Blog

How Dedicated Servers Turbocharge NFT Drops
NFT marketplaces matured rapidly, and the initial boom was problematic. The high-traffic, high-stakes platforms saw tens of thousands arriving together for a hyped drop or auction. This inevitably led to timeouts, failed requests, and outages across sites during marquee releases. Marketplaces suffered as infrastructure buckled under the pressure of artist-led drops that could send traffic spiking in minutes and trigger crashes during high-demand release windows. With all eyes on the platforms, the lesson was tough. Failed transactions hurt users, reputations, and creators alike.
Even after the speculative peak cooled, demand remains large and bursty: Similarweb estimated 4.3 million visits to OpenSea in May 2026, while Dune-linked reporting showed 467,322 active OpenSea users in May 2025 and a single day with more than 111,000 active users. On peak days, tens of thousands of new users can arrive globally as a single drop stretches networks across continents, bringing concurrent bidders from Los Angeles, London, Lagos, and Singapore into the same trading battle. The situation soon becomes effectively first-come, first-served, and the margin for error is so tiny that just 100 ms of page latency can dent conversion.
The best philosophy that modern NFT platforms can take is to treat drop day as the blueprint for regular operation and engineer for high throughput and capacity, with cross-regional low latency. The core for such an approach rests on dedicated server clusters with advanced load balancing, which are optimized for content delivery and augmented by multi-chain back ends with resilient data pipelines that can keep up with the demands of real-time blockchain interactions.
Choose Melbicom— 1,100+ ready-to-go configs — 21 Tier IV/III data centers — 55+ PoPs in 39 countries |
 |
Scalable NFT Hosting for Drop Days
Being able to scale begins with a horizontal approach on single-tenant dedicated servers. The scaling starts with multiple front-end/API nodes to expand to, clustered databases, in-memory caches, and separate pools for blockchain connectivity. Keeping each tier stateless or replicated helps with raising and contracting capacity rapidly before and after a release. Place a load balancer in front of every critical service; it performs health checks and load-shedding, preventing any single point of failure from affecting the rest of the system.
With this type of architecture, hot traffic is spread under burst conditions; multiple application nodes handle browsing, searching, and bidding, preventing any one machine from becoming a choke point. It also isolates heavy components, so if one service, such as a slow indexer, fails, it doesn’t take down the entire marketplace. Separating everything into microservices (listing, bidding, metadata fetch, search, user profiles, and notification pipelines) means they can each scale independently, which equates to higher throughput and predictable performance regardless of how big the crowd.
NFT server solutions: A practical cluster pattern
- For edge and ingress: Route users via Anycast DNS + L7/L4 load balancers to their nearest region and fan requests across local app pools.
- In the application tier: Use 8–N stateless API/web nodes per region, autoscale for drops in advance, and keep queues bounded with circuit breakers and back-pressure.
- For the caching tier: Read surges for listings, trait filters, leaderboards, and collections can be absorbed by leveraging Redis or Memcached, so long as the dedicated server is rich enough in RAM.
- The data tier: With primary/replica SQL or NewSQL clusters on NVMe-backed dedicated servers, you can steer read-heavy traffic to replicas with paths optimized for idempotence and retries.
- For search/index: You can speed up trait filters with dedicated nodes for full-text and attribute searches.
- Blockchain I/O: Each chain should run its own nodes (full, archive, or validator-adjacent), pooled behind load-balanced RPC endpoints on compute- and disk-optimized hosts, with fallback providers routed by a rate-aware client.
It all boils down to juggling enough headroom and keeping sustained utilization below safe thresholds. That way, a sudden 5–10× spike won’t land beyond system capacity.
Dedicated NFT Hosting: Elasticity vs. Predictability
For MVPs and platforms with moderate traffic, cloud VMs remain solid enough, providing familiar autoscaling and managed services ideal for emerging contenders. However, for large-scale operations, dedicated servers have two advantages that can make all the difference on drop day:
- Deterministic performance: No noisy neighbors, you have full CPU/memory/disk I/O, and line-rate NICs, so there are truly no hidden throttles under saturation.
- Bandwidth is more economical: Generous predictable egress matters as much as compute for global NFT media delivery.
What to consider:
| Dimension | Dedicated servers | Cloud VMs |
|---|---|---|
| Performance under surge | Deterministic; full hardware control | Variable, multi-tenant noise and tier caps |
| Bandwidth model | High per-server throughput; predictable egress | Typically metered egress; cost rises with success |
| Control surface | Root control for DB/OS/tuning and custom nodes | Faster primitives, but managed constraints apply |
For an ideal solution that ensures predictable UX at peak, many operators opt for a hybrid middle ground running core transaction paths, databases, caches, and chain I/O on dedicated clusters and sending overflow and ancillary jobs to the cloud.
Low-Latency, High-Throughput Design

Latency is naturally governed by geography. The requests of a Paris-based buyer being served from a Los Angeles origin will experience a delay, and in a competitive auction, the milliseconds matter, making it vital to push content outward and pull users inward and tackle the issue from both ends.
To do that, NFT media and static assets such as thumbnails, preview videos, and collection images should be cached via CDNs to keep them on edge nodes local to users so they don’t need to touch the origin to load. Dynamic API requests should be brought to the nearest region through geo-routing. These regional app pools lower the average latency, and the global routing layer prevents spikes in tail latency.
HTTP/2 and HTTP/3 (QUIC) should be enabled, and you can compress JSON and metadata to further reduce latency. Serve modern image formats (AVIF/WebP) and use server/CDN-side on-the-fly resizing so mobile users aren’t downloading 4K art when a 720p preview suffices. Another tactic is to keep connection reuse high and TLS handshakes short on the server to again lower the user-perceived latency. Together, these choices make pages faster and bids more responsive.
This design is simple to execute with Melbicom because we already operate with this blueprint in mind. Our servers are provisioned from 21 data center locations (Tier IV and Tier III facilities in Amsterdam and Tier III sites in other regions), and our CDN spans 55+ locations across 39 countries to help reduce pressure on the origin during traffic spikes, keep close to demand centers, and considerably shorten paths. Melbicom adds power/network redundancy for high-traffic drops.
Bandwidth for NFT platforms: Preparing the pipeline before crowds appear
- Keep high-capacity uplinks on origin so cache-miss storms don’t throttle.
- Set aggressive caching rules and warm edge caches for featured collections.
- Origin sharding can reduce load for hot collections by splitting media across multiple high-bandwidth servers behind DNS or CDN origin balancers.
The network design and Melbicom’s per-server bandwidth ceiling of up to 200 Gbps give operators room to breathe when the crowd appears without warning.
Future-Ready Multi-Chain Back Ends
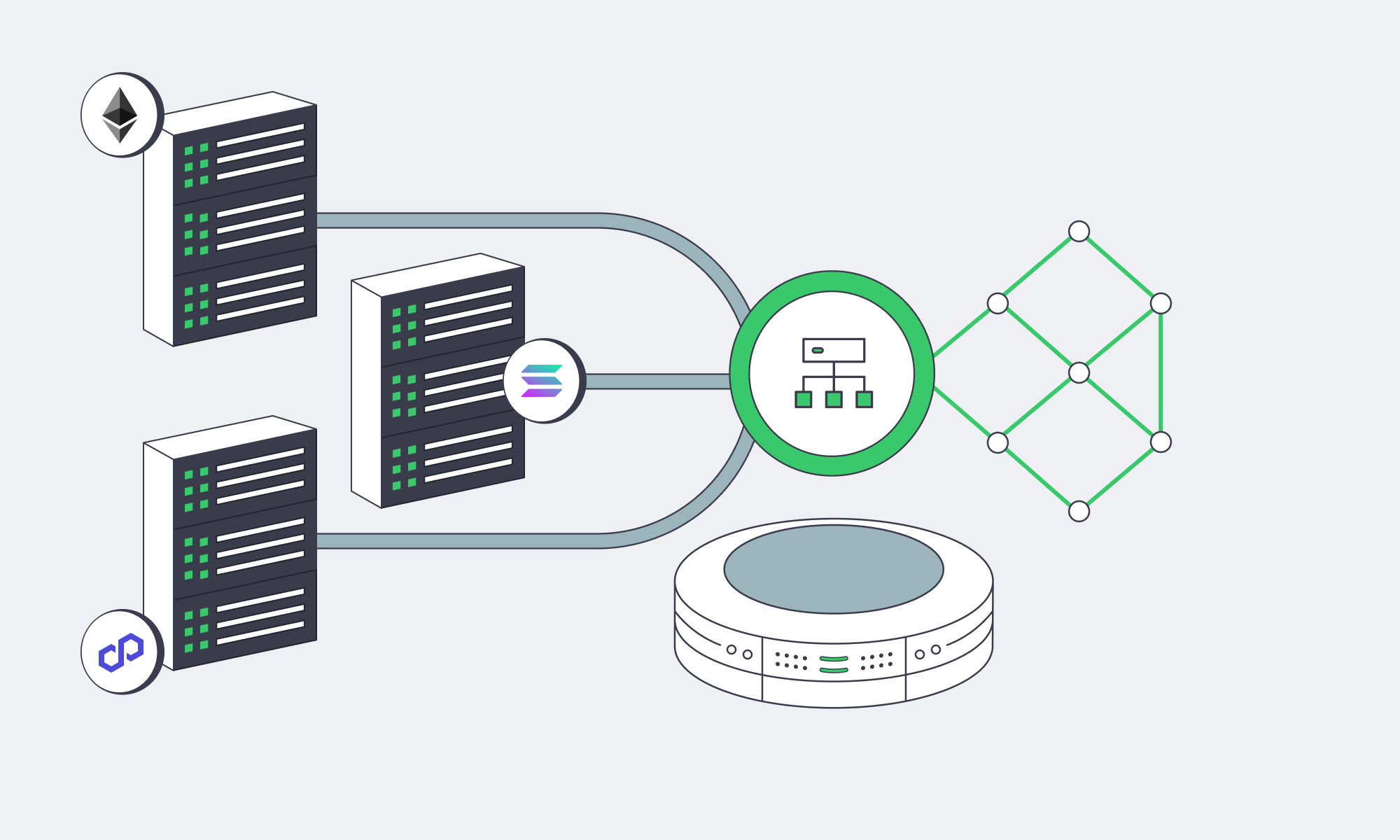
The marketplace choke point in the early days was the single-chain dependence; today, leading platforms span many chains and L2s. This benefits users and keeps fees manageable, but it can be demanding in terms of infrastructure. With each chain, additional RPC traffic, indexing, confirmations, and reorg handling are added to your critical path.
The way around this is to work with a multi-chain I/O fabric that consists of pools of RPC endpoints per chain running behind a client-side load balancer. That balancer must be chain-aware, understanding rate limits, method cost, backoff, and geo-aware to help find the nearest healthy endpoint. Heavy chains should ideally have their own nodes placed on disk-rich, CPU-steady dedicated servers to scale horizontally wherever feasible, especially deep history archive nodes and indexers to help speed up trait/ownership queries. If you mix your own nodes and trusted third-party endpoints with dynamic routing and health checks, you have sufficient redundancy.
When it comes to the data side of operations, the aim is a consistent sub-second response regardless of how high the concurrency is, which can be achieved by designing for reads. This means keeping cached projections of on-chain states, such as ownership, listings, and floor prices, that refresh on events and using read replicas for API queries. Writes should be kept idempotent so a retried bid doesn’t result in a double-spend. Trait filters and search data can be offloaded to optimized search clusters for aggregation.
Spike-Proof NFT Reliability Patterns
- Graceful degradation design: When RPC slows, you want browsing to remain responsive, so queue writes, show optimistic UI where appropriate, and reconcile.
- Circuit breaking: Avoid cascading timeouts by tripping RPC methods that are timing out; then try alternate regions/providers.
- Backpressure at ingress: During peaks, shed or delay low-value requests such as slow-polling clients to help keep bid and purchase paths rapid.
- SLO-driven autoscaling: Scale API nodes based on queue depth and p95 latency, not just CPU. Scale caches based on keyspace hotness.
Practical Operational Guidance

- Design for peak: If a typical day is 1×, you should engineer for 10× and practice load tests at 20×. If you can keep at least one region running at <50% utilization, then you know you can absorb a sudden spike without chaos.
- Place users at the core: Run two or three regions for global audiences and let your routing decide if your budget will cover it; keep failover active-active.
- Own the hot path: Keep bids, mints, purchases, metadata reads, and ownership checks on controlled infrastructure so you can tune and overprovision. Move batch jobs and low-priority tasks to overflow capacity.
- Observability is a key investment: During a drop, real-time route latency, queue depth, and RPC timing metrics speed incident response.
Melbicom aligns with this playbook. With 1,100+ server configurations ready to deploy, sizing clusters is simpler across 21 global locations and 55+ CDN locations in 39 countries. Those locations reduce origin load and lower latency.
Each server can reach up to 200 Gbps for egress storms, while 24/7 support lets teams focus on product instead of infrastructure.
Ready for Drop-Day Traffic?
Deploy high-performance dedicated servers with global bandwidth to keep your NFT marketplace lightning-fast at peak demand.