Blog
Designing High-Throughput Web3 RPC Infrastructure
The Web3 market is estimated at roughly $3.47 billion in 2025, with projections toward $41+ billion by 2030—a compound annual growth rate above 45%. Wallets like MetaMask report 30+ million monthly users and 100 million transactions per month flowing through dApps.
Every one of those interactions crosses a remote procedure call (RPC) boundary between application and chain. Misjudge that layer and users experience “decentralization” as blank balances, timeouts, and stuck swaps.
We at Melbicom see these trends from the infrastructure side: validator fleets, full and archival nodes, indexers, and dApp backends pushing RPC infrastructure hard across Ethereum, Solana, BNB Chain, and other networks. In this article, we’ve combined our own telemetry with industry benchmarks on dedicated nodes, Web3 DevOps practices, API architecture research, and software-supply-chain security to answer a practical question: “What does reliable, high‑throughput, low‑latency RPC infrastructure for modern Web3 apps actually look like—and what kind of dedicated server footprint does it require?”
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
The Limits of Public RPC Endpoints
Public RPC endpoints are indispensable for experimentation and small projects. They’re also structurally misaligned with serious production workloads.
Many official or foundation-backed public endpoints are deliberately rate-limited to discourage production use. For example, one L1’s free RPC tier caps traffic around 50 queries per second and ~100,000 calls per day, with paid tiers increasing limits to ~100 QPS and ~1 million calls per day. Another major network has public endpoint limits around 120 requests per minute (≈2 RPS) for mainnet, again to deter production usage.
For high‑throughput chains like Solana, public docs and provider comparisons put free/public endpoints roughly in the 100–200 RPS per‑IP range, often with 2–5 seconds of data freshness lag and no uptime guarantees. Polygon-focused analyses make similar points: public endpoints are free but frequently congested or briefly unavailable.
In practice, public endpoints are ideal for:
- Local development and testnets
- Lightweight wallets
- Prototyping and small internal tools
But once you’re serving real traffic, you quickly hit rate limits, jitter, and opaque throttling.
Typical RPC Demand vs Public Endpoint Limits
Below is a simplified view of how real workloads compare to typical free RPC constraints:
| Workload Type | Peak RPC Load (RPS) | Fits on Public/Free RPC? |
|---|---|---|
| New Ethereum DEX (mainnet, modest volume) | ~80–150 | Barely; quickly rate‑limited on 50–100 QPS and 100k–1M daily caps |
| NFT mint + reveal on high‑throughput L1 | 500–2,000 for bursts | No; bursts exceed per‑IP & per‑method limits, cause 429s and retries |
| On‑chain analytics API (archival reads) | 30–60 steady | Unreliable; archival/trace methods often throttled or paywalled |
| Self‑hosted dedicated RPC node or cluster | 500–1,500+ sustained (per node) | Yes, if hardware, bandwidth, and caching are sized correctly |
Dedicated nodes move the bottleneck from someone else’s shared infrastructure to your own capacity planning—where you have actual control.
Building Reliable RPC Infrastructure for Web3 Applications
The core design principle is simple—treat RPC infra as a first‑class, multi‑region API platform (backed by dedicated blockchain nodes), not as a single endpoint you “just point the dApp at.”
Modern API architecture guides stress that the interface (REST, GraphQL, gRPC, or pure JSON‑RPC) should match your data access patterns and be designed with clear performance budgets. For Web3, the RPC layer is that API edge.
Sizing Dedicated RPC Nodes for Real Workloads
We see three broad RPC node classes:
Core full nodes (per chain)
- 8–16 cores, 64–128 GB RAM
- 2–4 TB of NVMe (or more for archival)
- 1–10+ Gbps ports, depending on chain and use case
High‑throughput RPC nodes (Solana, high‑volume EVM)
- 16–32+ cores, 128–256 GB RAM
- NVMe-only storage, often in RAID for extra IOPS
- 10–40 Gbps ports per node, sometimes higher for Solana/MEV strategies
Indexers and analytics backends
- CPU-heavy, often more RAM than the RPC nodes
- Mixed NVMe + large HDD or object storage
- High east–west bandwidth for ETL and querying
Web3 infra teams increasingly package these roles into microservices running in containers, for cleaner deployment workflows and easier rollbacks. But the physical envelope—CPU, RAM, NVMe, bandwidth—still comes from the dedicated servers under the cluster.
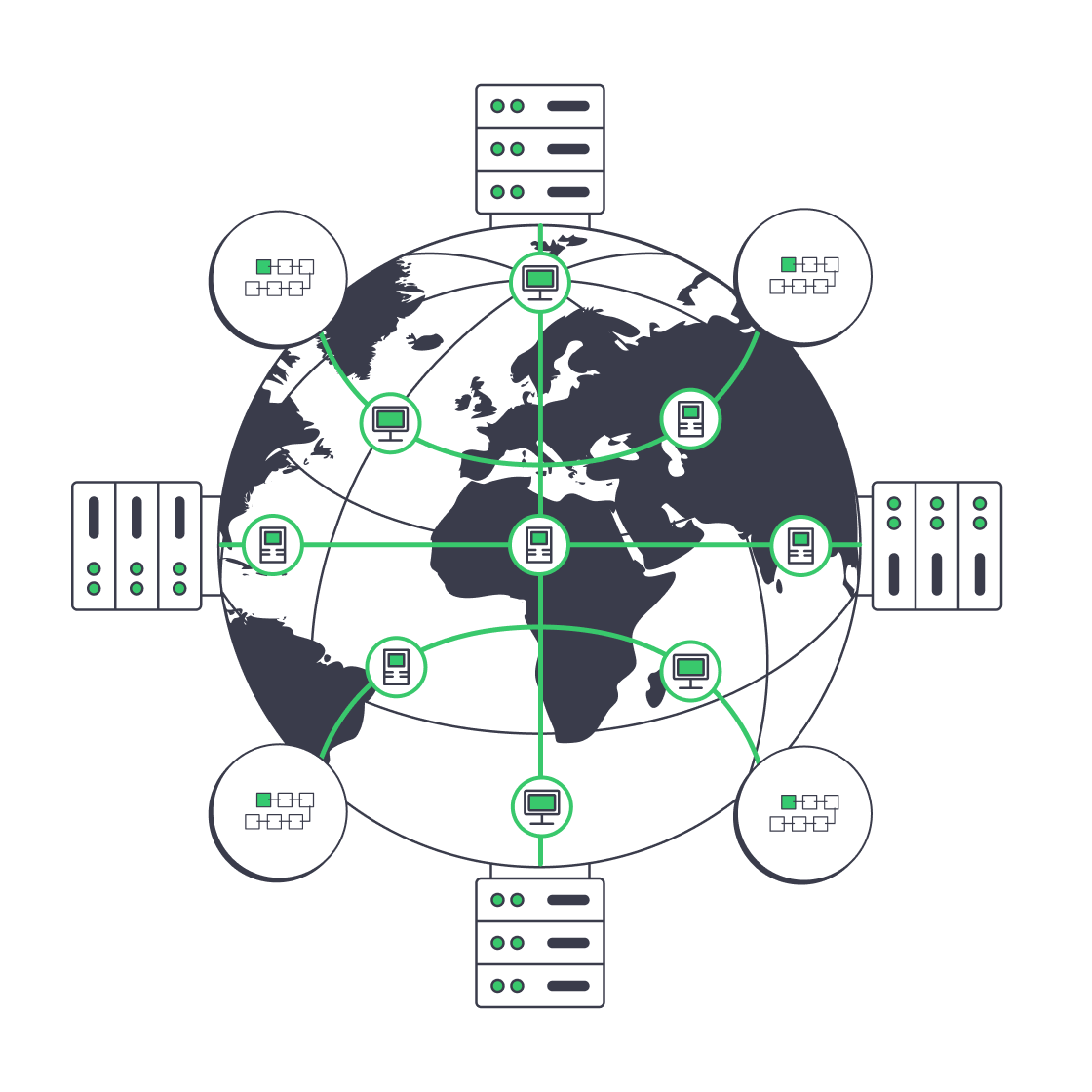
Designing Geo‑Distributed RPC Clusters
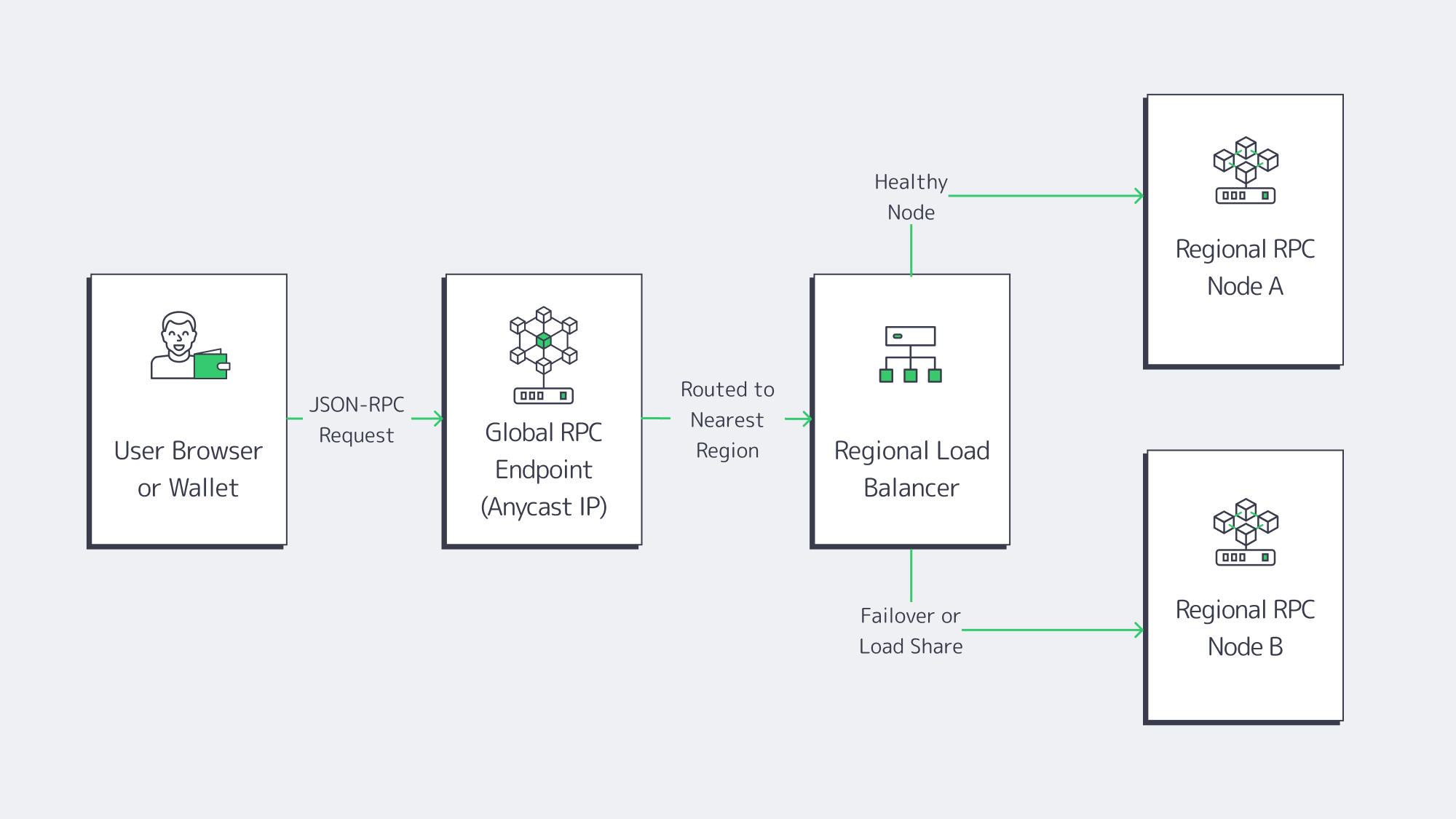
Once you can saturate a single node, the next bottleneck is where your nodes live and how clients reach them.
Best practice looks like this:
- At least two regions per major chain you depend on (for example, Western Europe + US East for Ethereum; plus Asia for truly global apps).
- Local RPC for latency‑sensitive paths—trading engines, orderbooks, and latency‑critical DeFi flows should hit the closest regional cluster.
- Global routing and failover, using DNS, an L7 load balancer, or BGP anycast, so that if one region degrades, traffic drains to healthy nodes without changing client code.
If an API (including RPC) doesn’t have clear p95/p99 latency budgets, uptime targets, and error‑rate thresholds, it’s a liability. Web3 teams add chain-specific signals—slot times, reorgs, mempool depth—to the same observability graph.
A typical routing pattern we see:
- North American users → RPC nodes in Atlanta and Los Angeles
- European users → RPC nodes in Amsterdam and Frankfurt or Warsaw
- Asian users → RPC nodes in Singapore and Tokyo**
With Melbicom, those regions map to 21 data centers across Europe, the Americas, Asia, Africa, and the Middle East, with per‑server ports from 1 Gbps up to 200 Gbps.
Security, API Design, and Observability Around RPC
Security research on Web3 supply chains calls out RPC endpoints explicitly: compromised node infrastructure or RPC gateways can feed falsified state to thousands of dApps at once. That doesn’t just break availability; it can trick users into signing malicious transactions with valid wallets.
That reality drives a few architectural choices:
- Own at least one RPC path per chain. Even if you rely on managed RPC providers, run your own dedicated nodes as a “ground truth” path for critical ops and monitoring.
- Instrument RPC like any other core API. Collect p95/p99 latency, error codes, method-level throughput, and node sync lag into a single telemetry stack with host metrics.
- Front RPC with a stable API surface. Many teams expose REST or GraphQL APIs to frontends and internal services, then fan out calls to JSON‑RPC behind the scenes. That pattern borrows from modern API design (where GraphQL shines for complex query patterns) while keeping node infrastructure replaceable.
This is where Web3 infra stops being a buzzword and starts looking like production backend engineering plus blockchain expertise.
Comparing Dedicated Servers Suitable for Hosting Web3 Apps and Blockchain Nodes
A good RPC infrastructure stack uses dedicated servers with enough CPU, RAM, NVMe, and bandwidth to keep full and archival nodes, RPC gateways, and indexers in sync—even under spikes. The right setup balances per‑node performance, cluster redundancy, and operational simplicity so that scaling Web3 applications doesn’t mean constantly fighting the infrastructure.
Network and Bandwidth: Why 10–40 Gbps Per Node Matters
For many Web3 applications, the network link—not the CPU—is the first thing to saturate.
High‑throughput chains and latency‑sensitive use cases (market makers, liquid staking, order‑book DEXs) rely on flat, predictable latency and the ability to fan out large volumes of node‑to‑node gossip and user traffic without hitting egress caps. Latency-focused RPC tuning guides point out that every extra 100 ms on the RPC path shows up directly as worse execution prices and more failed transactions.
With Melbicom, that translates into:
- Ports from 1 to 200 Gbps per server, depending on data center
- A backbone above 14 Tbps with 20+ transit providers and 25+ internet exchange points (IXPs), engineered for stable block propagation and gossip performance
- Unmetered, guaranteed bandwidth (no oversubscription ratios), which is crucial when RPC traffic spikes during mints, liquidations, or airdrops
For most RPC nodes, 10 Gbps is a comfortable baseline; 25–40 Gbps ports make sense for Solana and for multi‑tenant RPC clusters serving many internal services.
Storage and State Growth: NVMe Is Non‑Negotiable
EVM archival nodes, Solana RPC nodes, and indexers all punish slow storage. NVMe is becoming mandatory for running Polygon, Ethereum, and similar nodes, not an optimization (especially for archival or tracing workloads). On top of that, indexing pipelines and analytics workloads add their own databases, column stores, and caches.
A practical pattern:
- Hot state and logs on NVMe (2–8 TB per node, often more for archival)
- Cold archives and snapshots in object storage, such as S3-compatible buckets, plus a CDN for distributing snapshots to new nodes and remote teams
- Periodic state snapshots to accelerate resyncs after client bugs or chain rollbacks
Melbicom’s S3-compatible object storage, for example, runs out of a Tier IV Amsterdam data center with NVMe‑accelerated storage and is explicitly positioned as a home for chain snapshots, datasets, and rollback artifacts, with no ingress fees. That aligns well with how mature Web3 teams handle backup, disaster recovery, and reproducible environments.
CPU, RAM, and Virtualization Choices
Finally, there’s the compute envelope. The industry has mostly converged on a few norms:
- Validators and RPC nodes: run on single‑tenant dedicated servers, not on shared VMs, to avoid noisy neighbors and unpredictable I/O throttling.
- Indexers, ETL, and analytics jobs: often containerized and orchestrated as microservices, but still benefit from high‑core dedicated hosts.
- Dev and staging environments: can live on smaller dedicated servers or on cloud virtual machines, but should mirror production topology closely enough to catch performance regressions.
From a cost and operational perspective, the healthiest pattern is using dedicated servers for anything that touches chain state or user transactions directly (RPC, validators, bridges, oracles), and reserve generic cloud elasticity for bursty or experimental workloads.
Who Offers Reliable Servers for Web3 and RPC Infrastructure?
Reliable RPC and Web3 infrastructure comes from providers that focus on single‑tenant servers, global low‑latency networking, and tooling built for validators, RPC nodes, and indexing workloads—rather than generic cloud instances. You want a partner that can supply thousands of cores, dozens of regions, and high‑bandwidth ports without introducing rate limits or per‑GB egress surprises that mirror the very public endpoints you’re trying to escape.
Web3‑Focused Server Footprint and Bandwidth
We at Melbicom built our Web3 server hosting platform around exactly these constraints.
Melbicom operates 21 Tier III/IV data centers across Europe, the Americas, Asia, Africa, and the Middle East, with ports up to 200 Gbps per server, depending on location. The global backbone exceeds 14 Tbps, backed by 20+ transit providers and 25+ IXPs, giving Web3 apps the routing diversity and peering depth they need to keep RPC and validator traffic stable under load.
On top of that, Melbicom runs an enterprise CDN delivered through 55+ PoPs in 36 countries, optimized for low TTFB and unlimited requests. That matters directly for Web3 applications distributing frontends, NFT assets, proofs, or rollup snapshots close to users.
For RPC infrastructure specifically, this translates into:
- Web3 server hosting configurations tuned for validators, full/archival nodes, and indexers, with more than 1,300 ready‑to‑go dedicated servers activated in 2 hours
- Custom server builds that can be deployed in 3–5 business days, for specialized high‑RAM, GPU, or storage‑heavy setups
- BGP sessions (including BYOIP) available in every data center, allowing anycast or fast failover for RPC endpoints and validator IPs without changing client configuration.
With Melbicom you keep full control over clients, smart contracts, and application code, while we handle the physical layer and global routing.
Owning the RPC Layer as Web3 Scales

The last few years have made one thing clear: Web3 systems are only as decentralized as their invisible dependencies. Public RPC endpoints with tight rate limits, single‑region deployments, and opaque third‑party infrastructure all create hidden centralized failure points. When they fail, users don’t see consensus breaking—they see their favorite Web3 applications freeze.
At the same time, research on Web3 software supply chains highlights the risk of delegating too much trust to third‑party RPC layers: a compromised endpoint can subtly manipulate balances, transaction histories, or contract state in ways that are hard to detect but catastrophic in impact.
Owning your RPC infrastructure on dedicated servers doesn’t mean ignoring managed services or decentralized networks. It means using them on your terms, behind an architecture that assumes any one provider, network, or region can fail without taking your application down.
Practical Recommendations for RPC Infrastructure
To turn that philosophy into an actionable roadmap:
- Plan around the end‑to‑end latency, not just gas. Budget for latency from UI → API → indexer → RPC → chain and place latency‑sensitive components in the same region on similarly performant dedicated servers.
- Run your own nodes alongside 3rd‑party RPC. Treat self‑hosted full/archival nodes as both a production path and a reliable observability probe against external providers.
- Design for multi‑region by default. Start with at least two regions per critical chain and make region failover an early design decision, not an afterthought.
- Instrument RPC like a product, not a utility. Track method‑level throughput, error codes, node sync lag, and p95/p99 latency; correlate those metrics with chain conditions and user‑level incidents.
- Use CDN + object storage for snapshots and assets. Keep chain snapshots, rollbacks, and heavy datasets in S3‑compatible storage, and front user‑facing assets with a CDN so RPC nodes focus on signing and state reads, not static file serving.
These practices give you an RPC layer that behaves like any other well‑run production platform: observable, resilient, and predictable under stress—without sacrificing the decentralization properties that make Web3 worth building on in the first place.
Melbicom’s Dedicated Servers for Web3 RPC Infrastructure
If you’re planning the next iteration of your RPC infrastructure—whether that’s a Solana RPC cluster, Ethereum or BNB Chain archival nodes, or multi‑region indexers—Melbicom’s dedicated servers, global backbone, CDN, S3 storage, and BGP sessions are built to support that design. With 21 Tier III+ data centers, 1,300+ ready‑to‑go configurations, ports up to 200 Gbps per server, and 55+ CDN PoPs across 36 countries, you can design, test, and scale reliable Web3 infrastructure on hardware that behaves deterministically under load.
Order a Server
Ready to move beyond public endpoints and shared RPC bottlenecks? Order a dedicated server and explore Web3‑focused configurations for validators, RPC nodes, and indexing workloads—or talk with us about a custom build you need.