Blog
Bare Metal Server vs Cloud: Checklist for Performance, Compliance, and Cost
The old “bare metal vs cloud” argument was mostly about raw speed. That frame no longer holds. Published MLPerf Inference submissions on the same Dell PowerEdge XE9680 / 8x H200 platform show only low-single-digit differences between bare-metal and virtualized results on several throughput figures. The bigger differences now show up in tail latency, noisy-neighbor risk, auditability, and cost predictability.
That change tracks the market. Gartner forecast public cloud end-user spending at about $723.4 billion, Synergy Research Group estimated cloud infrastructure services revenue at $419 billion, and Flexera reported 29% wasted cloud spend alongside 58% usage of generative AI as a public cloud service. At this scale, picking the wrong substrate becomes an operating-model problem, not just a hosting preference.
Choose Melbicom— 1,300+ ready-to-go servers — Custom builds in 3–5 days — 21 Tier III/IV data centers |
 |
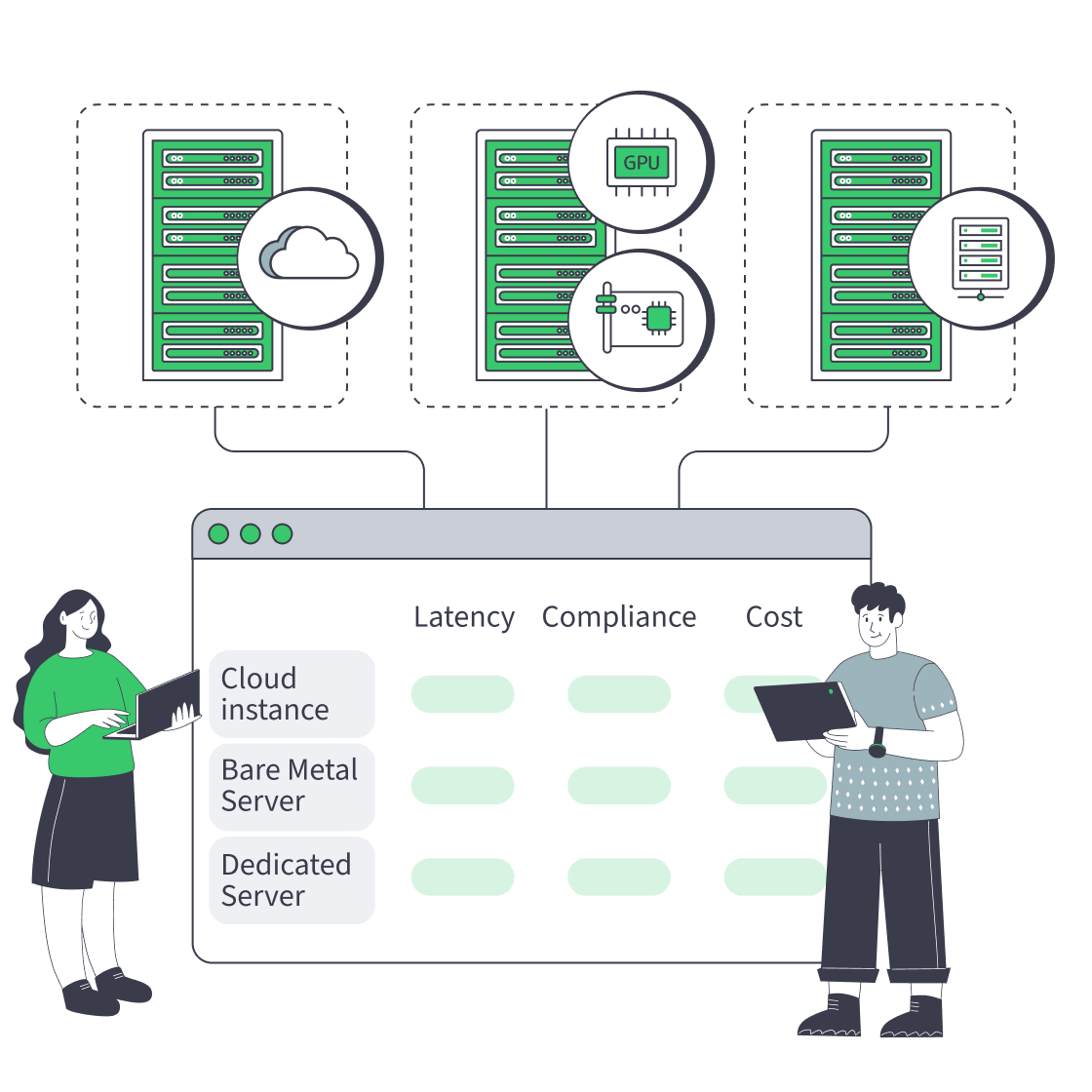
How Bare Metal, Dedicated Servers, and Cloud Instances Differ in Practice
Use cloud instances when elasticity and managed-service adjacency matter most. Use a bare metal server when you need physical determinism plus automation. Use dedicated server abstraction when you want single-tenant hardware as a stable, long-lived substrate with predictable cost and provider support. The choice is less about “fast versus slow” than about variance, control, and operational ownership.
Definitions that survive contact with production
A cloud instance is compute behind an API. You choose a shape, launch quickly, and pair it with managed services, but usually with less visibility into placement and contention.
A modern bare metal server is single-tenant hardware delivered with cloud-like expectations: API-driven lifecycle, fast rebuilds, and fleet-style management. Tools such as OpenStack Ironic + Metal3 exist to make physical hosts behave more like declarative infra.
A dedicated server is also single-tenant hardware, but the operational intent is different. It is a durable node in a known location, rented for stability, support, predictable economics.
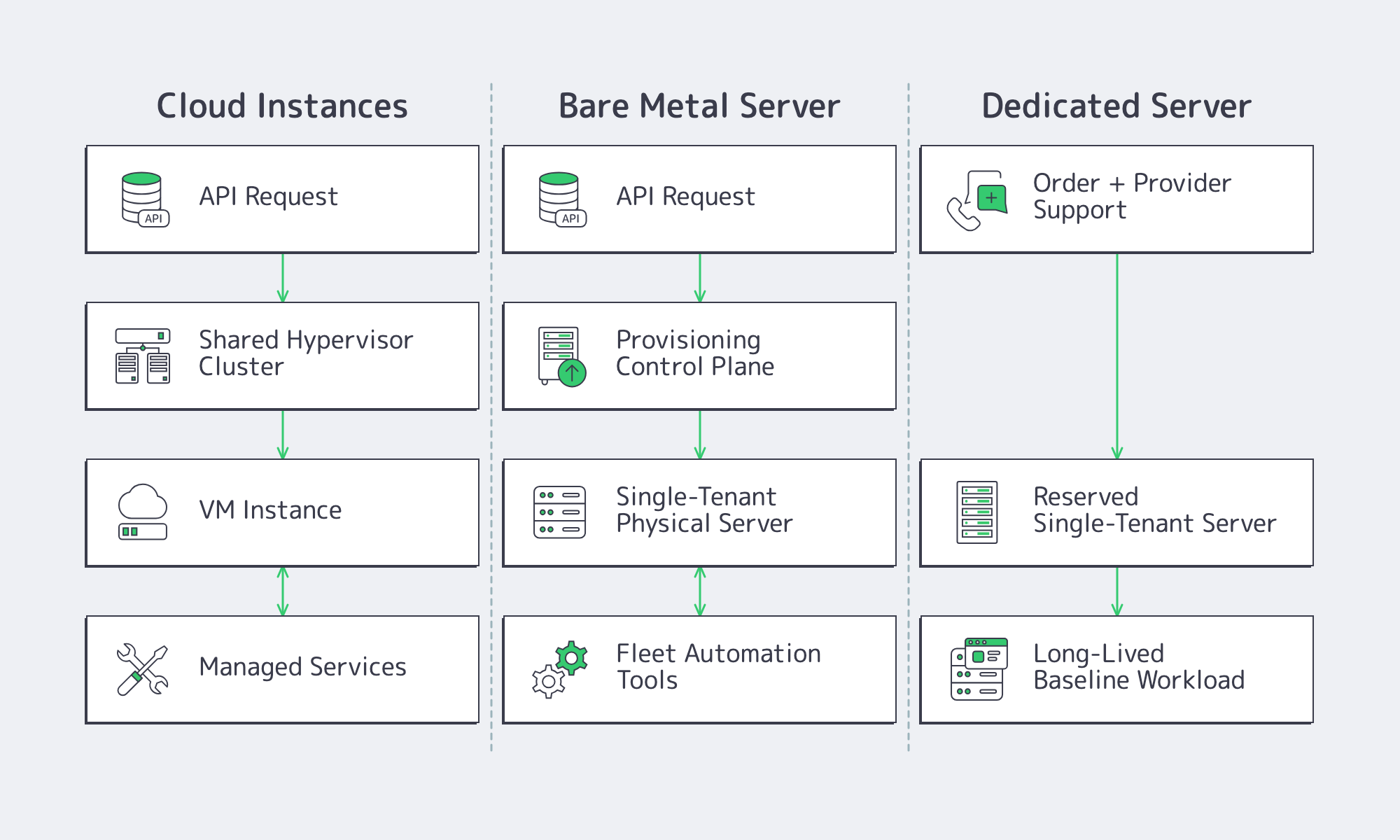
Bare metal server vs dedicated server: where the line actually is
The overlap is tenancy; the split is lifecycle. Bare metal is usually treated like part of a rebuildable fleet. Dedicated is usually treated like a stable substrate that you tune, keep, and plan around. “Cloud-like provisioning” on bare metal also does not mean instant by magic. It means automating the boot path and accepting more lifecycle responsibility.
When Bare Metal Is the Better Choice for Performance, Compliance, or Control
Bare metal is the better choice when performance debugging keeps pointing to placement, jitter, I/O contention, or specialized hardware paths. It can also simplify audit and residency conversations because tenancy boundaries are explicit. The value is not automatically higher average throughput; it is fewer hidden neighbors, fewer hidden schedulers, and clearer control over the machine itself.
Deterministic performance is about tail behavior
Performance-sensitive systems fail at P99, not at the median. Distance through fiber adds unavoidable delay before routing inefficiencies and queueing even enter the picture. Shared infrastructure adds another layer of uncertainty. That is why the strongest case for bare metal is often not headline throughput, but fewer surprises in the tail.
Noisy neighbors and hardware paths are the real differentiators
In a recent Kubernetes multi-tenant testbed study, researchers reported I/O-bound degradations of up to about 67% under combined noisy-neighbor stress. Even if your own environment never gets that bad, the structural risk is obvious. If your stack depends on stable cache behavior, known topology, predictable storage latency, or specialized NIC and accelerator paths, single-tenant hardware is easier to reason about. (arXiv)
Compliance and control often get simpler
Single-tenancy does not create compliance by itself, but it can make controls easier to explain. Gartner projected about $80 billion in sovereign cloud IaaS spending and described a shift of 20% of current workloads from global to local providers. That is a sign that locality, change control, and clearer boundaries are becoming design requirements.
What Automation + Operational Trade-Offs Come With Moving From VMs to Bare Metal
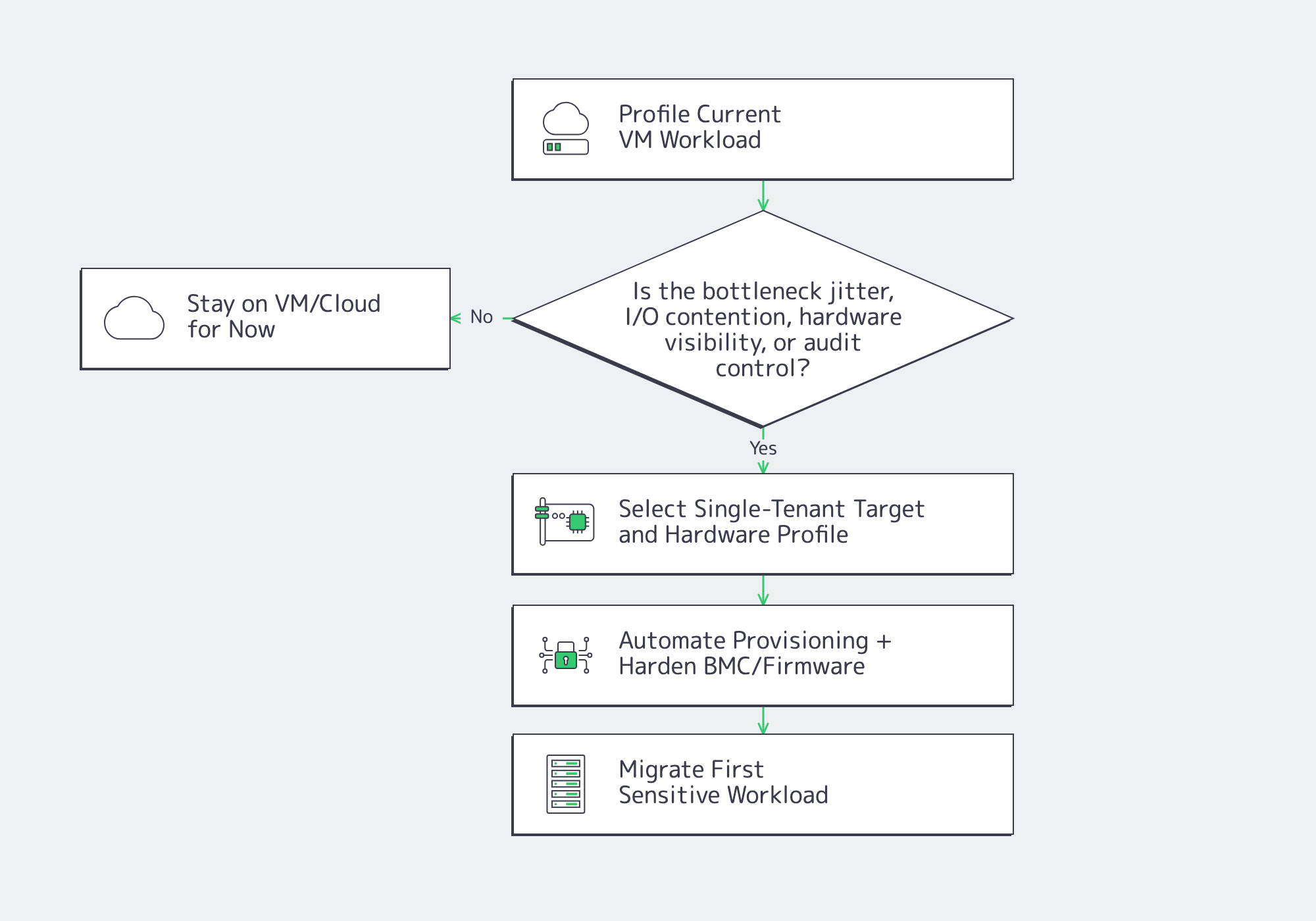
Moving from VMs to bare metal replaces clone-based convenience with hardware-aware operations. You gain determinism, but you also inherit the boot path, firmware lifecycle, BMC hardening, and spare-capacity planning. Teams that do this well automate provisioning early, treat host loss as normal, and move the noisiest or most control-sensitive services first.
Provisioning changes from “clone a VM” to “own the boot path”
On bare metal, provisioning becomes control plane to BMC to network boot or virtual media to OS image to configuration management. Ironic and Metal3 matter because they turn that sequence into an API-backed workflow instead of a rack-by-rack ritual.
Lifecycle, lead time, and BMC security become architecture concerns
Hardware is visible again: capacity planning, host replacement, firmware updates, and failure domains stop being somebody else’s abstraction. So does out-of-band management. NIST SP 800-193 and joint NSA/CISA guidance are clear that BMCs are highly privileged control planes and need separate hardening, segmentation, and patch discipline.
Migration friction is sometimes more expensive than compute
Leaving cloud is often less about CPU and more about data gravity, identity wiring, and the loss of VM-native conveniences. The UK Competition and Markets Authority has explicitly treated egress fees and related switching barriers as a competition problem. That makes data movement a first-class architecture cost.
Bare Metal Server Decision Checklist for Performance, Compliance, and Cost
Use the matrix below as a biasing tool, not a rigid rule. It is most useful when the real constraint is easy to name: variance, governance, hardware specificity, or cost shape.
| Decision Signal | Bias Toward | Why It Matters |
|---|---|---|
| Tail latency or jitter drives the SLO | Bare metal server or dedicated server | Physical isolation makes P99 tuning more predictable. |
| Shared I/O contention is the pain point | Bare metal server or dedicated server | Noisy neighbors can collapse disk or network behavior long before average CPU looks busy. |
| Audit, residency, or hardware-control requirements dominate | Bare metal server or dedicated server | Explicit single-tenancy and known hardware boundaries simplify evidence collection and change control. |
| You need known topology or specialized NIC/GPU behavior | Bare metal server or dedicated server | Repeatable hardware paths matter more than generic flexibility. |
| You want fleet-style hardware automation | Bare metal server | Ironic- and Metal3-style workflows fit rebuildable physical fleets. |
| You need fast burst capacity or managed-service adjacency | Cloud instances | Elasticity remains cloud’s clearest strength. |
| Your stack still depends on snapshots, quick clones, or live migration | Cloud instances, unless replaced at the app layer | VM-native workflows need redesign before metal feels natural. |
| Steady demand and volatile egress bills dominate the economics | Dedicated server | Flat monthly pricing and reserved port capacity make baseline cost easier to plan. |
A quick reality check on performance
The common myth is that bare metal wins mainly by avoiding the hypervisor. The more useful lesson from MLPerf Inference is narrower: average compute overhead can be modest, while placement and contention still dominate the user-visible outcome. On the same Dell PowerEdge XE9680 / 8x H200 platform, several published virtualized results sit within a few percentage points of the bare-metal submissions.
Migration Notes from VM-First Environments
- Identify the actual bottleneck. Move the workload constrained by jitter, storage latency, hardware visibility, or compliance pressure, not the one that is easiest politically.
- Start where single-tenancy buys down variance. Datastores, gateways, schedulers, and ingestion layers are common first moves.
- Keep adjacent interfaces stable. Melbicom’s S3 storage and CDN can let teams move sensitive compute first without rebuilding every data and delivery pattern at once.
- Treat network control as part of the design. Melbicom’s dedicated servers pair single-tenant hardware with API and KVM access, and Melbicom’s BGP sessions — including BYOIP — are available from all locations and free on dedicated servers when routing behavior is part of the product.
Key Takeaways for the Next Architecture Review
- Measure P95/P99, jitter, and storage variance before changing platforms. Median throughput alone is not a decision framework.
- Move the workloads that suffer from hidden contention, hardware opacity, or audit friction first; leave bursty, disposable, or service-adjacent pieces in cloud until the application layer is ready.
- Price migration as a systems change, not a server swap. Data movement, identity rewiring, and the loss of snapshot-heavy workflows can outweigh any compute savings.
- Do not scale bare metal operationally until provisioning, firmware policy, and BMC isolation are standardized. Otherwise every performance gain turns into day-two debt.
Conclusion: Choose for Variance, Control, and Operating Model
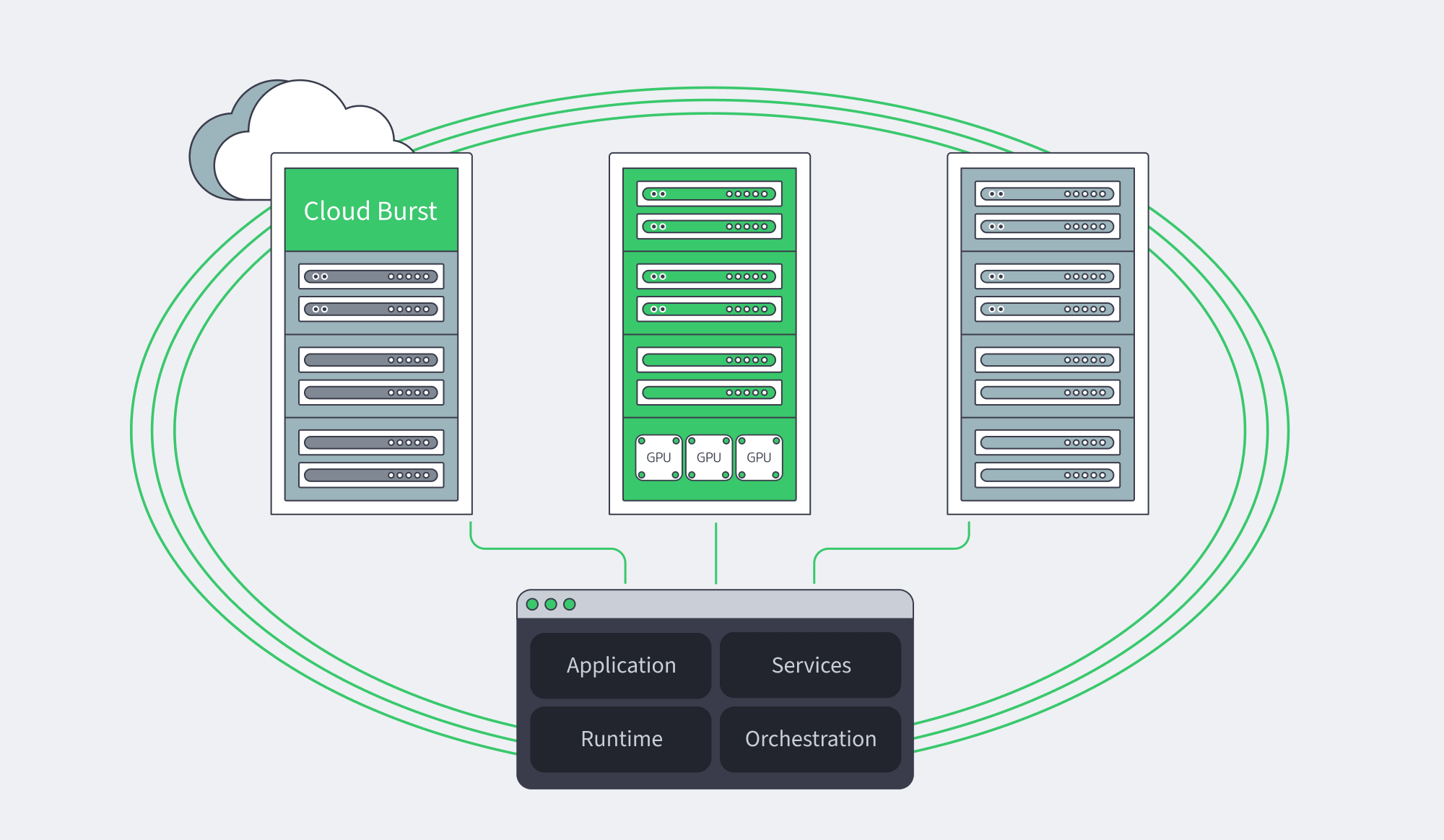
The best answer is rarely “cloud everywhere” or “metal everywhere.” It is usually a split: cloud where elasticity and managed services create real leverage, dedicated servers where single-tenant stability and predictable monthly cost matter most, and bare metal where hardware-level determinism and automation justify the extra operational ownership.
That is also why this comparison keeps returning. Performance-sensitive platforms do not need a slogan about bare metal being universally faster. They need a practical way to decide when variance, compliance, hardware control, and migration economics are important enough to justify moving down the abstraction ladder.
Explore dedicated servers
Compare single-tenant server options for performance-sensitive workloads that need predictable monthly cost, hardware control, and global deployment.