Blog

Dedicated Servers for Layer 2 and Rollup Networks
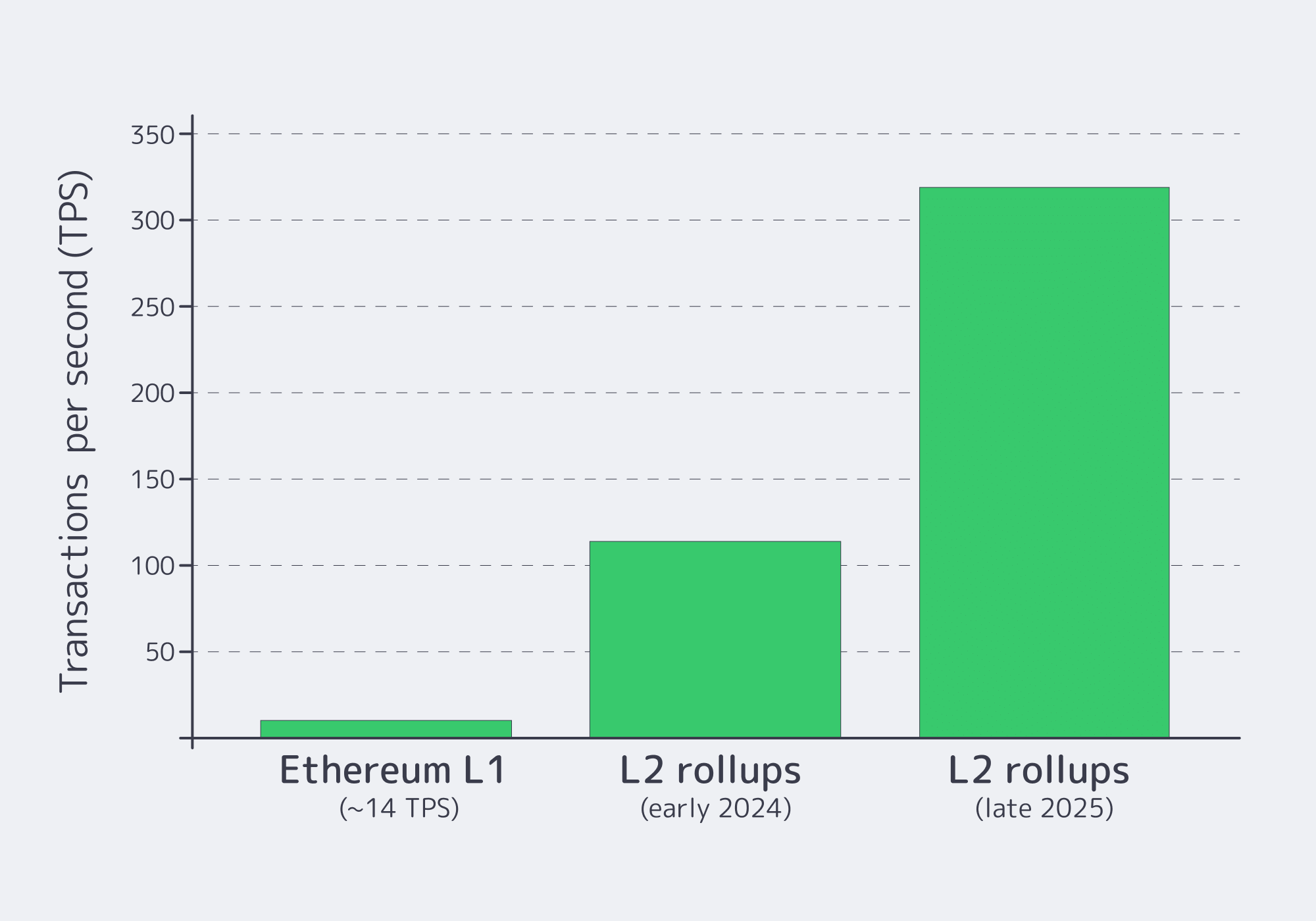
Ethereum’s Layer-2 rollup networks are no longer a side quest—they’re where volume is landing. By early 2024, major L2s were already doing roughly 100–125 transactions per second combined, while Ethereum mainnet sat around ~14 TPS. By the end of 2025, Layer-2 throughput reached roughly 300–330 TPS, about 20× the base layer’s capacity.
That growth doesn’t just stress-test protocol assumptions. It stress-tests infrastructure. A mature rollup network design has two compute cliffs: (1) the sequencer, which must turn a constant mempool into batches on schedule, and (2) the prover, which must turn those batches into zk-proofs fast enough that “finality” doesn’t feel like buffering. Latency to L1 and failure handling decide whether your L2 feels like a product—or a demo.
Rollup Network Design: The Production Pipeline, Not the Whitepaper
A Layer-2 rollup network is a pipeline. Users submit transactions; a sequencer orders them into L2 blocks/batches; the system posts data and state commitments to L1; and correctness is enforced via a fraud-proof window (optimistic) or validity proofs (zk). The sequencer is the piece that orders and produces batches, so its performance directly hits throughput and UX.
The point isn’t to relitigate early “single sequencer” setups—just to acknowledge the lesson: if one box coughs, the chain shouldn’t stop. The infrastructure choices that work at tens of TPS start failing at hundreds, because bottlenecks show up in CPU scheduling, storage latency, network jitter, and operational recovery. That’s why dedicated bare metal—where you control CPU, storage, and the network path end-to-end—shows up in most serious L2 runbooks.
Choose Melbicom— 1,400+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Which Dedicated Servers Maximize Sequencer Node Throughput
Pick a single-tenant box that can execute transactions, compress batches, and submit to L1 without jitter: high-clock, many-core CPU, 128–256+ GB RAM, NVMe state storage, and guaranteed bandwidth (1–200 Gbps per server). The goal is predictable block production and fast L1 submissions under peak load.
Sequencers aren’t “just networking.” They execute state transitions, build batches, and often do CPU-heavy preprocessing like compression. Arbitrum’s docs note the sequencer compresses transaction data with Brotli, and that higher compression levels demand more CPU—enough that the system can adjust behavior when under load. That’s the hardware reality: if the CPU is marginal, throughput becomes a negotiation.
Storage is the other silent limiter. State databases punish slow disks; NVMe reduces I/O stalls and makes restarts less terrifying. Then comes the network. High-activity rollups need to serve user traffic and submit frequent L1 updates, so the sequencer benefits from guaranteed bandwidth and low jitter. Melbicom’s dedicated platform is built around deterministic throughput: Melbicom offers per server ports up to 200 Gbps and 1,400+ ready configurations with ~2-hour activation when a sequencer needs more headroom.
Finally, L1 proximity matters. “Fast sequencing” looks slow if L1 submission is delayed by routing. Melbicom’s backbone runs at 14+ Tbps across 20+ transit providers and 25+ IXPs, which helps reduce propagation delays when your rollup is posting commitments and syncing cross-layer messages.
| Layer-2 node role | Key performance demands | Dedicated server baseline |
|---|---|---|
| Sequencer node (optimistic or zk) | Fast tx execution + batching; low-latency state DB; high-bandwidth, low-jitter path to L1 | 32–64 high-clock cores; 128–256+ GB ECC RAM; NVMe; 10–200 Gbps port (location-dependent); Tier III/IV placement near IXPs |
| Prover node (zk proof generation) | Parallel ZK math; accelerator-friendly; large memory; fast scratch; tight link to sequencer | GPU-ready server where available or 64+ core CPU; 256–512 GB RAM; NVMe scratch; private interconnect; scale-out cluster |
What Hardware Accelerates Zero Knowledge Prover Performance
ZK proving is math-heavy and parallel; speed comes from GPUs, memory, and bandwidth. Use GPU servers (often multi-GPU) with large ECC RAM and fast NVMe scratch space, then connect them to the sequencer over low-latency private links so proofs return quickly enough to keep the rollup moving.
ZK proving is where rollups spend real compute. The operations (FFT, MSM, hashing, field arithmetic) reward parallelism, which is why GPU acceleration is now the default. One performance study reports GPU-accelerated ZK proving can be up to ~200× faster than CPU-only approaches. Paradigm’s survey of ZK hardware points to GPUs as the practical accelerator today and highlights production examples like Filecoin’s proof workloads running on GPUs.
Even with GPUs, proof “time-to-submit” often demands serious CPU and memory for orchestration and witness generation. Ethereum Research captures the scale with a concrete datapoint: one rollup (Linea) reportedly uses a 96-core machine with 384 GB RAM to generate a validity proof for a batch in about ~5 minutes. That’s the budget you’re working with when users expect near-instant confirmations.
When one machine can’t keep up, provers scale out. Ethereum Research also discusses parallelization approaches where 100+ modest nodes could prove a large program in minutes—conceptually promising, operationally brutal without the right interconnect. This is where dedicated infrastructure earns its keep: low-latency, high-bandwidth private links between sequencer and prover (and among prover nodes) keep proof pipelines from collapsing under their own data movement.
Melbicom can deliver GPU-ready single-tenant servers, plus private networking patterns that make prover clusters less theoretical to operate day to day. We at Melbicom can also pair hot-path servers with S3-compatible object storage for colder artifacts—proof outputs, witness archives, and snapshots—so NVMe stays focused on throughput.
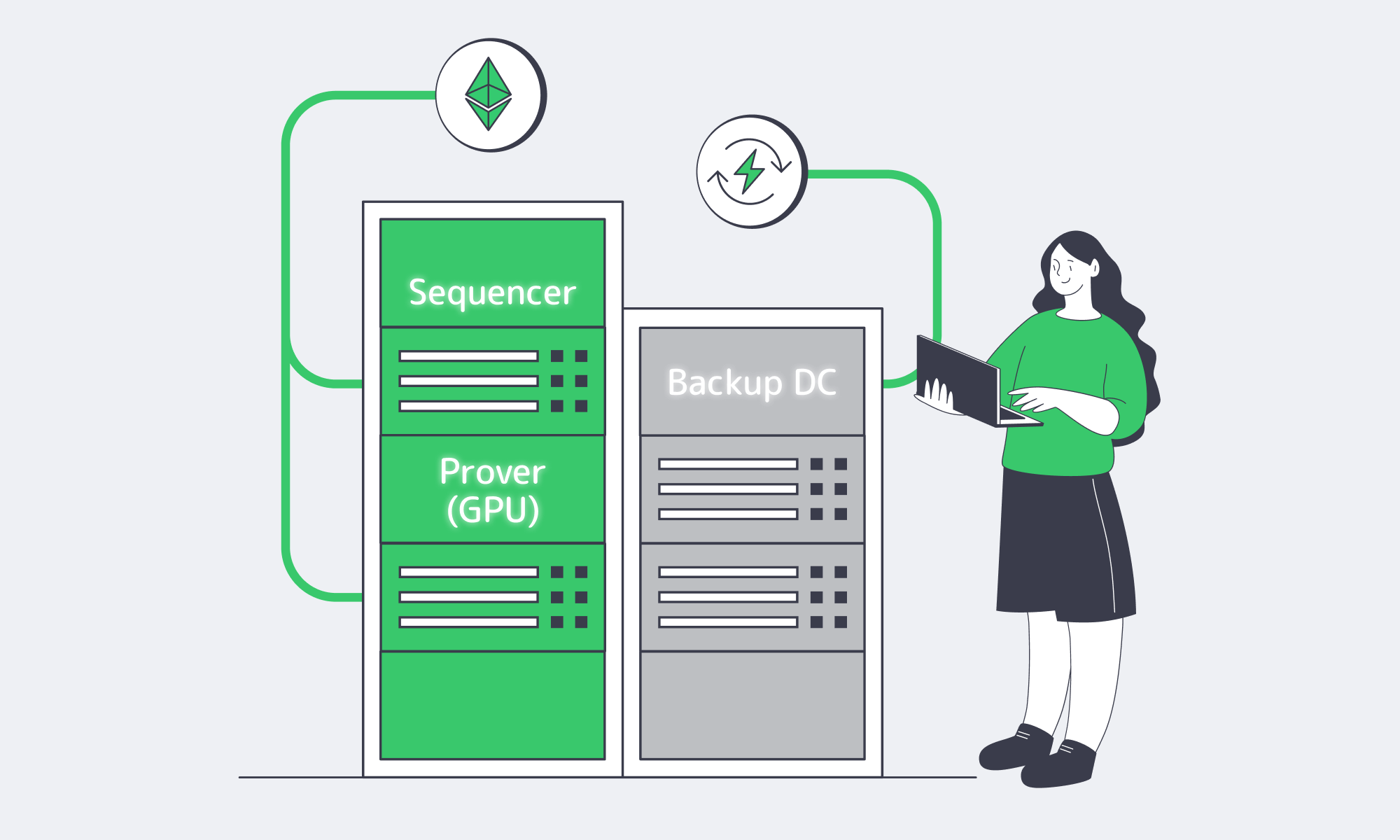
Which Infrastructure Ensures Resilient Layer 2 Network Failover
Design for failure, not heroics: run redundant sequencers and critical services in multiple regions, sync state continuously, and route users with network-level failover. Combine Tier III/IV facilities, private interconnects, and BGP-based IP continuity so maintenance or hardware faults don’t pause the chain—or strand users during bridges and withdrawals.
Early rollups left an uncomfortable paper trail. A hardware failure in Arbitrum’s lone sequencer node once caused a 10-hour outage. The lesson is straightforward: sequencers are infrastructure and operations. You need redundancy + fast, automated switching.
Modern failover usually looks like this: a primary sequencer in one region, a hot standby in another, continuous state synchronization, and traffic steering that doesn’t require users to chase new endpoints. BGP-based approaches help because they solve the hardest part—IP continuity—at the network edge. Melbicom supports customer BGP sessions (including BYOIP), so teams can keep endpoints stable through failovers and maintenance windows.
The datacenter layer matters, too. Tier III/IV facilities are built for maintenance and redundancy; your rollup shouldn’t be the first time a site discovers what happens when a component dies. In availability terms, Tier III is commonly associated with >99.98% uptime (≈1.6 hours downtime/year) and Tier IV with >99.995% (≈26 minutes/year)—numbers that stop feeling abstract once a sequencer outage freezes withdrawals. Melbicom operates across 21 Tier III/IV data center locations, and Melbicom’s on-site teams handle hardware swaps within 4 hours when failures happen in the real world.
Before you finalize architecture, here’s the ops checklist that tends to separate stable rollup network deployments from fragile ones:
- Size for worst-case, not average: benchmark your sequencer under peak mempool pressure and max compression settings; plan around p95/p99 latency and queue growth, not a quiet day.
- Treat proving as a queueing system: model proof generation as a backlog you must continuously drain; reserve headroom for witness generation and retries so “proof time” doesn’t drift upward during spikes.
- Engineer the L1/L2 link as a first-class dependency: measure L1 submission round trips and jitter; ensure enough bandwidth and routing stability that state commitments don’t stall behind packet loss or congestion.
- Fail over at the edge: build hot standbys, continuous state replication, and IP continuity so endpoints don’t change during incidents; run game days until failover is boring.
- Isolate blast radius: separate sequencer, prover, and public RPC workloads so a traffic surge or proof backlog can’t starve block production.
Conclusion: Building a Rollup Network That Feels Boring—in the Best Way
At scale, “performance” is a hardware profile and a network path. Sequencing wants predictable CPU, RAM, NVMe, and bandwidth. ZK proving wants GPUs, memory, and a tight handoff between sequencer and prover. Reliability wants redundancy, routing-level failover, and facilities that treat failure as routine rather than catastrophic.
Dedicated servers turn those requirements into something you can actually control: the CPU scheduler doesn’t change under you, the NIC isn’t shared, and your recovery plan isn’t blocked by multi-tenant constraints. That’s the difference between surviving growth and being surprised by it.
Deploy high-throughput L2 infrastructure
Provision dedicated servers and private networking for sequencers and zk provers across Tier III/IV sites. Activate in ~2 hours from 1,400+ configs, or request custom server builds (any vendor / product line).