Blog

Dedicated Server America: Region Selection and DDoS Resilience
Buying a dedicated server in America is now a latency-budget and risk-budget decision, not a generic geography choice. Round-trip time is driven by physical distance, intermediate hops, congestion, and server response time; even CDN offload only helps when the origin, cache layer, and request path are planned together. A practical fiber heuristic is that every extra 1,000 km can add roughly 10 ms of round-trip delay before queueing or application work is counted. That is enough to change p95 latency, bidder win rates, playback starts, and inference responsiveness.
The stakes are not theoretical. IAB puts full-year U.S. digital advertising revenue near $300 billion. Nielsen’s Gauge recently measured streaming at 47.5% of total U.S. TV viewing in a month. IDC says AI infrastructure spending has moved into the high hundreds of billions and is still rising sharply. Those markets do not fail gracefully when region selection, bandwidth math, or DDoS readiness is treated as an afterthought.
Deploy in America— Atlanta and Los Angeles capacity — DDoS-ready bandwidth planning — Stock servers live in 2 hours |
 |
How to Choose a Dedicated Server in America for Coast-Level Latency and Scale
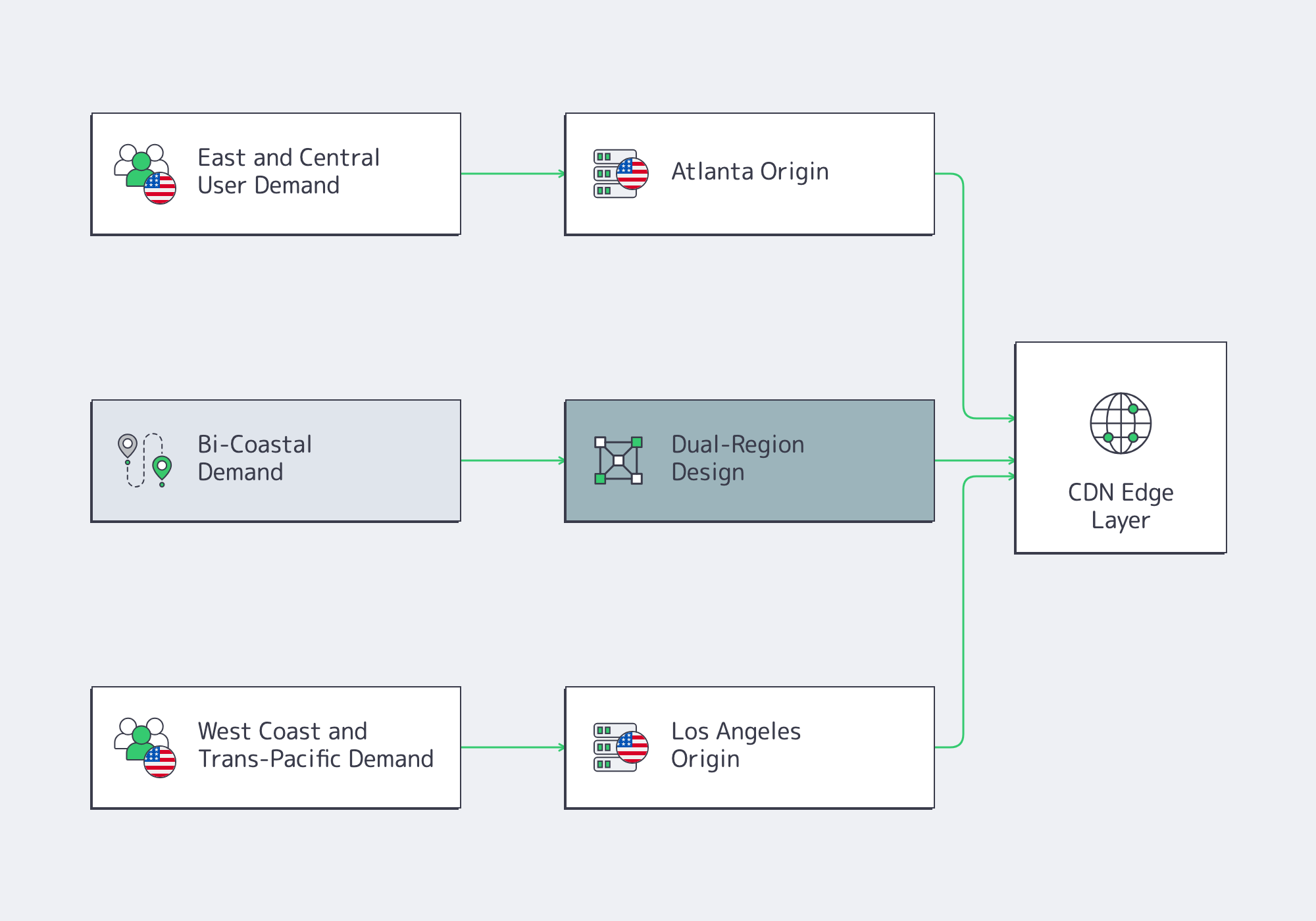
Choose the coast from real demand maps: user metros, revenue-critical API calls, playback starts, bidder traffic, and egress. Atlanta is the stronger anchor for eastern and central demand; Los Angeles fits Pacific and trans-Pacific demand. If traffic is bi-coastal, plan two regions instead of forcing one origin to carry both latency budgets.
The architecture pattern is simple: keep state, origin logic, inference endpoints, or session control near the largest user cluster; push repeated heavy objects outward. Cloudflare’s RTT guidance is clear that distance, hops, and congestion increase latency, while CDNs improve response time by moving cached assets closer to users. Melbicom’s Atlanta and Los Angeles DCs plus CDN footprint of 55+ CDN PoPs across 39 countries, including Ashburn, Atlanta, Dallas, Kansas City, and Los Angeles—fits that origin-plus-edge model.
Provider Due Diligence: Bandwidth, DDoS Posture, Delivery Time, and Remote Hands
Validate the provider like an incident is already underway. Ask how port speed maps to committed throughput, how transfer is counted, what happens during short DDoS spikes, how quickly stock or custom servers arrive, and which remote-hands tasks are routine. The objective is a runbook that survives launch pressure.
DDoS readiness needs first-minute clarity. NETSCOUT reports more than 8 million attacks across 203 countries and territories in half a year, with peaks up to 30 Tbps. If mitigation depends on a ticket, diversion delay, or unclear escalation path, availability is still undefined during active attack traffic.
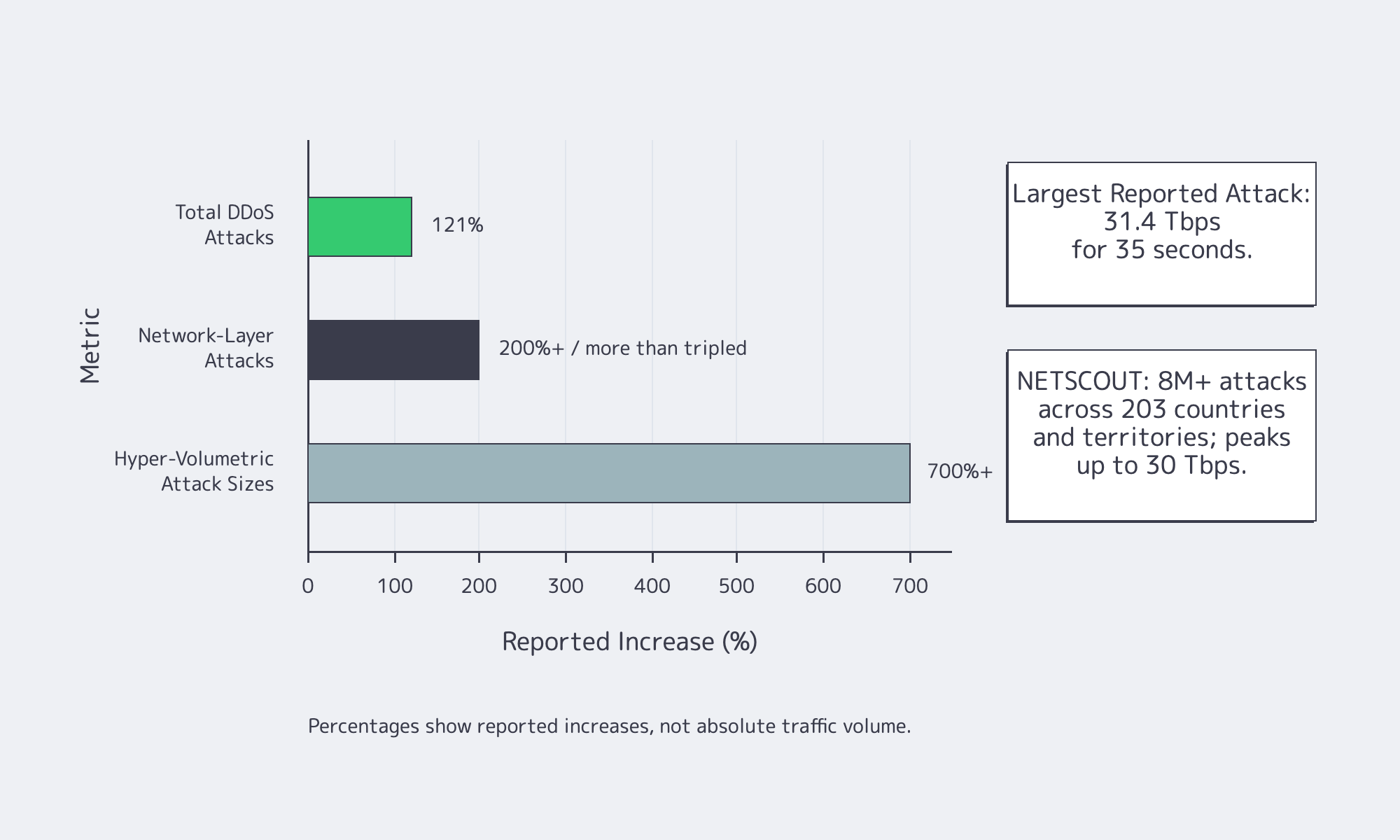
Bandwidth validation deserves the same rigor. Size ports from peak five-minute egress, not monthly averages. Confirm whether “unmetered” changes contention assumptions, whether burst traffic can queue, and how upgrades are handled before a launch, model release, sports window, or paid campaign. Melbicom offers 1,400+ ready-to-go server configurations activated in 2 hours; with 21 global data center locations, 24/7 support, 25+ IXPs, 20+ transit providers, and custom configurations delivered in 3–5 business days. Those facts matter because emergency growth and planned growth have different timelines for ordering and response.
Which Infrastructure Triggers Justify Upgrading for AI, Streaming, and Adtech
Upgrade when behavior changes, not when a refresh calendar says so. AI inference needs new capacity when latency slips before utilization looks catastrophic. Streaming needs headroom when event traffic jumps above baseline. Adtech needs more or better-placed servers when bidder paths, redirects, analytics, and creative delivery compete across the wrong coast for the largest user base.
AI workloads often expose memory, local-storage, and east-west-copying limits before CPU graphs look alarming. The next dedicated server should therefore be chosen for memory footprint, NVMe capacity, and network headroom as much as for cores. A common region-right-sizing pattern is to launch near the larger user cluster, measure p95 latency and egress, then add the second coast before the next product spike.
Streaming is more brutal because events bend the curve. AppLogic Networks says video is the largest application category by volume at 5.6 GB per user per day, and live-sport days accounted for all ten of its top traffic days, with peaks 30–40% above normal usage. In practice, a single origin that looks fine on ordinary days can become fragile during premieres, finals, or news-driven surges.
Adtech exposes the same problem through path design. AppLogic says ad analytics touches 93% of fixed-network subscribers, which makes it pervasive rather than peripheral. Melbicom offers regional placement, high-QPS routing, guaranteed bandwidth, BGP Session support for routing requirements, and CDN offload for creatives and landing assets. When bidder logic and conversion APIs drift across the wrong coast, the upgrade case has already arrived for infrastructure planning.
Compare Offers Worksheet for a Dedicated Server America Shortlist
Use this worksheet to compare any dedicated server America shortlist in operational terms. It focuses on decisions that affect production: coast fit, burst bandwidth, DDoS operating model, delivery windows, remote hands, and second-stage scale. Fill it with evidence from logs, monitoring, and incident assumptions—not sales adjectives.
| Buying question | What good looks like | Why it matters |
|---|---|---|
| Where is demand concentrated? | Logs point east, west, or clearly bi-coastal | Cuts avoidable RTT and hop count |
| How should bandwidth be sized? | Peak five-minute egress plus burst headroom | Prevents queueing during launches and live events |
| What is the DDoS model? | Immediate mitigation posture with explicit escalation | Short, large attacks leave little reaction time |
| How transparent are operations? | Known delivery windows, access methods, and remote-hands scope | Turns incidents and growth into planned work |
| What is the scale path? | Extra servers, second coast, CDN offload, stable routing | Avoids migration under pressure |
Used honestly, the worksheet exposes false economy. A lower-cost server in the wrong region can cost more through failed bids, late origin fetches, or incident response. Against that worksheet, Melbicom’s relevant facts are specific: Atlanta and Los Angeles options, 1,400+ ready-to-go configurations globally, 19 other global data center locations, 25+ IXPs, and 20+ transit providers. That gives the buying team concrete inventory and routing data to validate against its own traffic model.
Quick Path to Configure America Servers
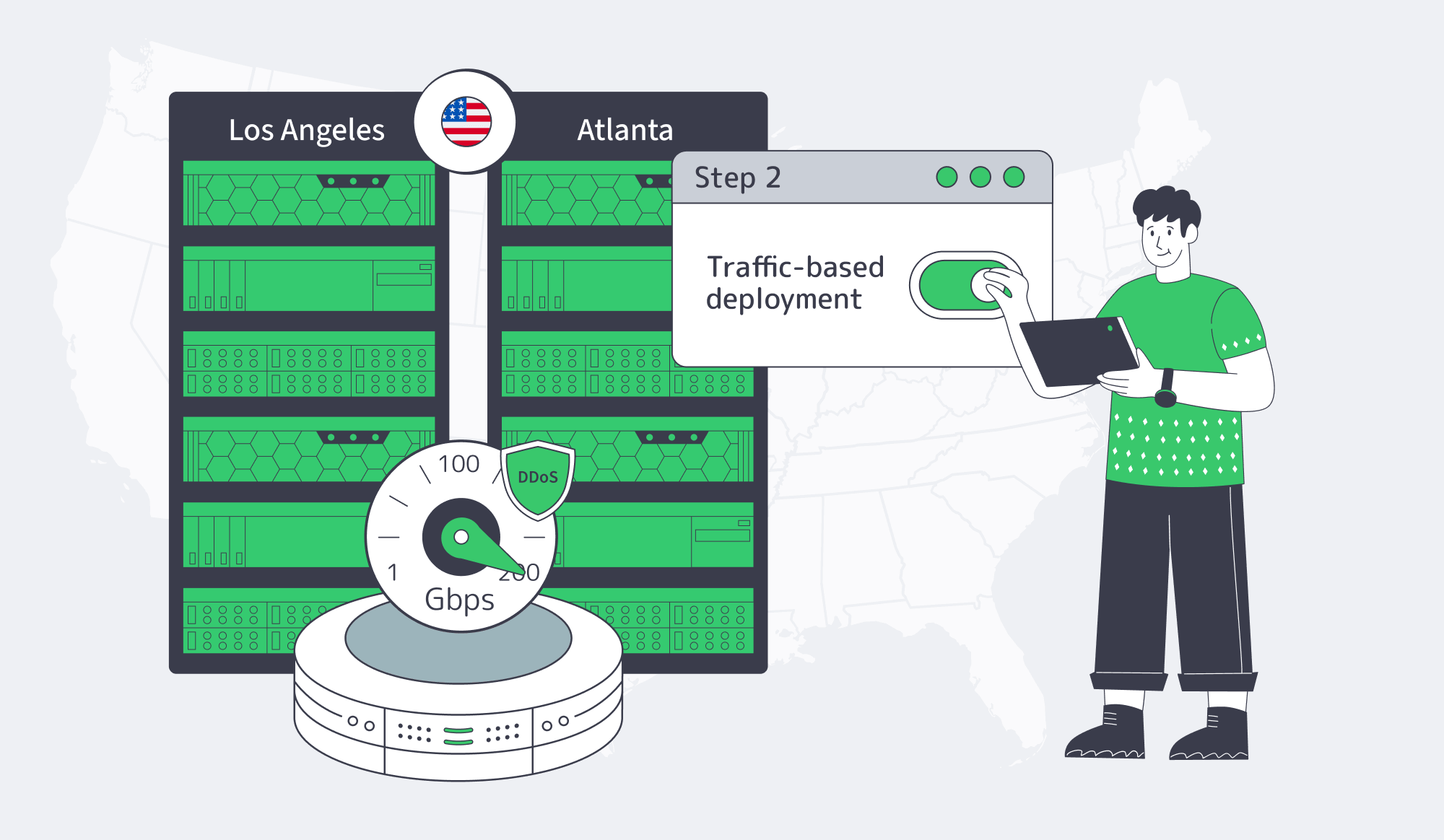
The fastest path is to convert traffic evidence into a server configuration before touching checkout. Start with recent logs, choose the coast, size the port from real peaks, decide whether stock or custom hardware is required, and define the CDN or routing dependencies that will shape the second phase.
- Build a city-weighted demand matrix from the last 30 days of request, playback, bidder, or API logs.
- Treat peak five-minute egress as the bandwidth baseline, then add burst headroom for launches, campaigns, live events, and model releases.
- Choose Atlanta, Los Angeles, or two regions based on p95/p99 tests rather than headquarters location.
- Reserve stock capacity early; when hardware needs are specific, plan custom configuration work 3–5 business days ahead.
- Use CDN offload for repeated heavy objects and confirm routing, DNS, access, and remote-hands requirements before migration.
Melbicom’s USA presence is the first stop for regional choices; the Atlanta and Los Angeles pages offer the city-level ready-to-go options; and the Dedicated Servers Configurator is the path when CPU, RAM, storage, and bandwidth requirements need a closer match to traffic.
Conclusion: Buy Dedicated Server America Capacity Around Traffic Truth
The best dedicated server America decision is not “which country?” but “which coast, port model, incident posture, and scale path match the traffic?” For modern platforms, the winning design combines a coast-correct origin, validated bandwidth headroom, DDoS-ready operations, and a second-stage plan before the spike arrives.
That planning discipline is especially important before streaming events, AI launches, and ad campaigns, where latency and availability problems show up in user behavior before they show up in monthly invoices. A provider should make the next capacity move easier to justify, faster to order, and clearer to operate.