Blog
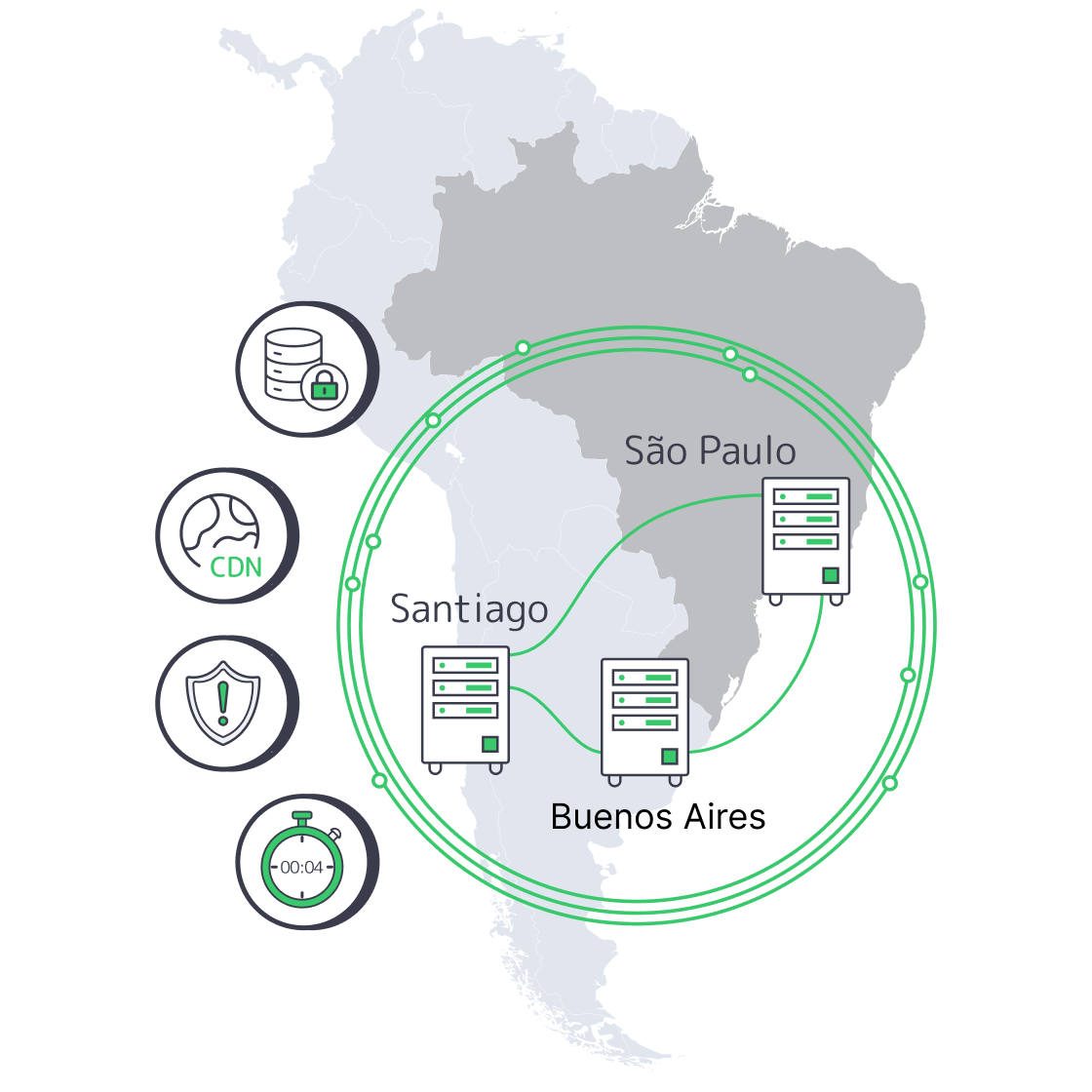
Active/Active Across São Paulo, Santiago, Buenos Aires
South America forces availability engineering to get honest—fast. When your workload is regulated (payments), adversarial (crypto), or real-time (iGaming cores), you don’t get to treat a region as “just another edge.” You have to prove uptime under partial failure: broken fiber segments, bad upstream routes, and the kind of cascading latency spikes that turn “highly available” into “highly unpredictable.”
This playbook shows how to run active/active clusters across São Paulo, Santiago, and Buenos Aires using dedicated hosting patterns that survive real incidents: transaction-safe replication, health-based traffic steering, and a CDN that can absorb volatility without masking it.
Choose Melbicom— Reserve dedicated servers in Brazil — CDN PoPs across 6 LATAM countries — 20 DCs beyond South America |
 |
South America Dedicated Server Requirements for “No-Excuses” Uptime
If you’re shopping for a South America dedicated server setup for 24/7 apps, don’t start with hardware checklists. Start with failure math:
- Every region is a set of metro failure domains. São Paulo, Santiago, and Buenos Aires are not just points on a map; they’re independent blast radii.
- Your data layer decides your uptime story. If the ledger can’t fail over safely, your active/active front end is theater.
- Routing must be health-based and reversible. Steer based on measured health (app + data), not on geography.
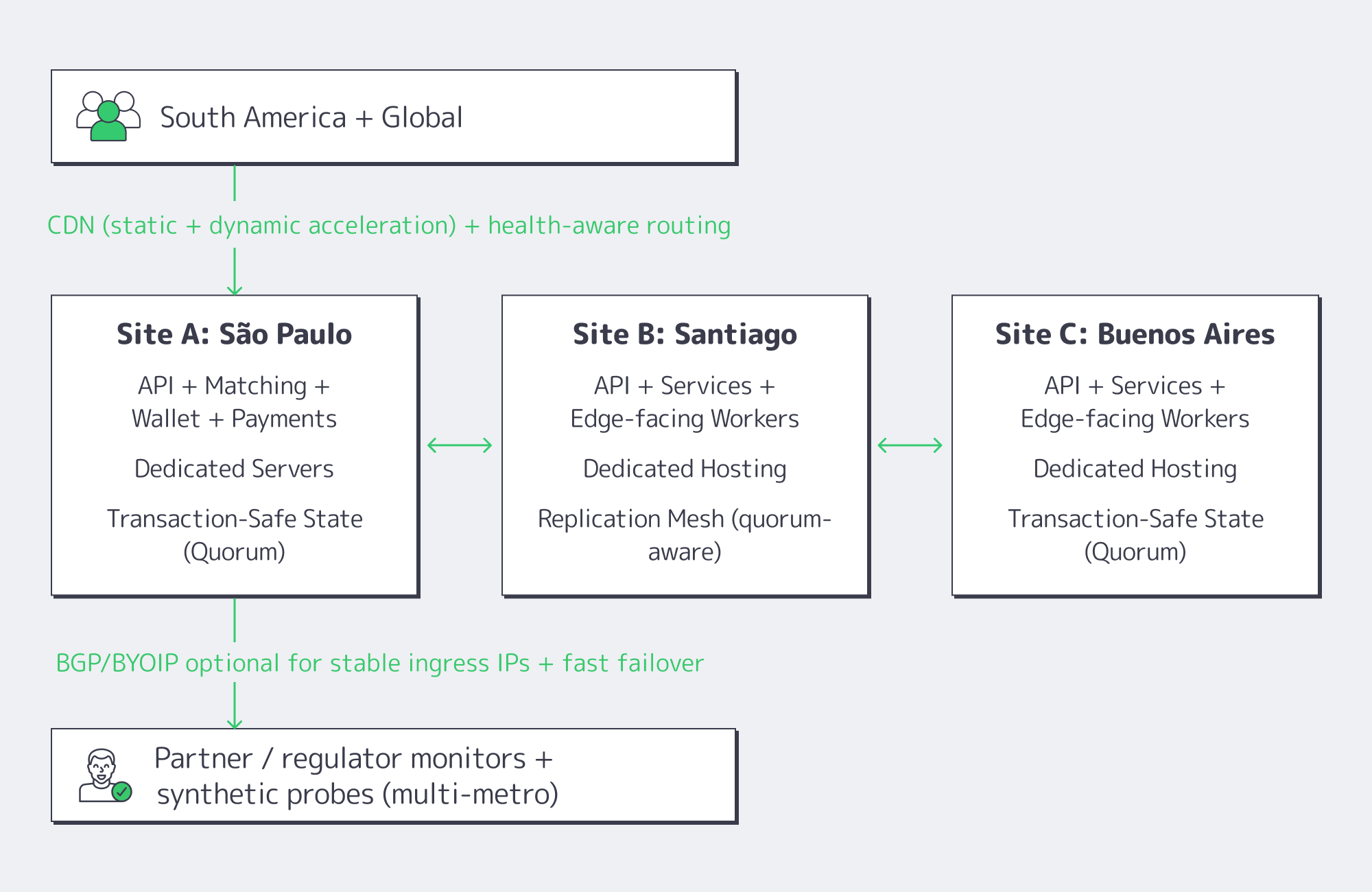
Diagram. The Three-Site Active/Active Shape
Melbicom supports the primitives you need for this design—BGP sessions (including BYOIP), private networking/inter-DC links, and S3-compatible object storage for snapshots/rollback artifacts—so your HA plan isn’t glued together from one-off scripts.
What Active/Active Dedicated Hosting Architecture Keeps 24/7 Apps Online Across South America?
Active/active that actually works in South America is a three-site design: each metro runs full production services, while a transaction-safe data core enforces correctness across sites. Put São Paulo on dedicated servers as the throughput anchor, use Santiago and Buenos Aires as equal peers, and front everything with health-based routing plus CDN shielding so failures degrade locally—not region-wide.
Dedicated Hosting in South America: The Stack That Holds Under Stress
For crypto exchanges, Web3 wallets, payment gateways, and iGaming cores, break the platform into three layers:
- Edge layer (CDN): static assets, API caching where safe, WAF rules if you use them, and the ability to steer around failures quickly.
- Stateless service layer: auth, pricing, game logic, matchmaking, session services—everything horizontally scalable.
- State layer: balances, orders, settlements, wallet state, player economy—anything that can’t be “eventually fixed” after an incident.
Melbicom’s CDN is explicitly built for multi-origin routing and automatic failover, delivered through 55+ PoPs in 36 countries (including Brazil, Argentina, Chile, Peru, and Columbia), which matters because the edge is where you buy time during a regional brownout (latency spikes, packet loss, upstream route churn).
São Paulo as the Regional Anchor (And Why It’s Not Optional)
São Paulo is where South America’s “always-on” backends usually converge because it’s the region’s interconnection gravity well: from there, you can reach IX.br’s 2,400+ networks, and latency can drop dramatically once you stop tromboning traffic via other continents.
Which Replication Strategy Between São Paulo, Santiago, and Buenos Aires Can Meet Strict RPO/RTO Targets?
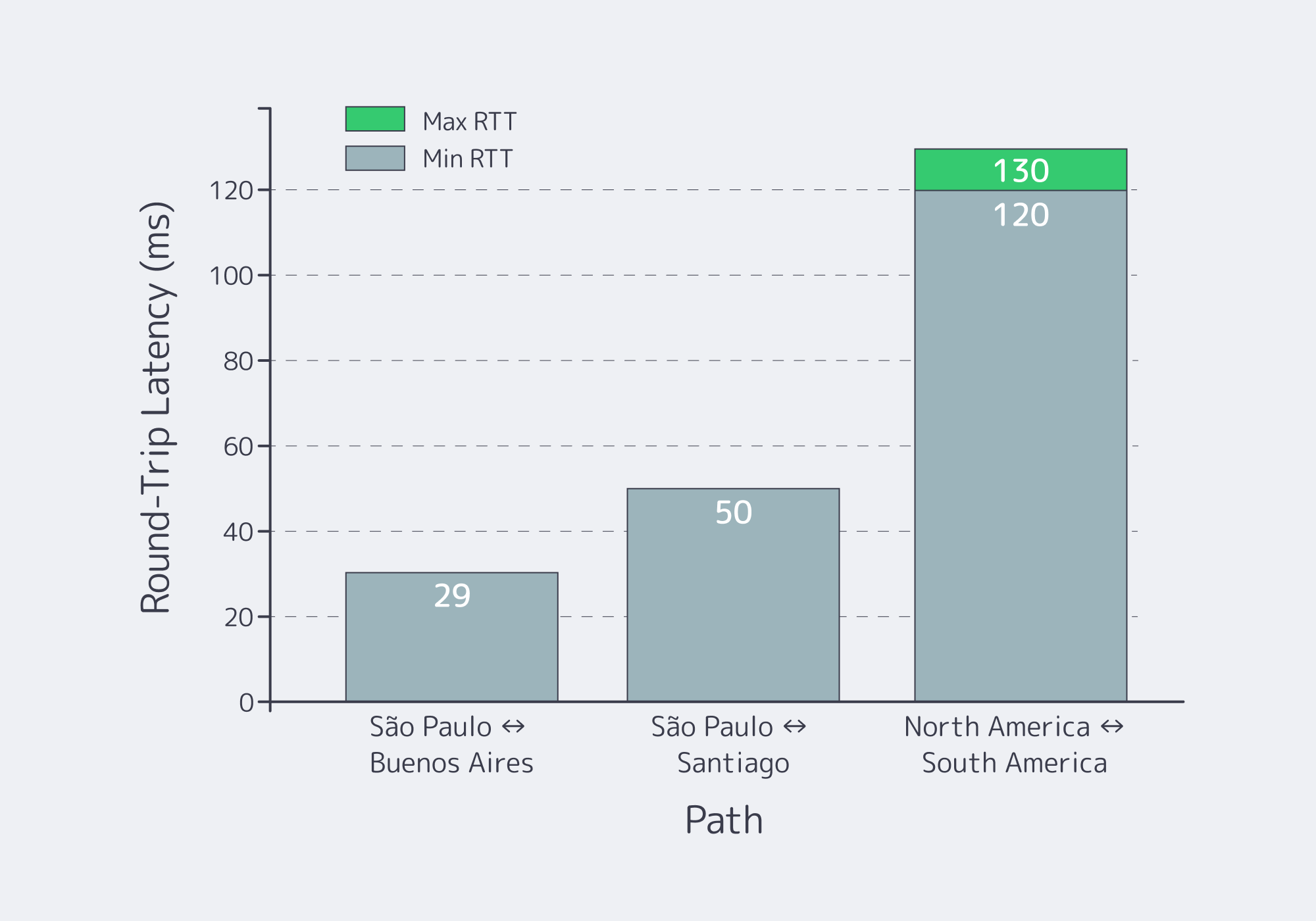
The replication strategy that hits strict targets is quorum-based, transaction-safe replication for the critical ledger, paired with asynchronous replication for everything else. Use synchronous commits only where “no lost transaction” is a hard requirement; otherwise replicate asynchronously with monitored lag. This yields near-zero RPO for the ledger and minute-scale RTO with automated promotion.
The Practical Replication Split: “Ledger vs. Everything Else”
A workable pattern in regulated systems:
- Tier 0 (Ledger / balances / settlement): quorum-based replication (Raft/Paxos-style consensus or another transaction-safe system) across three metros.
- Tier 1 (Orders, sessions, gameplay state): async replication + idempotency + replay.
- Tier 2 (analytics, logs, non-critical caches): async batch replication or rebuild.
Table: Replication Choices and Realistic RPO/RTO Outcomes
| Replication Mode (Three-Site) | Realistic RPO | Realistic RTO |
|---|---|---|
| Quorum-based, synchronous commit for ledger | 0 for committed txns | ~30–180s (automated failover + routing convergence) |
| Async replication with monitored lag (services + read models) | seconds (bounded by lag alarms) | ~1–5 min (promote + warm caches) |
| Snapshot/backup-driven recovery (last resort) | minutes to hours | hours (restore + rehydrate + verify) |
These are engineering targets, not marketing numbers. You only get the top row if you keep the quorum small (3 sites), keep the critical dataset scoped (ledger-only), and make routing conditional on data health—not just HTTP health.
Brazil Deploy Guide— Avoid costly mistakes — Real RTT & backbone insights — Architecture playbook for LATAM |
 |
Which Traffic Routing and CDN Pattern Across South America Maximizes Uptime for Regulated Workloads?
Use a two-tier routing design: CDN first (multi-origin + health checks) for everything cacheable and latency-sensitive, and BGP/BYOIP-based stable ingress for APIs that must keep fixed endpoints. Route only to sites that are healthy at both the app layer and the data layer; otherwise you’ll fail “correctly” but still break users.
Health-Based Routing That Isn’t Geo-DNS
Skip old geo-DNS tricks. Use:
Real health signals (not just “port open”):
- API p95 latency
- dependency health (DB quorum status, replication lag thresholds)
- queue depth / saturation
A routing controller that can make the call:
- CDN origin selection for web + assets
- L7 load balancer decisions for APIs
- BGP failover/anycast when fixed IPs are required
Melbicom’s BGP service is designed for this category of control—BGP at every data center, with routing policy support and IRR integration—so you can keep endpoints stable while still failing over quickly.
The CDN Pattern: Shield + Multi-Origin + Fast Purge
For regulated workloads, CDN is not “just static assets.” It’s a resilience layer:
- Origin pooling: keep three origins hot (SP/SCL/BUE) and route to the best healthy one.
- Shielding: reduce cross-border chatter by collapsing cache misses to a regional shield (often São Paulo), then distribute.
- Fast purge + versioned assets: when you push a critical client fix (wallet UI, payment flow), purge globally without waiting on TTL drift.
Melbicom’s CDN delivers instant cache purge across PoPs and supports multi-origin routing patterns explicitly.
Code example: a concrete “Only Route If Data Is Safe” gate
Below is a simple pattern, not a vendor-specific magic trick: the router only sends traffic to a site if (1) the API is healthy and (2) the site reports “ledger quorum OK” or “replication lag < threshold.”
| | routing_policy:sites:sao_paulo:http_health: https://sp.example.com/healthzdata_health: https://sp.example.com/ledger-quorumsantiago:http_health: https://scl.example.com/healthzdata_health: https://scl.example.com/ledger-quorumbuenos_aires:http_health: https://bue.example.com/healthzdata_health: https://bue.example.com/ledger-quorumdecision:- if: “data_health != OK”action: “drain_site” # do NOT route writes here- if: “http_health != OK”action: “remove_from_pool”- else:action: “weighted_route” # bias nearest healthy site | |
This is how you avoid the most common active/active failure mode: routing users to a site that’s “up” but not safe.
FAQ
Does active/active mean “no downtime ever”?
No. It means you can survive site failure without a full outage. You still need maintenance windows, rollback plans, and a strict definition of “correctness” under partial failure.
Can we hit zero RPO and sub-minute RTO at the same time?
For the ledger: often yes, if you scope the synchronous/quorum system to the critical dataset and keep automated routing tied to data health. For all state: usually no, because latency becomes the outage.
Where does object storage fit?
Use S3-compatible object storage for snapshots, rollback artifacts, and forensic retention. It’s not your hot-path database; it’s your “recover and prove” layer.
Closing the Loop: Proving Uptime, Not Promising It

The South America active/active story that passes scrutiny is simple: three metros, a ledger that replicates safely, and routing that refuses to lie. If São Paulo is degraded, Santiago and Buenos Aires should keep serving—but only when the data layer says it’s safe. If the data layer isn’t safe, you fail closed, preserve correctness, and recover fast.
Before going live, document the failure model you’re willing to survive (loss of one metro, loss of one interconnect path, partial packet loss), then build the telemetry and routing gates to enforce it. That’s what regulators, partners, and enterprise customers ultimately care about: not the diagram, but the evidence trail.
- Treat the ledger as a separate system with its own RPO/RTO targets; don’t let it inherit the “stateless scaling” assumptions of the API tier.
- Gate routing on data health, not just HTTP health (quorum status, replication lag, write availability).
- Keep a playbook for draining a site (read-only mode, write redirection, cache shielding) that can be executed automatically and verified externally.
- Use CDN as a resilience amplifier (multi-origin + shielding + purge discipline), not as a UX-only tool.
- Store rollback artifacts and snapshots where they can be audited and restored—then test restores as a scheduled production exercise.
Plan your São Paulo active/active rollout
Talk to our engineers about BGP/BYOIP, CDN, and S3-backed rollback so your South America active/active design is measurable, testable, and resilient.