Blog

Choosing Between Object and Block Storage for Your Workloads
Designing a dedicated server environment inevitably runs into a core decision: how to store data. The answer is rarely either/or; it hinges on the workload’s access patterns and long-term trajectory. As global data pushes toward ~180 zettabytes and ~80% of it remains unstructured, the storage fabric must offer both the low-latency precision of block volumes and the scale-out economics of object stores. The sections below compare the two models—architecture, metadata, scalability, consistency, and performance—then map them to best-fit workloads and a practical decision matrix that includes cost, compliance, and hybrid strategies (including S3-compatible gateways).
Choose Melbicom— 1,300+ ready-to-go servers — 21 global Tier IV & III data centers — 55+ PoP CDN across 6 continents |
 |
Object Storage vs. Block Storage: Architectures and Metadata
Block storage exposes a raw device to the OS. Data is split into fixed-size blocks, addressed by offset. The storage layer itself carries no content metadata; meaning and structure come later from the file system or database engine. This minimalism is a feature: it delivers direct, fine-grained control with minimal overhead, ideal for transactional systems and anything expecting POSIX semantics.
Object storage treats data as self-describing objects in a flat address space, each with a unique key and rich, extensible metadata (content type, tags, retention policy, custom attributes, checksums). Access is via HTTP APIs (commonly S3-compatible) rather than a mounted disk. The metadata dimension is decisive: it makes classification, lifecycle policies, and large-scale search practical without bolting on external catalogs.
Implications for dedicated deployments:
- Block volumes (local NVMe/SSD/HDD or SAN-backed LUNs) mount directly to a dedicated server. They favor in-place updates (e.g., 4K rewrites), strict write ordering, and tight OS integration.
- Object stores typically live as a separate service/cluster accessible over the network. They favor write-once/read-many patterns, bulk ingestion, and global distribution, with metadata policies enforcing retention and access.
Object Storage vs. Block Storage: Scalability and Consistency
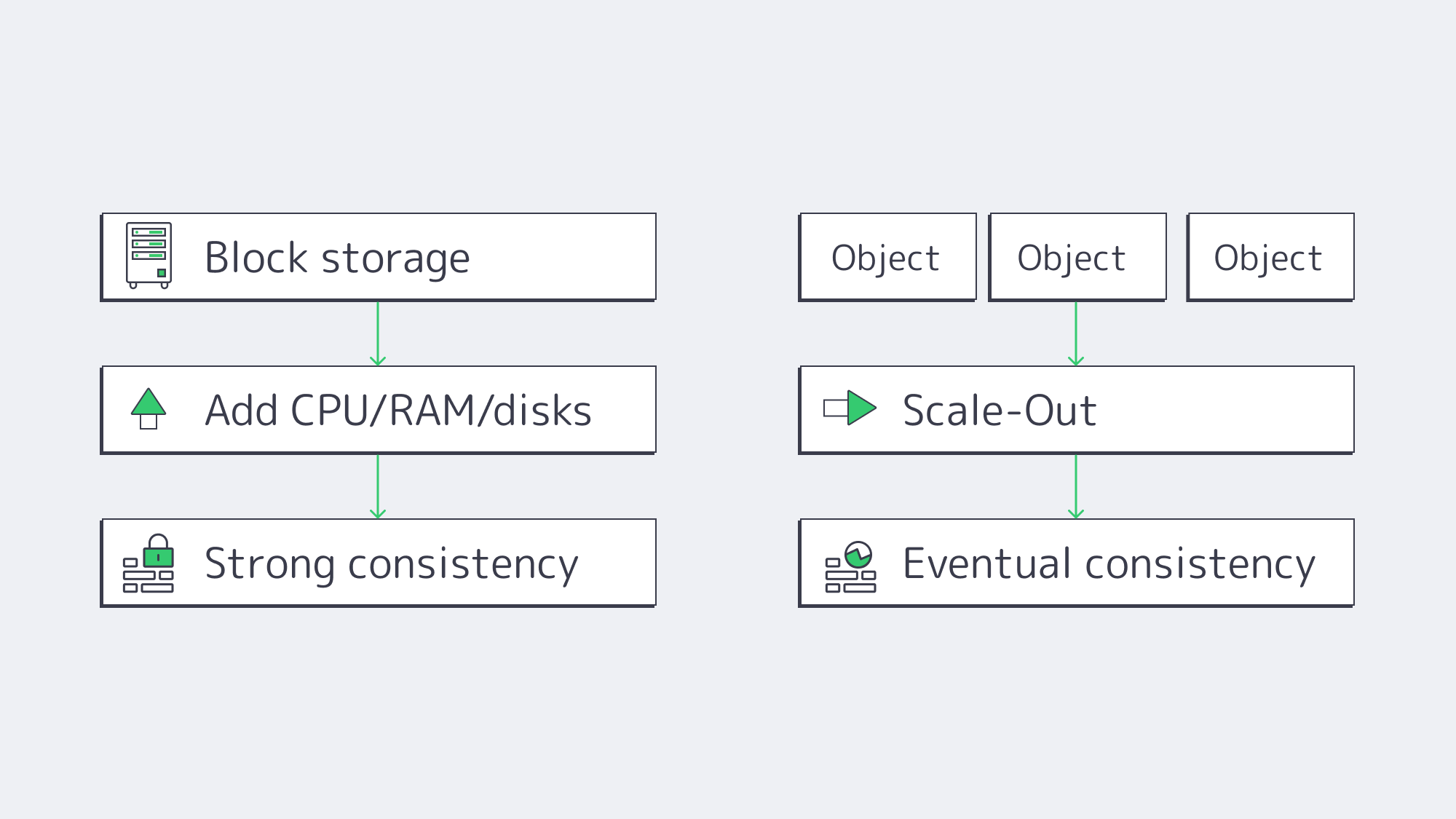
Scalability ceilings. Object storage scales by adding nodes—billions of objects across petabytes is routine thanks to flat namespaces and distribution. Growth is elastic: expand capacity without re-sharding applications. Block storage scales up impressively inside a server or array, but hits practical limits sooner. Beyond a volume/array’s comfort zone, you add LUNs, orchestrate data placement, and manage RAID rebuild domains—operationally heavier at multi-hundred-TB to PB scale.
Durability model. Object stores build durability into the substrate—multi-copy replication or erasure coding across nodes/rooms/regions—with common claims like “eleven nines” of durability. Block storage inherits durability from RAID, mirroring, and backups; robust, but traditionally your responsibility to design and operate.
Consistency. Block storage typically provides strong, immediate consistency at the device boundary; when a write completes, subsequent reads reflect it—non-negotiable for databases and VM block devices. Object systems historically leaned on eventual consistency to scale and remain available across partitions; modern platforms increasingly offer read-after-write or configurable strong consistency, but the default economics still favor eventual consistency for internet-scale workloads. Choose accordingly: strict transactions → block; massive, distributed reads with looser immediacy → object.
Performance profiles: latency, throughput, and IOPS
Latency. Local block storage (especially NVMe) routinely delivers sub-millisecond access. Modern enterprise NVMe drives can sustain read/write latencies well under 1 ms, making tail latency predictable for OLTP and VM workloads. Object access involves network hops and protocol overhead (authentication, HTTP), so small-object first-byte latency lands in the tens of milliseconds. That’s acceptable for archives, analytics batches, and media delivery—not for hot database pages.
IOPS. Block shines on small random I/O. A single NVMe can exceed 1,000,000+ 4K IOPS with enough queue depth and CPU. Filesystems and DB engines exploit this concurrency with fine-grained flush and journaling strategies. Object stores do not optimize for tiny random updates; each PUT/GET is a whole-object operation, better amortized over larger payloads.
Throughput. For large sequential transfers, both models can saturate high-bandwidth links, but object storage often scales aggregate throughput higher by striping a large object across many disks/nodes and reading in parallel. A single NVMe can deliver ~7 GB/s; an object cluster can exceed that for multi-GB objects when the network and clients pipeline aggressively. Rule of thumb: block for latency/IOPS, object for bandwidth at scale.
Two canonical scenarios:
- Relational or NoSQL database on a dedicated server. Needs low-jitter sub-ms access and in-place updates. Keep data/logs on local NVMe or SAN block volumes. Object storage can still serve the ecosystem: WAL/archive logs, snapshots, and cold backups.
- Media delivery or data-lake analytics. Store originals and derived assets as objects; read at high throughput via parallel GETs and push through a CDN. Accept slightly higher start latency for orders-of-magnitude easier fan-out and lifecycle cost controls.
Best-Fit Workloads
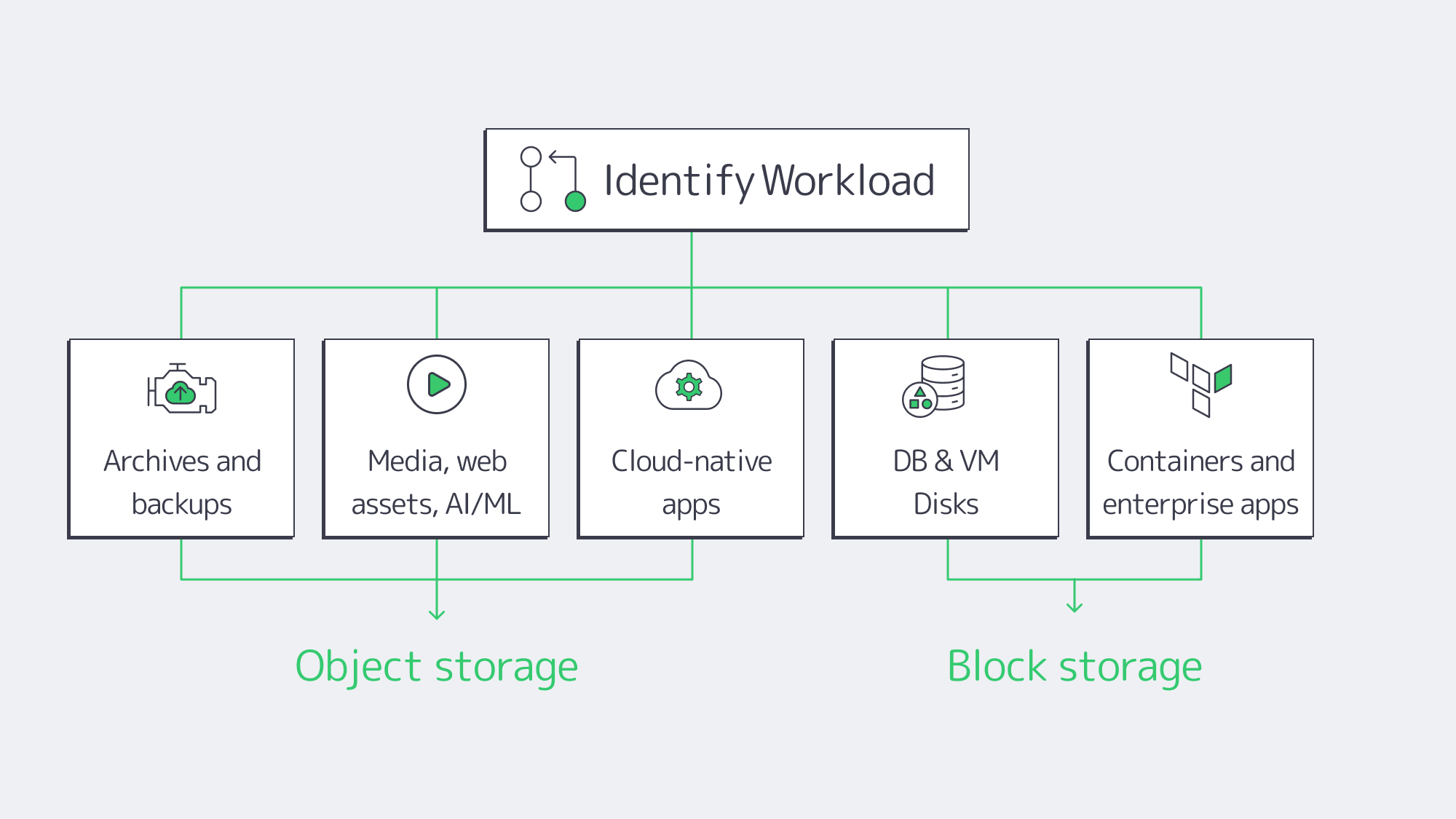
Object storage excels at:
- Archives and backups. Write-once/read-many, versioning, and lifecycle policies enable long-term retention with integrated integrity checks. Cold tiers can cut costs by up to ~80% for infrequently accessed data.
- Media, web assets, AI/analytics inputs. Parallel reads, global accessibility, and rich metadata make it the default backbone for images, video, logs, clickstreams, and ML training corpora.
- Cloud-native apps. Microservices exchange artifacts and user content via S3 APIs; metadata drives governance, and replication underpins cross-site DR.
Block storage is the default for:
- Databases and VM disks. Low-latency, strong consistency, in-place updates. Enterprises routinely keep sub-1 ms latency targets for mission-critical systems.
- Stateful containers and enterprise apps. Persistent volumes, high IOPS scratch capacity, and deterministic flush semantics for ERP/CRM streams, message queues, and build pipelines.
Decision Matrix: Cost, Compliance, Operations, and Hybrid Readiness
Cost. Object storage wins on $/GB at scale, running on commodity nodes with automatic tiering; capacity grows elastically, so less over-provisioning. Block storage commands a higher $/GB (especially NVMe) and often requires provisioning for peak IOPS—wasteful when average IOPS are lower (teams routinely overbuy by factors of ~2–3). Shifting static content and archives off block to object commonly yields ~30% spend reductions; moving render outputs or backups to object while keeping hot scratch on NVMe has shown ~40% performance gains in production pipelines.
Compliance and security. Object storage natively supports WORM (object lock), bucket/object-level ACLs, versioning, and geo-replication—ideal for audit logs, legal holds, and long-term records. Block relies on volume encryption, OS permissions, snapshots, and external backup/replication tools to achieve similar ends.
Operations. Object clusters scale out with minimal re-architecture; add nodes, let the service rebalance, and enforce lifecycle policies centrally. Block requires deliberate capacity and performance planning: RAID level selection, LUN layout, queue tuning, snapshot windows, and database/table partitioning as datasets grow.
Hybrid readiness. S3 has become the lingua franca. S3-compatible gateways can expose object buckets as NFS/SMB to legacy apps or cache writes locally while committing to the object backend—practical for phased migrations. Conversely, NVMe-over-Fabrics pushes block semantics across the network with near-local latency, enabling disaggregated “block pools” for dedicated fleets.
Comparison at a Glance
| Factor | Object Storage | Block Storage |
|---|---|---|
| Architecture | Distributed service, HTTP (S3) access; flat namespace with object keys. | Device-level volumes to the OS (local or SAN/iSCSI/NVMe-oF). |
| Metadata | Rich, extensible metadata per object; first-class for policy/search. | None at the block layer; context comes from the file system or app. |
| Scalability | Elastic scale-out to billions of objects/petabytes with node adds. | Scales up well but hits volume/array ceilings; add LUNs and manage placement. |
| Durability | Built-in replication/erasure coding; “11 nines” durability claims are common. | Provided by RAID/mirroring/backups you design and operate. |
| Consistency | Eventual by default at internet scale; many platforms offer read-after-write or tunable strong modes. | Strong and immediate at the device boundary; ideal for transactions. |
| Latency | Tens of milliseconds typical for small objects (network + API). | Sub-millisecond on NVMe/SSD is common for small random I/O. |
| Throughput | Excellent for multi-GB transfers via parallel reads across nodes. | Excellent within a server/array; single device ~7 GB/s; scale beyond requires sharding. |
| IOPS | Not optimized for tiny random updates; whole-object PUT/GET. | High IOPS (often 1M+ per NVMe) for 4K random operations. |
| Workloads | Archives, backups, media, data lakes, AI/analytics inputs, cloud-native artifacts. | Databases, VM images, stateful containers, enterprise apps, HPC scratch. |
| Cost/Ops | Lowest $/GB at scale; lifecycle tiering (e.g., cold object tiers) can save ~80% on cold data; simpler growth. | Higher $/GB; over-provisioning for IOPS is common; more hands-on tuning and backup orchestration. |
Hybrid Strategies and the Road Ahead
The architecture that wins is the one that matches storage type to data behavior and keeps migration paths open. A pragmatic pattern:
- Hot tier on block. Keep transactional databases, VM disks, and build/test scratch on local NVMe or shared block volumes. Enforce sub-ms latency and predictable IOPS.
- Warm/cold tiers on object. Move static content, logs, and historical datasets to object buckets with lifecycle policies. Use versioning and object lock to protect backups and audit trails. Cold tiers can trim storage costs by ~80% for rarely accessed data.
- Integrate with S3-compatible gateways. For legacy workflows, front a bucket with NFS/SMB to avoid rewriting applications. For cloud-adjacent analytics, process directly from S3 endpoints without copying back to block.
- Design for convergence. Unified platforms increasingly present file and object on a common backend, and NVMe-oF is bringing near-local block latency over the network. Both trends reduce trade-offs: object becomes faster and more “filesystem-like,” while block becomes more elastic and shareable across dedicated fleets.
In dedicated environments, that translates to: place data where it performs best today, automate its lifecycle to where it costs least tomorrow, and rely on open interfaces (S3, POSIX, NVMe-oF) so you can evolve without re-platforming.
Conclusion: Design for Performance and Scale—Not Either/Or

Object and block storage solve different problems by design. Block gives you deterministic, low-latency control for every 4K update—perfect for databases, VM disks, and stateful services. Object gives you near-limitless scale, integrated durability, and governance—perfect for archives, media, analytics inputs, and cloud-native artifacts. The most resilient dedicated environments blend both: block for hot paths, object for everything that benefits from distribution and lifecycle economics.
If you are planning the next refresh or building net-new, start by inventorying access patterns and consistency. Put strict transactions and small random I/O on block. Put bulk, unstructured, and shared-across-sites data on object with policies for retention, versioning, and tiering. Add S3-compatible gateways where you need to bridge legacy interfaces, and consider NVMe-oF as you centralize high-performance pools. The result is a storage fabric that meets SLAs today and scales gracefully as datasets—and ambitions—grow.
Launch Your Dedicated Server
Choose from 1,300+ configurations and spin up servers with NVMe and 200 Gbps bandwidth in 21 global locations.