Blog

GPU-First Nodes by IX.br for Brazil Workloads
São Paulo is becoming the landing zone for GPU-heavy workloads that need predictable performance inside Brazil. Brazil has nearly 188M internet users, so latency-sensitive apps, AI inference, and streaming workloads pay a penalty when requests have to cross an ocean.
Choose Melbicom— Reserve dedicated servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
The network side is decisive. IX.br, anchored in São Paulo, connects 2,400+ networks and has pushed past 22 Tbps peaks at the São Paulo exchange. Put GPU compute next to that IX and you’re operating inside the routing decision point where Brazilian networks meet.
| Availability Snapshot | Melbicom: What’s in Place | Why It Matters for São Paulo GPU Workloads |
|---|---|---|
| São Paulo dedicated servers | Capacity is being staged near IX.br to your requested CPU/GPU/RAM/NVMe and port speeds | You can design the node shape first, then scale the pattern. |
| Global capacity + delivery | 21 global Tier III/IV data centers, 55+ CDN PoPs across 36 countries, and 1–200 Gbps per-server ports (by site) | Stage overflow and distribution without breaking Brazil latency paths. |
| Custom builds | Custom server configurations can be deployed in 3–5 business days | Specify exact GPU, storage, and port targets instead of settling. |
Which São Paulo GPU Servers Let You Make the Most of Proximity to IX.br?
The São Paulo GPU servers that best support IX.br are purpose-built compute nodes (EPYC/Ryzen plus NVIDIA GPUs) paired with high-throughput network interfaces and routing control. Prioritize 10+ GbE uplinks, redundant paths, and BGP sessions so traffic stays on local peering routes—turning São Paulo into a low-latency “home region” for Brazil-first workloads.
If your goal is IX.br adjacency, you want a server profile that’s equal parts GPU box and network edge: interface speeds that match real ingestion/egress, plus routing control.
Latency sketch (round-trip time, RTT)
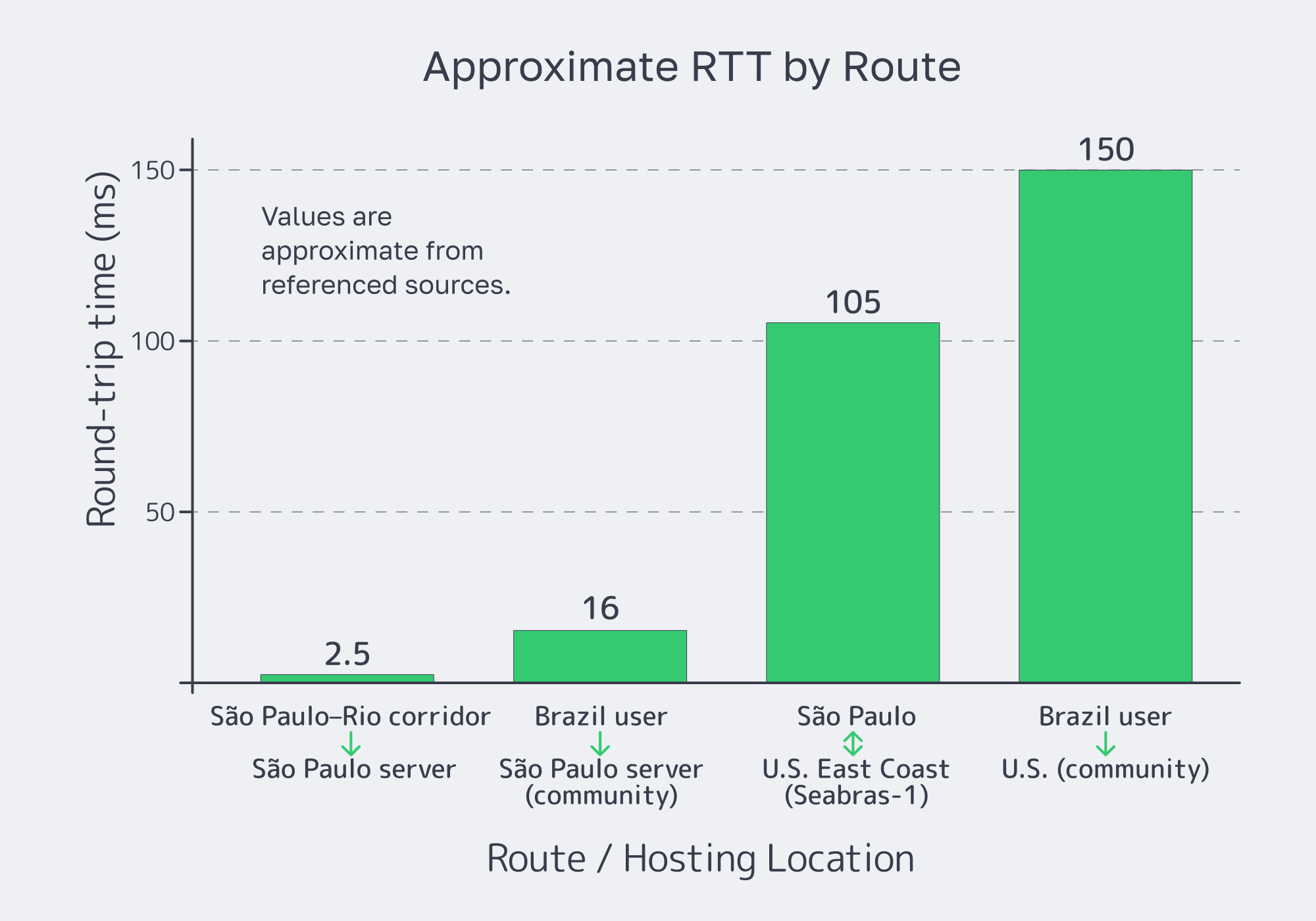
Melbicom frames the macro effect as up to ~70% latency reduction versus hosting the same workload overseas—especially when traffic can stay on domestic peering paths. The engineering win is that “fast” becomes repeatable: with local peering and BGP policy, you can keep critical APIs domestic, route around congestion, and still maintain global reach.
For GPU workloads, the pattern is “compute close, distribute wide.” Run training, feature generation, or transcoding on the São Paulo dedicated server; then push cacheable outputs outward. Regional CDN PoPs absorb delivery spikes for media segments, model artifacts, and dashboard assets, so the GPU node spends cycles on compute—not on re-sending the same bytes.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
What GPU Configurations Optimize Local AI Model Training
Optimized São Paulo training configurations balance GPU memory and throughput with a CPU platform that won’t starve accelerators. EPYC fits multi-GPU and high-I/O nodes (PCIe lanes and memory bandwidth); Ryzen fits single-GPU media and lighter training. Pair either with fast NVMe scratch, enough RAM to keep batches hot, and network headroom for dataset ingress and artifact egress.
Most “slow training” incidents are feed-and-flow failures: CPU → GPU, disk → GPU, network → disk. That’s why the São Paulo build is explicitly oriented around EPYC/Ryzen-class nodes, NVMe-first storage tiers, and port sizing (not “best-effort networking”).
Below are configuration patterns teams commonly request for a dedicated server in São Paulo that can handle model training, accelerated analytics, and media pipelines.
| Pattern (EPYC/Ryzen + GPU) | Best-fit workload | Why it works in São Paulo |
|---|---|---|
| Ryzen + 1 NVIDIA RTX-class GPU + NVMe | Media encoding, near-real-time vision, dev/test training | High clocks plus one large GPU keep latency work close while keeping thermals manageable. |
| EPYC + 2 NVIDIA data-center GPUs + high RAM + NVMe | Training plus accelerated analytics | A throughput “sweet spot” without extreme rack density; enough CPU/memory/I/O to keep loops fed. |
| EPYC + 4–8 NVIDIA data-center GPUs + density plan | High-density training / shared platform cluster | Maximum throughput per rack unit—if the facility can feed and cool it. Treat as a cluster building block. |
Which High Density Dedicated Clusters Improve Analytics Throughput
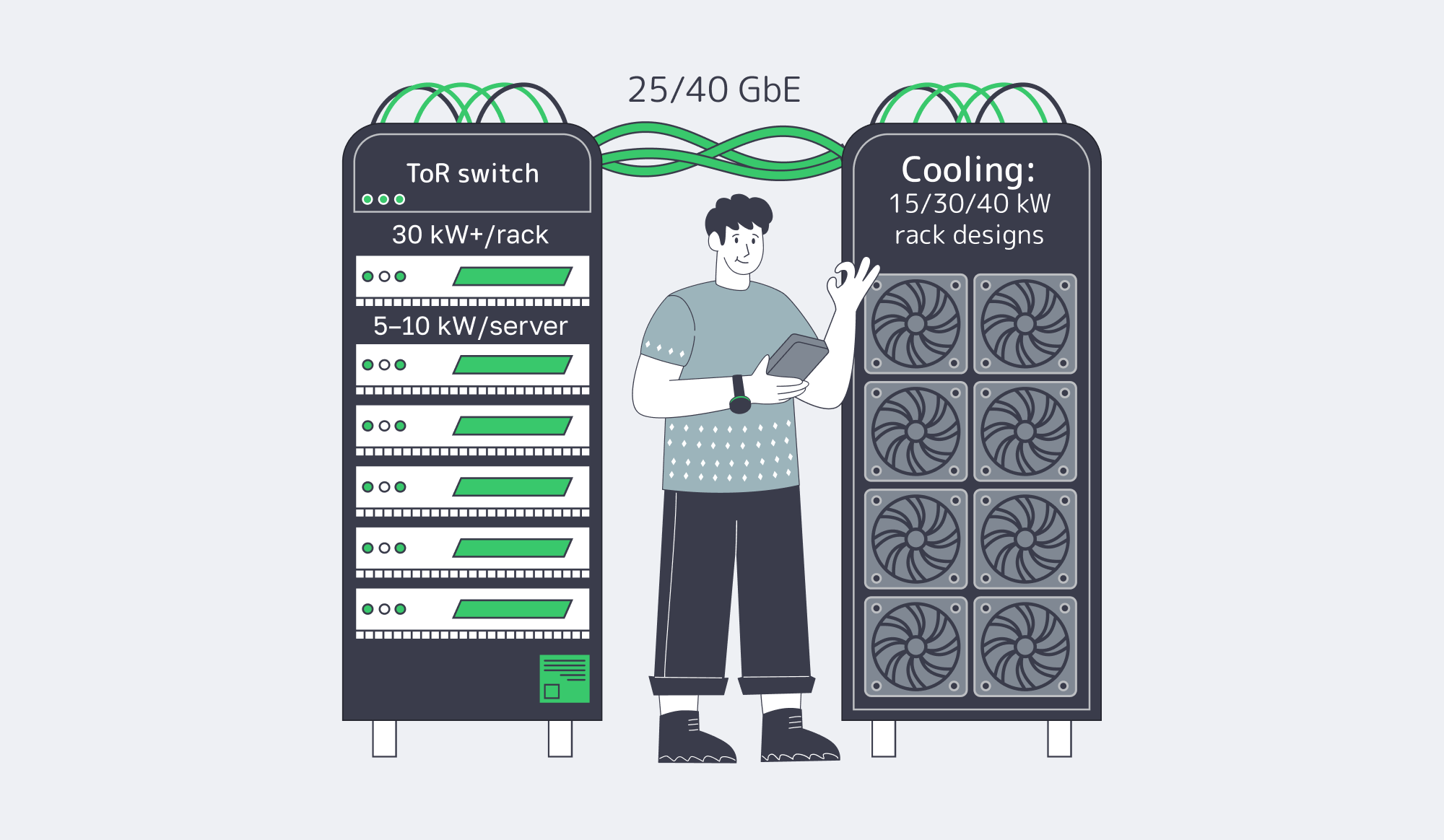
High-density clusters that improve analytics throughput are GPU-forward, network-first designs: multiple EPYC-based GPU nodes connected by 25/40 GbE, with local NVMe tiers and a private east-west fabric. The hard constraints are power, cooling, and acoustics—plan rack density so GPUs don’t throttle, and push distribution work to regional PoPs to keep São Paulo compute focused.
A cluster blueprint that scales cleanly in São Paulo:
- 8–12 identical GPU nodes (EPYC for multi-GPU; Ryzen where single-GPU latency work makes sense).
- 25/40 GbE top-of-rack fabric dedicated to east-west traffic (shuffles, joins, distributed training sync).
- Local NVMe scratch on every node + a shared dataset/checkpoint tier.
- Isolated control plane (deterministic provisioning, pinned driver stacks).
Now the constraints. Standard racks were built around 3–5 kW, while AI/GPU deployments routinely target 10–30+ kW per rack, with individual GPU servers consuming 5–10 kW; as density rises, cooling designs push toward 40 kW and beyond.
This is where “cluster + PoPs” becomes a performance strategy. Keep São Paulo GPUs reserved for computation, and use regional CDN PoPs to absorb repetitive delivery. On the network side, the difference between “local latency” and “local reliability” is upstream diversity: a backbone measured in 14+ Tbps, connected via 20+ transit providers and 25+ IXPs, is what keeps path quality stable when the internet gets weird.
The market tailwind is real. Grand View Research projects the Brazil AI data center market to grow at a 29.5% CAGR (2025–2030), reaching $2.3 billion by 2030.
Key Takeaways for GPU-First São Paulo Deployments

São Paulo plus IX.br is what makes Brazil feel like a first-class region for GPU workloads: low-latency access to local networks, plus the ability to build EPYC/Ryzen GPU nodes that run stable, repeatable pipelines. The forward-looking strategy is to start with a cluster blueprint you can grow, and a distribution layer that keeps GPUs busy.
- Standardize on two node shapes (Ryzen single-GPU and EPYC multi-GPU) so scheduling, spares, and imaging stay boring.
- Treat power and cooling as first-class capacity metrics (kW per server/rack and thermal headroom), not “facility trivia.”
- Use BGP only if you can instrument routes (RTT/jitter baselines, traceroutes, alerting); otherwise it’s just complexity.
- Offload cacheable outputs to the CDN so SP stays compute-bound, not egress-bound.
- Keep a “burst lane” to nearby regions using the global catalog, so São Paulo isn’t your only scaling lever.
Deploy São Paulo GPU servers
Get help selecting GPUs, ports, and IX.br adjacency. We’ll align power, cooling, BGP, and CDN so your São Paulo cluster scales predictably.