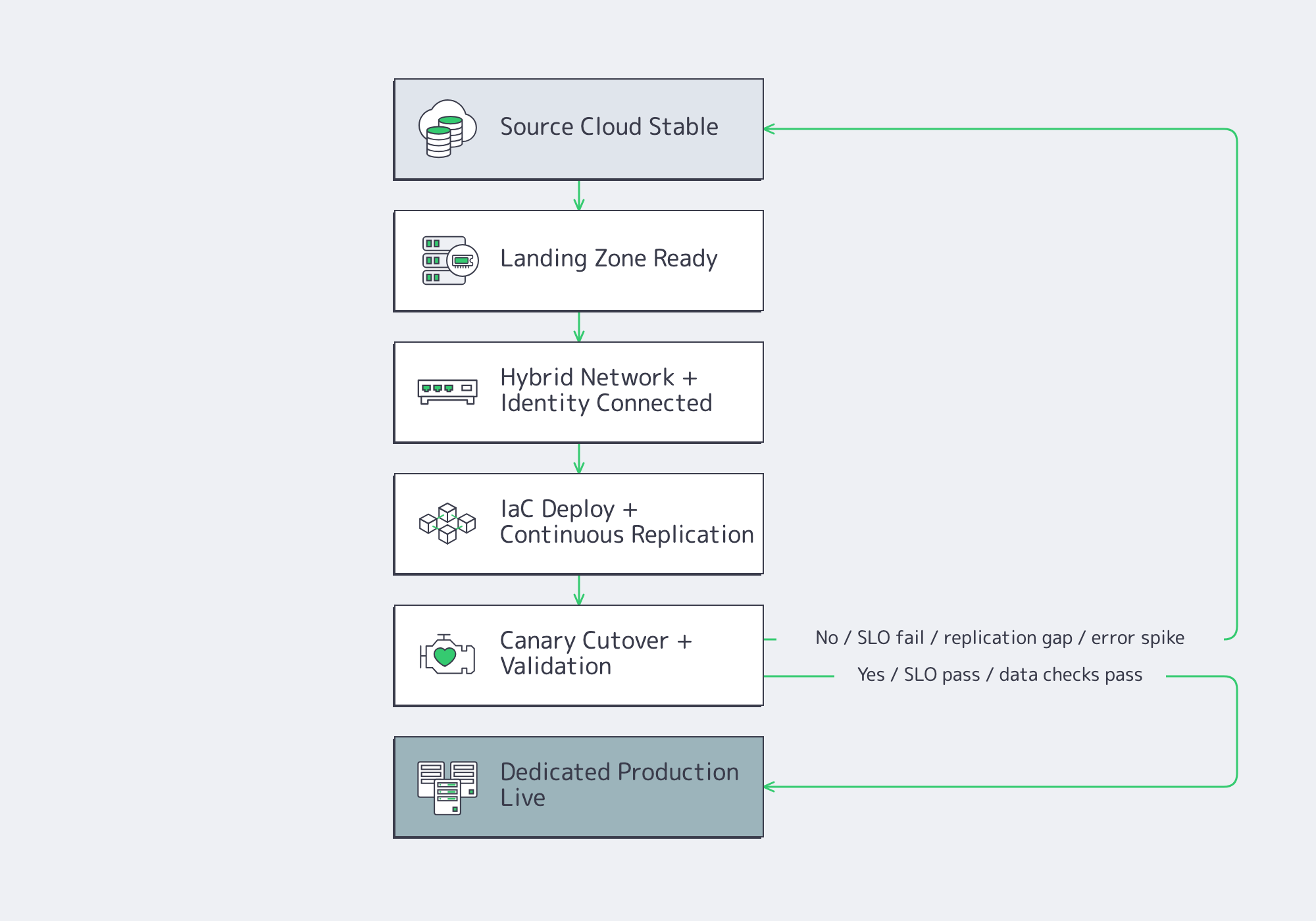
Execute repatriation as a reliability program. Build the landing zone first, connect it cleanly, automate it with infrastructure as code, replicate data continuously, shift traffic progressively, observe both environments at once, and keep rollback technically viable until production behavior proves the new placement is safe.
Build the landing zone like a product, not a rack
The target environment should arrive with a tenancy model, identity integration, image baselines, secrets handling, artifact storage, and backup strategy already defined. This is why control surfaces matter. Melbicom’s platform includes an API, a control panel, and isolated management access over VPN, which makes automation and failure recovery far less improvised than the old ticket-and-spreadsheet model.
Networking and traffic steering: plan for hybrid, not a cliff-edge
The safest cutovers do not flip traffic like a switch. They stage it. Start with replication paths that can tolerate real data volume, move to canaries, then small slices of production traffic, and keep the old path healthy until the new one proves itself. For internet-facing migrations, Melbicom supports BGP sessions that help preserve IP continuity for allowlists, partner integrations, and route control. Where origin load or geographic spread is the risk, Melbicom’s CDN can reduce exposure during staged cutovers.
IaC, data sync, observability, and rollback
Infrastructure as code is the foundation of believable rollback. If the target cannot be rebuilt cleanly, rollback becomes an argument instead of an action. For stateful systems, low-downtime execution usually means continuous replication, a narrow freeze window, validation gates, and explicit rollback triggers. During dual-run, standardized telemetry matters: OpenTelemetry gives teams one way to compare traces, metrics, and logs across both environments. Keep backups and rollback artifacts in neutral storage; Melbicom’s S3-compatible storage helps separate recovery data from the cutover substrate.
Key Takeaways That Keep Cloud Repatriation Pragmatic
The modern repatriation playbook is not “leave cloud.” It is “move the steady core, keep the elastic edge, and preserve reversibility.” That means candidate selection based on workload shape and data motion, cost models that count labor and tooling, and execution plans built like reliability engineering rather than relocation.
The business case gets easier to defend when the economics are steady enough to be visible. Ahrefs’ widely cited estimate of roughly $400 million in avoided IaaS spend over three years is an outlier, but the lesson holds: long-running workloads punish vague placement decisions.
- Rank your candidates by workload shape and data motion together as either signal alone can mislead.
- Fund dual-run and rollback rehearsals as planned work, not contingency overhead.
- Default to hybrid placement: move steady cores deliberately, and keep bursty or edge-heavy components where elasticity still pays.
Plan Cloud Repatriation with Melbicom
Run hybrid migrations on predictable, dedicated infrastructure. Get 1,300+ server configs, rapid custom builds, 21 global locations, BGP support, and CDN reach to stage traffic safely.