Blog
Multi-Node High Availability on Italy Dedicated Servers
Downtime isn’t a blip on a status page; it’s a revenue event. Peak-season retail e-commerce outages have been estimated at $1–2 million per hour, while finance/trading downtime can run $5 million+ per hour. That’s why “high availability” becomes a product requirement when checkout or execution is the core flow.
Dedicated infrastructure matters because predictability is a reliability feature: “noisy neighbor” contention can turn p99 latency into a moving target. With server hosting in Italia, geography also matters. Tier III facilities are typically designed for 99.982% availability (~1.6 hours/year), and Palermo’s position on Mediterranean routes can reduce latency to North Africa, the Middle East, and Southern Europe by ~15–35 ms.
Choose Melbicom— Tier III-certified Palermo DC — Dozens of ready-to-go servers — 55+ PoP CDN across 36 countries |
 |
Which Multi-Node Patterns Ensure Italy Dedicated Server Availability
High availability on an Italy dedicated server fleet means designing for inevitable node and network failures—and still hitting SLOs. Use redundant load balancers, an active-active stateless tier, and a data layer that continues after a node loss. Add N+1 capacity headroom, then prove the design with repeatable failover drills and chaos tests.
Load Balancing: Active-Active by Default, With a Redundant Edge
Treat the load balancer as a failure domain, not “just a router.” Run at least two LBs (failover pair or anycast/DNS design), and use health checks that eject sick nodes before they become brownouts. Keep app nodes stateless where possible so a backend can die mid-request without customer-visible downtime.
Dedicated Server Italy: Capacity Headroom as a Hard Requirement
Redundancy without headroom is theater. Design for N+1 so N-1 can still meet peak, and keep steady-state utilization around 60–70% on critical tiers to cover failures plus bursts. Load test the real constraints: DB connection pools, cache miss storms, and downstream rate limits.
Active-Passive Where State Makes It Safer
Some systems should not be multi-writer. Use active-passive for components like certain databases or tightly coupled stateful services—but demand automation: fencing to prevent split brain, automated promotion, and a measured RTO/RPO. If failover requires a human to remember the right commands, uptime depends on pager latency.
Geographic Redundancy: When the Math Forces It
Four nines is where a single building becomes a liability. Multi-location design is a recurring recommendation in reliability guidance. On dedicated servers, that often means an Italy primary plus a second site for disaster recovery, with DNS failover or BGP traffic steering.
Melbicom supports these designs with a backbone above 14 Tbps, connectivity across 20+ transit providers and 25+ internet exchange points, and optional BGP sessions for engineered routing and failover. In Italy, Palermo supports 1–40 Gbps per server, which matters when replication and catch-up traffic spike during incidents.
Chaos Engineering and Failover Testing: Stop Trusting Diagrams
Reliability is empirical. The chaos engineering tooling market had been pegged around $2–3B in 2024 and growing because teams learned the hard way: untested failover is imaginary failover.
Run experiments: kill an app node at peak, force a DB primary switch, sever a replication link, and roll an LB config forward and back. Track detect/route-around/recover times and SLO impact—then automate until drills feel boring.
What Database Quorum Configs Support Zero-Downtime E-commerce Deploys
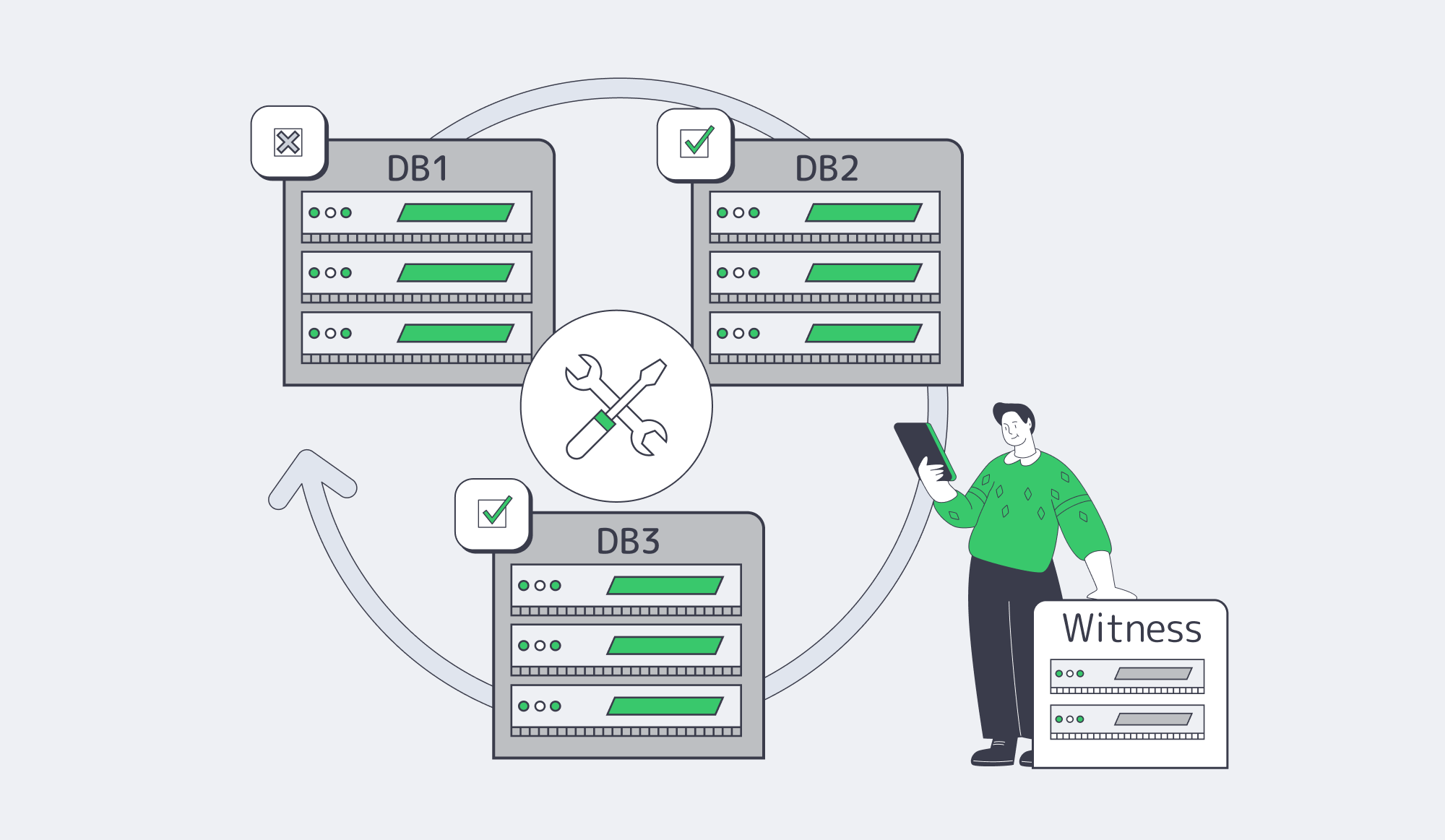
Zero downtime depends on quorum: a database topology where writes commit on a majority so the system keeps serving after a node failure and can be upgraded one node at a time. A three-node (or five-node) cluster avoids split-brain, and a lightweight “witness” can break ties when spanning two sites. Pair quorum with online schema changes and blue-green/canary deployments.
Odd Nodes, Majority Writes, Fewer Surprises
The practical rule is 2f+1 nodes: three nodes tolerate one failure; five tolerate two. Majority (quorum) commits trade a bit of write latency for survivability. If you stretch a cluster across exactly two sites, partitions get ambiguous—hence the witness pattern to prevent 1–1 deadlocks (Yugabyte).
Replication Models: Choose Your Truth About “The Last Write”
For trading and payments, synchronous or semi-synchronous replication is common because losing the last accepted transaction is worse than adding a little latency. Asynchronous replicas still matter for read scaling and distant DR, but they aren’t a substitute for quorum if your effective RPO is near zero.
Zero-Downtime Deploys: Overlap Versions, Shift Traffic, Keep Rollback Hot
Zero downtime is choreography: old and new code must coexist while traffic moves. The standard playbook—blue-green, canary, rolling updates—works because it keeps capacity online while changing software.
A compact pipeline teams can automate:
- Bring up the new version (green) on separate nodes; warm caches and connections.
- Run backward-compatible DB migrations (expand-first; avoid breaking reads/writes).
- Send a small slice of traffic (canary) and watch SLO metrics (error rate, p95/p99, business KPIs).
- Ramp traffic to green; keep the old version ready for immediate rollback.
- Drain and retire old nodes once stability holds.
- Perform “contract” migrations later (dropping old columns, removing flags) once safe.
CDN and Asset Versioning: Prevent “New Backend, Old Frontend” Outages
Many “availability incidents” are cache coherence failures. Version static assets (content-hash filenames) so deploys are atomic by URL, and purge only when required. Melbicom’s CDN footprint—55+ PoPs across 36 countries—reduces origin load so the core fleet has more headroom when something breaks.
From SLO to Redundancy, Alerting, and Runbooks
An SLO is a budget for failure. Convert it into requirements: how many failures you must survive, how fast you must detect them, and how quickly you must fail over.
The math is blunt: small changes in “nines” radically shrink the downtime budget (see the table below; source:Couchbase)). Tier IV targets are often cited around 99.995%, but software still fails—multi-node architecture carries the rest.
| Availability SLO | Max downtime/year (approx) | Typical architecture to meet it |
|---|---|---|
| 99.9% | ~8.8 hours | N+1 in one DC; automated node failover; tested restores |
| 99.99% | ~52.6 minutes | Multi-DC/site design; quorum/replication; automated site failover |
| 99.999% | ~5.3 minutes | Multi-region active-active for critical paths; aggressive automation; constant testing |
Redundancy Requirements: Start From the Worst Credible Failure Mode
List the failures that can violate the SLO: “DB primary dies,” “LB misconfig,” “cache stampede melts DB,” “Italy site loses upstream.” For each, define maximum tolerated user impact and the mechanism that keeps you inside the error budget. If restore-from-backup takes hours, four nines is already gone—replication and fast promotion are non-negotiable.
Alerting System: Page on Error-Budget Burn, Not on CPU Graphs
Burn-rate alerting pages only when users are being hurt fast enough to matter. A commonly cited approach uses 2% of the budget consumed in an hour for paging, and 5% in a day for escalation. Tie these to real user journeys (login/browse/checkout), not just host metrics.
Runbooks: Automate the Repeatable, Document the Dangerous
Every page should link to a runbook that answers: what’s broken, how to confirm, how to mitigate, and how to roll back safely. Test runbooks in game days, and convert repeated manual steps into automation (drain node, promote replica, reroute traffic, disable a feature flag).
Key Takeaways for Multi-Node Italy Deployments
- Write down your top three “revenue killers” (LB failure, DB quorum loss, deploy regression), then map each to a tested mitigation path with owners + RTO/RPO targets.
- Treat capacity as a resilience primitive: run N+1 with enough headroom that a single-node failure plus peak traffic doesn’t trigger rate limiting or queue collapse.
- Standardize a “quorum bundle”: odd-number clusters, explicit fencing, and a witness plan for two-site topologies—then rehearse promotion under load.
- Make deploy safety measurable: canaries gated on SLO burn-rate and business KPIs, with rollback that’s automated and practiced, not “documented.”
- Schedule failure on purpose: monthly game days that include a live failover, plus quarterly chaos experiments that validate assumptions about timeouts, retries, and backpressure.
Conclusion
High availability on dedicated servers is a discipline: assume failure, engineer redundancy, and measure whether failover stays inside the SLO. Load balance what can be stateless, fence and replicate what can’t, and keep enough headroom that “one node down” doesn’t become “everyone down.”
When the architecture is paired with SLO-based alerting and practiced runbooks, incidents stop being existential and start being measurable. That’s the difference between a platform that survives peak traffic and one that headlines it—for the wrong reasons.
Deploy HA Infrastructure in Italy
Build active-active apps and quorum databases on Palermo servers with tested failover, BGP routing, and 1–40 Gbps bandwidth options.