Blog
Operating Big Bare Metal Kubernetes Clusters
Running Kubernetes on physical servers stops being routine once the cluster has to survive racks, top-of-rack switches, power feeds, and upgrade waves that touch thousands of workloads. That is where managed abstractions can start working against you.
CNCF reports that 82% of container users run Kubernetes in production, and Flexera says 76% of large enterprises spend more than $5 million per month on public cloud. For bandwidth-heavy platforms, the question becomes predictability.
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
 |
What Is a Big Bare-Metal Kubernetes Cluster?
A big bare-metal Kubernetes cluster is not defined by node count alone. It becomes “big” when topology, automation, and change management become the main reliability controls, because racks, switches, control-plane pressure, and upgrade sequencing matter more than simply adding workers.
Kubernetes can scale to 5,000 nodes, 110 pods per node, 150,000 pods, and 300,000 containers. Useful envelope, wrong operating definition. In practice, a cluster feels big earlier, when the dominant problems change:
- Failure domains must become scheduling inputs.
- API bursts and watch fan-out must not swamp etcd.
- Version skew and API removals become SLO risks.
- Fleet boundaries matter as much as cluster size.
That is where dedicated servers start to make sense: not because they simplify K8s, but because they let you make topology, networking, and lifecycle management intentional.
What Makes a Bare-Metal Kubernetes Cluster “Big” from an Operations and Failure-Domain Perspective?
A bare-metal Kubernetes cluster becomes operationally “big” when failures are correlated rather than isolated. The platform has to survive rack loss, control-plane locality shifts, and rolling maintenance without manual rescue, because the real risk is shared fate across infrastructure, networking, and the systems meant to heal both.
Failure domains become schedulable topology
On physical infrastructure, the blast-radius stack is concrete:
- a single server
- a rack
- an aggregation domain
- a data-center domain
That is why topology stops being optional. Pod Topology Spread Constraints exist so replicas can be distributed across real boundaries instead of pretending every node is interchangeable. Melbicom’s network design is exactly the kind of physical layout Kubernetes should understand.
Control-plane traffic locality matters
Nodes do not automatically steer API traffic to a same-zone endpoint. In a large multi-rack cluster, locality therefore belongs in the load-balancing design, not in hopeful assumptions about the scheduler.
Upgrade blast radius is a first-order SLO risk
Big clusters are dominated by change: kernels, runtimes, CNI, CSI, Gateway implementations, policy engines, and Kubernetes itself. Two upstream rules shape every serious upgrade plan:
- version skew limits how far components can drift
- API deprecation explains why minor upgrades can still break workloads
On dedicated servers, staged upgrades are possible only if you have spare capacity, rollback room, and placement discipline.
Correlated failures: the “shared fate” problem
Large clusters fail in waves. A ToR pair flaps, a storage path saturates, or routing shifts just enough to turn healthy control-plane traffic into a storm. That is why API Priority and Fairness matters: protecting the API is part of self-healing.
How to Design Networking, Storage, and Control-Plane HA for Bare-Metal K8s Clusters
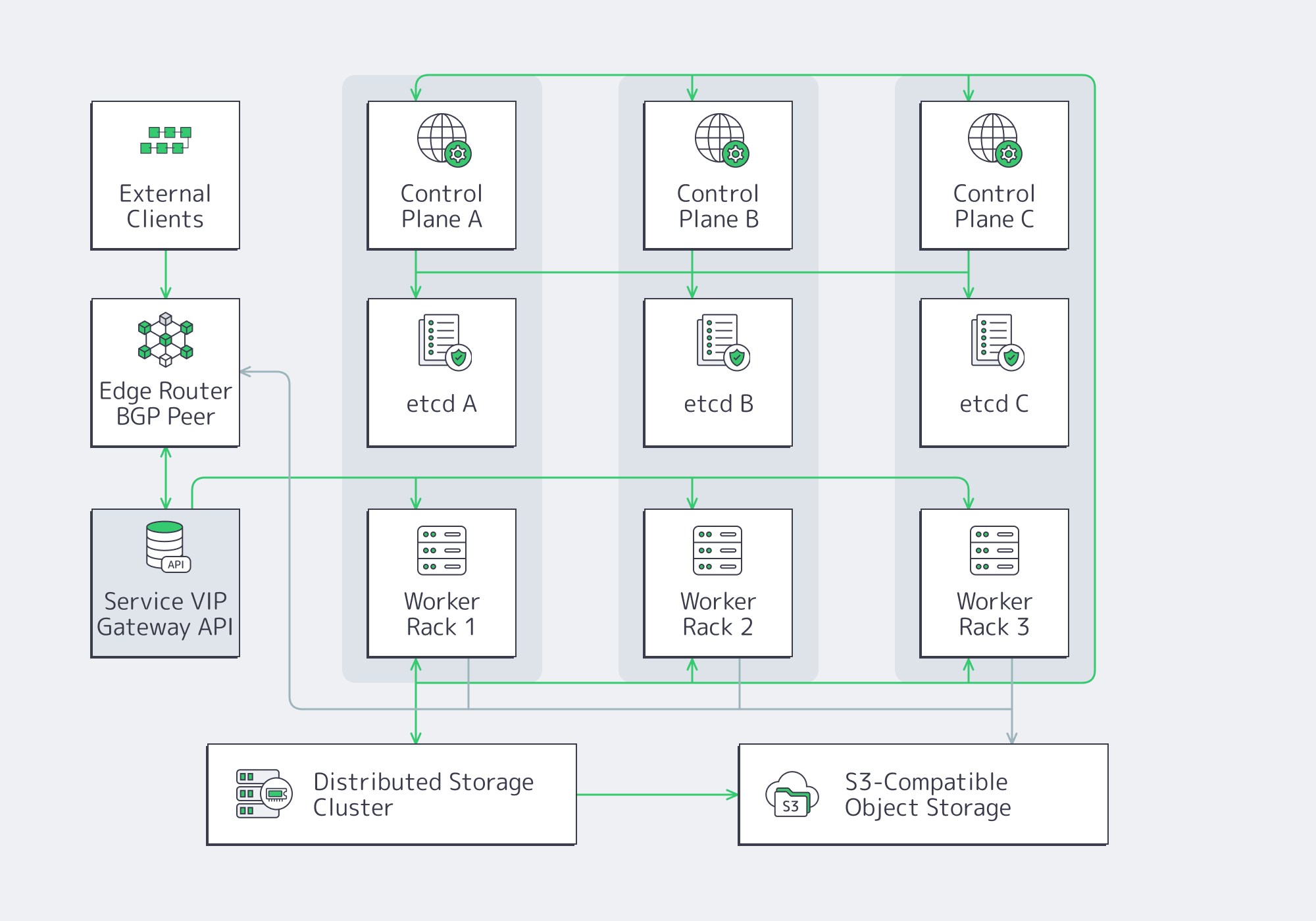
The right reference architecture optimizes for predictable behavior under failure and change. Large bare-metal clusters need an HA control plane placed across real failure boundaries, a data plane built for L3 multi-rack networking, a load-balancing strategy based on VIPs or BGP, and storage tiers aligned to recovery goals rather than convenience.
Control plane and etcd: HA that is actually operable
Place at least one control-plane instance per failure zone, then protect etcd like the latency-sensitive system it is. etcd hardware guidance calls for roughly 500 sequential IOPS for heavily loaded deployments versus about 50 for minimal viability, and its tuning docs warn that long fsync latency can trigger missed heartbeats and leader elections.
Kubernetes also recommends a separate etcd for Event objects in large environments, so high-churn data does not compete with the objects that keep the platform alive.
Networking baseline: assume L3, assume multi-rack, assume failure
At this size, Kubernetes networking is data-center engineering expressed through a CNI. Start from L3, assume east-west traffic will cross racks, and design for the path that fails first under load.
Kubernetes on bare metal: modern CNI and service routing choices
CNI choice at scale is really three decisions:
- how service load balancing works
- how network policy is enforced and debugged
- how observable the datapath is under real traffic
That is why modern designs gravitate toward eBPF data paths. Cilium’s kube-proxy replacement pushes service routing into the kernel, supports consistent hashing, and reduces iptables churn.
Load balancing: treat BGP as an infrastructure primitive, not a workaround
Bare metal Kubernetes has to create its own LoadBalancer semantics. In practice, that usually means:
- MetalLB advertising service VIPs over BGP
- kube-vip managing virtual IPs for the control plane and, where needed, services
At large scale, BGP is not a cloud substitute. It is the cleanest way to make Kubernetes endpoints participate in the wider network, which is why Melbicom’s BGP session service matters in this architecture.
North-south traffic: Gateway API is the “big cluster” control surface
Gateway API is the better north-south contract for large clusters because it separates infra ownership from route ownership and reduces cluster-wide ingress contention.
Storage strategy: performance tiers + failure domains + operable recovery
State punishes wishful thinking, so large clusters usually settle on three tiers:
- Local high-performance storage for low-latency workloads that can replicate at the application layer.
- Distributed block or file storage where transparent failover matters more than peak performance.
- Object storage for snapshots, backups, artifacts, and long-term telemetry.
VolumeSnapshots turn recovery into an API operation. Rook gives distributed storage a Kubernetes-native control loop. Thanos assumes object storage as the long-term metrics layer. Melbicom’s S3-compatible storage fits that third tier cleanly for backups, retention, and artifact pipelines.
How Day-2 Ops on Bare Metal Kubernetes Compare with Managed Kubernetes
Day-2 is the real trade. Managed Kubernetes removes part of the control-plane burden, but large bare-metal clusters give you more control over cost shape, routing, storage behavior, and lifecycle timing. The catch is simple: every convenience the cloud hides has to be replaced with automation that is reliable enough to become boring.
Patching and upgrades: make change boring or the cluster won’t survive
The core loop is straightforward: drain safely, reboot deliberately, validate aggressively. kubectl drain respects PodDisruptionBudgets, and Kured turns required reboots into a controlled DaemonSet workflow.
Node replacement automation: treat servers as replaceable, not precious
The sustainable posture is declarative lifecycle management for physical nodes:
- Tinkerbell for provisioning workflows
- Cluster API for cluster lifecycle
- Metal3 for bare-metal-oriented cluster management
Replacements have to preserve identity, labels, certificates, provider IDs, and topology membership. Melbicom’s dedicated-server platform matters here because hardware turnover is part of the design, not the exception path.
Observability at scale: the data plane is easy; the telemetry plane hurts
Prometheus is explicit that local storage is single-node in scope, which is why large clusters converge on remote or object-storage-backed metrics. In community discussion, users report query pain around roughly 10 million series, and the default --query.max-samples guardrail is 50 million. The durable pattern is short-term local TSDB plus long-term object storage, with a normalized pipeline such as the OpenTelemetry Collector.
Security: enforce intent at the platform layer
Large clusters need portable defaults and cluster-wide guardrails. Pod Security Standards and Pod Security Admission set the namespace baseline. NetworkPolicy remains the portable segmentation API. Audit logging turns cluster actions into evidence.
Cost and complexity: the honest comparison
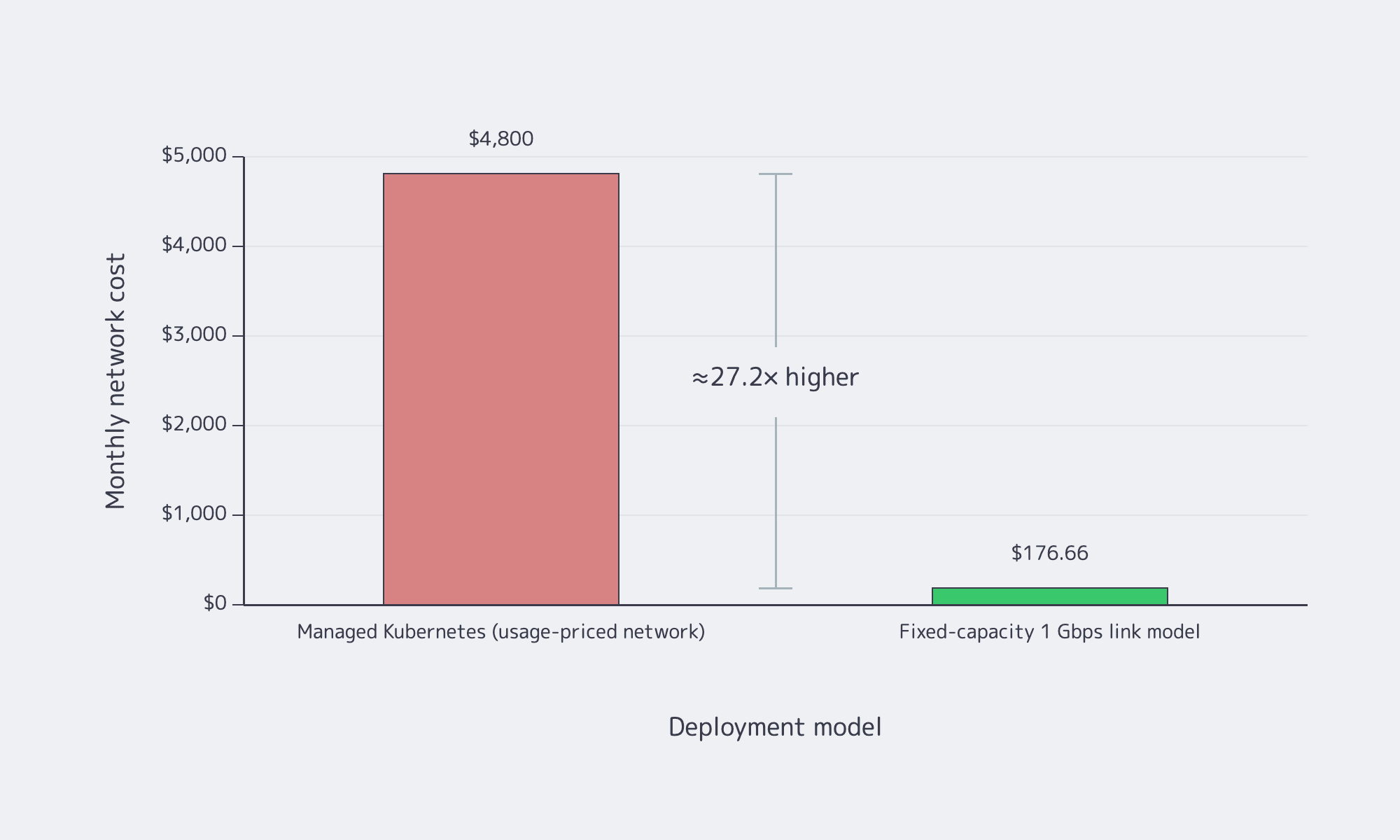
Managed Kubernetes shrinks the platform surface area you own, but it does not remove responsibility for workload design, policy, observability, or most storage decisions. The economic case for dedicated infra is strongest when network-heavy workloads punish usage-based pricing. One arXiv cost study modeled a monthly example at about $4,800 for a managed, usage-priced network path versus $176.66 for a fixed-capacity 1 Gbps link.
The trade is honest: dedicated infrastructure can change the cost shape, but only if provisioning, reboots, placement, and recovery are automated.
| Area | Large bare-metal Kubernetes (self-managed) | Managed Kubernetes |
|---|---|---|
| Control plane | You design HA, etcd hygiene, and API protection. | The provider runs more of the control plane, but clients and workloads can still overload it. |
| Networking | You supply load balancing, routing integration, and CNI policy behavior. | More primitives are prebuilt, but low-level control is narrower. |
| Node and storage lifecycle | You own patching, replacements, backup design, and performance isolation. | More integration is available, but application resilience and data design are still yours. |
Key Takeaways and Melbicom Fit
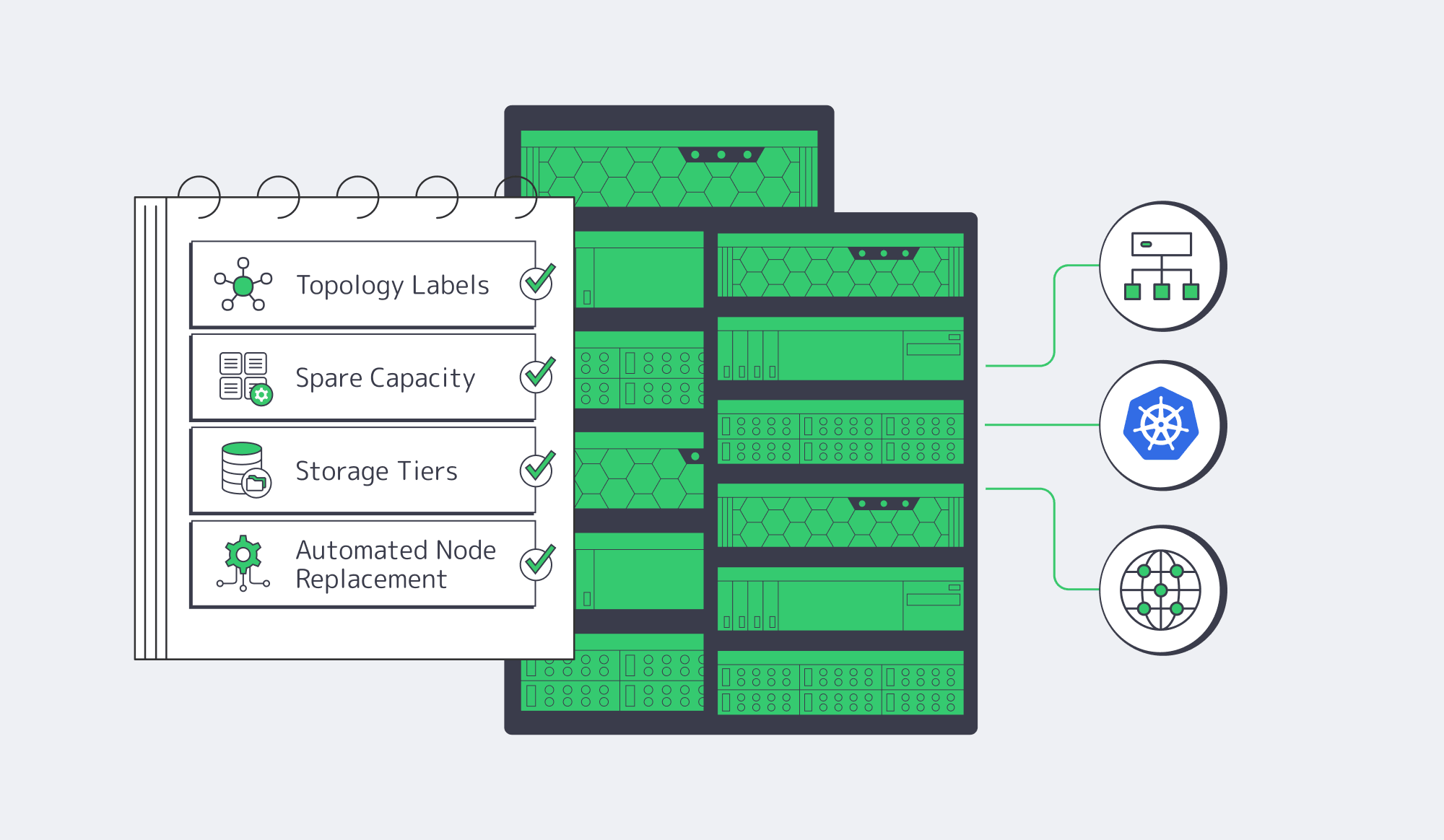
A big cluster is an operations boundary. Once racks, storage paths, and upgrade waves matter more than node count, the architecture has to privilege topology, routing, and automation over convenience. The best designs isolate failure domains, keep etcd fast, move traffic intentionally, tier storage, and treat hardware turnover as normal, because routing control, storage, and replacement cadence become part of the operating model.
- Model rack, power, and aggregation boundaries as first-class topology labels before maintenance turns into a shared-fate event.
- Reserve spare capacity and rollback room for every kernel, CNI, storage, and Kubernetes upgrade; blast radius should define rollout order.
- Standardize on L3 multi-rack networking and explicit service exposure so failures show up as routable problems instead of opaque “cluster weirdness.”
- Separate hot-path, failover, and retention storage into distinct tiers; one plane rarely satisfies latency, recovery, and telemetry economics at once.
Build on Bare Metal
Explore dedicated servers, BGP sessions, and S3-compatible storage for large Kubernetes clusters that need predictable networking, recovery, and upgrade headroom.