Blog

Dedicated Multi-Region Infrastructure for Oracles and Bridges
Oracle and bridge services live in the gap between deterministic chains and nondeterministic reality: data sources change, networks jitter, servers reboot, and packets occasionally disappear. Yet users and contracts still expect “now,” not “eventually.” In practice, the infrastructure is part of the security model—because when attestations arrive late or inconsistent, trust erodes fast.
Modern oracle and bridge operators already know the hard part isn’t computing the answer; it’s delivering the same answer, everywhere, on time—across multiple chains, regions, and failure modes—without leaking keys or accepting silent data-feed drift.
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
The Infra Problem: Trust Dies in the Jitter
Latency for oracle updates and cross-chain messaging isn’t one number. It’s a stack: ingest → normalize → sign/attest → broadcast → observe finality. Each stage has its own tail latency—and tails are where “near-100% uptime” quietly turns into a reliability incident.
The stakes are not theoretical. Infrastructure that enables millions of dollars in transaction value is less about marketing scale and more about operational expectation: once you’re a dependency, your failure modes become other people’s risk. And cross-chain is no longer a niche edge case. Today’s best practices obsess over operational hardening and key custody.
The takeaway: your latency budget and your failure budget are entangled. If you want fast, consistent delivery, you architect for the tail—not the median.
What Dedicated Infrastructure Minimizes Oracle and Bridge Latency

Dedicated infrastructure minimizes oracle and bridge latency by removing noisy-neighbor contention and by keeping hot-path services (ingest, signing, relays, and chain-facing RPC) on single-tenant machines with predictable CPU and I/O. The best setups treat latency like a budget: pin workloads per region, minimize cross-region hops, and keep failover paths warm—not theoretical.
The Practical Latency Budget: Where “Sub-Second” Gets Spent
- Inbound feed variability: API response jitter, rate limits, TLS handshake churn.
- Disk and queue pressure: state persistence, retry queues, log compaction.
- Cross-region coordination: quorum collection, threshold signing, finality watchers.
- RPC variability: shared endpoints, congestion, request throttling.
Dedicated servers help because you can shape the platform: reserve headroom, keep state on local NVMe, and isolate signing and quorum traffic from everything else.
Web3 Server Hosting That Treats the Network as a First-Class Component
If you’re running web3 applications that depend on real-time updates, your web3 infrastructure is not just compute—it’s routing discipline. This is where multi-region dedicated servers plus predictable networking matter.
Melbicom provides the building blocks that map to oracle/bridge needs: 21 Tier IV/III data centers, a 14+ Tbps backbone, and 20+ transit providers plus 25+ IXPs to reduce propagation delays and jitter between regions.
Example: a Concrete Multi-Region Topology
| Layer | Region Examples | What Matters Most |
|---|---|---|
| Ingest + Normalize | Amsterdam, Frankfurt | Keep collectors close to data sources; buffer aggressively; avoid shared queues. |
| Sign/Attest Quorum | Singapore, Los Angeles | Isolate signing; prefer deterministic I/O; keep quorum traffic on private paths. |
| Broadcast + Observe Finality | Tokyo, Stockholm | Fast chain-facing egress; stable RPC; region-local watchers for tail control. |
Locations above reflect some of Melbicom’s data centers and are shown as examples; pick regions that match the chains and venues you’re servicing.
Which Multi-Region Server Setup Ensures Near-100% Uptime
A near-100% uptime setup uses at least two independent regions with active-active service, plus a third region as a cold or warm backstop for disaster recovery. Critical services—signing, relays, and finality observation—should fail over automatically with stable endpoints, while state replication is continuous and tested. Uptime isn’t a promise; it’s engineered behavior.
Active-Active Isn’t Optional for Oracles and Bridges
The “single region + hot standby” model fails a basic reality check: even brief regional network events can create mismatched observations. For oracle operators, that shows up as delayed updates. For bridges, it shows up as relay lag and message backlog.
The modern pattern is:
- Active-active ingest and observation
- Regional quorum for signatures (threshold or multisig)
- Deterministic failover for client endpoints
The point isn’t only uptime. It’s keeping behavior stable under stress: same inputs, same outputs, same latency envelope.
Stable Endpoints: BGP Sessions, BYOIP, and Controlled Failover
If clients, contracts, or counterparties pin to endpoints, IP churn is operational debt. The clean way out is bringing your own IP space and controlling routing.
Melbicom supports BGP sessions (including BYOIP) so operators can keep endpoints stable while engineering regional preference and failover through routing changes rather than “change the URL and pray.”
What most CTOs care about is not that “BGP exists,” but routing safety and hygiene. This is where Melbicom delivers: RPKI validation and strict IRR filtering for customer routes—important guardrails when uptime is tied to the integrity of your route announcements.
State Replica That Doesn’t Become a Latency Tax
Replication is where good architectures die: either you replicate too slowly and failover loses state, or you replicate too eagerly and build a constant cross-region latency bill into every request.
A pragmatic pattern is asynchronous replication with fast catch-up and explicit RPO/RTO targets. That can be as simple as structured logs + object snapshots, or as involved as streaming replication—what matters is predictability and observability.
# Example: lightweight feed-state replication (operator-owned logic) # Goal: ship signed artifacts + last-seen checkpoints, not your entire database. rsync -az --delete /var/lib/oracle/checkpoints/ replica:/var/lib/oracle/checkpoints/ rsync -az --delete /var/lib/oracle/signed-artifacts/ replica:/var/lib/oracle/signed-artifacts/ |
When bandwidth is the constraint, location matters. Melbicom offers per-server port speeds up to 200 Gbps in most locations, which lets operators place replication-heavy tiers where the network headroom actually exists.
What Secure Hardware Protects Bridge Keys and Data Feeds
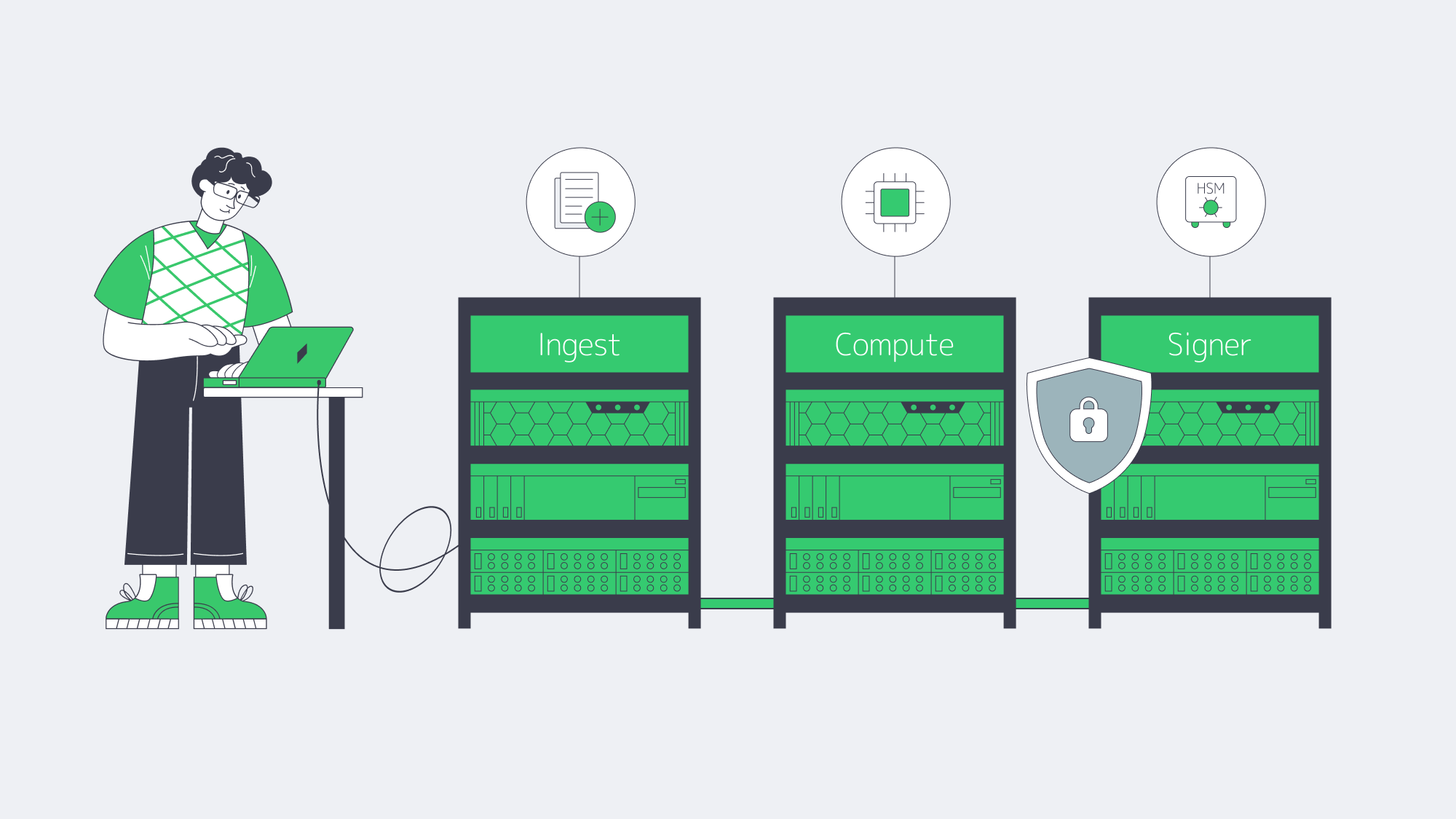
Secure hardware protects bridge keys and data feeds by isolating signing and sensitive processing onto single-tenant machines with locked-down access paths, hardware-backed key custody (such as HSM-backed operations), and strict separation between ingest, compute, and signing roles. The goal is blast-radius control: a compromised service shouldn’t expose keys or rewrite feeds.
Separate the Roles: Ingest ≠ Compute ≠ Sign
Most real incidents start with a “small” compromise: a collector host, a CI runner, a debug port. If ingest and signing share the same blast radius, you don’t have a key-management strategy—you have a hope-based security model.
Best practice is boring and effective:
- Ingest nodes can be replaced quickly; they should not hold signing material.
- Normalization nodes should have restricted egress and strict provenance controls.
- Signing nodes should be isolated, minimal, and auditable.
Dedicated servers make this separation more enforceable because you’re not sharing kernel neighbors or relying on a provider’s abstraction layer for isolation.
Hardware-Backed Key Custody Without Slowing the Hot Path
For bridges and high-stakes oracles, hardware-backed key operations reduce the chance that a software compromise becomes a key compromise. The operational trick is designing it so the signer remains fast and predictable: isolate it, keep it warm, and avoid forcing every request through cross-region round-trips.
Melbicom gives you in-region control and root-level access in Tier III+ DCs, along with stable networking: private links and BGP sessions that help keep the signaling path deterministic.
Data Feed Integrity: “Correct” Must Be Verifiable, Not Just Fast
- Multiple sources with explicit quorum logic
- Signed artifacts with traceable provenance
- Replay protection and deterministic ordering
- Continuous validation (detect drift, missing updates, and timestamp anomalies)
This is the difference between “a fast feed” and “a feed you can defend.”
FAQ
How do I know whether latency is a compute problem or a network problem?
Instrument the hot path end-to-end and split metrics by stage (ingest, normalize, sign, broadcast, finality). If p95 spikes correlate with cross-region hops or RPC response variability, it’s networking and topology—not CPU.
Is multi-region always worth the complexity?
For oracle and bridge operators, yes—because your failure modes are externalized. The complexity is the price of keeping outputs consistent under partial failures.
What’s the minimum multi-region footprint that still behaves well?
Two active regions + one backstop. Anything less turns “failover” into downtime plus cold-start latency.
Where does a CDN fit in this stack
Not for signing or quorum, but for distributing non-sensitive artifacts: dashboards, proofs, snapshots, static content, and client-side assets that should load fast globally. Melbicom’s CDN footprint spans 55+ PoPs across 36 countries.
Bridge Oracle Crypto: Key Takeaways for Low-Latency Trust
- Design for the tail, not the mean. Your p95/p99 latency is what users experience during congestion, RPC turbulence, and partial outages—so measure per stage and budget headroom intentionally.
- Run active-active where correctness matters. Two regions observing and relaying independently reduces “regional truth” drift and prevents one site’s network event from becoming system-wide lag.
- Keep endpoints stable through routing, not DNS scramble. Treat BGP-controlled failover as an operational primitive so clients don’t need reconfiguration during incidents.
- Isolate signing like it’s production finance—because it is. Separate ingest/compute/sign roles and assume any internet-facing node can be compromised.
- Practice failover as a routine operation. Define RPO/RTO, test replay scenarios, and rehearse key procedures so the first “real” failover isn’t also your first experiment.
Trust Is Built at the Speed of Your Infrastructure
Oracles and bridges don’t just use infrastructure—they are infrastructure. When latency spikes, updates arrive late. When uptime wobbles, counterparties lose confidence. And when keys or feeds aren’t protected by design, operational mistakes become systemic risk.
The durable pattern is consistent: dedicated servers for predictable performance, multi-region layouts that keep the hot path close to where it must execute, and hardened signing and data-feed boundaries that keep trust intact even when everything around gets noisy.
Deploy multi-region dedicated servers
Design for the tail with dedicated servers, stable BGP endpoints, and warm failover across regions. Keep keys isolated and updates consistent—without unpredictable jitter.