Blog
Milliseconds Matter: Build Fast German Dedicated Server
Modern European web users measure patience in milliseconds. If your traffic surges from Helsinki at breakfast, Madrid at lunch, and LA before dawn, every extra hop or slow disk seek shows up in conversion and churn metrics. Below is a comprehensive guide on putting a dedicated server in Germany to work at peak efficiency. It zeroes in on network routing, edge caching, high-throughput hardware, K8 node tuning, and IaC-driven scale-outs.
Choose Melbicom— 240+ ready-to-go server configs — Tier III-certified DC in Frankfurt — 55+ PoP CDN across 6 continents |
 |
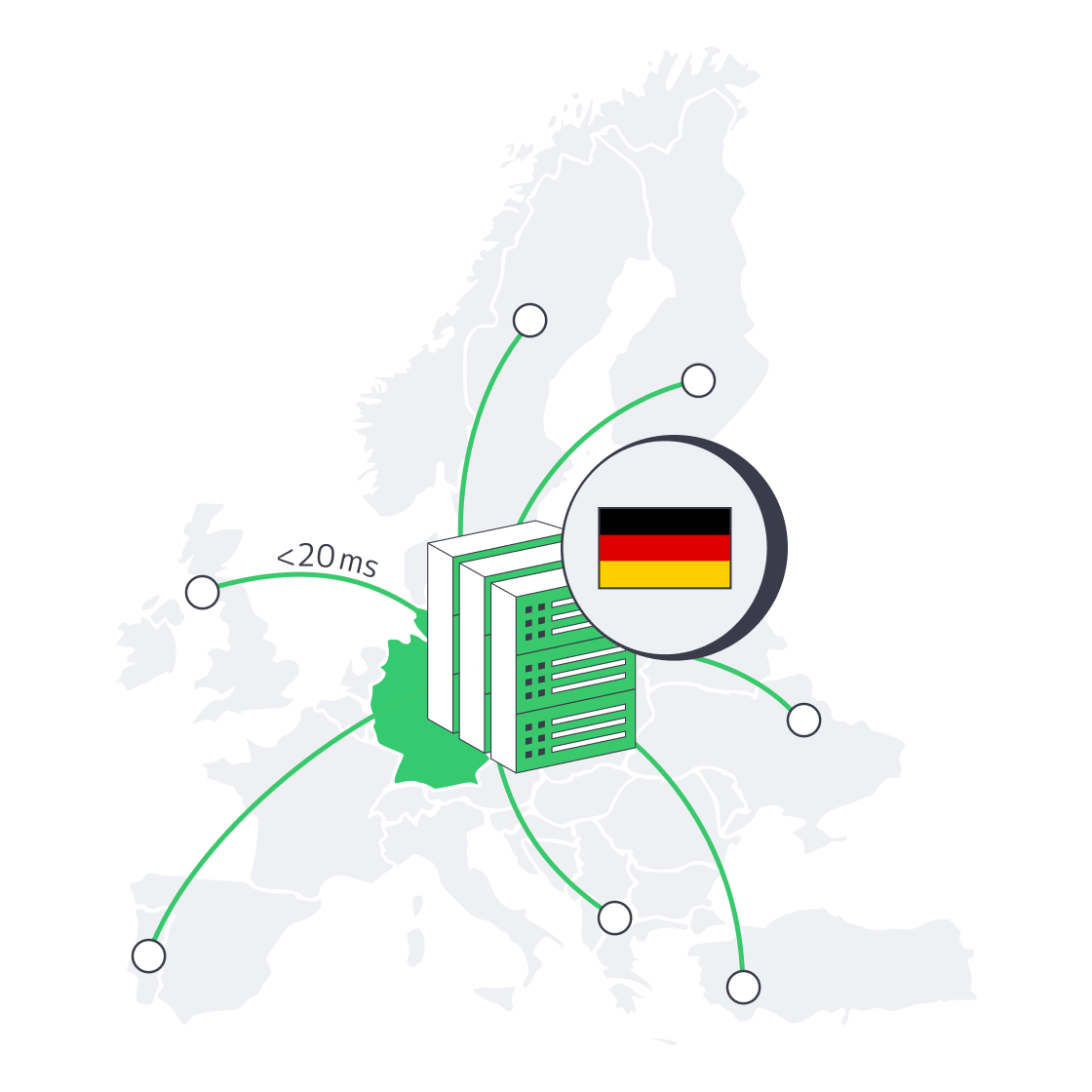
How Does Frankfurt’s DE-CIX Cut Latency for Dedicated Servers in Germany?
Frankfurt’s DE-CIX hub is the world’s busiest Internet Exchange Point (IXP), pushing tens of terabits per second across hundreds of carriers and content networks. Placing workloads a few hundred fiber meters from that switch fabric means your packets jump straight into Europe’s core without detouring through trans-regional transit. When Melbicom peers at DE-CIX and two other German IXPs, routes flatten, hop counts fall, and RTT to major EU capitals settles in the 10–20 ms band. That alone can shave a third off time-to-first-byte for dynamic pages.
GIX Carriers and Smart BGP
A single peering fabric is not enough. Melbicom blends Tier-1 transit plus GIX carriers—regional backbones tuned for iGaming and streaming packets—to create multi-path BGP policies. If Amsterdam congests, traffic re-converges via Zurich; if a transatlantic fiber blinks, packets roll over to a secondary New York–Frankfurt path. The failover completes in sub-second, so your users never see a timeout.
Edge Caching for Line-Speed Delivery
Routing is half the latency story; geography still matters for static payloads. That’s where Melbicom’s 55-plus-PoP CDN enters. Heavy objects—imagery, video snippets, JS bundles—cache at the edge, often a metro hop away from the end-user. Tests show edge hits trimming 30–50 % off total page-load time compared with origin-only fetches.
Which Hardware Choices Make a Dedicated Server in Germany Fast?
Packet paths are useless if the server stalls internally. In Melbicom’s German configurations today, the performance ROI centers on PCIe 4.0 NVMe storage, DDR4 memory, and modern Intel Xeon CPUs that deliver excellent throughput for high-traffic web applications.
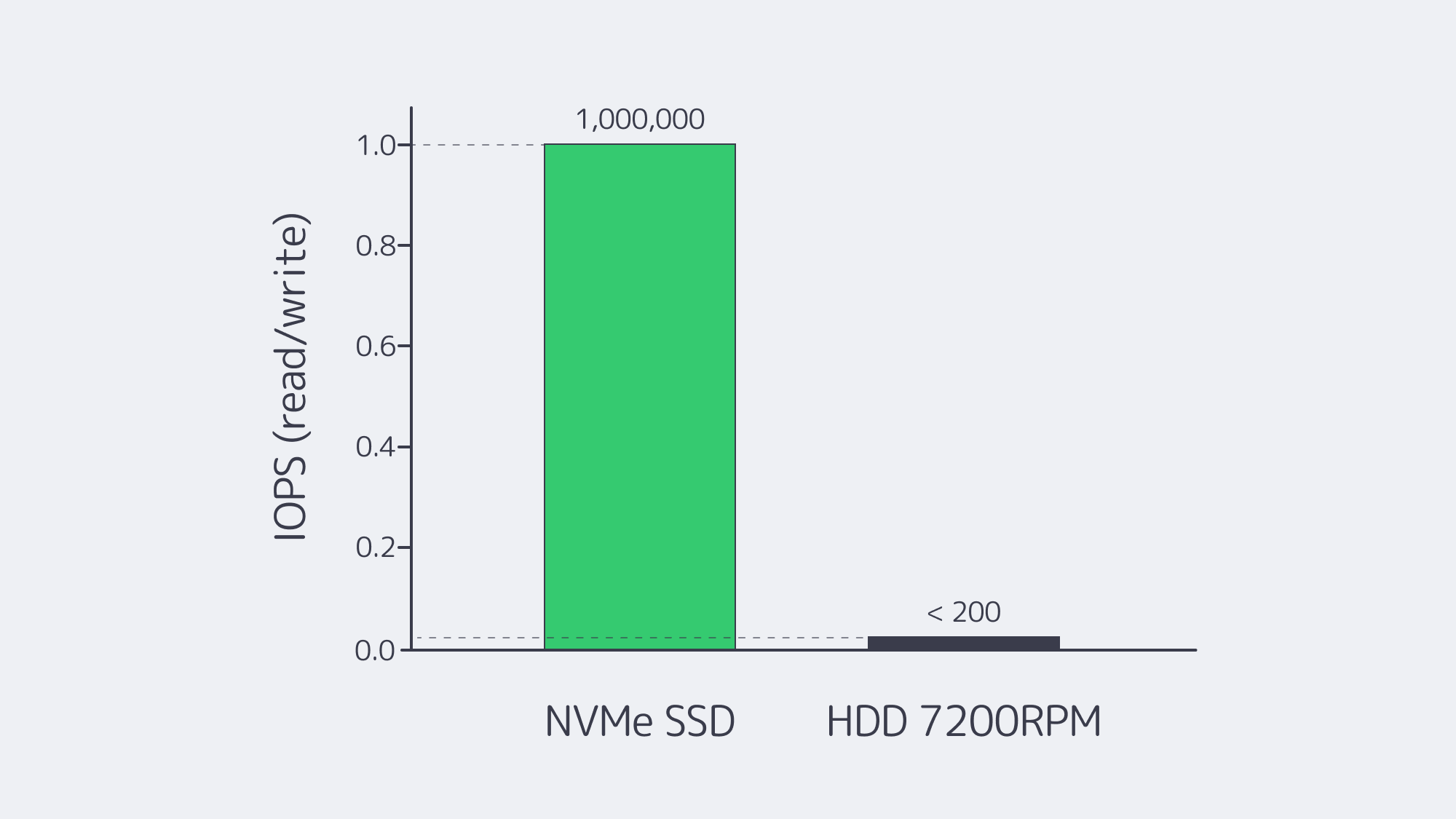
PCIe 4.0 NVMe: The Disk That Isn’t
Spinning disks top out near ~200 MB/s and < 200 IOPS. A PCIe 4.0 x4 NVMe drive sustains ~7 GB/s sequential reads and scales to ~1 M random-read IOPS with tens of microseconds access latency, so database checkpoints, search-index builds, and large media exports finish before an HDD hits stride. For workloads where latency variance matters—checkout APIs, chat messages—NVMe’s microsecond-scale response removes tail-latency spikes.
| Metric | NVMe (PCIe 4.0) | HDD 7,200 rpm |
|---|---|---|
| Peak sequential throughput | ~7 GB/s | ~0.2 GB/s |
| Random read IOPS | ~1,000,000 | < 200 |
| Typical read latency | ≈ 80–100 µs | ≈ 5–10 ms |
Table. PCIe 4.0 NVMe vs HDD.
DDR4: Memory Bandwidth that Still Delivers
DDR4-3200 provides 25.6 GB/s per channel (8 bytes × 3,200 MT/s | DDR4 overview). On 6–8 channel Xeon servers, that translates to ~150–200+ GB/s of aggregate bandwidth—ample headroom for in-memory caches, compiled templates, and real-time analytics common to high-traffic web stacks.
Modern Xeon Compute: High Core Counts and Turbo Headroom
Modern Intel Xeon Scalable CPUs deliver strong per-core performance with dozens of cores per socket, large L3 caches, and AVX-512/AMX acceleration for media and analytics. For container fleets handling chat ops, WebSocket fan-out, or Node.js edge functions, these CPUs offer a balanced mix of high single-thread turbo for spiky, latency-sensitive paths and ample total cores for parallel request handling (Intel Xeon Scalable family).
How to Tune Kubernetes Nodes for Low-Latency Workloads
Running containers on a dedicated server beats cloud VMs for raw speed, but only if the node is tuned like a racecar. Three adjustments yield the biggest gains:
- CPU pinning via the CPU Manager — Reserve whole cores for latency-critical pods while isolating system daemons to a separate CPU set. Spiky log rotations no longer interrupt your trading API.
- NUMA-aware scheduling — Align memory pages with their local cores, preventing cross-socket ping-pong that can add ~10 % latency on two-socket systems.
- HugePages for mega-buffers — Enabling 2 MiB pages slashes TLB misses in JVMs and databases, raising query throughput by double digits with no code changes.
Spinning-disk bottlenecks vanish automatically if the node boots off NVMe; keep an HDD RAID only for cold backups. Likewise, allocate scarce IPv4 addresses only to public-facing services; internal pods can run dual-stack and lean on plentiful IPv6 space.
How to Use IaC for Just-in-Time Scale-Out
Traffic spikes rarely send invitations. With Infrastructure as Code (IaC) you script the whole server lifecycle, from bare-metal provisioning through OS hardening to Kubernetes join. Need a second dedicated server Germany node before tonight’s marketing blast? terraform apply grabs one of the 200+ ready configs Melbicom keeps in German inventory, injects SSH keys, and hands it to Ansible for post-boot tweaks. Spin-up time drops from days to well under two hours—and with templates, every node is identical, eliminating the “snowflake-server” drift that haunts manual builds.
IaC also simplifies multi-region redundancy. Because a Frankfurt root module differs from an Amsterdam one only by a few variables, expanding across Melbicom’s global footprint becomes a pull request, not a heroic night shift. The same codebase can version-control IPv6 enablement, swap in newer CPUs, or roll back a bad driver package in minutes.
What Pitfalls Should You Avoid—Spinning Disks and Scarce IPv4?
Spinning disks still excel at cheap terabytes but belong on backup tiers, not in hot paths. IPv4 addresses cost real money and are rationed; architect dual-stack services now so scale-outs aren’t gated by address scarcity later. That’s it—legacy mentioned.
Why Frankfurt Is a Smart Choice for Dedicated Server Hosting in Germany

Germany’s position at the crossroads of Europe’s Internet, coupled with the sheer gravitational pull of DE-CIX, makes Frankfurt an obvious home for latency-sensitive applications. Add in GIX carrier diversity, edge caching, PCIe 4.0 NVMe, DDR4 memory, and modern Xeon compute, then wrap the stack with Kubernetes node tuning and IaC automation, and you have an infrastructure that meets modern traffic head-on. Milliseconds fall away, throughput rises, and scale-outs become code commits instead of capital projects. For teams that live and die by user-experience metrics, that difference shows up in retention curves and revenue lines almost immediately.
Order a German Dedicated Server Now
Deploy high-performance hardware in Frankfurt today—PCIe 4.0 NVMe, 200 Gbps ports, and 24/7 support included.